
elastic search
0、简介 mysql用作持久化存储,ES用作检索
基本概念:index库>type表>document文档 index索引 动词:相当于mysql的insert
名词:相当于mysql的db Type类型 在index中,可以定义一个或多个类型 类似于mysql的table,每一种类型的数据放在一起 Document文档 保存在某个index下,某种type的一个数据document,文档是json格式的,document就像是mysql中的某个table里面的内容。每一行对应的列叫属性、
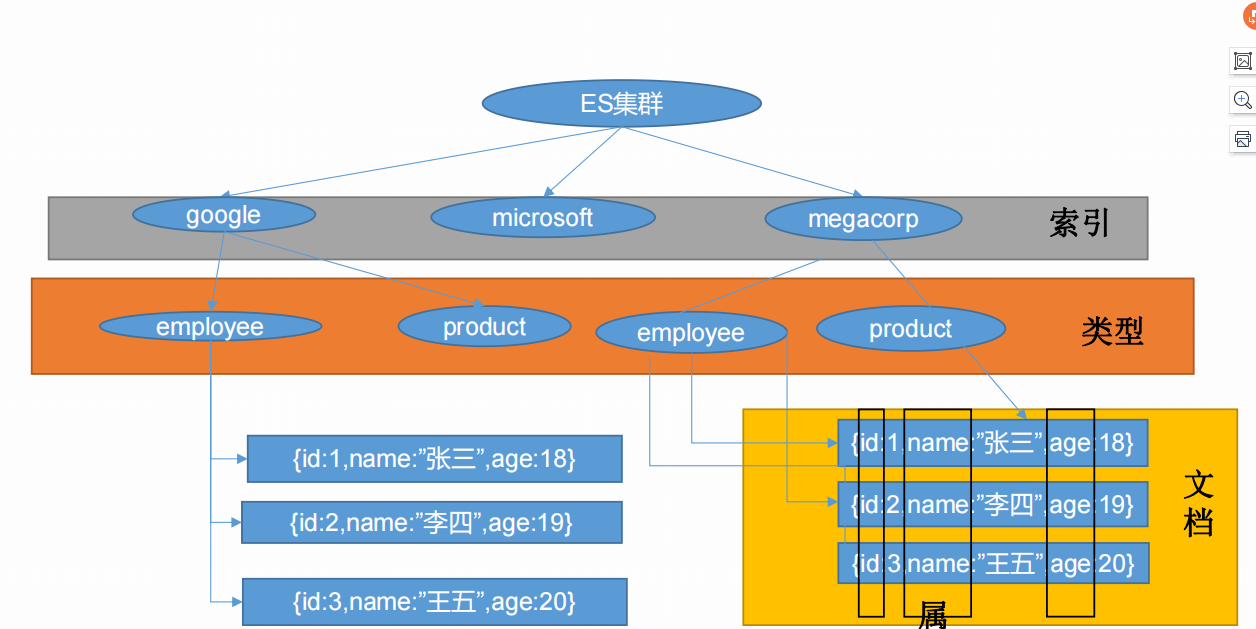
为什么ES搜索快?倒排索引
保存的记录
- 红海行动
- 探索红海行动
- 红海特别行动
- 红海记录片
- 特工红海特别探索
将内容分词就记录到索引中
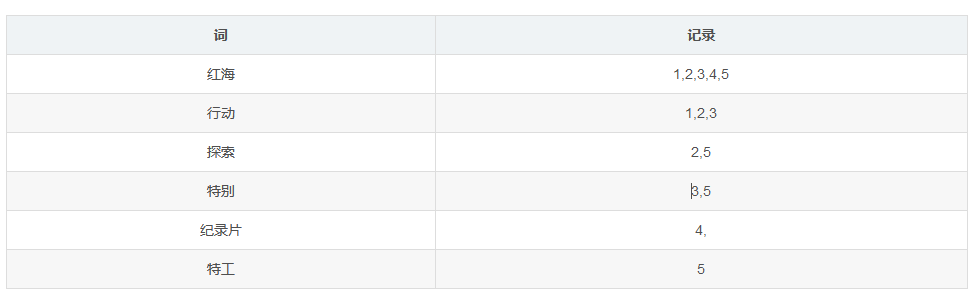
检索:
1)、红海特工行动?查出后计算相关性得分:3号记录命中了2次,且3号本身才有3个单词,2/3,所以3号最匹配
2)、红海行动?
