
jmeter-参数化
jmeter-参数化
参数化的现实考虑:
- 被业务场景所迫
所有用户都输入相同的数据,不能提现出真实的业务环境- 被系统体系所迫
存在缓存,不能体现出真正的性能- 被系统业务约束所迫
有些系统禁止同一用户多次登陆系统,也就严重到无法测试的地步
Tips:同一个变量应保证只有一个变量值。
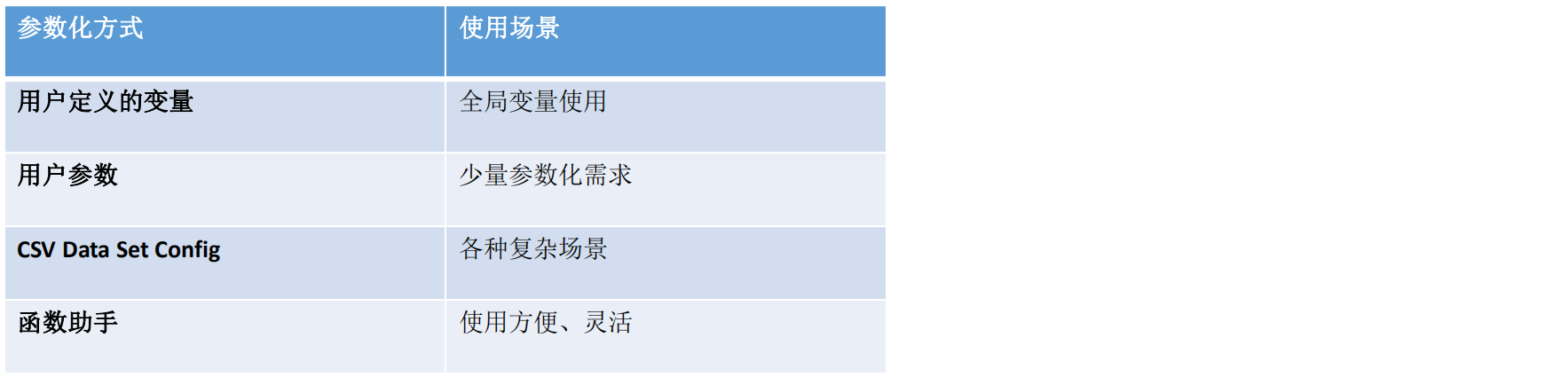
参数化1:User Defined Variables(用户定义的变量)
可见性:整个测试计划都是全局可见,与层级关系无关。
场景:
用户可根据需求自定义相应的变量,一般做全局变量使用
路径(2个路径,用法相同):
1. 线程组->配置元件->用户定义的变量
2. 测试计划

参数化2:User Parameters(用户参数)
可见性:整个线程组内全局可见,与层级没有关系
场景:
适合少量参数化需求场景使用
路径:
前置处理器 -->用户参数 User Parameters
特点:
一个线程组内,第一个线程取第一个,第二个线程取第二个(与线程循环无关)
举例:
设置3个线程,2个用户变量:则线程1取第一个变量,线程取第二个变量,线程3取第一的变量(线程数大于用户变量数)
2个线程组,每一个线程组的线程都会从第一个用户参数开始取(用户参数设置为测试计划级别)
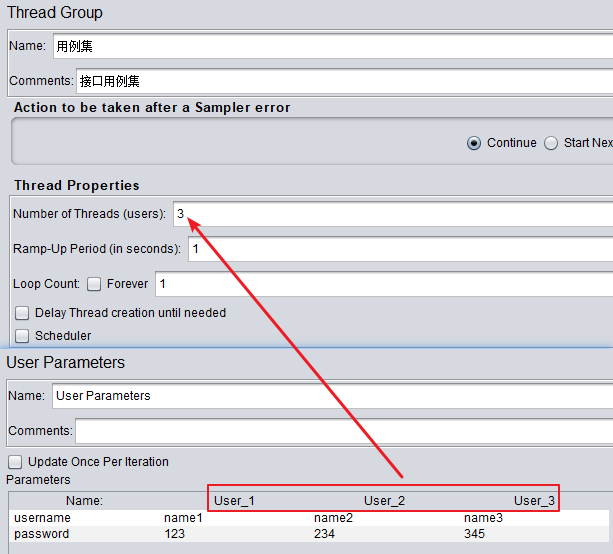
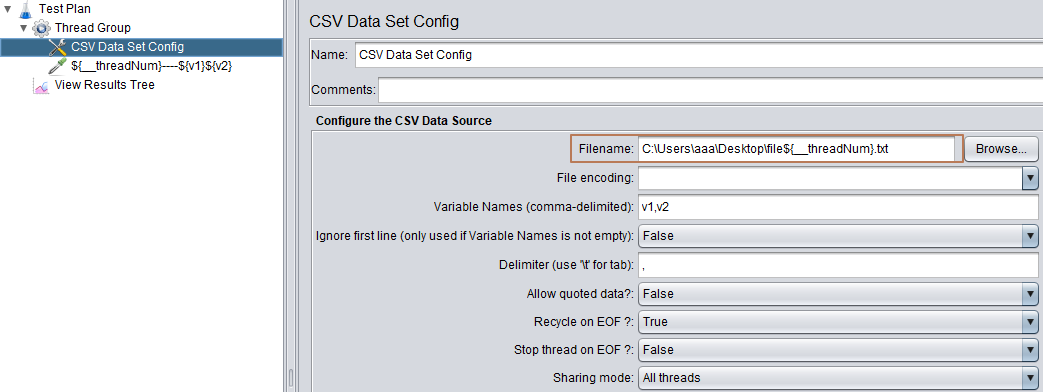
参数化3:CSV Data Set Config
可见性:整个线程组内全局可见,与层级没有关系
场景:
适用于各种复杂场景,用的最多
路径:
