2024-02-02-从chatgpt看NLP发展历史脉络-卢菁
摘要
2024-02-02 周五 老家 阴
小记: 静下来,学而思,不要高谈阔论,成长是需要时间的,不急了会有骨质增生的。
课程内容
1. NLP 发展4阶段

关键词: chatgpt 的出现都是有迹可循的必然过程,量变到质变是存在大量积累才会有的突破,因为足够大,所以不容易,创世的产品只要一次就够了,国内如果有公司吹嘘自己的大模型是完全自己独立训练的,别信,因为那肯定是吹牛逼。大模型只要初代和几个比较强的衍生代就可以了,我们站在巨人的肩膀上微调即可,不要那么憨批为了吹牛什么都敢说。
2. 大模型的两大流派
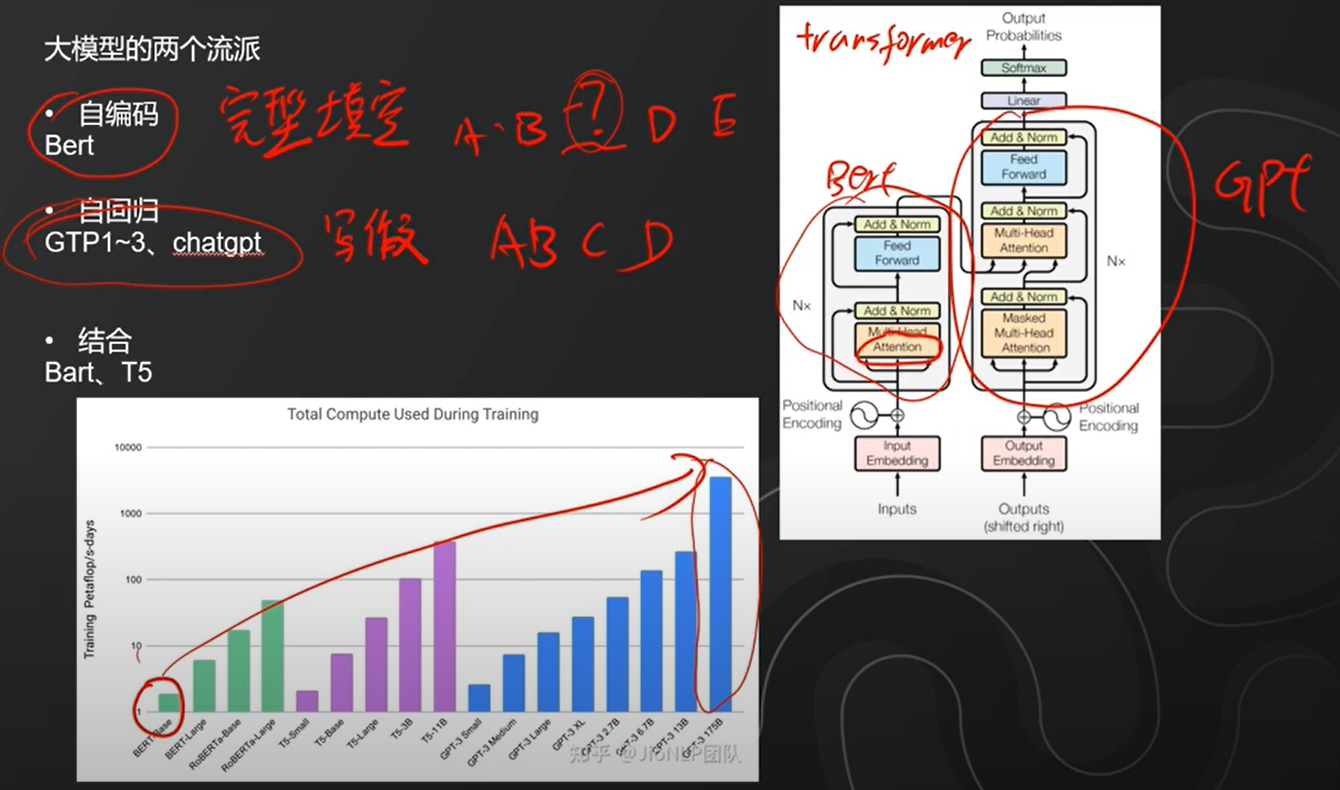
关键词:
a. 自编码: 代表产品,谷歌产品 Bert ,训练方式类似完形填空,相对写作来说比较简单,但是更加可控,毕竟完形填空已经限定了一定的情景;
b. 自回归: 代表产品,OpenAI 的 GPT-3 和 chatgpt ,训练方式类似写作,可以自由发挥的空间更大,但是存在幻性,同时只有聪明人才更善于骗人。被骗的人往往过于贪心,骗人的人知识聪明用错了地方。