关系型数据库中两个数据表示是独立的,即使他们里面有相同名称的列也不影响使用,但ES中不是这样的。elasticsearch是基于Lucene开发的搜索引擎,而ES中不同type下名称相同的filed最终在Lucene中的处理方式是一样的。
两个不同type下的两个user_name,在ES同一个索引下其实被认为是同一个filed,你必须在两个不同的type中定义相同的filed映射。否则,不同type中的相同字段名称就会在处理中出现冲突的情况,导致Lucene处理效率下降。
去掉type就是为了提高ES处理数据的效率。
Elasticsearch 7.xURL中的type参数为可选。比如,索引一个文档不再要求提供文档类型。
Elasticsearch 8.x不再支持URL中的type参数。
解决:将索引从多类型迁移到单类型,每种类型文档一个独立索引
1、安装elastic search
dokcer中安装elastic search
(1)下载ealastic search(存储和检索)和kibana(可视化检索)
docker pull elasticsearch:7.4.2 docker pull kibana:7.4.2 版本要统一
(2)配置
# 将docker里的目录挂载到linux的/mydata目录中 # 修改/mydata就可以改掉docker里的 mkdir -p /mydata/elasticsearch/config mkdir -p /mydata/elasticsearch/data # es可以被远程任何机器访问 echo "http.host: 0.0.0.0" >/mydata/elasticsearch/config/elasticsearch.yml # 递归更改权限,es需要访问 chmod -R 777 /mydata/elasticsearch/
(3)启动Elastic search
# 9200是用户交互端口 9300是集群心跳端口 # -e指定是单阶段运行 # -e指定占用的内存大小,生产时可以设置32G docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \ -e "discovery.type=single-node" \ -e ES_JAVA_OPTS="-Xms64m -Xmx512m" \ -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \ -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \ -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \ -d elasticsearch:7.4.2 # 设置开机启动elasticsearch docker update elasticsearch --restart=always
因为容器里的文件映射到了外面,所以删除容器和新建容器数据还在
第一次查docker ps启动了,第二次查的时候发现关闭了,docker logs elasticsearch
http://192.168.56.10:9200
数据挂载到外面,但是访问权限不足
把/mydata/elasticsearch下文件夹的权限设置好,上面已经设置过了
#遇到了更新阿里源也下载不下来kibana镜像的情况,先在别的网络下载下来后传到vagrant中 docker save -o kibana.tar kibana:7.4.2 docker load -i kibana.tar # 如何通过其他工具链接ssh 修改/etc/ssh/sshd_config 修改 PasswordAuthentication yes systemctl restart sshd.service 或 service sshd restart # 连接192.168.56.10:22端口成功,用户名root,密码vagrant 也可以通过vagrant ssh-config查看ip和端口,此时是127.0.0.1:2222
在安装离线docker镜像的时候还提示内存不足,看了下是因为外部挂载的内存也算在了vagrant中,即使外部删了很多文件,vagrant中df -h硬盘占用率也不下降。我在外部删完文件后在内部又rm -rf XXX 强行接触占用
(4)启动kibana:
# kibana指定了了ES交互端口9200 # 5600位kibana主页端口 docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.56.10:9200 -p 5601:5601 -d kibana:7.4.2 # 设置开机启动kibana docker update kibana --restart=always
(5)测试
查看elasticsearch版本信息: http://192.168.56.10:9200
{ "name": "66718a266132", "cluster_name": "elasticsearch", "cluster_uuid": "xhDnsLynQ3WyRdYmQk5xhQ", "version": { "number": "7.4.2", "build_flavor": "default", "build_type": "docker", "build_hash": "2f90bbf7b93631e52bafb59b3b049cb44ec25e96", "build_date": "2019-10-28T20:40:44.881551Z", "build_snapshot": false, "lucene_version": "8.2.0", "minimum_wire_compatibility_version": "6.8.0", "minimum_index_compatibility_version": "6.0.0-beta1" }, "tagline": "You Know, for Search" }
显示elasticsearch 节点信息http://192.168.56.10:9200/_cat/nodes
127.0.0.1 14 99 25 0.29 0.40 0.22 dilm * 66718a266132 66718a266132代表上面的结点 *代表是主节点
kibana
访问Kibana: http://192.168.56.10:5601/app/kibana
2、初步检索
1)检索es信息
(1)GET /_cat/nodes:查看所有节点
如:http://192.168.56.10:9200/_cat/nodes
可以直接浏览器输入上面的url,也可以在kibana中输入
GET /_cat/nodes127.0.0.1 12 97 3 0.00 0.01 0.05 dilm * 66718a266132 66718a266132代表结点 *代表是主节点(2)
GET /_cat/health:查看es健康状况如: http://192.168.56.10:9200/_cat/health
1613741055 13:24:15 elasticsearch green 1 1 0 0 0 0 0 0 - 100.0%注:green表示健康值正常
(3)
GET /_cat/master:查看主节点如: http://192.168.56.10:9200/_cat/master
089F76WwSaiJcO6Crk7MpA 127.0.0.1 127.0.0.1 66718a266132 主节点唯一编号 虚拟机地址(4)