配置原件 -->CSV Data Set Config
Tips:
- csv文件格式:无BOM的UTF-8格式
- 注意:csv文件末尾最多1个空行。
- 默认使用当前操作系统的编码格式,如果文件中包含中文乱码时,可尝试utf-8、gbk等
解决1:修改文件格式属性为utf8
解决2:设置文件编码格式为gb2312- 如果csv参数包含逗号,那么一定要使用 \ 来转义,否则 JMeter 会把它当作一个参数分隔符
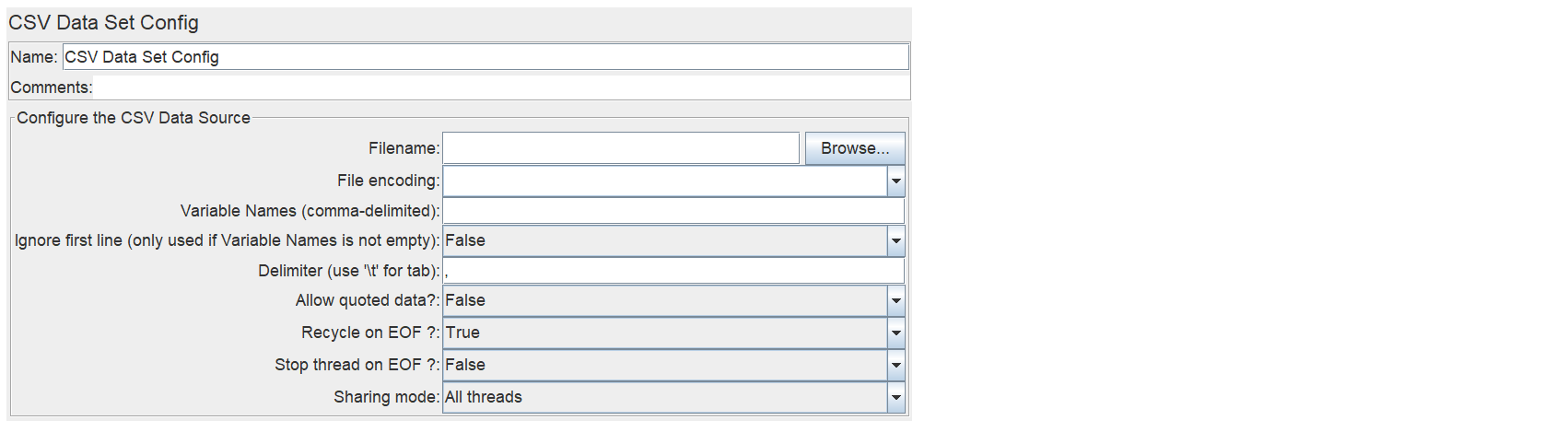
参数解释1:
Filename --> 文件的绝对路径/相对路径,jmeter默认先去bin目录下查找,然后去脚本目录下查找
File encoding --> 文件的编码(一般不用)
Variable Names --> 变量名,变量名(不填,则默认文件第一行为变量名,填写则应该设置忽略第一行)
Ignore first line --> 是否忽略第一行
Delimiter --> 不填,则默认逗号分隔
Allow quoted data --> 是否允许带引号,默认False。参数有用“”包裹,需设置为True
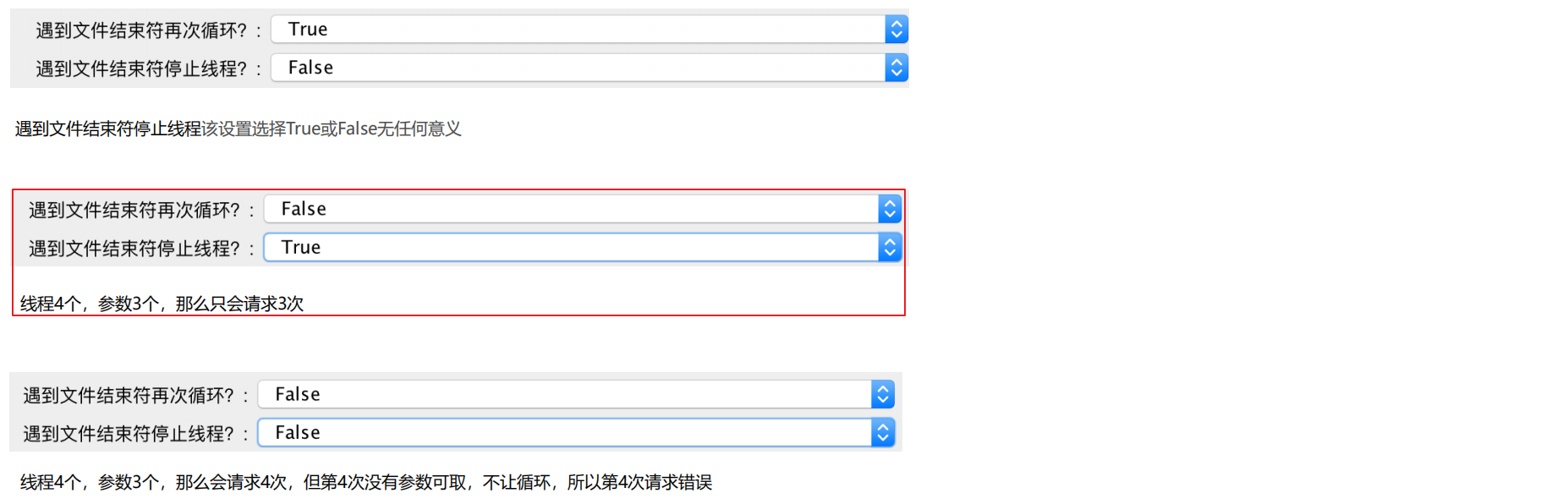
参数解释2:遇到文件结束符再次循环 与 遇到文件结束符停止线程?
Recycle on EOF --> 遇到文件结束符再次循环?(默认True)
Stop thread on EOF --> 遇到文件结束符停止线程?(默认False)
参数解释3:共享模式

以下线程数,循环次数指的是线程组中的属性
注:当CSV Data Set Config作用域设置为测试计划,则是针对全局的线程
