操作系统原理与实现 ChCore Lab:机器启动
实验指导书:https://ipads.se.sjtu.edu.cn/courses/os/labs/lab1.pdf
LEC2 https://www.cnblogs.com/vv123/p/17234414.html
LEC3 https://www.cnblogs.com/vv123/p/17236997.html
1 基本知识
1.1 熟悉 AArch64 汇编
练习 1
浏览《ARM 指令集参考指南》的 A1、 A3 和 D 部分,以熟悉 ARM ISA。请做好阅读笔记,如果之前学习 x86-64 的汇编,请写下与 x86-64 相比的一些差异。
ARM与x86的区别:
- 指令条数少,长度固定(32bits),各种指令的使用频率和执行时间相近。x86与此相反。
- ARM只用LDR、STR指令操作内存,其它指令均是寄存器上的操作;而x86指令对访问内存不加限制。
- ARM有更多的通用寄存器。等等。
1.2 构建 ChCore 内核
1.3 QEMU 与 GDB
在实验中,由于需要在 x86-64 平台上使用 GDB 来调试 AArch64 代码,因此使用gdb-multiarch代替了普通的gdb。使用 GDB 调试的原理是,QEMU可以启动一个 GDB 远程目标(remote target(使用 ) -s或-S参数启动),QEMU会在真正执行镜像中的指令前等待 GDB 客户端的连接。开启远程目标之后,可以开启 GDB 进行调试,它会在某个端口上进行监听。我们提供了一个 GDB脚本.gdbinit来初始化 GDB,并且设置了其监听端口为 QEMU 的默认端口(tcp::1234)。
练习2
启动带调试的 QEMU,使用 GDB 的where命令来跟踪入口(第一个函数)及 bootloader 的地址。
首先进行一个GDB的快速入门 https://wangjunstf.github.io/2021/06/12/gdb-ru-men-jiao-cheng/
where命令和bt的作用是一样的,用于显示当前程序的函数调用堆栈,即当前执行点在哪个函数中,该函数被哪个函数调用,以此类推,直到到达 main 函数。它打印出堆栈中每个函数的函数名、参数和返回地址等信息。
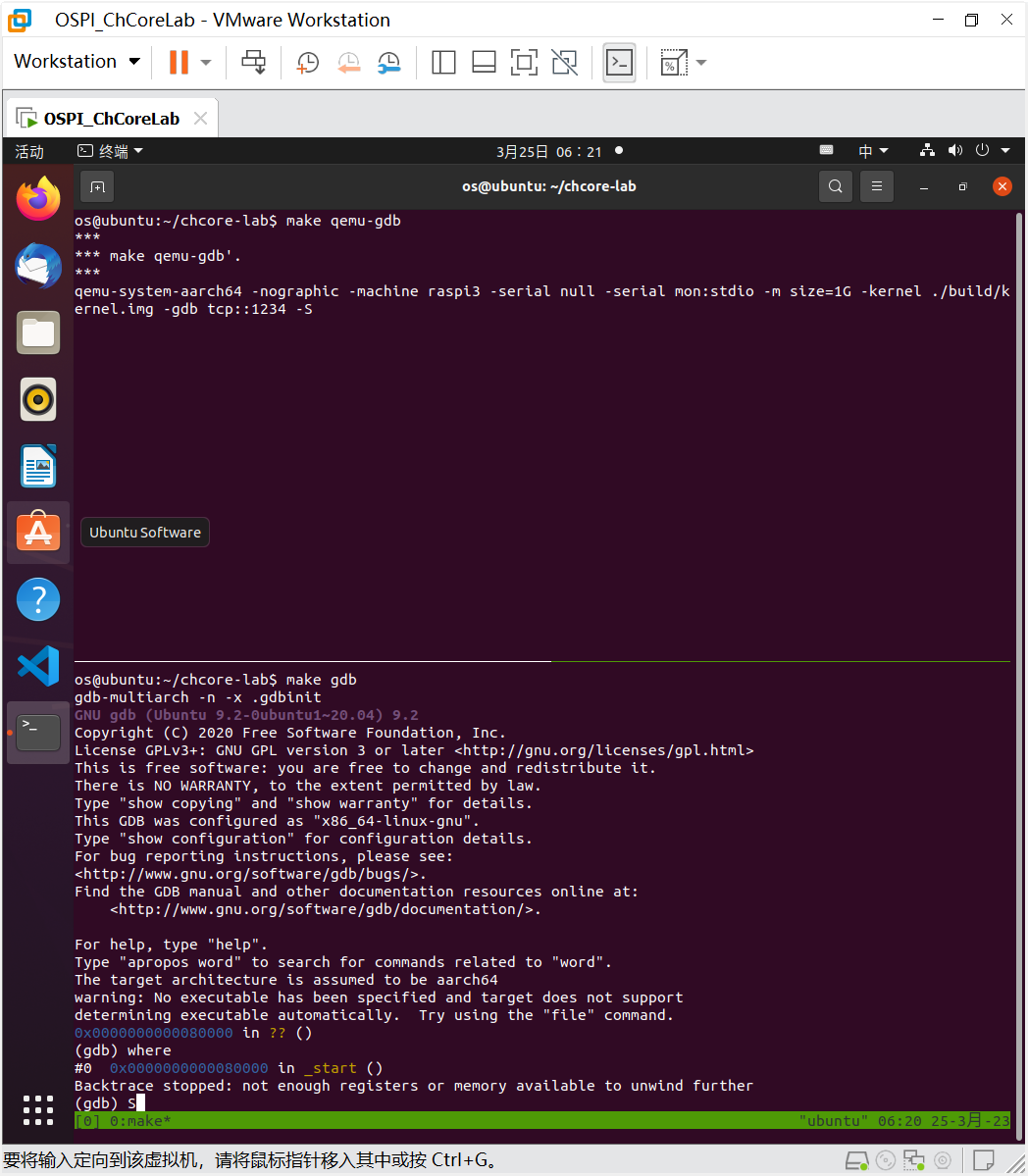
执行where可以发现入口函数是_start(),地址为0x0000000000080000
2 内核的引导与加载
2.1 编译与可执行文件
Raspi3 从闪存(SD 卡)中加载.img镜像中的 bootloader 并执行。 bootloader 包括两个功能:
- bootloader 通过函数arm64_elX_to_el1将处理器的异常级别从其他级别切换到 EL1。《ARM 指令集参考指南》的 A3.2 节简要描述了异常级别。
- bootloader 初始化引导 UART,页表和 MMU。然后, bootloader 跳转到实际的内核。在后续的实验中将会描述内存结构。
bootloader的源文件由一个汇编文件boot/start.S和一个C文件boot/init_c.c组成。
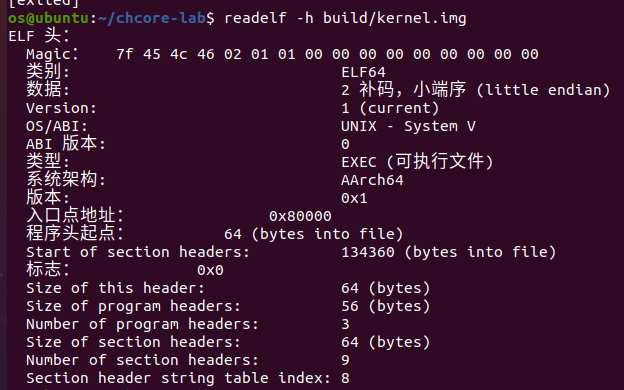
