Hive环境搭建
Apache Hive
Apache Hive 是一个数据仓库基础设施,构建在 Hadoop 上,用于数据的查询和分析。使用 Java 语言开发,开源在Github: https://github.com/apache/hive。 由于 Hive 构建在 Hadoop 生态系统之上,它利用了 Hadoop 的分布式计算和存储能力,因此 Java 作为 Hadoop 的主要语言,使 Hive 能够与 Hadoop 无缝集成。它提供了一种类 SQL 的查询语言(HiveQL),使用户能够以更直观的方式处理存储在 Hadoop 分布式文件系统(HDFS)中的大规模数据集。
主要特点
- 类SQL语法:HiveQL 提供类似 SQL 的语法,使得熟悉 SQL 的用户可以轻松上手。
- 数据存储:Hive 支持多种数据存储格式,如文本文件、ORC、Parquet 等,用户可以根据需求选择适合的格式。
- 扩展性:Hive 允许用户定义自定义函数(UDF),以扩展其查询能力。
- 分区和桶:Hive 支持对数据进行分区和桶化,以优化查询性能。
- 与 Hadoop 集成:Hive 与 Hadoop 紧密集成,可以利用 Hadoop 的分布式计算能力处理海量数据。
适用场景
- 数据分析:适合进行大规模数据的批量处理和分析。
- 数据仓库:用于构建数据仓库,支持数据的整理、查询和报表生成。
- ETL 过程:可以用于提取、转换和加载(ETL)数据。
工作原理
- 数据存储:用户将数据存储在 Hadoop 的 HDFS 中。
- 元数据管理:Hive 使用一个元数据库存储表结构、分区信息等元数据。
- 查询执行:当用户提交 HiveQL 查询时,Hive 将其转换为 MapReduce、Tez 或 Spark 任务,并在 Hadoop 集群上执行。
其他相关技术
Hive 使用 Apache Thrift 支持多种语言的客户端接口,包括 Python、C++、Ruby 等,允许开发者使用不同的编程语言与 Hive 进行交互。
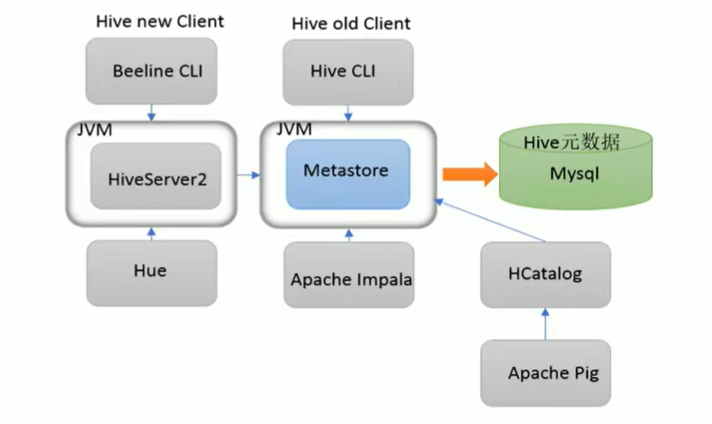
Hive MetaStore
https://hive.apache.org/docs/latest/adminmanual-metastore-administration_27362076/#introduction
Hive 的数据库、表、函数等这些元数据都存储在Metastore 组件中 。 根据系统配置方式,统计信息和授权记录也可以存储在此处。 Hive 或者其他执行引擎在运行时使用此数据来确定如何解析,授权以及有效执行用户查询。
部署模式
- 嵌入模式:在当前目录生成嵌入式的derby数据库存储元数据
- 本地模式:需要安装数据库MySQL来存储元数据,但是不需要配置启动Metastore服务。
- 远程模式:需要安装MySQL来存储Hive元数据,需要手动单独配置启动Metastore服务。
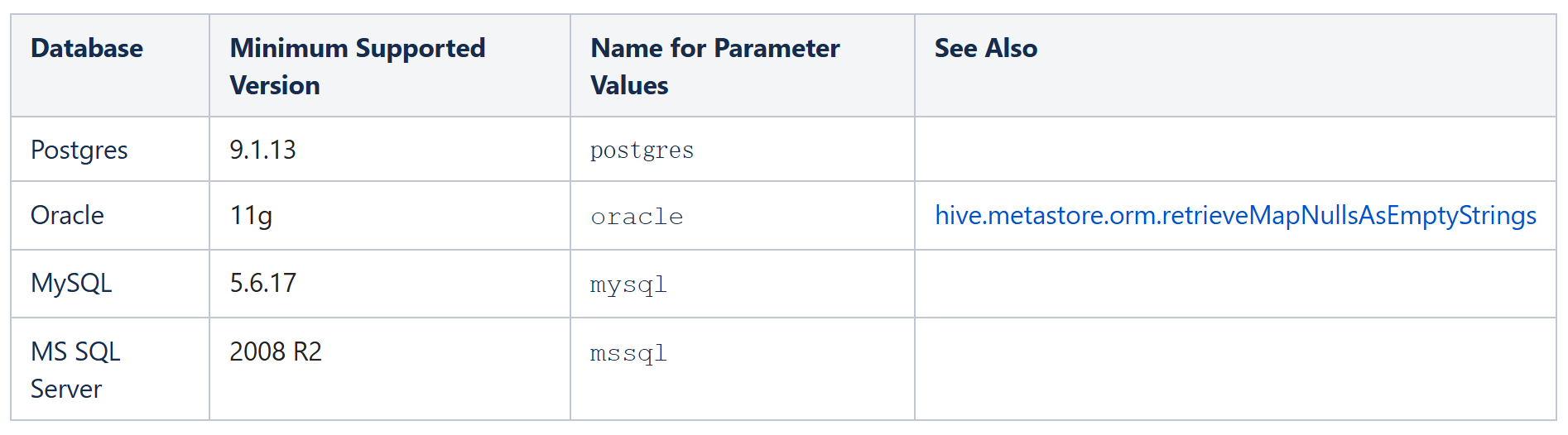
本地的嵌入式数据库无法支持多个请求同时访问,所以生产环境中一般存储元数据采用独立的关系型数据库而非Hive本地的嵌入式数据库。具体的支持列表参考官方文档:
https://cwiki.apache.org/confluence/display/Hive/AdminManual+Metastore+Administration#AdminManualMetastoreAdministration-SupportedBackendDatabasesforMetastore
下载及安装
注意与Hadoop的版本兼容性,一般 Hadoop3.x 版本建议用 Hive3.x 版本即可。更准确一点可以下载Hive源码,从源码中的pom.xml文件中可以找到到该版本兼容的hadoop版本。
下载
下载地址:https://archive.apache.org/dist/hive/。这里我下载3.1.2版本:apache-hive-3.1.2-bin.tar.gz
下载慢的话,可以从下面两个镜像地址下载:
