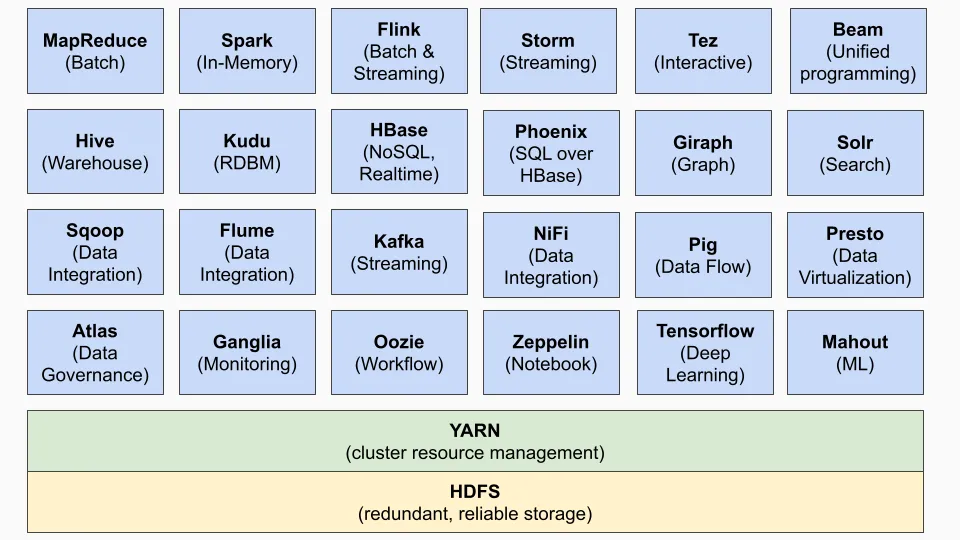
Yarn
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,
相当于一个分布式
的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序。
YARN 可以理解为集群的操作系统。集群是一组松散或紧密连接的计算机,它们协同工作,被视为一个单一系统。集群代表着资源的集合,例如计算资源、内存资源、磁盘空间和网络带宽,YARN 必须在集群上运行的作业之间进行仲裁。与操作系统管理机器资源并在竞争进程之间分配资源的方式类似,YARN 也在竞争作业之间分配集群资源。
YARN(Yet Another Resource Negotiator)是Hadoop生态系统的关键组成部分。它作为集群资源管理层,负责管理和分配在Hadoop集群上运行的分布式应用程序的CPU、内存和存储等资源。
YARN 的主要目标是将资源管理和数据处理功能分离为独立的组件。这使得一个全局资源管理器能够在单个集群上运行,从而支持各种数据处理应用程序,例如 MapReduce、Spark、Storm、Tez 等。
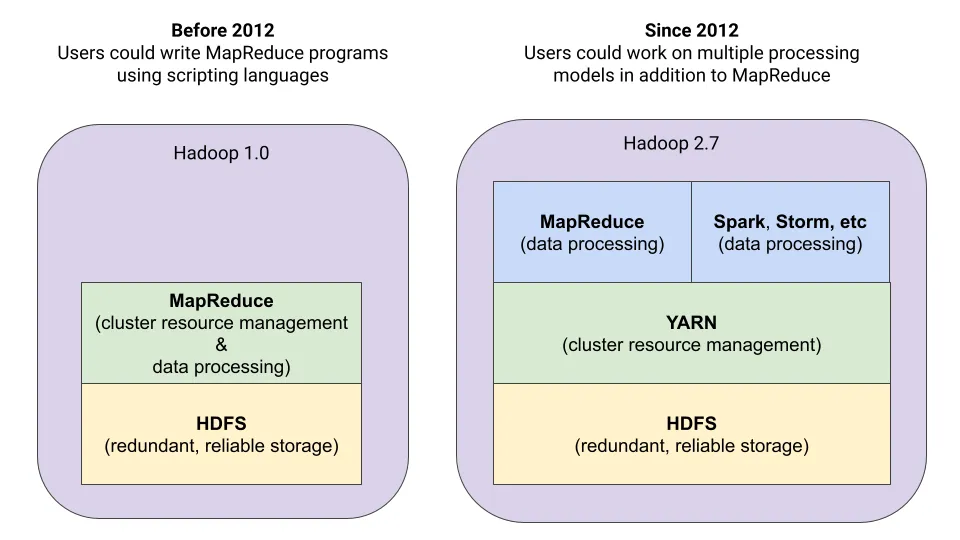
在 YARN 推出之前,Apache Hadoop 使用名为 MapReduce 的资源管理器,它既是资源管理器,又是处理引擎。该系统与 Hadoop 分布式文件系统 (HDFS) 紧密耦合,并且仅限于运行 MapReduce 作业。这使得用户难以在 Hadoop 集群上运行其他类型的应用程序。
为了克服这些限制,YARN 应运而生。YARN 将 MapReduce 的处理引擎和管理功能分离,使其能够支持多种处理引擎和应用程序。
Benefit of YARN
Centralized Resource Management: YARN provides a centralized resource management system that can dynamically allocate and manage resources for different frameworks/applications running on the Hadoop cluster.