GET/_cat/indicies:查看所有索引 ,等价于mysql数据库的show databases;如:http://192.168.56.10:9200/_cat/indices
green open .kibana_task_manager_1 DhtDmKrsRDOUHPJm1EFVqQ 1 0 2 3 40.8kb 40.8kb green open .apm-agent-configuration vxzRbo9sQ1SvMtGkx6aAHQ 1 0 0 0 230b 230b green open .kibana_1 rdJ5pejQSKWjKxRtx-EIkQ 1 0 5 1 18.2kb 18.2kb 这3个索引是kibana创建的2)新增文档
保存一个数据,保存在哪个索引的哪个类型下(哪张数据库哪张表下),保存时用唯一标识指定
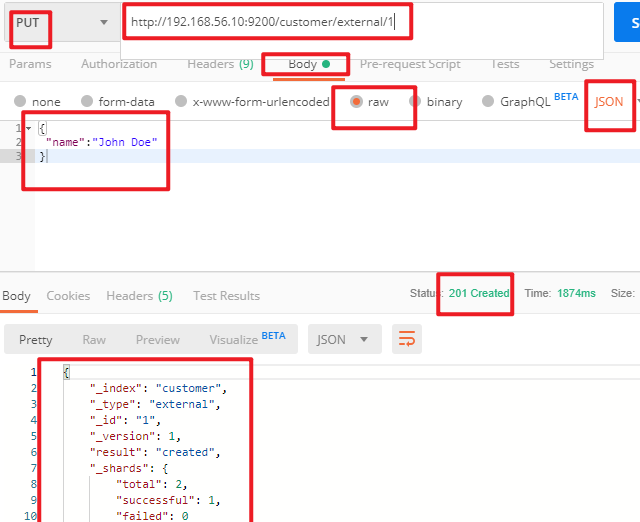
# # 在customer索引下的external类型下保存1号数据 PUT customer/external/1 # POSTMAN输入 http://192.168.56.10:9200/customer/external/1 { "name":"John Doe" }PUT和POST区别
POST新增。如果不指定id,会自动生成id。指定id就会修改这个数据,并新增版本号;
可以不指定id,不指定id时永远为创建
指定不存在的id为创建
指定存在的id为更新,而版本号会根据内容变没变而觉得版本号递增与否
PUT可以新增也可以修改。PUT必须指定id;由于PUT需要指定id,我们一般用来做修改操作,不指定id会报错。
必须指定id
版本号总会增加
怎么记:put和java里map.put一样必须指定key-value。而post相当于mysql insert
seq_no和version的区别:
每个文档的版本号"_version" 起始值都为1 每次对当前文档成功操作后都加1
而序列号"_seq_no"则可以看做是索引的信息 在第一次为索引插入数据时为0,每对索引内数据操作成功一次sqlNO加1, 并且文档会记录是第几次操作使它成为现在的情况的
创建数据成功后,显示201 created表示插入记录成功。
返回数据: 带有下划线开头的,称为元数据,反映了当前的基本信息。 { "_index": "customer", 表明该数据在哪个数据库下; "_type": "external", 表明该数据在哪个类型下; "_id": "1", 表明被保存数据的id; "_version": 1, 被保存数据的版本 "result": "created", 这里是创建了一条数据,如果重新put一条数据,则该状态会变为updated,并且版本号也会发生变化。 "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 0, "_primary_term": 1 }下面选用POST方式:
添加数据的时候,不指定ID,会自动的生成id,并且类型是新增:
{ "_index": "customer", "_type": "external", "_id": "5MIjvncBKdY1wAQm-wNZ", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 11, "_primary_term": 6 }再次使用POST插入数据,不指定ID,仍然是新增的:
{ "_index": "customer", "_type": "external", "_id": "5cIkvncBKdY1wAQmcQNk", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 12, "_primary_term": 6 }添加数据的时候,指定ID,会使用该id,并且类型是新增:
{ "_index": "customer", "_type": "external", "_id": "2", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 13, "_primary_term": 6 }再次使用POST插入数据,指定同样的ID,类型为updated
{ "_index": "customer", "_type": "external", "_id": "2", "_version": 2, "result": "updated", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 14, "_primary_term": 6 }3)查看文档
GET /customer/external/1
http://192.168.56.10:9200/customer/external/1
{ "_index": "customer", "_type": "external", "_id": "1", "_version": 10, "_seq_no": 18,//并发控制字段,每次更新都会+1,用来做乐观锁 "_primary_term": 6,//同上,主分片重新分配,如重启,就会变化 "found": true, "_source": { "name": "John Doe" } }乐观锁用法:通过“
if_seq_no=1&if_primary_term=1”,当序列号匹配的时候,才进行修改,否则不修改。实例:将id=1的数据更新为name=1,然后再次更新为name=2,起始1_seq_no=18,_primary_term=6
(1)将name更新为1
PUT http://192.168.56.10:9200/customer/external/1?if_seq_no=18&if_primary_term=6(2)将name更新为2,更新过程中使用seq_no=18
PUT http://192.168.56.10:9200/customer/external/1?if_seq_no=18&if_primary_term=6
结果为:
{ "error": { "root_cause": [ { "type": "version_conflict_engine_exception", "reason": "[1]: version conflict, required seqNo [18], primary term [6]. current document has seqNo [19] and primary term [6]", "index_uuid": "mG9XiCQISPmfBAmL1BPqIw", "shard": "0", "index": "customer" } ], "type": "version_conflict_engine_exception", "reason": "[1]: version conflict, required seqNo [18], primary term [6]. current document has seqNo [19] and primary term [6]", "index_uuid": "mG9XiCQISPmfBAmL1BPqIw", "shard": "0", "index": "customer" }, "status": 409 }出现更新错误。
(3)查询新的数据
GET http://192.168.56.10:9200/customer/external/1
