MySQL之JOIN算法
在MySQL8.0.18之前,使用嵌套循环算法或其变体执行表之间的连接操作,MySQL 8.0.18 开始,优化器会尽可能地使用哈希连接算法
一般把 join 前的表叫做左表、外表或者驱动表,join 后的表叫做右表、内表或者被驱动表。
Nested-Loop Join
https://dev.mysql.com/doc/refman/8.0/en/nested-loop-joins.html
Nested-Loop Join 意为嵌套循环连接,简称NLJ。简单的嵌套循环连接算法一次从循环中的第一个表中读取一行,将每一行传递到嵌套循环中,该循环处理连接中的下一个表。此过程重复多次,直到最后要连接的表为止。
例如:查询每个班级的班主任信息及其所教课程信息
mysql> mysql> EXPLAIN SELECT * FROM classes c LEFT JOIN teachers t ON c.head_teacher_id = t.teacher_id LEFT JOIN courses c1 ON t.teacher_id = c1.teacher_id;
+----+-------------+-------+------------+--------+---------------+---------+---------+--------------------------------------+------+----------+--------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+---------------+---------+---------+--------------------------------------+------+----------+--------------------------------------------+
| 1 | SIMPLE | c | NULL | ALL | NULL | NULL | NULL | NULL | 5 | 100.00 | NULL |
| 1 | SIMPLE | t | NULL | eq_ref | PRIMARY | PRIMARY | 4 | student_management.c.head_teacher_id | 1 | 100.00 | NULL |
| 1 | SIMPLE | c1 | NULL | ALL | NULL | NULL | NULL | NULL | 5 | 100.00 | Using where; Using join buffer (hash join) |
+----+-------------+-------+------------+--------+---------------+---------+---------+--------------------------------------+------+----------+--------------------------------------------+
3 rows in set, 1 warning (0.00 sec)
3张表的join类型分别为c(ALL),t(eq_ref), c1(ALL)。下面是这条 sql 使用 NLJ 算法的伪代码过程:
// 从最开始进行连接的表开始,首先筛选classes表要参与join的行
// 这里没有对classes表加where条件,所以是classes表的所有数据
