MapReduce
MapReduce 概述
开始之前,需要确保安装并配置了Hadoop并且正常运行,如果没有,可以参考下面的链接进行安装配置:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/ClusterSetup.html
WordCount v1.0
以官网提供的代码示例WordCount为例
提交到Hadoop运行
- 先cd到%HADOOP_HOME%目录下
- 将官网的WordCount源码保存到文件,文件放到某个目录,我这里就放到D盘根目录
执行命令./bin/hadoop com.sun.tools.javac.Main .\WordCount.java 编译WordCount.java,生成3个编译的class文件如下图所示

-
打成jar包,执行
jar cf wc.jar WordCount*.class将生成的class文件打成jar包,会在当前路径下生成wc.jar文件 -
执行命令:
./bin/hadoop jar wc.jar WordCount /input /output将jar包提交到hadoop,指定输入文件路径和输出文件路径。注意:这里指定的路径是HDFS里的路径,所以要求input对应的路径必须存在
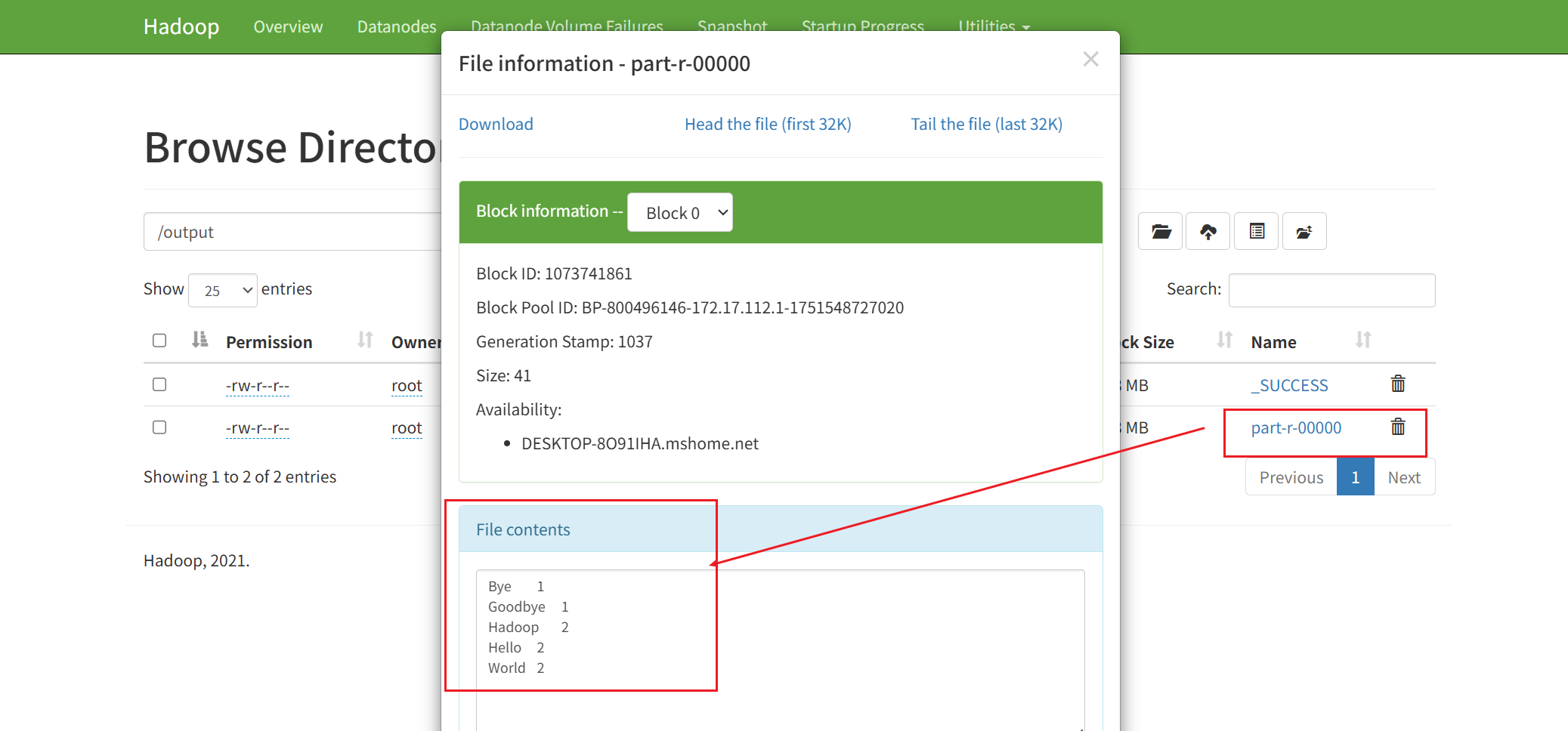
正常情况下会在HDFS里生成输出目录及相应的输出文件,如下图所示。如果报错: 找不到或无法加载主类 com.sun.tools.javac.Main,参考文末的问题解决方案
本地直接运行
创建一个java项目,添加如下的依赖,然后将官网的WordCount.java源文件直接运行
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.4.1</version>
</dependency>
添加程序参数,注意:这里的路径直接写不带盘符的本机绝对路径。如下图所示:
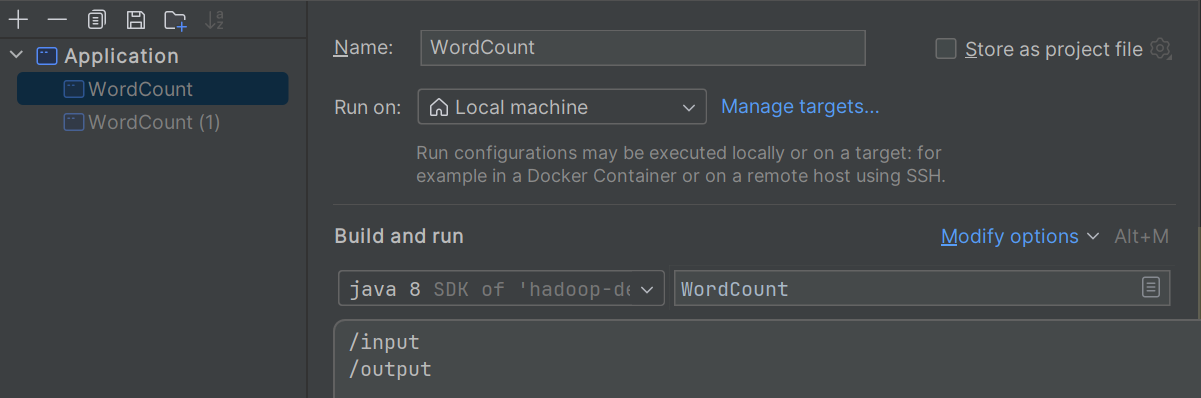
运行程序,在指定的输出目录(本地文件系统)下生成了下面的文件

这个part-r-00000其实就是个文本文件,可以直接用编辑器打开,内容如下:
Bye 1
Goodbye 1
Hadoop 2
Hello 2
World 2
Mapper
Mapper
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
....
/**
* Called once for each key/value pair in the input split. Most applications
* should override this, but the default is the identity function.
*/
@SuppressWarnings("unchecked")
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
// ....
}
}
WordCount的map方法,一次处理一行,将每行按空格进行分割
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
对于文件file01.txt,结果为:
< Hello, 1>
< World, 1>
< Bye, 1>
< World, 1>
文件file02.txt,结果为:
< Hello, 1>
< Hadoop, 1>
< Goodbye, 1>
< Hadoop, 1>
Reducer
输入输出
MapReduce框架只对<key,value>对进行操作,也就是说,该框架将作业的输入视为一组<key,value>对,并产生一组<key,value>对作为作业的输出,可以想象是不同类型的。
键和值类必须可由框架序列化,因此需要实现Writable接口。此外,关键类必须实现WritableComparable接口,以方便按框架进行排序。
MapReduce作业的输入和输出类型:
(输入)<k1,v1>->映射-><k2,v2>->组合-><k2、v2>->减少-><k3、v3>(输出)
Map-Reduce
Mapper
map的作用是对输入的key/value对进行处理,生成中间状态的key/value对
问题记录
Caused by: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset.
