应用微积分-MIT-18-013A--全-
应用微积分(MIT 18.013A)(全)
前言
这里呈现的 18.013A 课程旨在为在高中学习过微积分的学生提供一个一个半学期的微积分课程。它旨在是自包含的,因此可以在没有任何微积分背景的情况下跟随,对于那些冒险的人来说是可能的。
它利用了一些相对较新的工具,比如小程序,旨在使学科更易学习和更有趣。
然而,我们并不打算让这门课程仅仅成为一个简单的微积分课程,覆盖与传统课程相同的所有内容,但由于小程序和电子表格的使用,更容易吸收。
实际上,现代节省劳动力的设备并没有使生活更轻松简单。相反,它们节省了我们时间,使我们能够在生活中做更多事情,使生活变得比以往更加复杂和繁忙。
同样,我们希望这些新工具能让学生在同样甚至更多的努力下学到更多、更彻底地学到更多。
因此,所涵盖的材料在深度和多样性上远远超出了通常在微积分课程中尝试的范围。
实际上,我们试图在这个网站上的每一章几乎都注入了新的材料。
为什么我们这样做呢?
部分原因是人类的脆弱性:为了在创作这些材料时不至于发疯。
此外,也是为了保持对已经接触过该主题的人的兴趣。最后,是为了展示现在吸收和使用不久前对学生完全无法接触、很少教授,甚至在教授时很少掌握的材料是多么容易。
显然,一些额外材料主要是为了让学生感到困惑,有些做得很糟糕,尽管可以改进,有些可能会给你提出更好的建议,可以包含在其中。
作者们会很高兴如果你找到一种使用这些材料或从中学习的方法。如果您能通过电子邮件(djk@math.mit.edu)向我们发送您对此的任何评论,尤其是那些不喜欢看到的人,我们将不胜感激。
它仍处于可以更改的阶段。
那么在这里对微积分课程有什么新的内容呢?
引入电子表格的第零章是全新的。
第一章中对标准函数的讨论是新的。
通过插图在第二章中对三角函数进行几何定义是新的,第三章中关于各种度量标准(3.8)的部分是新的。(在那里可能带来更多的伤害而不是好处。)
第四章和第五章的主要创新是小程序,尽管在这个阶段引入特征向量和特征值的概念可能有些不同寻常。
第六章涉及在所有维度中定义微分的内容是新颖的;但我认为这有助于让学生看到为什么微分规则是什么样的,以及微积分为何有用。
第七章关于数值微分对我来说是新的。
第八章没有太多新内容,除了它适用于所有维度。
除了小程序之外,这门课程的主要创新可能是数值分析部分,单变量和多变量微积分的研究,复平面中积分的引入以及与物理学的应用。尽管这些在物理学中很常见,但在微积分课程中很少讨论。
我们的目的是涵盖足够多关于数学更高级领域的内容,让学生们意识到它们的存在,并激励他们想要进一步学习这些内容。
这些材料理论上可以由学生自学,但这很少会成功。学生往往会在某些地方卡住,由于没有目标来推动他们继续前进,他们会试图以逐渐减少的精力克服困难,最终对继续学习产生心理障碍。有组织的课程通过强迫他们面对考试和作业等障碍来防止这种情况的发生。
如果你尝试这样做并陷入困境,几乎是不可避免的,你可以尝试给我们发电子邮件,我们会尽力帮助你解决困难。
第一章:哲学、数字和函数
引言
我们考虑我们的努力将集中在的基本上下文:数字和函数的领域。我们描述了“标准函数”,这些函数在你的世界中最常出现,并且逆函数
主题
1.1 哲学
1.2 数字
1.3 函数
1.4 标准函数
1.5 其他函数
1.6 反函数
1.7 隐式函数
1.1 哲学
我们不会深入探讨哲学,只是列出一些我们希望在课程中融入的特点。
课程的哲学
1. 尽可能多地使用计算机。
2. 使用电子表格。
3. 鼓励积极学习而不是被动学习;试图让你思考材料。
4. 将一元微积分与多元微积分结合起来,使它们一起处理而不是一个接一个地处理。
5. 在适当时通过电子邮件向我提交作业。
6. 让你重新做作业直到正确为止。
7. 反馈是所需活动的重要组成部分。
学习的哲学
1. 学到的东西与投入的时间成正比。
2. 学习的最佳方式是自己想出想法或将其教给别人。
3. 第二好的方法是通过朋友或我们这样的人的提示来做。
4. 第三好的是从阅读中获取思想;但在阅读中停下来思考它们。
5. 第四好的:不可接受的:根本不了解它们。
6. 一个讲座的目的不是告诉你重要的事实,而是激发你尝试学习某个概念。
7. 课程的目标是使您能够在任何情境中使用微积分的概念。
1.2 数字
我们从数字的基本概念开始。自然数,表示为 N,是数字 1,2,3,...,在加法下是封闭的。
能够与 N 或 N 的子集建立一一对应关系的集合称为可数集。 对应
引入减法的概念使我们将 N 扩大到得到整数,表示为 Z,正数、负数或 0,使得我们的数字在减法运算下是封闭的。
练习 1.1 Z 可数吗? 解答
Z 在乘法下是封闭的;也就是说,两个整数的乘积是一个整数。
要得到一个在除法下封闭的数字集合:我们必须将 Z 扩大以得到有理数 Q,其形式为  ,其中 a 是 Z 中的数,b 是 N 中的数。
,其中 a 是 Z 中的数,b 是 N 中的数。
练习:
1.2 Q 可数吗?(参见图片提示。) 解答

1.3 证明或反驳:可数集的可数子集是可数的。 解答
数字的十进制形式
0 到 1 之间的数可以表示为小数点后跟着无限位数字的形式,每个数字为 1、2、3、...、9、0 中的一个。
有理数在某一点之后无休止地重复自己:(例如 1 / 4 是 .250* 或者 .249,星号表示你无休止地重复星号后的数字)1 / 3 是 .3,1 / 7 = .(142857),57 / 100 = .570。
无理数不会这样做。
练习:
1.4 证明有理数无休止地重复相同的有限数字序列,而无理数不会。 解答
1.5 是否存在非有理小数位序列? 解答
1.6 所有这样的序列都可数吗?(查看图片以获取提示。)解答

一个数,其第 k 位小数与列表中第 k 位数不同,不能在任何位置上!
代数数是整系数多项式方程的解。
练习 1.7 代数数可数吗? 解答
实数 R是所有不同的无限数字序列,有一个符号和有限位数的小数点前的数字。
你可以对它们进行加减乘除,但不允许除以 0。
还有其他我们可能称之为数的集合吗?
是的!有“模 x 的数”。这些是当你除以 x 时得到的 Z、Q 或 R 的余数。
还有复数,形成集合 C。这些是形如 a + ib 的表达式,其中 i² = -1,a 和 b 在 R 中,乘法和除法与 R 中的规则相同,附加规则如上。
评论 - 更多关于复数的内容
1.3 函数
集合是一个基本概念。我们以集合(或者另一个称呼:集合)作为基本概念。
有序可数集也被称为序列。1, 2, 3, ... 就是一个序列。
如果有两个元素,它被称为有序对。(3, 4)就是这样一个对。
函数是一组有序对的集合,其第一个元素都不相同。
第一个元素称为参数,第二个称为值。
参数的集合称为其定义域。
值的集合称为其值域。
我们通过f(参数) = 值来描述函数 f 中的每一对。

当 f 对两个不同的参数具有相同的值时,比如对 f(d) 和 f(e) 的值相同,这是完全可以的。
我们可以通过列出其对或者通过通常方式绘制代表性对的图形来描述一个函数:如果f(a) = b,在 x 轴上通过 a 的垂直线和 y 轴上通过 b 的水平线的交点处放一个点。
然而,我们无法列出具有无限或巨大定义域的任何函数中的所有对。
我们定义这样一个函数,通过提供一个你可以用来构建其值的过程,你可以选择其定义域中的任意参数。这个过程通常被称为函数的“公式”。
1.4 标准函数
标准函数 是在 R 的一个区间上定义的,它通过从任意三个基本函数的任意组合开始的有限序列的标准操作获得。
基本函数是什么?
恒等函数 f(x) = x

**指数函数 f(x) = exp(x)

**正弦函数 f(x) = sin(x)

标准操作是什么?
实数中的乘法、加法、减法、乘法、除法、将一个函数的值代入另一个函数作为参数,并进行“逆运算”。
我们遇到的大多数函数将是标准函数。
例如:4x²,x sin(x),
你可以在下面的小程序中输入你喜欢的标准函数 f 和 g,并观察以各种方式组合 f 和 g 的效果,还可以查看 f 的逆函数。
注意,当 f 对于多个参数具有相同的值时,你必须决定你想将哪个参数称为逆函数的值。
1.5 其他函数
还有其他函数吗?
是的,但我们主要关注标准函数。
我们可能会遇到哪些其他函数?
分段标准函数: 这些是在其定义域的子区间上是标准函数的函数,但在所有子区间中不一定是相同的标准函数。对于任何负参数为 0,对于正参数为 1 的函数是一个例子。这被称为阶梯函数。
x 的绝对值,对于负参数 x 是 -x,对于正 x 是 +x,是另一个例子。它的图像在 x 轴原点处呈 V 形。
通过无限级数定义的函数: 特别是通过一系列幂 x^n 和系数是幂的标准函数。一个简单而基础的例子是几何级数,由 g(x) = 1 + x + x² + ... + x^k + ... 定义。
使用微积分运算定义的函数: 这些通常是由标准函数的导数或积分定义的函数。一旦这些概念被定义,这样的定义就很容易。
序列可以被看作是以 N 或 N 的子集为其定义域的函数。
递归或隐式定义的函数:函数的递归定义是通过一个需要重复应用的过程来构造其值的过程来描述的,以便在整个定义域上定义它们。
例如,斐波那契数 f(n) 根据以下规则形成一个序列:f(0) = f(1) = 1;对于大于 1 的整数 n,f(n) = f(n - 1) + f(n - 2)。
这是这个序列的递归定义。
隐式定义的函数将在第 1.7 节中详细讨论。
来自真实现象的函数:这些通常起初是未知的。它们可能是任何东西。令人惊讶的是,我们将它们视为标准函数,或者视为上述其他类别中的一个函数时,我们的表现有多么出色。
为什么考虑标准函数?
它们可在计算器和电脑上使用。
它们只有孤立的奇点。
除了通常很容易定位的某些奇异点外,它们在大部分定义域上都是无限可微的。
它们可以在复平面上定义。
它们非常有用。
我们可以对任何在同一定义域上定义的 序列 或 函数 进行加、减或乘,并且在其中一个被除的地方,只要不是 0,就可以除另一个。为此,在它们的定义域中的每个自变量处,加、减、乘或除它们的值。
1.6 反函数
什么是反函数?
取一个函数 f:按照通常的方式画出它的图形;交换 x 和 y 轴,然后你就得到了反函数 f^(-1) 的图形。
y = f(x) 意味着 x = f^(-1)(y)。
这可以通过在纸上画图,将纸翻转过来,使旧的第一象限出现在右上角,并透过纸看旧图形来完成。
不要混淆反函数与倒数函数;它们是完全不同的概念。粗心的人可能会使用相同的符号表示法。这样做是错误的,因为它会引起混淆。
请注意,如果将 x = f^(-1)(y) 替换到 y = f(x) 中,你会得到 x = f^(-1)(f(x))。这最后一个方程可用作 f 的反函数的替代定义。
定义反函数存在问题。对于每个自变量,一个函数只能有一个有序对,而同样的值可以出现多次。这意味着交换自变量和值(这是我们在创建反函数时所做的),会产生一个非函数,除非原始函数确实每次都采用每个值。
当一个函数多次取值时,我们必须额外工作来为其定义一个反函数。换句话说,我们必须选择一个值作为新的自变量,并且放弃其他值。当 f 不是单值时,可以用许多不同的方式来做到这一点,因此在定义 f^(-1) 时总会存在某种任意性。
这方面最清晰的例子是函数 x²。它每个正值都有两个对应值。4 和 -4 都有相同的平方。对于这个函数的标准做法是定义其逆函数,x^(1/2),为正平方根,忽略负平方根。(然后负平方根用 -x^(1/2) 表示。)这个定义有两个优点:一个是正数比负数更正。另一个是,用这个定义(而不是选择负根作为逆函数),乘积的平方根是其因子的平方根的乘积。
一般来说,你可以通过查看 f 的图像,在 f 是单值的定义域上进行选择,并将其作为 f ^(-1) 的值域来选择 f 的逆。
一些有趣的配对:����� ���




练习 1.8 对于哪些值可以定义函数 cos(sin x) 的逆函数。(提示:设 f = cos(sin x),看看它的逆函数并找出答案。) 解答
1.7 隐式函数
函数的隐式定义是指没有给出其值的显式公式,而是通过给出其满足的条件来定义它。因此,其值必须被推断为定义的结果,因此它是“通过暗示”定义的。
一个例子是:通过 x² + y² =1 和 y > 0 来定义 y(x)。
将一个函数定义为其逆函数是隐式定义的另一个例子。
注意,在这个例子中你可以得到一个关于 y(x) 的公式;该公式表示了这个相同函数的显式定义。
练习:
1.9 这些内容对你来说有多熟悉?
1.10 陈述 cos x 是  意味着什么关于 arccos y 和 arcsin y? 解答
意味着什么关于 arccos y 和 arcsin y? 解答
1.11 想出一个可以放在这里的问题。
第二章:指数函数和三角函数
简介
我们考虑我们基本函数的性质。
主题
2.1 指数函数
2.2 三角函数
2.3 三角函数的性质
2.4 对数
2.1 指数函数
指数函数,用 exp x 表示,由两个条件定义:
它在参数 0 处的值为 1。
它是它自己的导数。 评论
这意味着它在 0 处的斜率为 1,这意味着它在那里增长,因此随着 x 的增加增长得更快,并且作为它自己的斜率,即使在负值时也增长得更快,永远不会变成 0。
如果你绘制它,并在参数 x 处画一条切线,那么该切线将保持在它下方,并在 x 轴上的 x - 1 处相交。
我们可以将 exp x 的表达式找到为 x 的无限级数,从一个常数开始,通过使用定义条件和导数的整数幂 x^n 的导数是 nx^(n-1) 的事实。

(如果这对你来说不熟悉,现在就相信它;在定义了我们的术语之后我们将证明它。如果你是初学微积分的人,你可能会觉得这一切都很神秘。如果是这样,请不要担心,但请阅读解答以了解下面提到的基本性质。)
如何?
当 x = 0 时,exp 为 1,这意味着第一个或常数项为 1。这一项必须是另一项的导数,根据上述幂导数公式,唯一可能的具有 1 作为其导数的项是 x。
类似地,唯一具有 x 作为其导数的项是  。因此等等,这导致了指数函数表达式的级数的一般项是...
。因此等等,这导致了指数函数表达式的级数的一般项是...
现在轮到你了。通过做下面的练习来完成这个句子。

练习:
2.1 弄清楚 exp x 的级数,并证明它确实如此。 解答
2.2 设定一个电子表格,使用你的级数计算它直到第 100 项为止。 解答
2.3 对于 x = 1,你需要多少项才能获得 10 位的精度? 解答
2.4 随机选择一个 x 并用电子表格计算 (exp x)(exp(-x))。你得到什么?(exp 3x)(exp(-x))³呢? 解答
对于任何函数,如果它是自己的导数或其导数是它的一个常数倍数,那么都可以获得相同类型的级数解。
这一事实使我们能够证明 指数函数的基本性质。
这些是 exp(x + r) 和 exp rx 的替代表达式。
exp(x + r) 的导数是它自己,但在 x = 0 时值为 exp r;
exp rx 在 x = 0 处的值为 1,但其导数为 r 乘以它自身。
这两个陈述都是导数的链式法则的直接结果,这将在第七章中详细讨论。
给定一个正数\(a\),我们可以通过将\(n\)个\(a\)的因子相乘来计算任意整数\(n\)的\(a^n\)。我们可以定义\(a^{(1/n)}\)为\(a^n\)的逆函数。我们可以定义\(a^{(m/n)}\)为\(a^{(1/n)}\)的\(m\)个因子的乘积。因此我们可以为任意有理数\(r\)定义\(a^r\)。
但我们如何定义无理数\(r\)的\(a^r\)呢?
我们可以证明,对于任意有理数幂\(r\),有 暂时就这样接受吧。
暂时就这样接受吧。
我们现在将明确地定义\(x^r\),以便它具有相同的性质。
我们需要的条件是它的导数是自身乘以
这意味着根据链式法则, 必须具有导数为
必须具有导数为 乘以 exp x 的导数,而后者是 exp x。因此,的导数必须是自身的 r 倍。
乘以 exp x 的导数,而后者是 exp x。因此,的导数必须是自身的 r 倍。
但这恰恰就是\(\exp rx\)的导数。当\(x\)为 0 时,这两个函数都是 1。
这意味着它们必须有相同的幂级数展开,因此必须是相同的函数!
所以我们有了我们对\(\exp rx\)的替代表达式,并且一下子定义了无理数次幂。至于\(\exp(x + r)\)呢?轮到你了。
练习 2.5:陈述并证明这些基本性质,即,表达式 exp(x + r)和 exp rx。(提示:它们在 x = 0 时有什么值?它们的导数是什么?从这些陈述中推导出它们的级数并识别它们。) 解答
由于我们有\(\exp rx = (\exp x)^r\),对于任何\(x\),我们可以将其应用于\(x = 1\),利用我们总是可以写成\(r = 1 * r\)的事实,来注意到:\(\exp r = (\exp 1)^r\)。
习惯上我们定义\(e = \exp 1\),这样我们可以写成\(\exp r = e^r\)。
表达式\(e^a\)在 99%的情况下都是指\(\exp a\)。事实上,使用符号\(\exp a\)的主要用途是当使用上标不方便时,比如在打字或机器输入时,特别是当\(a\)有上标或下标时。计算机和电子表格使用\(e^a\)的符号表示,这样可以避免上标,但不美观。
2.2 三角函数
正弦在直角三角形中是对边长度与斜边长度的比。
如果斜边长度为 1,那么 sin 就是三角形的对边长度。
就是三角形的对边长度。
如果角度很小,单位斜边对应的对边长度接近但小于单位圆周围两边的距离;而这个距离就是弧度中的角度大小。
因此,对于小角度,正弦略小于以弧度表示的角度本身。
余弦的补角被称为余弦\(x\),并写为\(\cos x\)。

下面的小程序可以帮助您可视化正弦和余弦代表单位圆上位置的 x 和 y 分量,作为角度(用弧度表示)的函数。它下面的图片显示了各种三角函数的大小表示为图中线段的长度的含义。
还有其他四个三角函数的几何定义如此处的插图所示

它们彼此相关,可以从图中通过观察相似三角形推断出来。
角 OAC、OBE 和 DBC 都等于。
sin = DB = OE,
tan = BC,
sec = OC,
cos = OD = EB,
cot = AB,
csc = OA
因此,第一象限中角的切线是垂直于该角的一边,在距其中心 1 的地方到另一边的切线的长度。
该象限中的角的正割是从其中心到与该角的一边距离为 1 的切线在该角的另一边的交点的线段的长度。
每个这些函数都有对应的余弦函数,对于余角来说是相同的。 在其他象限中,它们有适当的符号。
练习:
2.6 通过使用相似三角形推导出这些函数之间的关系。 解答
2.7 在不同象限中,每个函数的适当符号是什么? 解答
2.8 找出(tan x� + cot x)²的另一种表达式。 解答
2.9 哪些三角形与 OBD 相似? 解答
2.3 三角函数的性质
重要的性质有:
勾股定理(这实际上是我们下面讨论的距离的定义)。
加法定理,即 sin(a + b)和 cos(a + b)的表达式。
半角定理(前两者的推论)。
所有三角函数仅取决于角度模 2 的值 。
。
正弦定理:在三角形 ABC 中,长度 AB 和 AC 的比是相对角的正弦比: 。这只是事实,ABsin B 和 ACsin C 都等于 AH。
。这只是事实,ABsin B 和 ACsin C 都等于 AH。

余弦定理。(参见练习 3.5)
在原点为中心的单位圆上,角度为 的点的坐标是 (cos, sin),这意味着 y = sin,x = cos。
通过原点的单位圆的切线穿过 (x, y) 垂直于从中心到 (x, y) 的线,并指向第一象限的 y 轴。其方向由 (-sin, cos) 给出。
所有性质都可以从正弦的微分性质中得出。
目前我们假设

然后使用

我们得到

这两个声明结合起来告诉我们,如果我们两次对 sin x 进行微分,我们得到 -sin x;三次微分得到 -cos x,四次回到我们从 sin x 开始的地方。
并且我们有 cos 0 = 1,sin 0 = 0。
所以我们有 sin 0 = 0,(sin 0)' = 1,(sin� 0 )" = 0,(sin 0)''' = -1,并且进一步的导数在参数为 0 时重复为 (从起始点 0 1 0 -1 0 1 0 -1 0 1 0 -1,等等)。
这些信息确定了 x 的正弦的幂级数公式。
常数项必须为 0;线性项 x,二次项 0,三次项  ,继续下去,所有偶次幂项必须为 0,并且奇次幂项必须交替出现,并且除此之外就像 exp x 的级数展开中的那样。
,继续下去,所有偶次幂项必须为 0,并且奇次幂项必须交替出现,并且除此之外就像 exp x 的级数展开中的那样。
所有这些都是因为单项式 x^k 在 x = 0 处的所有导数都为 0,除了第 k 个导数为 k!因此,我们可以从在 0 处的导数值序列中读取正弦的幂级数。
我们得到

同样地

这意味着
exp ix = cos x + i sin x���� (A)
因此,我们可以使用指数函数的性质推导三角函数的性质。
例如,正弦和余弦的加法定理可以推导如下
exp i(a+b) = cos (a + b) + i sin( a + b) = (exp ia) * (exp ib)
= cos a cos b � sin a sin b + i(cos a sin b + cos b sin a)
对这些表达式进行实部和虚部的识别给出了加法公式。
练习:
2.10�推导出以 exp ix 和 exp(-ix) 表示的 sin x 和 cos x 的公式,该公式源于上述方程(A)。 解答
2.11 从勾股定理和余弦加法定理中找出 (sin t/2)² 和 (cos t/2)² 的表达式。 解答
2.12 设置一个电子表格来计算任意输入 x 的 sin x。需要评估 sin .5 到 8 位小数的 sin x 幂级数展开需要多少项? 解决方案
2.4 对数
自然对数,表示为ln x,是指数函数 exp x 的反函数。
它实际上在许多情境中自然出现。它有两个重要性质,可以从指数的两个基本性质推导出来。
ln x 的定义可以这样表述:它是你必须将 e 提升到的幂次方,以便得到 x:e^(ln x) = x = e ^(ln x)。
我们经常将其他数字,特别是 2 和 10,提升到幂次方,并通常会问:为了得到 x,你必须将 z 提升到什么幂次方? 答案被称为以 z 为底 x 的对数,写作 log [z] x。它是 z^x = z^x 的反函数。
上述提到的两个重要性质可以写成
ln ab = ln a + ln b
和
log[a]b * log[b]c = log[a]c 对于任何 a、b 和 c

练习:
2.13 推导它们。(我必须承认,我总是被糟糕的符号搞混,但我相信你们,年轻又聪明,能够做到。) 解决方案
2.14 从这两个方程推导出对于任何基数的对数我们有 log ab = log a + log b。 解决方案
第一个性质或者说练习 2.13 的结果意味着我们可以通过取 a 和 b 的对数,将它们相加,然后从其对数中检索出 ab 来执行乘法。因此,乘法可以简化为加法和取对数以及“反对数”。
在计算器出现之前,加法和乘法同样困难,这是对对数的一个重要用途,我记得在高中时被迫使用对数表和反对数表进行练习,并且当然要在这些表格中的值之间进行插值。很难想象比这更繁琐的数学事情了,你们这些幸运的家伙!
第三章:向量,点积,矩阵乘法和距离
引言
我们在这里引入向量和矩阵以及点积和矩阵乘法的概念。我们注意到点积在坐标旋转下是不变的,定义了线性依赖性,并描述了极坐标及其在三维中的推广。
主题
3.1 向量
3.2 欧几里得空间中的旋转坐标
3.3 点积
3.4 矩阵乘法
3.5 线性相关性和独立性
3.6 极坐标
3.7 柱面和球面坐标
3.8 关于向量空间中长度和距离的离题讨论
3.1 向量
我们将长度为 k 的数字序列称为 k-向量。
我们将 k-向量之间的加法和减法定义为逐项加法和减法,因此对于 2-向量,我们有
(a, b) + (c, d) = (a + c, b + d)
如果我们在欧几里得平面中选择一个原点 O,我们可以用一个向量来描述平面上的任意点,其第一个分量是点的 x 坐标,第二个是 y 坐标,即 (x, y),一个 2-向量。
我们称第 i 个分量值为 1,其余为 0 的向量为第 i 个方向上的基向量。在普通的三维空间中,x、y 和 z 方向上的基向量分别表示为 i、j 和 k。向量 (x, y, z) 也可以写作 xi + yj + zk。
我们在这里假设基向量彼此垂直,并且每个基向量的长度为单位长度。
3.2 在欧几里得空间中旋转坐标
如果我们将基向量 i' 和 j' 按角度  从 i 和 j 旋转(以使 i' 方向朝向 j),则固定向量 v 的分量变化如下:
从 i 和 j 旋转(以使 i' 方向朝向 j),则固定向量 v 的分量变化如下:
v[i] 变为
v[i]' = v[i] cos +� v[j] sin
+� v[j] sin
并且 v[j] 变为
v[j]' = - v[i] sin + v[j] cos
这些效果在附带的小程序中有所说明。你可以移动向量,也可以旋转基向量。
3.3 点积
给定两个分量为 R 中元素、具有相同分量数的向量 v 和 w,我们将它们的 点积 定义为 **对应分量的乘积之和,写作 v w 或 (v, w),如
w 或 (v, w),如  .。
.。
显而易见的事实:点积在 v 和 w 中是线性的,并且在它们之间是对称的。
我们定义 v 的长度 为 (v, v) 的正平方根;v 的长度 通常用 |v| 表示。
奇妙的事实:点积在坐标旋转下保持不变。
练习 3.1 证明此陈述。 解答
由于这个事实,当评估vw时,我们可以旋转坐标,使第一个基向量指向v的方向,第二个基向量垂直于在v和w的平面上。
**那么 v 将具有前两个坐标(|v|, 0),如果 v 和 w 之间的角度为 ,则 w 将具有定义类似的坐标(|w|cos,|w|sin)。
因此,点积 v****w** 在此坐标系(即具有这些基向量的坐标系)中为 |v||w| cos,因此在通过从中旋转得到的任何坐标系中也是如此。
点积在每个参数上是线性的这一事实非常重要和有价值。这意味着您可以在任一参数上应用分配律来表示和差的点积为点积的和或差。
示例
练习 3.2 用点积表达具有 v 和 w 为边的平行四边形的面积的平方。 解答
v 和 w 的点积除以 w 的大小,即 |v|cos,称为 v 在 w 方向上的分量。
与 w 方向的矢量,其大小和符号为 |v|cos,被称为 v 在 w 上的投影。
从 v 在 w 上的投影中减去 v 得到的矢量称为 v 垂直于 w 的投影 或 w 的法向量。(按定义,此投影在 w 方向上的分量为零,因此法线于 w。)
练习:
3.3 用点积表达 v 在 w 方向上分量的平方。 解答
3.4 用点积表达 v 垂直于 w 方向上的分量。 解答
3.5 利用点积在每个参数上的线性性质,写出 (v - w)****(v - w)。这建立了哪个著名定律? 解答
3.6 用点积和向量 w 表达 v 在 w 上的投影。 解答
3.4 矩阵乘法
一个数字的矩形数组,比如 n 行 m 列,被称为一个矩阵。矩阵 A 的第 i-j 个元素是第 i 行第 j 列的元素,并表示为 A[ij]。
这里有两个矩阵的示例,一个是 2 行 2 列,另一个是 2 行 3 列


如果矩阵 A 的列数与 B 的行数相同,我们定义乘积矩阵 AB 为 A 的行与 B 的列之间的点积。通过取 A 的第 i 行和 B 的第 j 列的点积得到的元素描述为 (AB)[ij]。 详见第 32.2 节以获取有关矩阵及其属性的更全面讨论。
练习:
3.7 找到上述两个矩阵的乘积。
3.8 构建一个可以将 4 行 4 列矩阵相乘的电子表格。 解决方案
3.9 在练习 3.8 中:
1. 矩阵乘积 AB 在哪里?
2. 在前四行中列 p、q、r 和 s 中出现了什么?
如果更改 A 或 B 中的任何条目,乘积将自动更改,因此您已经构建了一个 4 行 4 列的矩阵自动乘积查找器。
3. 你能用这个方法找到一个 2 行 3 列矩阵和一个 3 行 4 列矩阵的乘积吗?如何做?
4. 使用您的乘积查找器找到矩阵 A 的十次幂。(提示:对 A 和 B 使用它,并在正确的位置查找,您将找到它。)
向量 v 可以被写成由单行组成的矩阵,或由单列组成的矩阵。当将其写为列时,我们将写为 |v>;当写为行时,<v|。然后,向量 v 的长度的平方可以写为矩阵乘积 <v||v>。
当 Mv 是 v 的倍数时,向量 v 是矩阵 M 的特征向量。倍数称为 M 具有特征向量 v 的特征值。如果特征值为 s,则我们有 Mv = sv。
此处的小程序允许您输入任意 2 行 2 列的矩阵,并移动向量v。当 Mv 与 v 对齐时,v 是 M 的特征向量,其实数特征值由 Mv 的长度(在小程序中称为v')与 v 的长度之比给出,当它们指向相同方向时,符号为正。
练习 3.10 选择一个对称矩阵,并使用小程序近似确定两个特征向量。在纸上画出它们。你能注意到什么?是什么?
3.5 线性相关性和独立性
向量 v(1) 到 v(k) 之间的线性相关性是一个方程, 其中一些 c 不为 0。如果一组向量之间没有线性相关性,则称为线性独立,如果存在一个或多个线性相关性,则称为线性相关。
其中一些 c 不为 0。如果一组向量之间没有线性相关性,则称为线性独立,如果存在一个或多个线性相关性,则称为线性相关。
例子:假设 v(1) = i + j;v(2) =2i;v(3) = 3j。
那么 v(1), v(2) 和 v(3) 线性相关,因为存在关系
6v(1) = 3v(2) + 2v(3), 或者 6v(1) - 3v(2) - 2v(3) = 0
练习 3.11 证明:任何 k + 1 个 k-向量都是线性相关的。(你可以通过使用数学归纳法来做到这一点。)(如果你不熟悉数学归纳法,请阅读这个解决方案并熟悉一下!) 解答
3.6 极坐标
一个二维向量 (x, y) 可以由两个不是求和系数的数字描述:它的长度和它的向量与 x 轴的角度。
这两者中的第一个通常写作 r,第二个写作 。**
**这些参数遵循 
逆关系是 
r 和 被称为极坐标。**
计算极坐标中的角度 有点棘手;显而易见的尝试是 atan(y, x) 但是它只定义在  到
到  之间,而 的定义域大小为 2
之间,而 的定义域大小为 2 。
。
这里有一个有效的方法:
这给出了范围为 - 到 的 theta。如果你想要它的范围为 0 到 2,你可以给它添加 if(y < 0,8 * atan(1), 0)。

3.7 圆柱坐标和球坐标
在三维中有两个极坐标的类比。
在圆柱坐标中,x 和 y 被 r 和 正好像在二维中一样描述,而第三维度 z 被视为普通坐标。
r 然后表示到 z 轴的距离。
在球坐标系中, 一个一般的点由两个角度和一个径向变量描述, ,代表到原点的距离:
,代表到原点的距离:
这两个角度变量与经度和纬度相关,但纬度在赤道为零,而我们使用的变量  在 z 轴上为零(这意味着在北极)。
在 z 轴上为零(这意味着在北极)。
我们定义  ,以使得 r 总是由
,以使得 r 总是由  这里定义
这里定义
经度角由 定义,与二维情况完全相同。 因此我们有
定义,与二维情况完全相同。 因此我们有 ,y 是什么?
,y 是什么?
练习:
3.12 用 x、y 和 z 表示柱面和球面坐标的参数。
3.13 构建一个电子表格转换器,将坐标 x、y 和 z 转换为球面坐标的三个参数;反之亦然。通过将一个的结果替换为另一个的输入来验证它们的工作。
3.8 �关于向量空间中长度和距离的离题
两个向量v和w之间的距离是差向量v - w的长度。
在世界上你会遇到许多不同的距离函数。我们这里使用“欧几里得距离”,其中我们使用勾股定理。
如果距离和长度的概念在没有额外描述的情况下被使用,这就是我们的意思:
向量 w 的长度的平方是其分量的平方之和(或更一般地说,当分量为复数时,是其绝对值的平方之和)。它是点积(w,w)或 ww。
但这并不是你在生活中会遇到的唯一距离概念。
向量的长度应具有哪些性质?
传统的要求如下:
它应为正,并且对于零向量为零。
它应遵守三角不等式:两个向量的和的长度不大于它们长度之和。
如果长度为 0,则向量为(0)向量。
还有哪些长度或距离概念存在?
曼哈顿距离: 向量的长度是其分量的绝对值之和。
汉明距离: 长度是非零分量的数量。
最大分量距离: 长度是最大分量的绝对值。
假设我们称分量为 x[i],任何一个 dx[i]的小量,以及具有分量 dx[i]的距离值,我们称之为 ds。
然后在欧几里得空间中我们有 。我们定义度量
。我们定义度量 。**
。**
欧几里得空间可以被描述为L[2]。
练习 3.14 在 L[j]的定义中,哪些 j 值对应于汉明、曼哈顿和最大分量大小?(提示:j 可以是无穷大;对于汉明距离,概念类似但并非完全相同,并且仅在极限情况下类似。)
在使用非直角坐标时的欧几里得空间中的长度:
当你用极坐标描述欧几里得空间中的普通向量时,这些向量不遵守普通直角坐标的线性性质。例如,两个向量的和的长度不是它们长度的和,和的角度与 x 轴的角度也不是和的角度的和。
我们可以问,一个小向量的长度是多少,其端点之间的坐标差为 r 坐标 dr,角度差为 d?
如果我们在具有给定坐标的特定点,r 方向是指向远离原点朝向该点的方向,这个方向上的距离的测量方式与 x 或 y 方向上的测量方式相同。在这个方向上,具有坐标 dr 的向量的长度是|dr|。
方向垂直于 r 方向,逆时针方向增加,但距离不是 d。圆周的周长与圆的半径成比例,因此角向的距离也与 r 成比例。
结果是,极坐标中的距离由以下方式测量

非正交坐标中的长度:
任何 k 个线性无关的 k-向量都可以用作基础:任何其他 k-向量都可以表示为它们的线性组合。(为什么?通过练习 3.11,任何其他 k-向量与它们线性相关,可以用基础来解决该 k-向量。)
因此,在二维空间中,例如,任意两个具有不同方向的向量a和b可以形成基础,任何向量v都可以用这两个向量的系数来描述:如果v = s a + t b,那么我们可以用 2-向量(s,t)来描述v。
然而,如果我们描述欧几里得空间,向量a和b不是正交的,那么v的长度平方将不是 s² + t²。总的来说,如果我们定义(s,t)为v',我们得到长度平方为<v'|G|v'>,其中矩阵 G 取决于a和b之间的角度。
因此,如果a和b是夹角为的单位向量,则矩阵 G 为

矩阵 G 被称为给定基础的度量张量。
不同的度量:闵可夫斯基空间:
甚至有些向量空间中,距离的概念被可以是正的或虚的东西所取代:这就是闵可夫斯基空间:它有四个维度,三个空间维度和一个时间维度。在其中,距离的类比由��描述。
ds² = dx² + dy² + dz² �c²dt²
具有正或负 s²的向量被称为空间样或时间样;s² = 0 的向量被称为位于“光锥”上。
为什么有人要费心研究这些?
在欧几里得空间中,坐标的线性变化具有不改变距离的特性(使得两点之间的距离在变化后仍然保持不变),这些变化称为空间中的旋转。在闵可夫斯基空间中类似的变化是麦克斯韦电动力学方程的对称性,并且对应于空间中的旋转和“洛伦兹变换”。因此,即使是最后这个概念也具有重要的物理应用。所有其他概念在适当的情境下也是如此。
第四章:平行四边形的面积、行列式、体积和超体积,向量积
引言
我们考虑平行四边形的面积和平行六面体的体积以及二维和三维中行列向量作为边的图形的行列式概念。然后我们考虑矩阵应用于描述向量上的线性变换,并评估行列式的方法。
我们进一步讨论了矩阵的逆的概念以及如何计算它,引入了特征值和特征方程的概念,以及向量或叉乘。
主题
4.1 二维和三维中的面积、体积和行列式
4.2 矩阵和向量上的变换;零行列式的含义
4.3 通过高斯消元和通过行或列展开来评估行列式
4.4 行列式和矩阵的逆
4.5 向量积
4.6 特征值和矩阵的特征方程
4.1 二维和三维中的面积、体积和行列式
在二维空间中,由向量v和w限定的平行四边形的面积有一个简单的公式,其中v = (a, b)和w = (c, d):即 ad - bc
ad - bc
为什么会这样?
1. 如果 b 和 c 为 0,那么以向量(a, b)和(c, d)为边的平行四边形的面积是|ad - bc|显然成立,因为平行四边形是边长为|a|和|d|的矩形,其面积为|ad|。
2. 如果我们给(a, b)或(c, d)添加它们的倍数,面积和ad - bc都不会改变。平行四边形只是倾斜,其底和高保持不变。例如,如果我们给 c 加上 a,那么 ad - bc 就变成 ad - b(c + a),所以是-ba;但是如果给 d 加上 b,则产生的变化是 ab 到它;a(b + d) - b(c + a) = ad - bc,变化的净值为 0。
3. 从任意的 a、b、c 和 d 开始,通过反复添加其中一个行的倍数到另一个行,我们可以使 b 和 c 变为 0,之后我们就处于第一段考虑的情况,我们知道面积是|ad - bc|。
4. 由于这些添加没有改变面积,也没有改变|ad - bc|,所以这些必须从一开始就是相同的。
矩阵的行是(a,b)和(c,d)的矩阵的组合ad - bc称为行列式。通常写成

给定三维空间中的三个向量,我们可以形成一个 3×3 矩阵,其元素为它们的分量,并且我们将看到该矩阵的行列式的绝对值是由这三个向量确定的平行六面体的体积。
实际上,对于 k k-向量,类似的结果成立:它们的分量矩阵的行列式的绝对值是它们所界定的图形的 k-体积。
那么一个矩阵的行列式是什么呢?
在任何维度中,行列式的定义如下:
1. 行列式对任意行(或列)的元素是线性的,因此将该行中的所有元素乘以 z 会使行列式乘以 z,并且行为 v 和 w 的行列式等于除了该行为 v 和该行为 w 的行列式之外的所有其他行的行列式之和。
2. 如果两行交换,则行列式的符号会改变(等价条件是如果两行相同则行列式为 0)。
3. 对角线为 1,其他位置为 0 的矩阵的行列式为 1。
k×k 矩阵的行列式的另一个定义是它是 k 维度中体积的“带符号”版本,因此是线性的。
行列式通常写作 det M 或| M |,有时候也写作|| M ||。
如果 v 和 w 是矩阵 M 的两行,我们可以从前两个条件推断,将 v 的倍数添加到 w 不会改变 M 的行列式。
由 u,v 和 w 的方向和长度确定的平行六面体的体积几乎与 u,v 和 w 成线性关系;它与线性度的不同之处仅在于它总是正的,就像一维中的长度一样。
如果向量长度为单位长度并且相互垂直,则该体积为 1,并且如果将一边加到另一边,则不会改变;(这只是使平行六面体倾斜而不改变其体积。)由这三个向量的分量形成的矩阵的行列式的绝对值完全遵循相同的条件,因此是同一件事情。
在更高维度中,体积的类比被称为超体积,通过相同的论证可以得出相同的结论:由 k 维度中的 k 个向量确定的平行边区域的超体积是行列式的绝对值,其元素是它们在(标准正交)基向量方向上的分量。
实际上,行列式可以被认为是超体积的线性和带符号版本。
考虑一个以 x 为变量的平行边区域的超体积。对于正或负的 x,它对 x 是线性的,但它总是正的,并且其图形看起来像一个 V,对于 x = 0 取值为 0。
行列式对于正或负的 x 是相同的超体积,对于另一个 x 是超体积的负,且对 x 是线性的。其符号由约定确定,即对于具有对角线为 1 且其他位置为 0 的“单位矩阵”,其行列式为正。该单位矩阵通常写作 I。
练习:
4.0 证明上述论断:行列式在两行交换时改变符号的条件等价于另一条件,即当两行相同时行列式为 0(考虑到它对行的线性性质)。
4.1 假设 A、B 和 C 是平面上的三个向量。考虑三个三角形,其边分别是 A 和 B、A 和 C、A 和 B + C。它们的面积之间存在什么关系?(如果你没有看到,尝试一些简单的例子并推广。这里寻求的关系是一个或另一个的陈述。)关于行列式,其行是给定向量的分量(A 和 B)、(A 和 C)和(A 和 B + C)的,类似的陈述是什么?
在下面的小程序中,您可以输入三个 3 维向量,看到它们及其定义的平行六面体,以及其绝对值为体积的行列式的值。我们很快将看到如何计算行列式。还显示了这些向量(或叉乘)对的向量积,它们将在4.5 节中定义。
4.2 矩阵和向量的变换;0 行列式的含义
矩阵和行列式在另外两个重要的情境中出现;一个是在解多个变量的同时线性方程组时。另一个是在表示向量的线性变换时。其中第一个在第三十二章中有详细讨论。
在后一情境中,矩阵表示将列基向量转换为矩阵对应列的向量的转换。
原始基向量的和被转换为相应列的相同和。 这一事实定义了所有向量的变换。
当矩阵的行列式为零时,由其列或行给出的区域的体积为零,这意味着将基向量转换为线性相关的向量,并定义 0 体积的矩阵被考虑为一种转换。
当矩阵的列(和行)线性相关时,行列式为零。
练习:
4.2 哪个矩阵描述了将 x 轴方向的单位向量转换为 y 轴方向的单位向量,类似地,将 y 轴方向的单位向量转换为 z 轴方向的单位向量,将 z 轴方向的单位向量转换为 x 轴方向的单位向量?
4.3 哪个矩阵描述了将向量在 x 方向的分量加倍,y 方向的分量减半,而 z 方向的分量保持不变的转换。
4.4 哪个矩阵描述了将向量投影到(x,y)平面的三维转换?投影到 x 轴?投影到(x,y)平面上的对角线?
4.3 通过高斯消元和通过行或列展开来评估行列式
这一部分非常简略。有关更多讨论,请参见第三十二章。
通过高斯消元法求行列式: 通过将一行的倍数加到另一行,直到主对角线下的所有条目为 0,来进行这个操作。行列式(这些操作不会改变行列式)然后是对角线条目的乘积。机器可以对数百或数千的 n 阶矩阵进行这样的操作,但人们觉得这个练习有点乏味。
行列式在行或列中的展开: 让矩阵 M 具有元素 m[ij]。第一个索引描述行号,第二个描述列号。
M 的行列式是任意单行元素乘以一个因子的和。什么因子?
对于第 i 行的第 j 个元素,它是通过去掉该行和列得到的矩阵的行列式,乘以一个符号因子-1 到元素的索引之和,i + j

