2024-02-05 - Vit模型基础 - 卢菁
摘要
2024-02-05 周一 老家 晴
小记: 多模态大语言模型才是未来,多模态不过也是各个模态的组合,未来已来。
课程内容
1. 多模态入门: vit 模型
- vit: Vision Transforms
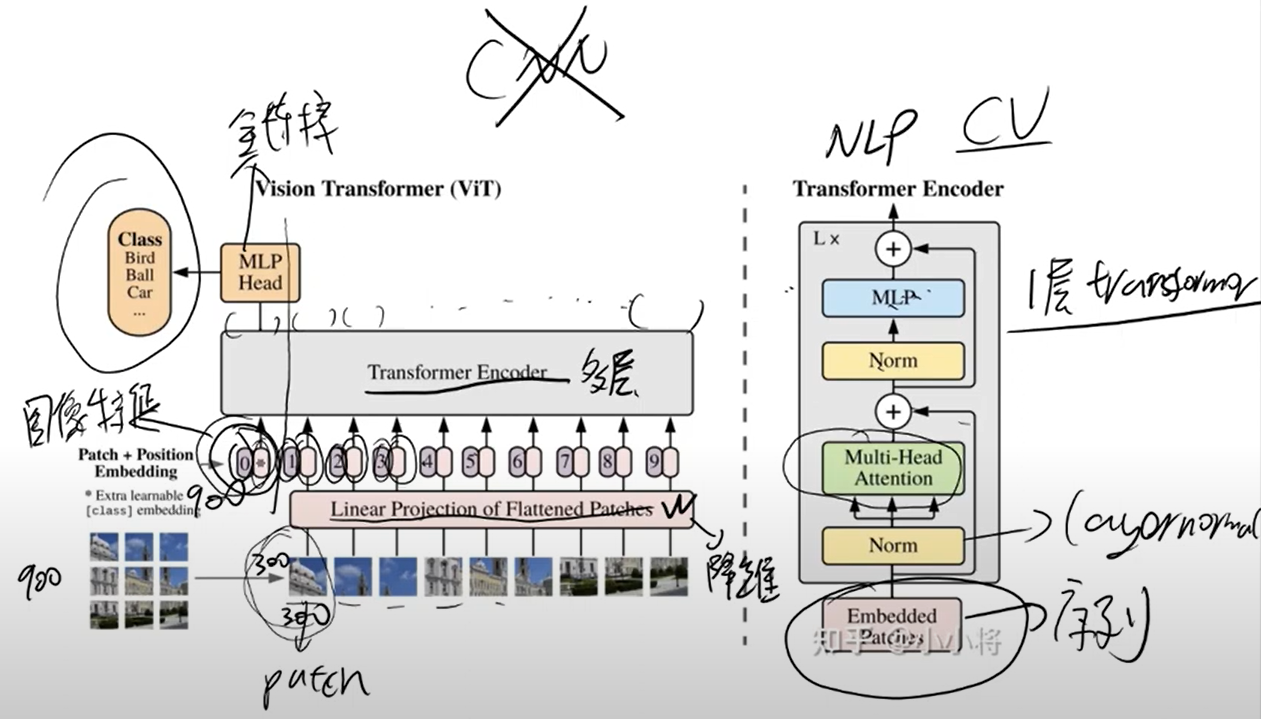
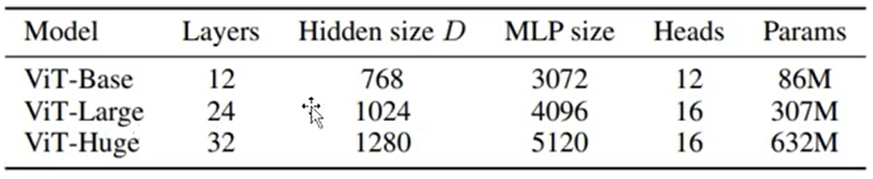
