个人第三次软件工程作业-效能分析
前言
在进行本次作业之前,发现之前编译的程序中,有一处bug:不能完整读取文件,导致词频统计不完整。在进行本次作业之前已经修复。
要求0
—具体要求:以 战争与和平 作为输入文件,重读向由文件系统读入。连续三次运行,给出每次消耗时间、CPU参数。
根据老师提供的工具,在这里选用 ptime.exe 在windows系统下进行测试。
1.首先根据提供的命令启动程序
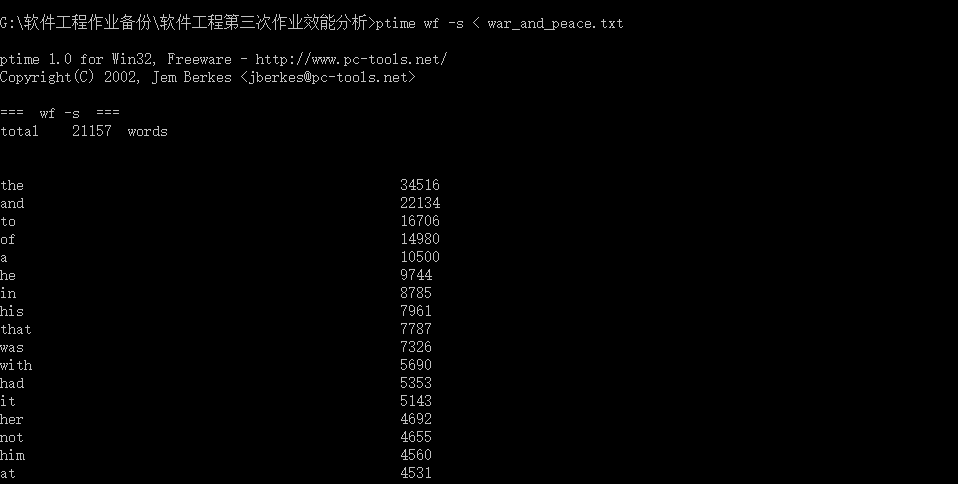
2.给出三次测试的消耗时间截图



时间总结
| 第一次 | 第二次 | 第三次 | |
| 测试时间/s | 124.038 | 182.880 | 180.224 |
| 平均时间/s | 162.381 | ||
3.cpu参数
cpu的详细参数,这里用CPU-Z来测试给出:

要求1
—具体要求:给出你猜测程序的瓶颈。你认为优化会有最佳效果,或者在上周在此处做过优化 (或考虑到优化,因此更差的代码没有写出) 。
上周我在写词频统计的程序时,第一选择就是用数组,加上最后添加冒泡排序实现程序的主要功能。这一点我认为如果采用最开始的方案,最终程序的性能一定不如利用map容器等相关知识编写出的程序。
同时我认为在去除符号标点这一项可能会出现瓶颈。定义的函数中部分代码如下:


1 for(int i = 0; i < nLen; i++) 2 { 3 if(ignoreSet.find(theString[i]) == ignoreSet.end()) 4 { 5 strResult += theString[i]; 6 } 7 }
此处进行符号判断时用的是最基础的知识,就是挨个字符判断是否是影响判断单词的标点符号,然后删除拼接,最后再接着进行排序。时间复杂度较高。预计优化后能减少10-20秒的运行时间。
要求2
—具体要求:通过 profile 找出程序的瓶颈。给出程序运行中最花费时间的3个函数(或代码片断)。要求包括截图。
在作业下面给出的参考博文中,刘伟硕 VS C#:[http://www.cnblogs.com/WeSure6/p/5275715.html],让我知道可以用VS提供的自带分析工具:performance tool进行性能分析。我便根据博文中的步骤,对我自己的程序进行分析。
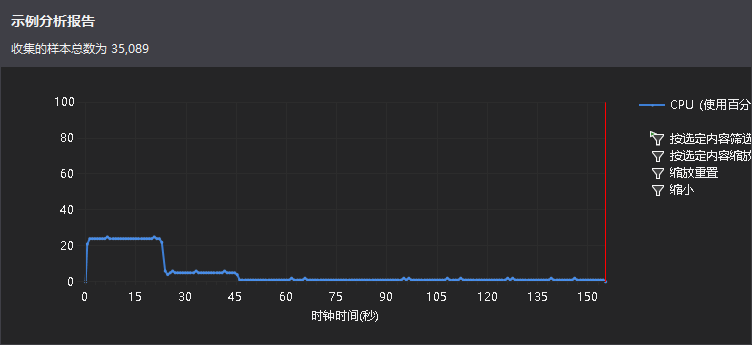
首先采用cpu采样对程序进行分析:
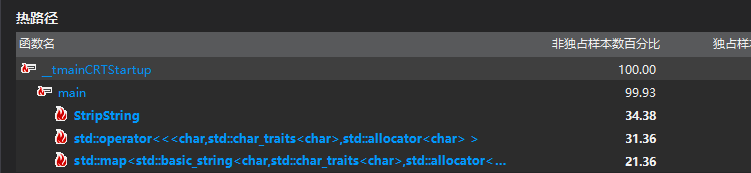
点开main可以看到如下图

可以发现占有率最高的代码语句是输出已经得到的词频统计的数据。分别输出单词,以及出现的次数。