c. 结合:代表产品,Bart 与 T5 ,训练方式是结合自编码和自回归的优势,历史总是如此,要么偏左要么偏右,居中平衡的往往没啥子亮点;
3. NLP 核心问题

关键点:
a. 中间类任务: 1. 分词;2. 词性标注;3. 句法分析;4. 同义词;
b. 语义理解类问题(自编码擅长): 1. 文本分类;2. 句子相似度;3.标签抽取;
c. 语义生成问题(自回归擅长):1.机器翻译;2. 文本摘要;3. 问答系统;4. 文本纠错;
随着大模型技术的发展,中间类任务逐渐变得没有必要,同样语义理解类问题同样可以通过语义生成问题解决此类问题,因此通过语义生成可以囊括大部分中间类任务和语义理解类问题,因此这也是 GPT 取得如此突破和成绩的原因。
心得: 选择大于努力,奋斗不一定等于成功。
4. Prompt 学习
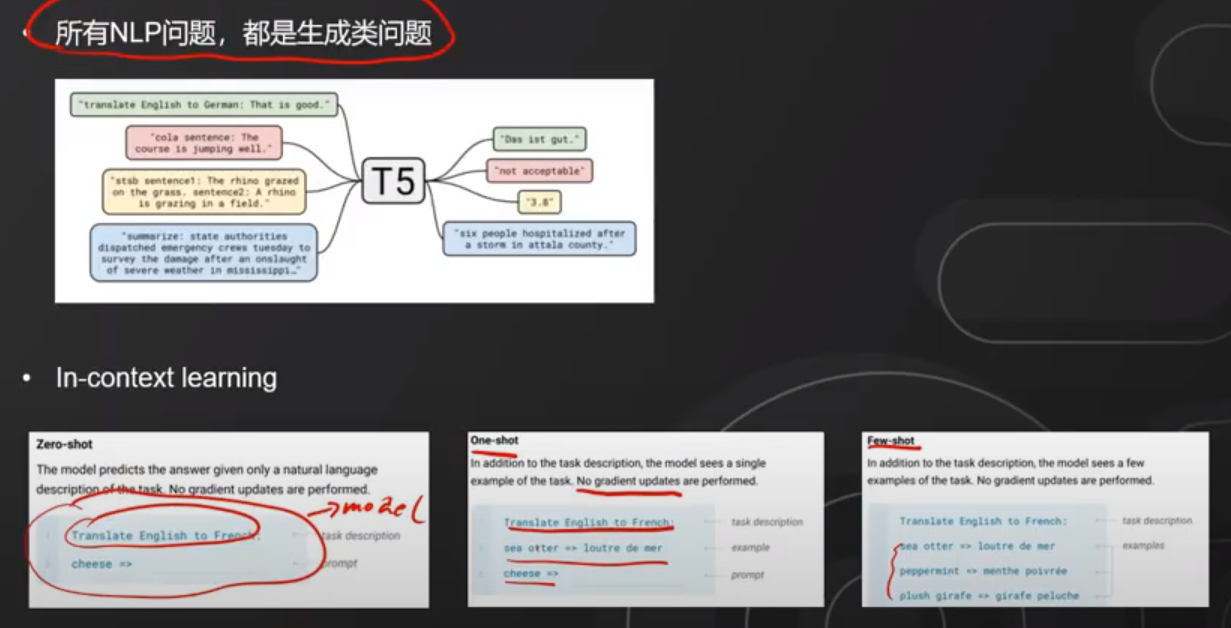
关键词: 通过 Prompt 可以标注特定的词义,因此在数据处理上就不用耗费大量的心神进行标注从而达到预期的目标,这也是大语言模型取得的很大的突破,因此普通人都可以进行大模型训练与学习。
心得: 所有 NLP 问题本质都是生成类问题;
5. 用户规模效应