其中M[ij]是通过消除第 i 行和第 j 列并将其余部分合并成一个方阵得到的矩阵的行列式。
为什么会这样?
乘以 m[ij]的因子必须是其他行中的线性因子,并且如果其中两行相同,则必须为 0,因此它必须与它们的行列式 M[ij]成比例。(还因为行列式对第 j 列是线性的,所以这个项除了来自该列的 m[ij]外不能有其他因子。)
那么,唯一剩下的问题是:为什么有符号因子?
当矩阵的两行或两列具有相同奇偶性(这意味着两者都有偶数索引或奇数索引)时,您可以通过偶数次单行或单列交换来交换它们,而当它们具有相反奇偶性时,您需要奇数次交换。每次交换都需要一个符号变化,因此如果行和列索引的奇偶性不同,必须有一个符号变化,以使不同索引的计算保持一致。
注意我们还有

因为根据方程(A),这是一个矩阵的行列式,其中两行,第 i 行和第 k 行,等于 M 的第 k 行,而两个相同的行的矩阵行列式为 0。
公式(A)称为在第 i 行中展开 det M。同样的操作也可以在列中进行,甚至可以同时对几行或几列进行。
表达式(-1)^(i + j)M[ij]被称为矩阵 M 的 ij-th 余子式。然后可以表述为:M 的任意一行与该行中条目的余子式向量的点积是 M 的行列式。 如果将“行”替换为“列”,同样的陈述也成立。
练习:
4.5 评估矩阵的行列式,其行依次为(1, 2, 5),(3, 1, -2)和(4, -2, 7),使用上述每种方法。你觉得哪种方法更快?
4.6. 对于一个随机但非平凡的 4 乘 4 矩阵,做同样的事情。哪个更快?
4.4 矩阵的行列式和逆矩阵
方阵 M 的逆矩阵是一个矩阵,表示为 M^(-1),满足 M^(-1) M = M M^(-1) = I。这里的 I 是与 M 相同大小的单位矩阵,对角线上为 1,其它位置为 0。
就变换而言,M^(-1)撤消了 M 产生的变换,因此组合 M^(-1)M 代表了什么变换都没有改变。
条件 MM^(-1) = I 可以写成

和

当 k 和 i 不同时,这些条件完全确定了给定 M 时矩阵 M^(-1),当 M 具有逆时。
这些方程与 4.3 节的两个条件(A)和(B)具有相同的形式,不同之处在于在(A)中行列式 det M 位于左边,而不是 1,在(A)和(B)中出现的是(-1)^(i + j)M[ij],而不是 M^(-1)[ji]。
因此我们可以将(A)和(B)两边都除以 det M,推导出

记住这里 M[ij]是通过省略 M 的第 i 行和第 j 列而得到的矩阵的行列式;M 的元素是 m[ij],而 M^(-1)[ji]代表的是 M 的逆矩阵中第 j 行第 i 列的元素。
我们可以用文字表达为:矩阵 M 的逆是其代数余子式组成的矩阵,行列互换,除以其行列式。
练习:
4.7 使用这个公式计算 练习 4.4 中矩阵的逆。检查乘积 M^(-1)M 以确保结果正确。
**4.8 设置一个电子表格,使用这个公式计算任意非零行列式的三乘三矩阵的逆。
(提示:通过将前两行复制到第四行和第五行,将前两列复制到第四列和第五列,你可以一次性获得所有的(-1)^(i + j)M[ij]。然后剩下的就是重新排列以交换指标,并除以行列式(行列式是 M 的任意一行与相应余子式的点乘)。)**
4.5 向量积
两个 3 维向量v和w的向量积,记作v w,是一个 3 乘 3 矩阵的行列式,其前两列是向量v和w的分量,第三列是基向量i, j和k。
w,是一个 3 乘 3 矩阵的行列式,其前两列是向量v和w的分量,第三列是基向量i, j和k。
这个定义看起来有些神秘。但它的意思只是在各个轴方向上的分量是这里的 i, j,和k的代数余子式。这些是普通二乘二矩阵的行列式。
vw是一个向量而不是一个数,有时被称为“叉乘”的v和w的结果。
从这个定义中,我们可以看到vw与另一个向量u的点积是一个矩阵的行列式,这个矩阵的列(或行)是这三个向量的分量,按照v, w, u的顺序排列,这使得它的大小成为由这些向量确定的平行六面体的体积。
明确地,叉乘的 x 分量为 。
。
其他分量可以通过在变量 x、y 和 z 之间循环移位来获得,将 x 变为 y,y 变为 z,z 变为 x。
向量积是根据行列式的性质对其向量因子都是线性的。因此,如果你将v乘以 10,vw也会乘以 10,而且你还有
(v + z)w = vw + zw
此外,vw如果其因子的顺序颠倒,则会改变符号:vw = - wv。这些陈述源自行列式的类似性质。
vw 的大小是由其因子定义的平行四边形的面积,即

vw垂直于其两个参数:vw v = vww = 0。这是因为具有两个相同列的矩阵的行列式为 0。
v = vww = 0。这是因为具有两个相同列的矩阵的行列式为 0。
我们可以推断(vw) (vw) = (vv)(ww) - (vw)(wv), 因为这两边代表的是以v和w为边的平行四边形的面积的平方(见 Exercise 3.2)。
人类在计算 3x3 行列式或向量积时,大约每四次中就会出现数值错误,尤其是当向量分量或矩阵条目具有许多负值时。在电子表格上建立一个行列式和向量积工具,并用它来检查而不是替换你自己的计算是明智的。这样你每次都会得到正确的答案。
实际上,构建这样一个工具比手动进行叉乘要容易得多。这几乎和进行点积一样容易。要做到这一点,将 v 和 w 输入为两个平行行,比如将 v[x] 放在 A2,v[y] 放在 B2,v[z] 放在 C2,以及类似地将 w 的分量放在 A3-C3。在 D2 中输入 =A2,并将其复制到 D3、E2 和 E3。 (你现在完成了一半。)接下来,在 A4 中输入 =B2C3-C2B3,并将其复制到 B4 和 C4。就是这样!第四行包含 vw,v 与 w 的叉乘。你可以通过验证它与前两行中的任意一行的点积是否为 0 来检查。
请注意,现在你可以改变 v 和 w,然后(幸运的话)第四行将包含新的第二行和第三行的叉乘。
你可以从第 4.1 节的 applet 中看到向量积的样子。
练习:
4.9 将向量积 vw 明确写出,用其因子的分量表示。
4.10 计算两个向量 (1, 2, 3) 和 (4, 5, 6) 的向量积。
4.11 按照上述指示构建一个向量积工具。
4.6 特征值和矩阵的特征方程
满足 Mv = xv(其中 x 是某个数)的向量称为矩阵 M 的特征向量,x 被称为 M 对应于 v 的特征值。(v 被称为对应于 x 的特征向量。)
条件 Mv = xv 可以重写为 (M - xI)v = 0。这个方程表示矩阵 (M - xI) 将 v 转换为 0 向量,这意味着 (M - xI) 不能有逆矩阵,因此其行列式必须为 0。
方程 det (M - xI) = 0 是给定 M 的变量 x 的多项式方程。它被称为矩阵 M 的特征方程。你可以解它以找到 M 的特征值 x。
方阵 M 的迹,写作 Tr(M),是其对角元素的和。
一个 2x2 矩阵 M 的特征方程形式为
x² - xTr(M) + det M = 0
一旦你知道矩阵 M 的特征值 x,就有一种简单的方法可以找到对应于 x 的列特征向量(当 x 不是特征方程的多重根时有效)。我们将其描述为 3x3 矩阵,但可以推广应用于任何大小的方阵。为此,取 (M - xI) 的任意两行的叉乘。
如果它不是 0 向量,那么它就是列特征向量!
为什么这样做有效?
v 是矩阵 M 的列特征向量的条件是 (M - xI)v = 0。
(M - xI)v 的分量是 (M - xI) 的行与 v 的点积。
如果 v 是 (M - xI) 两行的向量积,那么它肯定与这两行的点积为 0。
另一方面,它与 (M - xI) 的另一行的点积是 (M - xI) 的行列式,也是 0。
我们可以推断出,任意两行的向量积 (M - xI) 与 (M - xI) 的每一行都有 0 的点积,这是v是 M 的一个特征向量,对应于特征值 x 的条件。
问题可能出在哪里呢?嗯,向量积可能是0。如果其中一行是另一行的倍数,这种情况就会发生。如果两个不同的行对都发生了这种情况,这意味着所有行都是彼此的倍数,这意味着垂直于任何非全零行的每个向量都是特征向量。
练习:
4.12 为行 (1, 2) 和 (3, 4) 的矩阵写出特征方程。
4.13 对于行 (1, 2, 5),(3, 1, -3) 和 (4, -2, -8) 的矩阵也做同样的事情。
4.14 找到该矩阵的一个特征值。(提示:有一个是相当简单的数字。)
4.15 找到与之对应的一个列特征向量。
第五章:二维和三维中的向量与几何
介绍
我们研究了三维空间中的平面和二维和三维空间中的线的各种描述,以及描述点、线和平面之间相互关系的向量的使用。 我们还研究了向量三重积的性质。
主题
5.1 一些问题
5.2 线或平面的表示:初步说明
5.3 二维和三维中线的表示
5.4 三维中平面的表示
5.5 投影与应用
5.6 向量三重积
5.7 关于向量和平面的事实回顾
5.1 一些问题
这里有一些我们将要讨论的问题。
我们如何描述二维中的一条线或三维中的一条线或平面?
如何找到一条线上或平面内的点?
一个点与一个平面之间的距离,或者与一条线?
三维空间中两条斜线之间的距离?
平行线之间的距离?
一个点在一条线或平面上的投影?
所有这些都可以通过适当定义和操纵向量来回答。
5.2 线或平面的表示:初步说明
一个单一线性方程可以用来解出一个变量,其余变量的值用其他变量表示。 它将解的维度降低 1。
因此,三维空间中平面中的点将是一个线性方程的解。在二维中,一个线性方程确定一条线,而在三维中,需要两个方程来确定一条线。
形式为 ax + by + cz = d 的线性方程可以写成点积 v r = d,其中v是向量(a, b, c),r是(x, y, z)。
r = d,其中v是向量(a, b, c),r是(x, y, z)。
因此,对其的解决方案在v方向的分量上都具有相同的值,并且在v的垂直、法向或正交方向上不确定(所有这些词都是指同一件事)。 因此,v是从一个解到另一个解的向量的法线。
线可以通过给出其上的两点的坐标来描述(在任何空间),而平面可以通过给出三个不全位于一条直线上的点的坐标来描述。
此外,我们可以通过给出其上的任意一点和指向其方向的向量来描述一条线。
同样,我们可以通过给出一个点和从该点开始指向平面上其他点的两个线性独立向量来描述平面上的点。
我们现在来研究各种线和平面的各种特征之间的关系。
5.3 二维和三维中线的表示
线 L 上的两点 P[1]和 P[2]确定了 L。
L 可以被参数化描述为具有坐标 P[1] + s * (P[2] - P[1])的点集,其中 s 是某个数字。
(P[2] - P[1])是指向 L 方向的向量。
在二维空间中,向量是二维向量,只有一个垂直于 L 的方向,并且可以通过交换(P[2] - P[1])的坐标并改变一个符号来获得该方向(因此(7,-4)垂直于(4,7))。
使用垂直向量N,线的方程变为Nr = NP[1].
我们明确地做出了这个。L 由遵守的点组成
x� = P[1x]� + s * (P[2x] - P[1x] )
y� = P[1y]� + s * (P[2y] - P[1y] )
而 L 的方程是
(P[2y] - P[1y] ) x - (P[2x] - P[1x] )y = (P[2y] - P[1y] )P[1x] - (P[2x] - P[1x] )P[1y]
当求解 y 时:
 对于某个常数 C。
对于某个常数 C。
比值 ,即线的方程中 x 的系数,是两点的 y 坐标之差除以 x 坐标之差。 它被称为线 L 的斜率。
,即线的方程中 x 的系数,是两点的 y 坐标之差除以 x 坐标之差。 它被称为线 L 的斜率。
常数 C 称为线 L 的 y 截距。它是 L 与 y 轴相交的地方的 y 值。
在三维空间中,一条直线由两个方程确定。您可以像上面那样参数化描述它(尽管现在所有点和向量都有三个分量),但是您必须找到(P[2] - P[1])的两个垂直向量以找到表征它的方程。您可以自由选择这样做,但是两个方便的选择是:
**i**** ( P[2] - P[1]) ** 和 j(P[2] - P[1])
( P[2] - P[1]) ** 和 j(P[2] - P[1])
您可以要求这两者与r(回忆r =(x,y,z))的点积与P[1]相同。这给您提供了两个共同确定直线的方程。
从方程中找到一条直线上的点,您可以任意固定一个坐标,然后解另外两个坐标的方程。
以下小程序允许您输入任意两点。然后,它会显示您的点确定的三维空间中的直线,以及该直线的参数表示。
练习 5.1 找出此小程序中默认直线的两个方程。然后选择两个随机点,并找出它们所在直线的两个方程。
5.4 三维空间中的平面表示
我们现在解决问题:用点,一个点和一个向量,或者一个方程来描述平面的不同方法之间的关系是什么?
假设点P[1], P[2,] P[3]位于平面 Q 上,它们不全在一条直线上。
然后向量 P[2] - P[1] 和 P[3] - P[1] 在 Q 中具有方向,Q 中的任意点将具有 P[1] + s (P[2] - P[1]) + t (P[3] - P[1]) 的坐标,其中 s 和 t 是一对值。
这被称为具有参数 s 和 t 的平面的"参数化"表示。
(s 和 t 可以被认为是在由 (P[2] - P[1]) 和 (P[3] - P[1]) 给定的基底中的平面上的点的分量。)
你可以通过取叉积 (P[2] - P[1])(P[3] - P[1]) 来计算 Q 的法线。
我们通过定义缩写来简化
N = (P[2] - P[1])(P[3] - P[1]) = P[2]P[3] + P[3]P[1] +P[1]P[2]
因此平面的方程为
N****P = NP[1]
其中 P = (x, y, z)。
您可以明确写出这个方程
N[x] x + N[y] y + N[z] z = (N, P[1]) = (N[x]P[1x] + N[y]P[1y] + N[z]P[1z])
通常,但不是必要的对 N 进行 "标准化",即用 n 替换它,其中 
在实践中,平面通常由一个法向量描述,如这里的 n,以及其中的一个点。
我们从三个点开始,从中得到了平面的参数表示。然后从该表示中找到描述平面的方程。
如果我们可以通过这个方程从 Q 的描述回到三个点,我们将能够完全绕一圈并从任何其他点找到 Q 的任何表示。
Q 中有无限多个点,选择其中三个需要做出任意决定以确定其中三个。
如果 N 的三个分量都非零,我们可以将每对变量设为零并解出第三个。然后三个点将是

这些是平面与三个坐标轴相交的点。
从这些点出发,您可以再次绕圈,确定 Q 的任何表示。
在这个 applet 中,您可以输入三个任意点,它将找到并显示平面,显示 N, (N, P[1]),以及平面上点的参数表示。您可以做所有这些事情,除了制作图片。
练习:
5.2 写出此 applet 中默认平面的方程,并找到在该平面上具有两个 0 坐标的三个点。
5.3 从三个随机点开始,按照这个步骤找到 N 和平面与坐标轴相交的点。
5.4 建立一个电子表格,每当 N 的所有分量都不为零时就执行此操作。
当 N[z]不为零时,我们可以解方程得到平面的方程,NP = NP[1] 关于 x 和 y,得到

这里的 x 和 y 的系数对我们来说特别有趣。如果你固定 y,那么我们的三维空间就变成了一个平面。 然后代表着我们的平面与方程描述的平面的交点处的线的斜率:y = constant。 在这个情况下,交换 x 和 y 后,同样的陈述成立。
然后代表着我们的平面与方程描述的平面的交点处的线的斜率:y = constant。 在这个情况下,交换 x 和 y 后,同样的陈述成立。
5.5 找到您在练习 5.3 和 5.4 中描述的平面的两个斜率(y 固定和 x 固定)。
5.5 投影与应用
如果你从一个点向一条线或平面垂直投影,你到达该线或平面上的点被称为该点到该线或平面的投影。
假设我们有一个点P',一条线 L 和一个平面 Q。假设 L 由两个点P[1]和P[2]描述,Q 由法向量N和一个点P[3]描述。
在将向量概念应用于几何情况时,有一个基本事实是相当简单而极其有用的:
向量 A 在向量 B 上的投影由 给出
给出
为什么会这样?
因为它是一个在 B 方向上的向量,其长度是 A 的长度乘以 A 和 B 之间的角度的余弦,这正是这个投影所代表的。
我们如何利用这个事实?
假设我们想要找到P'到 L 的投影。我们可以将 P'写成P' - P[1] + P[1],其中P' - P[1]是一个向量。如果我们将P' - P[1]投影到P[2] - P[1]上,那么(P[1]加上这个投影)将在 L 上,并且是我们想要的点。
因此答案是

如果我们想要P'到 L 的距离,我们可以从 P'减去这个点。得到的向量的长度就是我们要找的答案。
假设我们想要找到P'到 Q 的距离。这将是P[3] - P'在N上的投影的长度。
P'在 Q 上的投影可以通过将P[3] - P'在N上的投影加到 P'上获得。
两条直线之间的距离就是两条直线上的一个点之间的向量的投影长度,该向量在每个点上的向量的叉乘方向上。如果两条直线是平行的,则这不起作用,因为这里需要的叉乘将是零向量。
如果直线平行,你可以形成一个从一条直线上的一个点到另一条直线上的一个点的向量,将其投影到直线方向的一个向量上,并将这个投影从中减去。得到的向量将垂直于直线,其长度将是所需的距离。
因此,如果你知道如何将一个向量投影到另一个上,并保持头脑清醒,你可以回答 5.1 节中提出的所有几何问题。
练习:
**5.6 绘制一个适当的图片并找到计算以下各项的公式:
然后根据以下输入计算答案:
P' = (1, 2, 3), P[1] = (1, 0, 0), P[2] = (1, 1, 1), P[3] = (-1, 2, -1), N = (2, 1, 4) , P[1]' = (-1, 4, 3), P[2]' = (2, 3, 4), P[1]" = (6, 0, 3), P[2]" = (6, 2, 6).**
5.7. 将点 P' 投影到线 L(包含 P[1] 和 P[2])。
5.8 将点 P' 投影到平面 Q(法线为 N,包含 P[3])。
5.9 点 P' 和 Q 之间的距离。
5.10 点 P' 和线 L 之间的距离。
5.11 三维空间中两条斜线 L 和 L' 之间的距离(包含 P[1]' 和 P[2]')。
5.12 三维空间中两条平行线 L 和 L" 之间的距离(包含 P[1]"和 P[2]")。
5.6 矢量三重积
具有边长 A,B 和 C 的平行六面体的体积是其底面的面积(比如面积为 |BC| 的平行四边形)乘以其高度,即 A 在 BC 方向上的分量。 这就是 ABC; 但它也是由列为 A,B 和 C 的矩阵的行列式,所以这里向量的线性函数是相同的,直到符号相同。 通常的符号约定给出
A(BC) = det(A, B, C)
通过循环排列向量(例如到 B,C,A)或通过反转点积因子的顺序,这个乘积不会改变。
我们可以推断出 ABC = CAB = ABC. 换句话说,我们可以在不改变这个实体的情况下交换点积和叉积。(当然,你必须先进行叉积运算。)与行列式一样,如果你只是反转叉积中的向量,这个乘积会改变符号。
矢量三重积 A(BC) 是一个向量,是法线于 A 和法线于 B****C 的,这意味着它在 B 和 C 的平面上。它在所有三个向量上都是线性的。
我们可以推断它是B的一个关于A和C的线性倍数加上C的一个关于A和B的线性倍数,条件是它与A垂直。
任何B(AC) - C(AB)的倍数都将满足所有这些条件。
什么是A(BC)**的倍数?
假设A(BC) = q(B(AC) - C(AB))成立。
早些时候我们看到一个具有边长为A和B的平行四边形的面积的平方可以写成(AA)( BB) - (AB)( AB)或者(BA)(B****A)。通过在右边的点和第一个叉积处交换,您可以将这个等式重写为
(BA)(BA) = B(A(BA)) =(AA)( BB) ) - (A****B)( AB)
如果我们在A(BC)中将A和C标识为相同的,并且将A(BA)与B进行点积,我们得到 q = 1,然后我们得到
A****(BC)� = B(AC) - C(AB)
这有时被称为后车法则,以便更容易记住适当的符号。当使用这个名称时,请记住这里的括号都尽可能地在表达式的最后。在不记住任何内容的情况下正确获取这里的符号的最简单方法是猜测一个符号,然后在A = i = C,B = j的情况下检查它。
练习 5.13 假设我们有一个三维空间中的向量 A 和一个未知向量 v,但我们知道 Av 和 Av。我们能找到 v 吗?是的!怎么做?
5.7 向量和平面事实回顾
这里是你应该对这些事物感到舒适的关键事实清单。
向量的每个分量分别相加。
通过将向量的每个分量乘以该数字来将向量乘以一个数字。
标量(点)积对每个参数都是线性的(因此您可以在其上使用分配律)。
标量积是通过将相同分量相乘然后求和来计算的。
标量积是两个向量参数的长度与它们之间夹角的余弦的乘积。
行列式在每一行和每一列中都是线性的,其大小是由其列(也由其行)确定的平行四边形或平行六面体的面积。
如果交换其两列,行列式的符号会改变。
作为单个元素 a[ij] 的函数,行列式的形式为 det(A) = ra[ij] + s;(它是一个具有非齐次项的线性函数)
系数 r 是 ij-余子式:从 A 中移除第 i 列和第 j 行后得到的矩阵的行列式,乘以 (-1)^(i+j)。
行列式可以通过行变换或在列或行上展开来求值。
两个向量的向量积是通过将它们的分量作为矩阵的前两列,并取其行列式来获得的向量,其中i, j, k是第三列。
向量积垂直于其向量因子,在三维空间中的大小是它们的平行四边形的面积。它还与其因子向量是线性的。
二维空间中的一条直线可以通过参数方程或线性方程来描述。
三维空间中的平面可以通过方程来描述,或者其点可以通过具有两个线性参数的公式确定。
如果一个平面的方程是 az + by + cx = d,它的方程也可以写成  。
。
量  分别称为 z 在 x 和 y 方向上的斜率。在二维空间中没有 z,斜率类似于
分别称为 z 在 x 和 y 方向上的斜率。在二维空间中没有 z,斜率类似于  。
。
第六章:可微函数、导数和微分
介绍
我们介绍了可微性的概念,讨论了标准函数的可微性以及不可微行为的示例。然后我们描述了两个变量函数的可微性、方向导数、偏导数、切平面和梯度。一些哲学含义也被讨论了。
主题
6.1 可微性、切线-线性近似
6.2 标准函数的可微性
6.3 非可微行为示例
6.4 二维导数:方向导数和偏导数
6.5 切平面和梯度向量
6.6 梯度和方向导数
6.7 哲学含义
6.1 可微性、切线-线性近似
一元实变量函数 f 在参数 x 处被称为可微的,如果其图形在任何包括 x 的开区间内的参数看起来像一条直线。(开区间是不包含其端点的区间。)
它在 x 处的导数是该直线的斜率。
(更确切地说,无论您选择多小的正近标准,都存在一个包含 x 的开区间,以便于该区间中除 x 本身之外的每个 x', 与该直线的斜率之差小于该近标准。)注
与该直线的斜率之差小于该近标准。)注
在参数 x 处,f 类似于的线称为f 在参数 x 处的切线,它表示的线性函数称为f 在参数 x 处的线性近似。
在 x 处切线的斜率由该线上任意两点 P[1] 和 P[2] 的 给出,其中 P[1] = (P[1x], P[1y]),P[2] = (P[2x], P[2y])
给出,其中 P[1] = (P[1x], P[1y]),P[2] = (P[2x], P[2y])
df = P[2y]- P[1y]
dx = P[2x] - P[1x]
我们使用符号dx和df来表示对应变量的变化,这种变化非常小,以至于我们可以假设对于 f(以及定义 f 的任何其他函数)的线性近似是精确的满足(如果没有这样的距离,请在您的想象中创建一个)。
这种变化称为微分。f 在参数 x 处的导数通常写作
实际上,如果 df 和 dx 是微分,那么根据定义,导数是 ,因为导数是线性近似中 f 的变化与 x 的变化的比率。
,因为导数是线性近似中 f 的变化与 x 的变化的比率。
此处的小程序允许您输入任何标准函数和定义域,并查看它,它的斜率和导数。
6.2 标准函数的可导性
所有标准函数在某些奇异点处可导,具体如下:
多项式在所有自变量处可导。
有理函数  在 q(x) = 0 处不可导,函数在那里趋向无穷大。这发生在两种方式中,由
在 q(x) = 0 处不可导,函数在那里趋向无穷大。这发生在两种方式中,由  演示。
演示。
正弦、余弦和指数函数在所有点可导,但正切和割线在某些值处是奇异的。(在哪里?)
诸如 x^(1/2) 和 x^(1/3) 的幂函数的反函数在它们定义的地方可导,除非它们的逆函数在那里的导数为零。
6.3 非可导行为的示例
函数发生跳跃时在跳跃处不可导,也不可导的是具有尖点的函数,就像 |x| 在 x = 0 处那样。
通常,最常见的非可导行为形式涉及函数在 x 处趋向无穷大,或者在 x 处跳跃或出现尖点。
然而也有一些更奇怪的情况。例如,函数 sin(1/x) 在 x = 0 处是奇异的,即使它总是位于 -1 和 1 之间。很难说它在 0 附近的行为如何,但它肯定不像一条直线。
如果函数 f 的形式为  ,如果 h 在那里消失,f 通常会在参数 x 处奇异,h(x) = 0。但是如果 g 在 x 处也消失,那么 f 通常在 x 附近表现良好,尽管严格来说在那里是未定义的。
,如果 h 在那里消失,f 通常会在参数 x 处奇异,h(x) = 0。但是如果 g 在 x 处也消失,那么 f 通常在 x 附近表现良好,尽管严格来说在那里是未定义的。
我们通常在这种情况下定义 x 处的 f 为 x 很接近的地方的线性近似到 g 和 h 的比值,这意味着我们定义 f(x) 为  ,当然,这里的分母不会为零。(如果分母为零且分子也为零,则可以尝试类似地定义 f(x) 为这些导数的比值,依此类推。)
,当然,这里的分母不会为零。(如果分母为零且分子也为零,则可以尝试类似地定义 f(x) 为这些导数的比值,依此类推。)
这种情况,即函数在孤立点处未定义,称为 "可去奇点",刚才讨论的消除它的程序称为 "洛必达法则"。
一个例子是  在 x = 0 处。
在 x = 0 处。





连续但非可导函数



6.4 二维导数:方向导数和偏导数
假设我们有一个两个变量的函数 f(x, y)。
这些东西有时被称为标量场。(标量表示它们不是向量,场表示有两个或更多变量。)
我们可以在 xy 平面中选择一条特定的线(例如 x = x[0] + rcos , y = y[0] + rsin),并考虑 r 的函数(其他所有内容固定):f(x[0] + rcos, y[0] + rsin)。
, y = y[0] + rsin),并考虑 r 的函数(其他所有内容固定):f(x[0] + rcos, y[0] + rsin)。
 然后被称为在 xy 平面上以 tan
然后被称为在 xy 平面上以 tan 斜率方向上在(x[0], y[0])处 f 的方向导数。
斜率方向上在(x[0], y[0])处 f 的方向导数。
换句话说,我们可以通过在 xy 平面中选择任何特定的线,将 f 简化为在该线上定义的单个值的函数,并定义该单变量函数关于该线上的距离的导数。
这个导数称为沿着该线方向的 f 的方向导数。(您可以在 applet 中查看两个变量函数的方向导数。)
f 关于 x 轴方向的方向导数称为关于 x 的偏导数,并写为
类似地,f 在 y 轴方向上的方向导数称为关于 y 的偏导数,并写为
这些偏导数的计算方式与普通一维导数完全相同。计算关于 x 的偏导数时,将 y 视为常数,并且与一维情况下完全相同地对 x 进行微分。
6.5 切平面和梯度向量
我们定义二维可微性如下。如果两个变量的函数 f 在参数(x[0], y[0])处的曲面在(x, y, f)空间中对于接近(x[0], y[0])的参数看起来像一个平面,那么我们称其在该参数处可微。
(给定任何正数标准,存在一个以(x[0], y[0])为中心的圆,在该圆内,其图形与平面之间的差异小于该标准。)
回想一下,f, x 和 y 变量的平面由一个线性方程定义,可以写成以下形式
f(x, y) = a (x - x[0]) + b (y - y[0]) + f(x[0], y[0]) (A)
这里 f 类似的平面称为在(x[0], y[0])处 f 的切平面,它代表的函数称为在(x[0], y[0])处定义的 f 的线性近似。
量 a 和 b 被称为关于 x 和 y 的偏导数,并写成如下形式

这里 a 是 f 在 x 轴方向的方向导数,i,而 b 是 f 在 y 轴方向的方向导数,j。
因此,在参数 x[0]和 y[0]处描述 f(x, y)的线性近似,描述在(x[0], y[0])处的 f 的切平面,因此采用以下形式

其中向量grad f,称为在(x[0], y[0])处 f 的梯度向量,是在点(x[0], y[0])处 f 在 x 和 y 方向的偏导数的向量

我们通常不写出指示梯度和线性近似定义点(x[0], y[0])的繁琐下标,因为它们太繁琐了,只需写成

注意我们可以将grad f 写成 ,其中符号
,其中符号 称为“del”,表示组合
称为“del”,表示组合 。
。
6.6 梯度和方向导数
我们已经看到上面的 2-矢量

被称为在参数(x[0], y[0])处 f 的梯度,通常写为grad f 或f.
在点(x[0], y[0])处由 f 定义的曲面的切平面方程可以用梯度描述为

从这个方程我们可以推断,切平面的法线在三维空间中的方向是(grad f, -1)的方向。
这个法线在(x, y)平面上的投影就是grad f 本身。
因此,grad f 在投影到 f 在(x[0], y[0])处的切平面的法线到(x, y)平面的方向。
这种关系可以在下面的小程序中看到。
符号被称为“del”。 它是一个奇怪的矢量算子。单独来看,它的意义和单手拍掌的声音一样难以理解。但放在可以作用其导数的东西旁边,它就变得很有意义。
在点(x[0], y[0])处对 f 的线性近似 fL 的方程使我们能够计算该点的 f 的方向导数。
假设我们寻求 f 在由单位向量u定义的方向上的方向导数。那么如果(r - r[0]) = su,那么 f 在该方向上的方向导数(在(x[0], y0)附近接近 fL)就是对 s 的 fL 导数。
但我们有
 给出
给出
如果 f 是一个更多变量的函数,比如 x、y、z、t,......我们可以用完全相同的方法来描述变化,唯一的区别是切线平面变成了切平面,而且有更多方向的偏导数。结论完全相同:
1. 梯度向量在法线投影的方向上进入坐标的超平面。
2. 任意方向的方向导数由该方向上的单位向量与梯度向量的点积给出。
3. 梯度向量在任意轴方向上的分量是 f 对应距离变量在该方向上的偏导数。
4. 那个偏导数是假定所有其他变量保持不变的情况下,对那个变量的普通导数。
所有这些的结果是,梯度向量,其分量可以通过普通的一维微分来计算,对于任意维度的场,都是计算其任意方向的方向导数所需的一切。
如果这些概念对你来说很奇怪,那就在下面的小程序中玩耍,直到你感觉舒服为止。左侧的图显示了右侧所表示的场限制在右侧所示的切割半平面上。在那一半平面的边缘也显示了它的线性近似。该线性近似的斜率是在那一半平面的边缘处的场的方向导数。
(当然,所显示的不是一个确切的半平面,而是一个矩形。在此感兴趣的边缘是第三个滑块的旋转轴。)
6.7 哲学含义
上面在二维中的讨论展示了关于导数的一个重要事实,这个事实既解释了微积分的有用性,也解释了我们能够计算所有标准函数以及其他函数的导数。
事实是:在线性近似中,即微分和导数的领域中,从两个不同原因引起的可微函数的变化,比如从 x 的变化和 y 的变化,并不相互作用,它们只是简单地相加,如上述 方程(A) 所述。
这一事实的一个含义是,在计算导数时,你可以将函数分析成简单的部分,计算由每个部分的变化导致的导数,并从每个原因中累加,得到整个函数的导数。
例如,恒等函数 f(x) = x 显然遵循 df = dx 和  ,如果 c 是一个常数,而 f = cx,我们有 df = cdx 和 f ' = c:这种情况下斜率为 c 的切线就是 f 本身。
,如果 c 是一个常数,而 f = cx,我们有 df = cdx 和 f ' = c:这种情况下斜率为 c 的切线就是 f 本身。
换句话说,当作用于 x 或 cx 时,取导数的作用是将因子 x 替换为 1。
现在假设我们考虑 f = x^n,其中 n 是某个正整数。这是 n 个因子中的每一个都是 x 的乘积。对于任何一个因子进行导数,其他因子保持不变,得到的和就是我们的事实,关于 x 的 f 的导数。我们得到

n 来自于将 n 个不同因子中的每一个替换为 1。
作为第二个示例,假设 f = g * h,函数 f 是 g 和 h 的乘积。
那么由于单独改变 g 而导致的 f 的微分变化将是(df)[h 固定] = (dg) * h,由于单独改变 h 而导致的将是(df)[g 固定] = g * dh。我们可以得出结论,f 的一般变化将是这些的和:df = dg * h + g * dh,这意味着 f ' = g' h + gh'。
另一个同样重要的事实的重要含义是,当你面对一个依赖于许多参数的未知函数时,你可以在考察函数关于任何事物的导数时,单独模拟函数相对于每个参数的变化,从而得到函数在任何变量的微分变化下如何变化的相对简单的模型。
然后,您可以希望通过对您建模的微分变化“积分”来发现函数在参数实际变化下的实际行为。
这种方法的替代方案是直接对参数进行实际变化的影响进行建模,这要困难得多。由于来自不同来源的变化相互作用并且可能变得非常难以建模,这一点使情况变得复杂。
虽然我们研究已知函数的导数以发展对该主题的理解,但微积分的深刻用途在于帮助我们通过这种“分析”过程确定未知函数:对其微分变化进行建模,然后“积分”它们。
牛顿发明了微积分来研究行星和受各种力作用的运动体的运动,并取得了令人难以置信的成功。
练习:
6.1 导数 applet 展示了您可以输入的任何函数的导数。 输入函数(sin x)² 在 -4 和 4 之间,看看您是否能找到其导数为 1/2 的点。
6.2 在 x = 1 处你找到了什么导数?导数为 0 的位置在哪里?
6.3 一个具有两个变量的函数在某点具有对 x 和 y 的偏导数是否意味着它在那里可微?
6.4 一个函数在某点所有方向都有方向导数,是否意味着在那点可微?
(提示:考虑在 x = y = 0 时的  。)**
。)**
6.5 鉴于(sin x)' = cos x,我们可以如何定义在 x = 0 时的  ?在 x = 0 时的
?在 x = 0 时的  呢?
呢?
6.6 函数 (x²+y²) sin x 的梯度是什么?在点 x = 1, y = 2 处沿着向量 (1, 1) 的方向导数是多少?
第七章:从定义中计算导数
引言
我们讨论了在电子表格上计算导数的方法,重点是重复使用对称逼近法,指数级递减的 d 并推断结果。
主题
7.1 引言:显然的逼近法:f'(x) ~ (f(x+d) - f(x))/d
7.2 四舍五入误差和导数
7.3 对称逼近法:f'(x) ~ (f(x+d) - f(x-d))/(2d)
7.4 推断答案序列
7.1 引言:显然的逼近法:f '(x) ~ (f(x+d) - f(x)) / d
假设我们有一个给定的函数 f,并且我们寻求其在参数 x[0] 处的导数。
一种估计它的方法是在两个点 x[1] 和 x[2] 处评估 f,然后检查从 (x[1], f(x[1])) 到 (x[2], f(x[2])) 的线的斜率。但是我们应该如何选择 x[1] 和 x[2],以及我们将学到 f '(x[0]) 的什么?
人们首先想到的选择是设置 x[1] = x[0],并且 x[2] = x[0] + d,其中 d 是一个非常小的值。因此可以计算

这不是一个可怕的做法,但是也不是很好,我们会看到。
问题在哪里?
如果 d 太大,线性逼近法将不准确,如果 d 太小,你的计算工具的不准确性可能会毁掉你的答案。而从太大到太小的过渡可能很难找到。
7.2 四舍五入误差和导数
d 太小会导致什么问题?
通常计算器、计算机或手工计算的结果并不完全准确。会有非常小的误差。通常,这些非常小的误差(称为四舍五入误差)可以忽略,因为它们在你的评估中所代表的“噪音”与 f 的值相比极其小。(一个值得注意的例外是当你的答案是 0 时;那么机器的答案将只是它产生的错误。)
一般来说,如果你取两个非常相似的数字,如 f(x[0] + d) 和 f(x[0]),然后取它们的差值,那么这个差值将远远小于任何一个数字,并且由差值表示的信号的信息因此远远小于任何一个数字所表示的信号,而噪声水平通常保持在相同水平上,用于差值的项和差值。
将减法结果除以一个非常小的 d(这相当于乘以一个巨大的  ),将信号和噪声放大在一起。最终结果是你得到了预期的答案加上大量的噪声,而你使 d 越小,噪声就会越大,这种影响会使你的计算不准确。
),将信号和噪声放大在一起。最终结果是你得到了预期的答案加上大量的噪声,而你使 d 越小,噪声就会越大,这种影响会使你的计算不准确。
如果你将 d 设定为低于你的计算机计算的准确度,你的答案通常会偏离超过 1,或者当你除以 d 时,你的程序会指责你除以 0。
电子表格允许你对大量不同的 d 值进行这种计算,而实际上所需的工作量不超过进行一次这样的计算。这通常使你有能力自己查看并确定舍入误差导致的重大误差出现在哪里。
只有当你计算的答案偏离正确答案太远,以至于这种效果变得明显时,你才会受到这种影响的困扰。因此,我们试图利用一些技术,使我们能够尽可能大地得到准确估计的 d 值。
怎么回事?
在电子表格的一行上设置一个 d 值的计算,然后在下一行上设置 d =旧的 ,并将结果向下复制至所需的行数。你将得到以替换的 d 重复的计算结果,然后是
,并将结果向下复制至所需的行数。你将得到以替换的 d 重复的计算结果,然后是 ,然后是,...,直到所得到的值太小以至于你的机器无法将其识别为 0 以外的值。
,然后是,...,直到所得到的值太小以至于你的机器无法将其识别为 0 以外的值。
如果你对导数的估计能够接近一个值并保持在那里,那很可能就是你寻找的导数。不幸的是,这并不总是发生。估计值倾向于接近然后再次远离,因为舍入误差的影响开始显现。
(幸运的是,现代计算机在计算时保留了比屏幕显示更高的精度,因此你可以容忍一定程度的舍入误差而不会注意到它。)
然而,有一件事情要好得多,通常可以接近你寻找的导数的值,并且不需要更多的工作!而不是计算!自己试试。
7.3 对称逼近:f '(x) ~ (f(x+d) - f(x-d)) / (2d)
使用这个公式对导数的“d-逼近”比使用天真的公式 效率高得多
效率高得多
为什么它更好呢?
答案是,如果 f 是一个二次函数,那么“对称公式”就是完全正确的,这意味着它的误差与 d²或更小的值成正比,随着 d 的减小而减小。天真的公式对于二次函数是错误的,并且产生与 d 成正比的误差。
为什么呢?
假设 f 是一个二次函数:f(x) = ax² + bx + c。
然后我们得到
f(x + d) = a(x + d)² + b(x + d) + x
和

