10 期末大作业
未交原因:晚上加班学习java导致错过提交时间。
1.用图表描述Hadoop生态系统的各个组件及其关系。
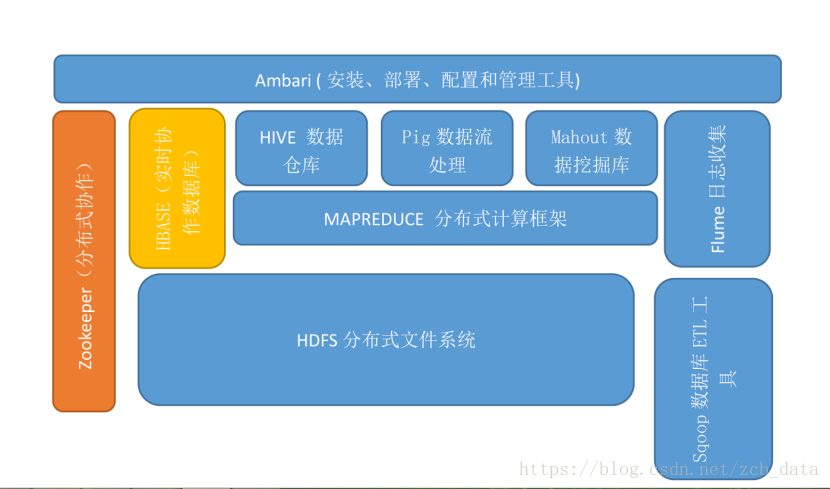
2.阐述Hadoop生态系统中,HDFS, MapReduce, Yarn, Hbase及Spark的相互关系。
HDFS(Hadoop分布式文件系统)
是Hadoop体系中 数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
Mapreduce(分布式计算框架)
MapReduce是一种 计算模型,用以进行大数据量的计算。其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。
Yarn
YARN(分布式资源管理器)是下一代MapReduce,即MRv2,是在第一代MapReduce基础上演变而来的,主要是为了解决原始Hadoop扩展性差,不支持多计算框架而提出的。YARN是下一代Hadoop计算平台,是一个通用的运行时框架,用户可以编写自己的极端框架,在该运行环境中运行。
Hbase(分布式列存数据库)
HBase是一个针对结构化数据的 可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。和传统关系数据库不同,HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
spark和spark2(大数据处理的计算引擎)
Spark是UC Berkeley AMP lab开发的一个集群计算的框架,类似于Hadoop,但有很多的区别。最大的优化是让计算任务的中间结果可以存储在内存中,不需要每次都写入HDFS,更适用于需要迭代的MapReduce算法场景中,可以获得更好的性能提升。例如一次排序测试中,对100TB数据进行排序,Spark比Hadoop快三倍,并且只需要十分之一的机器。Spark集群目前最大的可以达到8000节点,处理的数据达到PB级别,在互联网企业中应用非常广泛.
3.使用Linux的常用命令,教材P15。
系统信息
arch 显示机器的处理器架构
uname -m 显示机器的处理器架构
uname -r 显示正在使用的内核版本
dmidecode -q 显示硬件系统部件 - (SMBIOS / DMI)
hdparm -i /dev/hda 罗列一个磁盘的架构特性
hdparm -tT /dev/sda 在磁盘上执行测试性读取操作
cat /proc/cpuinfo 显示CPU info的信息
cat /proc/interrupts 显示中断
cat /proc/meminfo 校验内存使用
cat /proc/swaps 显示哪些swap被使用
cat /proc/version 显示内核的版本
cat /proc/net/dev 显示网络适配器及统计
cat /proc/mounts 显示已加载的文件系统
lspci -tv 罗列 PCI 设备
lsusb -tv 显示 USB 设备
date 显示系统日期
cal 2007 显示2007年的日历表
date 041217002007.00 设置日期和时间 - 月日时分年.秒
clock -w 将时间修改保存到 BIOS
关机 (系统的关机、重启以及登出 )
shutdown -h now 关闭系统
init 0 关闭系统
telinit 0 关闭系统
shutdown -h hours:minutes & 按预定时间关闭系统
shutdown -c 取消按预定时间关闭系统
shutdown -r now 重启
reboot 重启
logout 注销
文件和目录
cd /home 进入 '/ home' 目录'
cd .. 返回上一级目录
cd ../.. 返回上两级目录
cd 进入个人的主目录
cd ~user1 进入个人的主目录
cd - 返回上次所在的目录
pwd 显示工作路径
ls 查看目录中的文件
ls -F 查看目录中的文件
ls -l 显示文件和目录的详细资料
ls -a 显示隐藏文件
ls *[0-9]* 显示包含数字的文件名和目录名
tree 显示文件和目录由根目录开始的树形结构
lstree 显示文件和目录由根目录开始的树形结构
mkdir dir1 创建一个叫做 'dir1' 的目录'
mkdir dir1 dir2 同时创建两个目录
mkdir -p /tmp/dir1/dir2 创建一个目录树
rm -f file1 删除一个叫做 'file1' 的文件'
rmdir dir1 删除一个叫做 'dir1' 的目录'
rm -rf dir1 删除一个叫做 'dir1' 的目录并同时删除其内容
rm -rf dir1 dir2 同时删除两个目录及它们的内容
mv dir1 new_dir 重命名/移动 一个目录
cp file1 file2 复制一个文件
cp dir/* . 复制一个目录下的所有文件到当前工作目录
cp -a /tmp/dir1 . 复制一个目录到当前工作目录
cp -a dir1 dir2 复制一个目录
cp -r dir1 dir2 复制一个目录及子目录
ln -s file1 lnk1 创建一个指向文件或目录的软链接
ln file1 lnk1 创建一个指向文件或目录的物理链接
touch -t 0712250000 file1 修改一个文件或目录的时间戳 - (YYMMDDhhmm)
file file1 outputs the mime type of the file as text
iconv -l 列出已知的编码
iconv -f fromEncoding -t toEncoding inputFile > outputFile creates a new from the given input file by assuming it is encoded in fromEncoding and converting it to toEncoding.