{ "_index": "customer", "_type": "external", "_id": "1", "_version": 11, "_seq_no": 19, "_primary_term": 6, "found": true, "_source": { "name": "1" } }能够看到_seq_no变为19
(4)再次更新,更新成功
PUT http://192.168.56.10:9200/customer/external/1?if_seq_no=19&if_primary_term=1
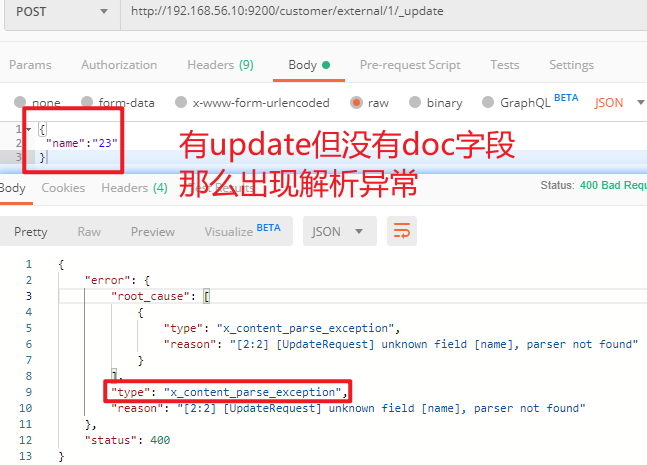
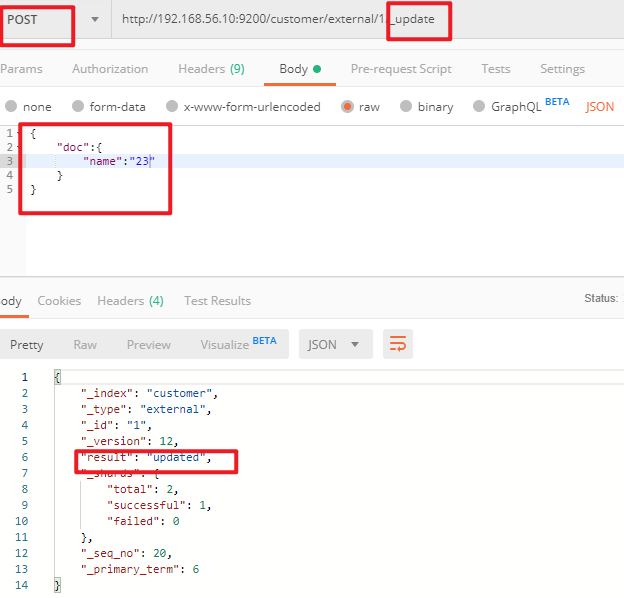
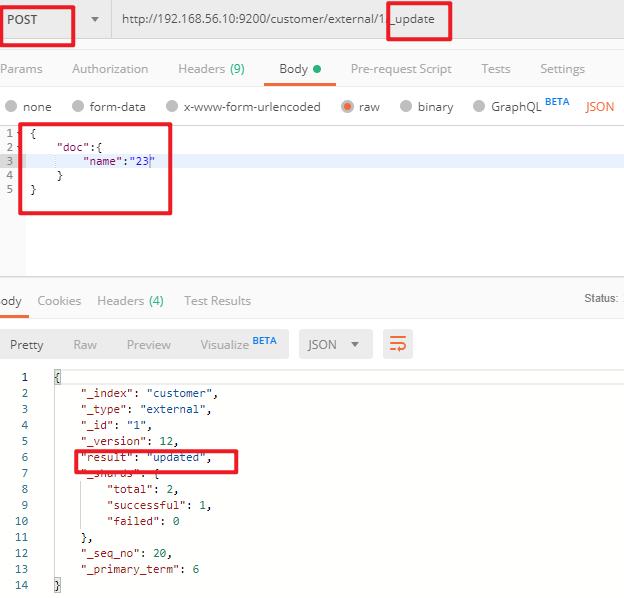
4)更新文档_update
POST customer/externel/1/_update { "doc":{ "name":"111" } } 或者 POST customer/externel/1 { "doc":{ "name":"222" } } 或者 PUT customer/externel/1 { "doc":{ "name":"222" } }不同:带有update情况下
POST操作会对比源文档数据,如果相同不会有什么操作,文档version不增加。
PUT操作总会重新保存并增加version版本
POST时带_update对比元数据如果一样就不进行任何操作。
看场景:
对于大并发更新,不带update
对于大并发查询偶尔更新,带update;对比更新,重新计算分配规则
(1)POST更新文档,带有_update
http://192.168.56.10:9200/customer/external/1/_update
如果再次执行更新,则不执行任何操作,序列号也不发生变化
返回 { "_index": "customer", "_type": "external", "_id": "1", "_version": 12, "result": "noop", // 无操作 "_shards": { "total": 0, "successful": 0, "failed": 0 }, "_seq_no": 20, "_primary_term": 6 }POST更新方式,会对比原来的数据,和原来的相同,则不执行任何操作(version和_seq_no)都不变。
(2)POST更新文档,不带_update
在更新过程中,重复执行更新操作,数据也能够更新成功,不会和原来的数据进行对比。
{ "_index": "customer", "_type": "external", "_id": "1", "_version": 13, "result": "updated", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 21, "_primary_term": 6 }5)删除文档或索引
DELETE customer/external/1 DELETE customer注:elasticsearch并没有提供删除类型的操作,只提供了删除索引和文档的操作。
实例:删除id=1的数据,删除后继续查询
DELETE http://192.168.56.10:9200/customer/external/1
{ "_index": "customer", "_type": "external", "_id": "1", "_version": 14, "result": "deleted", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 22, "_primary_term": 6 }再次执行DELETE http://192.168.56.10:9200/customer/external/1
{ "_index": "customer", "_type": "external", "_id": "1", "_version": 15, "result": "not_found", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 23, "_primary_term": 6 }GET http://192.168.56.10:9200/customer/external/1
{ "_index": "customer", "_type": "external", "_id": "1", "found": false }删除索引
实例:删除整个costomer索引数据
删除前,所有的索引http://192.168.56.10:9200/_cat/indices
green open .kibana_task_manager_1 DhtDmKrsRDOUHPJm1EFVqQ 1 0 2 0 31.3kb 31.3kb green open .apm-agent-configuration vxzRbo9sQ1SvMtGkx6aAHQ 1 0 0 0 283b 283b green open .kibana_1 rdJ5pejQSKWjKxRtx-EIkQ 1 0 8 3 28.8kb 28.8kb yellow open customer mG9XiCQISPmfBAmL1BPqIw 1 1 9 1 8.6kb 8.6kb删除“ customer ”索引
DELTE http://192.168.56.10:9200/customer
响应 { "acknowledged": true }删除后,所有的索引http://192.168.56.10:9200/_cat/indices
green open .kibana_task_manager_1 DhtDmKrsRDOUHPJm1EFVqQ 1 0 2 0 31.3kb 31.3kb green open .apm-agent-configuration vxzRbo9sQ1SvMtGkx6aAHQ 1 0 0 0 283b 283b green open .kibana_1 rdJ5pejQSKWjKxRtx-EIkQ 1 0 8 3 28.8kb 28.8kb6)ES的批量操作——bulk
匹配导入数据
POST http://192.168.56.10:9200/customer/external/_bulk
两行为一个整体 {"index":{"_id":"1"}} {"name":"a"} {"index":{"_id":"2"}} {"name":"b"} 注意格式json和text均不可,要去kibana里Dev Tools语法格式:
{action:{metadata}}\n {request body }\n {action:{metadata}}\n {request body }\n这里的批量操作,当发生某一条执行发生失败时,其他的数据仍然能够接着执行,也就是说彼此之间是独立的。
bulk api以此按顺序执行所有的action(动作)。如果一个单个的动作因任何原因失败,它将继续处理它后面剩余的动作。当bulk api返回时,它将提供每个动作的状态(与发送的顺序相同),所以您可以检查是否一个指定的动作是否失败了。
实例1: 执行多条数据POST /customer/external/_bulk {"index":{"_id":"1"}} {"name":"John Doe"} {"index":{"_id":"2"}} {"name":"John Doe"}执行结果