for each row in classes matching range {
// 将teachers表与classes表的每行根据join条件进行匹配
for each row in teachers matching reference key {
// 最后与courses表的每行根据join条件进行匹配
for each row in courses {
// 匹配成功,将该行发送到客户端
}
}
}
NLJ 算法每次将一行从外循环传递到内循环,所以它通常会多次读取内循环中处理的表。
Block Nested-Loop Join
https://dev.mysql.com/doc/refman/8.0/en/nested-loop-joins.html
Block Nested-Loop Join 意为块嵌套循环连接算法,简称BNL。它使用缓冲在外循环中读取的行来减少必须读取内循环中的表的次数。例如,如果将 10 行读入缓冲区并将缓冲区传递到下一个内循环,则可以将内循环中读取的每一行与缓冲区中的所有 10 行进行比较。这将必须读取内表的次数减少了一个数量级。
对于前面描述的 NLJ 算法的示例,使用连接缓冲进行连接如下:
for each row in t1 matching range {
for each row in t2 matching reference key {
// 存进join buffer
store used columns from t1, t2 in join buffer
// 缓冲区满了
if buffer is full {
// 读取 t3 表进行比较
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions, send to client
}
}
// 清空缓冲区
}
}
}
// 考虑到可能缓冲区没满,外层循环就结束了,所以这里再扫描一次 t3 表进行匹配
if buffer is not empty {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions, send to client
}
}
}
MySQL 会为每个可缓冲的连接分配一个缓冲区,因此可以使用多个连接缓冲区来处理给定的查询。在执行连接之前分配一个连接缓冲区,并在查询完成后释放连接缓冲区的内存。
块嵌套循环 join 算法可以减少外层循环次数,从而提高效率
假设外层有10条数据,内表如果有3条数据。因为这是全表扫描, 扫描内表是不会把数据查到缓存的,下一次扫描还是会去查io, 本来是要扫描外表数据集次数, 但是现在一次拿10条去扫描内表, 内表扫描一次就验证了10条数据,扫描次数就变为原来的10分之一, 这里的内表扫描次数是指去扫描内表的次数,而不是内表遍历的行数, 内表遍历一个周期算一次。
join_buffer_size
join_buffer_size 系统变量确定用于处理查询的每个连接缓冲区的大小
mysql> SHOW VARIABLES LIKE 'join_buffer_size';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| join_buffer_size | 262144 |
+------------------+--------+
1 row in set (0.00 sec)
假设S时t1,t2在join buffer中的大小,C是缓冲区中组合的数量,则t3表扫描的次数为(S * C) / join_buffer_size + 1,t3 扫描的次数随着 join_buffer_size 值的增加而减少,直到 join_buffer_size 大到足以容纳所有先前的行组合。此时,将其增大不会提高速度。