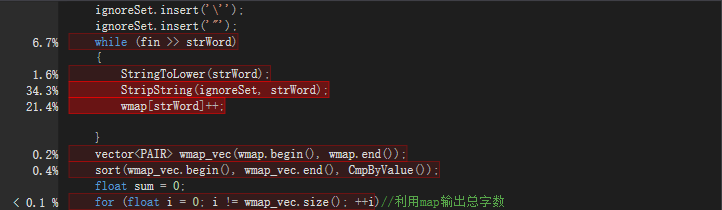
其实占有率第二高的代码语句是去除标点以及影响统计单词的各种符号。同时在上图可以看出来占有率第三高的是存放单词的语句。
所以根据以上图的情况可以知道这三个函数就是花费时间最多的函数。
(1)cout << left << setw(50) << wmap_vec[i].first << wmap_vec[i].second << endl;
这个语句就是用来输出最后统计结果的函数。按照程序运行的顺利来看,这个语句肯定是要花费时间最多的。因为要不断的打印输出结果,一行一行的将统计的结果输出,无疑是要花费很长时间的。
(2)void StripString(const set<char> &ignoreSet, string &theString)
这个函数的具体代码如下所示
1 void StripString(const set<char> &ignoreSet, string &theString) 2 { 3 string strResult; 4 int nLen = theString.length(); 5 for(int i = 0; i < nLen; i++) 6 { 7 if(ignoreSet.find(theString[i]) == ignoreSet.end()) 8 { 9 strResult += theString[i]; 10 } 11 } 12 theString = strResult; 13 }
这个函数首会传递两个参数,第一个参数是要除去的符号,例如:" ' , . ? ( )等。因为要从第一个字符开始检索,所以运行的效率就会变得很低。
3.wmap[strWord]++;
这个语句是将分好的单词存储在定义好的一个map容器中。这样才能方便之后对保存好的单词进行统计,排序。
要求3
—具体要求:给出如何改进瓶颈,改进后与改进前程序原理上 (而不是效果上的) 的差异。
在要求2中,分析到影响性能的三个最主要的函数或语句。根据我自己的理解,我认为想要优化map存储的过程或者是优化最后输出的过程都比较困难。所以我从优化去除标点的函数开始入手。
在我的理解中,之所以去除标点最为耗时,最主要的原因是这个函数写的比较“笨”,没有发挥编程语言的优势。为了实现这个部分的功能,只是简单的写了一个方法。所以我开始想办法优化。最开始我想到的是改变写法,在读取字符串之后,逐一排除标点符号。如下所示:
1 while(fin >> strWord) 2 { 3 StringToLower(strWord); 4 if(strWord!="."&&strWord!=","&&strWord!="?"&&strWord!=":"&&strWord!="!"&&strWord!=";"&&strWord!="\""&&strWord!="'"&&strWord!=";"&&strWord!="("&&strWord!="") 5 { 6 transform(strWord.begin(), strWord.end(), strWord.begin(), ::tolower); 7 ++wmap[strWord]; 8 } 9 }
改成这样之后,不仅看起来更笨了,而且很难阅读,并且最致命的是在我测试的时候发现花费的时间不仅没有减少反而增加了将近一倍。很显然不管怎么看,这种解决方案都是最差的。同时,我发现这样改出来的代码和初代代码在原理上并没有实质的区别,都是要读取字符串,每个字符都要逐一排查才能实现去除标点的功能。而且在我测试的时候,也同时发现最后输出的结果会有很多错误。所以我就果断放弃了这个方案。
之后我开始查阅资料,在知乎中看到了一个提问:“如何快速简单地统计一个英文文本文件中每个单词出现的次数,并将结果存入指定文件?”地址:https://www.zhihu.com/question/24328645/answer/27443008。在这个提问中多个人提到在《c++ primer》中有提到正好是我所用的map容器。因为之前我并没有看过这本书,所以并不知道其中的方法。所以我就开始阅读《c++ primer》。在这本书的第二篇第六章详细讲到了抽象容器类型。并且在本章中提到了iterator迭代器。
书中介绍道:迭代器 iterator 提供了一种一般化的方法 对顺序或关联容器类型中的每个元素进行连续访问 。我觉得这个方法可以很好的解决目前我遇到的问题。接着我了解到 “string类提供了向前和向后遍历的迭代器iterator,迭代器提供了访问各个字符的语法,类似于指针操作,迭代器不检查范围。用string::iterator或string::const_iterator声明迭代器变量,const_iterator不允许改变迭代的内容。” 之后便选用这个方法对程序进行改造。我便把去除符号的功能函数改写为如下所示:
1 void erasePunct(string &s) 2 { 3 string::iterator it = s.begin(); 4 while(it != s.end()) 5 { 6 if(ispunct(*it)) 7 it = s.erase(it); 8 else 9 ++it; 10 } 11 }
并且在读取字符串之后调用这个函数。