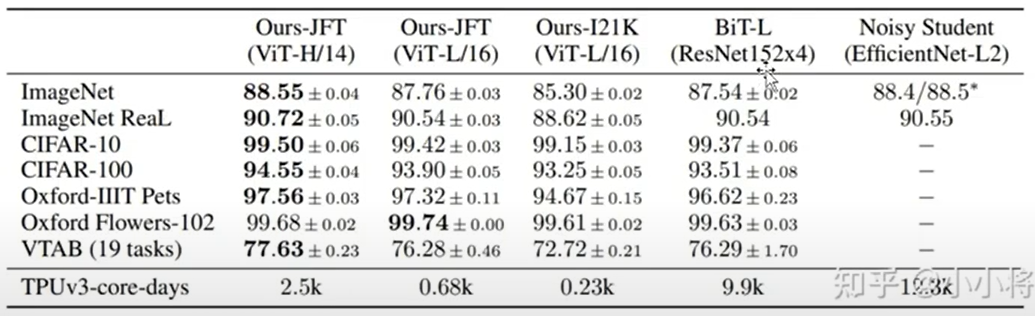
2. CNN vs Transforms
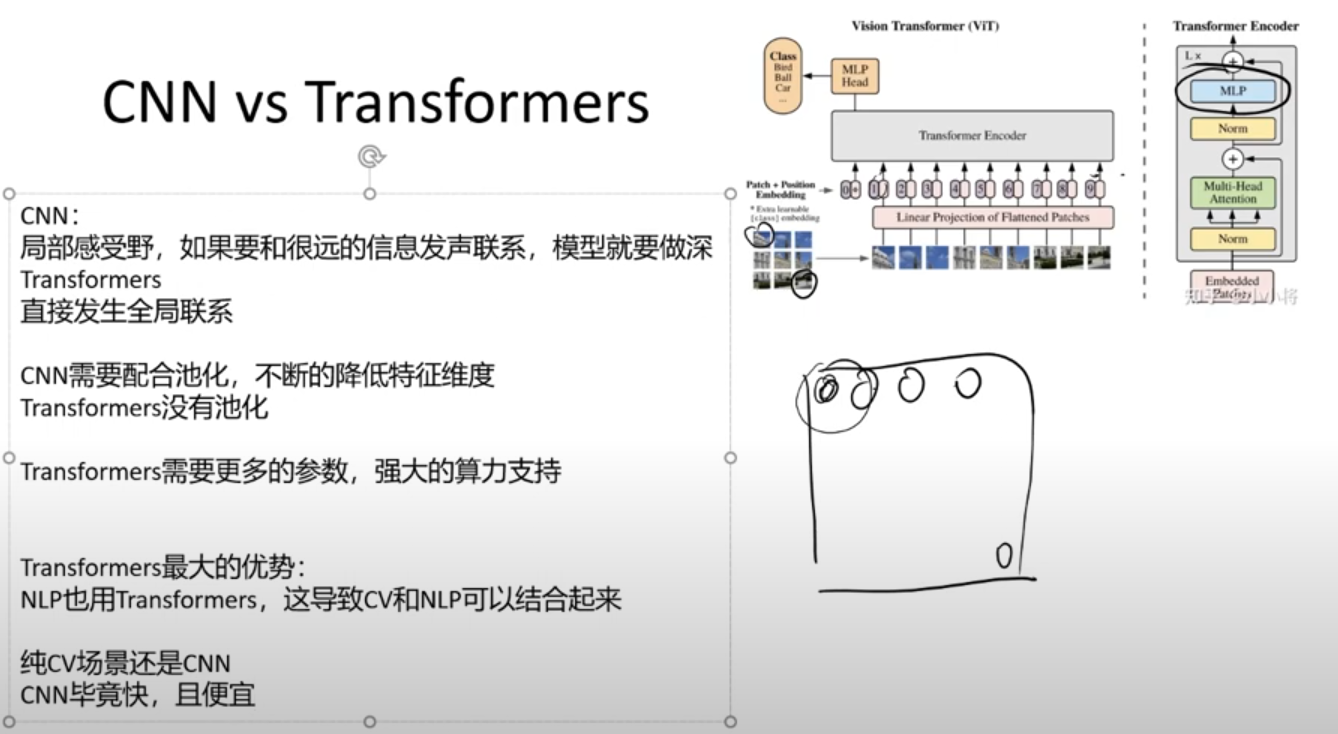
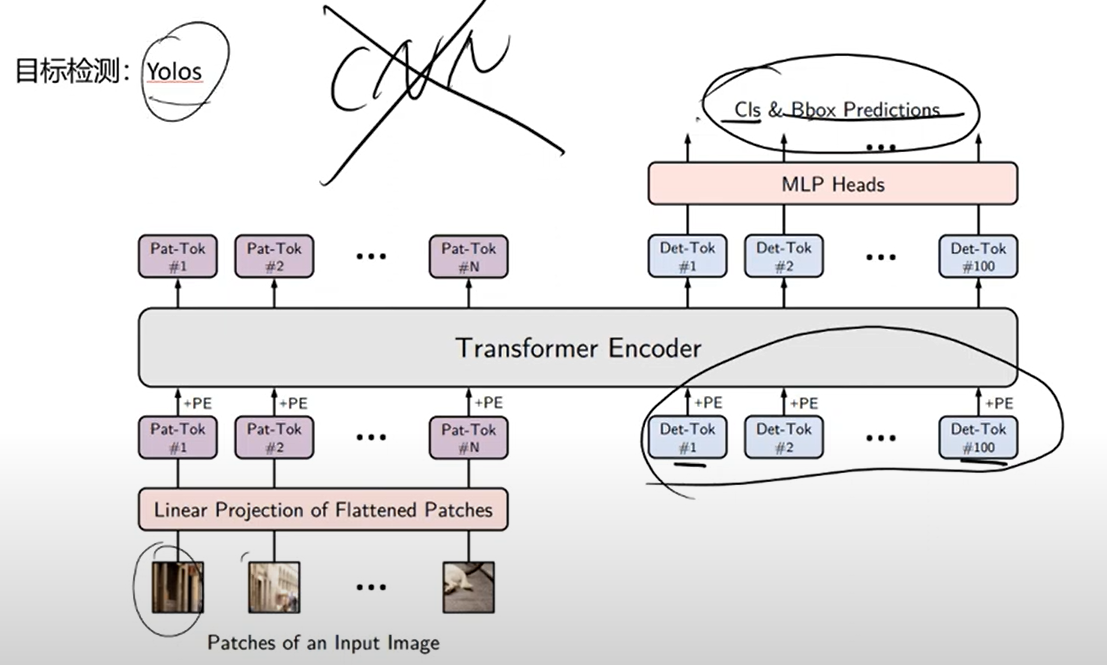
- 用神经网络对图像进行分类;
- 越靠近输入的网络,越倾向于提取特征(客观的需求)
- 越靠近输出的网络,越倾向于分类(主观的需求)