使用场景
使用 join buffer 的情况有以下几种
- 连接类型为 ALL
- 连接类型为 index,即没有可能的索引可用,并且分别对数据或索引行进行完整扫描时
- 连接类型为 range 时
缓冲的使用也适用于外连接:https://dev.mysql.com/doc/refman/8.0/en/bnl-bka-optimization.html
MySQL 不会为第一个非常量表分配连接缓冲区,即使其类型为 ALL 或index。只有与连接相关的列才会存储在其连接缓冲区中,而不是整行数据
在 MySQL 8.0.18 之前,当无法使用索引时,此算法适用于等值连接;在 MySQL 8.0.18 及更高版本中,在这种情况下采用hash join优化。从 MySQL 8.0.20 开始,MySQL 不再使用块嵌套循环,并且在所有以前使用块嵌套循环的情况下都采用hash join。
Hash join
https://dev.mysql.com/doc/refman/8.0/en/hash-joins.html
Hash Join 通常用于执行涉及较大数据集的连接操作。它特别适合在没有索引的情况下,对大表进行高效的连接操作。其基本思想是通过构建哈希表来加速连接操作
Hash Join 通常分为两个阶段:
- 构建阶段 (Build Phase):数据库从较小的表(称为inner table)中读取数据,并使用连接的key构建一个哈希表。连接的key通常是表中要参与连接的列。在这个过程中,每条记录的该列的值会被作为哈希表的key,记录自身作为value存储在哈希表中。
- 探测阶段 (Probe Phase):数据库扫描另一个较大的表(称为outer table),对于每一条记录,根据连接的key计算出哈希值,然后在之前构建的哈希表中查找匹配项。如果在哈希表中找到匹配的记录,则这两条记录就满足连接条件,结果将会被返回。
假设有这么一条sql:查询所有班级及其班主任信息
SELECT class_id, class_name, teacher_name
FROM classes JOIN teachers ON classes.head_teacher_id = teachers.teacher_id;
下面是使用Hash join的两个阶段:
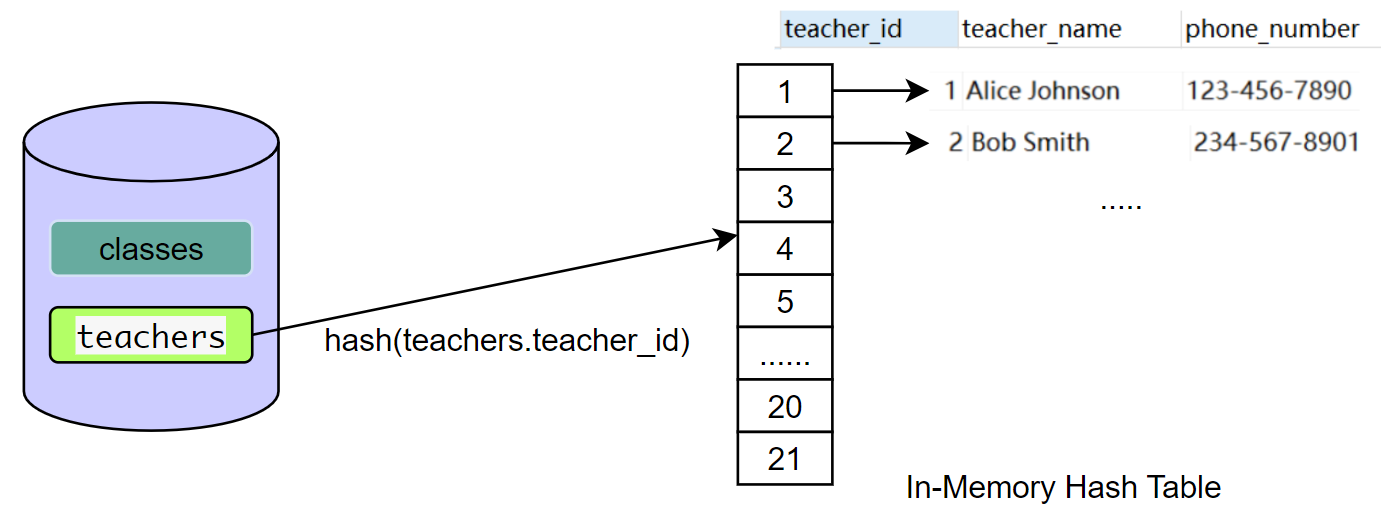
-
构建阶段
对teachers表构建hash表
![在这里插入图片描述]()
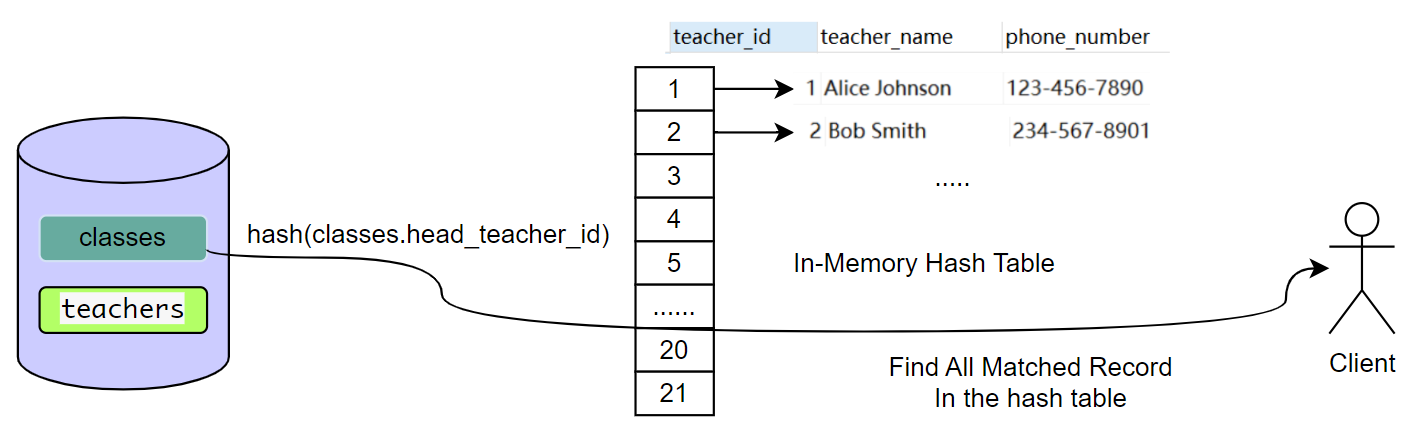
PS: 这里使用的是 teacher_id 作为 hash 的key,由于主键唯一,不会有hash碰撞,如果发生 hash 冲突,实际上也是使用链地址法来解决的,这里图上没画出来。 -
探测阶段
扫描班级表,通hash映射后的 teacher_id 进行匹配
![在这里插入图片描述]()
使用案例
假设现在有3张表
CREATE TABLE t1 (c1 INT, c2 INT);
CREATE TABLE t2 (c1 INT, c2 INT);
CREATE TABLE t3 (c1 INT, c2 INT);
