【模式识别和图像处理】StyleGAN,FCN,NeRF,PSPNET,LDMs网络结构图详解
一、AStyle-Based Generator Architecture for Generative Adversarial Networks(SytleGAN)
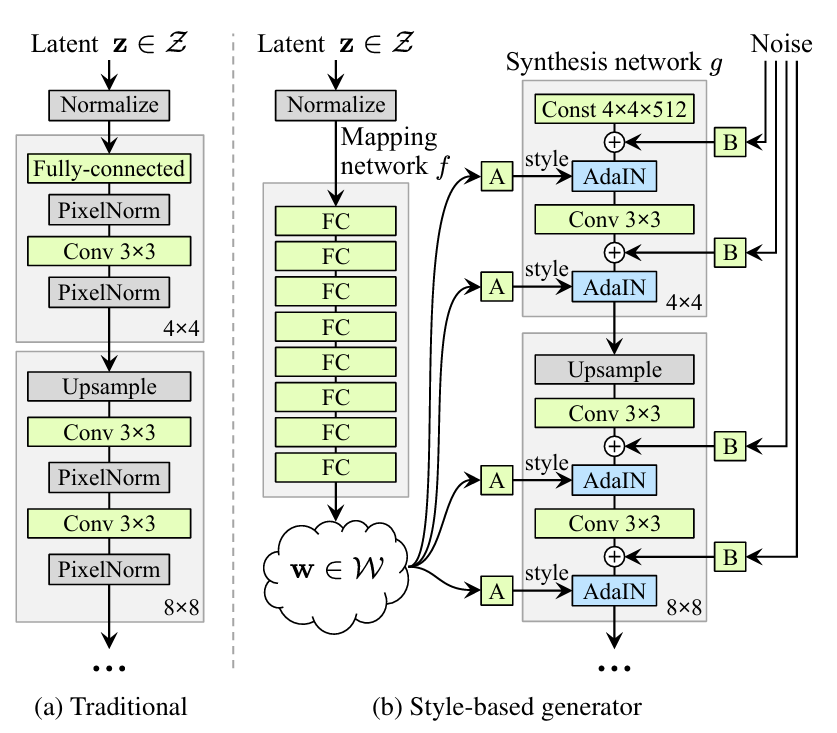
Generator部分主要分为了两个子网络:
Mapping network : Latent \(z\) 转换为 \(w\)
Synthesis network : 生成图像
StyleGAN中的style为控制人面目特征的主要属性,Mapping network生成的 \(w\) ,也便是用来影响图像style的变量。
1. Mapping network
由八个全连接层 ( fc ) 组成,输出向量 \(w\) 和 \(z\) 纬度相同。然后经过仿射变换生成A,分别送入Synthesis network的每一层网络,进行控制特征,用于控制不同的视觉特征。
由于 \(z\) 是符合均匀分布或者高斯分布的随机变量,所以变量之间的耦合性比较大,所以我们需要将Latent \(z\) 进行解耦,才能更好的后续操作,来改变其不同的特征。
2. Synthesis network
初始输入向量shape为 512 * 4 * 4,最后输出向量为 3 * 1024 * 1024,从 4 * 4 , 8 * 8 ,…, 512 * 512到 1024 * 1024 ,每一部分包含两个3 * 3大小的卷积层,其中一个用于上采样,一个用于特征学习,一共包含 18 层网络。
除了上述的 \(w\) 所分化的 A 作为style特征,同时用噪声(noise)作为B来影响发丝、肤色等细节和较小的特征,并且为了控制噪声仅对图片产生细微的变化,通过在自适应实例归一化,即 AdaIN (adaptive instance normalization)之前添加一个放缩过的噪声。
AdaIN:
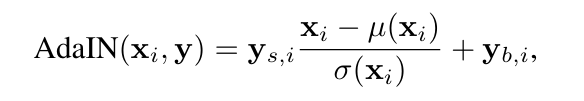
特征图的均值和方差中带有图像的风格信息。所以在这一层中,特征图减去自己的均值除以方差,去掉自己的风格。再乘上新风格的方差加上均值,以实现转换的目的。