按照csv文本内容顺序取
All threads :(默认)
1. 每一个线程取最新的数据
2. 每次循环取最新的数据
Current thread group :
1. 线程组为单位,线程组内的每个线程都是从第一行取数据(即:不同线程组都是从第一行开始取)
2. 每次循环取最新的数据
Current thread :
1. 每一个线程都是从第一行取数据
2. 每次循环取最新的数据
灵活应用小案例1
设置执行次数运行并查看结果
* 直接指定线程组的循环次数与CSV文件行数一致(灵活性差,了解即可)
* 动态的循环读取文件数据(更灵活)
1. 线程组的循环次数设置为永远
2. 修改CSV数据文件设置:遇结束符不循环,结束线程
灵活应用小案例2
不同线程读取不同csv文件的策略
参数化4:函数助手__CSVRead读取csv文件
特点:整个测试计划内,第一个线程取第一个,第二个线程取第二个(与线程设置的循环次数无关)
格式:${__CSVRead(a,b)}
a:文件路径;
b:csv文件的哪一列,索引0开始
例如:${__CSVRead(路径,1)} csv文件的第二列
小结
参数化 使用场景
- CSV Data Set Config:适用于参数取值范围较大的时候使用,该方法具有更大的灵活性
- User Parameters:适用于参数取值范围很小的时候使用
- User Defined Variables:一般用于Test Plan中不需要随请求迭代的参数设置,如:Host、Port Number
- 函数:可作为其他参数化方式的补充项,如:随机数生成的函数$

 浙公网安备 33010602011771号
浙公网安备 33010602011771号