在编译并链接诸如 ChCore 内核的可执行文件时,编译器会将每个 C 文件(.c)和汇编文件(.S)编译成为目标文件(objective file)(.o)。它是用二进制格式编码的机器指令编写的,但是由于文件内的符号地址等信息未完全生成,因此不能直接被运行。然后,链接器将所有已编译的目标文件链接(即在文件中填充其他文件中符号的地址等)成一个可执行目标文件(executable objective file) ,例如build/kernel.img,这个文件中是硬件可以运行的二进制机器指令组成的。可执行目标文件的常见格式是可执行和可链接格式(Executable and Linkable Format, ELF) 二进制文件。ELF 可执行文件以 ELF 头部(ELF header) 开始,后跟几个程序段(program section)。 ELF 头部记录文件的结构,每个程序段都是一个连续的二进制块,(硬件或软件)加载器将它们作为代码或数据加载到指定地址的内存中并开始执行。
以build/kernel.img文件为例,可以通过以下命令看到完整的 ELF 头部信息:
通过以下命令,看到build/kernel.img包含的程序段:
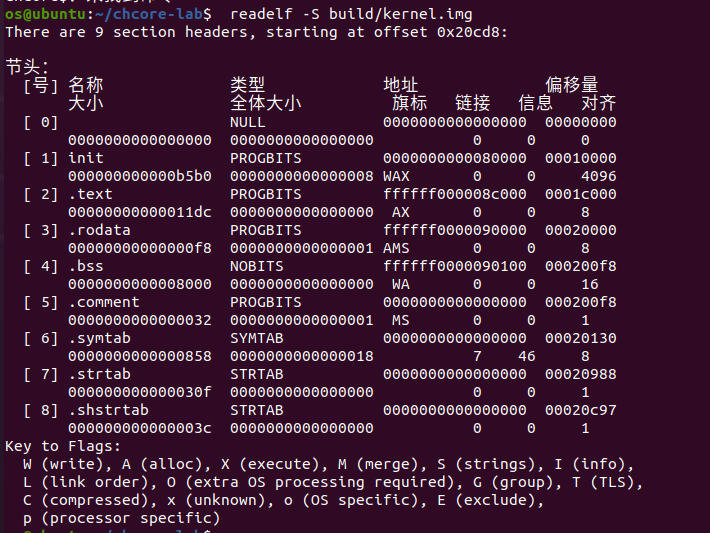
现在对一些主要的程序段进行一些解释:
- .init: 保存 bootloader 的代码和数据。这个特殊的段在CMakefiles.txt中定义。所有其余的程序段都是真正的 ChCore 内核。
- .text:保存内核程序代码,是由一条条的机器指令组成的。
- .data:保存初始化的全局变量或静态变量数据。定义在函数内部的局部非静态变量不在该段中存储。
- .rodata:保存只读数据,包括一些不可修改的常量数据,例如全局常量、 char *str = "apple"中的字符串常量等。然而,如果使用char str2[] = "apple",那么此时该字符串是动态地存在栈上的。
- .bss:记录未初始化的全局或静态变量,例如int a。由于在运行期间未初始化的全局变量被初始化为 0,因此链接器只记录地址和大小,而不是占用实际空间。
除上面列出的部分外,其他大多数段都包含调试信息,通常包含在可执行文件中,而不是加载到内存中。
练习 3
(1)结合readelf -S build/kernel.img读取符号表与练习2中的GDB调试信息,请找出请找出build/kernel.image入口定义在哪个文件中。
(2)继续借助单步调试追踪程序的执行过程,思考一个问题:目前本实验中支持的内核是单核版本的内核,然而在 Raspi3 上电后,所有处理器会同时启动。结合boot/start.S中的启动代码,并说明挂起其他处理器的控制流。
虚拟机自带了VSCode,我们打开chcore目录,大致浏览一下文件结构
练习2给出BootLoader的入口,以及build/kernel.img的elf头部给出.init的地址,均为0x0000000000080000
全局搜索80000,可以发现boot/image.h中定义的TEXT_OFFSET 值为0x80000。
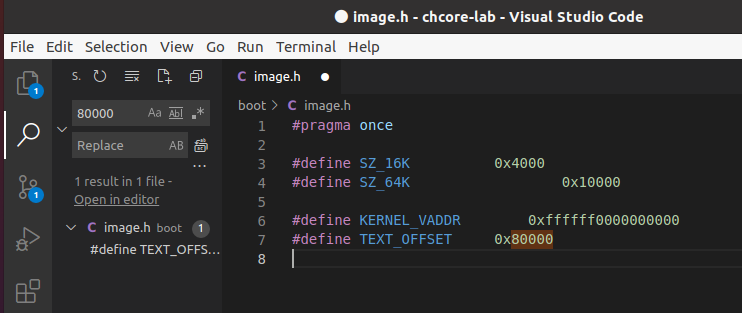
全局搜索TEXT_OFFSET,发现在scripts/linker-aarch64.lds.in中。
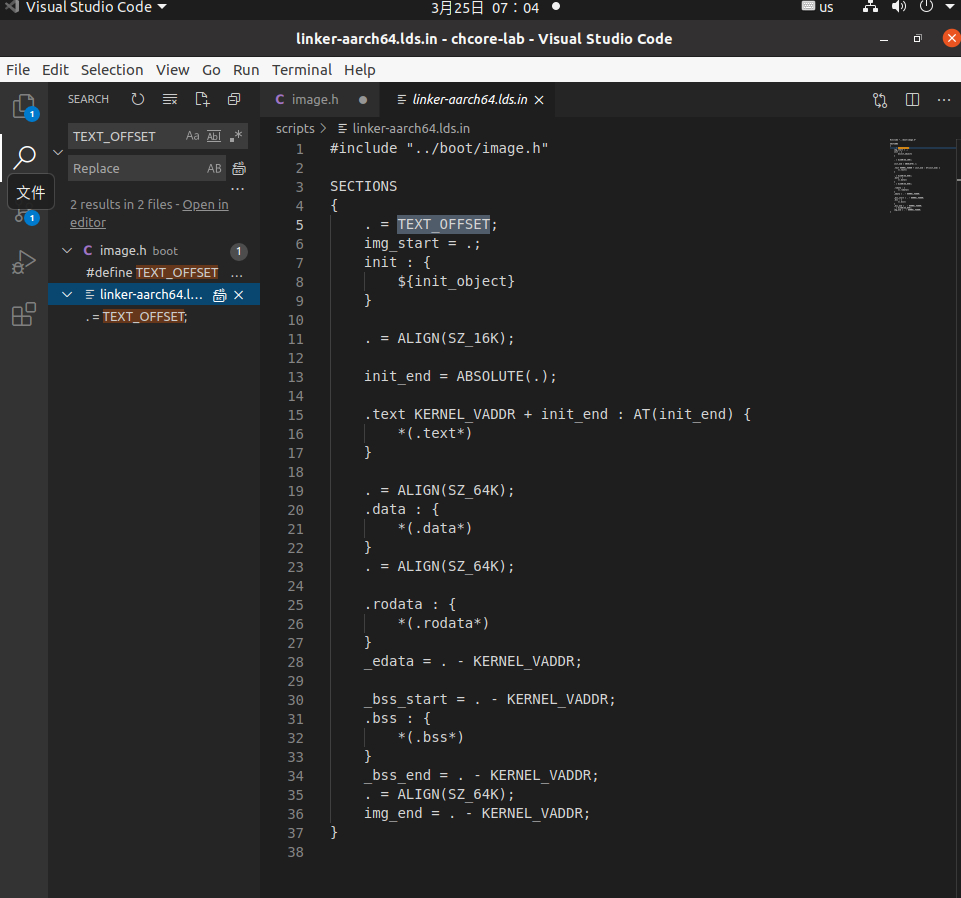
首先可以看到这两行
. = TEXT_OFFSET
img_start = .
按字面意思理解,image的启动地址在TEXT_OFFSET,这与我们得到的结论相符