另一方面,我们得到

这意味着对于任何二次函数的任何值的 d,对称逼近都是精确的;不需要使 d 变小;这对于非对称公式来说是不成立的。
一般来说,如果我们要求导的函数,f(x + d),可以在 d 的幂级数中展开,那么我们对称公式的第一个误差来自三次项,并且与 d²成正比。
发生这种情况的原因是 f(x + d) - f(x - d) 中的 d² 项会相互抵消,因为两项相同。顺便说一句,所有偶数次幂项也是如此;这个对于 x 处 f 的幂级数展开的近似中的误差都来自于奇数次幂项。
因此,如果我们用 替换 d,对称近似的误差将按 4 倍减少,而当我们将 d 除以 2 时,非对称公式的误差仅按 2 倍减少。
因此,随着 d 的减小,对于导数的对称公式比天真的非对称公式更快地接近真实答案。
现在我们问:我们能否获得更快的收敛速度?
7.4 推断答案序列
是的! 通过推断它!
推断是一种根据少数项来预测序列的发展方向,并创建一个新序列,每个阶段都是根据迄今为止序列项中的信息给出的最佳猜测答案。
一个巧妙的技巧可以消除一个序列中按固定因子从项到项减少的项,方法如下。例如,假设我们有一个序列,并且想要从中消除按 4 倍从项到项减少的项。
那么,如果你取序列中的任意一项的 4 倍,然后减去前一项,任何按 4 倍从项到项减少的贡献将在两者之间抵消;当然,你将得到正确答案 4-1 或 3 倍。
因此,在一个序列 s[1], s[2],... 中,每个序列中都有误差项按 4 倍减少,新序列,其第 j 项为 ,将消除按 4 倍减少的误差项。(在一般情况下,
,将消除按 4 倍减少的误差项。(在一般情况下, 中的主导误差项按 k 减少,类似的公式是
中的主导误差项按 k 减少,类似的公式是 
在我们的情况下,我们可以这样做。计算对导数的对称近似,并让 d 每行减少一半。然后,对称近似中的主导误差将每行减少 4 倍。如果我们将上述的二次近似应用于推断公式,我们将消除那个主导项,并且剩下的主导项将减少 16 倍(来自 f(x + d) 中的 d⁵ 项)。
这是我们能做到的最好的吗?
不! 我们可以使用 k = 16 的推断公式将这里的 16 替换为 64,然后使用 k = 64 的推断来做得更好。
这个方法的一个很好的特点是,每一步,从形成对称近似到产生所示的推断,都非常容易在电子表格上完成,并且只需要在一行中完成,然后复制到后续行中。
另一个好处是,如果你合理设置了这个,你可以通过只更改电子表格中的一个条目来改变微分的参数。你可以只输入新函数一次,并适当复制它来改变被微分的函数。其余所有事情,包括外推,只需要执行一次,几乎适用于所有标准函数。
练习:
7.1 按照上面的讨论描述设置一个电子表格的微分器,使用两级外推的对称差分形式。
7.2 在对 (sin x)² 在 x = 2 处进行求导时,你需要设置什么值的 d 才能使计算达到你的计算机所能显示的精度?
7.3 制作一个电子表格,保持 d 不变(比如设为 .001),并允许 x 变化。使用电子表格的 xy 图表功能,在范围为 -3.5 到 3.5 的区间内为 f 和 f' 绘制图表,其中 f = sin x。
7.4 你能找到一个此方法失效的函数吗?是什么函数?在哪里?你能修复它吗?
第八章:按规则计算导数
引言
我们回顾如何区分标准函数,以及如何找到在空间和时间中移动的物体所经历的函数的时间导数。
主题
8.1 基本函数的导数
8.2 函数组合的导数
8.3 高维导数
8.1 基本函数的导数
由于我们定义标准函数是通过将固定的一组操作(算术操作、替换和反转)应用于三个原始函数的组合而获得的,所以如果我们知道如何区分这三个函数以及如何在其他函数的导数方面对它们应用每个操作来区分由其他函数获得的函数,我们就可以区分任何标准函数。
三个基本函数的导数如下

通过处理每个操作的规则,对标准函数进行微分的任务仅需要解析其定义以将其分解为单个操作,然后对每个操作应用相应的规则。
为此,我们需要以下规则。
8.2 函数组合的导数
如果 f = cg,其中 c 是一个常数,那么 f ' 和 g ' 之间的关系是什么?
如果 f = g + h� 或 f = g - h,那么 f ' 与 g' 和 h ' 之间的关系是什么?
如果 f = g * h,同样的问题吗?
如果  ,那么 f ' 与 g ' 和 h ' 之间的关系是什么?
,那么 f ' 与 g ' 和 h ' 之间的关系是什么?
如果 f(x) = g(h(x)),同样的问题。
如果 f 是 g 的反函数,f = g^(-1)?
如果 f 满足方程 g(f(x)) = 0,在包含 x 的任意开区间内,如何用 g 和 g ' 的术语找到 f '(x)?
根据导数的定义,当 c 是常数时,我们知道 (cg) ' = cg '。
我们还知道根据第六章描述的基本原理,来自不同来源的导数贡献仅仅相加。
我们可以立即推断出如何区分求和、差异和乘积。
求和的区分规则: (g + h)' = g' + h'。同样的 (g - h)' = g' - h'。
乘积的区分规则: (g * h)' = g * h' + g' * h。
如果我们知道如何区分  ,我们可以利用之前的规则得到求
,我们可以利用之前的规则得到求  导数的规则,因为我们有
导数的规则,因为我们有  。
。
我们可以通过利用事实  来找到
来找到  。
。
通过乘法法则,我们得到 
重新排列这个语句并除以 h 得到 
练习 8.1 陈述根据这些事实得出的“商法则”,即用于找到 f'的规则给出。应用它来找到
要找到 f',只需观察当我们将 df 和 dg 视为微分时,我们将有 df = dg,而 f'意味着 ,并且给定 g = g(h)知道 g'会给我们
,并且给定 g = g(h)知道 g'会给我们 从而
从而 。
。
要从得到,我们需要乘以 ,因此我们得到“链式法则” (g(h(x))' = g'(h) * h'(x)� 其中 g'(h)在 h = h(x)处评估。
,因此我们得到“链式法则” (g(h(x))' = g'(h) * h'(x)� 其中 g'(h)在 h = h(x)处评估。
要找到函数 h(x)的反函数的导数,只需要观察到反函数是通过交换 x 和 y 轴获得的;由于 h 的导数是其图形切线的斜率,在交换 h 和 x 轴后,我们得到斜率 。
。
因此,函数 h 的反函数(h^(-1)(x))在参数 h(x)处的导数是与 x 和参数 x 有关的 h 的导数的倒数。
我们得到在 x = h(z)处评估的(h^(-1)(x))'是 与 z 处评估的 h'。这听起来比实际情况更糟。
与 z 处评估的 h'。这听起来比实际情况更糟。
获得相同结果的另一种方法是将链式法则应用于反函数的替代定义:h^(-1)(h(x)) = x。
通过链式法则,我们得到 1 = x' = (h^(-1)(h(x))' = (h^(-1))' * h'(x),其中 h^(-1)在 h(x)处评估;再次得出结论,(h^(-1))'在 h(x)处评估时是 h'(x)的倒数。
练习:
8.2 使用它们与 sin x 的关系找到 cos x,tan x,cot x,sec x 和 csc x 的导数。
8.3 使用 x^(1/n)是 x^n 的反函数的事实来找到(x^(1/n))',并且通过应用刚刚描述的“反函数法则”,找到指数函数 exp(x),sin x 和 tan x 的反函数的导数(即 ln(x),arcsin x 和 arctan x)
现在假设 g(f(x)) = 0 在包含 x 的区间上成立。
然后我们可以应用链式法则找到(g(f(x)))' = 0' = 0 = g'(f) * f'(x),并且这个方程将以 f 的形式确定 f'。这实际上是上面用来评估和 h^(-1)(倒数和反函数到 h)的导数的一般想法。
这是我们需要做微分的全部吗?答案是肯定的。
请注意,这里我们实际上只调用了两个规则,这两个规则允许我们对所有标准函数进行微分。
其中一个是多次出现规则,它允许我们单独处理变量的不同出现,并将它们的各自导数相加,以得到整个导数。
第二个是链式法则,它指出导数是一个变化率,是变化的比率,因此改变自变量,即改变斜率的分母,需要改变比率的导数,即原分母到新分母的导数。
为了说明如何使用这些规则,我们从中推导出了“幂规则”。
请记住,我们可以将任何指数 a 的函数定义为 exp(a * ln(x))。
我们可以利用指数函数 exp(x) 是其自身的导数这一事实,结合链式法则告诉我们

好的,我们是如何得到 ln(x) 的导数公式的?
嗯,ln(x) 是 exp(x) 的反函数。这意味着如果 y = exp(x) 那么 x = ln(y)。但是 exp(x) 是其自身的导数,这意味着当 y = exp(x) 时 y' 是 y。
由于反函数的导数是原函数的倒数,我们得到了 ,这是我们使用的公式。
,这是我们使用的公式。
还有一种变量出现的方式我们尚未遇到但应该提到。它们可以且经常出现在积分的上(或下)限中。当讨论到这个概念时,你将学会如何对这种类型的函数进行微分。然而你应该在这里意识到,当一个变量既出现在这样一个限制中,又出现在普通函数中时,你可以调用“分开出现”规则来单独处理这些出现,并将从每个出现中得到的导数贡献相加,以得到整个导数。
练习 8.4 找出 x^x 对 x 的导数。
8.3 高维度中的导数
在更高维度中会变得更加复杂吗?其实不会。
关于偏导数的重要事情是,根据其定义,它是普通导数,尽管其中某些依赖被忽略,并且它的计算方式与普通导数的计算方式完全相同。没有新的技巧,也不需要新的技巧。
当一些数量取决于一些变量,而这些变量又取决于其他变量时,会出现一些问题。
比如,假设我们对一个微小物体的温度 T 感兴趣,这个微小物体正在普通空间中运动,具有这样的特性,即随着它的移动,它的温度会达到其周围的温度。这个温度随时间和空间而变化。
身体的温度会因为时间的变化而改变,但也会因为它的运动而改变。
这里空间中的 T 是位置 (x, y, z) 和时间 t 的函数:T = T(x, y, z, t)(我们使用相同的字母来描述时间和温度,以最大程度地增加否则将是单调和不具说服力的叙述的混乱)。
现在进一步假设所讨论的物体通过方程 x = x(t),y = y(t),z = z(t) 描述了空间中的轨迹。(你可能想将这个简写为r = r(t),其中 r = (x, y, z)。)
我们提出了一个问题,即该物体所经历的温度随时间的导数是什么?
我们用微分的形式写出 dT
� 
我们还有

将这些放在一起,我们得到

从中我们得出结论

当你遇到这样的公式时,意识到它无疑是从一个类似的情况产生的不是一个坏主意,其中一个函数依赖于时间,也依赖于时间本身依赖于时间的空间变量。
这种事情有点像广义链式法则,有时被称为这样。
请注意,处理这类问题的方法是考虑微分,包括它们之间的所有可能依赖关系,并将它们都与独立变量的微分,这里是 t,相关联。然后,你可以将微分除以找到导数。
当存在多个相互关联的变量时会出现复杂情况。然后,可以有不同的偏导数,取决于哪些其他变量被保持不变,而且在你变化其中一个特定变量时,你可能可以选择固定哪个坐标。为了保持清晰,你必须引入一种符号,其中有一个位置可以描述要保持不变的变量。
第九章:矢量场的导数和极坐标中的梯度
介绍
定义了矢量场的散度和旋度,讨论了提供场的视觉表示的问题,并详细讨论了标量场的梯度。 特别是,我们考虑了如何以三种不同的方式在任意正交坐标系中表示它。
主题
9.1 矢量函数的导数; 散度
9.2 旋度
9.3 可视化两个变量的函数
9.4 极坐标和其他正交坐标系中的梯度
9.1 矢量函数的导数; 散度
梯度是几个变量的矢量函数。 这样的实体称为矢量场,我们可以问,我们如何计算这些东西的导数?
我们将在三维空间中考虑这个问题,并回答如下。
由于三维空间中的矢量有三个分量,并且每个分量在三个方向上都有偏导数,因此在任何坐标系中,矢量场的偏导数实际上有九个。
因此,在我们通常的直角坐标中,对于一个矢量场v(x, y, z),偏导数为

所有这些都可以通过计算用于计算标量函数(通常称为标量场)的偏导数的相同规则来计算。 幸运的是,对于我们来说,通常遇到的只有两种组合,而且值得了解。
这些中的第一个是散度,写作 div v,或用微分算子 del 表示, 它是具有分量
它是具有分量 的矢量算子
的矢量算子
明确地说,它是这个微分算子与矢量v的点积

由于它是点积,所以它是一个数而不是一个矢量。
这就是散度的定义方式,再次可以通过直接微分来计算,但是我们也必须解决以下问题:这意味着什么? 它对我们有什么兴趣? 我们如何使用它? 我们如何在其他坐标系中计算它?
我们将推迟回答这些问题,直到我们讨论了积分,因为答案与该主题密切相关。
然而,我们可以使用微分的规则来推导出以下有用的陈述:
两个矢量的和的散度是它们各自散度的和。
而函数 f 乘以矢量 v 的散度如下给出

练习:
9.1 推导这个方程。
9.2 将其应用于在球坐标中找到 的散度。回忆一下,向量
的散度。回忆一下,向量  在球坐标中有分量 (x, y, z)。
在球坐标中有分量 (x, y, z)。
9.2 旋度
向量场 v 的第二个重要的偏导数组合是其旋度。
这是微分算子 与向量 v 的叉乘积。

虽然我们将再次推迟对这个实体含义的全面解释,但我们可以观察到一些重要的性质,这些性质本身就使它具有重要性。
由于我们可以通过取梯度来从标量创建一个向量,我们可以问:
现在,如果我们对结果梯度取旋度会发生什么?也就是说,旋度梯度 f 是什么?我们也可以问。旋度 v 的散度是多少?以及梯度 f 的散度是多少?
这些问题的前两个有非常简单而极其重要的答案。第三个问题有一个重要的答案,尽管其含义尚不明显。
练习:
9.3 一般情况下评估散度旋度 v 和旋度梯度 f;这些答案本身使旋度和散度成为重要的算子。
9.4 根据偏导数写出梯度散度算子。 (通常被称为“拉普拉斯算子”。)
9.3 两个变量函数的可视化
两个实数变量的函数在三维空间中定义了一个表面,维度是原始的两个维度和函数本身。
我们今天可以产生一个三维图像,但在很多年里这是相当不切实际的,数学家们不得不满足于三维空间中这些表面的二维图像。有两种基本而互补的方法来做到这一点。
第一个是在 xy 平面上绘制等值轮廓线。这种方法用于显示等压线(称为等压线)在天气图中,或者用于显示地形图中的地表高度。
当这些等高线相当平滑时,等高线的切线表示一个方向,这个方向在该点处是水平平面和表面的切平面的交点。
xy 平面上等值轮廓线的法线指向梯度向量(加或减)的方向,也可以用来描述表面。
经过一点练习,你可以从这些等值轮廓线中得到函数表面的相当好的概念。因此,当这些等值轮廓线代表函数的不同值时,函数的上升相对陡峭,当它们彼此之间距离很远时,上升相对缓和。
描述两个变量函数的第二种方法是在许多点上沿着梯度向量的方向绘制小箭头,并将其连接成“增长线”(不是一个常见的术语)。
这些线将垂直于相等值等高线,并且会从“函数的局部最小点到局部最大点”(或者到或从你正在检查函数的区域的边界)。
你可以通过这种图片得到函数的性质的相当好的概念。
当正在研究的函数代表一些物理情境中的势能,或者是静电学中的电势时,这里描述的线是显示对物体或微小带电粒子的力指向的“力线”。
对于物理应用,我们真的希望能够可视化三个变量的函数,这在一个平面上描述起来非常困难。我们将尝试找到一天能够做到这一点的方法。
在接下来的 applet 中,你可以输入你喜欢的两个变量的标准函数和一个定义域,并查看它的等值线是什么样子的。使用第一个滑块,你可以在平面上的一个网格点处查看梯度(网格点的数量是可调的)。
在上次访问的网格点,你可以使用第二个滑块查看方向导数。对于箭头所示的角度,方向导数的大小由箭头的长度表示。当方向与梯度的点积为正时,方向导数的符号为正。
你可以查看方向导数 applet 中由函数定义的实际曲面来磨练你的直觉。
9.4 极坐标和其他正交坐标系中的梯度
假设我们有一个以 f(x, y) 形式给出的函数在二维中,或者以 g(x, y, z) 形式给出的函数在三维中。我们可以对给定的变量进行偏导数,并将它们排列成变量的向量函数,称为f 的梯度,即

意思是

但是假设我们以 r 和  的形式给出了 f 作为函数,即在极坐标中,(或者 g 在球坐标中,作为
的形式给出了 f 作为函数,即在极坐标中,(或者 g 在球坐标中,作为  ,,和
,,和  的函数)。
的函数)。
例如,假设 
我们如何找到 f 或 g 的梯度?
找到这样一个函数的梯度的一种方法是,将 r 或 或  转换为直角坐标,使用适当的公式进行转换,然后对结果表达式进行偏微分。
转换为直角坐标,使用适当的公式进行转换,然后对结果表达式进行偏微分。
因此我们可以写成

并通过普通的偏微分得到

有时,直接用极坐标或球坐标表达梯度更方便,就像用直角坐标表达的那样。
我们在这里想要一个包含对 r 和 的偏导数相乘的表达式,分别乘以指向 r 方向和 方向的向量。
所以我们想知道:这些偏导数应该与什么向量相乘才能形成梯度?
当我们找到答案时,实际上关于每个极坐标变量的偏导数将是极坐标方向单位向量与梯度的点积。
因此我们岔开话题讨论这些单位向量是什么,以便你能认识它们。
r 方向是从 x 轴逆时针倾斜了一个角度 的方向。 在那个方向上的单位向量,称为 u[r], 可以用以下三种形式之一表示

方向上的单位向量位于 r 方向的逆时针 90° 方向,因此它由以下方式给出:


我们现在问:在极坐标中 f 是什么?
我们知道,如果我们在 r 和 上做微小变化,f 的结果变化将由以下公式给出
 (A)
(A)
因为这个关系适用于任何变量。
但它们也必须遵守

如我们在 第 3.8 节 中简要提到的,在变量 r 和 做微小变化时,极坐标中的距离由以下公式描述:

由此我们推导出 
将两个关于 ds 的方程组合起来,我们得出:
 是 f 关于 r 的偏导数,正如
是 f 关于 r 的偏导数,正如  是它关于 x 的偏导数一样。
是它关于 x 的偏导数一样。
但是因为  中有一个 r 因子,所以在 方向上的 分量的分母中必须有一个补偿因子 r
中有一个 r 因子,所以在 方向上的 分量的分母中必须有一个补偿因子 r

和

对于任何维度中的任何正交方向,都可以进行类似的计算,我们可以预期结果。
f 在任何此类变量方向上的分量将是 f 对该变量的偏导数,除以该方向的距离变化与变量本身变化的比率。
使用最后一个方程,我们可以立即推断出的梯度为  ,当然在 r = 0 时除外,那里 不可微分。 类似地,我们发现
,当然在 r = 0 时除外,那里 不可微分。 类似地,我们发现  的梯度。
的梯度。
练习:
9.5 利用球坐标中的两个角变量都是极坐标变量的事实,将 3 维空间中的 ds² 表达为球坐标三个变量的微分。从中推导出球坐标中的梯度公式。
9.6 通过这种方法找到球坐标中  的梯度以及球坐标中 的梯度。
的梯度以及球坐标中 的梯度。
还有一种第三种方法可以通过使用链式法则来找到给定坐标的梯度。
我们首先考虑直角坐标中 f 的微分变化,然后将 x 和 y 的微分变化与其他坐标,比如 r 和 的微分变化联系起来。结合这些,我们可以将 f 的变化与后两个变量的变化联系起来。
由于我们知道如何在直角坐标中写出梯度,并且可以识别单位向量,我们可以将结果表达为另一坐标系中梯度的分量。
明确地,我们可以写成

并使用后两个方程式消除第一个方程式中的 dx 和 dy。结果是一个关于 dr 和 d 的表达式,其系数可以用各个方向的单位向量和直角坐标中的梯度来描述。
将该方程与定义偏导数的基本公式方程(A)进行比较,您可以读取梯度的分量。
当 f 以直角坐标给出但你想在你的坐标系中写出梯度时,或者如果你不确定 ds²和该坐标系中的距离之间的关系时,这种方法很有用。
练习:
9.7 在极坐标中明确地进行这个计算。
9.8 在球坐标中也这样做。
在进行偏导数时应该保持哪些变量恒定?
值得注意的是当我们对 x 或 y 进行偏导数时,我们总是指保持另一个变量,y 或 x,恒定;另一方面,对 r 和的偏导数总是指保持另一个变量,或 r,恒定。任何其他含义都必须明确描述。
有时候在偏导数中,人们可能会困惑于哪个变量或变量被保持恒定,在这种情况下,明确提供这些信息是明智的。因此,我们可以写成 表示对 x 的偏导数,保持 y 不变,这样就不会有关于什么是恒定的混淆。
表示对 x 的偏导数,保持 y 不变,这样就不会有关于什么是恒定的混淆。
关于梯度需要记住的最重要的事实是:
在任何正交坐标系中计算起来都很简单
你可以用它来确定所涉及函数的方向导数,无论方向如何。
在直角坐标中,它的分量是各自的偏导数。
两个场的和的梯度是它们梯度的和(梯度是一个线性算子)。
一个乘积的梯度可以通过应用常规的求导乘积法则来计算。
第十章:更高阶导数,泰勒级数,二次逼近和逼近的准确性
介绍
我们研究了对函数的二次和更高阶多项式逼近,最终得到泰勒级数。讨论了在临界点处的行为和确定逼近的准确性的应用。
主题
10.1 二次逼近
10.2 更高阶逼近和泰勒级数
10.3 更高阶逼近的用途
10.4 临界点处的二次行为
10.5 逼近的准确性和均值定理
10.1 二次逼近
线性逼近\(f\)在\(f'\)是恒定时确实是精确的,这意味着\(f\)是线性的。在线性逼近\(f\)在参数\(x[0]\)处的不准确性来自于参数\(x[0]\)和\(x\)之间\(f'\)的变化。
如果\(f'\)在\(x[0]\)和\(x\)之间的区间内是可微的,我们可以通过对\(f'\)进行线性逼近并将其用于估计区间内\(f\)的变化来获得对\(x\)处的\(f\)的更好逼近。
简而言之,如果\(f'\)在该区间内是可微的,我们可以计算其导数,称为关于\(x\)的\(f\)的二阶导数,并写为\(f"(x)\)或\(\),有时也写为\(\),并使用它来改进对\(f\)的估计。
所有我们的标准函数在它们定义的地方都具有可微的导数,甚至可微的二阶导数,等等,直到永远,除了可能在特定的奇异点处。
它们被称为“无限可微”,因为只要我们愿意,我们就可以不断地对它们进行微分。因此,我们可以计算二阶导数,以及第三阶和更高阶导数,并生成一系列对任何这样的函数的更好逼近。
10.2 更高阶逼近和泰勒级数
我们探讨以下问题:
这些对\(f\)的更高阶非线性逼近是关于它的导数的什么?
我们为什么要做这些事情?
这些逼近有多精确?
当\(f\)是多个变量的函数时会发生什么?
\(f\)在\(x[0]\)处的线性逼近是线性函数,其值为\(f(x[0])\),在那里的一阶导数为\(f'(x[0])\)。
二次逼近是其值和前两个导数与\(f\)在参数\(x[0]\)处相同的二次函数。作为二次函数,它可以写为\(f(x[0]) + a(x - x[0]) + b(x - x[0])²\)。
我们通过应用其导数等于\(f\)在参数 处的导数的条件来确定\(a\)和\(b\)。由于它在处的一阶导数为\(a\),二阶导数为\(2b\),我们推断出\(\),以便\(f\)在处的二次逼近变为
处的导数的条件来确定\(a\)和\(b\)。由于它在处的一阶导数为\(a\),二阶导数为\(2b\),我们推断出\(\),以便\(f\)在处的二次逼近变为

我们可以将这个论点扩展到创建立方逼近等,当 f 在 x[0]处适当可微时,通过应用相同步骤与更高阶导数。如果我们永远这样做下去,我们就得到了"在参数 x[0]处 f 的泰勒级数展开"。
练习:
10.1 写出一个关于 x[0]的一般无限可微函数 f 的泰勒级数展开。
10.2 写出一个一般函数的 5 次可微的 5 次逼近公式,并明确应用于 x[0] = 0 处的正弦函数。 给出在 x[0] = 1 处形成的正弦的立方逼近。
10.3 指数函数,作为其自身的导数,可以从其泰勒级数展开中分解出来。将该展开应用于 x[0]周围,推导出 exp(x)和 exp(x[0])之间的关系。
以下 applet 允许您输入一个标准函数,并查看这些逼近的前三个是如何定义在您选择的域上的。
10.3 高阶逼近的用途
这些更高阶逼近在以下方面是有用的:
1. 当所有较低导数在 x[0]处为 0 时,它们告诉我们关于 f 的关键信息。
2. 它们使我们能够获得对较低逼近的准确性的界限。
3. 它们可以用来推断重要事实(如练习 10.3 中所示)。
4. 作为多项式,它们通常比 f 本身更容易操作。
5. 有时高阶导数本身也很有趣。因此,力学的运动方程直接涉及加速度,这是位置的二阶导数。
6. 最后,与较低逼近相比,它们扩展了在其准确性范围内的展开点的距离。
10.4 临界点处的二次行为
一个 f '为 0 的参数 x[0],使得 f 本身是平的,被称为 f 的临界点。
当 f 在这样一个点上不为零时,它在那里的二次逼近是以 x[0]为中心的二次逼近。
二次函数基本上看起来都一样,特别是如果你愿意倒立。当以 0 为中心时,它们的行为是 ax² + c 的行为。常数 c 决定了它在图中的出现位置,但图的外观完全由参数 a 决定。如果 a 是正的,函数看起来像一个更胖或更瘦的 x²;如果 a 是负的,它看起来像一个更胖或更瘦的-x²。这告诉我们,当其二阶导数为正时,f 在 x[0]处有一个局部最小值,就像 x²一样;当 a 为负时,它在一个局部最大值处有一个局部最大值(f 在一个点处有一个局部最大值,该点至少与包含它的某个开区间中的值一样大)。
当 a 为零时,即 f 和 f ' 在 x[0] 处均有临界点时,二次近似是平坦的,你必须寻找三次或更高次近似来确定该点附近的 f 的行为。
练习 10.4 在什么情况下,当其一阶和二阶导数均在那里消失时,f 在 x[0] 处会有一个最大值?
10.5 近似精度和平均值定理
我们现在问,这里的任何近似都有多 准确,从微不足道的常数近似,线性近似,等等。
假设 x > x[0],m 是这两个参数之间 f 的 k 次导数的最小值,而 M 是那里的导数的最大值。
我们将引用一个原则,其最简单的形式是:你移动得越快,你走得越远,其他条件相同。 在这里,我们声称,如果我们通过在整个区间 (x[0], z) 内用该区间内的 k 次导数的最大值替换函数 f 的实际值来发明一个新函数 f[M],那么  和它的所有一阶到第 k = 1 阶导数将在该区间内的所有 x ' 上都遵守
和它的所有一阶到第 k = 1 阶导数将在该区间内的所有 x ' 上都遵守  。
。
这样想:如果你将速度 f ' 增加到值 M,你会增加行驶距离。如果你交替将加速度 f " 增加到 M,同样的论点,那将增加速度,从而增加行驶距离。依此类推。如果你增加更高阶的导数,这种增加将传导到所有更低阶的导数,并最终传导到 f 本身。
这样做的好处是,在 处的  的 k 次近似在参数 x 处是 精确 的,因为在 和 x 之间的区间内, 的 k 次导数是常数。现在, 的 k 次近似是 f 的 k-1 次近似加上
的 k 次近似在参数 x 处是 精确 的,因为在 和 x 之间的区间内, 的 k 次导数是常数。现在, 的 k 次近似是 f 的 k-1 次近似加上  。
。
我们上面的不等式应用于 j = 0,因此告诉我们,f 的 (k - 1) 次近似加上 至少 是 f(x),而通过应用相同的论点以相反的顺序,并将 M 替换为 m,我们可以推断出相同的近似加上  至多 是 f(x)。
至多 是 f(x)。
所有这些的结果是对这里的任何近似的程度 k - 1 的 f 在 处与参数 x 处的 f 之间的差异有界:它们的差异在 和 之间。
我们可以进一步注意到,这告诉我们 k - 1 次近似的误差可以写成  其中 q 位于 m 和 M 之间。
其中 q 位于 m 和 M 之间。
由于 m 和 M 是 f ^((k)) 在 x[0] 和 x 之间的最小值和最大值,如果 f ^((k)) 在该区间内取得其最大值和最小值之间的所有值(如果它在该区间内可微分,则必须如此),它将取值为 q。因此,我们可以写成  对于该区间内的某个 x '。
对于该区间内的某个 x '。
这使我们能够将我们的结论转化为以下陈述。
定理:
在参数 x 处评估的 f 的 k - 1 次近似的误差为

对于该区间内的某个 x ',如果 f ^((k)) 在该区间内连续。
练习:
10.5 当 k = 1 时陈述这个定理。这个结果被称为“平均值定理”。
10.6 重复上面的论证,针对当 x < x[0] 时发生的情况。结论如何改变?论证中有什么不同?
第十一章:多维度中的二次逼近
介绍
在二维或更多维中考察了二次逼近。我们考虑这样一个问题:在两个或更多个方向上,临界点何时是鞍点,
主题
11.1 二维或更多维的二次行为
11.2 临界点何时是最大值、最小值或鞍点?判据
11.1 二维或更多维的二次行为
现在让我们考虑当 f 是两个变量 x 和 y 的函数时会发生什么。
我们已经看到在这种情况下以及更高维度中可以定义偏导数、方向导数和可微性。
我们也可以再次定义二次逼近,但现在更加有趣。二维或更多变量的二次函数比一维的要多样得多。
二维中的一般二次函数形式为
ax² + bxy + cy² + dx + ey + g
这样的函数将有一个临界点,其梯度为 0 向量,即
2ax + by + d = 0
和
bx + 2cy + e = 0
两者都成立。
如果我们将该点称为(x[0], y[0]),我们可以像一维一样写二次函数
a(x - x[0] )² + b(x - x[0])(y - y[0]) + c(y - y[0])²� + g'
以便线性项已被消除。
在两个或更多维中,我们以显而易见的方式定义更高阶偏导数。
对于两个变量的 f 的二阶偏导数是通过先对一个变量取一阶偏导数,然后对该函数的下一个变量取偏导数得到的。
这里的一个很好的特点是,当您对适当可微的 f 取混合二阶导数时,取它们的顺序无关紧要。
这里二次函数的行为,除了一个常数,由系数 a、b 和 c 捕获,它们与偏导数的关系如下

注意,如果我们以显而易见的方式将四种可能的偏导数组成一个矩阵

(这个矩阵的行列式是二次函数的判别式,即 4ac - b²。)
这样的二次函数的行为如何?
如果 a 和 c 都是正数,而 b 为 0,这里每个变量的行为看起来像一维的 x²,f 在(x[0], y[0])处有一个最小值。
如果我们反转所有符号,使 a 和 c 为负数,同样取 b = 0,二次函数将在该点具有最大值,就像-x² - y²在(0, 0)处一样。
但现在有第三种可能性,即鞍点。
鞍点 是一个临界点,函数在某些方向上增加,在其他方向上下降。
有两个例子可以说明:在(0, 0)处的 x² - y²;以及在(0, 0)处的 xy。
第一个增加如果你远离原点移动到 |x| > |y| 的方向,否则不会增加。
当两个变量都具有相同的符号时,第二个增加,否则不会。
也有可能出现一些方向上函数增加(比如)而在另一些方向上是平坦的行为:就像在二维中的 x²。我不知道你应该如何称呼这种行为。与一维情况类似,当这种情况发生时,你必须查看导数 = 0 方向上的高阶导数,以了解你是否有一个真正的局部最大值或最小值。
练习 11.1 找到 (x - y - 1)xy 的临界点。它在那一点上的行为是什么?(你可以在 applet 中测试。)
在这个 applet 中,你可以输入具有鞍点的函数。这个名称的来源就变得清楚了。
11.2 临界点何时是最大值、最小值或鞍点?标准
我们已经看到,在两个维度上的临界点,一个函数可能有一个最小值,或者一个最大值,或者一个鞍点。
我们想知道如何从函数的公式确定将会发生什么。
我们特别关注函数在临界点的二次行为。
这种行为是由二阶导数决定的,也是二阶导数所确定的二次函数的行为。
所以我们真的想知道:给定一个没有线性项的二元二次函数,在原点时何时有最大值,何时有最小值,何时既不是?
答案如下:
我们可以将一个矩阵与函数关联起来,即其临界点的二阶偏导数矩阵,如上一节所定义。
二次函数的行为由该矩阵的特征值决定。
当它们是实数且为正时,你会得到一个最小值,当为负时,你会得到一个最大值,否则是一个鞍点,除非其中一个为 0,那么你会得到平坦。(这意味着对于一般函数,你必须查看这些方向上的高阶导数。)
为什么?
与特征值相对应的特征向量是基向量i和j的线性组合。它表示从临界点出发,二次函数在该方向上的行为类似于其特征值乘以该方向的距离。
因此,如果两个特征值都是实数且为正,函数将看起来像是 ax'² + by'²,其中 a 和 b 为正值,x' 和 y' 为适当方向上的坐标,我们的函数将有一个最小值。
另一方面,如果它们有相反的符号,函数会在一个方向上增加,在另一个方向上减少,我们将会得到一个鞍点。
如果存在复特征值呢?
不可能有!因为我们的矩阵是实的且对称的(记住混合偏导数与取偏导数的顺序无关),它的所有特征值都是实数。
而且,对应于不同特征值的特征向量总是彼此正交的!
这意味着二次函数的行为在原点处与 a'² + b'²完全相同,只是坐标轴可能沿着特征向量的方向旋转。
关于矩阵和特征值的相关性质的简要讨论见第三十二章。您可以用 applet 图形化地寻找二乘二特征值:矩阵乘向量。
在三维空间中会发生什么?
完全相同的陈述适用,只是现在我们有一个三乘三的对称二阶偏导数矩阵。
它的特征值将是实数,如果它们都是正数,你会得到一个最小值,如果它们都是负数,你会得到一个最大值。如果符号混合,你得到一个鞍点,如果某些特征向量为 0,则必须查看这些方向上的更高阶导数以确定发生了什么。同样,对应于不同特征值的特征向量将是正交的。
实际上,所有相同的陈述在任何有限维度中都成立。
练习 11.2 找出二次多项式 3x² + 2xy - xz + z² + y² 的第二部分矩阵的特征值。
为了确定是否有最大值或最小值,有必要知道二阶导数矩阵的特征值吗?
不需要!
您只需看特征方程式。如果它的所有可能项都存在并且符号交替,你得到一个最小值,如果它们都有相同的符号,你得到一个最大值,否则既不是最小值也不是最大值。
练习 11.3 怎么回事?
第十二章:导数的应用:直接使用线性近似
介绍
我们考虑将线性近似作为一种近似方法,并通过迭代使用它来确定逆函数以达到机器精度。
主题
12.1 使用线性近似估算函数值
12.2 通过迭代线性近似准确确定逆函数
12.3 此过程的电子表格实现
12.1 使用线性近似估算函数值
假设我们有一个函数 f,我们发现很难评估,但我们对它了解一些情况。我们希望尽可能利用我们所知道的东西来估计它在参数 x 处的值,知道它在某个参数 x[0] 处的值。
例如,假设我们想要评估 28 的立方根。
我们知道 27 的立方根是 3。
我们能做的最简单的事情就是进行“常数近似”,并将 28 的立方根近似为 3,好像立方根函数是一个常数。
如果我们想做得更好,接下来可以尝试的是应用线性近似。
f1 = f(x[0]) + (x-x[0])f '(x[0])
在我们的例子中,我们有 
对于立方根的线性近似, 那么,对于 28 的立方根,我们有
那么,对于 28 的立方根,我们有 
给定任何我们知道 f(x[0]) 和 f '(x[0]) 的函数 f,我们可以立即评估这个近似值。使用它涉及假装函数 f 的图形是其在 x[0] 处的切线,而不是它实际的样子。
我们可以通过考虑 f 的二阶导数来判断这个近似值有多好。
请注意,f '在 27 和 28 之间的范围内是负的,这意味着该区间内的一阶导数在那里减小。在 27 处的切线上保持不变。
这意味着在 27 的切线线性近似上高估了该区间内 f 的变化,因此我们知道

我们还可以观察到 f 的三阶导数在问题的区间内是正的,因此二次近似也低估了二阶导数和所有较低导数的变化,因此它是 f(28) 的一个下界,我们得到

在数值上,精确到小数点后六位,我们得到 3.03658 < f(28) < 3.03704;事实上,我们有 f(28) = 3.03659 的精度。
此处考虑的立方根函数是我们直接计算其逆函数的函数的逆函数,即立方函数。我们可以使用线性近似来计算任何这样的逆函数,以机器允许的精度,我们接下来将会看到的。
12.2 通过迭代线性近似准确确定逆函数
如何?
给定一对数字,(x[0],f(x[0])),在 x[0]处定义的线性近似函数 fLx[0]允许我们计算 fLx0 作为对 f(x)的近似。
如果我们知道 f 的逆函数,我们可以计算 f(-1)(fLx0),这给我们带来了一对新的数字,(f(-1)(fLx0),fLx0),我们可以称之为(x[1],f(x[1])),然后重复(或迭代)此操作以产生 x[2],然后 x[3],...,直到收敛。
这在旧日里是一种非常乏味的过程,学生们根本无法忍受。现在对于电子表格来说,这简直易如反掌,我们可以为所有我们遇到的逆函数设置并计算,只需要几分钟的时间:这些函数包括根(x^(1/j))、(自然)对数、arcsin 和 arctan。
还需要做什么?
在 x[j]处定义的线性近似函数 fLx[j]在 x 处的值由以下公式给出:
fLxj = f(x[j]) + f '(x[j]) (x - x[j])
设置这个,设置
x[j+1] = f^(-1) (fLxj)
只需进行迭代即可。
练习:
12.1 设置一个通用的根查找电子表格,以便您可以输入 x 和 j,它将使用这种方法来输出 x 的第 j 个根,其中计算机只计算整数次幂。(如何做到这一点的提示在下一节中。)
12.2 设置一个电子表格来使用计算机计算 exp x 的能力来查找 ln x。
12.3 对正弦和正切的逆函数做同样的操作。通常这些函数被写成 arcsine 和 arctangent 或 asin 或 atan 或介于两者之间的某个东西。
12.4 这种方法可能失败吗?如果是这样,为什么?
12.3 此过程的电子表格实现
你怎么能做到这样的事情? 首先将 x 和 j 放在固定的位置 X 和 Y。
然后在电子表格上设置以下列:
f(x[j]):
在第一列中输入 f(x[j])的连续值,从第一个已知值开始。
对于根,您可以从 x[0]� = f(x[0]) = 1 开始。
通过使用在 x[j-1]处的切线的线性近似在参数 x 处评估的 x[j-1]或 f(x[j-1]) + f '(x[j-1]) (x-x[j-1])来计算后续值 f(x[j])。(x[j-1]是前一行中第二列中的条目。)
x[j]:
在第二列中应用逆函数,f^(-1),到第一列中的值。
一旦你为 f(x[1])和 x[1]输入了指令,你可以将这些指令复制到一百行,然后完成任务。
如果 f 是一个根,x^(1/m),会发生什么?
一般来说我们有
f(x[j]) = fLxj-1 = f(x[j-1]) + (x - x[j-1])f '(x[j-1])
�对于第 j 个根,� ,因此该公式简化为
,因此该公式简化为

那就是您需要输入的所有内容。剩下的就是复制。
第十三章:解方程
介绍
我们构造了四种迭代方法来解方程 f(x) = 0。它们是:牛顿法,在这种方法中,我们通过找到旧点处 f 的线性近似为零的位置来从旧点到新点;穷人的牛顿方法与之相同,只是我们在线性近似中近似斜率,并且还有两种插值方法。
我们还提出了在二维空间中解两个联立方程的问题。
主题
13.0 解一个变量的方程
13.1 牛顿法
13.2 穷人的牛顿法
13.3 另一种线性方法
13.4 分而治之
13.5 解两个含两个变量的一般方程
13.1 牛顿法
正如刚才提到的,这种方法包括迭代过程,将 f 的线性近似设置为 0 以改进对 f = 0 解的猜测。
我们将在这里称为 fLx0 的自变量 x[0]的 f(x)的线性近似可以用以下方程描述