如果在Windows上安装的话,因为bin.tar.gz里比较新的版本不包含Windows上的一些cmd脚本,而src.tar.gz包里有。虽然可以将sh脚本翻译为cmd脚本,但是比较麻烦而且不保证正确性。另外,也不是所有版本的 src.tar.gz 包里都有这些cmd脚本,hive-1.2.2/和hive-2.1.1这两个版本是有的,所以额外下载 apache-hive-2.1.1-src.tar.gz 这个源码包,下载解压之后将里面的脚本其复制到 bin.tar.gz 解压后的目录里,后续可以用到。
安装
下载后进行离线安装
- 解压
tar -xzvf apache-hive-3.1.2-bin.tar.gz
cd apache-hive-3.1.2-bin
- 添加下面的环境变量,然后使其生效
# Apache Hive
export HIVE_HOME=/root/develop/hive/apache-hive-3.1.2-bin
export PATH=$HIVE_HOME/bin:$PATH
source /etc/profile
- Hive使用Hadoop,必须安装Haddop,并且需配置环境变量
HADOOP_HOME指向Hadoop安装位置,并确保HDFS上存在下面两个目录:/tmp和/user/hive/warehouse
cd $HADOOP_HOME
./bin/hadoop fs -mkdir /tmp
./bin/hadoop fs -mkdir /user/hive/warehouse
./bin/hadoop fs -chmod g+w /tmp
./bin/hadoop fs -chmod g+w /user/hive/warehouse
- 设置Hive环境变量HIVE_HOME:
export HIVE_HOME=<hive安装路径>
配置和启动Hive
创建Hive的配置文件,在$HIVE_HOME/conf目录下已经有对应的配置文件模板,需要重命名,建议复制,保留原始配置文件。具体如下:
$HIVE_HOME/conf/hive-default.xml.template => $HIVE_HOME/conf/hive-site.xml
$HIVE_HOME/conf/hive-env.sh.template => $HIVE_HOME/conf/hive-env.sh
$HIVE_HOME/conf/hive-exec-log4j.properties.template => $HIVE_HOME/conf/hive-exec-log4j.properties
$HIVE_HOME/conf/hive-log4j.properties.template => $HIVE_HOME/conf/hive-log4j.properties
修改hive-env.sh脚本,在尾部添加下面内容,具体的变量值需要手动进行替换
export HADOOP_HOME=$HADOOP_HOME
export HIVE_CONF_DIR=$HIVE_HOME\conf
export HIVE_AUX_JARS_PATH=$HIVE_HOME\lib
接下来修改$HIVE_HOME/conf/hive-site.xml配置文件:
hive-site.xml是从hive-default.xml.template直接复制过来,原来的文件里面有一些配置默认是derby的,所以修改成mysql的时候要特别注意。
| 属性名 | 属性值 | 备注 |
|---|---|---|
| hive.metastore.warehouse.dir | /user/hive/warehouse | Hive的数据存储目录,这个是默认值 |
| hive.exec.scratchdir | /tmp/hive | Hive的临时数据目录,这个是默认值 |
| javax.jdo.option.ConnectionURL | jdbc:mysql://localhost:3306/hive?characterEncoding=UTF-8&serverTimezone=UTC | Hive元数据存放的数据库连接 |