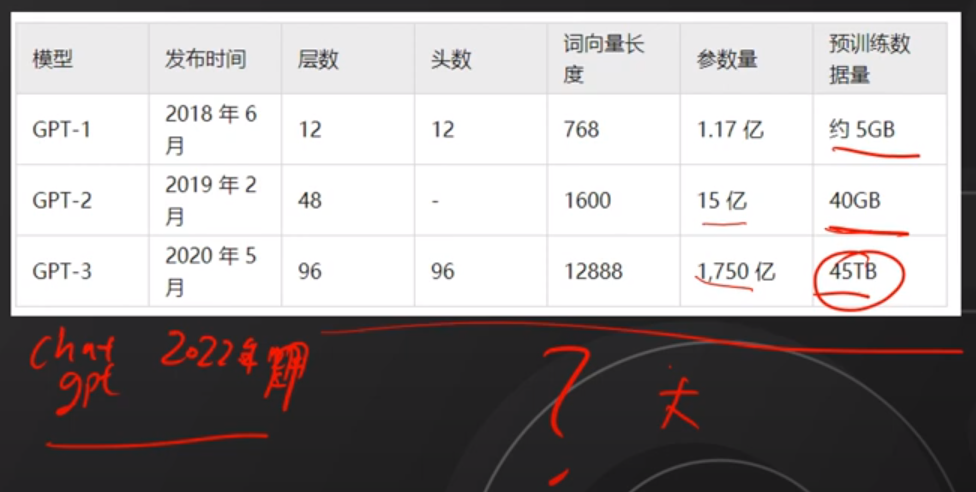
6. 大模型训练成本

关键词: ChatGpt 训练过程在全球范围内,寻找低成本人力的国家,动用 40个人力资源外包公司,单单电费消耗就达到了数百万美金。如此的资金政治调度能力,难呀!
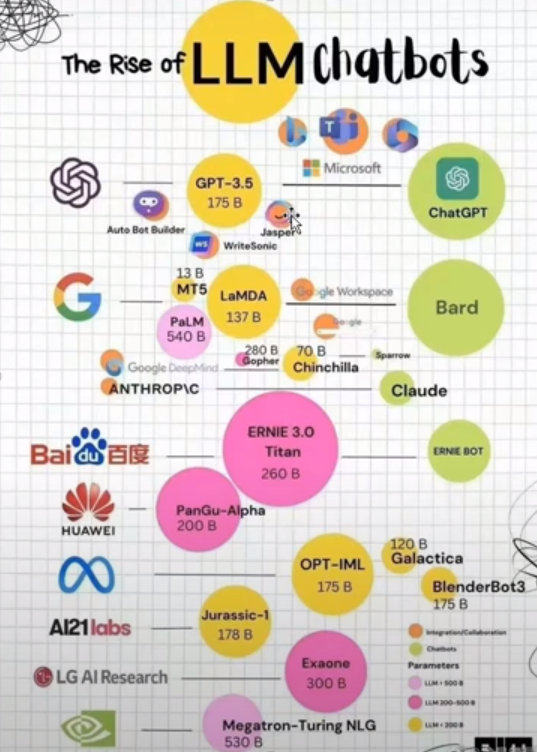
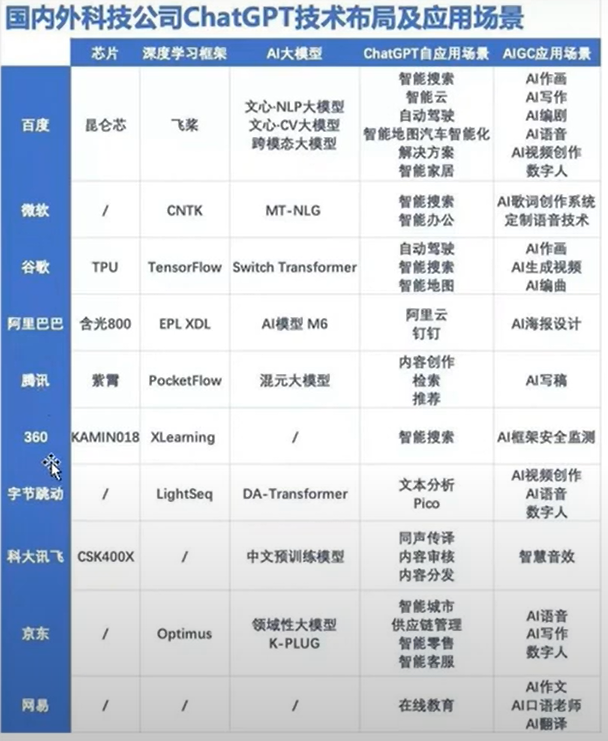
7. 各大厂商的大模型
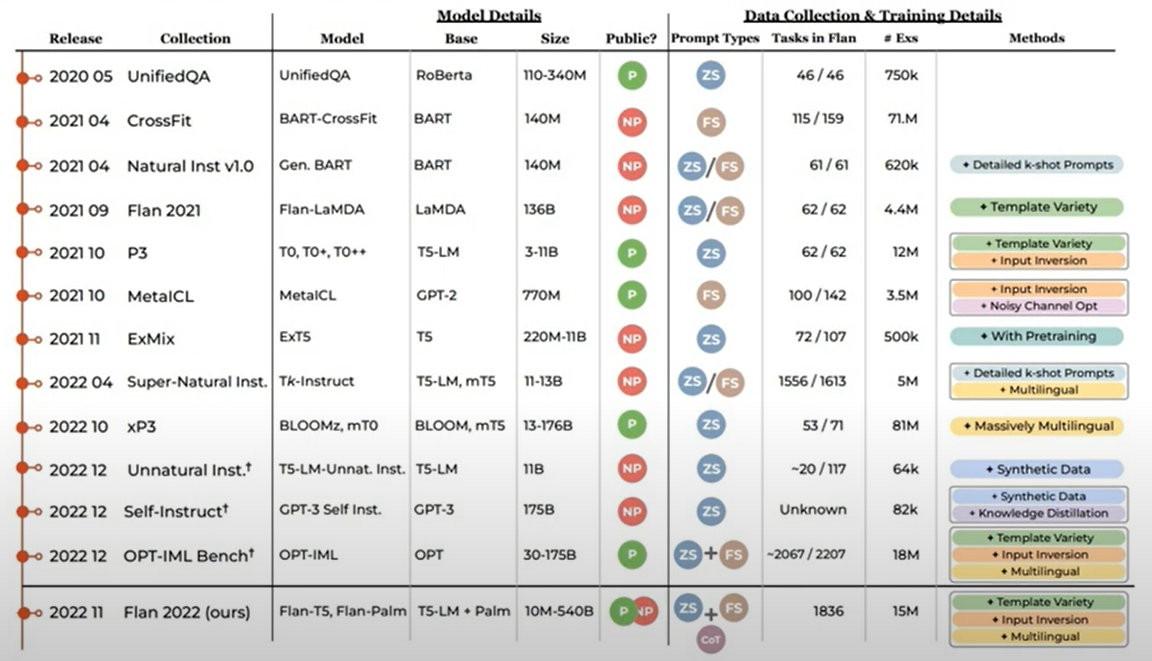