默认情况下,MySQL(8.0.18 及更高版本)会尽可能使用hash join。从 MySQL 8.0.18 开始,MySQL 对任何查询都采用哈希连接,其中每个连接都有等值连接条件,并且没有可应用于任何连接条件的索引,例如这个:SELECT * FROM t1 JOIN t2 ON t1.c1=t2.c1;在MySQL 8.0.17和MySQL 8.0.26版本执行计划如下图所示
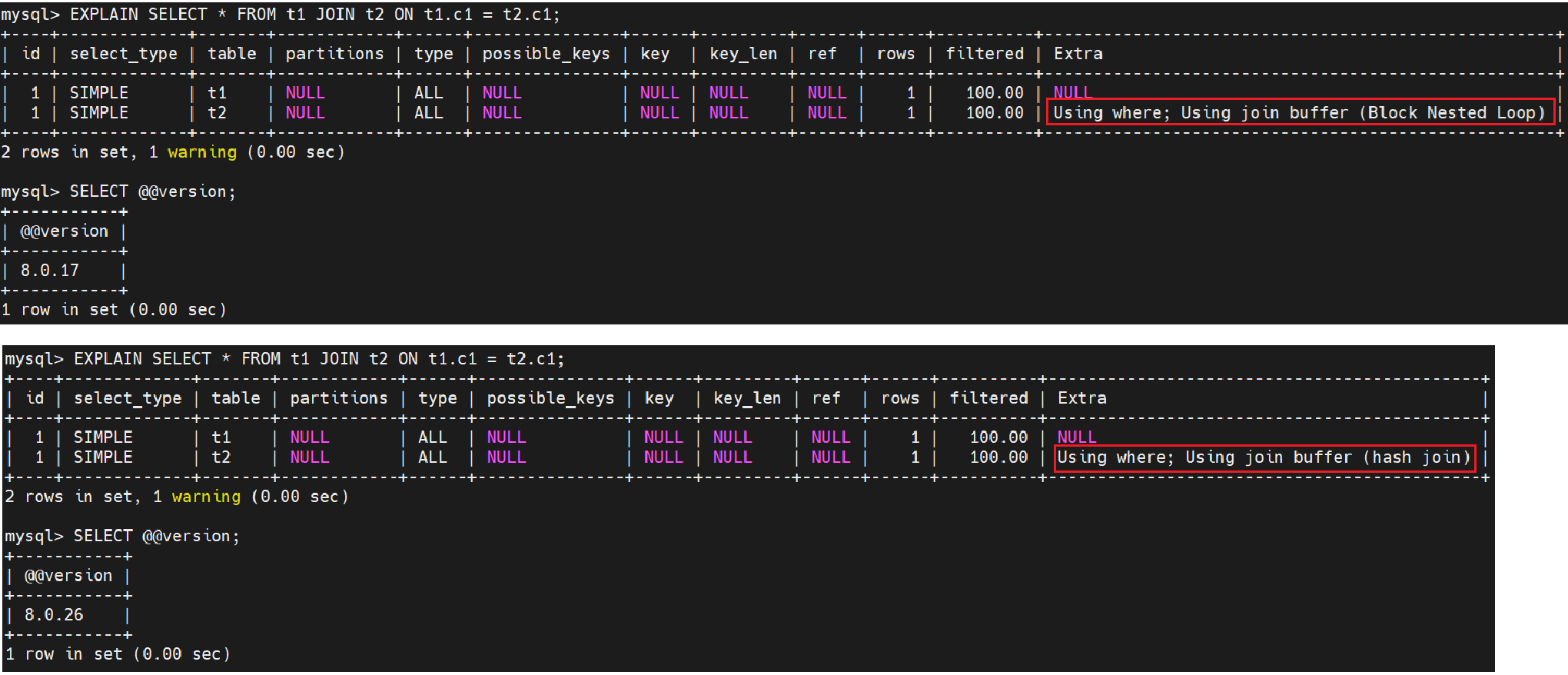
哈希连接通常比以前版本的 MySQL 中使用的块嵌套循环算法更快,并且旨在在这种情况下使用哈希连接来代替块嵌套循环算法。从 MySQL 8.0.20 开始,对块嵌套循环的支持被删除,并且服务器在以前使用块嵌套循环的地方都使用哈希连接。
在 MySQL 8.0.20 之前,必须包含 FORMAT=TREE 选项才能查看给定连接是否使用了哈希连接
涉及多个连接的查询,只要每对表至少有一个连接条件是等值连接
EXPLAIN FORMAT=TREE
SELECT * FROM t1
JOIN t2 ON (t1.c1 = t2.c1 AND t1.c2 < t2.c2)
JOIN t3 ON (t2.c1 = t3.c1)\G;
查询计划如下所示:
mysql> EXPLAIN FORMAT=TREE
-> SELECT * FROM t1
-> JOIN t2 ON (t1.c1 = t2.c1 AND t1.c2 < t2.c2)
-> JOIN t3 ON (t2.c1 = t3.c1)\G;
*************************** 1. row ***************************
EXPLAIN: -> Inner hash join (t3.c1 = t1.c1) (cost=1.05 rows=1)
-> Table scan on t3 (cost=0.35 rows=1)
-> Hash
-> Filter: (t1.c2 < t2.c2) (cost=0.70 rows=1)
-> Inner hash join (t2.c1 = t1.c1) (cost=0.70 rows=1)
-> Table scan on t2 (cost=0.35 rows=1)
-> Hash
-> Table scan on t1 (cost=0.35 rows=1)
1 row in set (0.00 sec)
在 MySQL 8.0.20 之前,如果任何一对连接表没有至少一个等值连接条件,则无法使用哈希连接,而是采用较慢的块嵌套循环算法。在 MySQL 8.0.20 及更高版本中会在这种情况下使用哈希连接,如下所示:
默认情况下,MySQL 8.0.18 及更高版本会尽可能使用哈希连接。可以使用 BNL 和 NO_BNL 这两个优化器提示之一来控制是否使用哈希连接。
优化器参数设置
MySQL 8.0.18 支持 hash_join=on 或者 hash_join=off 作为 optimizer_switch 这个变量的一部分,也可以使用HASH_JOIN或者NO_HASH_JOIN这两个optimizer hint来暗示优化器使用hash join。但是MySQL 8.0.19及以后,这些参数不再起作用
可以通过SHOW VARIABLES LIKE 'optimizer_switch';查看optimizer_switch变量的值
mysql> SHOW VARIABLES LIKE 'optimizer_switch'\G;
*************************** 1. row ***************************
Variable_name: optimizer_switch