find . -maxdepth 1 -name *.jpg -print -exec convert "{}" -resize 80x60 "thumbs/{}" \; batch resize files in the current directory and send them to a thumbnails directory (requires convert from Imagemagick)
文件搜索
find / -name file1 从 '/' 开始进入根文件系统搜索文件和目录
find / -user user1 搜索属于用户 'user1' 的文件和目录
find /home/user1 -name \*.bin 在目录 '/ home/user1' 中搜索带有'.bin' 结尾的文件
find /usr/bin -type f -atime +100 搜索在过去100天内未被使用过的执行文件
find /usr/bin -type f -mtime -10 搜索在10天内被创建或者修改过的文件
find / -name \*.rpm -exec chmod 755 '{}' \; 搜索以 '.rpm' 结尾的文件并定义其权限
find / -xdev -name \*.rpm 搜索以 '.rpm' 结尾的文件,忽略光驱、捷盘等可移动设备
locate \*.ps 寻找以 '.ps' 结尾的文件 - 先运行 'updatedb' 命令
whereis halt 显示一个二进制文件、源码或man的位置
which halt 显示一个二进制文件或可执行文件的完整路径
挂载一个文件系统
mount /dev/hda2 /mnt/hda2 挂载一个叫做hda2的盘 - 确定目录 '/ mnt/hda2' 已经存在
umount /dev/hda2 卸载一个叫做hda2的盘 - 先从挂载点 '/ mnt/hda2' 退出
fuser -km /mnt/hda2 当设备繁忙时强制卸载
umount -n /mnt/hda2 运行卸载操作而不写入 /etc/mtab 文件- 当文件为只读或当磁盘写满时非常有用
mount /dev/fd0 /mnt/floppy 挂载一个软盘
mount /dev/cdrom /mnt/cdrom 挂载一个cdrom或dvdrom
mount /dev/hdc /mnt/cdrecorder 挂载一个cdrw或dvdrom
mount /dev/hdb /mnt/cdrecorder 挂载一个cdrw或dvdrom
mount -o loop file.iso /mnt/cdrom 挂载一个文件或ISO镜像文件
mount -t vfat /dev/hda5 /mnt/hda5 挂载一个Windows FAT32文件系统
mount /dev/sda1 /mnt/usbdisk 挂载一个usb 捷盘或闪存设备
mount -t smbfs -o username=user,password=pass //WinClient/share /mnt/share 挂载一个windows网络共享
磁盘空间
df -h 显示已经挂载的分区列表
ls -lSr |more 以尺寸大小排列文件和目录
du -sh dir1 估算目录 'dir1' 已经使用的磁盘空间'
du -sk * | sort -rn 以容量大小为依据依次显示文件和目录的大小
rpm -q -a --qf '%10{SIZE}t%{NAME}n' | sort -k1,1n 以大小为依据依次显示已安装的rpm包所使用的空间 (fedora, redhat类系统)
dpkg-query -W -f='${Installed-Size;10}t${Package}n' | sort -k1,1n 以大小为依据显示已安装的deb包所使用的空间 (ubuntu, debian类系统)
用户和群组
groupadd group_name 创建一个新用户组
groupdel group_name 删除一个用户组
groupmod -n new_group_name old_group_name 重命名一个用户组
useradd -c "Name Surname " -g admin -d /home/user1 -s /bin/bash user1 创建一个属于 "admin" 用户组的用户
useradd user1 创建一个新用户
userdel -r user1 删除一个用户 ( '-r' 排除主目录)
usermod -c "User FTP" -g system -d /ftp/user1 -s /bin/nologin user1 修改用户属性
passwd 修改口令
passwd user1 修改一个用户的口令 (只允许root执行)
chage -E 2005-12-31 user1 设置用户口令的失效期限