1 while(fin >> strWord) 2 { 3 StringToLower(strWord); 4 erasePunct(strWord); 5 wmap[strWord]++; 6 }
编译,运行,测试。惊喜的发现果然运行时间减少了!而且单词是识别率变高了很多,超出了我的预期效果。
要求4
再次 profile,给出在 要求1 中的最花费时间的3个函数此时的花费。要求包括截图。
更新代码后的运行时间如下图所示:



| 第一次 | 第二次 | 第三次 | |
| 测试时间/s | 116.878 | 116.855 | 117.002 |
| 平均时间/s | 116.918 | ||
再次用vs2013进行性能分析:
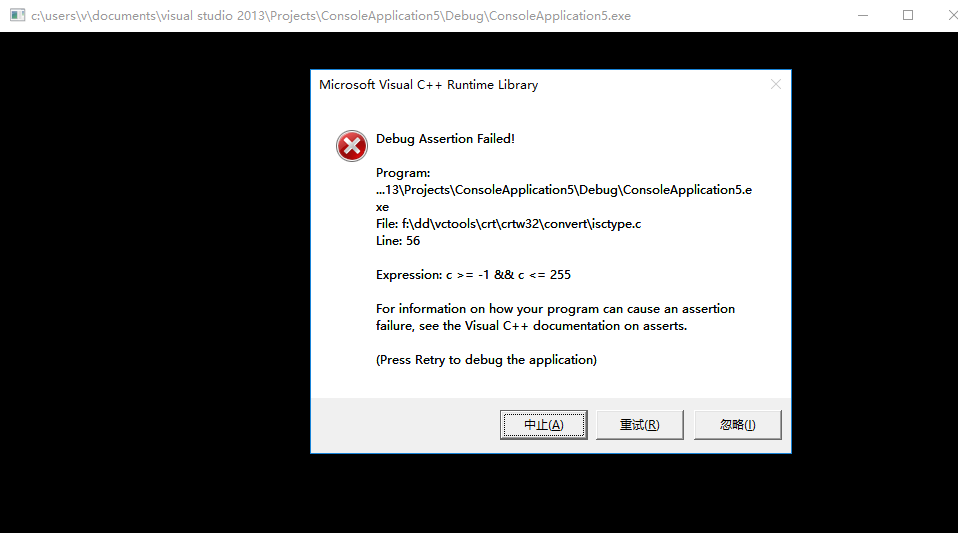
没想到在codeblocks编译器中正常运行的代码,在vs2013中进行调试的时候竟然报错。我开始上网查资料寻找出错原因。
在查阅大量网页之后,我自己认为是改动的函数中存在野指针,导致调试错误。试着修改野指针,让程序正常进行。
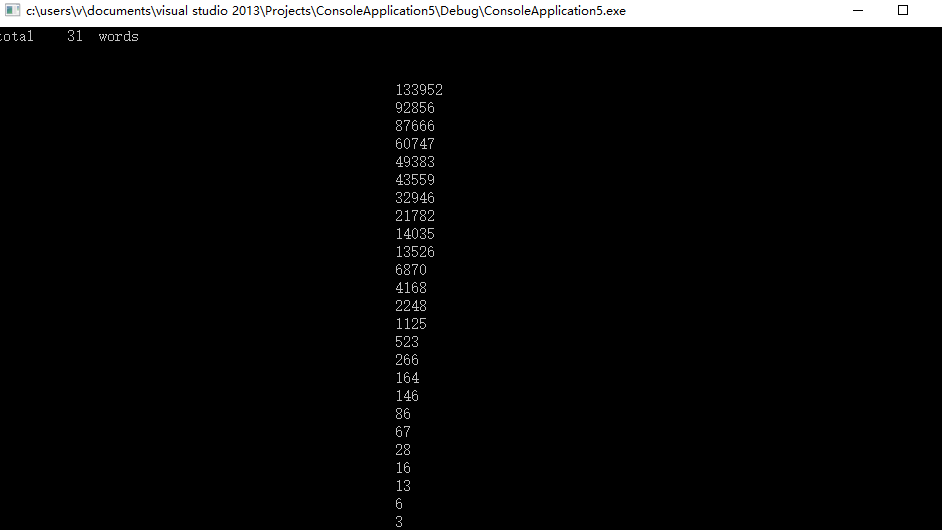
这次运行倒是正常运行了,但是明显出错。只有次数没有单词,而且单词数量明显不对。所以我又开始尝试修改,但是在大量尝试之后还是没办法修复。到目前也没找到修复方法。没办法正常运行程序性能分析只能到这里结束了。不过根据运行速度,我认为程序的性能还是明显提升。
要求5
git地址:https://git.coding.net/Vrocker/wf.git
补充
看完一些同学的效能分析博文后发现,大多数同学的程序都只是输出出现次数最多的前十个单词。我反复看题目的要求,并没有特殊声明输出是所有单词出现的次数,还是输出出现次数前十的单词以及对应的次数。但是毕竟大多同学都是只输出前十,所以我也改动了一下代码。
根据前文的分析,虽然输出时间会变得很少,但是明显的我最初的程序之所以运行较慢,去除符号还是主要因素。所以上文提及的优化思路并没有错误。
所以在最后补充只输出前十单词的运行时间:

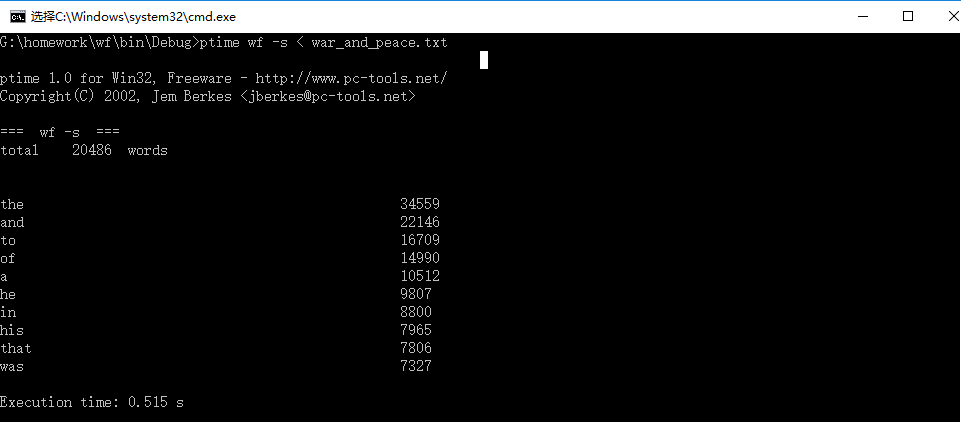
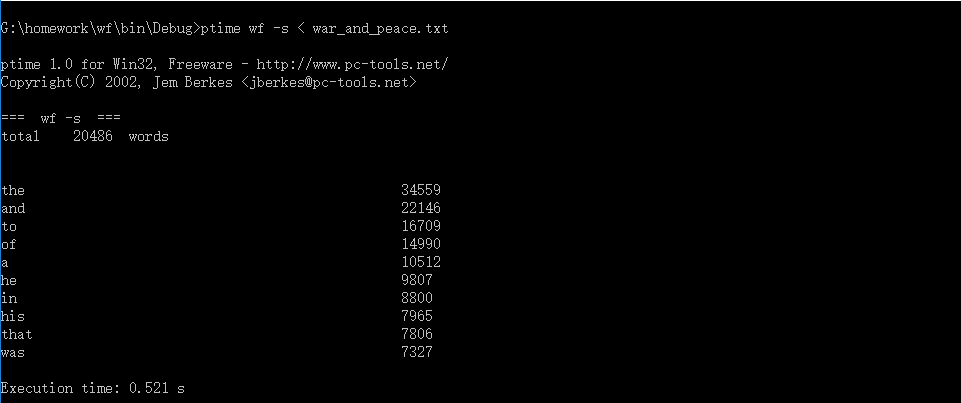
| 第一次 | 第二次 | 第三次 | |
| 测试时间/s | 0.506 | 0.515 | 0.521 |
| 平均时间/s | 0.514 | ||
速度还算理想。
在git上也暂且改成 输出出现次数前十单词 的代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号