如果我们设置 fLx0 = 0,并解出 x,我们得到

因此我们得到 ,一般可以定义
,一般可以定义

在随后的小程序中,您可以输入一个标准函数,选择可以显示的迭代次数(nb points),用第二个滑块调整 x[0],并使用第一个滑块查看每次迭代。您将看到函数和迭代的效果。
你会注意到,使用这种方法,你可能会得到一个附近的 0,或者一个远离的 0,这取决于一点运气。
在过去,找到 x[j]的步骤的繁琐程度是如此可怕,以至于不能安全地施加在学生身上。
现在,借助电子表格,我们可以在大约一分钟内设置并执行此操作,即使是混乱的函数 f。
要做到这一点,将您的初始猜测 x[0]放在一个框中,比如 a2,将“= f(a2)”放在 b2 中,并将“= f '(a2)”放在 c2 中。然后在 a3 中放入“= a2-b2/c2”,并将 a3、b2 和 c2 复制到您喜欢的任何地方。(当然,在执行此操作时,您必须解释 f 和 f'是什么。)
就是这样。
如果 b 列趋近于零,则 a 列中的条目将收敛到一个答案。
如果您想要更改您的初始猜测,您只需要在 a2 中输入其他内容;要解不同的方程,您只需要更改 b2 和 c2 并将它们复制下来。
这提出了一些有趣的问题;也就是说,我们能不能说出这种方法何时起作用,何时不起作用?
首先,您应该意识到许多函数有不止一个参数,使它们的值为 0。因此,您可能得不到您想要的解。
另外,如果函数 f 没有零点,比如 x² + 1,你永远也找不到解。
这里还有另一个问题:如果你的初始猜测, (或任何后续的
(或任何后续的 )接近 f 的临界点(在该点 f' = 0),那么在该参数处,数量
)接近 f 的临界点(在该点 f' = 0),那么在该参数处,数量 可能会变得巨大,导致你看到与你寻找的目标非常远的参数。
可能会变得巨大,导致你看到与你寻找的目标非常远的参数。
如果 f 是隐式定义的,你可能会发现在某个新的猜测 x[j]中,f 甚至没有定义,迭代会陷入死胡同。
我们能对这种方法的使用说些什么积极的吗?
是的!如果 f 在真解 x 处从负变为正,且 f'在 x 和您的猜测 x[0]之间是增加的,而且大于 x,那么该方法将始终收敛。类似的情况也适用于 f 从正变为负,以及许多其他情况。
为什么会这样?
如果 f'是增加的,那么 f 在 x[0]处的切线将在 x 和 x[0]之间低于 f 曲线,使得线性近似,即其曲线,将在 x 和 x[0]之间达到零,而在每次迭代中也是如此。因此,x 将朝着真解不断前进,无法逃脱,并最终到达那里。
该方法的另一个优点是,随着接近解,可微函数将越来越像当前猜测和真解���间的线性近似。因此,一旦当前猜测接近解,该方法就会非常快速地收敛。
练习:
建立一个电子表格来应用到以下函数:
**13.1 ** exp(x) - 27
**13.2 ** sin (x) - 0.1
**13.3 ** x²
**13.4 ** tan x
**13.5 ** x^(1/3)
**13.6 ** x^(1/3) - 1
13.2 穷人牛顿法
要应用刚才描述的牛顿法,需要在每次猜测时对函数 f 进行微分。这并不困难,但需要一点努力。
我们可以使用本质上相同的方法,使用形式为 的近似值来代替
的近似值来代替 ,其中 d 为某个值。然后我们需要决定使用什么值作为 d,但是通过电子表格,我们可以选择一个小值作为起始值,并在迭代过程中让它慢慢趋近于零。如果我们想更加精细,我们可以使用对称的导数近似
,其中 d 为某个值。然后我们需要决定使用什么值作为 d,但是通过电子表格,我们可以选择一个小值作为起始值,并在迭代过程中让它慢慢趋近于零。如果我们想更加精细,我们可以使用对称的导数近似 。
。
我们如何做到这一切?
在 e2 单元格中,我们可以放入我们的初始值 d,比如 10^(-3);然后在 e3 中放入"= e2*9/10",并向下复制,这样 d 将慢慢减小到 0。(为什么要这样慢慢减小?如果你进行得太快,舍入误差可能会在找到解之前毁掉你。)这里的迭代是

因此,我们可以将我们的猜测放在 f2 中,将 "= e2+f2" 放入 g2,将 h2 设置为 "= f(f2)",将其复制到 i2 中,然后将 f3 设置为 "= f2-e2*h2/(i2-h2)",并复制 g2、h2、i2 和 e3 和 f3 下去,我们就完成了。
练习 13.7 对于 13.1 节的练习中的每个函数都这样做。你在这里和常规牛顿法的结果之间发现了差异吗?如果有,是什么?
13.3 另一种线性方法
另一种简单的应用方法是选择两个参数,x[0] 和 x[0'],希望它们接近你想要的解,评估函数在它们处的值,并假设由这两个值和参数定义的直线是对 f 的合理近似。然后,你可以找到这条直线与 x 轴相交的地方,并将其用于替换两个初始值中的一个。
在进行这个过程时有两种情况;一种情况是 f 在两个点处具有相同的符号。这意味着它们的直线不会在你的猜测之间与 x 轴相交,然后你可以用新点来替换其中距离它最远的两个点之一。
另一方面,如果你的两个参数处的 f 的值具有相反的符号,则应该替换旧参数,在这个参数处 f 的符号与在新参数处的符号相同,这样在下一次也会是如此。
这种方法优于牛顿法的地方在于,一旦你找到值的 f 具有相反符号的参数,你必须在这些参数之间逐渐逼近一个解。(解是一个使 f 改变符号的点;对于连续的 f,这是一个使 f 为 0 的点;像 tan x 这样的函数在它们为无穷大(或更正确地说,未定义)的参数处改变符号,以及在它们为 0 的参数处。)
它的缺点是存在一些函数,其在你的猜测之间的真导数远非直线,每次迭代获得的收益非常少。因此,它可能收敛得非常慢。
用于找到 x[i + 1] 的方程,给定你用来计算它的两个值 x[i] 和 x[i'] 是

如果你将这与之前的方法进行比较,这相当于用前两个猜测的值近似牛顿法中的导数,而不是像“穷人的牛顿法”中一样,用最后一个猜测及其加上 d 的值。
这个方程可以解决,我们可以像以前一样轻松地找到一个新的 x[i]。通过少量的努力,我们可以弄清楚要丢弃的旧参数中的哪一个;以下设置可以做到:
在 s2 和 t2 中放入你的初始猜测。在 u2 中放入 "= f(s2)",并将其复制到 v2 中。
现在在 s3 中放入 "= s2 -(s2-t2)*u2/(u2-v2)",在 w2 中放入 "= if(abs(s3-t2)<abs(s3-s2),t2,s2)"。(这将把旧参数放在 w2 中更接近新参数。)
复制 s3 和 u2,现在在 t3 中放入 "= if(u2v2>0,w2,if(u2u3>0,t2,s2))",并将 t3、w2 和 v2 复制下来。
这个可怕的最后一条指令使得如果 u2 和 v2 具有相同的符号,t3 将保持更接近旧参数的值,否则将旧参数的值 f 相反的替换到 u3 中。
练习 13.8 这种方案与你之前的例子相比如何?在之前练习的各种例子上试一试吧。
13.4 分而治之
上一个方法使用直线逼近来获得两个旧参数之间的新参数,一旦旧参数的值 f 具有相反的符号。这通常是一个聪明的做法,除非区间的端点(在上面的列 s 和 t 中)收敛得非常慢。
为了避免这种可能性,我们可以一旦函数 f 在两点 a 和 b 处具有相反的符号,就在中点评估它,并将一个端点替换为中点。
这将使解必须位于的区间的大小减半。与牛顿算法的最佳部分或上述变体相比,这是较慢的收敛,但它是稳定且有效的,并且在固定数量的步骤中总是会明显提高准确性。
由于 2 的十次方略大于一千(是 1024),所以每十次迭代间隔的大小至少减少了 1000 倍,因此如果它从 1 开始,大约经过 35 步你将得到十位小数的答案。
算法是怎么进行的?
我们从两个参数 a 和 b 开始,并假设我们假定 a < b。我们评估 f(a)和 f(b),还有 。然后,如果这些中的最后一个和第一个具有相同的符号,您将替换 a 为
。然后,如果这些中的最后一个和第一个具有相同的符号,您将替换 a 为 ,保留 b,否则保留 a 并将 b 替换为。
,保留 b,否则保留 a 并将 b 替换为。
在电子表格中,您可以将您的初始猜测放在 aa2 和 ab2 中,在 ac2 中放置“= aa2/2+ab2/2”,在 ad2 中放置“= f(aa2)”并将其复制到 ae2 和 af2。然后您可以在 aa3 中放置“= if(ae2af2>0, aa2,ac2)”,在 ab3 中放置“= if(ae2af2>0,ac2,ab2)”,然后向下复制即可完成。
除非有错误潜伏,或者你以 ad2 和 ae2 具有相同的符号开始,否则在大约 35 步之后,这将使初始的 a 到 b 的间隔缩短至少 10^(-10)倍。
练习 13.9 将此算法的性能与以前的算法在相同的示例上进行比较。有什么评论吗?
13.5 求解两个一般的二元方程
牛顿法(以及贫穷人的牛顿方法)的一个很好的特点是它可以轻松地推广到二维甚至三维。
也就是说,假设我们有两个标准函数 f 和 g,它们是两个变量 x 和 y 的函数。每个方程,f(x, y) = 0 和 g(x, y) = 0 通常在曲线上满足,就像类似的线性方程在直线上满足一样。假设我们寻找这两个方程的同时解,那么它们将在这些曲线的交点上满足,如果有的话。
如果我们能够解出其中任一方程以 y 为自变量的 x 的表示式,我们可以找到一个曲线解的参数表示(以 y 为参数),并且在另一个函数上使用上一节的分而治之方法,每次将参数区间减半,就像在一维中一样。
这是一种缓慢而稳定的方法,可以相当容易地实现。但它假设我们可以获得一个或另一个曲线的参数表示。
我们总是可以尝试牛顿法,这在一般情况下相当容易实现。
要使用牛顿法,我们在某个初始点计算 f 和 g 的梯度,并找到一个新点,在该点上由初始点的梯度定义的 f 和 g 的线性近似都为 0。然后我们迭代这一步。
要实现这种方法大致需要牛顿法在一维中所需工作的三倍。另一方面,三倍几乎等于零,仍然是很小的。
这种方法遭受与牛顿法在一维中遭受的相同问题。
我们可能会远离我们在 xy 平面上想要的地方,特别是如果我们来到一个梯度很小的点。
当然,两条随机曲线可能根本不相交,所以可能根本没有解决方案,或者可能有许多解决方案。
但是如果我们能够在接近解的地方开始,再加上合适的情况,这个方法的效果会非常好。
我们如何设置它?
首先,您选择 x[0] 和 y[0] 的初始猜测;在电子表格中,将它们输入到前两列中(假设)。然后您需要一列输入 f(x, y) 和一列输入 g(x, y);以及一个分别用于 f 和 g 的 x 和 y 导数的列(一共四个导数)。
您现在已经拥有了计算 x[1] 和 y[1] 所需的所有信息。一旦您完成了这一步,您只需要复制所有内容,比如说 30 行,然后您就可以看到会发生什么。如果 f 和 g 都趋近于零,这意味着 x[i] 和 y[i] 都收敛,那么您将得到一个解决方案。
那么我们如何迭代?
我们必须解出关于 x 和 y 的两个线性方程,这两个方程陈述了在 (x[0], y[0]) 处由初始点的梯度定义的 f 和 g 的线性近似都为 0。
这些方程是什么?它们是

解是什么?
我们可以使用克拉默法则(行列式比的法则)来告诉我们解是什么。

并且

当然,所有进一步的迭代都与这个新猜测的迭代相同。因此,一旦输入了这些公式,只需复制它们就足以应用该方法。
**练习 13.10 在以下函数的电子表格中尝试此方法:f(x, y) = exp(x * y) - y² , g(x, y) = cos(x + y)。
找出三个解,使得两个变量都是正的。有多少这样的解呢?**
相同的方法可以在三维中实现,尽管在电子表格上所需的工作量开始变得稍微繁琐。
现在你必须输入三个变量,三个函数,它们的九个偏导数,当然克莱姆法则现在涉及到两个三乘三行列式的比值,现在是三倍。
如果你真的想要的话,你可以做到,而且实际上找到三个任意非线性方程在三个变量中的解,有合理的运气的话。
第十四章:极值点
简介
我们考虑如何找到单变量函数和多变量函数的最大值和最小值。
主题
14.1 最大值或最小值的一般条件
14.2 二维曲线上的极值点
14.3 三维曲面上的极值点
14.4 三维曲线上的极值点
14.5 分治法寻找一维极值点
14.1 最大值或最小值的一般条件
函数的局部最大值(或最小值)是指在其定义域内,函数取得比其邻居更大的值的点。
在任何我们可以向前和向后移动的方向上 f 有非零方向导数的点 q,不能是最大值或最小值,因为从 q 开始向前和向后移动会导致 f 在一个方向上增加,在另一个方向上减少。
对于可微函数 f 在点 q 处的内部“极值”点的基本条件是,f 在你可以从 q 出发的每个方向上都具有零导数,同时满足问题的条件。
对于一个变量的函数来说,这仅仅是 f ' 在 x = q 处等于 0 的条件,也就是说 q 是 f 的临界点。
要确定临界点是否是 f 的最大值或最小值,你必须查看 f 的二次近似(或者如果必要的话,查看 f 偏离平坦性的第一个更高的近似)。如果它的二阶导数是正数,那么像 x² 一样,f 在 q 处有一个最小值,如果是负数,那么 f 在 q 处有一个最大值。
你应该始终检查你找到的任何局部最大值或最小值是否是 f 的“全局”最大值或最小值。该全局极值点(或任何这样的点)可能出现在边界上,或者与你找到的第一个局部极值点不同的另一个局部极值点处。
如果 f 是一个多变量函数,那么即使在二次近似中也可能发生奇怪的事情,q 是一个临界点并不意味着它是一个极大值或极小值,即使二次近似远非平坦。正如 第十一章 中所指出的,q 很容易成为一个鞍点,你必须像该章节中指示的那样检查。
要解决这类问题,你要通过将所有导数都设为零来寻找 f 的临界点,并解决得到的方程。然后你必须检查你是否有一个最大值、最小值或者鞍点。
在这里,我们考虑的是当你处于二维或三维空间时,但是在一些曲面或曲线上寻找一个函数 F 的极值点时会发生什么。
14.2 二维曲线上的极值点
假设我们有一条曲线 C,由方程 G(x, y) = 0 定义,并且我们寻找 F(x, y) 在限定在这条曲线上的点之间的极值。
举个例子,假设 G 表示一个椭圆,ax² + by² = 1,我们想要找到 C 上 xy 的最大值。
在 C 上的任意点 q 处,我们可以沿着曲线的切线方向自由移动而保持在 C 上。我们上面对于极值的条件告诉我们,对于 q 要成为 F 的极值,F 在切线 t 方向上必须有 0 导数,定义为 G 曲线的切线。
这意味着 F 的梯度必须垂直于 t。但 G 的梯度也必须垂直于 t,所以 在二维空间中,F 的梯度和 G 的梯度必须平行,才能使 F 在 G 上有极值。
有两种标准表达这个条件的方法。
一个是注意到这意味着 由  F 和 G 形成的平行四边形没有面积,因此以这些向量为列的行列式必须为 0。
F 和 G 形成的平行四边形没有面积,因此以这些向量为列的行列式必须为 0。
另一个是注意到这意味着 F = cG,其中 c 是某个常数。
任一观察都可以帮助我们找到极值。
示例
第二种方法称为“拉格朗日乘数法”,常数 c 称为拉格朗日乘数。
在你可以点击上面的示例中,如果你写出由 G = ax²+by² -1 =0 定义的三个方程,i**** (F - cG) = 0� 和 j(F - cG) = 0,你可以解出它们的 x、y 和 c,并得到相同的解。
(F - cG) = 0� 和 j(F - cG) = 0,你可以解出它们的 x、y 和 c,并得到相同的解。
再次,计算二阶导数(或检查 F 的值)必须用于确定局部和/或全局极大值和极小值。
当曲线以参数 t 参数化时,你可以写成 F = F(x(t), y(t)) 并应用单变量条件 
练习:
14.1 解决上述示例的拉格朗日乘数方法的细节。
14.2 假设我们想要最大化一个垂直定向圆柱的体积,给定其侧面和顶部(但不包括底部)的表面积 q 的固定值。它应该有什么半径和高度?
14.3 三维空间中曲面上的极值
三维空间中的一个曲面由一个方程确定,我们将其写为 G = 0。
再次假设我们希望在这个曲面上找到 F 的极值。
这次 F 在曲面的切平面上的极点不能有非零分量,与之前的情况完全相同。
这意味着F 和G 必须再次指向同一个方向。
我们可以观察到这意味着叉乘F G 必须为 0,这个向量方程给了我们两个独立的分量方程,我们可以解决 G = 0 来找到极值。
G 必须为 0,这个向量方程给了我们两个独立的分量方程,我们可以解决 G = 0 来找到极值。
我们也可以像以前一样应用拉格朗日乘子法。这次所有向量都有三个分量,因此方程F = cG 给出了我们三个方程,加上 G = 0,足以确定 c 和极值的坐标。
再次,您必须识别最大值和最小值,并在每个极值点上区分仅局部极值和全局极值。
当曲面由参数表示时,您可以通过替换将问题减少到曲面的两个参数的二维问题中,对参数没有限制。然后,找到临界点涉及求解通过将 F 对参数的偏导数设置为 0 得到的方程。上一章的二维牛顿法可用于数值示例中执行此操作。
练习:
14.3 假设我们想要最大化 xyz - x,条件是 2x² + 4y² + 3z² = 6。写出由叉乘方法得到的临界点处 x、y 和 z 满足的方程。
14.4 写出拉格朗日乘子法得到的相同问题的方程。
14.5 假设由参数表示的曲面

**对于 0 < u < 2 ,0 < v < 。
,0 < v < 。
我们想要找到 F 的临界点,F = x⁴ - 2y²z²。
找到相同的方程。**
14.4 三维空间中的曲线上的极值
三维空间中的曲线 C 可以由两个方程定义(即作为两个曲面的交点),或者使用单个参数如同二维空间中一样。
如果 q 是 C 上 F 的极值,我们不能在 q 的参数处有Ft非零,根据我们的一般原理;否则,F 在 q 处将比 C 上的值大一侧而比另一侧小。
然而,这里的条件含义不同。我们不能再说F 在极值点指向某个特定方向。相反,它必须是某个特定方向的法向量,即 C 在这些点处的切向量。
当 C 被描述为两个方程 G = 0 和 H = 0 时,t 沿着 G  H 的方向,而 F 在该方向上没有分量的说法是 F 落在 G 和 H 的平面内,因此它们的平行六面体的体积为 0,且所有这些梯度的行列式必须为 0。
H 的方向,而 F 在该方向上没有分量的说法是 F 落在 G 和 H 的平面内,因此它们的平行六面体的体积为 0,且所有这些梯度的行列式必须为 0。
此条件和 G = 0 和 H = 0 确定了临界点的 x、y 和 z。
另一种陈述相同条件的方法是使用两个拉格朗日乘数,比如 c 和 d,并写成 F = c G + d H。我们可以通过编写此向量方程的所有三个分量并使用它们以及 G = 0 和 H = 0 来解出 c、d、x、y 和 z 的三个方程。
练习:
14.6 给定曲线定义为由方程 xyz = 1 和 x² + 2y² +3z² = 7 定义的表面的交点,通过行列式方法找到确定 2x³ - y³ 的临界点的方程。
14.7 为相同问题使用拉格朗日乘数法得到的临界点的方程。
14.8 我们寻找曲线 x = 5 sin t, y = 3 cos 3t, z = sin 2t 的 F 的临界点,其中 t = 0 到 2,其中 F = x² + y² + z²。为它们编写方程。
14.5 用于查找一维极值的分治法
在上一章讨论的解方程的分治算法可以应用于寻找一维函数的极值,因此也可以应用于参数化曲线上的函数的极值。
例如,假设您寻找曲线上的局部最大值。
要开始,您需要找到定义曲线的参数的三个值,使得在由中间参数值定义的曲线上,F 的值大于在其他两个点的值。
假设这些参数值是 a、b 和 c。然后,您可以检查参数值为  的函数 F。这两个点和 b 处的值的最大值将是具有与 a、b 和 c 相同特性的三个参数值的中心,即中间值的 F 值大于其他值的 F 值,但在此步骤之后,中心值和另一个值之间较大参数区间的大小将减小两倍。
的函数 F。这两个点和 b 处的值的最大值将是具有与 a、b 和 c 相同特性的三个参数值的中心,即中间值的 F 值大于其他值的 F 值,但在此步骤之后,中心值和另一个值之间较大参数区间的大小将减小两倍。
迭代将像零点找算法一样精确地找到解决方案。
练习:
14.9 解释为什么在 和 b 处 F 值的最大值大于这些点中最接近它的 a 和 c 周围点的两个值。
和 b 处 F 值的最大值大于这些点中最接近它的 a 和 c 周围点的两个值。
14.10 您可以将参数的域分成大小为 d 的区间,并列出曲线上这些区间之间点的 F 值列表。从中,您可以找到值列表上的局部最大值,并在每个局部最大值处开始此过程。为曲线 x = 5 sin t, y = 3 cos 3t, z = sin 2t, 对于 t = 0 到 2,以及 F = x² + y² + z²建立一个电子表格。找到局部最大值至小数点后 5 位。
第十五章:曲线
介绍
到目前为止发展的微积分工具使我们能够描述光滑曲线的大部分重要属性:在任何点的方向,以及它在那里与直线的偏差有多大。这由其曲率来衡量。其路径与平面性的差异由其挠率来衡量,也很容易计算。
主题
15.1 曲线及其固有属性的参数化表示
15.2 曲线的固有属性
15.3 曲率和曲率半径
15.4 曲率的计算
15.5 挠率
15.1 曲线及其固有属性的参数化表示
通过点 (x[0], y[0]) 且斜率为 r 的一条直线可以被参数方程 y - y[0] = rt, x - x[0] = t 表示。
在三维空间中,你还将会有 z - z[0] = st。
在二维空间中,一条直线可以描述为一个线性方程的解,而在三维空间中,可以描述为两个这样的方程的解。
类似地,一条曲线可以被参数化地表示为一个向量从原点到点 P 的分量 x、y 和 z,作为参数 t 的函数,或者作为空间维度的方程的解。
不同之处在于典型曲线不是一条直线。
假设我们有一个参数化表示的曲线。
这是一个例子:x = cos t, y = sin t, z = t。
这些特定的方程描述了称为 "螺旋线" 的曲线。
如果你愿意,你可以想象参数 t 代表时间变量,这些方程描述了某个粒子随时间的运动。
这些方程包含两种信息:关于沿着曲线的运动的信息,即沿着粒子轨道的运动的 "速度",以及关于轨道或曲线本身的信息。
我们希望从曲线的信息中提取出它所代表的曲线的固有属性。我们进一步想知道如何计算它们。
15.2 曲线的固有属性
首先,它们是什么?曲线的固有局部属性是什么?
一条直线有一个方向,我们可以用一个单位向量来描述它:
因此,方程组 x = 2t, y = 3t, z = t 描述了具有向量 (2, 3, 1) 的方向和单位向量的线。
一个一般的可微曲线在一个足够短的区间内看起来像一条直线。因此,在任何一点上它都有一个斜率,而该斜率通常是向量 v(t) 的方向。
我们定义 T(t) 为 v(t) 方向的单位向量

我们再定义一个参数 s(t),表示你在 t = 0 处和 t 时位于曲线上的距离之间的距离。
曲线的内在信息包含在切向量和沿曲线的距离参数之间的关系中。
在任何一点,曲线的第一次近似是由其在那里的斜率所确定的,即T(t)或T(t(s))的方向。
15.3 曲率和曲率半径
下一个重要的感兴趣的特征是曲线在位置 s 处与直线的偏差有多大。
我们通过曲率 (s)来衡量,其定义为
(s)来衡量,其定义为

即单位切向量在沿曲线的距离单位变化中的变化量的大小。
向量T是一个单位向量,没有维度;即它不受所有坐标的统一比例变化的影响。另一方面,s 是一个长度;因此 具有长度的倒数,即距离的倒数的维度。
具有长度的倒数,即距离的倒数的维度。
描述曲率所代表的信息的第二种方法是有的。参数 t 处的曲线的曲率中心是点 q(t),使得以 q 为圆心的圆与我们的曲线在 r(t)处相交,将在那里具有相同的斜率和曲率。
那个圆的半径称为参数 t 处曲线的曲率半径。
我们将看到,曲率半径,即长度,正好是 ,曲率的倒数。
,曲率的倒数。
在下一节的应用程序中,您可以输入您喜欢的参数化曲线,并查看曲率圆。
曲率的中心和曲线的切向量T(t)确定一个平面,称为曲率平面。
由于圆的半径始终垂直于切向量,因此从r(t)指向曲率中心的线将垂直于T。称为曲线的法向量的向量N(t)是一个从r(t)指向曲率中心的单位向量。
B(t),即"法向量"是一个单位向量,垂直于T 和 N,即曲率平面。按照惯例,其方向为T N。
N。
我们定义 a(t)(加速度)为 v(t)(速度)关于 t 的导数。按照这些术语,T 是 v 方向的单位向量,N是指向垂直于 v 的法线的投影方向的单位向量,而 B 是指向 va 的单位向量。
由曲线在“时间”t 处定义的“Frenet 框架”是单位向量集合,T(t),N(t)和 B(t)。
15.4 曲率的计算
对于曲线的曲率和各种感兴趣的方向的计算相当简单,只要给出曲线的参数表示,我们就可以指示电子表格计算沿着我们的曲线的所有内容。
向量 ,根据链式法则为
,根据链式法则为 是
是 的倒数,也可以写成
的倒数,也可以写成 。
。
由于T是指向 的单位向量。
的单位向量。
对于这个后面的表达式关于 t 的导数,根据商规则有

我们可以将 识别为我们用a(t)表示的运动的加速度。
识别为我们用a(t)表示的运动的加速度。
我们需要在这里对|v|关于 t 进行微分,鉴于
将所有这些放在一起,我们发现

这个结果看起来有点混乱,但实际上并不那么糟糕。回想一下 是a垂直于v的投影。因此,我们在这里有
是a垂直于v的投影。因此,我们在这里有 是垂直于v的a的投影除以v的大小的平方。
是垂直于v的a的投影除以v的大小的平方。
因此,曲率,即这个向量的大小,是垂直于 v 的法向量的分量除以 v 的大小的平方。

考虑螺旋线的例子:x� =� cos t, y = sin t, z = t。
我们可以计算:
这里a和v是垂直的,因此我们得到对于所有 t 值都有 。
。
曲率中心在通过计算的曲线上的点在 z 轴上的反射处,即在坐标为(-cos t, - sin t, t)的点处,距离(cos t, sin t, t)在a垂直于v的投影方向上的投影的方向上 2(或 )的距离。
)的距离。
练习:
15.1 证明圆的曲率为 。(这证明了曲率半径为
。(这证明了曲率半径为 。)
。)
15.2� 对于以下曲线(使用电子表格),找到曲率,位置 r 和曲率中心在 处,j = 0 到 700
处,j = 0 到 700
x= cos t, y = cos 2t, z = sin 3 t
尽力绘制它。
15.3 在 applet 上设置这条曲线。曲率最大的地方在哪里。
15.5 挠率
我们可以进一步。下一个感兴趣的量是曲率平面的“扭转”程度。这由曲线的挠率  来衡量,这是曲率平面法线相对于曲线上的距离的导数的大小。
来衡量,这是曲率平面法线相对于曲线上的距离的导数的大小。

这个导数可以直接计算得到。正如前面已经提到的,B(t)可以根据以下方式书写

根据链式法则,我们有

进一步注意到我们可以应用乘法规则来得到叉积�

而后一项为 0。
我们还有

我们还可以使用恒等式

将所有这些放在一起� 我们得到

我们发现挠率是这个的大小,因此是 分量的大小除以 a 和 v 构成的平行四边形的面积。
分量的大小除以 a 和 v 构成的平行四边形的面积。
没有人记得这个公式。满足于知道它的存在,知道如果你被迫这样做,你可以自己计算它,并且它可以设置为用电子表格自动计算。
练习:
15.4 作为对你手动技能的测试,看看你是否能够自己完成上述步骤并得到正确答案(我希望是上面给出的答案)。
15.5 创建一个电子表格来表示练习 15.3 的曲线和定义域,并在参数的代表值上计算其曲率和挠率,以及相同数值下曲线的坐标。在你的范围内,挠率最大在哪里?
第十六章:一些重要例子和物理中的一个表述
引言
牛顿定律规定具有质量 m 和坐标 x 的物体的运动可以用方程F = ma描述,其中a,物体的加速度是其位置 x 关于变量时间 t 的二阶导数,F是物体所受的力。
单个物体在三维空间中移动,其中力、位置和加速度都是向量。有一些简单的基本上是一维的例子,对于一般情况来说是如此重要以至于有普遍的重要性。我们考虑其中的两个。
我们还考虑了F = ma的一个重要的替代表述。
主题
16.1 恒定力
16.2 线性恢复力
16.3 哈密顿量
16.4 量子力学是什么?
16.1 恒定力
物体在地球表面上受到地球引力作用而运动是这样一个具有这样一个力的系统的例子。
当加速度是恒定的并且由-gk给出时,我们可以推导出物体的速度v(t)遵循
v(t) = v(t[0]) - g(t - t[0])k
这个速度是一个位置向量r(t)的导数,必须采用以下形式

到目前为止我们还没有讨论如何推导这些东西,但我们可以通过对r和v进行微分,并在时间 t[0]检查它们的正确性来验证它们。
(一般来说,如果加速度以 t 的多项式函数给出,我们可以生成包含多项式的形式,其次数比加速度大一和两个的速度和位置向量描述,并调整它们的系数以产生它们的正确公式。
然而,物理现象很少由明确依赖于时间的力和加速度描述。相反,最重要和基本的情况是物体经历一个与其位置线性相关的力。
虽然这些方程提供了在三维空间中受恒定加速度影响的运动问题的完整解,但它们并不能方便地回答我们可能提出的所有问题。
因此,我们可以使用它们来确定任何时间 t 的r和v,但它们并不特别方便用于推断r作为v的函数,反之亦然。
为了帮助回答这类问题,我们通过以下定义能量函数 E

这些术语中的第一个被称为物体的动能 T,第二个是它的势能 V。物体所受的力可以写成- V;E 对时间的导数则为
V;E 对时间的导数则为

这个事实,称为能量守恒,更普遍地成立:每当 F 可以被写成梯度时。
在这里,如果我们知道任何时候的 E 的值,我们可以利用它来计算 z 作为 v 的函数,或者反之亦然,从上面的表达式中得出 E。
16.2 线性恢复力
一个普通的弹簧的行为由线性恢复力描述。弹簧具有一个正常长度 x[e],如果拉伸或压缩,它会经历一种强度为
k |x-x[e]|
将其推回或拉回到其正常位置。这可以用以下力律描述。

我们可以通过一个势能函数 V 描述这样的力,该函数由  给出,并且再次具有能量守恒。
给出,并且再次具有能量守恒。
如果运动以质量 m 来描述,则系统遵循的微分方程是�

可以重写为

这正是  (以及 cos wt)遵循的微分方程。
(以及 cos wt)遵循的微分方程。
因此,我们可以得出结论

其中 c 和 d 是依赖于弹簧的位置和速度的初始值的常数。一般解也可以写成正弦和余弦项的和。
这个系统具有一个有趣的特性,这里出现的参数 w(顺便说一句,它是正弦运动的频率的度量,以及它的周期),只取决于 m 和 k,而不取决于初始条件。
此系统的势能函数为  。
。
一旦你知道系统中的能量,你可以再次利用能量守恒来推断速度与弹簧伸长之间的关系。
这里的解决方案,弹簧永远振荡,显然是不现实的。
弹簧停止移动。这是因为我们刚刚使用的模型遵循弹簧运动的能量守恒,而在现实中,弹簧运动中有空气阻力和一些摩擦,当你开始时,其中的一些能量会被转化为热量。
同样地,空气阻力会改变抛出的球的运动,例如在常重力情况下。
我们将很快考虑模拟摩擦和空气阻力的力律。首先,我们考虑牛顿运动定律的一个重要改写,可以应用于保守系统,即类似我们在这里考虑的两个系统,其中能量是守恒的。
要理解一个物理系统,你需要对它在不受干扰时的行为有所感觉,以及这取决于它的参数,还要了解它对外部刺激的反应,即外部强迫函数。
乍一看,你可能会认为有很多不同的可能刺激,这是一个不可能的任务。
研究此响应的标准方法是检查作为频率函数的周期性强迫函数的响应作为该频率的函数。
然后我们希望通过使用这些信息来描述对更一般的刺激的响应。这是通过称为傅立叶分析的过程完成的,该过程在第 30.6 节中简要讨论。
在第 33.3 节中,我们描述了如何在电子表格上解决接下来提到的二阶微分方程。这很容易做到,并且您可以使用在那里讨论的方法来研究振荡器的行为。
振荡器的微分方程可以写成
Mx" = -kx - f x' + csin wt
其中 x 是迄今为止称为 x-x[0] 的变量,M 是弹簧质量,k 是弹簧常数,f 表示系统受到的摩擦损失,w 是强迫函数的频率,c 是其振幅。
在自由系统中,c 是 0\。
练习:
**16.1 首先按照第 33.3 节描述的方案进行操作,以便在没有摩擦的情况下(因此 f = 0)观察发生的情况。
您可以选择您的 x 的比例,使得 M = 1,并假设您的 t 的比例是 k = 1。
您可以绘制 x 和 x' 相对于 t 和 x 相对于 x' 的图表,然后查看以下问题:**
16.2 当你将 k 乘以 4 时会发生什么?
16.3 当你为 f 引入一个小的正值时会发生什么?
16.4 当你保持 k 和 M 不变时,随着 f 的增加会发生什么?
当 f > 0 且 c = 0 时的振荡被称为瞬态。
当 f 和 c 都是正值时,那么就像 c = 0 一样存在瞬态行为,但同时也存在对强迫函数的稳态响应。
一个有趣的参数是稳态响应的振幅与 c 的比值,作为 w 的函数(其他参数固定)。
16.5 找到使此参数最大的 w 的值,对于 M - k = 1 且 f = .1。
16.6 当你将 f 增加到 .2 时会发生什么? .3? .5? 1?
16.3 哈密顿量
牛顿定律涉及力,而力是向量,比普通函数更难处理和思考。当处理一个复杂的系统时,通过描述系统的能量并从中推导出力,比直接跟踪力要容易得多。
在十八世纪末和十九世纪初,物理学家们开始设想以能量函数的形式重新表述运动定律,特别是对于能量守恒的相互作用对象系统。
最重要的重新表述涉及定义一个名为哈密顿量的函数�。它是我们之前遇到的能量 E,但是不是用位置和速度变量而是用位置和动量变量表达的。
例如,假设我们有一组物体,每个物体有三个位置变量和相应的动量变量。与 相对应的动量变量!,它本身是第 i 个物体的 x 坐标,则为!。然后物体 i 的动能为
相对应的动量变量!,它本身是第 i 个物体的 x 坐标,则为!。然后物体 i 的动能为 。如果它们之间存在相互作用的势能(例如由引力引起的),那么将会有形如
。如果它们之间存在相互作用的势能(例如由引力引起的),那么将会有形如 的每对物体 i 和 j 之间的势能项。
的每对物体 i 和 j 之间的势能项。
系统的哈密顿量,H,�,将如下所示

在这种表述中,对应于F = ma的运动方程为:
对于每个带有动量和位置 p[i]和 r[i]的粒子 i,以及每个方向 d,我们有

(这里的下标 d 指的是方向 x,y 和 z。)
这些方程被称为哈密顿方程。
实际上,在这种情况下,它们与牛顿方程具有相同的内容。它们的重要性特别在于量子力学最容易以哈密顿量的术语来描述。
如果我们在这里选择一个关于位置和动量变量的函数 Z,那么它的时间依赖性可以通过链式法则计算为

将哈密顿方程代入这里我们得到

这里略显难看的最后两项被称为 Z 和 H 的“泊松括号”,并写为{Z, H},因此我们有

练习:
16.7� 考虑由太阳和地球组成的系统,它们之间的势能为  。写出这个系统的哈密顿方程。
。写出这个系统的哈密顿方程。
16.2 径向力(正或负)称为中心力。以上例子暗示的地球上的力是其中的一个例子,如果我们选择太阳为原点。计算该系统中 r[e]**** v[e]的时间导数。
v[e]的时间导数。
16.4 什么是量子力学?
在研究原子中电子的行为时,物理学家遇到了以下难题:
电子似乎被电静力的影响困在原子周围的轨道上,就像行星在引力的影响下围绕太阳运行一样。引力和电静力吸引的力律实际上是相同的,电子似乎沿着具有明确定义能量的轨道运动。
另一方面,我们知道电子是带电粒子,我们也知道加速带电物质会根据麦克斯韦方程辐射能量,并最终停止。
任何人能想到的唯一结论是电子以某种方式在轨道上,其电荷密度随时间保持恒定。
但是,如果将电子设想为被限制在一个点的带电粒子,这怎么可能呢?唯一合理的静止点将是原点,但电子却分布在相当大的区域上。(直径约为 10^(-8)cm)
物理学家通过改变他们设想物理系统的方式做出了回应。
最初,人们认为电子具有可测量的变量,如位置和动量,这些变量是数字,描述它们的运动问题是发现它们的轨道。
他们转而认为系统的状态应该被描述为向量,可测量的变量被描述为作用于这些向量的线性变换(想象矩阵)。
在这种描述中,由矩阵 M 描述的变量在具有行向量<s|和列向量|s>的状态中的值是<s|M|s>。
在这种表述中,系统的动态发展源自基本运动方程:状态向量的时间导数与作用于该向量的哈密顿矩阵成比例。
量子力学的另一个有趣特征是,使用位置 x(由一个数字表示,这意味着状态是位置算符的特征向量,相应的动量变量表示为 的倍数)为基础,这些变换(或算符或矩阵)显然不对易。(您也可以定义一个相反的基础)。
的倍数)为基础,这些变换(或算符或矩阵)显然不对易。(您也可以定义一个相反的基础)。
测量一个变量并发现它的值为 z 是什么意思?
这意味着将系统的状态从原来的状态投影到具有特征值 z 的变量的特征向量(或如果有多个“特征空间”)。
当代表两个变量如 x 和的算符不对易时,这意味着什么?
这意味着它们没有共同的特征向量,因此不能同时测量。(如果同时测量,系统将被两者的特征向量所描述。但 x 和 没有共同的特征向量。)
没有共同的特征向量。)
这里使用的是什么样的向量空间?
这被称为希尔伯特空间;它是无限维的,描述每个方向上的分量的数字是复数。
原子中电子的状态是持续一段时间的稳定状态。它们是电子哈密顿量的特征态或特征向量。
它们实际上确实随时间演变,但并非以易于观察的方式;它们的状态在复平面上的角度变化,而这并不改变它们的电荷密度。
这个讨论不能假装教给你任何有关量子力学的有价值的东西,除了这样一个事实:它可以被看作是对这门课程中的概念的应用,每一个概念都变得无序起来。
这个方案能够以惊人的精度描述原子光谱。而且它还解释了更多其他事情。
第十七章:乘积法则和矢量微分
介绍
对于向量导数,微分的乘积法则同样适用。实际上,它允许我们推导出在非矩形坐标系中形成散度的规则。这可以通过找到指向每个基方向的具有 0 散度的向量来实现。
主题
17.1 介绍
17.2 乘积法则和散度
17.3 球坐标中的散度
17.4 乘积法则和旋度
17.1 介绍
在对称函数进行微分时,即被称为标量场的函数时,函数的梯度包含了所有关于切(超)平面(或线性近似或微分)的信息。
当微分向量场时,即关于几个变量的矢量值函数时,在每个方向的每个分量都有偏导数;因此在三维空间中有九个分量。
然而,散度和旋度在应用中具有特殊的重要性,我们将重点关注它们。它们表示为

对于

17.2 乘积法则和散度
现在我们来回答一个问题:如何应用乘积法则来评估这些内容?
"del"运算符和点积和叉积都是线性的,并且每个偏导数都遵循乘积法则。
我们的第一个问题是:什么是 
应用乘积法则和线性性我们得到

这有什么用?
借助它,如果你要求的散度函数可以写成某个函数乘以一个你知道或者可以轻松计算其散度的向量,那么求解散度就简化为求解该函数的梯度,利用你的信息并进行点乘。
练习 17.1 矢量场(x, y, z)的散度是多少?(-y, x, 0)的散度是多少?
17.3 球坐标中的散度
当你用球坐标或圆柱坐标描述向量时,也就是说,将向量写成由这些坐标定义的单位向量的倍数之和时,计算导数时会遇到问题。
单位向量本身随着坐标的变化而变化,因此您的向量的变化由于倍数的变化以及单位向量的变化而产生。
我们可以通过找到指向这些单位向量方向且具有 0 散度的向量来在这些坐标系中找到散度的简洁表达式。
然后,我们将我们的向量场写成这些向量的线性组合,而不是单位向量的线性组合。
根据乘积法则,我们寻找的散度表达式将是这些向量之一与其系数的梯度的点积的三个方向之和。乘积法则中的第二项都将为 0。
在将来的生活中,您很可能会遇到在这些坐标中表达散度的需要,因此我们将使用球坐标系来进行这种方法。
首先请注意:每当您在极坐标中微分函数时,您必须单独并仔细地处理其中的原点。坐标本身在那里是奇异的!最安全的做法是添加"除了 r = 0"或类似的声明,除非您确定您的结论在那里是合理的。通常情况下,它在您的坐标原点处是不成立的。
下面省略了这样的注意事项,但在涉及极坐标参数的微分时,您应该假设它们存在。
做这个过程中唯一非平凡的步骤是找到各个所需方向上的具有 0 散度的向量。这可以通过找到这些方向上任何向量的散度,并计算在每种情况下需要应用的倍数来抵消其散度,再次使用散度的乘积定理来完成。
向量(x, y, z)在球坐标系中径向指向,我们称之为 方向。它的散度为 3。
方向。它的散度为 3。
它也可以写成 或
或
因此,将其散度转换为 0 的乘数必须具有梯度,根据乘积定理,是 乘以自身。
乘以自身。
函数 正是这样做的,因此在方向上的 0 散度函数是
正是这样做的,因此在方向上的 0 散度函数是
练习 17.2 注意到(x, y, 0)的散度,也称为 r 或 ru[r],为 2。你应该乘以 r 的什么函数才能得到一个散度为 0 的向量呢?
向量(-y, x)指向 方向,已经具有 0 散度。它可以写成
方向,已经具有 0 散度。它可以写成
 方向是这两个方向的法向量,您可以通过取(-y, x, 0)和(x, y, z)的叉积得到一个在其中的向量,结果为(xz, yz, -r²)。
方向是这两个方向的法向量,您可以通过取(-y, x, 0)和(x, y, z)的叉积得到一个在其中的向量,结果为(xz, yz, -r²)。
这个向量的散度为 2z,形式为 rzu[r]- r²u[z]。
这两个项中的第一个项,rzu[r](即(xz, yz))具有非零散度,导致它的是 x 和 y,而不是 z 因子。我们可以借助上一个练习的结果引入一个乘数来消除该散度。
结果向量的形式为  ,其长度为
,其长度为  因此可以写成
因此可以写成 
总之,向量  具有 0 散度。
具有 0 散度。
如果我们将这些组合定义为  ,那么形式为
,那么形式为  的向量也可以写成
的向量也可以写成