pwck 检查 '/etc/passwd' 的文件格式和语法修正以及存在的用户
grpck 检查 '/etc/passwd' 的文件格式和语法修正以及存在的群组
newgrp group_name 登陆进一个新的群组以改变新创建文件的预设群组
文件的权限 - 使用 "+" 设置权限,使用 "-" 用于取消
ls -lh 显示权限
ls /tmp | pr -T5 -W$COLUMNS 将终端划分成5栏显示
chmod ugo+rwx directory1 设置目录的所有人(u)、群组(g)以及其他人(o)以读(r )、写(w)和执行(x)的权限
chmod go-rwx directory1 删除群组(g)与其他人(o)对目录的读写执行权限
chown user1 file1 改变一个文件的所有人属性
chown -R user1 directory1 改变一个目录的所有人属性并同时改变改目录下所有文件的属性
chgrp group1 file1 改变文件的群组
chown user1:group1 file1 改变一个文件的所有人和群组属性
find / -perm -u+s 罗列一个系统中所有使用了SUID控制的文件
chmod u+s /bin/file1 设置一个二进制文件的 SUID 位 - 运行该文件的用户也被赋予和所有者同样的权限
chmod u-s /bin/file1 禁用一个二进制文件的 SUID位
chmod g+s /home/public 设置一个目录的SGID 位 - 类似SUID ,不过这是针对目录的
chmod g-s /home/public 禁用一个目录的 SGID 位
chmod o+t /home/public 设置一个文件的 STIKY 位 - 只允许合法所有人删除文件
chmod o-t /home/public 禁用一个目录的 STIKY 位
文件的特殊属性 - 使用 "+" 设置权限,使用 "-" 用于取消
chattr +a file1 只允许以追加方式读写文件
chattr +c file1 允许这个文件能被内核自动压缩/解压
chattr +d file1 在进行文件系统备份时,dump程序将忽略这个文件
chattr +i file1 设置成不可变的文件,不能被删除、修改、重命名或者链接
chattr +s file1 允许一个文件被安全地删除
chattr +S file1 一旦应用程序对这个文件执行了写操作,使系统立刻把修改的结果写到磁盘
chattr +u file1 若文件被删除,系统会允许你在以后恢复这个被删除的文件
lsattr 显示特殊的属性
打包和压缩文件
bunzip2 file1.bz2 解压一个叫做 'file1.bz2'的文件
bzip2 file1 压缩一个叫做 'file1' 的文件
gunzip file1.gz 解压一个叫做 'file1.gz'的文件
gzip file1 压缩一个叫做 'file1'的文件
gzip -9 file1 最大程度压缩
rar a file1.rar test_file 创建一个叫做 'file1.rar' 的包
rar a file1.rar file1 file2 dir1 同时压缩 'file1', 'file2' 以及目录 'dir1'
rar x file1.rar 解压rar包
unrar x file1.rar 解压rar包
tar -cvf archive.tar file1 创建一个非压缩的 tarball
tar -cvf archive.tar file1 file2 dir1 创建一个包含了 'file1', 'file2' 以及 'dir1'的档案文件
tar -tf archive.tar 显示一个包中的内容
tar -xvf archive.tar 释放一个包
tar -xvf archive.tar -C /tmp 将压缩包释放到 /tmp目录下
tar -cvfj archive.tar.bz2 dir1 创建一个bzip2格式的压缩包
tar -jxvf archive.tar.bz2 解压一个bzip2格式的压缩包
tar -cvfz archive.tar.gz dir1 创建一个gzip格式的压缩包
tar -zxvf archive.tar.gz 解压一个gzip格式的压缩包
zip file1.zip file1 创建一个zip格式的压缩包
zip -r file1.zip file1 file2 dir1 将几个文件和目录同时压缩成一个zip格式的压缩包
unzip file1.zip 解压一个zip格式压缩包
RPM 包 - (Fedora, Redhat及类似系统)
rpm -ivh package.rpm 安装一个rpm包
rpm -ivh --nodeeps package.rpm 安装一个rpm包而忽略依赖关系警告