| javax.jdo.option.ConnectionDriverName | com.mysql.cj.jdbc.Driver | Hive元数据存放的数据库驱动 |
| javax.jdo.option.ConnectionUserName | root | Hive元数据存放的数据库用户 |
| javax.jdo.option.ConnectionPassword | 123456 | Hive元数据存放的数据库密码 |
| hive.metastore.db.type | mysql | Hive元数据存放的数据库类型 |
| hive.exec.local.scratchdir | $HIVE_HOME\data\scratchDir | 创建本地目录$HIVE_HOME/data/scratchDir |
| hive.downloaded.resources.dir | $HIVE_HOME\data\resourcesDir | 创建本地目录$HIVE_HOME/data/resourcesDir |
| hive.querylog.location | $HIVE_HOME\data\querylogDir | 创建本地目录$HIVE_HOME/data/querylogDir |
| hive.server2.logging.operation.log.location | $HIVE_HOME\data\operationDir | 创建本地目录$HIVE_HOME/data/operationDir |
| hive.metastore.schema.verification | false | 可选 |
| hive.server2.enable.doAs | false | 不加会遇到『user root cannot impersonate anonymous』,则要等待重连 |
相关配置内容如下:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.65.130:3306/hive?createDatabaseIfNotExist=true&serverTimezone=Asia/Shanghai</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>coreqiwithhs</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>system:user.name</name>
<value>root</value>
</property>
</configuration>
修改完毕之后,在配置的MySQL连接串对应的机器上新建一个数据库hive,编码和字符集可以选用范围比较大的utf8mb4
初始化元数据库,注:需要保证Hadoop集群是开启状态
Hive2.1开始,需要执行schematool进行初始化,这里数据库类型指定为mysql。Windows下注意是执行schematool.cmd(在ext目录下)
$HIVE_HOME/bin/schematool -dbType mysql -initSchema -verbose
# Windows下
cd $HIVE_HOME/bin
./hive.cmd --service schematool -dbType mysql -initSchema --verbose
命令执行完,看到下面的信息就算成功了
beeline> Initialization script completed
schemaTool completed
需要确保相关的驱动jar包放到$HIVE_HOME/lib目录下,以及确保数据库创建好
部署MetaStore服务
Hive可以启动一个叫做MetaStore的服务,该服务在Hive的客户端启动,用户通过客户端连接到MetaStore,然后和一个用于存储Hive的元数据信息的数据库进行通信。
修改$HIVE/conf/hive-site.xml配置文件,配置Hive MetaStore服务监听的端口
<property>