${init_object}又是什么?我们继续搜索,发现在CMakeList.txt中
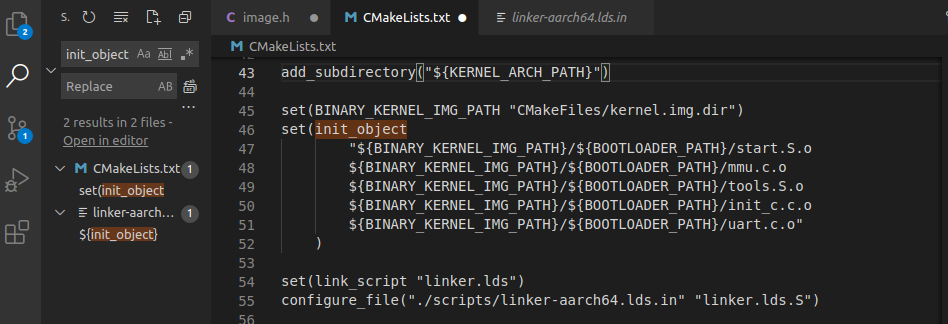
可见依次执行Start.s,mmu.c,tools.S,init_c.c,uart.c,这与https://www.cnblogs.com/vv123/p/17234414.html 中提到的操作系统启动过程相符。由此可以判断build/kernel.imag的入口定义在Start.S文件中。
好吧,第(2)问似乎已经给出了(1)的答案。。。
boot/Start.S的内容如下
#include <common/asm.h>
.extern arm64_elX_to_el1
.extern boot_cpu_stack
.extern secondary_boot_flag
.extern clear_bss_flag
.extern init_c
BEGIN_FUNC(_start)
mrs x8, mpidr_el1
and x8, x8, #0xFF
cbz x8, primary
/* hang all secondary processors before we intorduce multi-processors */
secondary_hang:
bl secondary_hang
primary:
/* Turn to el1 from other exception levels. */
bl arm64_elX_to_el1
/* Prepare stack pointer and jump to C. */
adr x0, boot_cpu_stack
add x0, x0, #0x1000
mov sp, x0
bl init_c
/* Should never be here */
b .
END_FUNC(_start)
分析这段汇编程序,含义是将mpidr_el1的值传送给x8,然后保留x8的低8位,如果x8的低8位为零则执行后面的primary段。否则"hang all secondary processors before we intorduce multi-processors"
由此可见,chcore是通过判断mpidr_el1低8位是否为0来判断当前启动的是主CPU还是应该挂起的其他CPU。
2.2 内核的加载与执行
ELF 文件的加载(load) 与执行(execute) 是启动一个程序的两个重要的步骤:
- 加载是指将程序的 ELF 文件按照链接规则从存储器(如 ROM)上按照每个段的加载内存地址(Load Memory Address, LMA) 拷贝到内存上指定的地址
- 执行需要将 ELF 文件中的段“放到”(可通过拷贝或页表映射等方式) 虚拟内存地址(Virtual Memory Address, VMA),然后开始真正执行ELF文件中的代码。
大多数情况下,一个段 LMA 和 VMA 是相同的。
通过objdump也可以查看 ELF 文件中每一个段的 LMA 和 VMA:
chcore$ objdump -h build/kernel.img
练习 4
查看build/kernel.img的objdump信息。比较每一个段中的 VMA 和 LMA 是否相同,为什么?在 VMA 和 LMA 不同的情况下,内核是如何将该段的地址从 LMA 变为 VMA?