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated. { "took" : 318, 花费了多少ms "errors" : false, 没有发生任何错误 "items" : [ 每个数据的结果 { "index" : { 保存 "_index" : "customer", 索引 "_type" : "external", 类型 "_id" : "1", 文档 "_version" : 1, 版本 "result" : "created", 创建 "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1, "status" : 201 新建完成 } }, { "index" : { 第二条记录 "_index" : "customer", "_type" : "external", "_id" : "2", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 1, "_primary_term" : 1, "status" : 201 } } ] }实例2:对于整个索引执行批量操作
POST /_bulk {"delete":{"_index":"website","_type":"blog","_id":"123"}} {"create":{"_index":"website","_type":"blog","_id":"123"}} {"title":"my first blog post"} {"index":{"_index":"website","_type":"blog"}} {"title":"my second blog post"} {"update":{"_index":"website","_type":"blog","_id":"123"}} {"doc":{"title":"my updated blog post"}}运行结果:
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated. { "took" : 304, "errors" : false, "items" : [ { "delete" : { 删除 "_index" : "website", "_type" : "blog", "_id" : "123", "_version" : 1, "result" : "not_found", 没有该记录 "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 0, "_primary_term" : 1, "status" : 404 没有该 } }, { "create" : { 创建 "_index" : "website", "_type" : "blog", "_id" : "123", "_version" : 2, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 1, "_primary_term" : 1, "status" : 201 } }, { "index" : { 保存 "_index" : "website", "_type" : "blog", "_id" : "5sKNvncBKdY1wAQmeQNo", "_version" : 1, "result" : "created", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 2, "_primary_term" : 1, "status" : 201 } }, { "update" : { 更新 "_index" : "website", "_type" : "blog", "_id" : "123", "_version" : 3, "result" : "updated", "_shards" : { "total" : 2, "successful" : 1, "failed" : 0 }, "_seq_no" : 3, "_primary_term" : 1, "status" : 200 } } ] }7)样本测试数据
准备了一份顾客银行账户信息的虚构的JSON文档样本。每个文档都有下列的schema(模式)。
{ "account_number": 1, "balance": 39225, "firstname": "Amber", "lastname": "Duke", "age": 32, "gender": "M", "address": "880 Holmes Lane", "employer": "Pyrami", "email": "amberduke@pyrami.com", "city": "Brogan", "state": "IL" }https://github.com/elastic/elasticsearch/blob/master/docs/src/test/resources/accounts.json ,导入测试数据,
POST bank/account/_bulk 上面的数据http://192.168.56.10:9200/_cat/indices 刚导入了1000条 yellow open bank 99m64ElxRuiH46wV7RjXZA 1 1 1000 0 427.8kb 427.8kb二、进阶检索
3.1)search检索文档
ES支持两种基本方式检索;
通过REST request uri 发送搜索参数 (uri +检索参数);
通过REST request body 来发送它们(uri+请求体);
信息检索
API: https://www.elastic.co/guide/en/elasticsearch/reference/7.x/getting-started-search.html请求参数方式检索 GET bank/_search?q=*&sort=account_number:asc 说明: q=* # 查询所有 sort # 排序字段 asc #升序 检索bank下所有信息,包括type和docs GET bank/_search返回内容:
- took – 花费多少ms搜索
- timed_out – 是否超时
- _shards – 多少分片被搜索了,以及多少成功/失败的搜索分片
- max_score –文档相关性最高得分
- hits.total.value - 多少匹配文档被找到
- hits.sort - 结果的排序key(列),没有的话按照score排序
- hits._score - 相关得分 (not applicable when using match_all)
GET bank/_search?q=*&sort=account_number:asc 检索了1000条数据,但是根据相关性算法,只返回10条uri+请求体进行检索
GET /bank/_search { "query": { "match_all": {} }, "sort": [ { "account_number": "asc" }, { "balance":"desc"} ] }POSTMAN中get不能携带请求体,我们变为post也是一样的,我们post一个jsob风格的查询请求体到_search
需要了解,一旦搜索的结果被返回,es就完成了这次请求,不能切不会维护任何服务端的资源或者结果的cursor游标
3.2)DSL领域特定语言
这节教我们如何写复杂查询