<name>hive.metastore.port</name>
<value>9083</value>
<description>Hive metastore listener port</description>
</property>
启动MetaStore服务:
# 这种方式会阻塞当前终端
$HIVE_HOME/bin/hive --service metastore -p 9083
# 以后台进程方式启动, 启动日志在当前目录的nohup.out文件里
nohup $HIVE_HOME/bin/hive --service metastore -p 9083 &
# 启动debug日志
$HIVE_HOME/bin/hive --service metastore -p 9083 --hiveconf hive.root.logger=DEBUG,console
使用netstat或者ps查看metastore服务是否起来
netstat -anp | grep 9083
ps -ef | grep metastore
# 或者通过jps可以看到RunJar的一个JVM进程
1067964 RunJar
HiveServer2
HiveServer、HiveServer2都是Hive自带的两种服务,HiveServer2是HiveServer的改进版。允许客户端在不启动CLI命令行工具的情况下对Hive中的数据进行操作,且两个都允许远程客户端使用多种编程语言向hive提交请求取回结果。但是,由于HiveServer不能处理多于一个客户端的并发请求,因此在Hive-0.11.0版本中重写了HiveServer代码,因此有了HiveServer2。HiveServer已经被废弃,HiveServer2支持多客户端的并发和身份认证,旨在为开放API客户端如JDBC、ODBC提供更好的支持。
配置文件hive-site.xml中可以修改下面几个关于HiveServer2的常用属性:
| 属性名 | 属性值 | 备注 |
|---|---|---|
| hive.server2.thrift.min.worker.threads | 5 | 最小工作线程数,默认值为5 |
| hive.server2.thrift.max.worker.threads | 500 | 最大工作线程数,默认值为500 |
| hive.server2.thrift.port | 10000 | 侦听的TCP端口号,默认值为10000 |
| hive.server2.thrift.bind.host | 127.0.0.1 | 绑定的主机,默认值为127.0.0.1 |
| hive.execution.engine | mr | 执行引擎,默认值为mr |
通过如下方式启动:./bin/hive --service hiveserver2或者:$HIVE_HOME/bin/hiveserver2
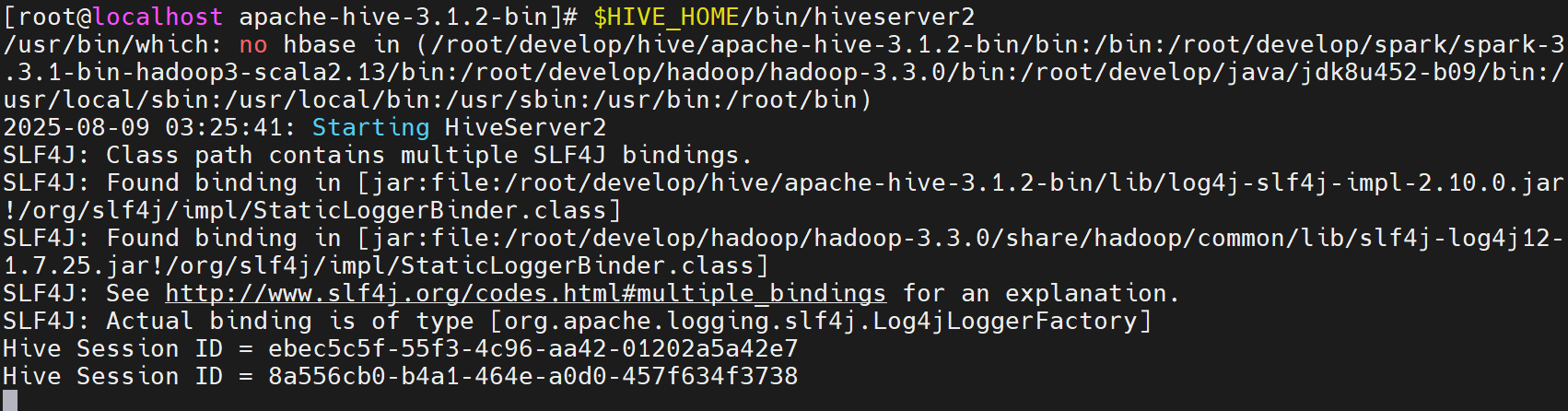
或者后台启动
nohup hive --service hiveserver2 > ./hive.log 2>&1 &
HiveServer2启动后需要等待一段时间才能访问,通过监听的端口查看服务是否启动:
[root@localhost ~]# netstat -ltpn | grep 10000
tcp6 0 0 :::10000 :::* LISTEN 1086634/java
停止HiveServer2 运行可以使用命令:
kill -9 1086634
如果有多个RunJar进程,可以通过使用 jps -ml 来确认目前HiveServer2使用的是哪个MetaStore服务
客户端连接
Hive提供了两个客户端工具:Hive Cli 和 Beeline
Hive Cli
脚本$HIVE_HOME/bin/hive,Hive的客户端命令行工具。主要功能:一是可用于以交互或批处理模式运行Hive查询;二是用于Hive相关服务的启动,比如metastore服务。