Value: index_merge=on,index_merge_union=on,
index_merge_sort_union=on,index_merge_intersection=on,
engine_condition_pushdown=on,index_condition_pushdown=on,
mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,
materialization=on,semijoin=on,loosescan=on,firstmatch=on,
duplicateweedout=on,subquery_materialization_cost_based=on,
use_index_extensions=on,condition_fanout_filter=on,
derived_merge=on,use_invisible_indexes=off,
skip_scan=on,hash_join=on,subquery_to_derived=off,
prefer_ordering_index=on,hypergraph_optimizer=off,
derived_condition_pushdown=on
1 row in set (0.01 sec)
Semijoin
https://dev.mysql.com/doc/refman/8.0/en/semijoins.html
Semijoin 意为半连接,是针对子查询场景的一种优化策略,优化器使用半连接策略来改进子查询执行。应用 Semijoin 时,它只返回其中左表中的行,这些行在右表中具有匹配的记录。与常规联接不同,包含两个表中匹配行,而 Semijoin 仅在结果中包含左表中的列。
列出有学生的班级
SELECT class.class_num, class.class_name
FROM class
INNER JOIN roster
WHERE class.class_num = roster.class_num;
这个sql会有重复的结果
可能会想到用DISTINCT来取重,但这样效率比较低,因为必须先产生带重复值的结果集,然后才能进行去重
可以将其转换为子查询来做
SELECT class_num, class_name FROM class
WHERE class_num IN (SELECT class_num FROM roster);
在这种情况下,优化器可以识别出IN子句要求子查询只返回 roster 表中每个 class_num 的一个,因为 class_num 是主键唯一的。在这种情况下,查询可以使用半连接;也就是说,一个只返回 class 中与 roster 中的行匹配的每一行的一个实例的操作。
SELECT class_num, class_name
FROM class
WHERE EXISTS
(SELECT * FROM roster WHERE class.class_num = roster.class_num);
限制条件
在MySQL 8.0.16及更高版本中,任何具有EXISTS子查询判断的语句都会进行与具有等效In子查询判断语句相同的Semijoin转换。
在MySQL中,子查询必须满足这些条件才能作为半连接处理(或者,在MySQL 8.0.17及更高版本中,如果不修改子查询,则使用反连接):
- 在 WHERE 或者 ON 条件的最外层,必须是IN, = ANY,或者 EXISTS 等条件判断类型,例如
SELECT ...
FROM ot1, ...