Flexibility: The scheduling and resource management capabilities are separated from the data processing component. This allows for running various types of data processing applications on a single cluster.
Better Cluster Utilization: YARN’s dynamic resource allocation ensures each application gets the resources it needs to run successfully without affecting other applications. Additionally, resources unutilized by one framework/application can be consumed by another.
Cost-Effective: With YARN, one “do-it-all” Hadoop cluster can run a diverse set of workloads and support a variety of applications, making it a more efficient and cost-effective platform for big data processing.
Reduced Data Movement: As there is no need to move data between Hadoop, YARN, and systems running on different clusters of computers, data motion is reduced.
基础架构
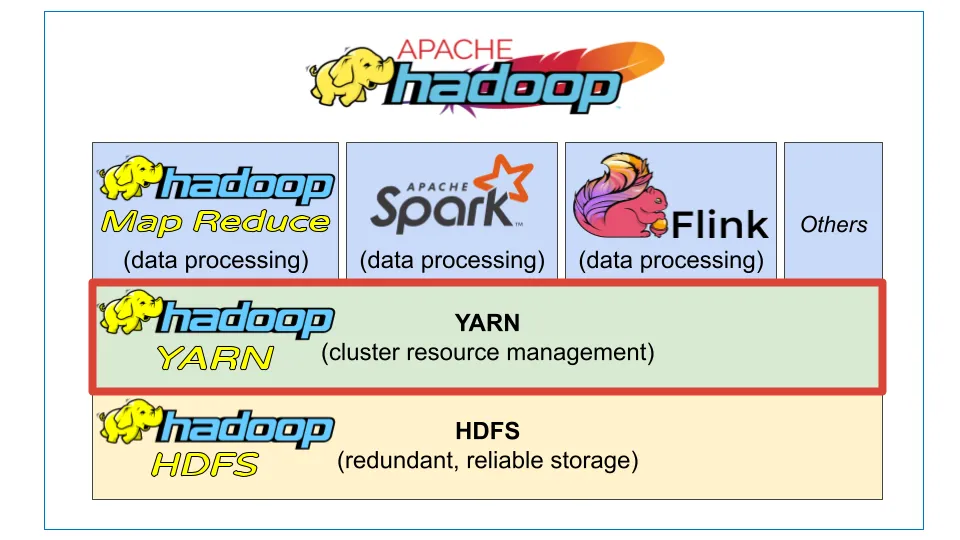
- 管理集群资源,例如计算、网络和内存
- 作业的调度和监控
基本架构
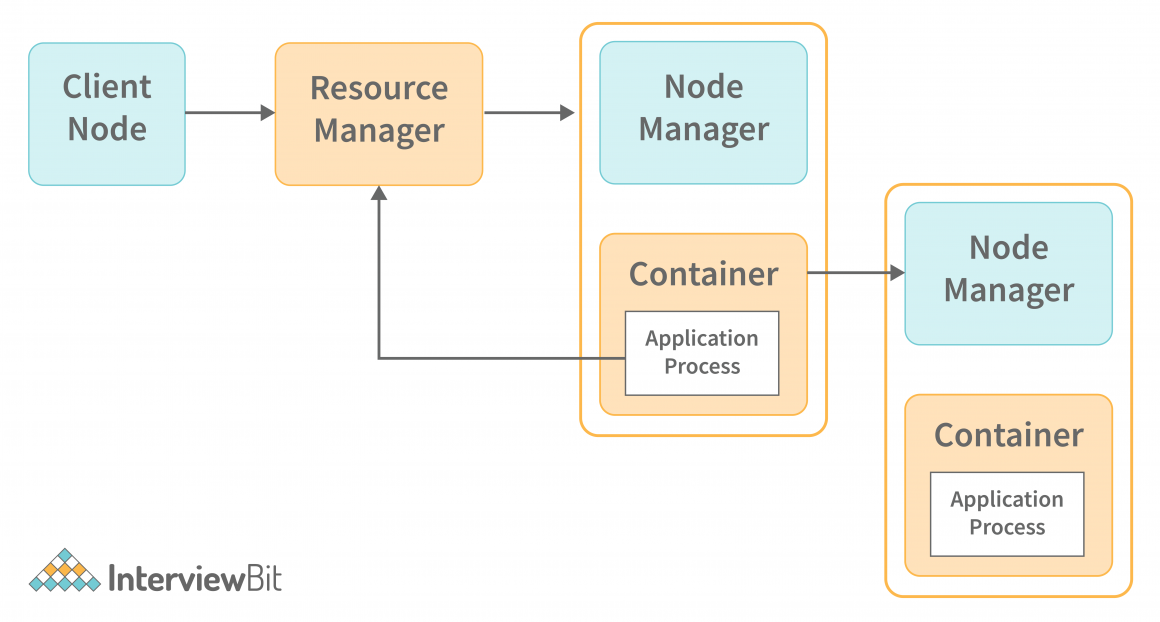
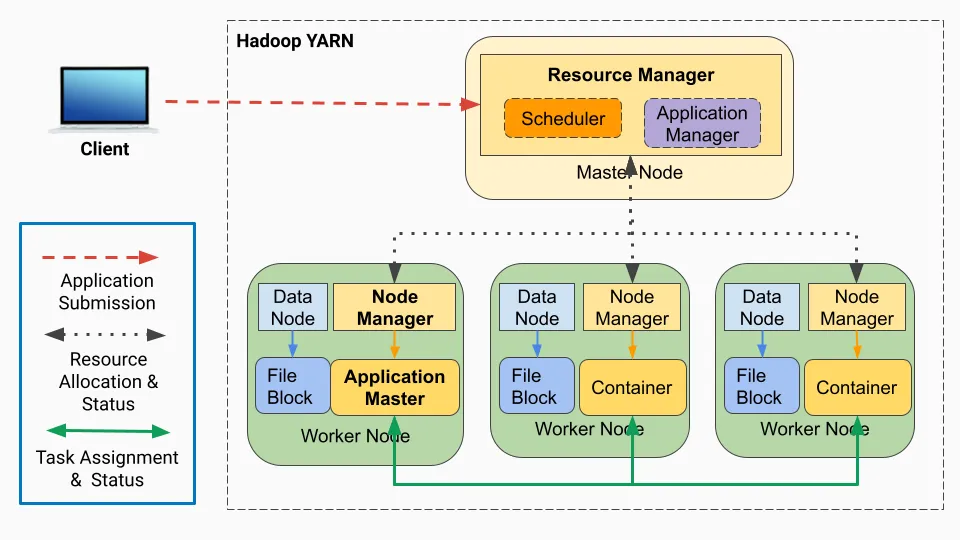
Resource Manager
Node Manager
这两个组件以主从关系工作,其中资源管理器(RM)为主,节点管理器为从。单个资源管理器在群集中运行,每台机器有一个节点管理器。这两个组件共同构成了数据计算框架。让我们先讨论一下资源管理器。
Resource Manager (RM)
ResourceManager是一个在主节点上运行的Java进程,负责根据各种作业的需求在Hadoop集群中管理和分配CPU、内存和磁盘等资源。
Cluster resource tracking: It maintains a global view of the cluster and tracks the available resources on each node.
Cluster health monitoring: It monitors the health of nodes in the cluster and manages the failover of resources in case of node failures.
Cluster resource allocation: It receives resource requests from application masters and allocates the necessary resources to run the application.