rpm -U package.rpm 更新一个rpm包但不改变其配置文件
rpm -F package.rpm 更新一个确定已经安装的rpm包
rpm -e package_name.rpm 删除一个rpm包
rpm -qa 显示系统中所有已经安装的rpm包
rpm -qa | grep httpd 显示所有名称中包含 "httpd" 字样的rpm包
rpm -qi package_name 获取一个已安装包的特殊信息
rpm -qg "System Environment/Daemons" 显示一个组件的rpm包
rpm -ql package_name 显示一个已经安装的rpm包提供的文件列表
rpm -qc package_name 显示一个已经安装的rpm包提供的配置文件列表
rpm -q package_name --whatrequires 显示与一个rpm包存在依赖关系的列表
rpm -q package_name --whatprovides 显示一个rpm包所占的体积
rpm -q package_name --scripts 显示在安装/删除期间所执行的脚本l
rpm -q package_name --changelog 显示一个rpm包的修改历史
rpm -qf /etc/httpd/conf/httpd.conf 确认所给的文件由哪个rpm包所提供
rpm -qp package.rpm -l 显示由一个尚未安装的rpm包提供的文件列表
rpm --import /media/cdrom/RPM-GPG-KEY 导入公钥数字证书
rpm --checksig package.rpm 确认一个rpm包的完整性
rpm -qa gpg-pubkey 确认已安装的所有rpm包的完整性
rpm -V package_name 检查文件尺寸、 许可、类型、所有者、群组、MD5检查以及最后修改时间
rpm -Va 检查系统中所有已安装的rpm包- 小心使用
rpm -Vp package.rpm 确认一个rpm包还未安装
rpm2cpio package.rpm | cpio --extract --make-directories *bin* 从一个rpm包运行可执行文件
rpm -ivh /usr/src/redhat/RPMS/`arch`/package.rpm 从一个rpm源码安装一个构建好的包
rpmbuild --rebuild package_name.src.rpm 从一个rpm源码构建一个 rpm 包
YUM 软件包升级器 - (Fedora, RedHat及类似系统)
yum install package_name 下载并安装一个rpm包
yum localinstall package_name.rpm 将安装一个rpm包,使用你自己的软件仓库为你解决所有依赖关系
yum update package_name.rpm 更新当前系统中所有安装的rpm包
yum update package_name 更新一个rpm包
yum remove package_name 删除一个rpm包
yum list 列出当前系统中安装的所有包
yum search package_name 在rpm仓库中搜寻软件包
yum clean packages 清理rpm缓存删除下载的包
yum clean headers 删除所有头文件
yum clean all 删除所有缓存的包和头文件
DEB 包 (Debian, Ubuntu 以及类似系统)
dpkg -i package.deb 安装/更新一个 deb 包
dpkg -r package_name 从系统删除一个 deb 包
dpkg -l 显示系统中所有已经安装的 deb 包
dpkg -l | grep httpd 显示所有名称中包含 "httpd" 字样的deb包
dpkg -s package_name 获得已经安装在系统中一个特殊包的信息
dpkg -L package_name 显示系统中已经安装的一个deb包所提供的文件列表
dpkg --contents package.deb 显示尚未安装的一个包所提供的文件列表
dpkg -S /bin/ping 确认所给的文件由哪个deb包提供
APT 软件工具 (Debian, Ubuntu 以及类似系统)
apt-get install package_name 安装/更新一个 deb 包
apt-cdrom install package_name 从光盘安装/更新一个 deb 包
apt-get update 升级列表中的软件包
apt-get upgrade 升级所有已安装的软件
apt-get remove package_name 从系统删除一个deb包
apt-get check 确认依赖的软件仓库正确
apt-get clean 从下载的软件包中清理缓存