其散度是

或

或

这就是球坐标中的散度形式。
在这里的最后一行中,我们使用了球坐标中的梯度形式:请记住, 是一个极坐标变量,其半径为 r, 是一个极坐标变量,其半径为 。还请记住,r 是 sin。
这最后一个表达不太漂亮,但在物理应用中相当重要。
它特别出现在组合  中,称为 f 的拉普拉斯。
中,称为 f 的拉普拉斯。
在矩形坐标和球坐标中,拉普拉斯采用以下形式,这些形式来自梯度和散度的表达式

练习:
17.3 找到  的散度
的散度
17.4 根据上面对球坐标的逻辑,推导出柱坐标中的散度形式。应用它来找到柱坐标中的拉普拉斯。
17.4 乘积法则与旋度
乘积法则应用于旋度的形式为

(这是一维乘积规则和我们所有乘积的线性性的直接推论。当这些导数作用于 f 时,它们形成这里的第一项,当它们作用于 v 时,它们形成第二项。这里的怪异星号表示普通乘法。)
最后一节中用于减少球坐标中散度计算的方法同样适用于旋度的计算。
你会记得,方法是找到指向正确方向的具有 (0) 旋度的向量,将一般向量表示为这些向量的组合,并使用乘积定理来表示结果。有了旋度为 (0),乘积定理中的两项之一消失了,我们就得到了我们的公式。
你需要做的就是找到每个适当方向上旋度为零的向量。这很容易做到,因为任何函数的梯度都会有旋度为零。
因此,我们可以取和以及的梯度,这些将是指向正确方向的向量,并立即给出

通过乘积定理,我们推导出

不幸的是,我必须承认在任何情境下我从未使用过这个结果。所以你可以放心地忽略它,我想。
练习:
17.5 找到柱坐标中与旋度类似的表达式。
17.6 找到 的旋度
的旋度
第十八章:复数及其函数
引言
复数、它们在复平面上的表示以及在复平面上定义的函数在许多学科中都非常重要。基本性质得到了回顾。
主题
18.1 符号、用大小和角度表示复数、实部和虚部
18.2 复变函数
18.3 函数 z 的 z = x + iy,没有旋度,作为向量
18.4 德莫弗定理
18.5 对数和角度的多值性问题
18.1 符号、用大小和角度表示复数、实部和虚部
为什么要研究复数和复变函数? 答案
我们引入 i,即 -1 的平方根,以允许负数有平方根,这是普通实数中没有的。
复数可以被描述为二维欧几里得空间中的向量。
我们通常使用 x 变量表示数字的实部,使用 y 变量表示其虚部。因此,在处理复数时,基础向量i和j分别是数字 1 和 i。
数字 (1 + i) 可以表示为向量 (1, 1)。
在这个背景下,向量的长度 r 是分量的平方和的正平方根。
对于数字 (a + ib),r 是 (a + ib)(a - ib) 的平方根。
角度  的定义与向量完全相同。
的定义与向量完全相同。
我们通常将这个向量的 x 分量称为其实部,将 y 分量称为其虚部。
复数具有普通向量所缺乏的附加属性,即我们可以定义它们之间的乘法,使其遵守算术的通常交换、结合和分配律。这一事实允许按照我们用来定义普通实函数的规则来定义复值函数。
18.2 复变函数
依赖于组合 (x + iy) 的 (x, y) 函数被称为复变函数,而这种函数在这个变量上可以展开成幂级数的函数尤为重要。
这个组合 (x + iy) 通常被称为 z,并且我们可以定义诸如 z^n、exp(z)、sin z 以及所有标准 z 函数的函数,以及 x 函数。
它们的定义方式完全相同,唯一的区别是它们实际上是复值函数,也就是说,它们是这个二维复数空间中的向量,每个向量都有一个实部和一个虚部(或分量)。
我们先前讨论的大多数标准函数具有一个性质,即当它们的参数为实数时,它们的值是实数。明显的例外是平方根函数,对于负参数它变为虚数。
由于我们可以将 z 乘以自身和任何其他复数,因此我们可以形成 z 的任何多项式和任何幂级数。我们通过它们在复平面上处处收敛的幂级数展开式来定义 z 的指数和正弦函数。
由于产生标准函数的所有操作都可以应用于复杂函数,因此我们可以通过与产生实变量的标准函数相同的步骤来产生复变量的所有标准函数。
18.3 z 的函数,z = x + iy,在向量方面没有旋度
我们已经看到,在向量中,函数 r 维度单位向量的旋度在导数被定义的地方为 0。关于变量 z 的任何函数 f 的一个类似的陈述也有。
我们可以通过对 f(z) 进行微分的链式法则来推导它。

由于  是 1,而
是 1,而  是 i,我们发现
是 i,我们发现

并且在取此方程的实部和虚部时,我们得到

这些条件告诉我们,对于 x + iy 的函数的实部和虚部的“梯度向量”在复平面的任何地方都是正交的。
将这两个方程结合起来告诉我们任何 z 的两次可微函数的实部或虚部的二维拉普拉斯算子都为 0。
练习 18.1 在此明确推导这个性质。
我们可以将任何函数 f(z) 的实部或虚部表示为两个变量 x 和 y 的实函数。
我们可以将其作为三维图像,或者可以使用“等势线”方法,在平面图中通过等势线来表示任一函数。
在讨论该表示时,我们注意到我们还可以在适当点将梯度向量连接在一起形成路径,有时这些路径被称为“力线”,因为它们在某些物理上下文中是如此。
我们讨论的关系告诉我们的是,任何适当可微函数的 z 的实部的等势线都是虚部的力线,反之亦然!
例如,考虑函数 z²。它的实部是 x² - y²,虚部是 2xy。
练习:
18.2 使用 applet 查看每个的等高线;并验证其中一个的等高线是否与另一个的垂直。
18.3 尝试计算  ,其中 x 和 y 均小于 1。
,其中 x 和 y 均小于 1。
18.4 德莫弗定理
变量 z,z = x + iy 可以用它的长度和角度表示,就像任何二维向量一样,关系如下

德莫弗定理是这样陈述的: 。因此,我们可以写成
。因此,我们可以写成

18.5 对数和角度多值性问题
z 的对数可以从上一个方程描述为

这个公式存在一个问题,问题在于角度  在复平面上不是一个良定义的函数,因此 ln z 也不是。
在复平面上不是一个良定义的函数,因此 ln z 也不是。
困难在于,当我们逆时针绕原点转动时,角度不断增加,并在每一次旋转后增加 2 。
。
因此,对于给定的 z 值,对数的值取决于你是如何到达的;除非你人为地限制其角度,比如范围从 - 到 。如果这样做,函数 ln z 在负实轴上是不连续的。
对于像 x^(1/2) 和 x^(1/3) 这样的反幂函数也存在类似的问题。
有几种方法可以解决这个问题。
通俗的方法是通过引入一个为它们定义的不连续线,称为切线,来精确定义这样的反函数。
因此,对于对数函数,你可以说它的虚部,,的值从 0 到 2。如果是这样,它在正实轴上是不连续的,一个一侧为 0,另一侧为 2。
或者你可以让它的值从 - 到 +,这样它的不连续线就是负实轴,你可以选择从原点开始的任何其他半不连续线。
处理这个问题的另一种方法是将复平面替换为一个称为黎曼曲面的几何结构,在此曲面上,所涉及的函数是单值的,没有不连续性。
对于对数函数来说,这个曲面绕着原点旋转。对于平方根来说,如果你绕原点转两圈,你会回到起点。
练习:
18.4 为函数 (z² - 1)^(1/2) 定义一个适当的切割系统。你能找到一个定义其切割线为单线段的定义吗?
18.5 描述每种情况下此函数的黎曼曲面。
第十九章:反导数或不定积分
介绍
找到反导数就是找到一个在一系列值上具有给定导数的函数。 可以做到这一点的导数类别以及一些找到反导数的方法都在描述。
主题
19.1 Introduction
19.2 反导数的非唯一性
19.3 通过观察找到反导数以及我们可以反导数的函数类
19.4 替换
19.5 分部积分
19.6 关于参数的微分
19.7 偏分解
19.1 介绍
如果我们想要研究由某种物理或其他情况定义的未知函数,那么分析的方法就是研究其导数,作为适当变量的函数,并从中推导出一个方程。
这个方程通常是微分方程的一个例子,微分方程是涉及未知函数的导数的方程。解微分方程的过程称为积分。
当我们有一个关于单变量 x 的区间上的函数 f 的导数的显式公式,并且此公式仅依赖于自变量 x 时,这个问题的一个重要特例发生了。
我们想要尽可能多地了解这些信息能为我们提供的关于函数 f 的信息。
因此,我们希望从 g(x),其中 ,对于 a < x < b,到达 f(x);我们想“撤销”微分算子
,对于 a < x < b,到达 f(x);我们想“撤销”微分算子 ,并且这可以被称为找到 g(x)的反导数来找到 f(x)本身或者尽可能多的关于它的信息;这个任务的标准名称是找到反导数的。
,并且这可以被称为找到 g(x)的反导数来找到 f(x)本身或者尽可能多的关于它的信息;这个任务的标准名称是找到反导数的。
这个过程也被称为找到关于 x 的 g(x)的不定积分。
我们将不再使用这个术语,因为我们想以完全不同的方式定义定积分,并且想要避免这两个概念之间的混淆。
当然,你可以从名称的相似性中预料到 定积分(此处根本没有定义)和此处的反导数之间会有密切关系。如果你这么猜,你是对的。但是这种关系是一个基本定理,称为微积分的基本定理。
19.2 反导数的非唯一性
找到类似于定义函数的逆的问题与找到反导数的困难相似,该函数在某些参数上取得多个值。 知道原始函数达到其中一个值并不能确定逆函数;在这种情况下,需要以附加条件的形式提供额外信息,以区分可能被称为逆函数的多个可能原始参数之间的差异。
从导数到函数的过程中,我们必须面对常数的导数为零的事实:因此,我们可以将任何常数添加到任何可能的反导数中,并得到另一个同样有效的反导数。
这实际上是说要完全确定一个反导数,你必须添加额外的信息。特别是函数在任一参数处的值足以通过其定义域上的导数来确定它。
因此,我们必须认识到没有附加条件的情况下,对于给定的 g,没有一个单一的反导函数 f;我们可以找到一个反导函数,或者描述所有反导函数(在这种情况下,你应该给任一反导函数加上 +c),但在另外指定附加条件之前使用术语“g 的反导函数”并不完全正确。
(我记得当我在古代学习微积分时,我们必须玩一个类似于“西蒙说”的游戏,带着 +c;如果问题是这样提出的,答案必须有 +c;否则不带。正如我从更久远的时候记得的那样,很容易让一个人分心以输掉西蒙说的游戏,同样容易忘记在需要时写上 +c。)
19.3 凭眼观察求反导数和我们可以反区分的函数类
区分已知标准函数的过程可以通过解析函数定义并将适当的区分规则应用于其定义的每一步来实现。
没有特定的反区分规则;我们必须反向使用区分规则。这些规则允许我们反区分大量标准函数,但并非全部。
我们几乎可以立即将一些函数识别为其他函数的导数。例如,我们可以通过将规则应用于反向区分幂来反区分 x 中的任意多项式。
因此, 的一个反导数(当反区分多项式时,一个标准错误是在做这个过程中精神上出现疏忽,而不是反区分某个项;请始终检查你是否已经这样做了。)
的一个反导数(当反区分多项式时,一个标准错误是在做这个过程中精神上出现疏忽,而不是反区分某个项;请始终检查你是否已经这样做了。)
我们可以类似地反区分任意幂(甚至  ,其中之一的反导数是 ln(x))。而且我们可以反区分 e^(ax) 和 任意多项式的 sin(x) 和 cos(x),尽管后者需要应用一些技巧。
,其中之一的反导数是 ln(x))。而且我们可以反区分 e^(ax) 和 任意多项式的 sin(x) 和 cos(x),尽管后者需要应用一些技巧。
原来,还有更多的技巧可以让我们对任何有理函数  进行求导,其中 p 和 q 是多项式,如果我们可以将 q(x)分解为一次和二次因子;还有一些技巧可以让我们对指数与多项式、正弦和余弦的倒数、多项式除以线性或二次函数的平方根、指数正弦和多项式的乘积以及其他各类函数进行反求导。
进行求导,其中 p 和 q 是多项式,如果我们可以将 q(x)分解为一次和二次因子;还有一些技巧可以让我们对指数与多项式、正弦和余弦的倒数、多项式除以线性或二次函数的平方根、指数正弦和多项式的乘积以及其他各类函数进行反求导。
另一方面,有一些看起来简单的标准函数我们无法反求导,因为它们的反导数恰好不是标准函数。
(如果这些反导数足够重要,我们会给它们起名字,制作表格,并将它们添加到我们基本函数列表中(目前包括 x、sin x 和 e^x)。但事实证明,它们很重要,但不是那么重要;我们给它们起名字、列表格,但称它们为特殊函数。
最简单的不能作为标准函数反求导的函数是 ,这两个函数都有特殊函数作为特定的反导数。
,这两个函数都有特殊函数作为特定的反导数。
在微积分教师中,曾经存在着一种争论,即学生是否应该学会所有反求导的技巧,以便对任何可反求导的东西进行反求导。
有些人认为,掌握微积分的标志是能够通过尝试应用各种技巧来进行反求导,从而对奇怪的函数进行反求导。其他人指出,有“积分表”,列出了基本上所有可反求导函数及其反导数,因此,这种技能,其发展是一种奇妙的智慧和记忆练习,但实际价值非常有限。
当时学生面临的障碍是,他们很难获得一本相对完整的积分表副本,并且很难在庞大的积分表中查找内容,这使得第一个观点稍微占据了一点优势。
然而,今天,有商业可用的程序,如 Maple、MATLAB 和 Mathematica(也许还有其他程序),它们可以为您输入的任何函数提供详细的反导数公式,并且立即执行;这似乎使争论倾向于第二个观点。
无论如何,每个微积分学生都应该了解反求导的四个基本工具,我们现在讨论这些工具。
在这样做之前,我们应该注意到一个重要事实,即找到反导数是一个线性操作(与求导相同),因此一个和的反导数是其和的各项的反导数之和。
19.4 替换
到目前为止,反积分最重要的工具是将链式法则反向应用;这意味着给定一个函数 f(x),找到一个函数 u(x),使得你可以将 f(x) 写成 在这种情况下,你可以声明 f 的一个反导数是 g(u(x))。
在这种情况下,你可以声明 f 的一个反导数是 g(u(x))。
(这种写法看起来复杂,但实际使用起来比看起来容易。)
例如,假设我们有 f(x) = sin⁵ x cos x。
然后我们可以设定 u(x) = sin x,并找到 ,我们可以将其识别为
,我们可以将其识别为 的导数,这就是 f 的一个反导数。
的导数,这就是 f 的一个反导数。
相同的思想可以用于反积分任何奇次正弦和余弦多项式,如果你应用恒等式(sin²x + cos²x = 1)将所有项转换为一个正弦或余弦的线性形式,就像上面的 f 一样。
使用这种技术被称为“替换”;变量 u 在某种意义上替代了 x。
注意,如果我们能够识别 f(x) 是已知函数的导数,那么我们可以通过检查进行反积分。
使用 u(x) 的替换,我们将问题转换为:我们能否将 识别为 u 的函数的导数?
识别为 u 的函数的导数?
在上面的例子中,新问题变成了:我们能否将 sin⁵ x 识别为关于变量 sin x 的导数?由于 sin⁵ x 是 sin x 的幂,我们可以将其识别为 的导数,从而找到了 f 的一个反导数。
的导数,从而找到了 f 的一个反导数。
有一些众所周知的标准替换,可以让我们对许多潜在有用的函数进行反积分。我们在下面进行回顾。
寻找适当的替换可能有助于找到某个特定反导数,这有点像智力侦探工作。这类似于解决国际象棋问题,虽然也许没有实际价值,但可能是一个很好的锻炼,可以培养你的推理能力或者找到一开始看起来像大海捞针的东西的能力。
这里有一些函数类(称为被积函数),你至少应该在理论上能够积分。细节可能变得复杂和乏味,但这仅仅意味着你不会被要求经常做这些计算。
1. 任何 x 的多项式。 这些可以直接通过逐项使用反向幂规则来进行检查。
2. 任何 x 的单一正或负幂次, 如 (x-3)^(1/3) 或 (1-x)^(-1)。同样的方法。
3. 任何指数形式如 e^(ax)。 同样,可以直接应用不同 iating exponents 的规则进行反积分。
4. 任何正弦和余弦的多项式乘以任何指数,就像最后一种情况一样。在这里,你可以使用正弦和余弦的指数公式,将其转换为一组指数的丑陋和,每个指数都适用于情况 3。一些指数将是复数,但又怎样���
5. 函数  ,其积分是 (x-a) 的反正切。
,其积分是 (x-a) 的反正切。
6. 任何 x 的有理函数,即任何形如  的函数,其中 p 和 q 都是多项式。要做到这一点,你必须能够将 q 因式分解为线性(也许是二次的)项,使用后面讨论的"部分分式展开"技术,然后使用上述的情况 1、2 和也许 5 进行积分。
的函数,其中 p 和 q 都是多项式。要做到这一点,你必须能够将 q 因式分解为线性(也许是二次的)项,使用后面讨论的"部分分式展开"技术,然后使用上述的情况 1、2 和也许 5 进行积分。
(思路是  可以写成一个多项式和 q(x) 的零点的单个倒数幂之和(如果你不喜欢使用复数零点,也许还有类似情况 5 的项)。)
可以写成一个多项式和 q(x) 的零点的单个倒数幂之和(如果你不喜欢使用复数零点,也许还有类似情况 5 的项)。)
7. x 的正弦和余弦的有理函数(理论上)。这可以通过神奇的代换  减少为一个有理函数,然后应用情况 6。对于一个复杂函数完成这个过程的想法对我来说太可怕了,但它应该有效。理论上,对于 sinh 和 cosh 的有理函数,使用代换
减少为一个有理函数,然后应用情况 6。对于一个复杂函数完成这个过程的想法对我来说太可怕了,但它应该有效。理论上,对于 sinh 和 cosh 的有理函数,使用代换  应该也可以。
应该也可以。
8. 任何  和 x,或者
和 x,或者  和 x,或者
和 x,或者  和 x 的有理函数。 要做到这些,你可以使用代换 x = sin t,或者 x = cosh t 或者 x = sinh t,分别得到 t 的正弦和余弦的有理函数,然后可以应用情况 7 完成任务。
和 x 的有理函数。 要做到这些,你可以使用代换 x = sin t,或者 x = cosh t 或者 x = sinh t,分别得到 t 的正弦和余弦的有理函数,然后可以应用情况 7 完成任务。
9. x 和一个平方根的有理函数,要么是线性函数要么是二次函数。(一个丑陋的例子是  ;这里是另一个
;这里是另一个  。)
。)
如果你有一个线性因子的平方根,你可以使用代换 t = 那个平方根因子,将你的被积函数转换为一个有理函数,然后可以使用情况 6 进行积分。
对于二次因子,你可以完成平方,然后进行线性替换,将被积函数转换为情况 8 的形式之一。
能够识别这些方法可能适用的被积函数类别是个好主意。然而,除非你在做任何事情时从不犯错误,否则我建议你如果被迫做一个复杂的后续类型的积分,最好使用 Maple 或 Mathematica 或类似的工具来实际完成。
有一些简单的例子可以练习,以了解涉及的内容。
10. 正弦、余弦或指数与 x 中的多项式的乘积。
这可以简化为对每个多项式中的幂进行正弦、余弦或指数与单个幂的乘积,并将结果相加。
后面的积分可以通过分部积分或关于参数的微分来完成,这两种方法都在下面讨论。
11. 指数、正弦和余弦的多项式与 x 的多项式的乘积。这可以通过使用三角函数的复指数表达式将其简化为情况 10。
12. 涉及对数和其他函数的积分。你可以通过分部积分来消除对数,然后,如果你得到了你可以识别的内容,你就可以完成任务。
这些是我们可以积分的所有函数吗?
不,还有其他的。(你可以通过写出看起来很可怕的函数并对其进行微分来生成任意复杂的函数,你会发现将结果积分很容易。)
每个被积函数由标准函数组成,在积分时不会出现奇点,可以以任何所需的精度进行数值积分。上述方法相对于数值积分的优势在于,你可以在这里保持参数不定,并且必须在进行简单的数值积分时指定它们。
此外,还有一大类特殊函数,它们的性质已经被广泛研究,并且大量的积分可以用它们来表示。
在这个现代化的时代,培养识别哪些被积函数看起来对你来说是可积的艺术是一个好主意。如果你要积分的函数对你来说看起来不熟悉,请尝试使用其中一个数学程序。
19.5 分部积分
第二个有用的工具是乘积法则的反向版本。正如我们经常提到的,乘积法则告诉我们

这意味着如果我们寻求 h(x) 的一个反导数,并且我们可以将 h 写成 fg',那么我们可以将 fg' 写成 (fg)' - f 'g,并且 fg' 的一个反导数就是 (fg)' 的任意反导数与 f 'g 的一个之间的差值。
但是 (fg)' 的一个反导数由 fg 给出;所以我们可以在这里使用乘积法则将寻找 fg' 的反导数的问题简化为寻找 f 'g 的反导数,对于任何 f 和 g。
对于形式为 A(x)x 的乘积,如果你知道 A(x) 的一个反导数 B(x) 和 B(x) 的一个反导数 C(x),那么这个工具就是有用的。
我们可以在上述等式中将 f = x 和 g = B,然后写出 A(x)x = B'(x)x,通过这个过程是 (Bx)' - B,其中我们使用了恒等式 x' = 1。这具有 Bx - C 作为一个反导数,因此 Bx - C 因此是 Ax 的一个反导数。
这个过程称为分部积分。它对于找到指数和幂的乘积、三角函数和幂的乘积或对数和幂的乘积的反函数非常有用,等等。
例如,假设我们要对 x ln x dx 进行积分,也就是说,我们要求关于 x 的 x ln x 的反导数。
如果我们设 u = ln x 并且 dv = x dx,我们可以推导出  是 x 的一个可能的反函数。
是 x 的一个可能的反函数。
通过分部积分,我们得到 udv = (uv)' - vdu,积分后得到

练习:
尝试使用这种技巧对下面的被积函数关于 x 进行积分:
19.1. x⁴(ln x)
19.2. x sin x
19.3. x exp x
19.4. (sin x) exp x (提示:分部积分两次并解出得到的方程。)
19.5. x (sin x) exp x
19.6 关于参数的微分
还有另一种工具,有时可以用来计算反函数,当满足某些收敛条件时有效。
假设我们知道 g(x, y) 的反函数,其中 g 是参数 y 的某个可微函数,同时也是 x 的一个函数。然后我们可以推导出  的反函数是 g 的反函数关于 y 的导数。
的反函数是 g 的反函数关于 y 的导数。
例如,我们知道  的一个原函数是
的一个原函数是
在这里你也可以对 y 进行更高阶的导数。这使得你可以通过对  关于 y 求 k 次导数,然后设置 y = a 来推导出形如 x^k e^(ax) 的反函数的公式。
关于 y 求 k 次导数,然后设置 y = a 来推导出形如 x^k e^(ax) 的反函数的公式。
当适用时,这种方法将反函数的查找转换为适当的求导。然而,几乎你用这种方法推导出的一切都可以通过分部积分得到。
19.7 部分分解
我们知道如何对形如  的函数进行反函数,其中 a 和 b 可以是任意值。这将使我们能够找到有理函数 的反函数,如果我们能将它化简为这种形式的项的和以及可能的多项式。
的函数进行反函数,其中 a 和 b 可以是任意值。这将使我们能够找到有理函数 的反函数,如果我们能将它化简为这种形式的项的和以及可能的多项式。
如果 p(x) 的次数高于 q(x),我们可以通过类似长除法的过程提取一个商多项式 s(x),称为合成除法。
然后我们可能会剩下一个余项多项式 r(x)。我们知道如何对 s(x) 进行反函数,因此对于 的反函数化简为对  进行反函数,其中分子的次数低于分母的次数。
进行反函数,其中分子的次数低于分母的次数。
现在假设我们可以将 q 因式分解成像 (x-a) 或 (x-b)³ 或 ((x-d)²+ c²)^m 这样的因子。
令人惊讶的事实是,表达式 可以分解为每个都具有形式  或
或  的项,其中 a、d 和 c 为某些整数值的 b,每个都可以进行反求导。
的项,其中 a、d 和 c 为某些整数值的 b,每个都可以进行反求导。
这里是一个分解它的过程。
假设分母 q 可以分解为(x-b)^kt(x),使得 t(b)不为 0。
假设我们找到了关于 x = b 的 的泰勒级数展开的前 k 项
的泰勒级数展开的前 k 项

那么在涉及(x-b)的负幂的中,给出如下:
如果 k = 1,则只有一个项,
对于 k = 2,我们有  ,其中 A 与之前一样,而 B 为
,其中 A 与之前一样,而 B 为  ,依此类推。
,依此类推。
对于二次因子也有类似的规则。
以这种方式分解分母 q 的过程称为"部分分式法"。
我们再次回顾各种方法,详见第 27.1 节,并提供一些练习积分,详见第 27.3 节。对于重复我们深感抱歉。
第二十章:曲线下的面积及其许多推广
引言
由正函数 f 定义的曲线与 x 轴之间的面积在两个特定的 y 值之间被称为 f 在这些值之间的定积分。从矩形的面积是其边长的乘积这一事实开始,我们可以给出一般曲线下面积的形式定义。所使用的方法是广义的,可以定义多种不描述面积的积分。这些包括在复平面上的路径上的积分,在任意欧几里德空间中的路径上的积分,在平面上的区域上的积分,在三维空间中的曲面上的积分以及在体积上的积分。
主题
20.1 面积和符号
20.2 精确定义和黎曼和
20.3 总是可积函数
20.4 不可积函数
20.5 特殊黎曼和
20.6 在复平面上的曲线积分
20.7 欧几里德空间中的曲线积分
20.8 面积积分
20.9 曲面积分
20.10 体积积分
20.1 面积和符号
假设我们有一个非负函数 f 关于变量 x,在某个包含区间[a, b]的定义域内,其中 a < b。
如果 f 足够良好,在线段 x = a,x = b,y = 0 和曲线 y = f(x)之间存在一个明确定义的面积。
那个面积被称为 f dx 在 x = a 和 x = b 之间的定积分(当然,只针对那些有意义的函数)。
它通常写为

如果 c 位于 a 和 b 之间,显然有

为了使这个方程对任意 c 成立,当 b 小于 a 时,我们要求上面的符号代表所指示面积的负值。
在函数 f 有时为负的地方,我们定义定积分和相同的符号来表示自变量 x 和 y = f(x)之间的面积,其中 f 为正数减去当 f 为负数时两者之间的面积(当 a 小于 b 时)。
要使这个定义具有数学意义,我们必须给出一个计算面积的过程,至少在理论上,并且给出我们可以和不能定义的函数 f 的一些指示。
这里 f 被称为被积函数,并且它被积分为"ds"。
我们定义面积的方法基于我们知道矩形的面积是什么,即它是其边长的乘积。如果函数 f(x)是一个常数 c,那么所讨论的面积将是一个矩形,面积将是 c(b - a)。
这就是我们为常数函数定义面积所需的全部。
我们的任务是将这个定义推广到不是常数的函数上。
20.2 精确定义和黎曼和
标准方法通过想象我们将区间[a, b]分成许多小带来处理更一般的函数类,并估计每个带的面积为其宽度与带内 x 的某个 f(x)值的乘积。
那么面积将会像带的面积之和那样。 如果我们让最大带长趋向于零,我们可以希望找到带面积的结果和逼近真实面积。
标准做法是让第 i 条带从 x[i-1]开始,到 x[i]结束;该带的面积估计为(x[i]-x[i-1])f(x'[i]),其中 x'[i]在带内的任意位置。
黎曼和是刚才指出的形式的和:它是带宽乘以带内 f(x)值的和。 如果带的面积之和趋向于一个与每个带中使用的参数无关的常数,当最大带宽趋向于零时,该函数被称为黎曼可积的。
上述使用的符号可以从这个方法理解;我们正在对带的面积求和,对于大小为 dx 的 x 周围的一个非常小的区间,其被估计为f(x)dx,并将这个求和应用于所有这样的带。
20.3 总是可积函数
有两种情况我们知道 f 将在区间a和b上是黎曼可积的。
如果 f 在包括有限端点的区间内处处连续,则 f 将是可积的。
如果一个函数在 x 处连续,那么在 x 附近足够接近的值将彼此足够接近,并且足够接近于其在 x 处的值。
在[a, b]上 f 的连续性意味着在任何带中估计的变化可以通过使带的宽度足够小来使之成为带宽的任意小倍数。
因此,通过要求最大带宽足够小,你可以使黎曼和的总可能变化量成为 b - a 的任意小倍数。
我们可以(并且很快将)证明有界的在有限区间上单调递增或单调递减的函数是可积的,即使它不连续。
我们可以定义函数的变差为其在增长区间内的增加总和,以及在减少区间内的减少总和。
我们将推断,一个在 a 和 b 之间具有有界(总)变差的函数将在该区间上是黎曼可积的。
20.4 不可积函数
有没有不是黎曼可积的函数?
是的,有,并且你必须小心假设一个函数是可积的而没有看它。
非可积函数的最简单示例是:在区间[0, b]中的 ;以及在包含 0 的任何区间中的
;以及在包含 0 的任何区间中的 。这些本质上是不可积的,因为它们的积分代表的面积是无限的。
。这些本质上是不可积的,因为它们的积分代表的面积是无限的。
还有其他一些情况,积分性质失败,因为被积函数变化太大。
这的一个极端例子是在任何有理数上为 1,在其他地方为 0 的函数。
因此,选择用于表示黎曼和中的单个切片的面积将取决于我们在该区间中选择评估被积函数的有理数 x 还是非有理数 x。
对于这个函数,无论间隔多么小,你可以得到一个黎曼和为 0 或 b - a。
在这种情况下,可以使用更聪明的面积定义来定义它。(你可以争论,实质上,非有理点比有理点多得多,你可以忽略后者,积分将为 0。)
如果我们考虑在区间[-a, b]中由定义的曲线下的面积,其中 a 和 b 为正数,该区域在 0 和 b 之间有无限正部分,在-a 和 0 之间有无限负部分。可以定义这里的面积,使得这些部分相互抵消,并且可以给出净面积的含义。(如果去掉任何小的 d 间隔[-d, d],剩下的面积是有限的,并且可以计算。然后可以将这个面积的极限值作为 d 趋于 0。结果称为积分的主部分,可以这样定义,对于像这样的函数,其无限面积可能有相反的符号,并且可以互相抵消。)
20.5 特殊黎曼和
从现在开始,为了方便起见,我们将考虑所有条带宽度相同的黎曼和,d。
具有固定宽度的一般黎曼和则由 d 乘以每个条带中选择的 f 值的总和组成。
我们定义以下四个特别感兴趣的选择。
如果我们总是在每个条带中评估 f 的最左边的参数,则称总和的值为L(d)。
如果我们总是在每个条带中评估 f 的最右边的参数,则称总和的值为R(d)。
如果我们在每个条带中评估 f 的最大值的参数,则称总和为M(d)。
如果我们在每个条带中评估 f 的最小值的参数,则称总和为m(d)。
我们可以得出以下观察。我们假设 f 是有界的,使得 m(d)和 M(d)都是有限的。那么一个条带的最右边参数是下一个条带的最左边参数。
因此,L(d)和 R(d)之间的唯一区别在于 R(d)从最后一个条带中得到了 d * f(b)的贡献,而 L(d)缺少,而 L(d)得到了 R(d)缺少的 d * f(a)的贡献。
条带端点之间的论证在左侧对 L 间隔有贡献,而在右侧对 R 间隔有相同的贡献。
因此我们有
R(d) = L(d) + (f(b) - f(a) * d
这意味着当 d 趋近于 0 时,R(d)和 L(d)会合并在一起。
其次,M(d)大于或等于真实面积,并且大于或等于通过细分宽度为 d 的条带获得的任何其他黎曼和。同样,m(d)小于或等于真实面积,或者小于或等于通过细分获得的任何其他黎曼和。
最后,请注意,如果 f 在 a 和 b 之间是递增的,则 M(d) = R(d)且 m(d) = L(d),这意味着真实面积和通过细分获得的任何黎曼和都被夹在 d 趋于 0 时逐渐接近的边界之间。
这意味着通过细分获得的所有黎曼和都必须趋近于相同的值,并且函数 f 是可积的。
如果 f 在 a 和 b 之间不是递增的,但我们可以将该区间分解为在每个部分内 f 是递增或递减的部分,并且 f 在 a 和 b 之间具有有界的总变差,则 f 将通过将结果分别应用于所有部分,并将得到的边界相加而被积。
在接下来的小程序中,您可以输入任何标准函数和限制,然后查看用左手规则和右手规则计算不同切片数的面积。
练习:
20.1 计算 函数在区间-1 到 2 中的积分。如果您将此值加到该函数在此区间上的左手规则积分结果中(从下面的小程序中获取),您将得到什么?尝试不同的 d 值。
函数在区间-1 到 2 中的积分。如果您将此值加到该函数在此区间上的左手规则积分结果中(从下面的小程序中获取),您将得到什么?尝试不同的 d 值。
20.2 使用电子表格计算此被积函数的左手规则和右手规则,对于 d = .01 和 d = .02 和 d = .005。
20.6 在复平面中积分曲线
到目前为止考虑的定积分代表 xy 平面上的面积。然而,我们将其定义为通过将 x 区间划分为小的子区间(例如宽度为 d),并将每个子区间的面积的估计值的总和,即 f(x')d,取积分。
现在假设 C 是复平面中的一条曲线,让 f 是变量 z 的函数,其中 z = x + iy。我们可以通过将曲线分成小段,并对所有段求和 f(z')(z[i] - z[i - 1]),其中 z'是第 i 个间隔的点,其端点为 z[i]和 z[i - 1],来定义对该曲线的积分 f(z)。
这个沿着曲线的积分将不再代表面积,因为 f 和 z 之间的差异都不再是实数。但是我们可以将复数相乘,因此这个定义是完全合理的。
这样的实体在复平面中被称为轮廓积分。虽然这个积分不再具有面积的解释,但它仍然具有这样的特性,即如果路径 C 是有限的,函数 f 在其上是有界的且连续的,那么它是良好定义的。我们将其表示如下

这种类型的积分是非常有价值的数学工具,我们很快就会看到。
不要被在复平面中积分和处理具有复值的函数的奇异性所吓倒。几乎你能够说的关于普通积分的一切都适用于这些积分。
练习:
20.3 将函数 sin z 沿虚轴积分,从 0 到 i,利用你对正弦函数积分的了解。
20.4 在电子表格上以数值方式做同样的事情,写成 ,其中 z = x + iy,x = 0(因此 z = iy),y 从 0 到 1。
,其中 z = x + iy,x = 0(因此 z = iy),y 从 0 到 1。
20.7 在欧几里得空间中的曲线积分
我们将把将曲线分成小片段并将每个片段的端点之间的差乘以某个函数进行求和的思想扩展到任何欧几里德空间中的曲线 C 上的积分。
如果 f 是一个标量场,也就是说,一个定义在我们空间中的点的函数,我们可以对路径上的分割点 求和,再次r'是第 i 个子间隔中的点。这可以定义,但这里r的差异将是一个向量,并且总和将是一个向量场。
求和,再次r'是第 i 个子间隔中的点。这可以定义,但这里r的差异将是一个向量,并且总和将是一个向量场。
当我们在这里用一个向量场w(r)代替 f 时,得到的概念要更有用,并且对曲线 C 上由端点 定义的间隔求和。结果就是一个数字而不是一个向量。
定义的间隔求和。结果就是一个数字而不是一个向量。
它的定义方式与确定积分中的面积完全相同。它的标准表示法是

有两个重要的例子,其中这种积分发生。
首先,假设我们沿着 C 积分一个单位切向量 dl。
dl。
对于足够小的间隔,这个单位切向量基本上将是一个指向 的单位向量。结果就是对曲线 C 上
的单位向量。结果就是对曲线 C 上 的积分。由于这只是对曲线的每个子间隔的长度|dl|进行求和,其在整个曲线上的总和将是 C 的长度。
的积分。由于这只是对曲线的每个子间隔的长度|dl|进行求和,其在整个曲线上的总和将是 C 的长度。
曲线 C 的长度因此由给出

其中 T 是曲线方向的单位向量。
其次,在物理学中,力 F 在沿路径 C 推动物体时所做的功由形式的积分给出

正如我们已经注意到的,我们通过将曲线分割成越来越小的片段,计算每个片段内指定的点积,并在各个片段上求和来定义这样的积分。
到目前为止,我们已经概括了面积的概念或者说我们对它的方法,以定义复平面或欧几里得空间中路径上的积分。
相同的想法可以应用于二维区域的积分,三维空间中的表面,三维空间中的体积,或者高维度中的任何东西。
在每种情况下,您都可以将您感兴趣的区域分解为直径趋于零的片段,并在这些片段上对积分因子乘以片段大小的度量进行求和。
在三维空间中对表面进行积分时,必须考虑到表面像曲线一样具有方向,因此我们必须相应地进行定义,就像我们刚刚对曲线所做的那样。
您可以在此处输入任何标准向量场和任何参数化曲线,并查看下面的 applet 中展开的积分结果。
练习 20.5 使用 applet 在默认螺旋路径上积分向量场 xi + yj+ 2zk,并且沿着直线积分,两者都是从 z = 0 到 z = 4 其他变量端点为 0。结果如何比较?
其他变量端点为 0。结果如何比较?
20.8 面积积分
我们对面积的最初概念是通过对线的积分来定义的。我们将线段分成小间隔,并用它们来将由 f 定义的曲线下的面积分成条带。
然而,没有任何阻止我们将整个区域分成小片段并将它们相加。
因此,如果我们有一个区域 A,我们可以在上面放置一系列微小的正方形,并计算有多少个正方形在它内部,以及有多少个在它的边界上,并从这些数字(以及正方形的大小)估算其面积。
我们可以类似地估计由f(x, y)定义的表面下的体积,方法是将每个正方形的面积乘以其中一点的 f 的值;同样,我们可以定义黎曼和,并考虑当每个片段的最大面积趋近于零时,所有黎曼和都趋近于一个特定值时,积分被定义。
这种类型的积分称为面积积分,我们可以表示为

如果 f 在有界闭区域上连续,那么这样的积分将始终是明确定义的。
20.9 表面积分
在三维空间中,我们可以对足够好的表面进行积分,方法是将其分成小片段,并且与在平面上的区域完全相同。
飞机毕竟只是三维空间中表面的一个特别简单和直接的例子。
我们考虑的表面在小距离上看起来大部分像平面,因此每个微小表面元素都将具有本质上是平面的小片面积 dS。
然而,每个小表面元素 dS 都有一个法线方向n,再次考虑向量 dS,即其面积 dS 乘以(外部)法线向量 n是合适的。
您可以将所有这些乘以被积函数的小向量相加,并为这些定义黎曼和以获得表面积分。
上面最后一句指的是将向量 dS(记住 dS是|dS|乘以表面外法线n)与被积函数相乘;有三种明显的方法可以做到这一点。
如果被积函数是一个函数 f(x, y, z),我们可以相乘,和将会是一个向量。这是可以的,但这是最不常见的做法。
标准做法是有一个被积向量 v(x, y),并将其与 dS进行点乘,并对这些片段的点乘求和。这是最常见的表面积分形式。
我们用以下符号表示这样的积分

这种积分在物理应用中特别有用。
特别是当向量v是电流密度时,v****n被定义为流经法线为 n、表面积为 dS 的表面的 v 电流密度的数量,每单位时间。
上面的积分告诉我们单位时间内有多少东西流经表面 S。
电流密度被定义为质量和电荷,但这种表面积分在讨论电场和磁场时也很重要。
高斯定律,例如在静电学中规定,区域 R 内的总电荷是电场垂直于表面的分量在该区域表面 R 上的积分的常数倍
R 上的积分的常数倍