- 检查HADOOP_HOME环境变量是否已设置
- 检查winutils是否安装,参考:https://cwiki.apache.org/confluence/display/HADOOP2/WindowsProblems (这个链接会在控制台的异常堆栈中出现)
并且是否在HADOOP_HOME/bin/目录下有hadoop.dll和winutils.exe这两个文件 - 尝试在main方法开始的时候设置系统属性:System.setProperty("hadoop.home.dir", "值为HADOOP_HOME环境变量的值");
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
参考:https://blog.csdn.net/syl_ccc/article/details/105946007
再次运行程序,如果还不可以正常 运行,检查本地hadoop解压文件是否存在丢失重要文件,检查hadoop/bin下这俩文件是否缺失,如果缺失需要下载后再运行程序
若上述方法无效,将/Hadoop/bin/下的hadoop.dll文件复制到C:\Windows\System32下,再次运行,一般情况可以解决
Exception message: CreateSymbolicLink error (1314): ???????????
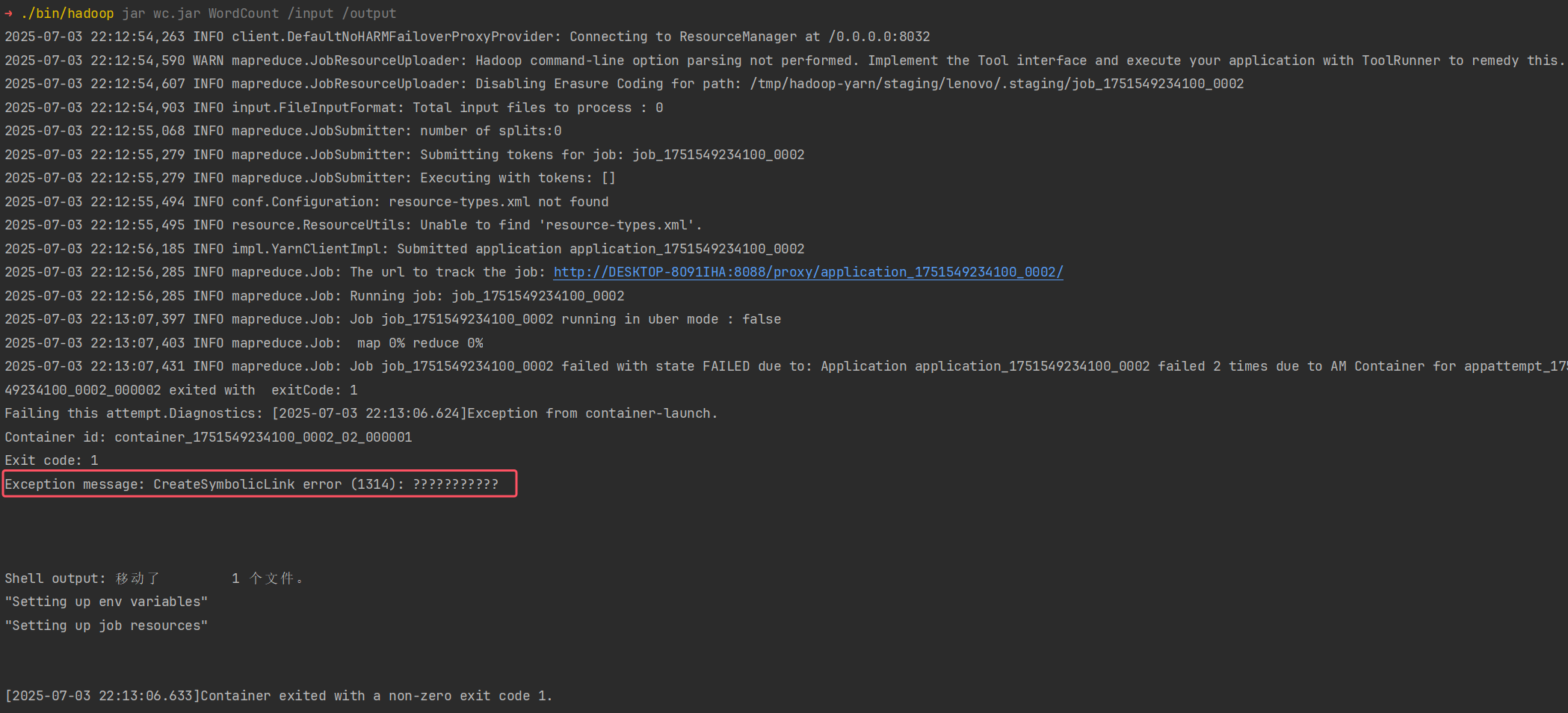
报了如上的错误,这是因为权限的问题,解决办法如下。