Elasticsearch提供了一个可以执行查询的Json风格的DSL(domain-specific language领域特定语言)。这个被称为Query DSL,该查询语言非常全面。
(1)基本语法格式
一个查询语句的典型结构如果针对于某个字段,那么它的结构如下: { QUERY_NAME:{ # 使用的功能 FIELD_NAME:{ # 功能参数 ARGUMENT:VALUE, ARGUMENT:VALUE,... } } }示例 使用时不要加#注释内容 GET bank/_search { "query": { # 查询的字段 "match_all": {} }, "from": 0, # 从第几条文档开始查 "size": 5, "_source":["balance"], "sort": [ { "account_number": { # 返回结果按哪个列排序 "order": "desc" # 降序 } } ] } _source为要返回的字段query定义如何查询;
- match_all查询类型【代表查询所有的索引】,es中可以在query中组合非常多的查询类型完成复杂查询;
- 除了query参数之外,我们可也传递其他的参数以改变查询结果,如sort,size;
- from+size限定,完成分页功能;
- sort排序,多字段排序,会在前序字段相等时后续字段内部排序,否则以前序为准;
(2)from返回部分字段GET bank/_search { "query": { "match_all": {} }, "from": 0, "size": 5, "sort": [ { "account_number": { "order": "desc" } } ], "_source": ["balance","firstname"] }查询结果:
{ "took" : 18, # 花了18ms "timed_out" : false, # 没有超时 "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1000, # 命令1000条 "relation" : "eq" }, "max_score" : null, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "999", # 第一条数据id是999 "_score" : null, # 得分信息 "_source" : { "firstname" : "Dorothy", "balance" : 6087 }, "sort" : [ # 排序字段的值 999 ] }, 省略。。。(3)query/match匹配查询
如果是非字符串,会进行精确匹配。如果是字符串,会进行全文检索
- 基本类型(非字符串),精确控制
GET bank/_search { "query": { "match": { "account_number": "20" } } }match返回account_number=20的数据。
查询结果:
{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, // 得到一条 "relation" : "eq" }, "max_score" : 1.0, # 最大得分 "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "20", "_score" : 1.0, "_source" : { # 该条文档信息 "account_number" : 20, "balance" : 16418, "firstname" : "Elinor", "lastname" : "Ratliff", "age" : 36, "gender" : "M", "address" : "282 Kings Place", "employer" : "Scentric", "email" : "elinorratliff@scentric.com", "city" : "Ribera", "state" : "WA" } } ] } }
- 字符串,全文检索
GET bank/_search { "query": { "match": { "address": "kings" } } }全文检索,最终会按照评分进行排序,会对检索条件进行分词匹配。
查询结果:
{ "took" : 30, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 2, "relation" : "eq" }, "max_score" : 5.990829, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "20", "_score" : 5.990829, "_source" : { "account_number" : 20, "balance" : 16418, "firstname" : "Elinor", "lastname" : "Ratliff", "age" : 36, "gender" : "M", "address" : "282 Kings Place", "employer" : "Scentric", "email" : "elinorratliff@scentric.com", "city" : "Ribera", "state" : "WA" } }, { "_index" : "bank", "_type" : "account", "_id" : "722", "_score" : 5.990829, "_source" : { "account_number" : 722, "balance" : 27256, "firstname" : "Roberts", "lastname" : "Beasley", "age" : 34, "gender" : "F", "address" : "305 Kings Hwy", "employer" : "Quintity", "email" : "robertsbeasley@quintity.com", "city" : "Hayden", "state" : "PA" } } ] } }(4)
query/match_phrase[不拆分匹配]将需要匹配的值当成一整个单词(不分词)进行检索
match_phrase:不拆分字符串进行检索字段.keyword:必须全匹配上才检索成功前面的是包含mill或road就查出来,我们现在要都包含才查出
GET bank/_search { "query": { "match_phrase": { "address": "mill road" # 就是说不要匹配只有mill或只有road的,要匹配mill road一整个子串 } } }查处address中包含mill road的所有记录,并给出相关性得分
查看结果:
{ "took" : 32, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 8.926605, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "970", "_score" : 8.926605, "_source" : { "account_number" : 970, "balance" : 19648, "firstname" : "Forbes", "lastname" : "Wallace", "age" : 28, "gender" : "M", "address" : "990 Mill Road", # "mill road" "employer" : "Pheast", "email" : "forbeswallace@pheast.com", "city" : "Lopezo", "state" : "AK" } } ] } }match_phrase和match的区别,观察如下实例:
GET bank/_search { "query": { "match_phrase": { "address": "990 Mill" } } }查询结果:
{ "took" : 0, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, # 1 "relation" : "eq" }, "max_score" : 10.806405, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "970", "_score" : 10.806405, "_source" : { "account_number" : 970, "balance" : 19648, "firstname" : "Forbes", "lastname" : "Wallace", "age" : 28, "gender" : "M", "address" : "990 Mill Road", # "990 Mill" "employer" : "Pheast", "email" : "forbeswallace@pheast.com", "city" : "Lopezo", "state" : "AK" } } ] } }使用match的
keywordGET bank/_search { "query": { "match": { "address.keyword": "990 Mill" # 字段后面加上 .keyword } } }{ "took" : 0, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 0, # 因为要求完全equal,所以匹配不到 "relation" : "eq" }, "max_score" : null, "hits" : [ ] } }修改匹配条件为“990 Mill Road”
GET bank/_search { "query": { "match": { "address.keyword": "990 Mill Road" # 正好有这条文档,所以能匹配到 } } }查询出一条数据
{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, # 1 "relation" : "eq" }, "max_score" : 6.5032897, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "970", "_score" : 6.5032897, "_source" : { "account_number" : 970, "balance" : 19648, "firstname" : "Forbes", "lastname" : "Wallace", "age" : 28, "gender" : "M", "address" : "990 Mill Road", # equal "employer" : "Pheast", "email" : "forbeswallace@pheast.com", "city" : "Lopezo", "state" : "AK" } } ] } }文本字段的匹配,使用keyword,匹配的条件就是要显示字段的全部值,要进行精确匹配的。
match_phrase是做短语匹配,只要文本中包含匹配条件,就能匹配到。
(5)query/multi_math【多字段匹配】
state或者address中包含mill,并且在查询过程中,会对于查询条件进行分词。GET bank/_search { "query": { "multi_match": { # 前面的match仅指定了一个字段。 "query": "mill", "fields": [ # state和address有mill子串 不要求都有 "state", "address" ] } } }查询结果:
{ "took" : 28, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 4, "relation" : "eq" }, "max_score" : 5.4032025, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "970", "_score" : 5.4032025, "_source" : { "account_number" : 970, "balance" : 19648, "firstname" : "Forbes", "lastname" : "Wallace", "age" : 28, "gender" : "M", "address" : "990 Mill Road", # 有mill "employer" : "Pheast", "email" : "forbeswallace@pheast.com", "city" : "Lopezo", "state" : "AK" # 没有mill } }, { "_index" : "bank", "_type" : "account", "_id" : "136", "_score" : 5.4032025, "_source" : { "account_number" : 136, "balance" : 45801, "firstname" : "Winnie", "lastname" : "Holland", "age" : 38, "gender" : "M", "address" : "198 Mill Lane", # mill "employer" : "Neteria", "email" : "winnieholland@neteria.com", "city" : "Urie", "state" : "IL" # 没有mill } }, { "_index" : "bank", "_type" : "account", "_id" : "345", "_score" : 5.4032025, "_source" : { "account_number" : 345, "balance" : 9812, "firstname" : "Parker", "lastname" : "Hines", "age" : 38, "gender" : "M", "address" : "715 Mill Avenue", # "employer" : "Baluba", "email" : "parkerhines@baluba.com", "city" : "Blackgum", "state" : "KY" # 没有mill } }, { "_index" : "bank", "_type" : "account", "_id" : "472", "_score" : 5.4032025, "_source" : { "account_number" : 472, "balance" : 25571, "firstname" : "Lee", "lastname" : "Long", "age" : 32, "gender" : "F", "address" : "288 Mill Street", # "employer" : "Comverges", "email" : "leelong@comverges.com", "city" : "Movico", "state" : "MT" # 没有mill } } ] } }(6)query/bool/must复合查询