二、Fully Convolutional Networks for Semantic Segmentation(FCN)
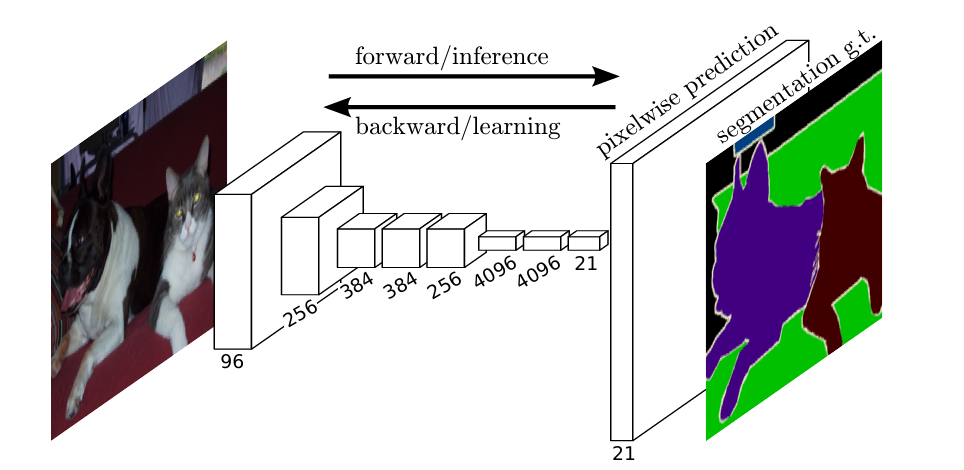
FCN是对图像进行像素级的分类(也就是每个像素点都进行分类),从而解决了语义级别的图像分割问题。
FCN网络结构主要分为两个部分:全卷积部分和反卷积部分。
其中全卷积部分为一些经典的CNN网络,用于提取特征
反卷积部分则是通过上采样得到原尺寸的语义分割图像。
FCN的输入可以为任意尺寸的彩色图像,输出与输入尺寸相同,通道数为n(目标类别数)+1(背景)。
上采样:在卷积过程的卷积操作和池化操作会使得特征图的尺寸变小,为得到原图像大小的稠密像素预测,需要对得到的特征图进行上采样操作。可通过双线性插值实现上采样,且双线性插值易于通过固定卷积核的转置卷积实现,转置卷积即为反卷积。
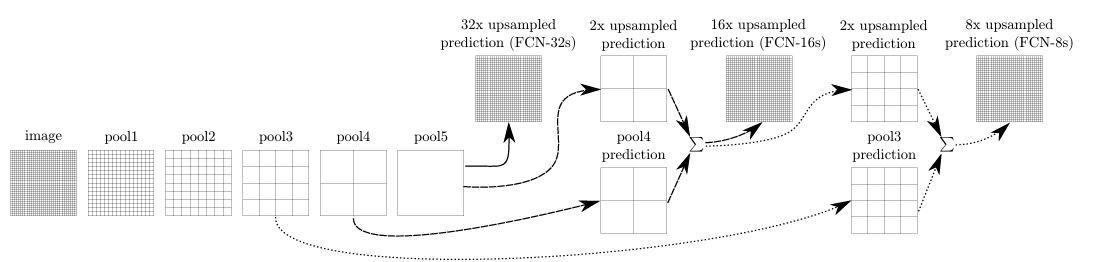
跳级结构:通过跳级结构将最后一层的预测(富有全局信息)和更浅层(富有局部信息)的预测结合起来,在遵守全局预测的同时进行局部预测。将底层(stride 32)的预测(FCN-32s)进行2倍的上采样得到原尺寸的图像,并与从pool4层(stride 16)进行的预测融合起来(相加),这一部分的网络被称为FCN-16s。随后将这一部分的预测再进行一次2倍的上采样并与从pool3层得到的预测融合起来,这一部分的网络被称为FCN-8s。
三、NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
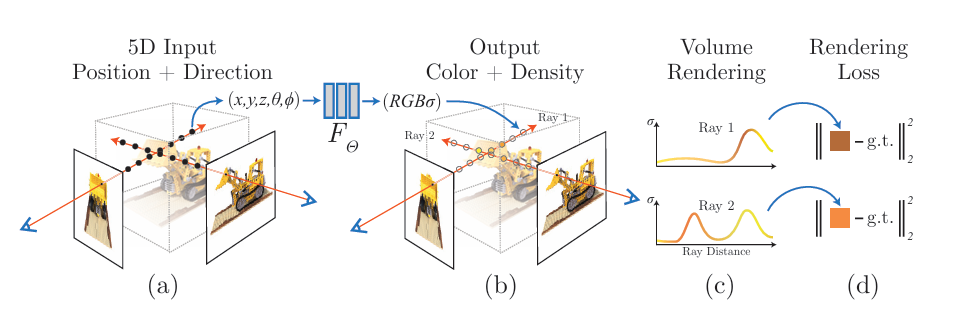
NeRF函数是将一个连续的场景表示为一个输入为5D向量的函数,包括一个空间点的3D坐标位置x=(x,y,z),以及方向d(θ,ϕ);
输出为视角相关的该3D点的颜色c=(r,g,b),和对应位置(体素)的密度σ。
x首先输入到MLP网络中,并输出 \(\sigma\) 和一个256维中间特征,再和d一起输入到额外的全连接层(128维)中预测颜色。