- 可能是权限问题
普通用户没有 创建符号链接的权限,换成管理员执行即可
以管理员方式运行启动hadoop,hdfs的脚本
./sbin/start-all.cmd
-
如果本机用管理员执行依然不行
通过win+R打开注册管理器gpedit.msc,或者计算机配置->windows设置->安全设置->本地策略->用户权限分配->创建符号链接。
添加 everyone ,重启 -
如果以上方法不行,修改%HADOOP_HOME%/etc/hadoop/core-site.xml文件,添加 fs.defaultFS 和 fs.default.name两个相同的属性
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
Name node is in safe mode
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.SafeModeException): Cannot delete /tmp/hadoop-yarn/staging/lenovo/.staging/job_1751553109699_0001. Name node is in safe mode.
The reported blocks 16 has reached the threshold 0.9990 of total blocks 16. The minimum number of live datanodes is not required. In safe mode extension. Safe mode will be turned off automatically in 12 seconds. NamenodeHostName:0.0.0.0
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.newSafemodeException(FSNamesystem.java:1570)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkNameNodeSafeMode(FSNamesystem.java:1557)
这是因为在分布式文件系统启动的时候,开始的时候会有安全模式,当分布式文件系统处于安全模式的情况下,文件系统中的内容不允许修改也不允许删除,直到安全模式结束。安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。运行期通过命令也可以进入安全模式。在实践过程中,系统启动的时候去修改和删除文件也会有安全模式不允许修改的出错提示,只需要等待一会儿即可。
可以手动离开安全模式
bin/hadoop dfsadmin -safemode leave
hadoop dfsadmin -safemode leave
enter - 进入安全模式
leave - 强制NameNode离开安全模式
get - 返回安全模式是否开启的信息