提示:从每一个段的加载和运行情况进行分析
objdump的执行结果如下
os@ubuntu:~/chcore-lab$ objdump -h build/kernel.img
build/kernel.img: 文件格式 elf64-little
节:
Idx Name Size VMA LMA File off Algn
0 init 0000b5b0 0000000000080000 0000000000080000 00010000 2**12
CONTENTS, ALLOC, LOAD, CODE
1 .text 000011dc ffffff000008c000 000000000008c000 0001c000 2**3
CONTENTS, ALLOC, LOAD, READONLY, CODE
2 .rodata 000000f8 ffffff0000090000 0000000000090000 00020000 2**3
CONTENTS, ALLOC, LOAD, READONLY, DATA
3 .bss 00008000 ffffff0000090100 0000000000090100 000200f8 2**4
ALLOC
4 .comment 00000032 0000000000000000 0000000000000000 000200f8 2**0
CONTENTS, READONLY
可以发现只有init和.comment的VMA和LMA相同,.text,.rodata,.bss的VMA都比LMA多了ffffff0000000000。
全局搜索ffffff0000000000,发现它在熟悉的boot/image.h中,被定义为 KERNEL_VADDR
#pragma once
#define SZ_16K 0x4000
#define SZ_64K 0x10000
#define KERNEL_VADDR 0xffffff0000000000
#define TEXT_OFFSET 0x80000
再次搜索KERNEL_VADDR,回到了熟悉的链接脚本文件scripts/linker-aarch64.lds.in
#include "../boot/image.h"
SECTIONS
{
. = TEXT_OFFSET;
img_start = .;
init : {
${init_object}
}
. = ALIGN(SZ_16K);
init_end = ABSOLUTE(.);
.text KERNEL_VADDR + init_end : AT(init_end) {
*(.text*)
}
. = ALIGN(SZ_64K);
.data : {
*(.data*)
}
. = ALIGN(SZ_64K);
.rodata : {
*(.rodata*)
}
_edata = . - KERNEL_VADDR;
_bss_start = . - KERNEL_VADDR;
.bss : {
*(.bss*)
}
_bss_end = . - KERNEL_VADDR;
. = ALIGN(SZ_64K);
img_end = . - KERNEL_VADDR;
}
为了看懂这个文件,还需要学习一下链接脚本的相关知识: https://www.cnblogs.com/jianhua1992/p/16852784.html
可见init并没有指定VMA,而.text,.rodata,.bss使用页表映射的方式指定了VMA?
究其原因,大概init作为开机执行的固定段,只需要在物理地址中执行,不需要虚拟内存?
学完虚拟内存相关知识后再回来看看。
3 内核态基础功能
3.1 内核态输入输出
为了支持在引导阶段和内核执行过程中的调试等功能,需要支持标准输入输出。在 ChCore 中,内核态标准输出函数printk定义在kernel/common/printk.c中。其功能,和常用的 libc 中的格式化标准输出printf()功能类似,不同的是,printf()是用户态可以调用的系统调用,其实现是需要调用的是内核态的格式化输出,而现在需要实现的正是内核态的格式化输出。
练习 5
以不同的进制打印数字的功能(例如 8、10、16)尚未实现,请在kernel/common/printk.c中填充printk_write_num以完善printk的功能。正确完成此练习后,输入make grade可通过print hex和print oct两个测试。
要完成printk_write_num,还需要对前面的simple_outputchar和prints稍作分析,见中文注释
static void simple_outputchar(char **str, char c)
{
if (str) {
**str = c;
++(*str);
} else {
uart_send(c);
}
}
enum flags {
PAD_ZERO = 1,
PAD_RIGHT = 2
};
static int prints(char **out, const char *string, int width, int flags)
{
int pc = 0, padchar = ' ';//补全字符
if (width > 0) {
int len = 0;
const char *ptr;
for (ptr = string; *ptr; ++ptr)//计算string长度
++len;
if (len >= width)
width = 0;
else
width -= len; //得到剩余需要补全的长度
if (flags & PAD_ZERO)
padchar = '0';
}
if (!(flags & PAD_RIGHT)) {//PAD_RIGHT是指在原数的右边补空格(即左对齐)
for (; width > 0; --width) {
simple_outputchar(out, padchar);
++pc;
}
}
for (; *string; ++string) {
simple_outputchar(out, *string);
++pc;
}
for (; width > 0; --width) {//PAD_ZERO是指在原数的左边补0
simple_outputchar(out, padchar);
++pc;
}
return pc;
}
// this function print number `i` in the base of `base` (base > 1)
// `sign` is the flag of print signed number or unsigned number
// `width` and `flags` mean the length of printed number at least `width`,
// if the length of number is less than `width`, choose PAD_ZERO or PAD_RIGHT
// `letbase` means uppercase('A') or lowercase('a') when using hex
// you may need to call `prints`
// you do not need to print prefix like "0x", "0"...
// Remember the most significant digit is printed first.