8. 互联网核心技术的改变
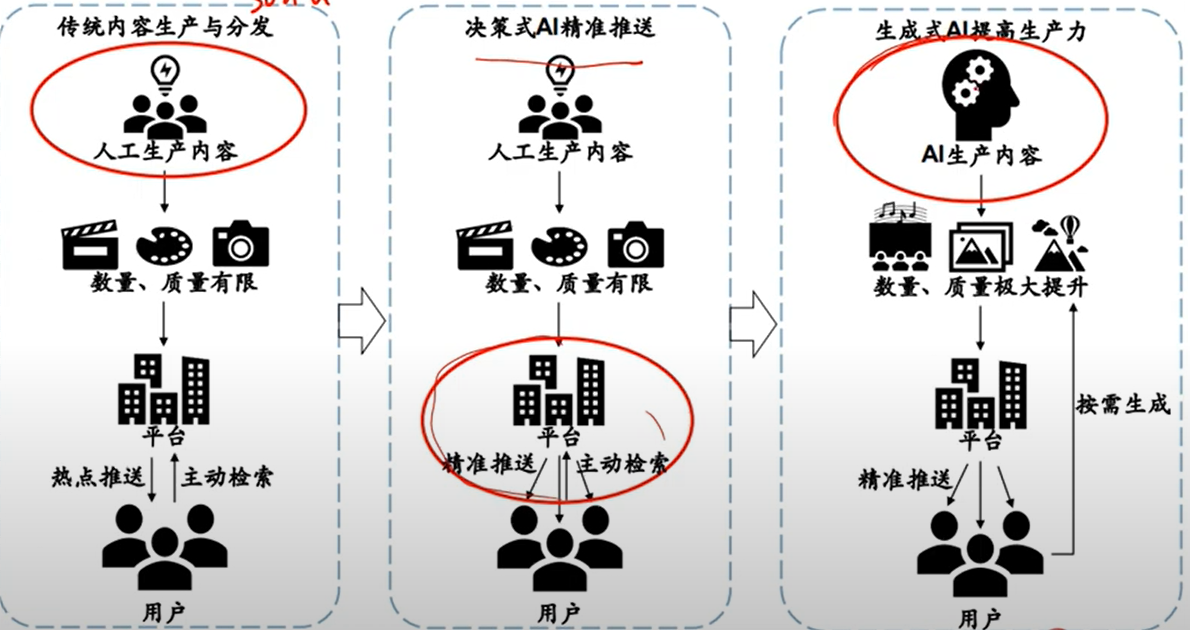
关键词: AI 生成内容将会是下一个时代的风口,用户生成内容将会逐渐没落,因为个人在回答或者诉求上具有很强的主观性。
9. 人力成本

10. chatgpt 在中国应用的最大风险

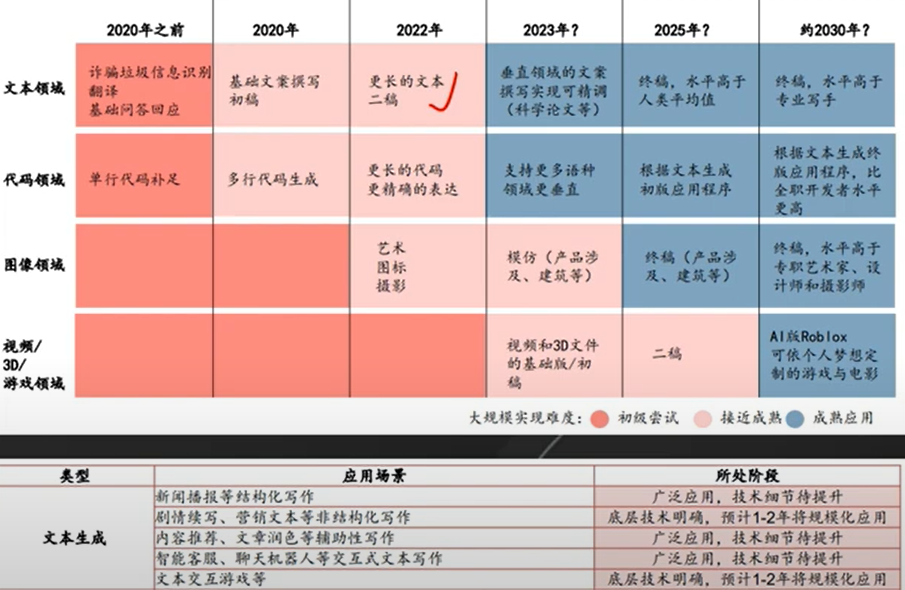
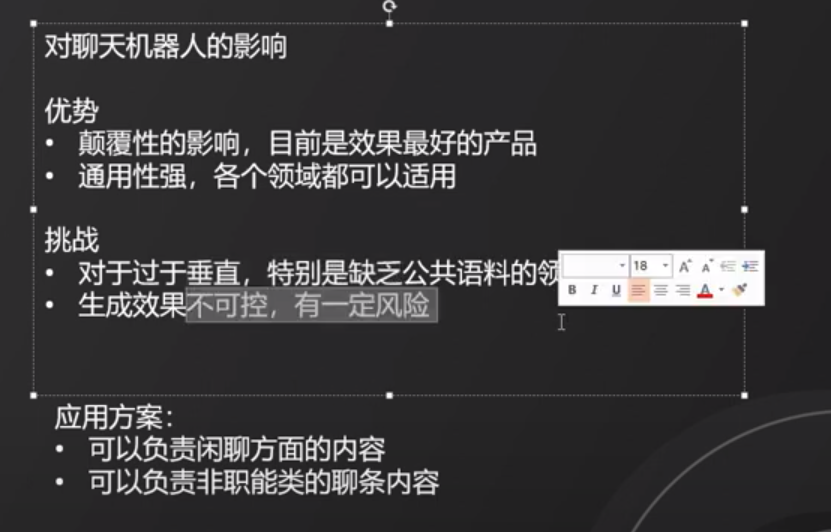
11. chatgpt 对内容生成的影响