复合语句可以合并,任何其他查询语句,包括符合语句。这也就意味着,复合语句之间可以互相嵌套,可以表达非常复杂的逻辑。
must:必须达到must所列举的所有条件
must_not:必须不匹配must_not所列举的所有条件。
should:应该满足should所列举的条件。满足条件最好,不满足也可以,满足得分更高
实例:查询gender=m,并且address=mill的数据GET bank/_search { "query":{ "bool":{ # "must":[ # 必须有这些字段 {"match":{"address":"mill"}}, {"match":{"gender":"M"}} ] } } }查询结果:
{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 3, "relation" : "eq" }, "max_score" : 6.0824604, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "970", "_score" : 6.0824604, "_source" : { "account_number" : 970, "balance" : 19648, "firstname" : "Forbes", "lastname" : "Wallace", "age" : 28, "gender" : "M", # M "address" : "990 Mill Road", # mill "employer" : "Pheast", "email" : "forbeswallace@pheast.com", "city" : "Lopezo", "state" : "AK" } }, { "_index" : "bank", "_type" : "account", "_id" : "136", "_score" : 6.0824604, "_source" : { "account_number" : 136, "balance" : 45801, "firstname" : "Winnie", "lastname" : "Holland", "age" : 38, "gender" : "M", # "address" : "198 Mill Lane", # "employer" : "Neteria", "email" : "winnieholland@neteria.com", "city" : "Urie", "state" : "IL" } }, { "_index" : "bank", "_type" : "account", "_id" : "345", "_score" : 6.0824604, "_source" : { "account_number" : 345, "balance" : 9812, "firstname" : "Parker", "lastname" : "Hines", "age" : 38, "gender" : "M", # "address" : "715 Mill Avenue", # "employer" : "Baluba", "email" : "parkerhines@baluba.com", "city" : "Blackgum", "state" : "KY" } } ] } }must_not:必须不是指定的情况
实例:查询gender=m,并且address=mill的数据,但是age不等于38的
should:应该达到should列举的条件,如果到达会增加相关文档的评分,并不会改变查询的结果。如果query中只有should且只有一种匹配规则,那么should的条件就会被作为默认匹配条件二区改变查询结果。
实例:匹配lastName应该等于Wallace的数据
GET bank/_search { "query": { "bool": { "must": [ { "match": { "gender": "M" } }, { "match": { "address": "mill" } } ], "must_not": [ { "match": { "age": "18" } } ], "should": [ { "match": { "lastname": "Wallace" } } ] } } }查询结果:
{ "took" : 5, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 3, "relation" : "eq" }, "max_score" : 12.585751, "hits" : [ { "_index" : "bank", "_type" : "account", "_id" : "970", "_score" : 12.585751, "_source" : { "account_number" : 970, "balance" : 19648, "firstname" : "Forbes", "lastname" : "Wallace", # 因为匹配了should,所以得分第一 "age" : 28, # 不是18 "gender" : "M", # "address" : "990 Mill Road", # "employer" : "Pheast", "email" : "forbeswallace@pheast.com", "city" : "Lopezo", "state" : "AK" } }, { "_index" : "bank", "_type" : "account", "_id" : "136", "_score" : 6.0824604, "_source" : { "account_number" : 136, "balance" : 45801, "firstname" : "Winnie", "lastname" : "Holland", "age" : 38, "gender" : "M", "address" : "198 Mill Lane", "employer" : "Neteria", "email" : "winnieholland@neteria.com", "city" : "Urie", "state" : "IL" } }, { "_index" : "bank", "_type" : "account", "_id" : "345", "_score" : 6.0824604, "_source" : { "account_number" : 345, "balance" : 9812, "firstname" : "Parker", "lastname" : "Hines", "age" : 38, "gender" : "M", "address" : "715 Mill Avenue", "employer" : "Baluba", "email" : "parkerhines@baluba.com", "city" : "Blackgum", "state" : "KY" } } ] } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号