static int printk_write_num(char **out, long long i, int base, int sign,
int width, int flags, int letbase)
{
char print_buf[PRINT_BUF_LEN];
char *s;
int t, neg = 0, pc = 0;
unsigned long long u = i;
if (i == 0) {
print_buf[0] = '0';
print_buf[1] = '\0';
return prints(out, print_buf, width, flags);
}
if (sign && base == 10 && i < 0) {
neg = 1;
u = -i;
}
// TODO: fill your code here
// store the digitals in the buffer `print_buf`:
// 1. the last postion of this buffer must be '\0'
// 2. the format is only decided by `base` and `letbase` here
//从后边的代码来看,是从s开始输出到'\0'
//s应当从print_buf的末尾开始,不断向前拓展
s = print_buf + PRINT_BUF_LEN - 1;
*s = '\0';
//简单的进制转换
while (u > 0) {
char tmp = u % base;
if (tmp <= 9) tmp = tmp + '0';
else tmp = tmp - 10 + (letbase ? 'a' : 'A');
*(--s) = tmp;
u /= base;
}
if (neg) {
if (width && (flags & PAD_ZERO)) {
simple_outputchar(out, '-');
++pc;
--width;
} else {
*--s = '-';
}
}
//补0的情况直接输出负号,补0宽度减1,然后交给prints补0
//左对齐的情况直接在s里添上负号交给prints即可
return pc + prints(out, s, width, flags);
}
完成后执行make grade,通过了前两个测试
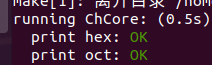
3.2 函数栈
有了格式化标准输出后,我们可以增加更多用于调测的内核态功能,例如堆栈回溯:AArch64 的函数调用使用的是bl指令(类似于 x86-64 中的call指令),并且使用栈结构保存函数调用信息:例如,函数的返回地址、所传入的参数等、上一个栈的指针等。因此,这些函数栈中的信息可以用来追踪函数的调用情况。
栈指针(Stack Pointer, SP) 寄存器(AArch64 中使用sp寄存器)指向当前正在使用的栈顶(即栈上的最低 位置)。栈的增长方向是内存地址从大到小 的方向,弹出和压入是栈的两个基本操作。将值压入堆栈需要减少 SP,然后将值写入 SP 指向的位置。从堆栈中弹出一个值则是读取 SP 指向的值,然后增加 SP。
与之相反,帧指针(Frame Pointer,FP) 寄存器(AArch64 中使用 x29 寄存器)指向当前正在使用的栈底(即栈上的最高 位置)。FP 与 SP 之间的内存空间,即当前正在执行的函数的栈空间,用于保存临时变量等。在AArch64中,SP 和 FP 都是 64 位的地址,并且 8 对齐(即保证可以被 8 整除)。
练习 6
内核栈初始化(即初始化 SP 和 FP)的代码位于哪个函数?内核栈在内存中位于哪里?内核如何为栈保留空间?