WHERE (oe1, ...) IN
(SELECT ie1, ... FROM it1, ... WHERE ...);
在 MySQL 8.0.17 及以后, 子查询也可以是被 NOT,IS [NOT] TRUE或者 IS [NOT] FALSE 等修改过的表达式参数
-
查询没有UNION,不包含HAVING子句,不包含任何聚合函数,没有LIMIT子句,这4个是独立的条件,任意一个都可能导致不使用半连接
-
外部查询中没有使用STRAIGHT_JOIN
-
外部表和内部表的总数必须小于 join 操作中允许的最大表数量
-
子查询可以是相关子查询,也可以是不相关子查询。在 MySQL 8.0.16 及其以后, 去相关性会着眼于于用作
EXISTS参数的子查询的WHERE子句中的相关性强的条件,并使其可以优化,就像使用IN (SELECT b FROM…)一样。这里的相关性强指查询条件使用的是等值条件,并且这个条件是唯一的WHERE条件,或者是使用AND进行组合的条件,并且此条件使用的列其中一个是子查询中的表的列,而其他的是外部表中被查询的列。 -
DISTINCT关键字是允许的,但会被忽略。半连接策略自动处理重复删除
-
GROUP BY子句是允许的,但会被忽略,除非子查询还包含一个或多个聚合函数
-
ORDER BY子句是允许的,但会被忽略,因为排序与半连接策略的评估无关
半连接执行策略
Semijoin是一种准备时转换,它支持多种执行策略,如Table pullout、Duplicate Weedout、FirstMatch、LooseScan和Materialization。如果子查询满足 Semijoin 的限制条件,MySQL会将其转换为半连接(或者,在MySQL 8.0.17或更高版本中,如果适用,则转换为反连接),并从执行策略中做出基于成本的选择。
-
Table pullout
将子查询转换为连接查询,或使用 table pullout 策略将查询作为子查询表和外部表之间的内部连接运行。Table pullout 策略会将表从子查询拉到外部查询。可以通过SHOW WARNINGS查看具体转换后的sql语句 -
Duplicate Weedout
这种策略会将 Semijoin 当作普通的 join 运行,并使用临时表删除重复记录 -
FirstMatch
在扫描子查询的内部表中的行组合时,如果给定值组有多个实例,只选择一个而不是全部返回。这种方式扫描并消除了不必要行的产生。 -
LooseScan
使用索引扫描子查询表,该索引允许从每个子查询的值组中选择单个值。 -
将子查询转换为一个索引号的临时表,用于执行join操作,该索引用于移除重复项。如果临时表与外部表有连接操作,这个索引也可能用于加速查找;如果没有,则会扫描该临时表。关于物化操作,参考:Section 10.2.2.2, “Optimizing Subqueries with Materialization”.
优化器参数设置
https://dev.mysql.com/doc/refman/8.0/en/switchable-optimizations.html
semijoin 这个标志控制是否使用半连接。从MySQL 8.0.17开始,这个标志同时也会控制是否使用反连接。

如果semijoin为on,那么firstmatch、loosescan、duplicateweedout 和 materialization这几个标志可以控制semijoin使用的执行策略
如果duplicateweedout为off(表示禁用Duplicate weedout这个半连接策略),及时在应该使用Duplicate weedout这个半连接策略的场景也不会使用它,除非所有其他适用的策略都被禁用了才会使用它
如何验证
EXPLAIN 输出会指示半连接策略的使用,如下所示:以下面这条sql为例
EXPLAIN SELECT class_num, class_name FROM class
WHERE class_num IN (SELECT class_num FROM roster);
通过EXPLAIN的扩展信息,可以看到使用了Semijoin转换
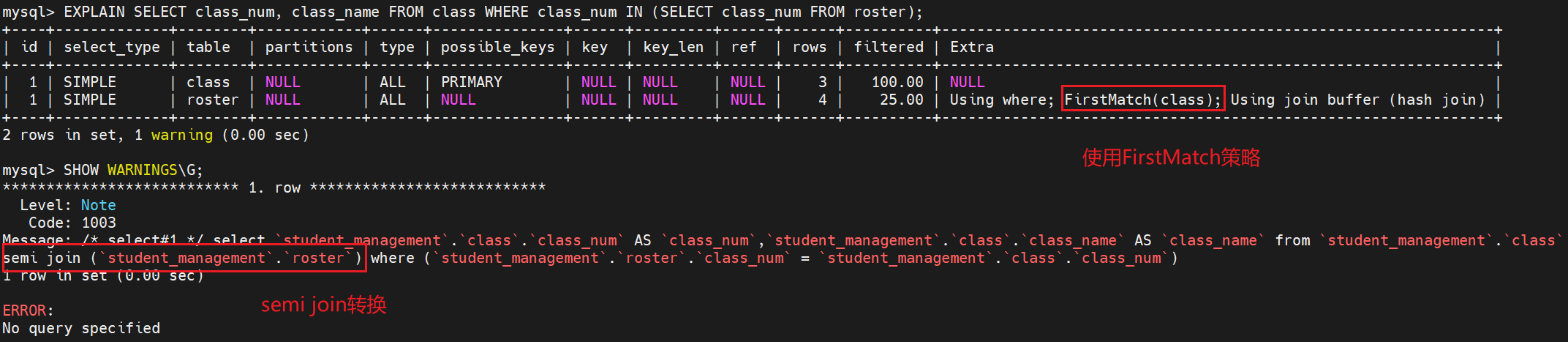
如果将子查询转换为半连接,应该可以看到子查询条件会消失,其子查询的表和 WHERE 子句会合并到外部查询的连接列表和 WHERE 子句中。
下面是一些使用 Semijoin 的场景的执行计划解释,可以通过执行计划来查看是否使用了 Semijoin 以及什么场景下使用 Semijoin