Job scheduling: See Scheduler
Application master management: See Applications Manager
RM由两部分组成:
- 应用程序管理器:负责接受作业提交,并为名为ApplicationMaster的实体启动一个容器。如果容器发生故障,它还会重新启动ApplicationMaster容器。
- 调度器:调度器负责分配磁盘、CPU和网络运行应用程序等资源,但受队列和容量的限制。调度器不监视应用程序,也不会在应用程序或硬件故障时启动重启。
调度器
调度器负责根据定义的策略,在已提交的应用程序之间调度和协调集群中的可用资源。它支持不同的策略来管理容量、公平性和服务级别协议 (SLA) 等约束。
YARN 中提供三种类型的调度策略:
FIFO
最简单的调度器,遵循先到先得,适用于较小的集群和简单的工作负载
容量调度器
该调度器将集群资源划分为多个队列,每个队列都有自己的预留资源,同时能够动态利用其他队列中未使用的资源。它适用于大规模、多用户环境。
公平调度器
在接受的作业之间公平、平等地平衡资源,而不需要一定数量的预留容量。它适用于运行具有不同大小和资源要求的作业的集群。
Application Manager
ApplicationManager是一个界面,用于维护已提交、正在运行或已完成的应用程序列表。它负责:
- 处理工作提交:接受向YARN提交的工作,
- 为ApplicationMaster协商资源:协商用于执行特定于应用程序的应用程序主控的第一个容器,以及
- 管理ApplicationMaster的故障转移:失败时重新启动应用程序主容器。
在Unix中,容器是一个进程,在Linux中是一个cgroup。MR任务在容器内运行。集群中的一台机器可以有多个容器。
Node Manager
NodeManager是一个在集群中的每台机器上运行的代理。它负责在该机器上启动容器并管理容器对资源的使用。它将使用情况报告回资源管理器的调度器组件。
NodeManagers是在Hadoop集群中的从属/工作节点上运行的Java进程。它们负责管理每个工作节点上的容器和资源,为应用程序提供安全的运行时环境,并允许高效灵活的资源分配。
- 报告节点健康状况:每个节点管理器都会向ResourceManager报告自己,并定期发送心跳以提供节点状态和信息,包括内存和虚拟核。如果发生故障,节点管理器会向资源管理器报告任何问题,将资源分配转移到健康的节点。
- 启动容器:节点管理器从ResourceManager获取指令,在其节点上启动容器,并使用指定的资源约束设置容器环境。
- 容器管理:节点管理器管理容器生命周期、依赖关系、租约、资源使用和日志管理。
容器
容器是资源分配的一个单位,是Hadoop集群中特定工作节点上的抽象表示。容器被分配来执行应用程序中的任务,如MapReduce作业或Spark任务。每个容器都分配了特定数量的资源,如CPU、内存和磁盘空间,使任务能够在受控和隔离的环境中运行。
-
ResourceManager
YARN中的ResourceManager负责根据应用程序主机的资源请求将容器分配给它们。它提供了容器启动上下文(CLC),其中包括环境变量、依赖关系、安全令牌和创建应用程序启动过程的命令。 -
NodeManager
YARN中的NodeManager负责启动具有指定资源约束(CLC)的容器。 -
ApplicationMasters
Application Masters管理这些容器中任务的执行,监控其进度,并处理任何任务失败或重新分配。
Application Master
它维护一个正在运行的应用程序的注册表,并监控其执行情况。每当向框架提交作业时,都会为其选择一个AM。它负责将资源从资源管理器分配到节点管理器,然后节点管理器监视和执行任务。
AM is a process that runs the main function/entry point of an application, such as the Spark driver. It has several responsibilities, including:
- 请求资源:与资源管理器协商,以获取启动容器执行任务所需的资源。
- 运行Master/Driver程序:它运行Master/Drive程序,如Spark Driver,该程序设计作业执行计划,在分配的容器中分配任务,跟踪任务执行状态,监控进度并处理任务失败。
Hadoop YARN中的应用工作流
得益于 YARN 的灵活设计,Hadoop YARN 集群能够适应各种工作负载。因此,单个 Hadoop 集群可以同时运行多个应用程序,例如 MapReduce、Spark、Storm、Impala 等,从而实现更高的灵活性和效率。
本节我们将以一个Spark应用程序为例,讲解YARN如何处理作业请求、分配资源,以及如何管理ApplicationMaster、NodeManager等组件。
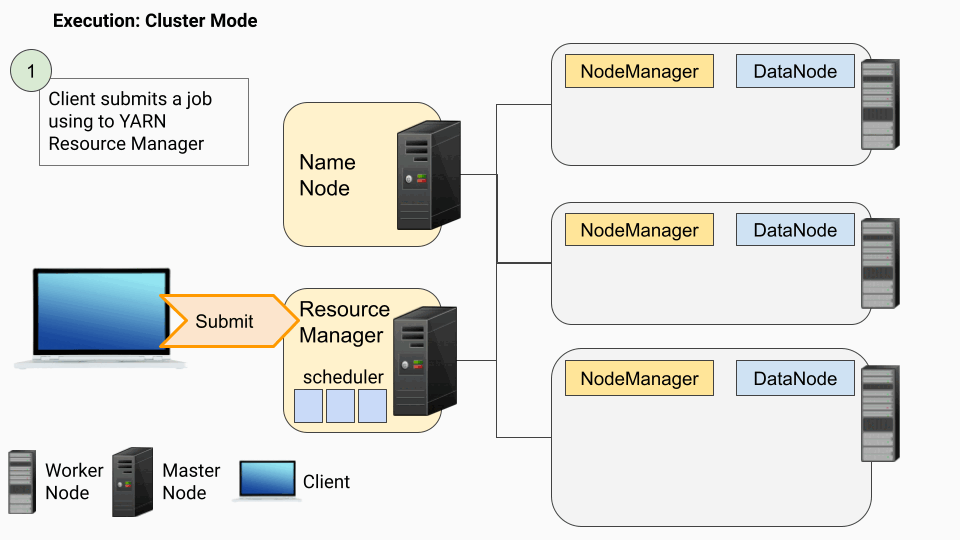
步骤1:客户端使用spark submit向YARN资源管理器提交作业。
步骤2:作业进入ResourceManager中的调度程序队列,等待执行。
步骤3:当执行作业时,ResourceManager会找到一个能够启动容器以运行ApplicationMaster的NodeManager。
步骤4: ApplicationMaster启动驱动程序(创建SparkSession/SparkContext的程序的入口点)。
步骤5: ApplicationMaster/Spark计算作业所需的资源(CPU、RAM、执行器数量),并向资源管理器发送请求以启动执行器。ApplicationMaster与NameNode通信,以使用HDFS协议确定集群内的文件(块)位置。
步骤6:驱动程序将任务分配给执行器容器,并跟踪任务状态。
步骤7:执行器容器执行任务并将结果返回给驱动程序。驱动程序汇总结果并产生最终输出。
运行YARN应用程序
- 第一步包括请求RM(资源管理器)创建应用程序主(AM)进程。客户端提交作业,RM找到一个节点管理器,可以启动一个容器来承载AM进程。AM进程代表客户端作业/应用程序。它可以自己运行作业,并从RM返回或请求额外的资源。在后者中,RM让其他机器上的节点管理器代表AM进程启动容器来运行分布式计算。为新容器分配选择的节点允许计算尽可能靠近输入数据执行,也称为数据局部性。理想情况下,容器被分配给承载数据块副本的节点。下一个首选项是与输入数据块位于同一机架中的节点,最后是集群中的任何可用节点。
YARN应用程序的运行时间从几秒钟到几天不等。
作业到应用程序的映射可以通过三种方式进行:
- 每份申请一份工作:这是最简单的模式。
- 每个应用程序有多个作业:这适用于将多个作业(可能相关)作为工作流或在单个用户会话中运行。好处是容器可以在作业中重用,作业之间的中间数据可以缓存在内存中。
- 持续运行的应用程序:在这种模型中,充当协调器的应用程序会一直运行,甚至永远运行,并在各种用户之间共享。Apache Slider和Impala是采用这种策略的两个应用程序。在Apache Slider的情况下,长时间运行的应用程序主机会启动集群上的其他应用程序。始终在线的应用程序主机减少了执行作业的延迟,因为消除了启动应用程序主机的开销。
RM高可用
Hadoop 2.4中引入了YARN的高可用性。一对资源管理器在活动/备用配置中运行,以实现高可用性。如果活动资源管理器死亡,则备用资源管理器将变为活动资源,集群将继续正常运行。管理员可以手动或自动完成从待机模式到活动模式的转换。对于自动转换,需要Zookeeper进行选举
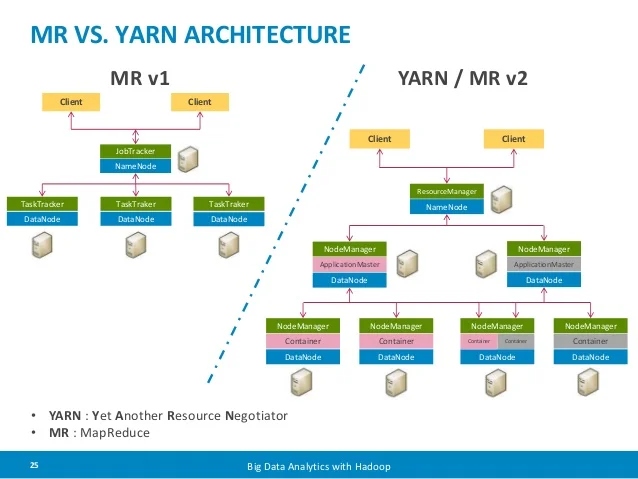
https://stackoverflow.com/questions/31044575/mapreduce-2-vs-yarn-applications

 浙公网安备 33010602011771号
浙公网安备 33010602011771号