位于kernel\head.S中的start_kernel函数
#include <common/asm.h>
#include <common/vars.h>
BEGIN_FUNC(start_kernel)
/*
* Code in bootloader specified only the primary
* cpu with MPIDR = 0 can be boot here. So we directly
* set the TPIDR_EL1 to 0, which represent the logical
* cpuid in the kernel
*/
mov x3, #0
msr TPIDR_EL1, x3
ldr x2, =kernel_stack
add x2, x2, KERNEL_STACK_SIZE
mov sp, x2
bl main
END_FUNC(start_kernel)
其中kernel_stack是定义在kernel\main.c中的数组
//kernel\main.c
#include <common/kprint.h>
#include <common/macro.h>
#include <common/uart.h>
#include <common/machine.h>
ALIGN(STACK_ALIGNMENT)
char kernel_stack[PLAT_CPU_NUM][KERNEL_STACK_SIZE];
int stack_backtrace();
// Test the stack backtrace function (lab 1 only)
__attribute__ ((optimize("O1")))
void stack_test(long x)
{
kinfo("entering stack_test %d\n", x);
if (x > 0)
stack_test(x - 1);
else
stack_backtrace();
kinfo("leaving stack_test %d\n", x);
}
void main(void *addr)
{
/* Init uart */
uart_init();
kinfo("[ChCore] uart init finished\n");
kinfo("Address of main() is 0x%lx\n", main);
kinfo("123456 decimal is 0%o octal\n", 123456);
stack_test(5);
break_point();
return;
/* Should provide panic and use here */
BUG("[FATAL] Should never be here!\n");
}
KERNEL_STACK_SIZE是定义在kernel\common\vars.h中的常量(8192 = 0x2000)
/* Leave 8K space to kernel stack */
#define KERNEL_STACK_SIZE (8192)
#define IDLE_STACK_SIZE (8192)
#define STACK_ALIGNMENT 16
因此内核栈的SP即为kernel_stack数组的地址 + KERNEL_STACK_SIZE。
前面提到过.bss段记录未初始化的全局或静态变量,而kernel_stack就是程序中唯一的全局变量,因此地址应该是前边readelf得到.bss的VMA地址ffffff0000090100。SP的地址为0xffffff0000090100 + 0x2000 =0xffffff0000092100。
FP去哪了,似乎没有定义?
借助gdb x命令,查看寄存器的值。