3. 多模态: Blip模型
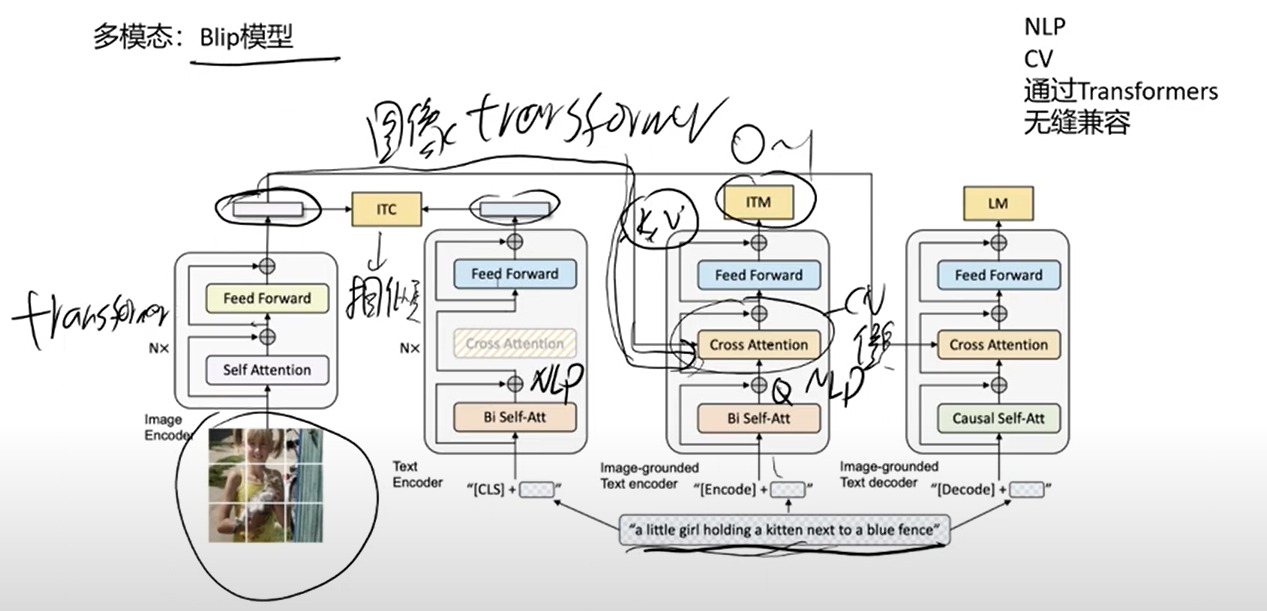
关键点: NLP 和 CV 都可以通过 Transformers 无缝实现兼容,视觉处理Transformers 比使用 CNN 好很多。
总结
心得: 多模态是研究的最佳方向,赶紧上车。
后会无期,未来可期!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号