(引力场和区域内质量量之间存在类似关系;对于磁场,磁荷(单极子)的明显缺失意味着可比方程的右侧对于磁场为 0。)
这种积分通常被称为通量积分。
20.10 体积积分
将路径、线、区域或表面分割成小片的想法同样适用于体积。
因此,我们通过相同的方法定义体积积分,希望这次不需要重复了。(这里还是:将体积分割成更小的片段,比如立方体,并让片段的直径趋于零,对每个片段的贡献求和。)
体积在三维中是数字而不是向量,因此定义非常直接。
当被积函数为 1 时,积分变为体积本身。
对具有任意作为被积函数的密度进行的体积积分是 V 中的总量任意。这样的积分经常遇到。
特别地,电荷或质量密度的体积积分给出了该体积内的电荷或质量。
你也会遇到矩。对体积 V 内材料关于 z 轴的质量密度乘以 r²(其中 r 表示到 z 轴的距离)的积分给出了 V 内材料关于 z 轴的惯性矩。
更一般地说,矩是与轴或点的距离的幂乘以适当的密度的积分。惯性矩是关于一个轴的“矩”。
体积积分通常表示为

在定义了所有这些实体之后,我们现在转向问题:我们如何评估它们?
基本答案是:我们使用微积分基本定理,我们现在将描述,要么直接给出一个答案,要么将问题的积分减少到我们执行一个或一系列反导数的情况。
显然,这里的定义可以扩展到三维以外的维度。
在每种情况下,我们都可以通过相同的论证证明连续函数在有界闭区域上的积分始终存在。
第二十一章:一维微积分的基本定理
介绍
对函数进行积分和对其进行微分是逆运算;因此曲线下的面积是其作为上端点的积分的反导数。我们探讨了此主张的证明及其对一维积分的影响。
话题
21.1 普通积分的基本定理
21.2 在复平面上的路径积分的基本定理
21.3 欧几里得空间中路径积分的基本定理
21.1 普通积分的基本定理
对于实函数在实线段上的普通积分,微积分基本定理是明确积分是反导数的陈述。这意味着微分消除了积分,反之亦然,尽其所能。
这有两种表现形式:如果对函数 f 进行微分,然后进行积分,您将获得积分区间端点之间的函数差

此公式意味着我们可以使用在求定积分中找到反导数的所有方法。
第二个应用较少但仍有用:如果您对函数 f 进行积分,然后对其上端点(如上所示的 y)进行微分,则会再次获得 f

这些性质对于我们在上一章中介绍的另外两种一维积分基本上以相同的方式成立。
这些陈述的类似物对于定义的每一种积分都成立。我们将依次讨论这些。
我们首先证明了这些陈述在普通积分的情况下的情况。
为了证明上述第一个主张,我们观察到如果我们将从 a 到 y 的区间分成微小子区间,则如果在每个子区间中它是真的,则所得结果成立。
在任何区间内,中值定理告诉我们,其端点之间的 f 的差异是它们之间的分离乘以 f 在某个中间点的导数。
因此,从 x 到 x + d 的区间上的实际差异,f(x + d) - f(x)可以被认为是某个黎曼和的来自该子区间的贡献, 对于区间内的某个点 x'。
对于区间内的某个点 x'。
由于积分的存在意味着所有黎曼和都收敛于它,通过在每个子区间上应用中值定理获得的特定子集在最大 ds 趋于零时也必须如此,我们发现导数的积分是每个无穷小子区间端点之间 f 的变化。
这些变化的总和是整个区间 f 的变化,这是我们的积分。
第二个主张可以重写为如下声明

当 dy 趋于零时。
由于积分代表了矩形的面积,其中的边界为 dy 和 f(y),当 dy 趋于零时,这个结果在 f 在参数 y 处连续时成立。
在这种情况下,对于足够接近 y 的参数的值 f 是任意接近 f(y) 的,并且足够窄的矩形的面积将任意接近于 f(y)dy。
重申一遍,这些陈述的含义是 我们找到的所有反导数方法都可以应用于确定曲线下的面积,更一般地,用于计算定积分。
21.2 复平面中路径积分的基本定理
用于定义复平面中路径上积分的面积的泛化遵守了与普通实积分相同的基本定理。
我们可以将路径分解成小的片段,每个片段上的积分值将对于足够小的 dz 和 f 在 z 处连续的 f(z + dz) - f(z) 进行近似。我们不会重复上述给出的论点,但注意其结果

再次强调,这意味着 第十九章 中讨论的所有方法在复平面中的运作方式完全相同。
特别感兴趣的是 当 b = a 时路径闭合的情况;
我们期望积分为 0。这在 f 是一个明确定义的函数时是成立的。
当 f 具有对数因子时,情况并非总是如此,因为这些不是真正的函数,可以在同一点上取不同的值。
一般来说,在一个闭合路径上,如果 f 在路径内部没有奇点,那么 f 的积分将为 0,但如果路径内有奇点,则一般情况下不为 0,这些奇点会产生对数因子。
像多项式、exp(x)、正弦和余弦的多项式指数和多项式等函数都是始终定义良好的,并且它们的积分总是明确地遵循上述方程。具有对数因子的函数在某种意义上遵循它,但其中的 f(b) 和 f(a) 的值可能取决于路径。
关于对数的与此相关的奇异性的最简单示例在于 被积函数 z^(-1).
假设我们在绕原点的半径为 r 的圆形路径上积分此函数。那么我们有 z = rexp(i ),因此在固定 r 时,我们有 dz = irexp(i)d。因此
),因此在固定 r 时,我们有 dz = irexp(i)d。因此  变成了 id。而它在围绕半径为 r 的圆上的积分是 2
变成了 id。而它在围绕半径为 r 的圆上的积分是 2 i。
i。
这相当于说,用这个被积函数从 a 积到 b,我们得到一个实部加上 2 i 的任何整数倍,这取决于路径 P 绕原点旋转的次数。
i 的任何整数倍,这取决于路径 P 绕原点旋转的次数。
如果函数 f 在路径 P 所围区域内不是奇异的,则沿 P 的 f 的积分将为 0。
如果 f 可以在某个参数 z[0]周围的幂级数中展开,其中包括正负项,则除了负一次幂之外的所有幂都是其他幂的导数,它们的积分是路径无关的。
负一次幂给出了如上所述的问题。在该点周围的幂级数展开中,负一次幂的系数称为函数在该点的残留。该函数在该点周围的积分是其残留的 2i 倍。
总而言之,在复合积分的情况下,基本微积分定理完全适用,但是某些函数的积分具有相同的端点但具有不同的值。
这是因为积分得到的实体实际上不是真正的函数,而是多值的。
一个有趣的问题是,可以从被积函数中检测到这种奇怪的现象吗?
答案是可以的;如果被积函数在两个路径之间是奇异的,则积分的值将不同,并且将由两个路径之间残留的和的 2i 倍差异。
这个事实给了你一个宝贵的工具,用于评估超越所有可用反微分的积分。
第二种形式的基本定理,即对于其上限端点的复积分的导数与普通实积分完全相同。在我看来,在这种情况下很少使用。
练习:
21.1 在复平面上评估 z ^(-1) dz 的积分,围绕原点进行圆形路径。
21.2 对其进行积分,该路径在逆时针方向绕原点旋转两次。
21.3 对其进行积分,该路径形成围绕点 z = 2 的半径为 1 的圆。
21.4 在半径为 1 的圆上围绕原点进行积分。在以 z = 1.5 为中心的半径为 2 的圆上进行积分。
21.3 欧几里得空间路径上的积分的基本定理
我们在 P 中取一条路径,它可以被分成许多小段,每一段在小距离上都类似于一条直线,并选择在其上下文可微的标量场 f。
我们通过与先前情况相同的方法来证明这种情况下的基本定理。我们首先考虑被积路径的一个非常小的部分,对于可微曲线来说,它看起来像一条直线。
线段端点之间的 f 的变化构成了构成 C 的微小部分的方向导数,该方向导数乘以线段的长度 ds。
如果该线段具有单位切向量 T,则此变化由(Tf)ds 给出,并且我们有
f(r + Tds) - f(r) = ds(Tf).
如果我们将此语句总结到整个路径 P 上,我们得到

这意味着沿路径的梯度分量的积分将给出 f 的变化或 P 前后端点处的值之间的差异。
这是多维线或路径积分的基本定理的形式。
在第二十三章中,我们将展示如何将路径积分转换为普通积分,可以对其应用寻找反导数的工具。
此处的基本定理给出了在被积函数乘以 ds 的形式为(Tf)ds 时,评估定积分的更简单方法,这也可以写作(dsf)T。
注意,这意味着这样的积分不依赖于你使用的路径,而仅依赖于端点。
要有效地使用此结果,您必须了解什么样的矢量场可以识别为标量场的梯度。
这样做的一种方法是找到各种标量场的梯度,这样你将会熟悉它们。
在下一章中,我们将找到一个测试,您可以使用该测试确定您的积分是否具有适合使用此定理的形式。
不仅如此,我们还将找到一种公式,用于将沿一条路径的积分与沿另一条路径的积分相关联,当被积函数的形式不是梯度与 ds 点乘的形式时。
记住,您可能能够将您的积分的一部分识别为梯度,从而留下一个相对容易需要简化为普通积分的部分。
练习:
21.5  查找从(0, 0, 0)到(1, 2, 3)的路径上的积分,该路径从原点沿 x 轴上升到 x = 1,然后平行于 y 轴到 y =2,然后沿 z 轴平行到 z = 3。
查找从(0, 0, 0)到(1, 2, 3)的路径上的积分,该路径从原点沿 x 轴上升到 x = 1,然后平行于 y 轴到 y =2,然后沿 z 轴平行到 z = 3。
(提示:忽略路径,使用基本定理。)
21.6 评估以下场的梯度:
第二十二章:高维空间中的基本定理;可加度量,斯托克斯定理和散度定理
介绍
我们寻找(并找到了)与表面和体积积分的基本定理类似的模拟物。为此,我们检查具有与我们的积分相同可加性属性的构造,因为任何将积分与其他事物相关联的定理必须将其与具有相同可加性属性的其他事物相关联。凭借这一事实的线索,我们找到了我们所寻找的结果,即斯托克斯定理和散度定理,这是这个学科中最强大的工具。
主题
22.1 一般评论
22.2 表面上的度量和斯托克斯定理
22.3 体积上的度量和散度定理
22.1 一般评论
二维和三维中的基本定理是所有领域中最重要和最有影响力的结果之一。它们提供了一些关键,允许将控制电磁现象的定律表示为微分方程,这是我们理解物理结构的来源,也是无线电及其后续发展的基础。
代替简单地陈述这些基本定理,我们首先探讨一个问题:它们可以采用什么自然形式?
我们所定义的积分:在实数线上,在复平面上,在几维空间的路径上,或在曲面或体积上都具有重要的性质,即它们是有限可加的。这意味着,如果你在两个不重叠的片上定义任何一个积分,它们的值就是在任一片上的值的总和。
显然,区间内的曲线下的面积遵循这个属性;实际上,这是我们定义的这个概念的所有泛化的基础。
在每个泛化中都要记住,我们采用了一个合适的“片”的定义:(依次是在复平面中的曲线上的区间,或在多个维度中的路径上,或在平面上的小区域上或在三维空间中的曲面上或在体积的要素上。)
然后将其大小的适当“度量”乘以定义在其上的一些函数 f;并定义这个产品在一个大片上的值为其在该片的分割(“黎曼和”)上的值的总和,其值是在更小的片上的。
然后我们将片段的最大直径逼近零的极限。在每种情况下,我们都可以声明对于连续函数 f,得到的和收敛到一个我们称为积分的极限值。
现在我们提出一个问题,是否存在其他自然实体,像这些一样具有相同的“可加性”属性,即在几个部分的“总和”上的值等于其在每个部分上的值的总和。
我们这样做是因为我们想要将适当的积分与其他事物联系起来,而任何可能与某种积分相等的其他事物一般来说,至少必须具有这个属性。
这个问题的最简单答案决定了每个上下文中基本定理的结构。
首先,我们解决了这个问题的一个维度积分,在那里我们已经看到了答案。
我们问,除了由函数 f 定义的曲线下的面积之外,还有哪种构造在实线段的区间上定义时具有这种可加性质?
有一个简单而自然的答案:如果我们在实线段上划分一个区间 [a, b],一个自然的可加实体是 F(b) - F(a),即区间端点处函数 F 的差,或者等价地,a 和 b 之间 F 的变化是可加的。
显然,两个完全不相交区间上 F 的变化之和是两者之和;更有趣的是,两个相邻区间上 F 的变化是每个变化的总和。我们有
(F(b) - F(c))+(F(c) - F(a))= F(b) - F(a)
这句话的意思是来自中间点 c 的贡献,它是一个区间的前端和另一个区间的后端,互相抵消了,我们只有来自结果大区间两端的贡献。
这个答案并不令人兴奋,其一维泛化到复平面中的路径或欧几里得空间中的路径同样直截了当。
在复平面上的路径 C 上,F(此时 F 是一个实值或复值函数)在 C 的端点处的差是有限可加的。
如果我们将一条路径分成两个子路径,或者将一条路径连接到另一条路径的末端,那么结果子路径的末端值之差总和等于整个路径上的差异,而不需要任何修改。
再次,假设给定一个在多维空间中定义的标量场 F,并给定其中的一个路径 C,则对于 C 上的 F 的变化,相同的可加性质成立。
实际上,在这些上下文中,在 第二十一章 中我们在发展微积分基本定理时使用了这种可加性。
那么,唯一有趣的问题就是,当我们考虑平面上的一个区域,或者一个表面上的区域,或者一个体积上的区域时,与路径上的差异类似的东西可以找到什么呢?我们特别关注的是涉及到给定区域的边界的实体,这就是对于路径上的区间来说 F(b) - F(a) 代表的东西。
22.2 表面上的测度和斯托克斯定理
现在假设我们在平面上有两个相邻但不重叠的区域,比如矩形。我们问:我们能在每个矩形的边界上定义什么实体,使其像曲线上的 F 的差异那样具有可加性?
我们需要的是来自两个矩形的公共边界的贡献互相抵消。
有一种简单的方法可以实现这一点:我们可以沿着矩形的外部边界周围,按照某个标准方向积分。
我们总是选择逆时针方向作为正方向。
如果我们这样做我们将在一个相邻矩形之间的内部边界上进行积分,并在另一个矩形上向下进行积分,这将不会有任何贡献,我们将得到可加性。
要考虑的下一个问题是,我们应该在矩形的边界上积分什么类型的实体(或其他区域)?
我们原则上可以以这种方式积分标量或矢量场;我们在上一章中看到,矢量场的线积分是普通积分到路径积分的最自然推广
一个区域的自然可加性边界定义实体是围绕其边界的路径切线向量与某个向量 v 的点积的线积分

这个实体将在任何定义了它的向量 v 上是可加的,在平面上,或者说在任何局部平面的表面上,甚至在由局部平面组成的任何表面上。
我们用一个带有圆圈的积分符号表示这种类型的积分,意味着我们正在沿着分段局部平面区域 A 的边界进行积分。
现在我们要问当 A 是具有轴平行边的矩形时,这个积分是什么?(顺便说一句,我们总是可以旋转我们的坐标,使得任何矩形在旋转后边将是轴平行的。)
我们假设我们在三维空间中工作。
然后我们的积分由围绕 A 的垂直和水平段组成,如此处所示。
我们选择我们的矩形的角落为 (x, y) 和 (x + dx, y + dy) 对于微小的 dx 和 dy。
然后沿着右侧向上和左侧向下的积分v dl 将会有贡献
dl 将会有贡献
(vy - vy)dy
而从右到左沿其顶部和从左到右沿其底部的积分贡献
(vx - vx)dy
观察到对于微分,我们可以将 A(q + dq) - A(q) 重写为  在这里应用这个公式并将上述两个贡献相加,我们发现我们围绕无限小矩形的积分是
在这里应用这个公式并将上述两个贡献相加,我们发现我们围绕无限小矩形的积分是

在我们这里的坐标系中,z 方向是矩形平面的法线方向,您会观察到这里的内容是 v 的旋度分量与矩形的面积元素相乘

现在我们有了我们的基本定理。 对于平面上的面积积分,它被称为格林定理。 对于一般足够分段光滑的表面,它被称为斯托克斯定理

这个结果适用于表面上的任何可以被分解成小矩形的区域 A,通过等式两边的可加性。
实际上,您可以(我们忽略了一些)稍微费点劲推导出三角形以及矩形的相同无穷小结果。因此,这个结论也适用于任何可以合理分解成微小且不重叠的矩形和三角形的区域。
您会发现 v 的旋度在定理中自然地出现了。事实上,这个定理的性质是我们对旋度感兴趣的主要原因。
这个定理有一些直接的后果。
首先,如果 v 的旋度在一个表面上为 0,那么沿着它的线积分从一个点到另一个点将与路径无关,只要路径保持在表面内。
其次,如果您可以计算从一点到另一点沿着一个路径的线(或路径)积分,您可以通过在其边界为两条路径的任何表面上积分其旋度来推断其沿另一条路径的积分。
22.3 体积上的测度和散度定理
假设我们在三维中有一个体积 V,它具有分段局部平面边界。 (这意味着其边界可以被分解成在小距离处看起来平面的有限数量的部分。我们已经定义了一个函数 f 在其上的可加积分(并且可以对任意维度中的“超”体积上的函数执行相同操作)。)
我们能定义一个在边界上可加的体积积分吗?
答案是肯定的。
V 的表面在边界局部平面的任意点都可以用"外法线"方向来表征。如果我们在这个表面上对矢量v的外法线分量进行积分,并连接相邻的体积,那么一个的外法线将会另一个的内法线,它们相遇的地方的边界的贡献将会抵消。
这意味着连续矢量场 v 的外法线在边界上的积分,  V 的体积上将在体积上可加。 我们写成
V 的体积上将在体积上可加。 我们写成

并称之为通过 V 表面的外部"通量"。
现在我们可以讨论上一节中针对面积所考虑的相同问题:如果我们让 V 成为一个无穷小的轴平行矩形体积,边长为 dx、dy 和 dz,在(x, y, z)处有下角,那么这个积分是多少?
矩形体积 V 有六个外表面,它们构成了它的前面和后面,分别沿着三个轴方向。外法线在正面朝正方向,背面朝负方向。
正如在二维情况下一样,垂直于 x 方向的两个面的贡献成为了 v 在 x + dx 处与 x 处的差值,沿着这些面对 y 和 z 变量的积分。
这个贡献, 可以重写为
可以重写为 。
。
以完全相同的方式,沿着 y 和 z 方向法线的面的贡献可以分别写为 ,它们相加得到
,它们相加得到
我们发现,对于所示的小体积 V,我们有

同样地,对于倾斜的平行六面体区域或棱柱,我们可以获得相同的结果,并且我们可以使用可加性来推导出对于任何具有分段局部平坦边界和在其上定义的任何分段连续向量场的任何体积的相同结果。
这个结果再次极为重要。它被称为散度定理,也被称为高斯定理。
更或多少明显的是,通过合适的定义,任何更高维度中都有一个类似的定理。它再次代表了微积分基本定理的高维版本:右侧的散度导数可以被积分,产生积分的极限点处的差异,将右侧的三维积分转换为左侧 V 边界上的二维积分。
练习:
**22.1 考虑由 定义的向量场 E
定义的向量场 E
计算其通过以原点为中心、半径为 R 的球面的通量的积分。同时计算其散度。(我们之前已经做过这个题目了。)你能解释这个吗?**
22.2 在以点(0, 0, 2)为中心、半径为 1 的圆周围的 E 的通量积分是多少?
第二十三章:将线积分减少为普通积分及相关减少
介绍
尽管在路径 P 上进行线积分的最容易评估当被积函数可以表达为梯度并且积分变成 P 端点处函数值的差异时,但我们在这里考虑将线积分减少为普通积分的过程。我们还描述了如何将表面通量积分转换为平面区域上的二维积分。
主题
23.1 将线积分化为普通积分
23.2 例子
23.3 实用评论
23.4 多重积分和面积积分
23.1 将线积分化为普通积分
我们寻求沿路径 P 的点积w(x, y, z) dl的积分。
dl的积分。
要做到这一点,我们首先需要描述路径;(假设我们无法将w识别为梯度。)
一般来说,有三种定义路径的方式;最有利于计算积分的是参数表示形式。
或者路径可以定性地定义(例如:“它是以点(a, b, c)为中心的圆,半径为 d”),或者可以通过方程(二维情况)或两个方程(三维情况)定义。
当路径定性定义时,您必须自己提供参数表示形式。
通常我们将注意力集中在相对简单的路径上,这些路径由圆弧、直线或圆锥曲线(椭圆、抛物线或双曲线)的部分组成,并且有这些的标准参数表示形式。
当路径由两个方程定义时,您可以尝试将这些方程解为变量 x、y 和 z(或者可能是球坐标的变量等)中的两个,以第三个作为参数。这个任务的难度取决于方程的性质,我们不会在这里进一步讨论它。
我们在这里假设我们从一个参数表示形式开始。这意味着我们有一个参数 s(通常代表时间 t 或者可以经常选择为变量 x、y 或 z 之一)和公式,给出 x、y 和 z 作为 P 上 s 的函数。这可以写为  (s),或者为(x(s), y(s), z(s)),如 x(s)i + y(s)j + z(s)k,或者我们可以给出这三个分量的表达式。
(s),或者为(x(s), y(s), z(s)),如 x(s)i + y(s)j + z(s)k,或者我们可以给出这三个分量的表达式。
一个例子是螺旋线
x (s) = cos s, y(s) = sin s, z(s) = s
在当前符号中,s 是一个任意参数,不是路径上的弧长。
曲线 P 也将有一个开始参数值 s[0]和一个结束参数值 s[1]。
矢量w可以假定为关于 x、y 和 z 的函数,我们可以通过使用 x、y 和 z 的定义作为它的函数来将其转换为关于 s 的函数。
我们的计划是将w(x, y, z)dl简化为从 s[0]到 s[1]的某个 ds 的积分,我们这样做如下

现在w(x, y, z)dl可以写成 ,我们可以用类似的替换来替换 dx 为
,我们可以用类似的替换来替换 dx 为 ,y 和 z 也做类似的替换。这里的中间表达式是一个普通的积分,也是这里所寻求的简化。
,y 和 z 也做类似的替换。这里的中间表达式是一个普通的积分,也是这里所寻求的简化。
那么我们如何构建它呢?
我们执行以下过程:
步骤 1:用 s 的形式表示 x,y 和 z。也就是说,写出 P 的参数表示。
步骤 2:分别对 x,y 和 z 关于参数 s 进行微分。
步骤 3:将得到的向量与 w(x(s), y(x), z(s))的点积。
步骤 4:对 s 从 s[0]积分到 s[1]得到的函数进行积分。
23.2 例子
例子 1
我们首先计算我们的螺旋线的弧长从 开始
开始
P 的参数方程为 x = cos s,y = sin s,z = s。因此我们得到

要计算弧长,我们想要对 P 的每个无穷小部分的长度 dl 求和。
由于我们正在积分 dl,其中T是指向 P 的切线方向的单位向量,即 的方向,我们可以通过将其与单位向量T的点积来找到 dl,该单位向量遵循
的方向,我们可以通过将其与单位向量T的点积来找到 dl,该单位向量遵循 。
。
我们发现 P 上的弧长由以下给出

这里的被积函数是 的绝对值
的绝对值
这里是
这个螺旋线的积分值和弧长因此为 。
。
例子 2
计算淘气孩子将一块质量为 M 的石头从窗户扔出并落在窗户下方 30 英尺处时重力所做的功。这里的功由石头的路径上的线积分Fdl给出。由于F = -Mgk,最终普通积分 ds 中的被积函数变为 ,重力所做的功为
,重力所做的功为

无论路径如何,这里的积分值都是适当单位下的,因为力是梯度,积分因此是路径无关的。
23.3 实用评论
虽然这里的简化过程很直接,但有许多细节需要处理,很容易走错。
标准错误通常是粗心大意的错误:在步骤之间丢失一个因子,以及在对w进行点积之前未区分的参数表达式,以及错误地阅读或解释问题,切换加法和乘法等。
当您的路径 P 以两个方程的解或定性描述的方式呈现给您时会发生什么?
为了将路径积分化为关于一个变量的单一积分,您几乎总是必须能够将路径上的位置(路径上的 x,y 和 z 的值或路径上某些其他坐标集)表示为该变量的函数。这通常要求您能够根据给定的信息使用您的变量作为参数产生路径的参数表示。
当路径由直线段或圆弧组成时,您应该准备好根据直线段的起点和终点以及圆弧的中心半径和终点角度来参数化表示它们。
从(a,b)到(c,d)的直线段可以表示为
x = a + s(c - a)
y = b + s(d - b)
对于 0 < s < 1。
练习:23.1 在三维中陈述类似的结果。
半径为 u,以(b,c)为中心的圆可以用参数表示为
x = b + u cos s
y = c + u sin s
练习 23.2 这里 s 的适当限制是什么?
当路径由方程定义,并且您能够解出它们以找到所有变量,以某一个变量或某些其他参数为单位,您可以处理该问题,就好像从一开始信息就以参数形式给出一样。
否则,您始终可以通过数字方式找到曲线上的许多点,并使用我们即将描述的方法对产生的积分进行数值近似。
当然,执行这种积分的最简单方法是观察到向量w或其显著部分是标量函数的梯度。然后,积分简化为在端点处的评估,我们根本不必担心路径。
练习:
23.3 在给定的 w = (x,y²,z³)下,计算沿上面的螺旋路径的 w 与 dl 的点积。
23.4 在从(1,0,0)到 的直线路径上计算相同的积分。
的直线路径上计算相同的积分。
23.5 计算围绕以点(5,0,0)为中心的 xy 平面上的单位圆的线积分 。(提示:使用斯托克斯定理。)
。(提示:使用斯托克斯定理。)
23.6 您想要找到由 ax² + by² = c 定义的椭圆的弧长。将其边界用参数形式表示,设置积分并执行它。
23.4 多重积分和面积积分
当给定定义在区域上的积分时,将其化为多重积分的标准程序是将其转化为多重积分。
多重积分是涉及两个或更多个普通积分的表达式,其中一个的积分限制可能取决于下一个的积分变量的值,因此积分可能必须按特定顺序执行。
要将面积积分减少为一对多重积分,必须执行以下步骤:
1. 选择一组方便的变量。这可以包括矩形变量或极坐标或任何其他变量。您选择它们使得积分被积函数或将需要的积分限制(最好两者都)尽可能简单; 并选择您打算在这些变量中定义积分的顺序。当您没有线索时,您可以从明显的变量 x 和 y 开始。
2. 适当地表达积分的上下限,以便您要积分的区域由您的积分限制内的点表示。
3. 用您的变量 u 和 v 以及 du 和 dv表达面积元素dA。
4. 用您的变量表达被积函数。
5. 积分您生成的每个普通积分,必要时按适当顺序进行。
例子:我们希望在整个 xy 平面上对函数 exp(-r²)进行积分。
一种方法是用普通的 x、y 坐标。
然后在每个变量中,积分的限制都是从 到。
到。
(这是一个不恰当的积分,因为限制是无限的,而我们实际上只定义了有限区域上的积分。但是,这里的被积函数对于任何变量的大值都表现得非常好,因此我们可以忽略这一事实,并想象我们将积分截断到巨大的有限值。这不会显著改变答案。)
面积元素 dA 在矩形坐标中为 dxdy。
被积函数可以表达为 exp(-x²-y²)。
我们的任务是评估两个因子的乘积,每个因子都是对所有有限值的 exp(-x²)积分 dx。
答案是 的平方,其中积分限制为-R 和 R,R 非常大。
的平方,其中积分限制为-R 和 R,R 非常大。
我们也可以在极坐标中执行此积分。
这里 r 从 0 到无穷大, 从 0 到 2
从 0 到 2 。
。
面积元素是线元素 dr 和 rd 的乘积,因此我们有 dA = rdrd。
被积函数是
这里的积分是微不足道的,并且产生值 2-0 或仅为 2。
我们剩下的积分是从 0 到无穷大的  如果我们设
如果我们设  ,那么我们有 du = 2rdr,积分项 dr 变为
,那么我们有 du = 2rdr,积分项 dr 变为  并且在 u 上的积分限仍然是 0 和无穷大。因此,这个积分的值是
并且在 u 上的积分限仍然是 0 和无穷大。因此,这个积分的值是  ,而这里两个积分的乘积只是 。
,而这里两个积分的乘积只是 。
注意,我们刚刚证明了这种类型积分的积分是 
在评估这种类型积分所需的步骤中,第二步和第三步值得进一步讨论。
第三个是,在你的坐标系中表达面积元素,在下一章的 24.2 节 中将会讨论。
第二个是,在变量的正确限制条件上找到正确的积分区域,以匹配你想要积分的区域,在 31.5 节 中有详细讨论。
下面的小程序允许你选择限制条件,并查看平面上的结果区域。了解其感觉的一个好方法是首先设置限制条件,先对一个变量进行积分,然后再对另一个变量进行积分,然后尝试通过相反的顺序进行积分来匹配它。你甚至可以尝试通过指定极坐标变量或反之亦然来匹配在直角坐标系中给定的区域。一般来说,人们在第一次尝试时通常会搞砸,所以练习一下可能是值得的。
第二十四章:将曲面积分降维为多重积分和雅可比行列式
介绍
表面积分在表示重要物理概念方面具有重要意义,例如物质或电荷的流动,以及电场或磁场的通量。我们还希望能够计算它们,并在这里展示如何进行计算。
主题
24.1 概念讨论和主要结果
24.2 对平面上区域的积分的影响:雅可比
24.3 对更高维度的推广
24.4 体积和表面积分作为单个普通积分
24.1 概念讨论和主要结果
给定曲面 S 和向量场 w,我们已经定义了一个积分,通常称为通过 S 的 w 的通量。
我们通过将 S 划分为微小的局部平面片,并将每片的面积乘以与之垂直的 w 分量的积之和来定义它。
这正是在实数线段上定义的普通一维积分的精确类比,只是将该区间替换为我们的曲面 S。我们已将其表示为

那么这样一个积分的价值是多少呢?
当曲面被参数化定义时,我们可以直接回答这个问题。
假设我们的曲面由两个参数 s 和 t 定义,以便对于给定范围内的每对值 (s, t),我们有值 x(s, t),y(s, t) 和 z(s, t),表示相应点 S 上的坐标。这形成了一个我们表示为  的向量
的向量
现在假设我们对给定的 s 和 t 值进行微小变化,将 s 更改为 s + ds,将 t 更改为 t + dt。
这些变化分别导致 x、y 和 z 的变化,对于 x 的变化分别为 x(s + ds, t) - x(s, t) 和 x(s, t + dt) - x(s, t),也可以写成  ,y 和 z 的变化表达式类似。
,y 和 z 的变化表达式类似。
简而言之,s 和 t 的变化会导致位置向量  的变化,我们可以用向量
的变化,我们可以用向量  表示它们。
表示它们。
来自值范围 s 到 s + ds 和 t 到 t + dt 的积分对我们积分的贡献是 由这两个向量形成的平行四边形作为基底的平行体的体积,其高度由 w 在这两个向量上的分量给出。
在图中,A 和 B 分别表示 。
正如我们在第三章看到的那样,这个体积是行列式的绝对值,其列是三个向量的分量 和 w;这个行列式也可以根据下式写成

这就是我们所寻找的答案。
这里的曲面积分可以写成这里显式被积函数在适当 s 和 t 的范围内的二重积分。
在普通积分的情况下,我们将正号赋予 x 轴以上的区域,将负号赋予 x 轴以下的区域。在这里,我们也类似地将符号与体积的部分相关联,以便我们通常使用的被积函数是实际行列式,而不是表示无符号体积的绝对值(上面给出的),它表示无符号体积。
你会注意到这里表达式的符号在交换 s 和 t 时是相反的,这表示在任意曲面片上没有预定义的答案:哪一端是上?
无论你在什么样的情境下操作,我希望你知道这个问题的答案,并且可以安排这里 s 和 t 的顺序以符合那个答案。
这里是曲面积分如何简化为一对普通积分的方式

直到适当的符号。
例子:
假设我们有由 x = Rsin s cos t,y = Rsin s sin t,z = Rcos s 定义的曲面,对于 0 < s <  ,且 0 < t < 2,固定参数 R。
,且 0 < t < 2,固定参数 R。
这个曲面是以原点为中心的半径为 R 的球面。
假设w是 R^(-2)u[R],它是与这个曲面垂直的,是来自原点的单位电荷的电场。
我们发现这里关于 s 的偏导数形成向量(Rcos s cos t, R cos s sin t, -Rsin s),而关于 t 的偏导数形成(-Rsin s sin t, R sin s cos t, 0)。我们可以通过注意到这些偏导数彼此和w, ,是法线的事实来评估行列式,因此行列式是这些向量的大小的乘积,这些向量是 R,Rsin s 和
,是法线的事实来评估行列式,因此行列式是这些向量的大小的乘积,这些向量是 R,Rsin s 和 。
。
我们的积分变成了 sin s ds dt 的积分,积分变成了 4 。注意这个结果与 R 无关。
。注意这个结果与 R 无关。
我们也知道,顺便一提,w的散度除了在原点外都为 0。这告诉我们,根据散度定理,如果我们通过将封闭球体外的任何区域的表面添加到其上,并减去不包括原点的任何区域的表面积,我们将不会改变这个答案。
这意味着如果我们像这样对包围含有原点的区域 V 的任何曲面(足够光滑以使我们的定义有意义)进行 w[b]的积分,我们将得到相同的答案。
它进一步暗示,如果我们对来自任何电荷分布的 w 的总和进行积分,我们将从 V 内的每个电荷(符号和电荷量的数量)得到一个贡献 4,而没有其他的。
这个陈述被称为高斯定理。 习惯上用 来表示体积小元素中的电荷量。 高斯定理可以写成以下形式
来表示体积小元素中的电荷量。 高斯定理可以写成以下形式

习题 24.1 将在垂直圆柱体外壁上从 z = 0 到 1 的垂直部分上的 w[n]的积分,其中 w = (x², xy, z²),表达为一对普通积分,即多重积分。
24.2 平面上的区域积分的含义:雅可比行列式
在 xy 平面上对面积 A 进行的积分是面积积分的一个特殊且易于可视化的情况。
在上一节的结果中,我们可以添加这样的条件,即 z(s, t) = c 在我们的曲面上始终成立,这样我们就得到了一个面积积分。
在这种情况下,每个面积元素的法线方向始终是k方向。因此,我们只关心w的 z 或k分量,因此可以将注意力集中在标量场 w[z]上,其中 w[z] = f(s, t)。
在这种情况下,被积函数乘以面积元素,变为 f(s, t)dA,如果我们取 s = x,t = y,那么面积元素 dA 由 dxdy 给出,于是变为 f(x, y)dxdy。
然而,前一节的结果包含一个重要的含义当 s 和 t 不是 x 和 y 时。 它总体上告诉你如何将面积积分或以面积元素 dxdy 表示的积分写成以元素 dsdt 的积分,如果你给定了任意两个参数s 和 t,可以在给定的区域 A 内写出 x = x(s, t)和 y = y(s, t)。
简而言之,它告诉你如果你在具有面积元素 dxdy 的面积积分中改变变量,要得到以元素 dsdt 的积分,该怎么做。
这告诉你什么?
这里的行列式中 w[z]的“余子式”是二乘二行列式,是关于 s 和 t 的 x 和 y 的偏导数的 z 分量。
我们得到:表达式 f(x, y)dxdy 可以写成 f(x(s, t),y(s, t))dsdt J 的形式,其中 J 被称为从变量 x, y 到 s, t 的变换的雅可比行列式,J 由 x 和 y 关于 s 和 t 的偏导数的行列式的绝对值给出。

当然,我们不需要引入曲面积分的概念来推导这个结果。 当在 s 和 t 中进行无穷小变化 ds 和 dt 时,得到的 xy 平面上的面积是平行四边形的面积,其边长是
那个平行四边形的面积是 Jdsdt,这就是以坐标 s 和 t 表示的适当面积元素 dA。
这个非常重要的结果是链式法则的二维类比,它告诉我们一维积分中 dx 和 ds 之间的关系,
请记住这里定义的雅可比行列式始终为正。
练习:
24.2 从 dxdy 到 dsdt 的雅可比行列式,与从相反方向进行的雅可比行列式之间有什么关系?
24.3 通过检查上述矩阵与转置矩阵(交换行和列)之间的矩阵乘积来解释这一点。
24.4 假设 x = uv 和 找到这个变换在每个方向上的雅可比行列式。
找到这个变换在每个方向上的雅可比行列式。
24.3 对更高维度的泛化
上面讨论的一切同样适用于任意欧几里得维度的积分。
因此,你会遇到三维体积积分,对于这些,体积元素 dV 可以根据变量 s、t 和 u 的表达式 dV = dxdydz = Jdsdtdu 来表示,其中 J,雅可比行列式,是变量 x、y 和 z 对于 s、t 和 u 的偏导数的行列式的绝对值。
还有在“相空间”上的积分,其中每个粒子有 3 个位置和 3 个动量变量,空间和时间的积分,以及对许多粒子的位置的积分。
在更高维度中,体积的类比被称为超体积,表面的类比被称为超表面。它是整个空间维度少一维的区域。
一个平坦的超表面(称为超平面)有一个法线方向,它垂直于其中所有点之间的差异。
再次,我们可以通过在无穷小平坦表面上局部定义对向量w的法向分量的积分,如上所做的那样。
再次发现,所定义的积分变为w和表面上坐标对于定义表面的参数的偏导数的行列式的积分,就像上面发生的那样。
再次坐标系的变化导致超体积元素的变化,可以像以前一样通过雅可比行列式描述。唯一的区别是相关行列式具有更高的维度。
练习 24.5
找到从柱坐标到球坐标的雅可比行列式,即找到 之间的关系。
之间的关系。
24.4 体积和表面积分作为单个普通积分
有时可以将体积和表面积分作为普通积分进行,而不必费心讨论前几节中讨论的一般方法。
当你的被积函数和被积区域具有足够的对称性,以至于你可以通过观察来做除了一个积分之外的所有积分,这种情况就会发生在我们的形式主义导致的多重积分中。
为什么要费心做这些事情?
有两个原因,但都不是很令人信服,但在这里它们是。
首先,使用适用于对任何合理形状和任何合���被积函数进行积分的一般方法来解决问题,其中大部分问题你可以通过直观解决,就像用大炮打蚊子,或者让哲学家教幼儿园一样。
其次,在传统的微积分学习中,你在学习表面积和体积以及多重积分之前很久就学习了单一积分,因此你有机会在不了解这些概念的情况下找到这些问题的答案。
最简单的例子是找到 x 轴(y = 0)、两条线 x = a、x = b 和函数 y = f(x) 定义的曲线之间区域的面积。
你可以将其写成带有被积函数 1 的面积积分,但这样做后,你可以立即将其变为二重积分,并对 y 进行积分,得到该面积的标准公式

假设你将曲线 y = f(x) 绕 x 轴旋转,并询问由此操作生成的区域的体积在 x 上具有相同的限制。
现在你可以争辩说,在 x 和 x + dx 之间的这个区域的小切片中的体积是半径为 f(x) 的圆的面积乘以 dx。因此,你可以将其写成一个带有被积函数为该面积的单一积分

它的表面积呢?
再次,我们可以将我们的曲面切割成 x 和 x + dx 之间的部分。任何一个切片中的表面积将是 ds 乘以半径为 f(x) 的圆的周长。
在这里你必须要小心,因为相对于 x 轴,切割的曲面通常是倾斜的,这里的因子 ds 不是 dx,而是我们切片中由 y = f(x) 定义的曲线的长度。
我们知道

所以

或

这给出了

作为由绕 x 轴旋转的曲线 y = f(x) 生成的曲面的表面积。
可以为由绕 y 轴旋转的由 y = f(x) 定义的曲线获得的区域生成类似但不同的公式。
练习 24.6 找到由曲线 y = f(x) 绕 y 轴从 (a, f(a)) 到 (b, f(b)) 定义的区域的体积和表面积的单一积分表达式。
你也可以在其他坐标系中做类似的事情,例如通过直观地积分球坐标的一个或多个变量。
这种方法的一个标准例子是球体。假设我们想确定半径为 R 的球体的体积和表面积。
注意,球体是由绕 x 轴旋转的曲线  。体积或表面积的积分限为 x = -R 和 x = R,被积函数为
。体积或表面积的积分限为 x = -R 和 x = R,被积函数为
对于体积

对于表面

或者

这些可以与标准结果相结合。有趣的是,在切片厚度为 d 的球体中,只要它的两侧有球体的部分存在,切片的表面积  与其位置无关。
与其位置无关。
像上面那样的公式可以用于圆锥体、楔形体和各种其他形状。
第二十五章:数值积分
介绍
我们可以很容易地设置一个电子表格来评估给定积分 f 在从 a 到 b 的大量点,并形成黎曼和。一个对称的做法是“梯形法则”,它通过在给定区间的两端具有相同高度的梯形的面积来近似条带中的面积。我们探讨了这个规则和更准确的外推。其中一个被称为辛普森法则。
主题
25.1 梯形法则
25.2 辛普森法则
25.3 外推和更好的逼近
25.4 线积分的数值评估
25.5 在电子表格上执行通量(表面)积分
25.1 梯形法则
我们面临的问题是在有限区间[a, b]内找到由方程 y = f(x)描述的曲线与 x 轴之间的面积。
我们采用了定义积分的方法。当 f 在区间内连续时,我们将其分成 N 个子区间,每个宽度为 ,我们将其称为 d,(我们假设 b > a),并评估 f 在每个区间的端点,从 a + jd 到 N 为止。
,我们将其称为 d,(我们假设 b > a),并评估 f 在每个区间的端点,从 a + jd 到 N 为止。
当 f 只有分段连续时,您应该先将区间分成 f 连续的子区间,然后按照我们在每个区间中讨论的方式继续。
梯形法则包括将每个子区间的面积近似为其宽度 d 乘以其端点处 f 值的平均值。对于第 j 个区间,这是