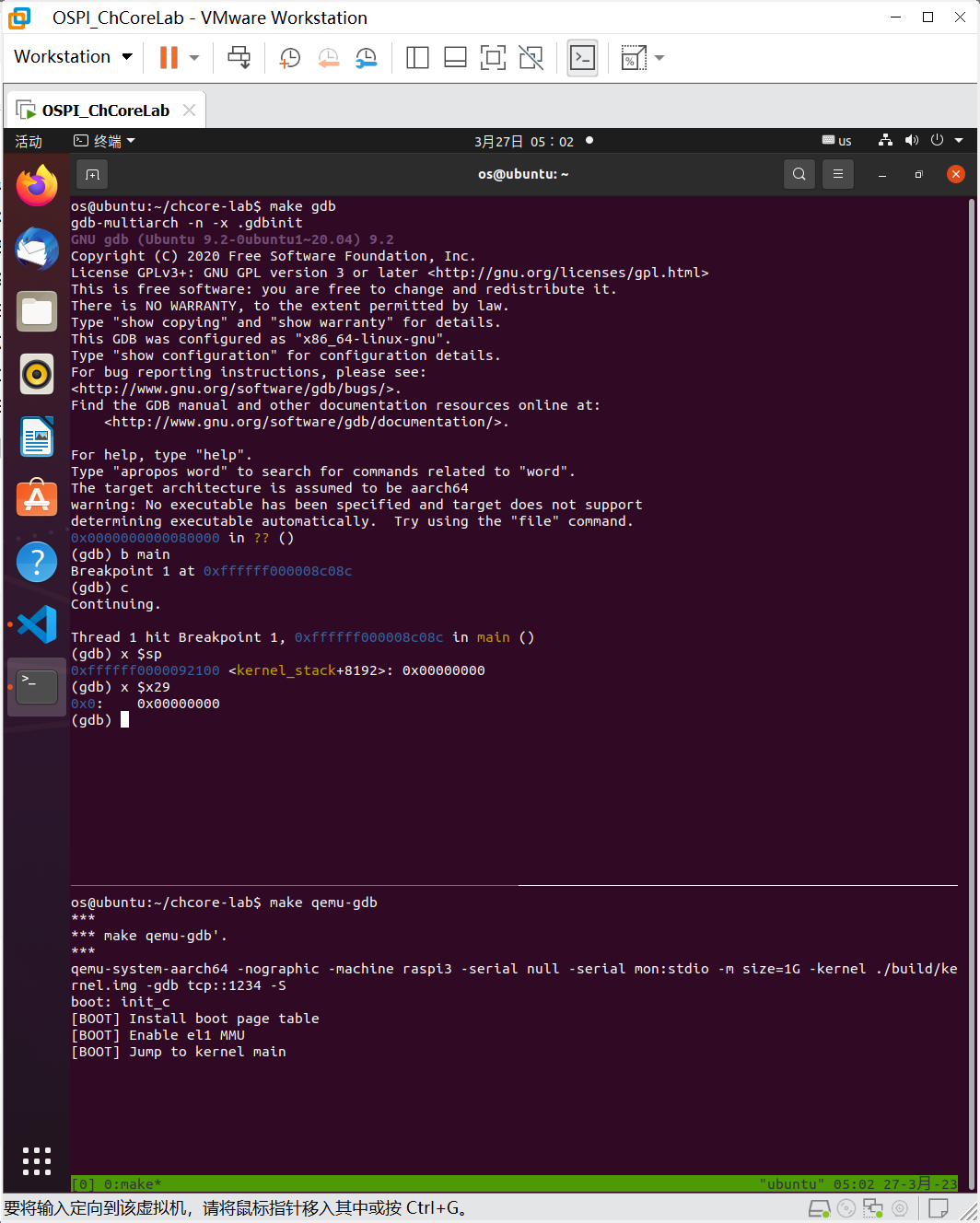
可见sp确实为ffffff0000092100,而用于存放FP地址的x29寄存器为0,应该还没有初始化。
(做完练习7后才发现)

在进入函数时,该函数在真正执行函数内部逻辑之前会有一些初始化栈帧指针的代码:通常通过将上一个函数所使用的 FP 压入栈来保存旧的 FP,然后再将当前的 SP 值复制到 FP 中。此外,这段初始化代码也会记录函数的返回地址、保存函数参数、保存寄存器的值等作用。返回地址保存在链接寄存器(Link Register,LR)(AArch64 中使用x30寄存器)中。根据这些调用惯例(calling convention),可以通过遵循已保存的 FP 指针链来追溯函数的调用顺序以及函数栈。这个特点可以用于调试,如定位代码的执行路径、查看调用函数时所用的参数等。
练习 7
为了熟悉 AArch64 上的函数调用惯例,请在kernel/main.c中通过GDB 找到stack_test函数的地址,在该处设置一个断点,并检查在内核启动后的每次调用情况。每个stack_test递归嵌套级别将多少个64位值压入堆栈,这些值是什么含义?
提示:GDB 可以将寄存器打印为地址及其 64 位值或数组,例如
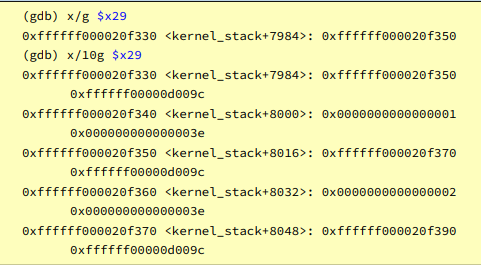
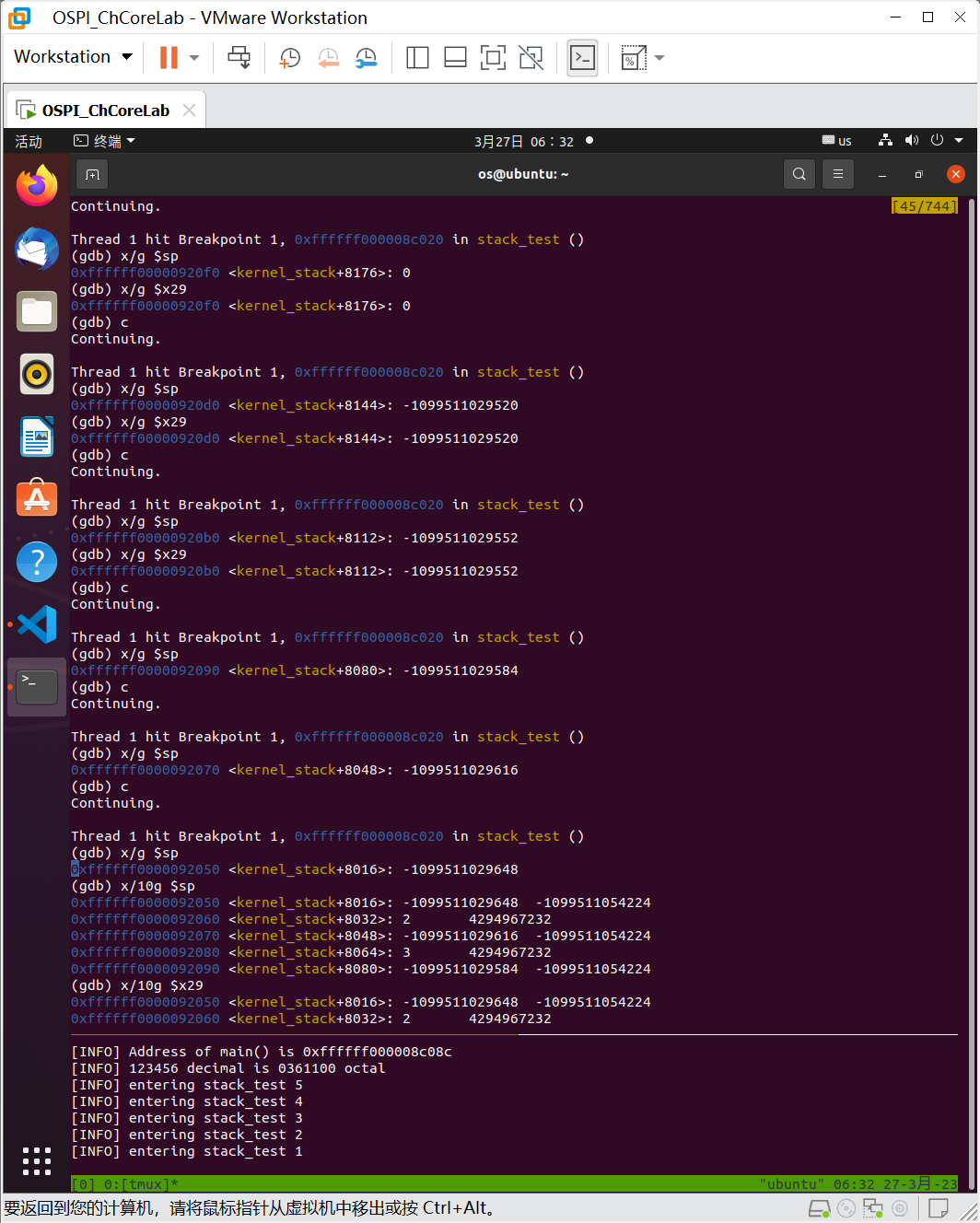
可以发现,每个stack_test递归嵌套级别使sp和fp同步降低32字节,将4个64位值压入堆栈。其中有一个值明显是stack_test的参数long x,其他三个尚不明确。
(后来发现,x/x才能输出16进制表示,至少可以看出高两位是0xffffff开头的地址值)
下面,我们使用 GDB 来读取汇编代码直观地理解 AArch64 中函数调用惯例,方法是在运行第一条指令(通过 GDB 命令s)后输入x/30i stack_test命令以显示stack_test函数开始的 30 行汇编代码。
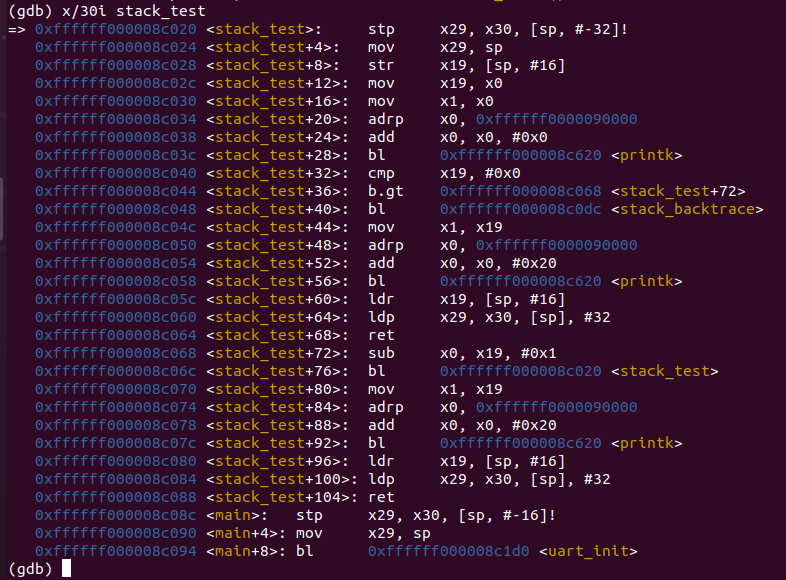
void stack_test(long x)
{
kinfo("entering stack_test %d\n", x);
if (x > 0)
stack_test(x - 1);
else
stack_backtrace();
kinfo("leaving stack_test %d\n", x);
}
分析汇编代码,可见每次sp向下移动32字节,将x29,x30和x19三个寄存器的值入栈。
x19占用了最低的16字节,是函数的参数。x29、x30分别是帧指针(FP)和返回地址(LR)。
练习 8
在 AArch64 中,返回地址(保存在x30寄存器),帧指针(保存在x29寄存器)和参数由寄存器传递。但是,当调用者函数(caller function)调用被调用者函数(callee fcuntion)时,为了复用这些寄存器,这些寄存器中原来的值是如何被存在栈中的?请使用示意图表示,回溯函数所需的信息(如 SP、FP、LR、参数、部分寄存器值等)在栈中具体保存的位置在哪?
https://blog.csdn.net/rikeyone/article/details/108196507
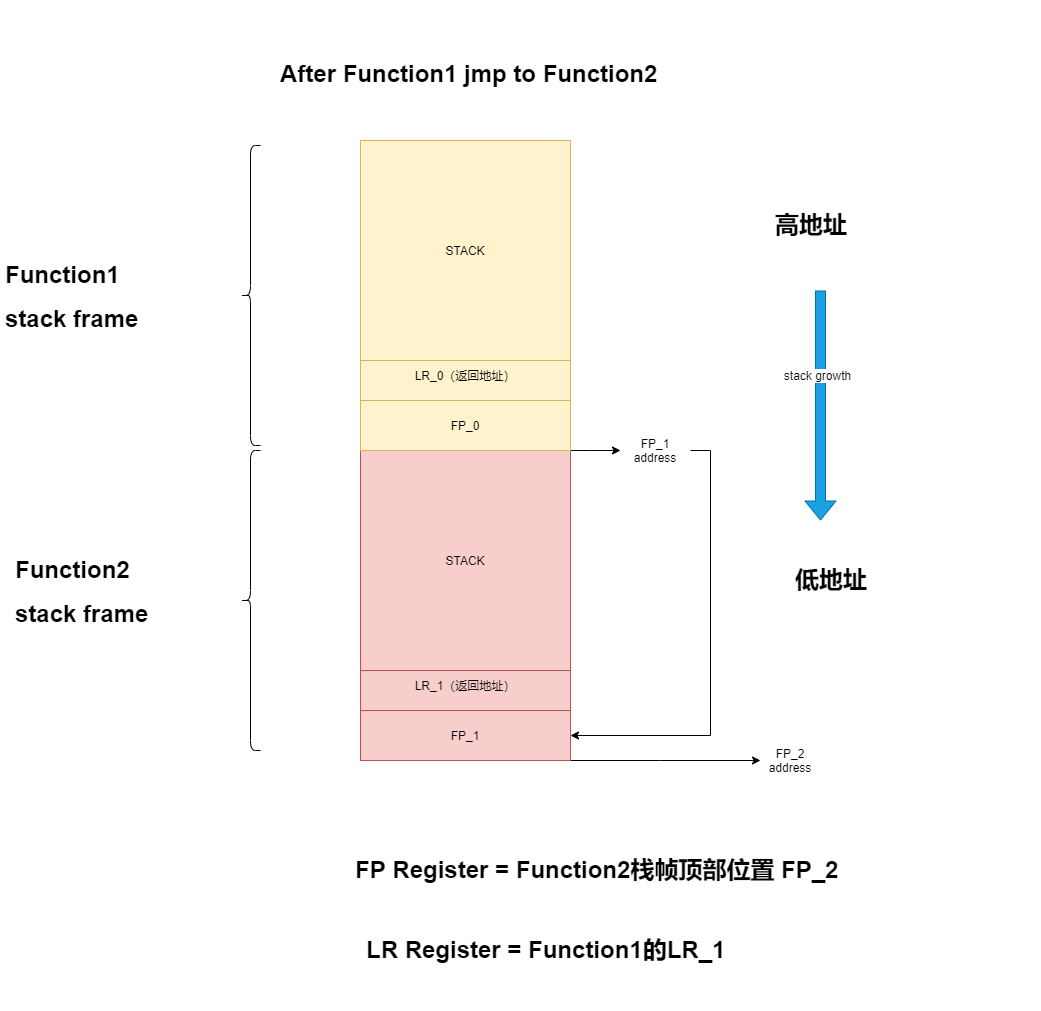
ARM64平台上的栈帧寄存器是FP,它记录的是一个函数执行过程中的栈顶(FP=SP),并且把父函数的FP保存在堆栈的栈顶,以便于回溯。
根据对汇编代码的分析,次入栈的32字节数据,低16位存放函数参数,高16位依次是FP和LR。
将断点设在stack_backtrace(),执行x40/x $sp
