2024-2025-2 20244330《Python程序设计》综合实践报告(实验四)
2024-2025-2 20244330《Python程序设计》综合实践报告(实验四)
课程:《Python程序设计》
班级: 2443
姓名: 李馨逸
学号:20244330
实验教师:王志强老师
实验日期:2025年5月14日
必修/选修: 公选课
一、选题
因为本人是个二刺螈,平时里的一大的爱好就是看漫画。然而,我常用的几个漫画网站虽然阅读体验还不错,但却没有提供将漫画保存到本地的功能。每次想要把喜欢的章节留着以后慢慢回味或者离线观看,就只能手动一张张图片下载或者截图,不仅操作繁琐,还特别浪费时间。
于是,我想我为什么不自己动手写一个漫画自动下载器呢?这个工具可以根据漫画详情页的链接,智能地抓取整本漫画的内容,并按照章节或页面自动分类、下载和保存为本地文件。这样一来,不仅可以节省大量时间,还能让我的漫画收藏变得更加系统化和便捷化。
二、实验目的
- 实现自动识别漫画详情页中的章节链接
- 从每个章节页面中提取所有漫画图片链接
- 批量下载图片并按照章节分类保存至本地
- 生成整洁有序的文件夹结构,方便后续查阅
三、实验分析
首先,需要引入requests库用于发送 HTTP 请求,获取网页的 HTML 内容。同时使用BeautifulSoup库对获取到的 HTML 进行解析,从中提取出所需的图片链接。
在获取到所有图片链接后,程序将遍历这些链接,使用requests再次发起请求,下载每一张图片的二进制数据。下载完成后,将图片以适当的文件名保存到本地指定目录中,确保文件命名有序且不重复。
此外,在程序运行过程中,加入了若干提示语句用于输出当前状态信息,例如正在解析页面、正在下载图片、下载完成等,以便用户了解程序的执行进度和操作结果。
四、代码设计
首先(在同学的帮助下)观察了我需要的链接的形式以及网站的一些机制,发现
- 漫画详情页的链接形如:
https://cn.baozimhcn.com/comic/XXX-YYY - 漫画第 n 章的阅读页链接形如:
https://cn.baozimhcn.com/comic/chapter/XXX-YYY/0_n.html - 章节编号是从 0 开始依次递增的,且不分章节类型(包括正文、序章、插图等内容),统一按时间顺序排列
- 当访问的
n超过最大章节编号时,服务器会返回 302 重定向响应,并在Location字段中给出当前有效的最大章节地址 - 正常访问的网页不会出现
Location字段,因此可以通过判断是否包含该字段来确定章节是否存在
于是,就可以根据上面的发现来构造链接并进行访问了。
由于我们需要根据是否发生重定向来判断章节是否结束,因此单独封装了一个 req.py 文件用于处理所有的网络请求逻辑,将相关的异常处理和判断逻辑集中管理,提高代码的可维护性和复用性。
然后(在同学的帮助下)观察了阅读页的网页结构,发现
- 页面中主要包含两种图片标签:
<img>和<amp-img>,其中<amp-img>是实际显示漫画内容的标签 - 所有漫画图片的 URL 中都包含
scomic字符串,而广告或其他无关图片则不含该关键词 - 因此我们可以通过筛选
src属性中是否包含scomic来过滤出真正的漫画图片链接
通过这种方式,我们能较为准确地提取每章的所有图片链接,避免误下广告或其他无效资源。
于是就可以根据上面的发现来构造图片链接并下载了。
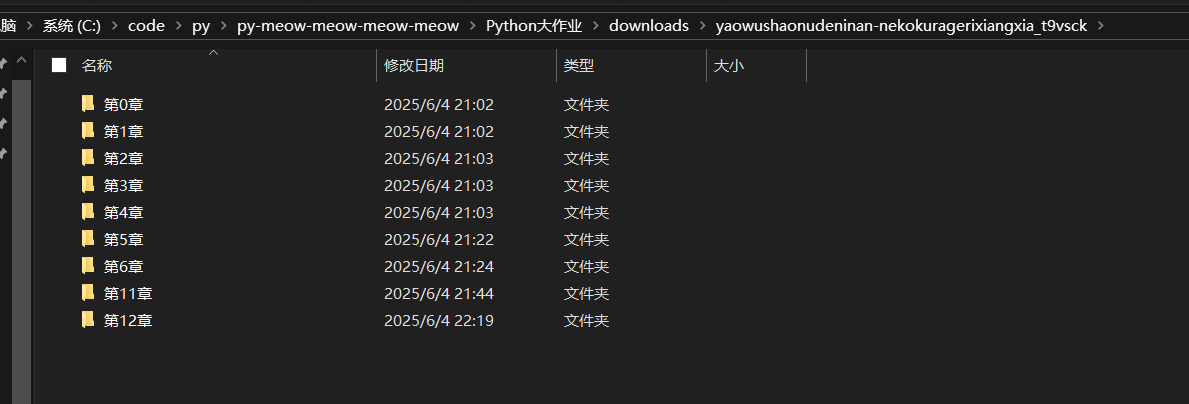
为了便于管理和后续查阅,程序在下载漫画时会按照如下结构创建本地目录:
- 以漫画名称命名的主文件夹