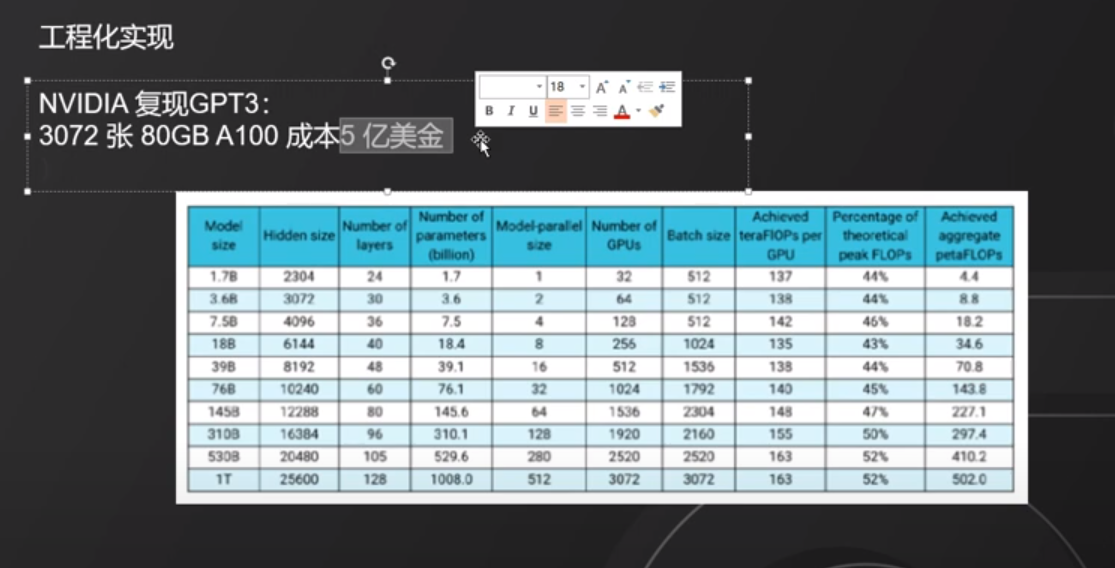
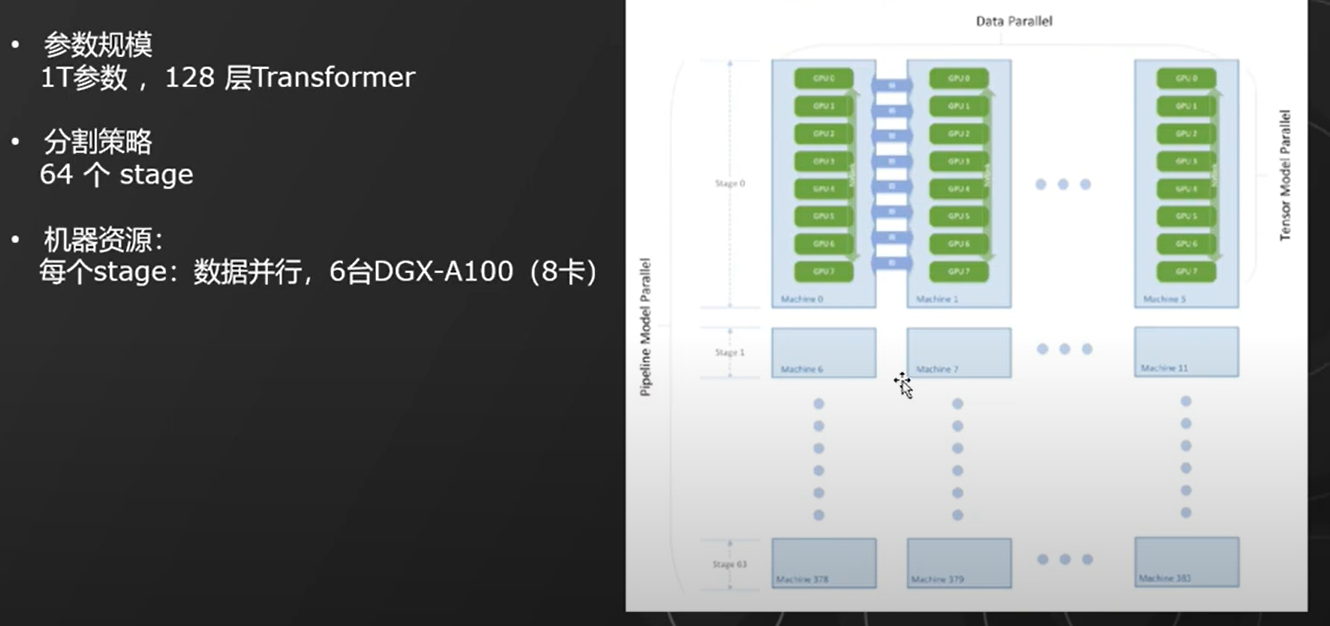
12. 工程化实现
13. 不要搞知识图谱


总结
心得: 大模型的训练耗时,耗钱,耗心神,创业公司应该结合大模型进行实际的业务开发和应用,从头开始训练自己的大模型完全没有意义的。所以很多搞知识付费的公司将会很快消亡进而被 AI 生成内容替代。
面向未来,而不是沉浸死亡。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号