Hive Cli是需要通过访问Hive Metastore服务再去访问HiveServer服务的,所以需要配置MetaStore服务地址
如果需要在其他机器上通过bin/hive访问hivemetastore服务,只需要在该机器的hive-site.xml配置中添加metastore服务地址即可。
<property>
<name>hive.metastore.uris</name>
<value>thrift://localhost:9093</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to
remote metastore.</description>
</property>
使用hive覆盖指定配置项
hive --hiveconf hive.metastore.uris=thrift://localhost:9083
也可以使用 hive 命令行工具的 -f 参数来指定配置文件。在命令中使用 --hiveconf 选项来覆盖特定配置。
hive --hiveconf hive.exec.local.scratch.dir=/tmp/hive --hiveconf hive.exec.scratchdir=/tmp/hive
效果就是会启动一个交互式shell,然后可以输入Hive查询命令
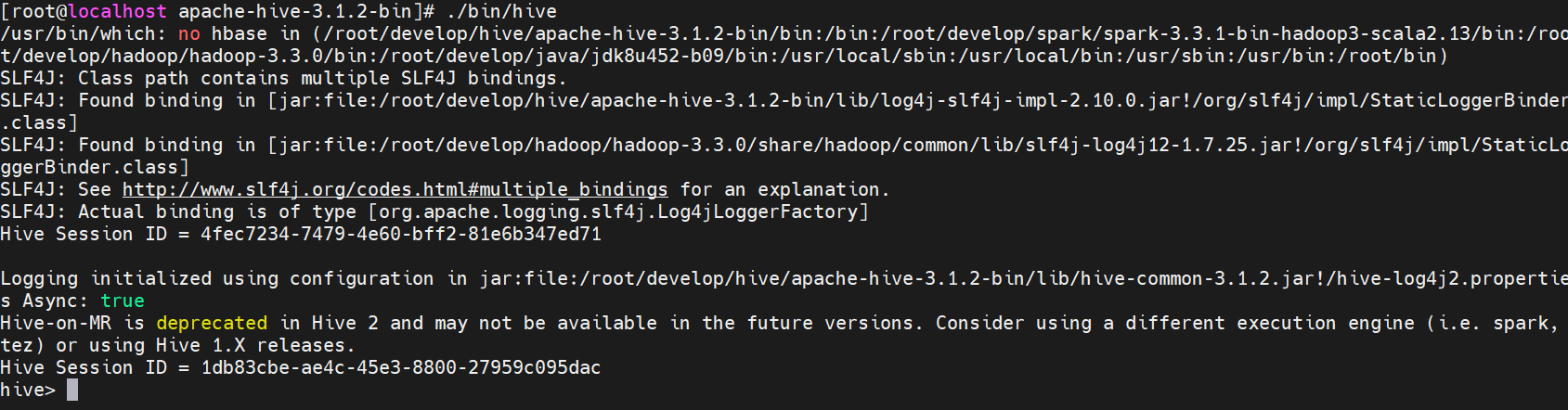
Beeline
HiveServer2也提供了一个命令行工具,叫Beeline。脚本位于$HIVE_HOME/bin/beeline,因此Hive Cli被弃用了。Beeline是一个JDBC客户端,是官方强烈推荐使用的。和Hive Cli相比,性能加强,安全性提高,推荐使用。Beeline客户端不访问MetaStore,直接访问HiveServer2,因此需要先启动HiveServer2。
执行beeline脚本直接进入客户端模式,然后通过输入:! connect jdbc:hive2://localhost:10000 连接HiveServer2
beeline> ! connect jdbc:hive2://localhost:10000
Connecting to jdbc:hive2://localhost:10000
Enter username for jdbc:hive2://localhost:10000: root
Enter password for jdbc:hive2://localhost:10000:
也可以直接通过下面的命令进行连接:
# 如果 HiveServer2 在默认端口(10000)上运行,则可以省略端口号,Beeline 会自动使用它。
$HIVE_HOME/bin/beeline -u jdbc:hive2://$HS2_HOST:$HS2_PORT -n root
例如
beeline -u jdbc:hive2://localhost:10000
# 以root用户登录
beeline -u jdbc:hive2://localhost:10000 -n root
连接成功,会出现下面的信息:
Connecting to jdbc:hive2://localhost:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.2 by Apache Hive
0: jdbc:hive2://localhost:10000>
安装配置脚本
提供一个初始化Hive的配置脚本,需要Python3.12+运行
import os
import xml.etree.ElementTree as ET
# Hive解压目录
hive_install_dir = "/opt/hive"
def rename_hive_config_file(src, dst):
# 读取源文件所有内容,直接写入目标文件(含新名)
with open(hive_install_dir + src, 'rb') as f1, open(hive_install_dir + dst, 'wb') as f2:
f2.write(f1.read())