- 每个章节单独建立一个子文件夹,命名为“第X章”
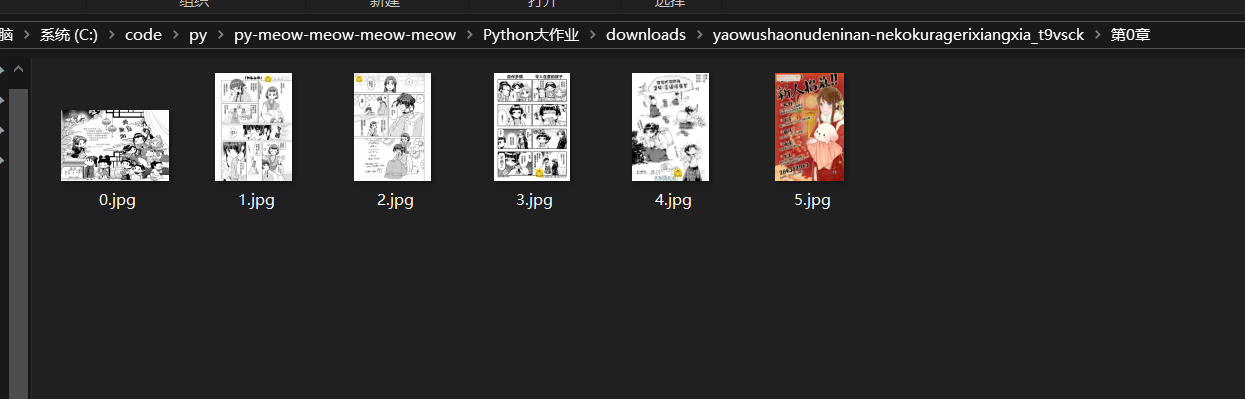
- 图片按顺序编号保存为
.jpg格式
这样组织后的文件结构清晰明了,用户可以直接打开对应章节查看漫画内容。
五、代码具体实现
首先是req.py
点击查看代码
import requests
class Req:
def __init__(self, url, method='get', headers=None, timeout=1000):
self.url = url
self.method = method
self.headers = headers
self.timeout = timeout
def send(self):
try:
response = requests.request(self.method, self.url, headers=self.headers, timeout=self.timeout, allow_redirects=False)
response.raise_for_status()
if response.headers.get("Location")!=None:
return ""
return response.content
except requests.RequestException as e:
print(f"Request failed: {e}")
return None
当访问的网页响应异常时会抛出错误,当网页被重定向时会返回空字符串,便于主程序进行判断。注意request函数的参数中设置了allow_redirects=false来禁止重定向,不然无法获取重定向前的网页headers。
然后是主程序
点击查看代码
import os
import req
from bs4 import BeautifulSoup
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Host": "cn.baozimhcn.com",
"Priority": "u=0, i",
"Sec-Ch-Ua": "\"Chromium\";v=\"136\", \"Microsoft Edge\";v=\"136\", \"Not.A/Brand\";v=\"99\"",
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": "\"Windows\"",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0"
}
引入了相关的库,设置了一个常量headers,因为requests默认的headers很容易就被识别为爬虫,所以换了一个更加真实的headers
点击查看代码
def main():
url = input("输入漫画详情页的网页链接(如:https://cn.baozimhcn.com/comic/XXX-YYY):")
url=url.split("/")
name=url[4]
url.insert(4,"chapter")#通过观察法找到网址规律
url = "/".join(url)
i=0
print(f"开始下载:{name}")
while True:
url_0=url+f"/0_{i}.html"
rq = req.Req(url_0,headers=headers)#访问阅读详情页
response = rq.send()
if response==None:
print(f"第{i}章未能获取响应。")