wait - 等待,一直到安全模式结束。
应用执行失败,但是控制台又没有明显的报错
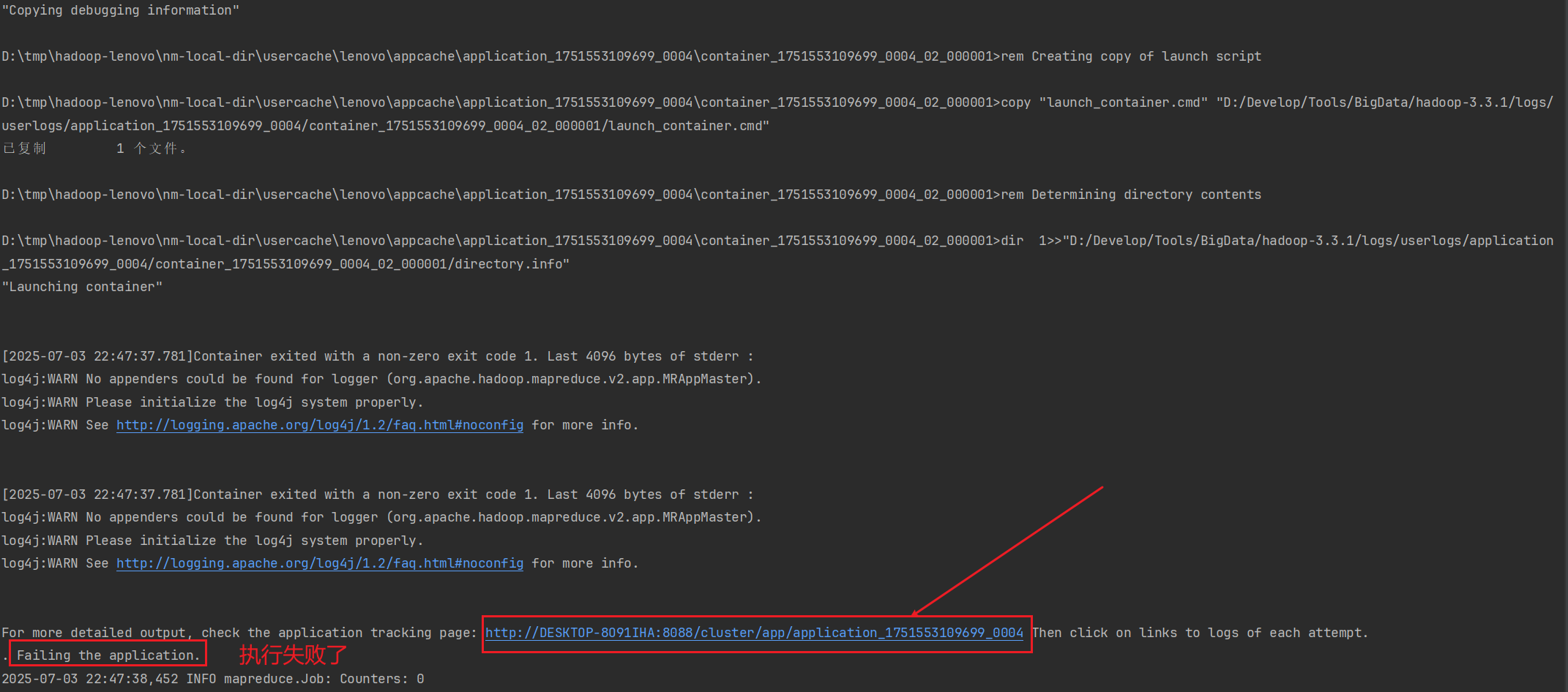
点开此链接
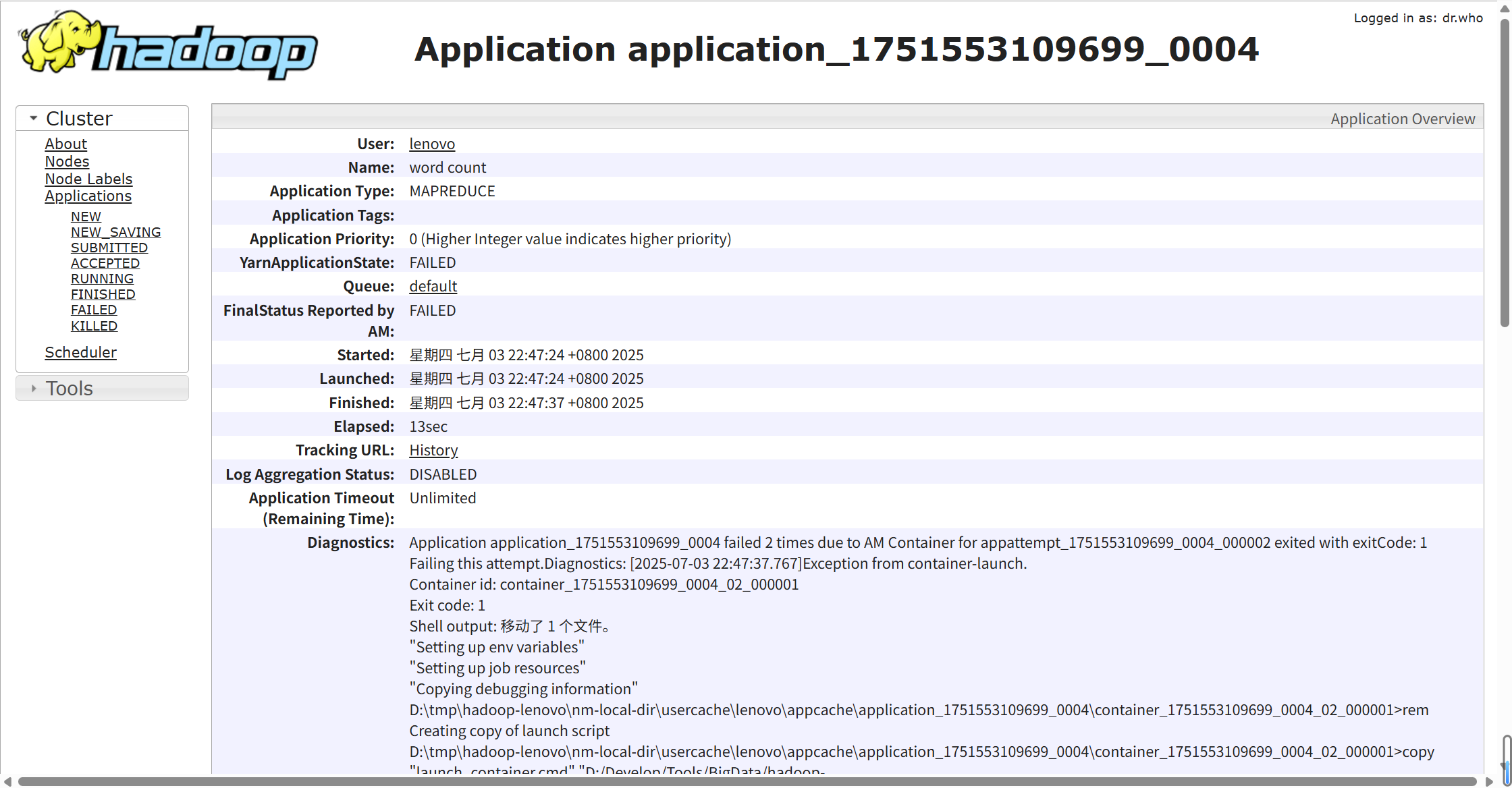
一直往下翻

点进这个日志
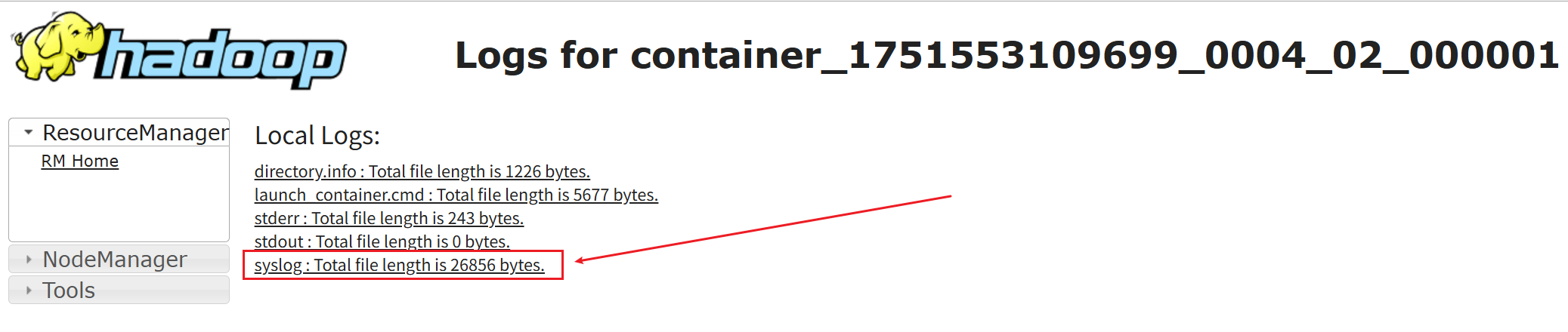
然后就可以看到执行过程中的异常堆栈了
尝试编译Hadoop程序时找不到com.sun.tools.javac.Main
- 可能是JAVA_HOME设置不正确
- 如果还不行,
bin/hadoop com.sun.tools.javac.Main WordCount.java最终会执行java com.sun.tools.javac.Main WordCount.java,所以可以直接执行后面的这条命令来进行编译 - 添加环境变量CLASSPATH,值为
.;%JAVA_HOME%\lib\tools.jar;%JAVA_HOME%\lib\dt.jar - 手动指定classpath:./bin/hadoop -classpath D:\Develop\Java\JDK\oraclejdk8_192\lib\tools.jar com.sun.tools.javac.Main .\WordCount.java
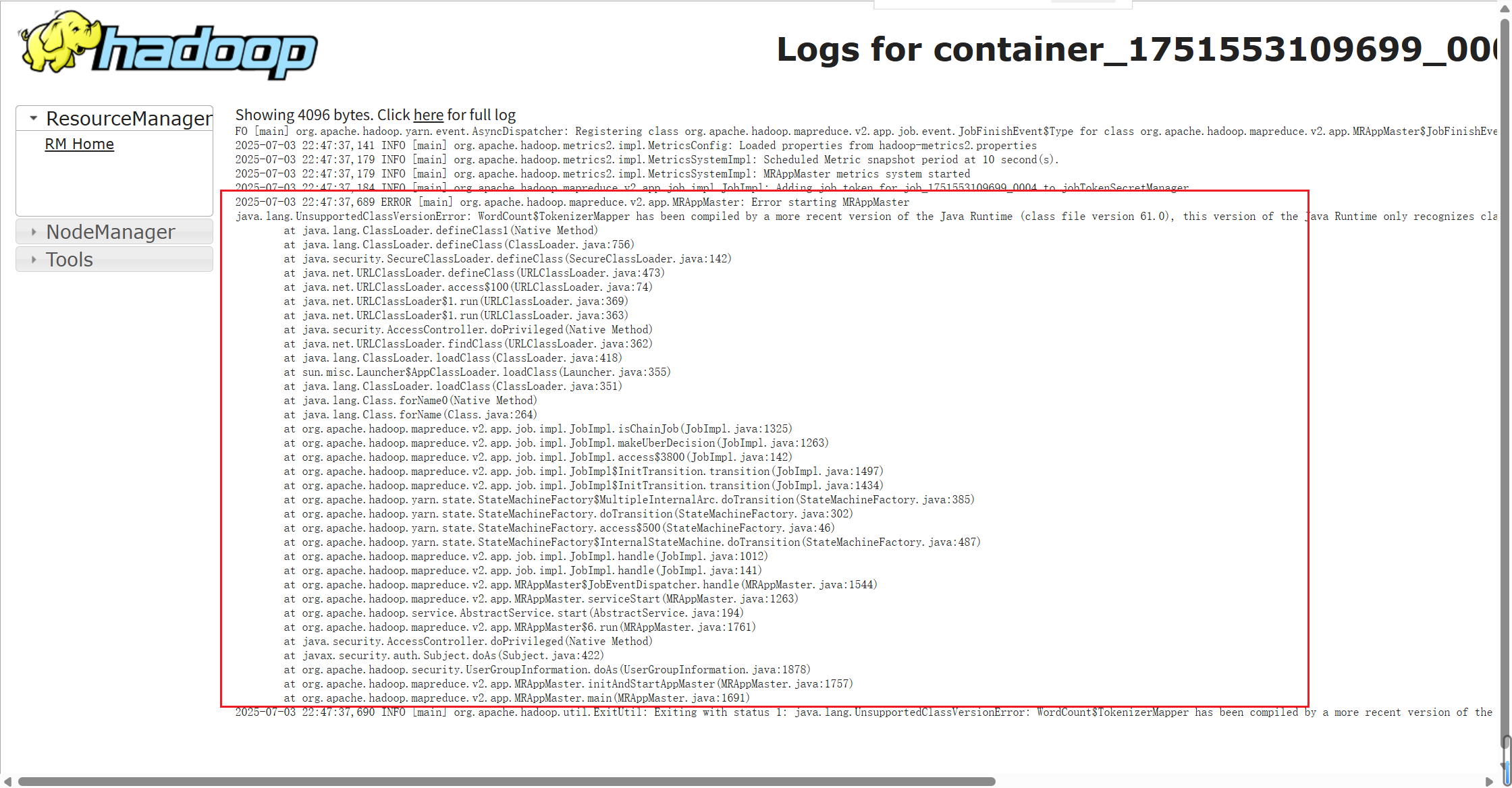