apt-cache search searched-package 返回包含所要搜索字符串的软件包名称
查看文件内容
cat file1 从第一个字节开始正向查看文件的内容
tac file1 从最后一行开始反向查看一个文件的内容
more file1 查看一个长文件的内容
less file1 类似于 'more' 命令,但是它允许在文件中和正向操作一样的反向操作
head -2 file1 查看一个文件的前两行
tail -2 file1 查看一个文件的最后两行
tail -f /var/log/messages 实时查看被添加到一个文件中的内容
文本处理
cat file1 file2 ... | command <> file1_in.txt_or_file1_out.txt general syntax for text manipulation using PIPE, STDIN and STDOUT
cat file1 | command( sed, grep, awk, grep, etc...) > result.txt 合并一个文件的详细说明文本,并将简介写入一个新文件中
cat file1 | command( sed, grep, awk, grep, etc...) >> result.txt 合并一个文件的详细说明文本,并将简介写入一个已有的文件中
grep Aug /var/log/messages 在文件 '/var/log/messages'中查找关键词"Aug"
grep ^Aug /var/log/messages 在文件 '/var/log/messages'中查找以"Aug"开始的词汇
grep [0-9] /var/log/messages 选择 '/var/log/messages' 文件中所有包含数字的行
grep Aug -R /var/log/* 在目录 '/var/log' 及随后的目录中搜索字符串"Aug"
sed 's/stringa1/stringa2/g' example.txt 将example.txt文件中的 "string1" 替换成 "string2"
sed '/^$/d' example.txt 从example.txt文件中删除所有空白行
sed '/ *#/d; /^$/d' example.txt 从example.txt文件中删除所有注释和空白行
echo 'esempio' | tr '[:lower:]' '[:upper:]' 合并上下单元格内容
sed -e '1d' result.txt 从文件example.txt 中排除第一行
sed -n '/stringa1/p' 查看只包含词汇 "string1"的行
sed -e 's/ *$//' example.txt 删除每一行最后的空白字符
sed -e 's/stringa1//g' example.txt 从文档中只删除词汇 "string1" 并保留剩余全部
sed -n '1,5p;5q' example.txt 查看从第一行到第5行内容
sed -n '5p;5q' example.txt 查看第5行
sed -e 's/00*/0/g' example.txt 用单个零替换多个零
cat -n file1 标示文件的行数
cat example.txt | awk 'NR%2==1' 删除example.txt文件中的所有偶数行
echo a b c | awk '{print $1}' 查看一行第一栏
echo a b c | awk '{print $1,$3}' 查看一行的第一和第三栏
paste file1 file2 合并两个文件或两栏的内容
paste -d '+' file1 file2 合并两个文件或两栏的内容,中间用"+"区分
sort file1 file2 排序两个文件的内容
sort file1 file2 | uniq 取出两个文件的并集(重复的行只保留一份)
sort file1 file2 | uniq -u 删除交集,留下其他的行
sort file1 file2 | uniq -d 取出两个文件的交集(只留下同时存在于两个文件中的文件)
comm -1 file1 file2 比较两个文件的内容只删除 'file1' 所包含的内容
comm -2 file1 file2 比较两个文件的内容只删除 'file2' 所包含的内容
comm -3 file1 file2 比较两个文件的内容只删除两个文件共有的部分
字符设置和文件格式转换
dos2unix filedos.txt fileunix.txt 将一个文本文件的格式从MSDOS转换成UNIX
unix2dos fileunix.txt filedos.txt 将一个文本文件的格式从UNIX转换成MSDOS
recode ..HTML < page.txt > page.html 将一个文本文件转换成html