else:
if len(response) == 0:
print(f"下载完毕,共{i+1}章")
break
#print(len(response))
soup=BeautifulSoup(response, 'html.parser')
imgs = soup.find_all('amp-img')
for img,k in zip(imgs,range(len(imgs))):
if "scomic" in img['src']:
img_url = img['src']
print(f"正在下载第{i}章的第{k+1}张图片:{img_url}")
rq = req.Req(img_url, headers=headers)
response = rq.send()
if response != None:
if not os.path.exists(f"./downloads/{name}/第{i}章"):
os.makedirs(f"./downloads/{name}/第{i}章")
with open(f"./downloads/{name}/第{i}章/{k}.jpg", "wb") as f:
f.write(response)
print(f"第{i}章的第{k+1}张图片下载完成。")
else:
print(f"第{i}章的第{k+1}张图片下载失败。")
i += 1
按照前面分析的流程构造链接,访问网页,获取图片链接,下载图片,并且附加了一些提示语句
六.实验结果
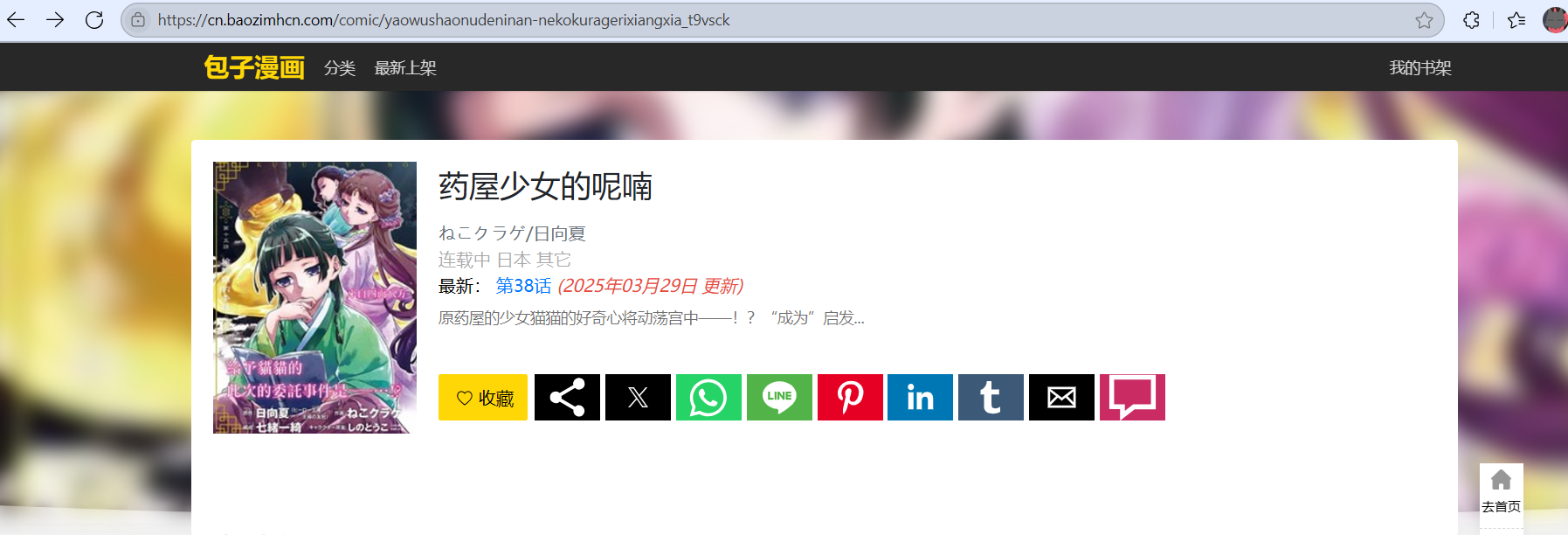
这是演示视频:https://www.bilibili.com/video/BV1WhTEz8Ere/?spm_id_from=333.1387.list.card_archive.click
https://gitee.com/w317714/py-meow-meow-meow-meow/blob/master/Python大作业/app.py
https://gitee.com/w317714/py-meow-meow-meow-meow/blob/master/Python大作业/req.py
七. 实验过程中遇到的问题和解决过程
-
问题1:不了解网页和链接相关的知识
-
问题1解决方案:求助于张锐,在帮助下完成了链接和网页结构的分析,漫画详情页的链接形如
https://cn.baozimhcn.com/comic/XXX-YYY,漫画第n章的阅读页的链接形如https://cn.baozimhcn.com/comic/chapter/XXX-YYY/0_n.html,漫画章节按时间顺序从0开始编号,并且不区分正文和其他内容(如序章、插曲、作者公告等) -
问题2:漫画详情页并没有写总共多少章,不知道怎么判断
-
问题2解决方案:求助于张锐,他发现了重定向和直接访问的关键差别,当访问的
https://cn.baozimhcn.com/comic/chapter/XXX-YYY/0_n.html中的n超过了最大章节编号,会被重定向到最大章节编号对应的章节,重定向的网页响应headers中有一个Location参数,而正常访问的网页没有。于是,就可以根据上面的发现来构造链接并进行访问了。 -
问题3:被网站的反爬识别了,爬取不到网页内容
-
问题3解决方案:求助于张锐,他告诉我requests的默认headers很容易就被识别为爬虫,于是他帮我写了一个接近浏览器的headers。
-
问题4:想做图形界面,加入阅读功能
-
问题4解决方案:询问张锐后发现自己好像在ddl之前学不会图形界面了,所以就算了。