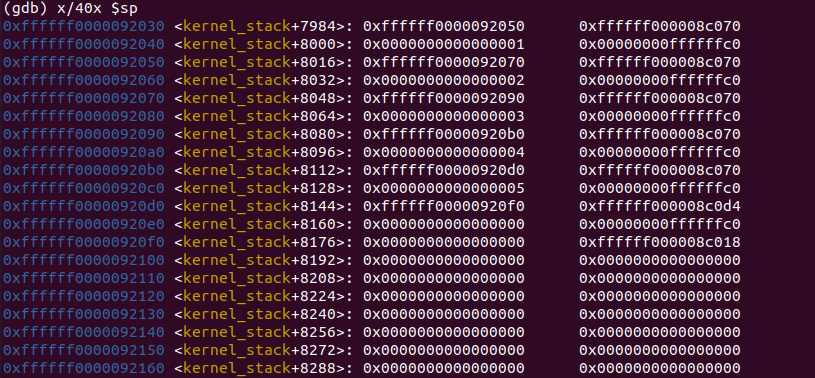
此时第一行是进入最内层stack_test函数后更新的FP和LR。
可以发现每一层函数栈中的FP都存放父函数FP的地址(92030->92050->92070...),直到最外层stack_test函数指向了值为0的位置。
ChCore 通过调用stack_backtrace()函数进行栈回溯,该函数定义在kernel/monitor.c,并且回溯结果忽略该函数本身。该文件中的read_fp()函数可以通过内联汇编的方式,直接读到当前 FP 的值。stack_backtrace的输出格式如下:
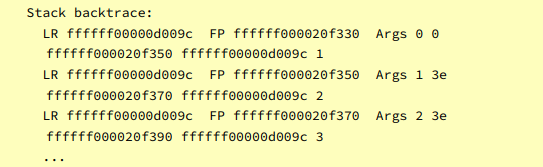
输出的第一行反映了调用stack_backtrace的函数,第二行反映了调用该函数的函数,依此类推,其终止条件可以通过“练习 7”得知。
输出结果的每一行包含 LR,FP 和 Args,并且以十六进制表示。FP 表示函数栈的帧指针(x29),即刚进入该函数并设置 FP 后的值。LR 表示函数返回后的指令地址,即调用者函数bl指令的下一条指令。bl [label]指令跳转到label,并将寄存器x30设置为PC + 4。最后,在Args之后列出的五个值是函数的前五个参数。如果函数的参数少于 5 个,则多余的值是无效的。
例如,第一是stack_test(0)的 信 息。 在这一行中,LR表示stack_test(0)返回之后的指令地址,FP是该函数初始化栈之后的FP,而 Args 为 0(后面 4 个值无效)。
练习 9
使用与示例相同的格式, 在kernel/monitor.c中 实
现stack_backtrace。为了忽略编译器优化等级的影响,只需要
考虑stack_test的情况,我们已经强制了这个函数编译优化等级。
根据练习8的讨论,嵌套函数中,子函数的FP处存放着父函数FP的地址。因此只要得知最内层函数栈中的FP,即可通过FP = (u64*)(*FP)不断得到外层的FP。而monitor.c给出了获取当前FP的函数,因此while循环迭代直到FP为0即可。不过对指导书中的“五个参数,多余的值无效”有些疑惑,应该只需要考虑stack_test的函数栈吧。
#include <common/printk.h>
#include <common/types.h>
static inline __attribute__ ((always_inline))
u64 read_fp()
{
u64 fp;
__asm __volatile("mov %0, x29":"=r"(fp));
return fp;
}
__attribute__ ((optimize("O1")))
int stack_backtrace()
{
printk("Stack backtrace:\n");
// Your code here.
u64* FP = (u64*)read_fp(); read_fp();
FP = (u64*)*FP;//从stack_backtrace()返回到stack_test()最里层
while (FP != 0) {
printk("LR %lx FP %lx Args %d %d %d %d %d\n",*(FP+1),FP,*(FP-2),*(FP-1));
FP = (u64*)*FP;
}
return 0;
}
完成后,执行make grade进行测评,得到满分。
总结
作为OS萌新,感觉ChCore Lab还是很有挑战性的,为了完成一个Lab学习的东西要远远多于书上几十页的理论知识。但是和单单看书相比,确实对理解操作系统有很大帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号