recode -l | more 显示所有允许的转换格式
文件系统分析
badblocks -v /dev/hda1 检查磁盘hda1上的坏磁块
fsck /dev/hda1 修复/检查hda1磁盘上linux文件系统的完整性
fsck.ext2 /dev/hda1 修复/检查hda1磁盘上ext2文件系统的完整性
e2fsck /dev/hda1 修复/检查hda1磁盘上ext2文件系统的完整性
e2fsck -j /dev/hda1 修复/检查hda1磁盘上ext3文件系统的完整性
fsck.ext3 /dev/hda1 修复/检查hda1磁盘上ext3文件系统的完整性
fsck.vfat /dev/hda1 修复/检查hda1磁盘上fat文件系统的完整性
fsck.msdos /dev/hda1 修复/检查hda1磁盘上dos文件系统的完整性
dosfsck /dev/hda1 修复/检查hda1磁盘上dos文件系统的完整性
初始化一个文件系统
mkfs /dev/hda1 在hda1分区创建一个文件系统
mke2fs /dev/hda1 在hda1分区创建一个linux ext2的文件系统
mke2fs -j /dev/hda1 在hda1分区创建一个linux ext3(日志型)的文件系统
mkfs -t vfat 32 -F /dev/hda1 创建一个 FAT32 文件系统
fdformat -n /dev/fd0 格式化一个软盘
mkswap /dev/hda3 创建一个swap文件系统
SWAP文件系统
mkswap /dev/hda3 创建一个swap文件系统
swapon /dev/hda3 启用一个新的swap文件系统
swapon /dev/hda2 /dev/hdb3 启用两个swap分区
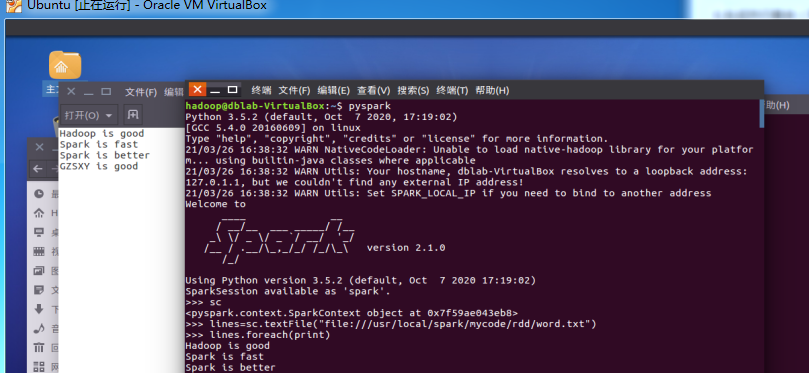
作业:03 Spark RDD编程基础
未交原因:忘记提交时间导致第二天发现已经错过提交时间。
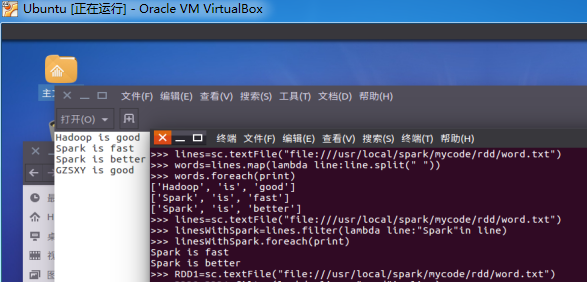
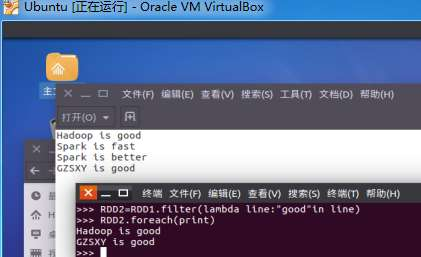
作业:04 RDD编程练习
未交原因:错过提交时间。
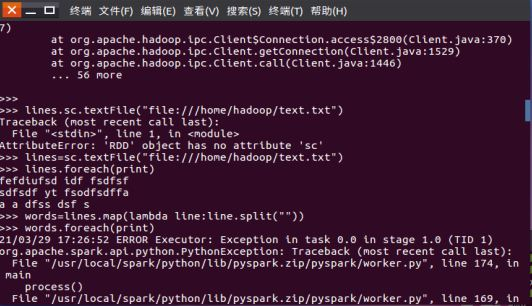
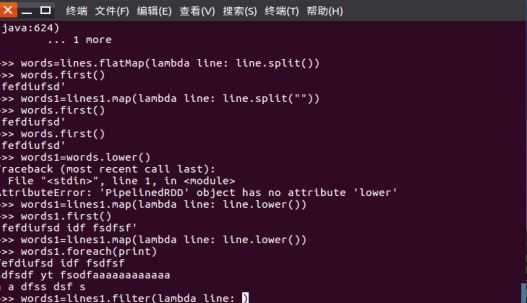
一、filter,map,flatmap练习:
1.读文本文件生成RDD lines
2.将一行一行的文本分割成单词 words
3.全部转换为小写
4.去掉长度小于3的单词
5.去掉停用词
6.练习一的生成单词键值对
作业:05 RDD练习:词频统计,学习课程分数
未交原因:错过提交时间。
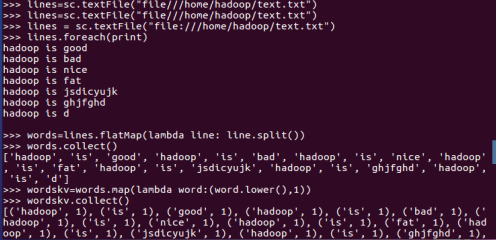
一、词频统计:
1.读文本文件生成RDD lines
2.将一行一行的文本分割成单词 words flatmap()
3.全部转换为小写 lower()
4.去掉长度小于3的单词 filter()
5.去掉停用词
6.转换成键值对 map()
7.统计词频 reduceByKey()
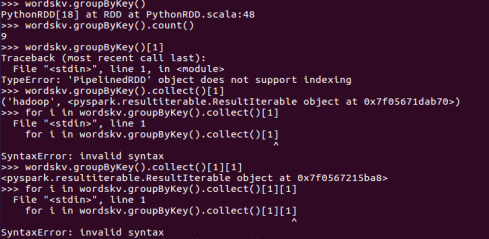
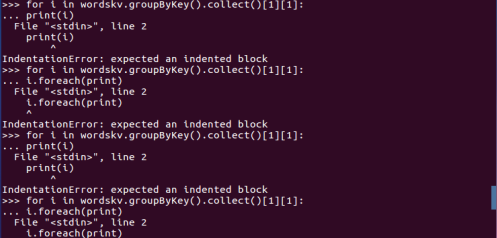
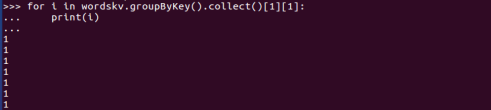
二、学生课程分数 groupByKey() -- 按课程汇总全总学生和分数
1. 分解出字段 map()
2. 生成键值对 map()
3. 按键分组 groupByKey()
4. 输出汇总结果 for i in <>
作业:06 RDD编程
未交原因:错过提交时间。
总共有多少学生?map(), distinct(), count()

开设了多少门课程?

每个学生选修了多少门课?map().countByValue() //map(), countByKey()
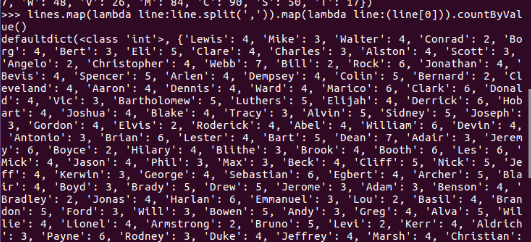
每门课程有多少个学生选?map(), countByValue()

Tom选修了几门课?每门课多少分?filter(), map() RDD

Tom选修了几门课?每门课多少分?map(),lookup() list

作业:07 Spark RDD编程 综合实例 英文词频统计
未交原因:错过提交时间。
1. 用Pyspark自主实现词频统计过程。
>>> s = txt.lower().split()
>>> dd = {}
>>> for word in s:
... if word not in dd:
... dd[word] = 1
... else:
... dd[word] = dic[word] + 1
...