因此体密度只与空间位置x有关,而颜色则与各个参数都有关系。
Nerf引入了经典的体渲染理论来进行色彩与密度(也就是Nerf输出值)的建模:
连续形式:
离散形式:
反映了该模型在该光线的某处的粒子的密度,也就是一个具体的三维坐标上粒子的密度
颜色C(x)反应了该具体的三维坐标上,从光线的方向看去,粒子反射的颜色
光线累积量T(x)是一个随着光线的路径长度增加,而不断对体素密度积分的量,它的大小是随着光线达到的地方深度的增加而逐渐减小的,也就是说透明度在不断的下降,光线没有碰撞到任何粒子的概率在减小
位置输入编码:
难以学习到高频信息,使用位置信息编码,将输入先映射到高频可以有效地解决这个问题
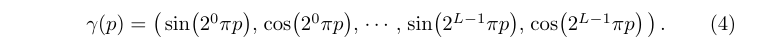
积分转成累加:
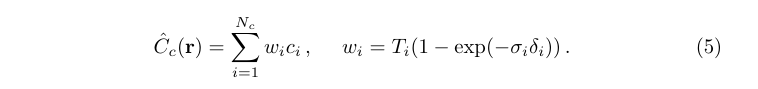
四、Pyramid Scene Parsing Network
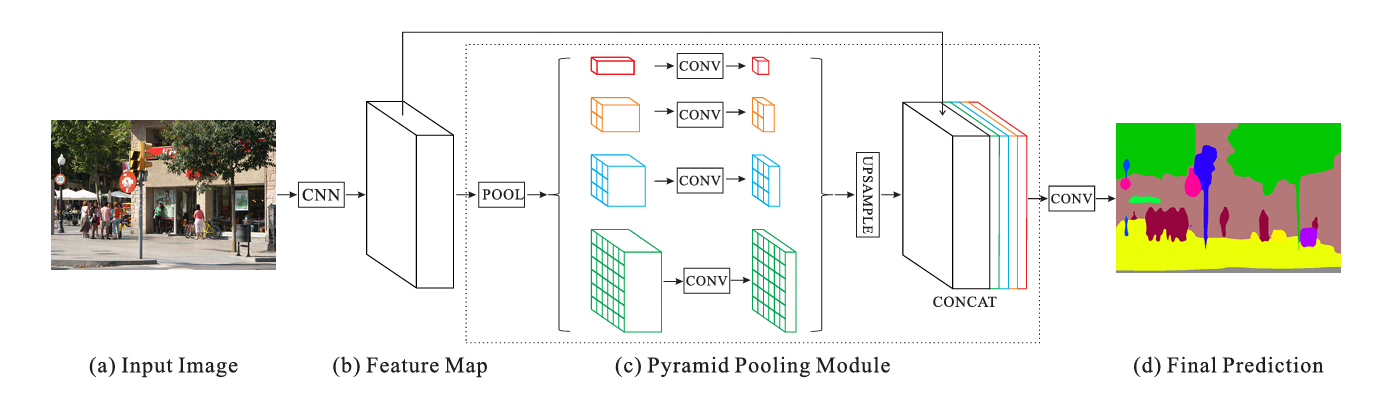
psp模块的样式如下,其psp的核心重点是采用了步长不同,pool_size不同的平均池化层进行池化,然后将池化的结果重新resize到一个hw上后,再concatenate。
金字塔池化(SPP): SPP 能生成的不同级别的特征图最终被展平并拼接起来,然后输入到全连接层中进行分类。该全局先验模块是为消除CNN进行图像分类时需输入固定尺寸图像的这一约束而设计的。为了进一步避免丢失表征不同子区域之间关系的语境信息,我们提出了一个包含不同尺度、不同子区域间关系的分层全局信息。如上图图中的(c)部分所示,将该金字塔池化模块的输出作为深度神经网络最终的特征图,并称其为全局场景先验信息。
红色:这是在每个特征map上执行全局平均池的最粗略层次,用于生成单个bin输出。
橙色:这是第二层,将特征map划分为2×2个子区域,然后对每个子区域进行平均池化。
蓝色:这是第三层,将特征 map划分为3×3个子区域,然后对每个子区域进行平均池化。
绿色:这是将特征map划分为6×6个子区域的最细层次,然后对每个子区域执行池化。
网络结构:
- 输入图像(a)