现在我们来回答这个问题:为什么要这样做?
是否比起选择一个随机点 x'在第 j 个区间中计算 d * f(x')作为该区间对面积的贡献来说,使用这个梯形法则更好?
要对这个问题得到部分答案,请考虑一个宽度为 d、中心在 x[j]处的区间,为了方便起见,我们将 x[j]设为 0。
然后区间开始于 ,并在
,并在 结束。
结束。
现在假设我们可以在 x 周围用幂级数展开我们的被积函数 f,结果是
f(x) = f(0) + ax + bx² + cx³ + ex⁴ + ...
在这个区间内这个函数的实际面积将是

(这里的因子 的产生如下:端点和各有相同的贡献,每个为
的产生如下:端点和各有相同的贡献,每个为 。)
。)
因子 的产生方式类似。请注意,在这里 ax 和其他奇数次幂项在这里根本不贡献,因为它们是奇数的,它们的贡献会相互抵消。)
的产生方式类似。请注意,在这里 ax 和其他奇数次幂项在这里根本不贡献,因为它们是奇数的,它们的贡献会相互抵消。)
我们描述的梯形法则提供了对于这个区域的以下建议答案

f(0)的贡献完全正确,b 的贡献是三倍于此,而 e 的贡献是五倍于此。
请注意,这里任何关于 0 对称的估计都将准确得到奇数(a、c 等)项。
特别地,我们可以使用"中点法",它将面积近似为 f(0)d,这样就能准确获得 a、c 等贡献,但完全得不到 b、e 等项的贡献。
导致 a 和 c 项相互抵消的对称性是梯形法在此处拥有的巨大优势,它与中点法共享此优势。
考虑一下,如果我们将 d 减小一半(或任何其他因子 z)。由于这种对称性,梯形法或中点法中的误差会在每个区间中减少 8 倍,但现在有两个区间,而不是一个。
因此,必须加倍此错误以便在原始区间上进行比较,而且梯形法或中点法中的实际误差在任何一个来自 b 项的区间中会减少四分之一,甚至在 e 和其他项中会减少更多。
练习:
25.1 设置一个电子表格,将给定区间 a 到 b 分成 N 个等分区间,评估给定函数,比如 sin x,在每个 N + 1 个区间端点,并计算结果积分的梯形法评估。
25.2 制作一个具有同时计算 N = 1、2、4、8、16 和 32 的能力的电子表格。(您可以通过从 32 开始并输入指令=if(mod(j,2^k)=0,2*prev column entry,0)来将它们放在一起,其中 j 是子区间端点的索引,k 是列索引。每增加 1 次 k,梯形区间的数量就会减少一半。)
25.2 辛普森法则
在上一节的符号表示中,函数 f 在介于和之间的实际面积将是

另一方面,我们描述的梯形法则对于这个区域提供了以下建议答案

而"中点法"将面积近似为 f(0)d。
这意味着如果我们将中点法的两部分与梯形法的一部分混合在一起,我们将完全正确地得到二次 b 项,而误差的主导项将来自 e 项,其量级将为 d⁴。
刚才描述的积分近似法则称为辛普森法则,在介于 和
和 之间的区间中采用以下形式
之间的区间中采用以下形式

请注意,在这个公式中,f 在间隔为 的位置进行评估。如果我们在这里给参数 一个新名称,称之为 h,那么辛普森法则的公式变为

它代表了对由 f 在从 -h 到 h 的区间内定义的曲线下面积的逼近;一个其误差与 h 的四次方成正比的逼近。
值得注意的是,当应用于一系列小子间隔时,这些各种规则的外观是什么样子的。
梯形法则给予所有中间点的评估相等的权重 d,因为每个点都是一个子间隔的左端点和右端点,它从每个端点获得 的权重。
另一方面,最后两个评估只是一个子间隔的末端,这些获得权重为 。
中点法则给予奇数次评估 d 或 2h 相等的权重。
辛普森法则给出的权重形成模式 1 4 2 4 2 ... 4 1 乘以  ,因为中点获得权重
,因为中点获得权重  ,而梯形法则除以 3 解释了其余部分。
,而梯形法则除以 3 解释了其余部分。
| 端点 a | 第一个间隔的中点 a + h | 第一个间隔的末端 a + 2h | 第二个间隔的中点 a + 3h | 第二个间隔的末端 a + 4h | 等。 | |
|---|---|---|---|---|---|---|
| 梯形法则项 | hf(a) | 0 | 2hf(a + 2h) | 0 | 2hf(a + 4h) | 等。 |
| 中点法则项 | 0 | 2hf(a + h) | 0 | 2hf(a + 3h) | 0 | 等。 |
| 辛普森法则项 |  |
 |
 |
 |
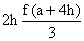 |
等。 |
注意,在为 f 生成辛普森法则中产生误差的幂级数中,主导项是 ex⁴ 项,如果我们将间隔减半,这将导致误差减少 16 倍。
25.3 外推和更好的逼近
我们在讨论数值微分时看到,当我们有一系列数字,这些数字是对一个数字 A 的逼近,其误差从项到项按给定因子 r 减少时,我们可以外推这个序列,以获得一个更快收敛的序列。
一般的外推规则是:为了消除按因子 z 减少的误差,将当前结果乘以 z 减去前一个结果,然后将此差异除以 z - 1。
例如,如果我们查看梯形法则提供的答案,对于值 16d、8d、4d、2d、d,我们得到一个近似答案序列,其误差可以预期每次减少大约 4 倍。如果我们将这些答案表示为 ,并查看序列
,并查看序列 ,(对于 j = 2 到 5),那么在每个 B 中下降为 4 倍的 A 项将在每个 B 中抵消掉,我们只会留下更高阶的项。
,(对于 j = 2 到 5),那么在每个 B 中下降为 4 倍的 A 项将在每个 B 中抵消掉,我们只会留下更高阶的项。
如果我们在这里将这个过程应用于梯形法则,我们得到了先前定义的辛普森法则近似。
练习 25.3 验证这个说法。
但我们知道辛普森法则中领先的项每次减少 16 倍,我们可以用同样的方法来玩它们。
我们可以形成 ,由
,由 定义,对于 j = 3 到 5,并得到一个“超级辛普森法则近似”,其中(在幂级数展开中)领先的项每次减少 64。
定义,对于 j = 3 到 5,并得到一个“超级辛普森法则近似”,其中(在幂级数展开中)领先的项每次减少 64。
我们可以再继续这样做两次:得到对于 j = 4 和 5 的 ,以及
,以及 ,这大约是我们用 16 个区间进行近似的最好的结果。
,这大约是我们用 16 个区间进行近似的最好的结果。
练习:
25.4 使用练习 25.2 的结果来计算 A 到 E。在你知道值的积分上比较它们的准确性。(例如 sin x 从 x = 0 到 1。)
请注意,虽然这些方法非常好,但在 sin x 上特别有效。**
25.5 你能找到一个这种积分方法很糟糕的函数吗?你可以怎么改进它?
25.4 线积分的数值评估
假设我们面对一条线积分,这是沿着欧几里得空间中某条路径的积分,其中向量场v为 ds。
ds。

我们可以设置一个电子表格来评估这样的积分,而几乎没有困难。
在本节中,我们描述了如何实现这一点,并试图怂恿你自己在电子表格上做一些类似的事情。
顺便说一句,一旦你拥有这样的东西,你就可以用极少的努力修改路径、被积函数或者网格大小,因此可以使用你的产品来评估你所遇到的任何线积分。
线积分与普通积分相比更复杂,主要是因为你不仅需要处理被积函数,还需要处理路径,而对于普通的被积函数,路径是实线的一个区间,由其两个端点完全确定,你只需要处理被积函数。
我们所做的取决于积分的路径 C 如何定义。
最简单的情况,我们在这里解决的是当我们把 C 给出作为一个参数曲线时发生的情况。
这意味着我们有一个参数,让我们称之为 t,并且对于每个坐标 x、y、z 等,我们有 t 的函数形式,并且 t 值的区间定义了曲线。
我们的计划是将 t 区间分成许多小片段,并在这些片段的边界处计算 x(t)、y(t)、z(t) 和 vx, y(t), ...)、vy, y(t), ...)、...。
换句话说,我们将为 x、y 和 z(在三维空间中)的每个计算分配一列;并且为矢量场 v 在点 (x(t), y(t), z(t)) 处的每个分量进行计算。然后,我们使用一列来描述来自一个子区间(比如 t 到 t + d 之间)的积分贡献。
我们用什么来估计这个贡献?
t 是 x(t) 在该区间内的变化乘以该区间端点上 v[x] 的平均值,再加上 y 和 z 上相同的情况。我们只在这里写下 x 的贡献,即

在最后一列,我们将这些贡献加起来,覆盖各个区间,这就是我们的积分。这是线积分的梯形法则。
一旦完成了这个步骤,我们如何改变路径? 修改 x(t)、y(t) 和 z(t) 列,以使用不同的 t 函数。
我们如何改变被积函数 v? 改变它的列。
我们如何改变区间大小参数 d? 只需改变它。
我们究竟要如何做到这一点?
我喜欢把前五行留给注释和数据输入。
在 B2 中,我会放入起始 t 值,在 B3 中放入 d 的值。
在顶行,我会给出对曲线和矢量场的文字描述。
所以我会从第 6 行开始计算。
这里是我会放在 t 列(A 列)的内容。
A6=B2
A7=A6+B3
A8=2*A7-A6
并且我会把 A8 复制到 A9-A1005(或者更远,如果你愿意)。
在 x、y 和 z 列中放入
B6=x(A6)(当然,你必须放入这个函数是什么)
C6= y(A6)
D6=z(A6)
并将这些复制到 B7-B1005,等等。
在 v 列中,放入 v 的各个分量的值
E6=vx
F6=vy
G6=vz
并将其复制下去。
接下来设置
H6=(B7-B6)*(E(7)+E(6))/2
并将其复制到 I6 和 J6 的位置,并向下延伸。
设置
K6=H6+I6+J6
并且
L7=L6+K6
并将这些复制下去,你就完成了。
如果最终的 t 值出现在 Ak,则积分答案将在 Lk 中。
你可以调整 d,并且可以像普通积分一样进行外推。
这里使用的方法是梯形法则的路径积分版本。
通过一点诡计,你可以推断出这一点积分版本的辛普森法则,并且也可以推断出它。
你可以通过对一个 d 值、2d 值和 4d 值进行积分来检查准确性(确保适当调整端点,以检查准确性)。
在没有外推的情况下,当你将 d 减小一半时,答案的差异应该减少 4 倍;用细分的结果的 减去较粗糙的结果的
减去较粗糙的结果的 或较粗糙的结果应该会改善到 Simpson 的结果。
或较粗糙的结果应该会改善到 Simpson 的结果。
依此类推。
25.5 在电子表格上进行通量(表面)积分
当表面 S 以参数形式描述时,也就是说,给定函数 x(s, t),y(s, t)和 z(s, t),以及 s 和 t 的值域,你可以使用电子表格来计算任何可定义在电子表格上的向量函数w(即与表面法线的点积)的通量积分。
你可以利用电子表格的能力,在二维的大范围位置复制单个指令,行和列。
假设你想要先对 s 进行积分,然后再对 t 进行积分,你将从 t[1]到 t[2]进行积分,并从 s1 到 s2 进行积分。假设你想将每个范围分成 N,N = 100 个片段。
这个计划如下:你设置 s 值、t 值的数组,然后是 x、y 和 z 值,然后是 w[x]、w[y]和 w[z]值的数组,最后是一个积分的数组;这些数组中的每一个都将是 N + 1 乘以 N + 1 的大小,但最多只需要构造 3 或 4 个条目。其余的都是复制。
设置一个 t 值的数组,将 t[1]分配给第一列中使用的第一行,然后在其下一行中将(previous + (t[2] - t[1]) / N),以及在(previous to previous)之下的(2 * previous - (previous to previous))。将其复制到接下来的 98 行。然后将下一列的条目设置为“=左侧条目”,将其复制到接下来的 98 列和行。
这应该在每一行中给出一个单一的恒定 t 值,但在每一列中给出不同的值。
接下来设置两列来计算每个 t 值的 s1 和 s2。
通过在第一列中放置=s[1]、第一行中的 s[1] + (s2 - s1) / N(在 N 上使用美元符号)以及下一列中的(2 * 左侧 - 左侧左侧)来设置一个 s 值的数组。
然后将这个复制到 98 行,并将第三列复制到 98 行。
再次设置相同大小的 x、y、z 和 w[x]、w[y]和 w[z]数组,方法是将 x(s0, t[0])放在 x 数组的左上角条目中,并将其复制到整个数组中。其他 5 个数组也可以类似地完成。
要计算积分,你可以将每个“区间对”ds 和 dt 的贡献相加,即
w[x] * (dy[s]dz[t] - dy[t]dz[s]) + w[y] * (dz[s]dx[t] - dz[t]dx[s]) + w[z] * (dx[s]dy[t] - dx[t]dy[s])
要再次计算每个 2x2 矩形中的积分,你只需要计算顶部左侧的一个,然后再次复制到一个 100 乘 100 的数组中。
这可以一次完成或每个项都完成一次。积分将是整个数组上的这些的总和。
对于一对区间,你需要做什么来获得 w[x]或 dy[s]或 dz[t]?
假设区间的角落是(s,t),(s + d,t),(s,t + d')和(s + d,t + d')。
然后,二维中梯形法则的类比给出

尽管创建这个最后一个数组很混乱,但实际上只需要在一个正方形中完成并复制,而且只需要完成一次,并且可以在其他数组具有相同起始点的情况下重复使用。
请注意,要更改 s 和 t 的域,只需更改前两个数组;要更改参数化,只需更改 x、y 和 z 数组,要更改计算其通量积分的向量w,只需更改其三个数组。
通过对最后一个数组进行不同的求和,可以获得对表面子集的积分。
这里是一个例子
t[1] =1,t[2] = 2,s[1] = t²,s[2] = t³,


请注意,更改 t[1]、t[2]、s[1]、s[2]、x、y、z、w[x]、w[y]或 w[z]每次只需要更改一个条目,然后将其复制到整个相应的数组中。(或在适当的地方。对于 t[1]和 t[2],您无需复制任何内容,对于 s[1]和 s[2],那是一列。)
很容易推断这些结果:您可以将 N 更改为 50,并对最后一个数组的左上角进行求和,将 N 更改为 25,并对该数组的左上角进行求和。
此积分的结果为 N = 100 时为 132.2450414,N = 50 时为 132.1941481,N = 25 时为 131.9909671。
在 50 和 100 之间,这些之间的差异大约是 25 和 50 之间的 4 倍。将更好的乘以,减去更差的乘以得到 132.262006 和 132.261875。假设剩余误差按 16 的倍数下降,给出 132.2620145 的估计,这可能准确到 6 位小数。
这可以通过扩大数组并尝试 N = 200 来验证,这只需要复制,并形成一个新的总和。
练习:
25.6 创建刚才描述的电子表格,并验证或证伪上述说法。
25.7 您能得到描述的积分的最佳估计是什么?
25.8 将 s 和 t 更改为从 0 到 和 2,使 x、y 和 z 等于球坐标中的值,并让 w 为向量(x,y,0)。通过这种方法找到积分的合理精度。
和 2,使 x、y 和 z 等于球坐标中的值,并让 w 为向量(x,y,0)。通过这种方法找到积分的合理精度。
第二十六章:微分方程的数值解
简介
你可以使用辛普森法则等技术来解决更一般的一阶微分方程的数值解。我们来探讨一下��
主题
26.1 微分方程简介
26.2 左手法则与外推法
26.3 梯形法则的泛化
26.4 辛普森法则的泛化;龙格-库塔 2^(th) 阶法则
26.5 评论
26.1 微分方程简介
微分方程是涉及导数的方程。方程的阶数是方程中出现的最高阶导数。
这里有一些例子

这前四个是一阶微分方程,最后一个是二阶方程。
前两个被称为线性微分方程,因为它们在变量 y 中是线性的,第一个有一个右侧与 y 无关的“非齐次项”,第二个是齐次线性方程,因为所有项在 y 中都是线性的。
这前三个是“可分离的”微分方程,因为它们可以重写为 dx f(x) = dy g(y),其中 f 和 g 适当。
如果你只知道一个函数的导数,那么你没有足够的信息来完全确定它。因此,你可以寻找微分方程的解,或者一般解(通常每个方程阶数中都有一个常数),或者在一些额外条件下的解。
你可以通过积分找到任何可分离的一阶微分方程的一般解,(有时也称为“求积法”)。你只需对方程的两边进行积分 dx f(x) = dy g(y)。因此,如果无法精确积分,你可以直接将前一章的数值技术应用于每个方程,并对其进行数值求解。
我们在这里要讨论的问题是:
假设我们有一个不可分离的一阶微分方程,因此我们无法直接将其解决为求积。我们能否将以前用于积分的数值技术应用于解决这些方程的任务?
答案是肯定的,我们将在下面展示如何。确实有一个我们接下来会讨论的复杂性,但可以克服。
这个事实的含义是,任何行为可以由一阶微分方程或甚至一组相关的一阶方程建模的系统,都可以通过现代计算机迅速数值解决到任何所需的精度。这使得这些系统的实时控制成为可能,并在工程领域具有巨大价值。
26.2 左手法则与外推法
我们寻求形式为一阶微分方程的解

我们假设我们知道 y(a) 并希望找到 a 和 b 之间的参数 x 的 y,特别是想要找到 y(b)。
我们考虑以下例子

在 a = 0,b = 1 或 2 以及 y(0) = 1 的情况下,用来说明所讨论的方法。
我们希望将区间 [a, b] 分成长度为 d 的小子区间,对于每个子区间,通过对其中的 的估计乘以 d 来近似 y 的变化。
的估计乘以 d 来近似 y 的变化。
使用普通积分时,我们有很多不同的估计 f 的方法,左规则、右规则、梯形规则或辛普森规则,以及其他方法, 这些方法是基于在子区间内使用 f 在各个参数处的值。
这里的复杂性在于我们除了在点 a 处不知道 y 的值外,在任何地方都不知道 y 的值,或者更一般地说,我们只能根据在以前的子区间上的计算来期望在子区间的左侧有 y 的近似值。实际上,我们对该子区间的处理的目的是将我们对其左端点上 y 的估计扩展到对其右端点上 y 的估计。
由于这个事实,我们必须使用一些程序来估计子区间中的 y,以便应用左手法则之外的任何以前的技术。
这个复杂性不影响左手法则;所以我们首先问,我们如何应用那个规则? 然后:使用左手法则是否可能得到准确的数值解? 欧拉和其他人发现的左手法则,包括对区间 x 到 x + d 的 y 变化进行估计。
y(x + d) - y(x) = f(x, y(x))*d
并且依次将其应用于 a 和 b 之间的每个子区间,以计算每个 j 下的 y(a + j*d) 并最终计算出 y(b)。它涉及在 f(x, y) 中使用前一个子区间左端点处获得的 x 和 y 的值来计算每个区间内的 y 的变化。
这种方法的优点是在电子表格上实现非常容易。它的缺点是不太准确。它在每个子区间的端点之间是不对称的,因此,如果你将 d 减小一半,那么主导误差项也会减小一半。 结果,要将准确性提高 1000 倍,你必须将 d 减小 1000 倍,而这并不是解决这类微分方程的有效方法。
下面的指令实现了当此处的最后一行被复制或向下填充 N - 1 行时,用于 f(x, y) 的此规则。这些是 A、B、C 和 D 列,以及 1-9 行。
要切换到不同的微分方程,你只需要适当地更改 D9 条目并将结果复制下来。
| A | B | C | D | 1=row number |
|---|---|---|---|---|
| 左手法则 | f(x,y)=x+y | 2 | ||
| 输入 a | 0 | 3 | ||
| 输入 b | 1 | 4 | ||
| 输入 N | 64 | 5 | ||
| 输入 y(a) | 1 | 6 | ||
| d | =(B4-B3)/B5 | � | 7 | |
| 区间索引 | X | Y | f(x,y) | 8 |
| 0 | =B3 | =B6 | =B9+C9 | 9 |
| =A9+1 | =B9+$B$7 | =C9+(B10-B9)*D9 | =B10+C10 | 10 |
这里间隔索引无关紧要,仅用于方便检查您的计算是否有足够的行。 (您可以省略它。)
我们可以利用外推法来提高这里的性能, 就像我们在第七章中用于数值微分以及在上一章中用于数值积分一样。
假设我们用子间隔数 N 来表征我们对区间[a, b]的划分。 让我们将应用左手规则的结果称为 L(N)。 要计算 L(N/2),只需复制整个内容到其他位置,通过将 B10 中的条目乘以 2 来更改第二项,然后将该条目复制下来。 答案将在一半的步骤后出现。
然后我们可以定义一个外推的左手规则,L2,当 N 被 2N 替换时其准确性应该提高 4 倍,通过
L2 = 2L(2N) - L(N)
那么这条规则的行为应该与梯形法则的行为相差不远。 而且我们可以通过外推这个规则来做得更好,形成 L[3]:
L3 = (4*L2 - L2)/3
这应该使得误差在加倍间隔的情况下减少 8 倍,然后我们可以再次外推,形成 L[4],依此类推,根据规则
Lj = ((2^(j-1)) Lj-1 - Lj-1)/(2^(j - 1)-1)*
令人惊讶的是,通过这种方式可以达到相当高的准确性。 L(32)不是很准确,而 L(1),L(2),L(4),...,L(16)更差,但它们允许计算 L ,后者要好得多。
练习 26.1 设置一个电子表格来计算这些值,对于 f(x, y) = x + y, a = 0, b = 1,其中 y(a) = 1,并计算 y 在 x = 1 处的值的 L 。
对于这个问题,得到的 y(2)的结果如下。比例误差在第二个表格中描述
| N | L | L[2] | L[3] | L[4] | L[5] | L[6] | L[7] | L[8] |
|---|---|---|---|---|---|---|---|---|
| 1 | 3 | |||||||
| 2 | 5 | 7 | 精确答案 | = | 11.7781122 | |||
| 4 | 7.125 | 9.25 | 10 | |||||
| 8 | 8.921 | 10.71686 | 11.20581 | 11.37807 | ||||
| 16 | 10.17 | 11.41207 | 11.64381 | 11.70638 | 11.728268 | |||
| 32 | 10.92 | 11.66817 | 11.75353 | 11.76921 | 11.773395 | 11.77485027 | ||
| 64 | 11.33 | 11.74777 | 11.77431 | 11.77727 | 11.777811 | 11.77795396 | 11.77800322 | |
| 128 | 11.55 | 11.77013 | 11.77758 | 11.77805 | 11.778098 | 11.7781071 | 11.77810953 | 11.77811037 |
令人非常惊讶的是,即使回到一个间隔的近似值也会改善最终答案,因为它允许进行一次额外的外推。
| N\L 索引 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 1 | -0.7453 | |||||||
| 2 | -0.5755 | -0.405677 | -1 | � | � | � | � | |
| 4 | -0.3951 | -0.214645 | -0.15097 | � | � | � | � | |
| 8 | -0.2426 | -0.090104 | -0.04859 | -0.03396 | � | � | � | |
| 16 | -0.1368 | -0.031078 | -0.0114 | -0.00609 | -0.00423 | � | � | |
| 32 | -0.0731 | -0.009335 | -0.00209 | -0.00076 | -0.0004 | -0.000277 | � | |
| 64 | -0.0378 | -0.002576 | -0.00032 | -7.1E-05 | -2.6E-05 | -1.34E-05 | -9.25E-06 | |
| 128 | -0.0193 | -0.000678 | -4.5E-05 | -5.6E-06 | -1.2E-06 | -4.33E-07 | -2.27E-07 | -1.56E-07 |
| 左手规则 y' = y + z 的比例误差,y(0) = 1,找到 y(2) |
由这些结果可以看出,使用最简单的数值方法并对其进行极端外推,实际上可以得到准确的结果。
注意这里所有的外推都是使用左手规则在 x = 2 处得到的最终答案。当中间的 x 值变得可用时,你可以通过在中间 x 值上应用外推来改善所有的计算,从而获得稍微更好的结果。
因此,第一次外推可以应用于在两个区间后更新 y,第二次在每组四个区间后更新,等等。这减少了 y 中的误差叠加的影响,在这里只有轻微的帮助。
显然,你越把 d 减小,就越好,也就是说,你把 N 变得越大,效果就越好。
但是,在这里,使用更小的 N 值进行外推比将 N 加倍改进答案要有效得多。
26.3 梯形法则的泛化
使用梯形法则来数值逼近积分,比使用左手法则要好得多,如果你能找到一种方法,在你只有左端点处 y 的估计时,在区间的右端点处计算 f(x, y)。
显然,首先近似这样做是使用在左端点定义的 y 的线性近似来近似区间的右端点的 y。得到的规则是

该规则由以下方法近似区间端点处 y 值的差异,即d 的一半乘以左端点处 f 的导数和在左端点定义的对右端点处导数的线性近似的和。当 f 不依赖于 y 时,我们得到通常的梯形法则。
另一种观察区间从 x 到 x + d 的方法是通过定义左手规则的“迭代”,如下所示

在这些条件下,这里的计算规则是

左手规则不适用,因为 y 在区间上发生了变化。这里应用的对 y 的线性近似只不过是因为y 的导数发生了变化,这是一个二阶导数的影响。
因此,它造成的误差是与区间大小的平方成正比的,并且与梯形法固有的误差相当。因此,我们预计当 N 加倍时,该规则的结果会提高 4 倍的准确性。
再次强调,设置一个电子表格来计算这个规则对于任何 N 的预测并不复杂,你可以像以前一样进行外推。
它的优点在于,你可以从因子 4 的外推开始,因为在加倍点数时,准确性提高了 4 倍,这一点内在于其结构之中。
该规则不再具有与梯形法相同的权重结构,因为当你在给定的中间点从左边计算 f(x, y) 时,你使用的是在上一个点处的线性近似,而当你在其右侧的区间中计算时,你使用的是在前一个区间中从规则本身计算出的 y 的值。这就是生活。
这是第 9 和第 10 行中的条目,可以替代上面的条目来产生此计算,当红色条目被复制时。表中 D 和 E 列中的红色条目是给出微分方程 y' = x + y 的。它们必须被更改,并且结果被复制,以便切换到不同的微分方程。
| B | C | D | E | |
|---|---|---|---|---|
| X | y=y(x-d)+(f0+f1)*d/2 | f0=x+y(x) | f1=x+d+y(x)+d*f0 | 8 |
| =B3 | =B6 | =B9+C9 | =B10+C9+(B10-B9)*D9 | 9 |
| =B9+$B$7 | =C9+(D9+E9)*(B10-B9)/2 | =B10+C10 | =B12+C10+(B12-B10)*D10 | 10 |
练习 26.2 比较使用上述规则和使用左手规则得到的结果,对同一问题进行比较。
使用这种梯形法得到的结果如下所示,具有不同级别的外推:
| N\L# | L[1] | L[2] | L[3] | L[4] | L[5] | L[6] | L[7] | L[8] |
|---|---|---|---|---|---|---|---|---|
| 1 | 5 | |||||||
| 2 | 9.5 | 11 | ||||||
| 4 | 10.9458 | 11.42773 | 11.48883929 | |||||
| 8 | 11.52449 | 11.71739 | 11.75877194 | 11.77676745 | ||||
| 16 | 11.70817 | 11.76939 | 11.77681781 | 11.77802087 | 11.7780613 | |||
| 32 | 11.75976 | 11.77696 | 11.77804039 | 11.77812189 | 11.77812515 | 11.77812617 | ||
| 64 | 11.77341 | 11.77796 | 11.77810835 | 11.77811289 | 11.77811259 | 11.7781124 | 11.77811229 | |
| 128 | 11.77692 | 11.77809 | 11.77811199 | 11.77811223 | 11.77811221 | 11.7781122 | 11.7781122 | 11.7781122 |
这些计算对于这个问题的准确度显示在下表中:
| N\L# | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 1 | -0.57548 | � | ||||||
| 2 | -0.19342 | -0.06606 | ||||||
| 4 | -0.07067 | -0.02975 | -0.02456 | � | � | |||
| 8 | -0.02153 | -0.00516 | -0.00164 | -0.00011 | � | |||
| 16 | -0.00594 | -0.00074 | -0.00011 | -7.8E-06 | -4E-06 | |||
| 32 | -0.00156 | -9.8E-05 | -6.1E-06 | 8.23E-07 | 1.1E-06 | 1.19E-06 | � | � |
| 64 | -0.0004 | -1.3E-05 | -3.3E-07 | 5.84E-08 | 3.4E-08 | 1.68E-08 | 7.6E-09 | � |
| 128 | -0.0001 | -1.6E-06 | -1.8E-08 | 2.51E-09 | 7.1E-10 | 1.84E-10 | 5.3E-11 | 2.4E-11 |
| ����������� (f0 + f1)/2 规则的比例误差 y' = y + z, y(0) = 1,寻找 y(2) |
您会注意到,这里没有外推的估计比上一个方法的第一次迭代更好一点,对于 N = 128,好了 6 倍。然而,在外推后,结果比上一个表格中更准确了成千上万倍。请参阅一阶常微分方程 Applet
26.4 辛普森规则的泛化;龙格-库塔 2 阶规则
通过提供一个估计区间内 y 变化的规则,其精度与辛普森规则相当,您甚至可以做得更好。
为此,我们估计区间起点、中点和终点处的 f,并给予这些估计相对权重 1 4 1,就像辛普森规则一样。只需要对中点和右端点的 f 的估计精确到“二阶”,使其误差为立方或更小。
有很多方法可以做到这一点。f 的左手值根本没有问题,是 f(x, y(x))。龙格-库塔二阶规则涉及使用

在区间中间对被积函数进行近似,以及

在右端进行近似,使用

因此,给定的符号,该方法提供以下规则

同样,这个规则可以在电子表格上很容易地实现。现在您需要为 x、y 和此规则中出现的四个 f 项中的每个列都需要一个或两个条目,并且为每个列复制。它也可以被外推。
练习 26.3 使用旧的初始条件,y(0) = 1,在 x = 1 时计算相同方程的解,y' = y + x。对于 N = 32,它比以前的方法好多少?
这个规则的显著之处在于误差是四阶的,就像辛普森规则一样。因此,如果我们将区间数加倍,那么对于大的 N 值,误差将减小 16 倍。辛普森规则具有这样的对称性,这使得成立。令人惊讶的是,这里的估计没有立方误差项,但它们确实没有。
有了 B11 中的 x 和 C11 中的 y,这里是对于方程中的 D、E、F 和 G 的 f 的相关条目,用于拷贝以计算方程 y' = y + x
| f = x + y(x) | f[1] = f + (1 + f)d / 2 | f + (1 + f[1])d / 2 | f + (1 + f[2])d |
|---|---|---|---|
| =B11+C11 | =D11+(1+D11)*(B12-B11)/2 | =D11+(1+E11)*(B12-B11)/2 | =D11+(1+F11)*(B12-B11) |
这里是在 x = 2 时这种方法的结果。外推假设误差的主导项在减半区间后减小了 16 倍。
| N\L# | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| 1 | 11 | � | 精确答案 | = | 11.7781122 | ||
| 2 | 11.670139 | 11.71481481 | � | ||||
| 4 | 11.767941 | 11.77446077 | 11.77638483 | ||||
| 8 | 11.777331 | 11.77795654 | 11.77806931 | 11.77809605 | |||
| 16 | 11.778058 | 11.7781065 | 11.77811134 | 11.77811201 | 11.77811213 | ||
| 32 | 11.778109 | 11.77811201 | 11.77811218 | 11.7781122 | 11.7781122 | 11.7781122 | |
| 64 | 11.778112 | 11.77811219 | 11.7781122 | 11.7781122 | 11.7781122 | 11.7781122 | 11.7781122 |
| Runge-Kutta 规则 y' = y + x, y(0) = 1, 对于 y(2) 的值与外推 |
这里显示了比例误差
| N\L# | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| 1 | -0.06606425 | ||||||
| 2 | -0.00916728 | -0.00537 | |||||
| 4 | -0.0008636 | -0.00031 | -0.00015 | ||||
| 8 | -6.6365E-05 | -1.3E-05 | -3.6E-06 | -1.4E-06 | |||
| 16 | -4.6011E-06 | -4.8E-07 | -7.3E-08 | -1.6E-08 | -5.5E-09 | ||
| 32 | -3.0291E-07 | -1.6E-08 | -1.3E-09 | -1.6E-10 | -3.2E-11 | -1.1E-11 | |
| 64 | -1.9431E-08 | -5.3E-10 | -2.2E-11 | -1.4E-12 | -1.4E-13 | -1.3E-14 | 8.3E-15 |
| Runge-Kutta 规则 y' = y + x, y(0) = 1, 对于 y(2) 的外推的比例误差 |
可以看到,对于这个评估规则,相同数量的评估点(Runge-Kutta 的 N 相当于梯形规则的 2N)在这个例子中可能产生大约一千倍的准确性,尽管梯形法的最佳外推比这里的最佳未外推 Runge-Kutta 公式好一千倍。查看一阶常微分方程 Applet
26.5 Comments
这些方法提出了以下问题:
**它们何时会失败?
它们能被改进吗?
是否有更好的技术可用?**
显然,这些方法显然不能直接应用于无限区间,因此如果遇到这种情况,你必须对其进行处理,比如改变自变量,使其成为一个有限区间问题,然后再考虑使用其中一种方法。
对于有限问题,它们也可能失败,有两种一般情况;如果 f 的高阶导数变大,你可能会在尝试使用它们时遇到困难。
例如 sin(100000x) 和  对于接近 0 的 x 值。这些对于这样的技术确实是个问题。
对于接近 0 的 x 值。这些对于这样的技术确实是个问题。
在前一种情况下,尽管 f 是有界的,但使用较小的 N 值将无法给出 f 的合理图像,在后一种情况下,无论 N 值如何,都不会在足够接近 0 处给出合理的图像。
还有另一种情况可能会遇到问题,那就是,尽管 f 表现良好,但你寻找的解在你关心的区间某一点上变为无穷大。
这并不是你可能期望的那么糟糕或奇怪的问题。但如果你尝试天真地应用它们,它们确实会破坏这些方法。
首先,这实际上只意味着 y 的倒数,函数 ,在 y 变为无穷大时经过零点。为零并不比它为其他任何值更令人惊讶,所以这种情况在非线性微分方程中很容易发生。
,在 y 变为无穷大时经过零点。为零并不比它为其他任何值更令人惊讶,所以这种情况在非线性微分方程中很容易发生。
其次,最重要的是,如果您知道 y',您也知道 ,并且可以像对 y 一样轻松地对应用这些方法。如果我们定义:
,并且可以像对 y 一样轻松地对应用这些方法。如果我们定义: ,我们发现,对于 y' = f(x, y)
,我们发现,对于 y' = f(x, y)

我们可以应用讨论过的规则来解决给定 z(a)而不是 y(b)的 z(b)。
实际上,当 y 大于 1 时,z 的导数将小于 y 的导数,因此您可以期望在近似 z 的变化方面比 y 更容易。当 y 爆炸并趋向无穷大时,z 在 0 附近静静地漫步,其行为可以很容易地通过我们的方法跟踪。
因此,在解决可能发生这种情况的方程时,谨慎的方法是同时为 y 和 z 设置您喜欢的方法,并且当 y 的数量小于 1 且 z 的数量最多为 1 时使用 y 方法,当 z 的数量最多为 1 时使用 z 方法。
设置您喜欢的方法,并且当 y 的数量小于 1 且 z 的数量最多为 1 时使用 y 方法,当 z 的数量最多为 1 时使用 z 方法。
在我们的例子中,我们有 y' = x + y,z 的方程变为 z' = -z²x - z,这与原方程一样容易处理。
在我们的计算中,我们使用了 y'方程,尽管整个区间内 y 大于 1。通过使用 z 方程,我们可能会做得更好。
当然,在我们的例子中,原方程中 y 是线性的,而非齐次项是 x 的线性,因此这个问题不会出现。
练习 26.4 尝试您喜欢的方法解决微分方程 ,其中 z(0) = 1,并比较您获得的 z(1)的倒数值,即
,其中 z(0) = 1,并比较您获得的 z(1)的倒数值,即 与您之前为 y 获得的值。
与您之前为 y 获得的值。
数值方法有很多传统知识,这个领域被称为数值分析。
这曾经是一个非常枯燥的领域,因为学习一种您根本无法使用的方法是乏味的,就像在没有厨房可以烹饪的情况下尝试阅读食谱一样。
现在您可以轻松地玩弄这些方法,并且它们对实时控制有戏剧性的应用,因此这个领域现在实际上很有趣。
您会注意到,在每种情况下,仅使用更大的间隔进行外推能够提高这里的估计精度,每种方法的因素大约为十万到一百万。
我们使用的外推方法是改进解决方案的最佳方法吗?
答案是否定的。
这些外推的方法有一个很大的优势,就是易于执行,但以加倍 N 的代价获得了额外的精确度。
实际上,如果你运用得当,通过将 N 增加 2 倍,并选择最佳的权重,为点选择最佳权重,并在每个区间使用相应准确的规则来近似 f,你可以获得额外的精确度。
如果你想象 y 写成 x 的幂级数,理论上每个新点都可以用来消除一个更高幂次的贡献,这样,使用 N 个点可能会产生一个仅由 y 的 N 次及更高导数产生误差的规则。
因此,比我们在这里所达到的要更高的准确度是可能的。但另一方面,我们在这里所做的工作所需的努力相对较少。
第二十七章:积分操作
介绍
为了让自己对处理积分有些信心,值得尝试做一些积分。我们回顾了各种方法,并给出了一些积分列表供你自行测试。
主题
27.1 基本标准技术
27.2 一些特殊技巧
27.3 练习示例
27.1 基本标准技术
我们在第一章中定义的标准函数包括多项式、有理函数、三角函数及其有理函数、指数函数和这些函数的多项式、指数函数和多项式以及三角函数的乘积,等等。
上述提到的函数类别都可以通过标准技术进行积分,还有一些其他函数也可以。
我们首先回顾标准技术,这些技术在第十九章中已经简要描述。
首先,你应该认识到,你可以通过反向使用乘积法则来对积分变量的任意幂进行积分,除非该幂为-1。因此,我们有

这意味着你可以对任何多项式以及任何单独的幂进行积分,甚至是分数幂或负幂。结果是另一个幂,除非被积函数是幂是 ,它的积分是自然对数,ln x,因此它积分为
,它的积分是自然对数,ln x,因此它积分为
你应该迅速认识到可积函数还包括常见函数的导数。这些函数包括正弦和余弦、指数函数等,以及其他一些函数,如
接下来,你应该准备好认识到可以通过积分变量的变换将函数转化为多项式或幂或其他函数的这些变换。例如,如果你遇到

你应该自问:处理 的简单方法是将其转化为
的简单方法是将其转化为 。然后,剩余的被积函数是
。然后,剩余的被积函数是 ,所以这个积分变为
,所以这个积分变为
.
同样,你应该认识到

就像

处理类似于 的积分,你应该认识到可以通过换元来处理它。为了避免混淆,最简单的方法是在这里设置 u = 3x - 7,这告诉我们
的积分,你应该认识到可以通过换元来处理它。为了避免混淆,最简单的方法是在这里设置 u = 3x - 7,这告诉我们 ,所以积分可以写为
,所以积分可以写为

类似地,你应该准备好意识到需要一系列连续简单的替换,就像在积分中一样

这变成了

在这些操作中,你明智地在应用替换 u = u(x) 之前完整地写出它,并努力不要忘记在从 dx 到 du 的过渡中应用链式法则。
有了这些方法,您可以积分任何多项式或幂或任何通过简单替换可转换为多项式的积分变换。
分部积分使您能够扩展您可以完成的积分范围,包括多项式乘以指数或对数或正弦和余弦等。
它将一个被积函数转换为一个新的函数,其中部分被积分,其余被微分。因此,给定 x 的多项式乘以 ln x,您可以微分后者并积分前者,结果将是一个可积的幂。
通过指数或适当的三角函数,乘以多项式,您可以对多项式进行微分并对其余部分进行积分,反复进行此操作,直到多项式变为常数。
甚至可以通过两次分部积分的方式积分像 e^x sin x 这样的函数。
以下是细节:
首先设定 u = e^x,dv = sin x,这给出了通过分部积分的新被积函数 -vdu,它是 e^x cos x。
另一次分部积分同样给我们带来了新的被积函数 -e^x sin x,最终我们得到了一个原始积分的方程

同样的技巧可以用来积分一个指数与正弦或余弦以及 x 的多项式的乘积。
例如考虑  。如果我们选择
。如果我们选择  ,我们会得到
,我们会得到  (正如刚才所示),积分就变成了一个可以完成的积分。
(正如刚才所示),积分就变成了一个可以完成的积分。
您可以积分 x 的任何多项式,正如我们所看到的那样。您还可以通过将其转换为不同参数的正弦和余弦的 和,使用它们的复数指数形式的表达式,积分任何正弦和余弦的多项式。
例如考虑 (sin x)²。我们可以写成