>>> ss = sorted(dd.items(),key=operator.itemgetter(1),reverse=True)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'operator' is not defined
>>> import operator
>>> ss = sorted(dditems(),key=operator.itemgetter(1),reverse=True)
>>> print(ss)
[('the', 136), ('and', 111), ('of', 82), ('to', 71), ('our', 68), ('we', 59), ('that', 49), ('a', 46), ('is', 36), ('in', 26), ('this', 24), ('for', 23), ('are', 22), ('but', 20), ('--', 17), ('they', 17), ('on', 17), ('it', 17), ('will', 17), ('not', 16), ('have', 15), ('us', 14), ('has', 14), ('can', 13), ('with', 13), ('who', 13), ('be', 12), ('as', 11), ('or', 11), ('(applause.)', 11), ('those', 11), ('nation', 10), ('you', 10), ('their', 10), ('new', 9), ('these', 9), ('us,', 9), ('so', 8), ('by', 8), ('than', 8), ('must', 8), ('because', 8), ('what', 8), ('every', 8), ('all', 8), ('its', 8), ('been', 7), ('at', 7), ('when', 7), ('no', 6), ('less', 6), ('cannot', 6), ('let', 6), ('too', 6), ('common', 6), ('was', 5), ('time', 5), ('people', 5), ('only', 5), ('know', 5), ('nor', 5), ('now', 5), ('from', 5), ('seek', 4), ('work', 4), ('greater', 4), ('whether', 4), ('america', 4), ('more', 4), ('before', 4), ('power', 4), ('which', 4), ('long', 4), ('through', 4), ('men', 4), ('meet', 4), ('women', 4), ('journey', 3), ('up', 3), ('between', 3), ('were', 3), ('say', 3), ('where', 3), ('an', 3), ('god', 3), ('may', 3), ('last', 3), ('economy', 3), ('hard', 3), ('do', 3), ('today', 3), ('there', 3), ('founding', 3), ('hope', 3), ('crisis', 3), ('words', 3), ('carried', 3), ('them', 3), ('future', 3), ('come', 3), ('shall', 3), ('most', 3), ('generation', 3), ('day,', 3), ('you.', 3), ('things', 3), ('upon', 3), ('force', 3), ('i', 3), ('spirit', 3), ('just', 3), ('over', 3), ('father', 3), ('question', 3), ('your', 3), ('once', 3), ('across', 3), ('face', 2), ('better', 2), ('do,', 2), ('why', 2),
2. 并比较不同计算框架下编程的优缺点、适用的场景。
–Python
Python优缺点
优点
1、简单:Python是一种代表简单主义思想的语言。阅读一个良好的Python程序就感觉像是在读
英语一样,尽管这个英语的要求非常严格!Python的这种伪代码本质是它最大的优点之一。
它使你能够专注于解决问题而不是去搞明白语言本身。
2、易学:就如同你即将看到的一样,Python极其容易上手。前面已经提到了,Python有极其简
单的语法。
3、免费、开源:Python是FLOSS(自由/开放源码软件)之一。简单地说,你可以自由地发布这
个软件的拷贝、阅读它的源代码、对它做改动、把它的一部分用于新的自由软件中。FLOSS
是基于一个团体分享知识的概念。这是为什么Python如此优秀的原因之一——它是由一群希
望看到一个更加优秀的Python的人创造并经常改进着的。
4、高层语言:当你用Python语言编写程序的时候,你无需考虑诸如如何管理你的程序使用的内
存一类的底层细节。
5、可移植性:由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工作在
不同平台上)。如果你小心地避免使用依赖于系统的特性,那么你的所有Python程序无需修
改就可以在下述任何平台上面运行。这些平台包括Linux、Windows、FreeBSD、
Macintosh、Solaris、OS/2、Amiga、AROS、AS/400、BeOS、OS/390、z/OS、Palm
OS、QNX、VMS、Psion、Acom RISC OS、VxWorks、PlayStation、Sharp Zaurus、
Windows CE甚至还有PocketPC、Symbian以及Google基于linux开发的Android平台!
6、解释型语言:一个用编译型语言比如C或C++写的程序可以从源文件(即C或C++语言)转换
到一个你的计算机使用的语言(二进制代码,即0和1)。这个过程通过编译器和不同的标
记、选项完成。当你运行你的程序的时候,连接/转载器软件把你的程序从硬盘复制到内存中
并且运行。而Python语言写的程序不需要编译成二进制代码。你可以直接从源代码运行程
序。在计算机内部,Python解释器把源代码转换成称为字节码的中间形式,然后再把它翻译
成计算机使用的机器语言并运行。事实上,由于你不再需要担心如何编译程序,如何确保连接
转载正确的库等等,所有这一切使得使用Python更加简单。由于你只需要把你的Python程序