def config_hive_site(config_xml_path, config_props: dict[str, str] = None, output=None):
if output is None:
output = config_xml_path
# 如果配置文件不存在,则创建新的
if not os.path.exists(config_xml_path):
configuration = ET.Element("configuration")
tree = ET.ElementTree(configuration)
tree.write(output, encoding='utf-8', xml_declaration=True)
if config_props is None:
return
# 解析现有配置文件
parser = ET.XMLParser(target=ET.TreeBuilder(insert_comments=True))
tree = ET.parse(config_xml_path, parser)
root = tree.getroot()
# 添加新的配置项
for prop_name, prop_value in config_props.items():
# 检查是否已存在相同的配置项
config_props = root.findall(f".//property[name='{prop_name}']")
if config_props:
value_node = config_props[0].findall('value')[0]
print(f"updated: {prop_name}: {value_node} -> {prop_value}")
value_node.text = prop_value
else:
# 如果配置项不存在,创建新的
property_el = ET.SubElement(root, "property")
name_el = ET.SubElement(property_el, "name")
name_el.text = prop_name
value_el = ET.SubElement(property_el, "value")
value_el.text = prop_value
print(f"added: {prop_name}: {prop_value}")
ET.indent(tree, space=" ", level=0)
tree.write(output, encoding='utf-8', xml_declaration=True, method="xml")
if __name__ == '__main__':
# 重命名配置文件
rename_hive_config_file("/conf/hive-default.xml.template", "/conf/hive-site.xml")
rename_hive_config_file("/conf/hive-env.sh.template", "/conf/hive-env.sh")
rename_hive_config_file("/conf/hive-log4j2.properties.template", "/conf/hive-log4j2.properties")
# 替换为具体的 Hadoop 和 Hive 路径
HADOOP_HOME = os.getenv('HADOOP_HOME', '/opt/hadoop')
if HADOOP_HOME is None:
print("HADOOP_HOME is not set")
exit(1)
HIVE_HOME = os.getenv('HIVE_HOME')
if HIVE_HOME is None:
print("HIVE_HOME is not set")
exit(1)
os.system(HADOOP_HOME + "/bin/hadoop fs -mkdir /tmp")