- 使用卷积神经网络CNN并从最后一个卷积层中得到特征map(b)
- 金字塔池化(c):对于特征map进行不同程度的平均池化得到1x1,2x2,3x3,6x6大小的区域,然后对结果各自送入卷积层得到结果并通过上采样和concate得到金字塔池化模型部分的最终输出
- 将3的结果送入一个卷积层后得到最终的逐像素场景预测。
五、High-Resolution Image Synthesis with Latent Diffusion Models
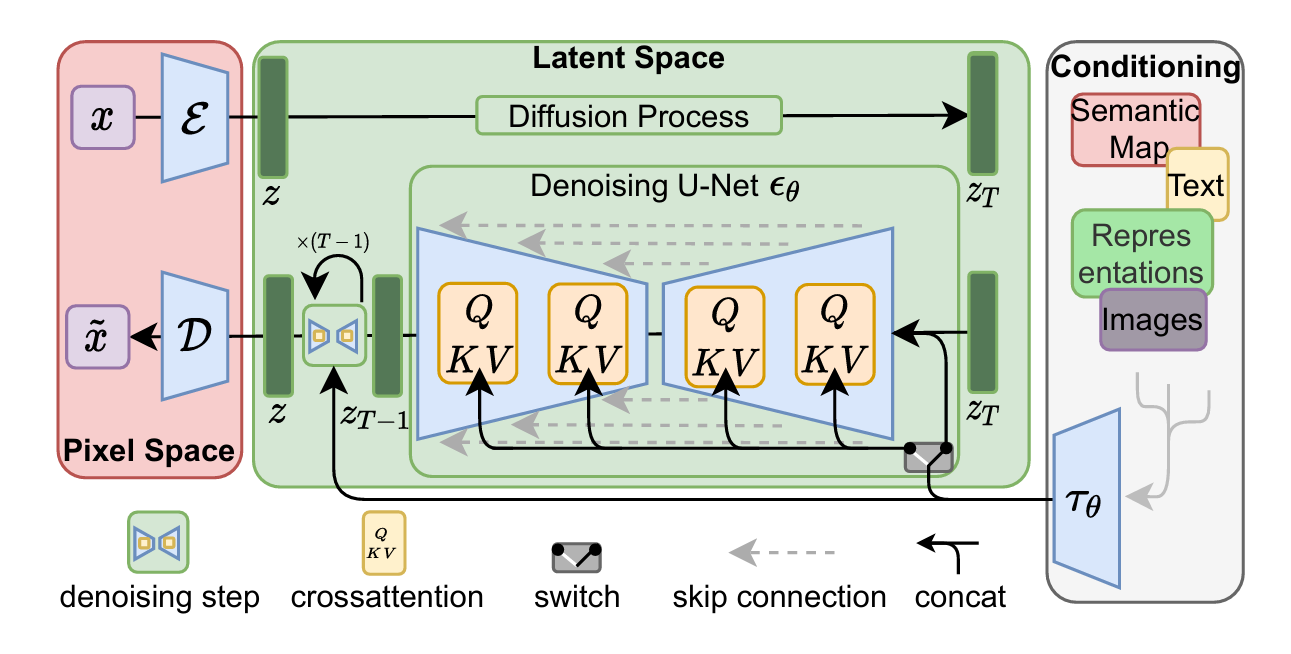
论文提出一种在潜在表示空间(latent space)上进行diffusion过程的方法,从而能够大大减少计算复杂度,同时也能达到十分不错的图片生成效果。
流程图的左侧表示输入数据RGB空间下\(x \in \mathbb{R}^{H \times W \times 3}\)。
\(\varepsilon\) 为编码器 encoder ,将 x 压缩成低维表示 \(z = \varepsilon (x)\)
\(\mathcal{D}\) 为解码器 将低维的 z 还原成原始像素空间
\(\varepsilon_\theta\) 为用于生成控制的条件去噪自编码器
\(QKV\) 为 注意力机制
扩散模型包括两个过程:前向过程(forward process)和反向过程(reverse process),
其中前向过程又称为扩散过程(diffusion process):对数据逐渐增加高斯噪音,直至数据变成随机噪音。
网络流程:
- 输入 x 经过 encoder \(\varepsilon\) 后 转化为 z
- z 经过扩散过程(前向过程)转变为 \(z_T\)
- \(z_T\) 与 控制条件 \(\tau_\theta\) concat 后经过多层Attention去噪得到 \(z_{T-1}\)
- 重复 T 轮 过程3 得到去噪训练后的 z
- z 通过 decoder \(\mathcal{D}\) 还原为原始像素空间 \(\widetilde{x}\)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号