java.lang.UnsupportedClassVersionError: WordCount$TokenizerMapper has been compiled by a more recent version of the Java Runtime (class file version 61.0), this version of the Java Runtime only recognizes class file versions up to 52.0
原因是./bin/hadoop com.sun.tools.javac.Main .\WordCount.java使用了高版本的jdk
- 检查%JAVA_HOME%是否使用了高版本
- 如果JAVA_HOME使用的是JDK8,尝试设置HADOOP_CLASSPATH环境变量
export HADOOP_CLASSPATH=$JAVA_HOME/lib/tools.jar
- 执行hadoop命令时会先执行%HADOOP_HOME%\etc\hadoop\hadoop-env.cmd设置环境变量,可以修改该脚本,在开头手动强制设置JDK路径
set JAVA_HOME=JDK安装目录
执行start-all.cmd时NameNode, DataNode, NodeManager都可成功启动,但是ResourceManager启动报错:拒绝访问
Caused by: 5: 拒绝访问。
at org.apache.hadoop.io.nativeio.NativeIO$Windows.createFileWithMode0(Native Method)
以管理员权限运行脚本即可
参考:https://issues.apache.org/jira/browse/HDFS-16056?page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel&focusedCommentId=17359121
乱码问题
WEB管理界面日志乱码
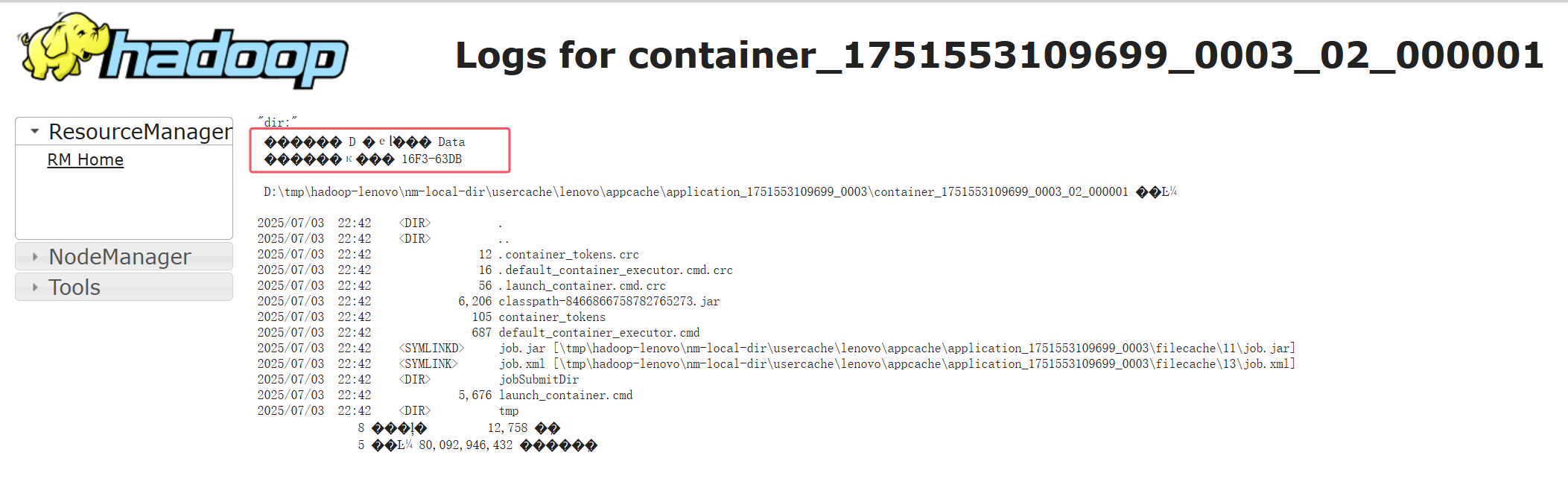
搜索这个应用id,一般可以在文件系统中找到其日志文件,
sterr和stdout是文本文件,如果使用操作系统文件编辑器打开不乱码的话
hadoop涉及输出文本的默认输出编码统一用没有BOM的UTF-8的形式,但是对于中文的输出window系统默认的是GBK,有些格式文件例如CSV格式的文件用excel打开输出编码为没有BOM的UTF-8文件时,输出的结果为乱码,只能由UE或者记事本打开才能正常显示。因此可以尝试将hadoop默认输出编码更改为你自己的编码
HDFS/MapReduce 配置编码,统一集群内部的编码:
在core-site.xml或mapred-site.xml中设置file.encoding或mapreduce.map.output.encoding为GBK或UTF-8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号