os.system(HADOOP_HOME + "/bin/hadoop fs -mkdir /user/hive/warehouse")
os.system(HADOOP_HOME + "/bin/hadoop fs -chmod g+w /tmp")
os.system(HADOOP_HOME + "/bin/hadoop fs -chmod g+w /user/hive/warehouse")
hive_config_xml = os.path.join(HIVE_HOME, "conf", "hive-site.xml")
print("Update Hive config file: hive-site.xml: ", hive_config_xml)
props = {
"javax.jdo.option.ConnectionURL": "jdbc:mysql://localhost:3306/hive?characterEncoding=UTF-8&serverTimezone=UTC",
"javax.jdo.option.ConnectionDriverName": "com.mysql.cj.jdbc.Driver",
"hive.metastore.schema.verification": "false",
"datanucleus.schema.autoCreateAll": "true",
"hive.metastore.warehouse.dir": "/user/hive/warehouse",
"hive.exec.scratchdir": f'{HIVE_HOME}/data/scratchDir',
"hive.querylog.location": f'{HIVE_HOME}/data/querylogDir',
}
config_hive_site(hive_config_xml, props)
os.makedirs(props["hive.exec.scratchdir"], exist_ok=True)
os.makedirs(props["hive.querylog.location"], exist_ok=True)
os.makedirs(os.path.join(HIVE_HOME, 'data', 'resourcesDir'), exist_ok=True)
os.makedirs(os.path.join(HIVE_HOME, 'data', 'operationDir'), exist_ok=True)
问题记录
- 执行$HIVE_HOME/bin/schematool -dbType mysql -initSchema -verbose报错
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
这个错误是因为使用的guava-19.0.jar这个jar包的版本不对,缺少com.google.common.base.Preconditions#checkArgument这个方法
[root@localhost apache-hive-3.1.2-bin]# ll ./lib/ | grep guava
-rw-r--r--. 1 root root 2308517 Sep 26 2018 guava-19.0.jar
-rw-r--r--. 1 root root 971309 May 20 2019 jersey-guava-2.25.1.jar
替换guava这个jar包的版本即可,我这里是替换为guava-22.0.jar这个版本,或者其他合适的版本也可以
- 执行$HIVE_HOME/bin/schematool -dbType mysql -initSchema -verbose报错
Exception in thread "main" java.lang.RuntimeException: com.ctc.wstx.exc.WstxParsingException: Illegal character entity: expansion character (code 0x8