拷贝到另外一台计算机上,它就可以工作了,这也使得你的Python程序更加易于移植。
7、面向对象:Python既支持面向过程的编程也支持面向对象的编程。在“面向过程”的语言中,程
序是由过程或仅仅是可重用代码的函数构建起来的。在“面向对象”的语言中,程序是由数据和
功能组合而成的对象构建起来的。与其他主要的语言如C++和Java相比,Python以一种非常
强大又简单的方式实现面向对象编程。
8、可扩展性:如果你需要你的一段关键代码运行得更快或者希望某些算法不公开,你可以把你的
部分程序用C或C++编写,然后在你的Python程序中使用它们。
9、丰富的库:Python标准库确实很庞大。它可以帮助你处理各种工作,包括正则表达式、文档
生成、单元测试、线程、数据库、网页浏览器、CGI、FTP、电子邮件、XML、XML-RPC、
HTML、WAV文件、密码系统、GUI(图形用户界面)、Tk和其他与系统有关的操作。记住,
只要安装了Python,所有这些功能都是可用的。这被称作Python的“功能齐全”理念。除了标准
库以外,还有许多其他高质量的库,如wxPython、Twisted和Python图像库等等。
10、规范的代码:Python采用强制缩进的方式使得代码具有极佳的可读性。
缺点
Python语言非常完善,没有明显的短板和缺点,唯一的缺点就是执行效率慢,这个是解释型语言
所通有的,同时这个缺点也将被计算机越来越强大的性能所弥补。
Python应用场景
1、Web应用开发
Python经常被用于Web开发。比如,通过mod_wsgi模块,Apache可以运行用Python编写的
Web程序。Python定义了WSGI标准应用接口来协调Http服务器与基于Python的Web程序之间
的通信。一些Web框架,如Django,TurboGears,web2py,Zope等,可以让程序员轻松地开发
和管理复杂的Web程序。
2、操作系统管理、服务器运维的自动化脚本
在很多操作系统里,Python是标准的系统组件。 大多数Linux发行版以及NetBSD、OpenBSD
和Mac OS X都集成了Python,可以在终端下直接运行Python。有一些Linux发行版的安装器
使用Python语言编写,比如Ubuntu的Ubiquity安装器,Red Hat Linux和Fedora的Anacond
–MapReduce
优点:
1)MapReduce易于编程
如果要编写分布式程序,只需实现一些简单接口,与编写普通程序类似,避免了复杂过程。这个分布式程序可以分布到大量廉价的 PC 机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得 MapReduce 编程变得非常流行。
2)良好的扩展性
当计算资源不能得到满足的时候,可以通过简单的增加机器来扩展它的计算能力。
3)高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的 PC 机器上,廉价的 PC 机器坏的概率相对较高,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由 Hadoop 内部完成的。
4)适合PB级以上海量数据的离线处理
这里的“离线”可以理解为存在本地,非实时处理,离线计算往往需要一段时间,比如几分钟或几个小时。可以实现上干台服务器集群并发工作,提供数据处理能力。
缺点:
1)不擅长实时计算
MapReduce 不适合在毫秒或者秒级内返回结果。
2)不擅长流式计算
流式计算的输入数据是动态的,而 MapReduce 的输入数据集是静态的,不能动态变化。这是因为 MapReduce 自身的设计特点决定了数据源必须是静态的。
3)不擅长DAG(有向图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce 并不是不能做,而是使用后,每个 MapReduce 作业的输出结果都会写入到磁盘,会造成大量的磁盘 IO,导致性能非常的低下。
典型应用场景
1)单词统计
2)简单的数据统计,比如网站PV和UV统计
3)搜索引擎建立索引
4)搜索引擎中,统计最流行的K个搜索词
5)统计搜索词的频率,帮助优化搜索词提示
6)复杂数据分析算法实现
–Hive
优点:
(1)简单容易上手:提供了类SQL查询语言HQL
(2)可扩展:为超大数据集设计了计算/扩展能力(MR作为计算引擎,HDFS作为存储系统)
一般情况下不需要重启服务Hive可以自由的扩展集群的规模。
(3)提供统一的元数据管理
(4)延展性:Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
(5)容错:良好的容错性,节点出现问题SQL仍可完成执行
缺点:
(1)hive的HQL表达能力有限
1)迭代式算法无法表达,比如pagerank
2)数据挖掘方面,比如kmeans
(2)hive的效率比较低
1)hive自动生成的mapreduce作业,通常情况下不够智能化
2)hive调优比较困难,粒度较粗
3)hive可控性差
应用场景:
(1)数据仓库:数据抽取、数据加载、数据转换 (2)数据汇总:每天/每周用户点击数、流量统计 (3)非实时分析:日志分析、文本分析 (4)数据挖掘:用户行为分析、兴趣分区、区域展示
–Spark
spark的优势:(1)图计算,迭代计算(训练机器学习算法模型做广告推荐,点击预测,同时基于spark的预测模型能做到分钟级)(2)交互式查询计算(实时)
缺点:1.资源调度方面,Spark和Hadoop不同,执行时采用的是多线程模式,Hadoop是多进程,多线程模式会减少启动时间,但也带来了无法细粒度资源分配的问题。但本质上讲其实这也不能算是Spark的缺点,只不过是tradeoff之后的结果而已。2.其实Spark这种利用内存计算的思想的分布式系统你想要最大发挥其性能优势的话对集群资源配置要求较高,比如内存(当然内存不足也能用)
spark的主要应用场景:(1)推荐系统,实时推荐 (2)交互式实时查询
spark特点:(1)分布式并行计算框架(2)内存计算,不仅数据加载到内存,中间结果也存储内存(中间结果不需要落地到hdfs)
还有一个特点:Spark在做Shuffle时,在Groupby,Join等场景下去掉了不必要的Sort操作,相比于MapReduce只有Map和Reduce二种模式,Spark还提供了更加丰富全面的运算操作如filter,groupby,join等。
大作业:
1.选择使用什么数据,有哪些字段,多大数据量。
使用Q房网数据,字段较多,成千上万条数据。
2.准备分析哪些问题,可视化方式?(8个以上)
分析房价分布,户型分布等等,使用不同图进行可视化。
3.当前进展。
正在准备。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号