课程总结
这个学期我有幸选修了王老师的 Python 课程,现在回想起来,这真是一段非常宝贵的学习经历。王老师不仅教学经验丰富,而且为人亲切、幽默风趣,在课堂上总能用生动的语言将知识点讲解得通俗易懂。即使是作为一门偏基础的通识课程,王老师的课依然让我收获满满,可以说是我整个大学期间所上过的公选课中最值得推荐的一门。
在课程中,我从零基础开始接触编程,逐步了解了 Python 的基本语法、函数使用以及简单的文件操作等内容。虽然课程定位是入门级,但内容安排合理、节奏适中,既照顾到了没有编程经验的同学,也让我这样的初学者能够稳步提升。更重要的是,王老师在教学过程中常常结合实际案例,让我们明白编程不仅仅是敲代码,更是解决问题的一种思维方式。
通过这门课,我不仅掌握了 Python 的基本使用方法,更重要的是建立了对编程的兴趣和信心。我相信这些知识和思维方式在未来学习其他编程语言时也会起到重要的启发作用。即使课程已经结束,我在课堂上学到的内容仍会在我今后的学习道路上持续发挥作用。
最后,我想真诚地感谢王老师的辛勤付出。这门课让我真正体会到了学习的乐趣和编程的魅力。如果以后还有机会,我一定会继续深入学习 Python;同时,我也会毫不犹豫地向学弟学妹们推荐这门课程,希望他们也能从中受益。再次感谢王老师的教导,谢谢!
最后的最后,
王老师的恩情还不完✋😭🤚
王老师的恩情还不完✋😭🤚
王老师的恩情还不完✋😭🤚
课程感想体会和建议
在选修这门《Python程序设计》之前,我对编程除了上学期学的c语言以外没有任何的基础,只是出于兴趣和对未来发展的考虑选择了这门课。一学期下来,虽然学习过程中有挑战,但整体收获颇丰,也让我对计算机编程有了更全面的认识。
刚开始接触Python的时候,面对代码总有一种棘手的感觉。不过王老师讲课节奏清晰,每节课的知识点都安排得恰到好处,不会让人感到压力过大。而且课堂上常常结合生活中的例子讲解概念,比如用“排队买饭”来类比队列结构,让我这样的初学者更容易理解抽象的逻辑关系。
除了知识点本身,我觉得最宝贵的是我开始学会如何“思考问题”。以前遇到任务时总是想着“怎么写代码”,现在会先思考“这个问题应该分几步解决”、“有没有更简洁的方法”。这种思维方式的转变,对我今后无论是在专业学习还是日常生活中解决问题,都有很大帮助。
另外值得一提的是,课程中布置的作业和练习大多贴近课堂内容,能够很好地检验学习效果,同时也不会让人觉得过于负担。每次完成一个小任务后都会有一定的成就感,这也激励我坚持学了下来。
当然,作为一门面向非计算机专业学生的公选课,我认为还有一些可以改进的地方:
-
适当介绍更多应用场景:比如简单讲讲 Python 在数据分析、自动化办公、人工智能等领域的应用,这样可以让同学们看到所学知识的实际价值,也能激发学习兴趣。
-
鼓励同学之间交流学习经验:有些问题可能老师讲完我们一时没完全理解,但如果能有一个小组讨论或者线上交流平台,大家可以互相帮助,学习效率也会更高。
总的来说,这次学习经历让我意识到编程并不是遥不可及的事情,只要愿意动手、不怕出错,每个人都能掌握基本技能。Python 是一门非常友好的入门语言,也很适合用来培养计算思维。我相信即使将来不从事相关行业,这段学习经历也会对我的逻辑能力和信息处理能力产生积极影响。
最后,感谢王老师的耐心指导和辛勤付出,也感谢课代表在课后答疑中的帮助。这门课不仅让我学会了Python更重要的是让我养成了主动思考的习惯。同时,我也会毫不犹豫地向学弟学妹们推荐这门课程,希望他们也能从中受益。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号