at [row,col,system-id]: [3215,96,"file:/root/develop/hive/apache-hive-3.1.2-bin/conf/hive-site.xml"]
原因是因为hive-site.xml这个xml文件有非法字符,去掉即可

使用VsCode等编辑器打开,可以直观看到红色错误提示非法字符
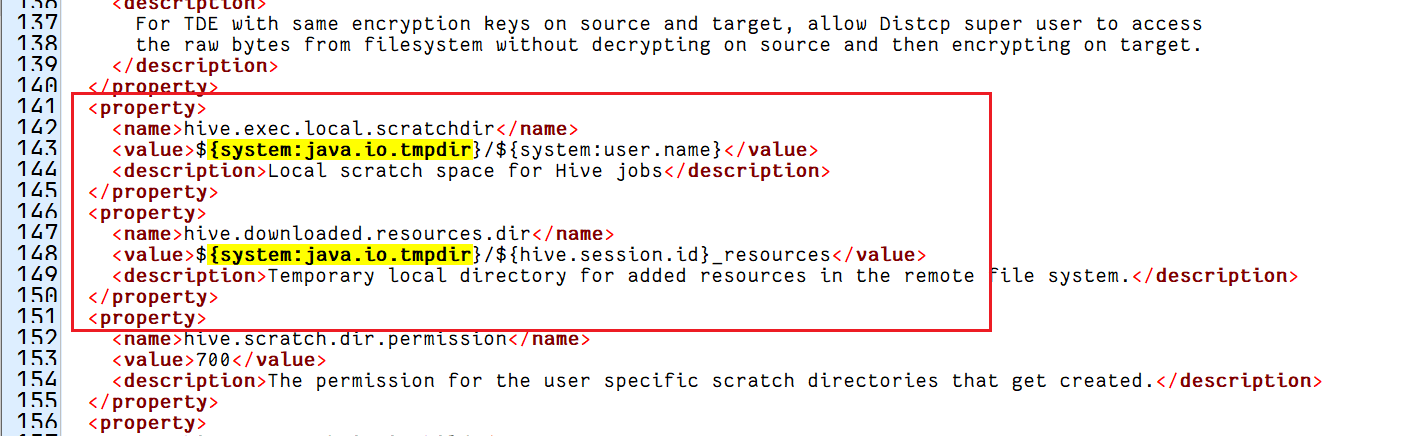
- 执行/bin/hive脚本启动Hive报错:java.net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7
这个报错信息显示是某个路径写法不对, 应该是 Hive 配置文件 hive-site.xml 中配置的,在其中搜一下
配置文件中有挺多地方配了 ${system: } 这种格式的值的,这些值是默认的配置模板文件 hive-default.xml.template 中配好的。和之前的包含特殊字符一样,这又是另一个坑了,模板文件中配好的东西竟然不能直接用。
解决办法是将配置文件中${system:java.io.tmpdir} 这类配置值中的system:去掉,改为 ${java.io.tmpdir}
- 使用beeline连接HiveServer2时报错:
25/08/09 03:30:32 [main]: WARN jdbc.HiveConnection: Failed to connect to localhost:10000
Error: Could not open client transport with JDBC Uri: jdbc:hive2://localhost:10000:
Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException
(org.apache.hadoop.security.authorize.AuthorizationException):
User: root is not allowed to impersonate anonymous (state=08S01,code=0)
Beeline version 3.1.2 by Apache Hive
修改 hadoop 配置文件 etc/hadoop/core-site.xml,加入如下配置项,然后重启hadoop
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
这里配置项名称中root部分为报错的用户名,例如你使用的用户名是xxx,则应该配置的key是hadoop.proxyuser.xxx.hosts和hadoop.proxyuser.xxx.groups
- 如果在beeline输入的语句提示:No current connection
通常表示 Beeline 或 Hive Shell 没有成功连接到 HiveServer2
-
消除slf4j的警告信息:这个是因为hive和hadoop使用的日志实现版本不一致导致的,移除一个就可以了
-
执行命令show databases;报错:Error: java.io.IOException: java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: ${system:user.name%7D (state=,code=0)
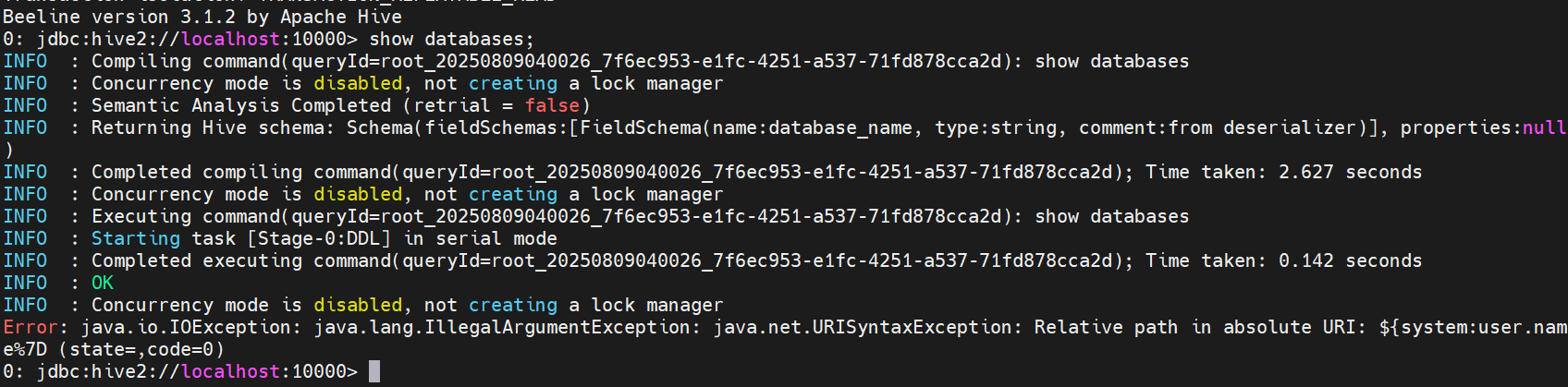
和问题3一样,这个是因为hive-site.xml中配置了值为${system:user.name},将其去掉,改为${user.name}
- 执行schemaTool脚本时报错:Missing Hive Execution Jar: /usr/local/hadoop/hive/lib/hive-exec-*.jar
实际上错误信息提示的jar包是在文件系统中存在的
Windows上使用Git bash执行脚本会有这个问题
参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号