Extra列出现 Start temporary,End temporary
表示使用了临时表,未被 Table pulled 的表,且位于Start temporary和End temporary覆盖的EXPLAIN输出行范围内的表,其 rowid 会位于临时表中。
Extra 列出现 FirstMatch(tbl_name)
表示使用了 FirstMatch 这个策略,tbl_name 表示左表,例如:

Extra 列出现 LooseScan(m..n)
表示使用了 LooseScan 这个策略,m 和 n 是使用的索引部分
Temporary table use for materialization
如果 select_type 值是 MATERIALIZED ,并且 rows 值是 <subqueryN> ,表示使用了临时表的物化操作
使用场景
MySQL 8.0.21 及其以后,半连接转换也可以应用于使用了 [NOT] IN 或 [NOT] EXISTS 子查询条件的单个表的 UPDATE 或 DELETE 语句,前提是该语句不使用 ORDER BY 或 LIMIT,并且优化器提示或优化器optimizer_switch变量设置为允许半连接转换。
Anti-Join
Anti-Join 意为反连接。应用反连接时,它返回一个表中的行,而另一个相关表中没有匹配的记录。这与半连接是完全相反的。
举个例子:查没有学生登记的班级
SELECT class_num, class_name
FROM class
WHERE class_num NOT IN (SELECT class_num FROM roster);
此查询在内部重写为antijoin形式:SELECT class_num、class_name FROM class antijoin roster ON class_num,它返回 class 中与 roster 中任何行都不匹配的每一行的一个结果。这意味着,对于 class 中的每一行,一旦在 roster 中找到匹配项,就可以丢弃类中的行。
如果所比较的表达式可以为空,则在大多数情况下无法应用反连接转换。此规则的一个例外是(…NOT IN (SELECT…)) IS NOT FALSE,其等价物(…IN (SELECT)) IS NOT TRUE可以转换为反连接。
Semi-join 和 Anti-Join 对比
反连接根据另一个表中不存在匹配项过滤行,而半连接根据相关记录的存在过滤行,但只返回第一个表中的列。两者都仅仅只返回左表中的行,半连接返回左表中与右表匹配的行,而反连接返回右表中与左表不匹配的行。下面是两者的一些指标对比:
| Semi-join | Anti-Join | |
|---|---|---|
| 目的 | 查询左表在右表中匹配的数据 | 其目的是从左表中检索记录,右表中有相应的匹配记录 |
| 结果 | 结果包括两个表中的匹配记录 | 结果排除了两个表中的匹配记录 |
| 实现方式 | 使用INNER JOIN,EXISTS子查询或者IN | 使用 LEFT JOIN或者NOT EXISTS子查询 |
| 用途 | 用于查找两个集合之间的共同元素 | 用于识别一个集合中唯一而不存在于另一个集合的元素 |
| 例子 | Selecting customers who placed orders. | Selecting customers who haven’t placed any orders. |
使用场景
MySQL 8.0.17及其以后,下面的子查询会被转化为 antijoin:
- NOT IN (SELECT ... FROM ...)
- NOT EXISTS (SELECT ... FROM ...).
- IN (SELECT ... FROM ...) IS NOT TRUE
- EXISTS (SELECT ... FROM ...) IS NOT TRUE.
- IN (SELECT ... FROM ...) IS FALSE
- EXISTS (SELECT ... FROM ...) IS FALSE.
简单来说,任何 IN (SELECT ... FROM ...) 或者 EXISTS (SELECT ... FROM ...) 形式的子查询的反过来的形式就会被转换成 antijoin。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号