对于任意数量的正弦和余弦的任意乘积,可以做类似的简化。这样的任何乘积都可以写成它们参数的和与差的正弦和余弦的 和,以这种方式。
这意味着您可以通过应用迄今为止描述的方法来积分 x 的幂、积分或其他函数。
我们已经看到,我们可以积分 x 的任意幂,不管是否可积分。
偏分式的方法提供了一种将任意关于 x 的有理函数,换句话说,任意两个多项式的比值,写成多项式加上(x - r[j])的倒数之和的方法,其中分母多项式能够被分解为线性因子,而 r[j]是该多项式的根。
例如,假设我们的有理函数是  。
。
此函数具有以下明显的特性:
1. 当 x 非常大时,它的行为类似于  ,这是 2。
,这是 2。
2. 当 x 非常接近 1 时,它的行为类似于  。
。
3. 当 x 非常接近 2 时,它的行为类似于  。
。
4. 当 x 为 0 时,其值为  。
。
一般而言,这样的函数可以写成一个多项式加上在每个根处的最奇异项的可微函数之和。每个后一项在 x 趋于无穷大时必须趋于零。
这里意味着我们的函数可以写成

我们上面的性质告诉我们立即 p(x) = 2, a(x) = 4, b(x) = 19 + b(x - 2),以及  ,这意味着 b = 6,并且我们可以将我们的有理函数写成
,这意味着 b = 6,并且我们可以将我们的有理函数写成
2 + 4(x-1)^(-1) + 19(x-2)^(-2) + 6(x-2)^(-1)
一般来说,您可以通过将主导奇异项从分母中提取出来,并在该处评估其余表达式,从而在每个奇异点处读取该主导奇异项的系数。这里的每一项都可以轻松地积分。
如果奇异点处的奇异项的次数大于 1,如上例中的 x = 2,您可以通过以下三种方式之一找到非主导项的系数,无论哪种方式您觉得更容易或更合适。
1. 你可以将主导奇异因子提取出来,并计算其余部分关于奇异点的泰勒级数。相关项是那些与主导奇异项相乘仍然奇异的项。
2. 您可以从原始表达式中读取的系数减去主导奇异项;差异将在相同点具有较弱的奇异性,您可以再次通过直接检查读取其领先项的系数,如有必要,重复该过程。
3. 您可以评估有理函数在任意数量的新点上,以确定未知系数。这是确定上述 b 的方法,评估在 0 处。
多项式项是那些当 x 趋于无穷大时不会趋于零的项。领先的项可以通过直接检查找到。其他项可以通过多项式除法或使用上述第三种方法评估多项式系数来确定。
如果分母有具有复根的项,这些项可以与实根一样处理。
将可积函数的范围扩展到正弦和余弦的有理函数,使用代换 。通过这种替换,我们得到
。通过这种替换,我们得到

所以任何正弦和余弦的有理函数都变成了 u 的有理函数,因此可以通过部分分式积分。
还有一类标准可积函数。这些函数在其中有一个二次函数的平方根。二次函数可以通过完成平方形式(x - a)² + b²或(x - a)² - b²或 b² - (x - a)²减少,这可以通过变量的变化转换为 u² + 1, u² - 1 和 1 - u²,这可以通过涉及 tan x、sec x 和 sin x 的代换来处理。
完成平方包括重写二次函数
ax² + bx + c
如

27.2 一些特殊技巧
有些函数一般情况下是不可积的,但是对于某些特定端点之间的积分可以进行求值。
这些通常是可以重写的积分,可以通过添加已知积分,使用对称性,或者通过其他一些技巧,作为复平面中封闭路径上的积分重新编写。
这样的积分可以通过使用残差定理来计算,残差定理规定了沿简单闭合路径 C 逆时针围绕函数 f(z)的积分是 2 i 乘以 C 内的 f 的残差之和。
i 乘以 C 内的 f 的残差之和。
具有孤立奇点的函数的残留是其奇点处的倒数第一次幂的系数。
因此例如, 在 z = 0 处的残留为 2。
在 z = 0 处的残留为 2。 在的偶数倍处的残留为 1,而在的奇数倍处的残留为-1。
在的偶数倍处的残留为 1,而在的奇数倍处的残留为-1。
我们知道函数 是 arctangent 的导数,因此我们实际上可以在任何范围内对其进行积分。特别是由于我们有
是 arctangent 的导数,因此我们实际上可以在任何范围内对其进行积分。特别是由于我们有
这是另一种推断这一事实的方法。我们可以使用部分分式将其写为

因此,这个函数在上半平面的 i 处有一个奇点,在下半平面的-i 处有一个奇点,其残留分别为 。如果我们沿着实轴从-R 到 R 再绕一个上半平面的半圆从 R 回到-R,对于 R > 1,这将围绕 i 的奇点。
。如果我们沿着实轴从-R 到 R 再绕一个上半平面的半圆从 R 回到-R,对于 R > 1,这将围绕 i 的奇点。
因此积分的值将为 ,根据残差定理。
,根据残差定理。
在大半圆上,被积函数的行为将类似于 ,而由于该半圆的长度仅为R,所以围绕它的积分将随着 R 的增加而像
,而由于该半圆的长度仅为R,所以围绕它的积分将随着 R 的增加而像 一样趋于零。
一样趋于零。
这告诉我们,实轴上从-R 到 R 的积分值将随着 R 的增加而趋于。
这给我们一个我们知道的积分。
然而,相同的技术也适用于更复杂的被积函数,并且允许我们再次从-R 到 R 做许多积分,当 R 趋于无穷时。
我们给出两个例子。
其中一个是所谓的 的傅立叶变换
的傅立叶变换

其中 C 是上半平面中半径为 R 的半圆,同样,随着 R 的增加,C 上的积分也趋于零。
现在我们使用这种方法来求和一个级数。cot x 函数在 x = 0 处奇异,并且具有周期性,周期为,因此它在的每个倍数处都是奇异的。它在每个这些奇异点处的残余为 1。
此外,如果你远离实轴,它会迅速接近 i 或-i,因为它是

分子和分母中的第二项将在上半平面中占主导地位,使被积函数接近于-i,而第一项将在下半平面中占主导地位,使其在那里随着|y|的增加接近于 i。
这意味着对于半径为 R(R 为半整数倍的以避免在实轴附近出现问题)的大圆上的 积分将随着 R 趋于无穷而趋于零,就像前一种情况一样。
积分将随着 R 趋于无穷而趋于零,就像前一种情况一样。
这进一步意味着该函数的残余之和必须在这个圆内趋于零。但对于每个正整数或负整数 j,该函数在 处的残余。
处的残余。
在 z = 0 处,这个被积函数的残余可以计算为 z cot z 在 z = 0 处的二阶导数的一半。(我们将这里的奇异项因子化,然后将被积函数的其余部分展开为泰勒级数,以获得 z^(-1)系数。)
由于 sin z 按 增长���可以写成
增长���可以写成
因此, 在 z = 0 处的残余因此为
在 z = 0 处的残余因此为 ,我们得出结论
,我们得出结论

或

你实际上可以在电子表格上对这个求和的前 128(或 1024)项进行求和,并通过比较不同幂次的求和来外推。如果首先形成 S2 = S(2k)-S(2(k-1)),那么 S3 = (4S2-S2)/3,然后 S4 = (8S3-S3)/7,等等。你可以通过数值方法得到这个答案的极高精度,并验证这个结论。
27.3 实例练习
现在我们为您列出了一些积分,请仔细查看它们,并尝试确定如何攻击每一个。一旦你对如何做它们有了想法,你就应该做一些相应的练习。只有做了十几个积分,并陷入了所有标准陷阱,然后你才会知道要避免什么。
这里有一些提示,直到你自己犯了这些错误才可能有所帮助。
最常见的错误是在变量改变时忘记了一个小因子,以及将 dx 与某些 du 关联起来。
在复制一行到下一行时丢失一个小因子也很常见,以及漏掉一个符号。
忘记你正在进行积分,并写出一个常见函数的导数而不是你需要通过观察来进行积分的积分,这种情况也很常见。
在更改变量时没有调整积分限是另一个常见的错误。
忽视被积函数的奇点,并没有注意到你已经积分过一个奇点,这种情况较少见,只是因为你很少遇到这个问题。
在没有任何 f' 因子存在的情况下,粗心地集成  。
。
练习:描述您将如何评估以下每个积分。然后做五个。
1. 
2. 
3. 
4. 
5. 
6. 
7. 
8. 
9. 
10. 
11. 
12. 
13. 
14. 
15. 
16. 
17. 
18. 
第二十八章:电场和磁场介绍
引言
我们简要概述了电场和磁场的历史和基本事实,描述了密度、局部守恒、δ函数和静电势的概念。
主题
28.1 电学和磁学:历史回顾和基本事实
28.2 密度和守恒定律
28.3 点粒子和δ函数
28.4 静电学和电势
28.1 电学和磁学:历史回顾和基本事实
电学和磁学力的系统研究始于十八世纪末。通过用一种物质擦拭另一种物质产生带电物体。观察到了两种电荷,相同电荷相互排斥,而异种电荷相互吸引。
本杰明·富兰克林用带电芦苇球进行了实验,这促使普里斯特利和卡文迪许试图证明电力是一种与重力力量完全相反的力。库仑通过他的实验证明了两个不同电荷之间的力确实是它们距离的平方的倒数,且沿着连接它们的线。吸引力的形式与质量之间的引力完全相同。
在某个阶段,有人提出了通过电场概念描述电力的想法。这被定义为给定电荷分布时小虚构带电物体所经历的单位电荷力。
球的表面积与其半径的平方成正比,而点电荷的电场与相同量的半径的平方成反比。因此,对球面周围电场的法向分量的积分与球的半径无关,只测量其中心电荷的强度。
我们称矢量W的法向分量在任意表面上的积分为“W通过该表面的通量”。上述说明可以表述为:通过包含中心电荷的球面的电场通量仅与电荷量成正比,并且是该电荷量的常数倍。
高斯通过发现的散度定理将这个声明推广到包含电荷的任何区域的表面。该定理暗示了通过空间任何区域的边界的电场通量是适当常数乘以该区域的电荷量。
在 19 世纪末,伏打发明了电池,人们可以实际产生电流。厄斯特德和安培在约 1820 年发现,电流会产生力,使磁化的指针朝向围绕导线的圆周切线方向排列。特别是,安培发现,长直导线上的磁力对这样的指针产生的电流流量成正比,与指针距离导线的距离成反比。
一个圆的周长与其半径成比例,刚刚描述的磁场与半径成反比。因此,沿着围绕导线的任意圆周的磁场分量在路径方向上的积分与其半径无关。它是一个适当的常数乘以通过导线的任何这样圆周的电流“通量”或流量。
我们定义矢量场 W 在路径方向上围绕封闭路径的分量的积分为W 围绕该路径的环流。 安培定律可以表述为:磁场围绕导线的环流是通过它的电流通量的一个常数倍。
法拉第得到这样一个想法,即如果电流通量导致磁场环流,那么应该有某种互惠性:磁通量应该能够导致电流环流。1831 年,在寻找这种效应之后,他发现了他著名的感应定律:通过表面 S 的变化磁通量会在其边界上产生电场环流。 这意味着它在 S 的边界路径周围产生“电势差”,这意味着绕着它的导线中的带电粒子将在绕着导线移动时受到作用。这将使电流在表面周围的导线中流动,而该电流是通过(任何)被导线限定的表面的磁通量的导数的常数倍。
通过增加和减少一根导线中的电流量,你可以使其磁力振荡,这将导致另一根导线中的电流来回流动。
世纪中叶,斯托克斯发现了他的数学定理,将矢量场W在表面 S 上的环流与W在 S 的边界周围的环流相关联。
麦克斯韦利用这一事实证明,电磁学方程的一致性要求在存在变化的电场时修改安培定律。
通过这一修改,他指出(大约在 1862 年)即使在没有物质的情况下,电场和磁场也可以显示出波动行为,并且他断言光现象正是由这种波构成的。他的说法预测了光速,这只是最近才被测量的,而且与该测量完全一致。
他于 1874 年发表了描述电磁场行为的著名微分方程。麦克斯韦的发现之所以与众不同,是因为完全是理论性的。他利用了斯托克斯定理的数学含义,而不是实验来发现他的"位移电流",其存在使他能够将光与电磁学联系起来。
麦克斯韦发现背后的思想是:根据斯托克斯定理,矢量场W的旋度通量通过一个表面是其在表面边界周围的环流。根据这个定理,任何矢量场的旋度通量通过具有相同边界的任意两个表面必须相同。
法拉第的发现使人们能够通过将磁铁靠近导线移动或(等效地)将导线靠近磁铁(如戴维斯和基德尔于 1854 年获得专利的治疗设备中)产生振荡的电流。
从一个导线中的电流变化中感应出另一个导线中的电流,假设第一个导线中的变化电流产生了变化的磁场,根据法拉第定律,这个磁场产生了第二个导线中的电流。
现在假设第二根导线中有一个间隙。电流将流过它,直到间隙两侧的电荷积累,并且这个电流将产生自己的磁场。如果两根导线中的电流被制成振荡,即随时间正弦函数地来回流动,尽管有间隙,电流将大部分时间流动,如果正弦波的频率足够大,那么在任何时候间隙处的电荷积累将很少,并且在导线中电流流动时的"阻抗"也很小。
根据安培定律(应用于非稳态电流情况),在这种情况下,导线周围将有振荡的"磁环流",来自导线中电流的振荡流动。但是,如果我们取一个穿过导线的表面,并将其变形使其通过间隙而不是导线,那么它将没有电流通过!然后,根据安培定律,同一路径上将没有磁环流,与先前的说法相矛盾。
围绕具有间隙的导线的圆圈可以通过穿过导线的表面填满,或者通过扭曲该表面保持其边界不变,使其只穿过间隙。旋度通量的积分对于这两个表面必须是相同的。因此,在间隙中必须有某种东西,像电流一样,对磁场的旋度通量有贡献。
麦克斯韦得出结论,在这种情况下,电流通量不可能是磁场旋度通量!安培定律描述了稳态电流流动充分,但在电流流动是时间相关时必须进行修改!
在给定边界的情况下,通过线圈或间隙使我们的表面通过时,电流通量将不同。磁场的旋度通量在两者中必须相同。如果磁场的旋度通量是通过线圈的电流通量,则在间隙中必须是其他东西,而该其他东西的通量必须相同。
我们在间隙中唯一知道的是它包含由其表面上的电荷振荡引起的变化的电场。麦克斯韦假设一致性要求在安培定律中有一个额外的时间相关项,与这个电场的时间导数的通量成比例。
这个术语,他称之为“位移电流”,在结果方程中产生了显著的对称性。当写成微分方程时,高斯定律、安培定律与麦克斯韦的修改以及法拉第定律表明,在没有物质存在时,电场和磁场遵循“波动方程”,并暗示着可以存在电场和磁场的波动,这些波动以有限的速度传播。
麦克斯韦断言光是这种波动形式暗示着可以从电磁现象中推导出特定的有限光速。他方程的对称性不仅包括在普通空间中的旋转,还包括将空间与时间混合的变换,称为洛伦兹变换。
1888 年,赫兹在实验室里实际上创造了电磁波并检测到了它们。他连接了一根线圈和一个小间隙,通过线圈通电直到电容器上的电场产生火花;产生的电流振荡产生了可在另一个类似电路上观察到的波。
马尔康尼从中得到这样的观念,即这种波可以通过导致远处的导线流动来用于通信。在 19 世纪 90 年代,他建立了设备,以便将信号传输到不断扩大的距离,并且到了 1901 年,能够将电报信号传输到大西洋的对岸,这些信号可以被接收并用于无线通信。
这些主题涉及的物理定律数量不多,可以用几行话来陈述。我们现在将考虑它们在向量微积分概念中的数学含义。
28.2 密度与守恒定律
我们经常通过描述质量或电荷的分布来描述其中任何一个在包含点 P 的小体积 dV 中的量。因此,质量密度有时被表示为 ,用
,用 表示包含在该体积中的质量,而电荷密度的定义与之完全相同,其中
表示包含在该体积中的质量,而电荷密度的定义与之完全相同,其中 表示电荷密度,
表示电荷密度, 表示体积 dV 中的电荷量。
表示体积 dV 中的电荷量。
如果质量或电荷恰好以速度v(P)移动,我们根据 定义电流j(P)。这个电流通过任何表面 S 的通量代表单位时间内通过该表面流动的电荷或质量的量。
定义电流j(P)。这个电流通过任何表面 S 的通量代表单位时间内通过该表面流动的电荷或质量的量。
通过表面 S 的质量或电荷单位时间流量是,具有适当电流矢量

这个事实使我们能够通过方程描述这些量的局部守恒。这个守恒意味着在给定体积中电荷或物质的数量变化的唯一方式是通过体积边界的流动。如果流入流量是向内的,它将增加,如果净流量是向外的,它将减少。这告诉我们密度在任何体积 V 上的积分的导数将是其表面上电流的外流通量的负值, V
V

回想一下,散度定理告诉我们,对于任何矢量场W(P),我们有

将这个定理应用于守恒方程中的矢量场j,并选择 V 为固定体积,使得时间导数仅影响被积函数,并利用导数和积分的线性性质将导数移到积分内部,我们得到

并且这个关系对所有体积 V 都成立。
在物理学中,我们从这个陈述中得出结论,即在定义的任何地方,被积函数都为零,这给我们带来了守恒定律的微分形式

这个方程的内容当然与原始定律的内容完全相同:体积中质量或电荷的变化量是流入 V 的量减去流出 V 的量。
28.3 点粒子和δ函数
库仑定律告诉我们关于点电荷的电场。这引出了一个问题:位于点 P 处的点电荷的电荷密度是多少?
这个问题可以用对体积的积分来回答:如果你在不包含 P 的体积上对这个密度进行积分,你会得到 0。如果体积包含 P,你会得到位于那里的电荷量。
这基本上意味着密度除了在点 P 处为 0 之外都为 0。但是在该点的贡献必须足够大,以便对积分产生显著的贡献。
这对于有界函数或者根据我们对积分的定义的任何函数都是不可能的。
然而,我们实际上并不知道点粒子是什么样的,也没有办法在实验上区分点粒子和半径在 10^(-100)厘米数量级的具有扩展形状的粒子。
我们对密度进行的积分以获得体积 V 中的总质量或电荷是一个体积积分,当用普通一维积分表示时,需要三个一维积分。
与点粒子的密度类似的现象在一维中发生,称为“delta 函数”。点粒子的密度实际上可以描述为变量 x、y 和 z 的 delta 函数的乘积。因此,我们将讨论一维情况。
在进一步讨论之前,我们先回答一个问题:为什么我们关心这些问题?为什么现在?
答案在这里:库仑定律描述了伴随点粒子的电场。我们可以利用这一事实来确定由电荷密度  表征的任何电荷分布产生的电场。我们只需将每个产生该电荷密度的带电粒子对电场的贡献相加即可。
表征的任何电荷分布产生的电场。我们只需将每个产生该电荷密度的带电粒子对电场的贡献相加即可。
我们很快会看到,通过这样做,我们实际上正在解一个带有非齐次项的线性微分方程 。
我们在这里犯了一个错误,用于解决这个方程的方法可以描述如下:我们首先找到了对于任意点 P(这里是库仑定律与 P 无关)的 delta 函数非齐次项的解。然后我们利用这个解(通过积分),找到了一般非齐次项的解。
我们找到的解遵守带有适当零边界条件的微分方程。通常称为给定微分方程和边界条件的格林函数,因为格林发明了这种方法。(顺便说一句,格林是一个面包师,对数学和科学有浓厚兴趣。他是自学科学和数学的。)找到它可以通过积分解决具有任意非齐次项的相同方程。
这里是另一种看待相同想法的方式:您想找到给定物理系统对任意外部刺激的响应,其对刺激的总和的响应等于对每个刺激的响应的总和。为此,您找到每个可能点的单点刺激的响应。然后,通过(求和)将该刺激与响应函数的乘积积分,您可以找到对任意刺激的响应。
这种非常强大的方法用于解决一般非齐次线性微分方程,通过首先解决带有 delta 函数非齐次性的方程,这意味着我们想要使用 delta 函数。
我们想在这里使用它们来将库仑定律推广到确定任意电荷分布的电场。
一维 delta 函数可以描述为阶跃函数的导数,因此我们首先定义阶跃函数。
通常使用两种标准阶跃函数。
第一个函数,表示为  ,对于负的 x 值为 0,对于正的 x 值为 1。我们不太在乎它在 x = 0 处的值是多少,但它可能是 0、
,对于负的 x 值为 0,对于正的 x 值为 1。我们不太在乎它在 x = 0 处的值是多少,但它可能是 0、 或 1。
或 1。
第二个函数,通常写作  ,对于正的 x 值为 1,对于负的 x 值为 -1,在 0 处为 0。
,对于正的 x 值为 1,对于负的 x 值为 -1,在 0 处为 0。
这些函数之间存在关系  ,除了在 x = 0 处可能有所不同。
,除了在 x = 0 处可能有所不同。
显然,按照定义,这两个函数在 x = 0 处都没有导数。
但是,这两个函数与到处都有导数的简单函数之间的差异很小。实际上,没有真正的方法来区分这两者之间的区别。
因此,我们可以在假装使用这些其他函数的导数时使用 delta 函数。
数学家们最初对 delta 函数非常怀疑。然而,他们现在接受它作为所谓的“分布”,而不是函数。
一个在实际上与 几乎无法区分的函数是  。正切函数在负值很大时接近
。正切函数在负值很大时接近  ,在正值很大时接近
,在正值很大时接近  。其参数中的因子
。其参数中的因子  加速了其行为,使其基本上成为一个阶跃函数。其从 -1 到 1 的导数是完全定义良好的,基本上是
加速了其行为,使其基本上成为一个阶跃函数。其从 -1 到 1 的导数是完全定义良好的,基本上是  。
。
第二个函数,除了一个常数外,被称为误差函数。它的导数是  ,对于非常大的 k 具有近似的性质
,对于非常大的 k 具有近似的性质  。这个函数和正切函数的导数对于极小的参数都很大,否则几乎为零。
。这个函数和正切函数的导数对于极小的参数都很大,否则几乎为零。
以指数和误差函数定义的函数在远离零点时要比在靠近零点时变化小得多,这比正切函数要好一点。
Delta 函数的好处是除了 0 之外的参数都为零,在包含 0 的区间上的积分为 1,这些性质与这些函数在不可观测参数处几乎相同。
作为一个函数,delta 函数在参数 0 处没有太多意义,除非对其进行积分;它的积分是一个阶跃函数,这是完全定义良好的。
当你在积分之外看到一个 delta 函数时,你可以将其视为上述两个函数之一,不必为此失眠。
点粒子的密度可以描述为三个变量 x、y 和 z 中的 delta 函数的乘积。它可以写成 
28.4 静电学和电势
正如我们现在已经多次注意到的那样,库仑定律规定,相同的电荷相互排斥,而不同的电荷则以反比例平方力的方式相互吸引。当吸引时,这种力与重力非常相似,但作用于带电粒子之间,与它们的质量成比例,而不是它们的质量。以下陈述都涉及静电场:由不随时间变化的电荷密度产生的场;而不是由变化的电荷密度产生的电场。
现在这里是这个定律的一些数学含义:
1. 我们可以用以下公式��示 P 点处带电粒子的电场。 (这就是库仑定律。)

2. 该场的散度为 0,除非 P - P' = 0。 (通过微分。)
3. 围绕 P'的球体上的该场的通量为 4 e。 (通过积分。)
e。 (通过积分。)
4. 包含 P'的任意体积的边界上的该场的通量为 4e,而在任何其他体积上为 0。 (根据散度定理。)
5. 一组电荷的场是每个电荷的场的总和。 (物理事实。)
6. 包含点电荷的任何体积上的点电荷密度的积分为 e,如果该体积不包含电荷,则为 0。 (密度的定义。)
7. 一组电荷的密度是它们密度的总和。
8. 对于 P'处的点电荷,E在 V 的边界周围的通量为 4倍于其电荷密度在 V 上的积分。 (通过 4、5、6、7。)
9. 对于 在 V 上的积分为 0。 (通过散度定理。)
在 V 上的积分为 0。 (通过散度定理。)
10. E的旋度为 0,除了在 P = P'处的点电荷。 (E指向外部,并且仅依赖于外部方向的距离=通过微分。)
11. 点电荷的电场E沿任意封闭路径的环流为 0。 (通过斯托克斯定理和 10。)
12. 对于任何电荷排列都成立。
13. 对于任何电荷分布,E(P)可以写为- V,其中 V(P)是“电势函数”。 (将 V 定义为从某一点到 P 的-E的线积分。这由 11 唯一定义。)
V,其中 V(P)是“电势函数”。 (将 V 定义为从某一点到 P 的-E的线积分。这由 11 唯一定义。)
14. V(P)满足方程

15. P'处点电荷的电势 为
为 ,并且它满足方程
,并且它满足方程

(检查 是否是 P'处点电荷的电场。)
是否是 P'处点电荷的电场。)
16. 在自由空间中(忽略其中的任何物质)由电荷密度 确定的电势由以下公式给出
确定的电势由以下公式给出
 (通过使用 15 进行积分。)
(通过使用 15 进行积分。)
17. 导体是一种电荷可以自由移动的材料。在静态情况下,导体上的电势必须是恒定的。
18. 平面导体的作用类似镜子,因此受平面导体限制的电荷密度 的电势为

点 P' 在平面中的反射点为 P"。
练习:
28.1 逐条审视上述每个陈述。仔细证明它以满足自己。向某些受害者解释它。
28.2 假设你有一个电荷分布  并且它在两侧被直角平面导体所限制。它会产生什么电势函数?(提示:尝试用两个镜子。)
并且它在两侧被直角平面导体所限制。它会产生什么电势函数?(提示:尝试用两个镜子。)
28.3 假设你的分布被三个垂直平面的导体所限制。你会发现什么电势函数?
总结:
固定电荷分布的静电场  符合以下方程
符合以下方程

它可以写成一个标量场的梯度,-V,称为电势,因此它符合以下方程

点 P 处的点电荷在 P' 处的电势为

第二十九章:磁场、磁感应和电动力学
引言
我们简要概述了在没有物质的情况下磁性、磁感应和电动力学的基本定律、波动方程、标量和矢量势以及不变性质。
主题
29.1 安培定律及其后果
29.2 法拉第定律及其后果
29.3 麦克斯韦一致方程
29.4 波动方程
29.5 电势
29.6 不变性质
29.1 安培定律及其后果
根据安培定律,电流通过直导线的通量会在导线周围的圆路径上产生磁场B的“循环”。
用符号表示,我们得到

如果我们将这个陈述推广到任何表面,并与斯托克斯定理应用于向量B相结合

我们得到

对于任何表面 S。
物理学家得出结论,即被积函数在任何地方都必须几乎为 0,并声称下面的微分定律在稳恒电流磁场的任何地方都成立。

我们已经看到,当没有稳定电流时,仍然会有电荷守恒,正如我们所看到的,它遵循方程

将上述方程两边求散度,我们看到当 ,即电荷密度,是时间依赖时,它是不可能成立的。我们得到
,即电荷密度,是时间依赖时,它是不可能成立的。我们得到

如果这是真的,就意味着电荷密度永远不会改变。
29.2 法拉第定律及其后果
法拉第发现,就像电流通量引起了磁场环流一样,磁通量也引起了电流环流,但效果与磁通量的导数成正比,而不是与其时间导数成正比。
因此,他找到了以下积分关系(称为法拉第电磁感应定律)

用言语表述:通过表面的磁场通量的导数与其边界周围的电动势成比例(即绕其周围的电场的循环积分)。
这种效应的一个结果是你可以以这样的方式旋转磁铁,使电流在导线中流动,甚至更多,在一卷导线中流动。这是实现电力发电的手段。
应该注意到,在这些发现的时候,向量微积分的符号和概念实际上并不存在,对我们来说似乎是显而易见的结论,鉴于斯托克斯定理和矢量的旋度的概念,在大部分 19 世纪都非常晦涩难懂。
如果我们将斯托克斯定理应用于这里的电场E,我们可以用电场E的旋度的通量的负 c 乘以右侧代替。如果我们固定一个表面 S,导数可以带入积分内部,我们得到了对于任意固定表面 S

如果我们作出这样的物理假设,即当它在任何方向的分量上被积分时为 0 时,某个量总是 0,那么我们就得到了微分方程

而这可以被认为只是法拉第定律的一个重新表述。
这个定律并不直接暗示没有磁性电荷,它们像正电荷一样为磁场提供“源”,而负电荷则为电场提供“汇”。电荷密度与电场的散度成正比。
如果我们对上述最后一个方程的左侧进行散度运算,我们会发现磁场B的时间导数的散度必须为 0。这意味着,如果B有散度,那么在任何时间都必须完全相同;除非这个方程中出现了磁场电流密度。至今尚未发现磁场源,因此据我们所知,我们有
法拉第还引入了“力线”的概念。电场表示对一个小“测试”电荷的力。他建议将无穷小的场线连接起来,形成他给出这个名称的路径。
对于磁场,点处磁场的方向表示了一个指南针放置在该点时的指向,或者如果将铁屑放置在该点时,铁屑排列的方向。
他发现磁场线没有源头或汇流,而是形成闭合环路。另一方面,电场线起源于正电荷的位置,这些正电荷是其“源”,并在负电荷处结束,称为“汇”。
换句话说,他发现这些或任何其他矢量场的源代表着场的散度为正的地方,而汇则是场的散度为负的地方。
如果你对静电场的行为有一些了解,这给了我们也许是发展直观概念的最佳方式,即一个矢量场的散度是什么。想象一下你的场代表一个电场;它的散度对应于产生这样一个场的电荷密度。
29.3 麦克斯韦的一致方程
正如我们已经注意到的,安培定律在存在时间相关电流时必须进行修改,因为否则我们将会有

当(例如交流)电流通过具有间隙的电路时发生的情况,麦克斯韦意识到,如果电路中存在这样的东西,那么一致性要求在间隙中有某种东西对B的旋度有贡献。
但是这个间隙在第一近似中是空的空间;唯一存在于其中的是由电荷密度产生的电场E。
请回忆在静电学中我们有关系式 。
。
我们可以看到,一种一致的改变安培定律以考虑可变电流的方法是在其左边加上一个项 ,得到
,得到

练习 29.1 对这里的两边进行散度运算,以验证此方程是否与电荷守恒一致。
我们可以将电场和磁场满足的所有微分方程整理成以下列表。尽管这些方程远比 1874 年他发表的那些简单,它们被称为“麦克斯韦方程”。那时的方程与现在的差不多,但变量有 20 个,方程也有 20 个。

当前这些方程的形式是由赫维赛德得到的,他引入了矢量符号、散度和旋度。
从 1831 年法拉第法到 1874 年麦克斯韦方程之间,在这一领域取得进展缓慢的原因之一是人们很难描述多维现象,并且很难理解他们所写的方程,没有矢量符号的帮助。
我们在这里忽略了物质对电场和磁场的影响,除了提供电流和电荷。
实际上,物质由带有正负符号的电荷粒子和磁偶极(如小磁铁)组成,这些受到电场和磁场的影响。
电场使导体中的电荷移动,并极化非导体。通过吸引一种符号的电荷并排斥另一种电荷,它们使非导体表现得像它们充满了电偶极。
因此,非导体通过极化产生的场影响内部场的效果,物理学家通过定义两种电场D和E以及两种磁场B和H来描述这些现象,其中一种是由实际电荷分布产生的场,另一种是包括物质中极化效应的场。你将在物理课程中学习这些内容。
29.4 波动方程
现在我们考虑麦克斯韦方程告诉我们关于电场和磁场在空间中的行为,其中没有电荷或电流。 在这些情况下,方程变为

如果我们对第一个方程取时间导数并对第二个方程取旋度,我们会得到

我们可以利用矢量恒等式  和麦克斯韦方程
和麦克斯韦方程  将此方程变为
将此方程变为

或者

练习 29.2 对相同的方程进行相同的操作,对第一个方程取旋度,对第二个方程取时间导数,以在没有电荷或物质的情况下得到以下结果
.
这个方程,空间中的 B 和 E 都遵守,在空间中称为波动方程。它是一个偏微分方程,看起来相当可怕,但很容易找到解决方案。如果你选择空间中的任意方向,并称其为 x 方向,那么任何关于变量 x - ct 的矢量函数(以及关于 x + ct 的任何函数)都将遵守它。
练习 29.3 通过微分和链式法则验证此断言。
这些形式的解以速度 c 在空间中向前或向后的 x 方向“移动”。它们被称为平面波,因为它们在垂直于 x 方向的平面上是恒定的。麦克斯韦想到了光可能由这样的波组成。在他的方程中出现的常数 c 可以从电磁实验中测量出来,在麦克斯韦提出这个概念时,光速已经被测量出来,并且在实验误差范围内它们是相同的。
29.5 势
没有旋度的矢量场可以写成势函数的梯度。因此,我们可以将静电场描述为这样的梯度。
当我们这样做时,我们发现可以将在空间中的电荷分布产生的势解释为积分,乘以在积分点处由单位电荷产生的势。
像 B 一样具有消失散度的矢量场,可以以类似的方式写成矢量势的旋度。
我们定义矢量势 A,使得 
使用这个定义, 可以是任何东西而不改变任何东西。
可以是任何东西而不改变任何东西。
在静态电流的情况下,即没有时间依赖性时,我们设定  并推导出以下方程
并推导出以下方程

我们可以在整个空间内解决这个方程,边界条件是A在无穷远处趋于0,就像我们解决 V 一样。结果,与上一章节中 V 的结果完全相同。

在时变情况下,我们通过以下方式定义矢量势A:

这些定义并不能完全确定A和 V。
给定任意标量场 f,我们可以将 加到 V 上,B和E都不会改变。这种变化被称为“规范变换”,而B和E的这些表达式被称为“规范不变”,因为它们不受规范变换的影响。
加到 V 上,B和E都不会改变。这种变化被称为“规范变换”,而B和E的这些表达式被称为“规范不变”,因为它们不受规范变换的影响。
练习 29.4 找出由麦克斯韦方程(包括源 和 j)隐含的 A 和 V 满足的方程。
和 j)隐含的 A 和 V 满足的方程。
29.6 不变性质
麦克斯韦方程具有这样的性质,它们在空间旋转和一种可以被视为在闵可夫斯基空间中旋转的特殊变换下保持不变。这被称为洛伦兹变换。
在 19 世纪末,物理学家逐渐意识到这种不变性意味着对于运动坐标系的变换形式与力学中通常使用的形式不同。
众所周知,声音是空气或其他介质的运动组成。在真空中是没有声音的。物理学家长期以来一直在思考是否存在类似于光的介质。
他们假设了一种“以太”,它是光的介质,就像空气中的粒子形成声音的介质一样。如果存在这样的介质,了解我们相对于它的运动程度将是很有趣的。
米歇尔逊和后来的米歇尔逊和莫雷在 19 世纪 80 年代尝试通过测量不同方向上的光速来测量我们相对于“以太”的速度。他们发现,即使光源相对于观察者运动,光速在所有方向上都是相同的。
爱因斯坦在 1905 年解释了这一观察结果,基于这样的断言:自然法则,包括具有相同光速的麦克斯韦方程,无论你是否在运动,对你来说都是相同的。
费兹杰拉德和洛伦兹已经展示了如何修改普通力学方程以使它们具有与麦克斯韦方程相同的不变性质。
我们还没有讨论与电场和磁场相关的能量,也没有考虑它们对物质的影响。
即使没有这样的讨论,从麦克斯韦方程的结构中,可以很清楚地看出,电子绕着原子稳定轨道运动,就像行星绕太阳运动的概念与之不一致。
如果它们这样做了,作为带电粒子,它们会产生电磁波,这些波将带走能量。如果能量守恒,轨道就无法稳定,除非电子具有独立于时间的电荷密度。
用允许电子具有时间独立电荷分布的表述取代经典力学是 20 世纪早期物理学的主要胜利之一。
要理解这些事情,最好学一些物理学。
第三十章:级数
引言
无限级数是有用的数学工具。我们讨论它们的收敛性,幂级数的性质,以及确定它们和的方法。
主题
30.1 引言
30.2 交替序列收敛的条件
30.3 绝对收敛的条件
30.4 幂级数和收敛半径
30.5 操作绝对收敛级数
30.6 计算级数的部分和
30.7 幂级数系数的表达式
30.8 傅立叶级数
30.1 引言
无限级数是一系列项的无限和。以下是一些例子:
谐波级数

几何级数

交替谐波级数

指数级数

我们可以将任何级数与一个序列相关联,称为该级数的部分和序列。级数的第 j 个部分和被定义为其前 j 个项的和。
因此,给定级数
a[1] + a[2] +...+ a[n] +...
我们通过以下方式定义 s[j]

如果一个序列收敛到值 A,那么对于任何正标准 c,存在一个 n,使得序列中第 n 个之后的所有项都在以 A 为中心、半径为 c 的区域内。
如果一个级数的部分和序列收敛到 A,那么该级数被认为收敛到 A,A 被称为其极限。
我们区分级数的两种收敛方式。如果级数的绝对值序列,|a[j]|收敛,则称级数为绝对收敛。一个同时具有正负项的级数可以收敛,尽管它不是绝对收敛的。
例如,谐波级数根本不收敛,因此交替谐波序列不是绝对收敛的。然而,交替级数确实收敛。当|x| < 1 时,几何级数绝对收敛。当 x = 1 时,它发散,当 x = -1 时,它不收敛,但实际上在某种意义上是“可求和的”,我们将看到。
一个绝对收敛的级数可以以许多方式进行操作而不改变其值。因此,你可以重新排列它的项,可以逐项积分或微分,基本上可以将其视为有限级数。
一个收敛但不绝对收敛的序列可以被赋予一个值,但你必须非常小心。你不能重新排列它的项;那可能会将其值改变为几乎任何东西。事实上,对它的任何操作都是可疑的。
发散的级数通常是非常有趣甚至有用的,尽管具有这种性质。这可以通过以下(至少)四种方式发生:
首先,即使级数不收敛,你可能也能通过可求和性的概念给这样的级数赋予一个值。如果其部分和序列收敛,则级数是收敛的。如果其前 k 个部分和的平均序列收敛,则称为 C1 可求和。因此,级数
1 - 1 +1 - 1 ...
有部分和
1, 0, 1, 0, 1, 0, ...
它们不收敛。然而,前 k 项的平均值形成序列

它收敛到 1/2,因此这个级数是 C[1]可求和的。
你可以进一步定义 C[2]和更一般的 C[k]可求和性:级数的部分和的平均序列定义了一个以它们为部分和的级数;如果这个级数是 C[1]可求和的,那么原始级数被称为 C[2]可求和。
练习:
30.1 找到一个 C[2]可求和但不是 C[1]可求和的级数。(提示:看看前 k 项的平均值为 1, 0, 1, 0, ...的级数)
30.2 给出 C[j]可求和性的一个合理定义。
其次,你可能会注意到级数的部分和 s[n]与某个函数 n 的差异(随着 n 的增加而趋向无穷大)收敛。因此,调和级数的第 n 个部分和与函数 ln(n)的差异逐渐趋近于一个常数  ,我们将在下面讨论。称为欧拉常数。
,我们将在下面讨论。称为欧拉常数。
第三,当你处理幂级数时,你可能能够通过称为“解析延拓”的一些过程之一赋予发散级数意义,我们也将讨论这个问题。
最后,我们有时会遇到幂级数,其项是隐式定义的,我们对系数值感兴趣,而这些系数值与任何实际序列的值无关。这样的实体称为形式幂级数,即使对于每个可能的非零参数它都发散,也可能会有用。
30.2 交替序列收敛的条件
一个项交替为正负的序列称为交替序列,如果满足两个简单条件,这样的序列将收敛:
1. 其项的绝对值递减:因此我们有  。
。
2. 这些项收敛于 0。
这两个条件中第二个是收敛的必要条件;第一个不是。
为什么这些条件足以收敛?
我们可以将连续的一对项从一开始或第一个项之后组合在一起。这些导致我们得到以下两个表达式
(a[1] + a[2]) + (a[3] + a[4]) + (a[5] + a[6]) + (a[7] + a[8]) + ...
和
a[1] + (a[2] + a[3]) + (a[4] + a[5]) + (a[6] + a[7]) + (a[8] + a[9]) + ...
请注意,由于级数项交替为正负,括号中的项是相邻项绝对值的差值,根据我们的第一个条件,它们都具有它们第一个项的符号。
例如,假设 a[1] 为正数。那么第一个表达式中的所有项都是正数,它的部分和将增加。另一方面,第二个表达式中第一项后的所有项都将是负数,它的部分和将减少。因此,我们级数的偶数部分和都在最终和之下,并且会增加,而奇数部分和会在最终和之上,并且会减少。
所以所有后续部分和必须在每个阶段都夹在任意两个相继和之间。
根据我们的第二个条件,连续部分和之间的差异(它们是级数本身的项)趋近于 0,这意味着部分和的值受限于逐渐接近 0 的区间,这意味着部分和在柯西意义上收敛(它们的差异趋近于 0)。
每个交替级数都遵循上述两个条件,第一项为正数,则奇数部分和递减,偶数部分和递增。这意味着对部分和的连续两两求平均比部分和本身更接近总和。
交替调和级数具有奇妙的性质,经过这样的平均后,结果的偶数和奇数平均仍在增加和减少,如果你平均这些的一对,然后平均你得到的一对,依此类推,这个性质被保留下来。这些事实可以用来极其精确地找到这个序列的值,只需查看它们的前几项。
你可以通过复制一条指令在电子表格上对连续项求平均,并根据前文所述的方式重复这样做。你会惊讶地发现,你可以从前 25 个项中确定其总和的精确程度,其中最小的项为 0.04。
练习 30.3 使用电子表格找到交替调和序列的前 40 个部分和。然后取连续对的和并重复 20 次。(这可以通过一条形如  的指令完成,复制到列 d、e、f、g 中,...)
的指令完成,复制到列 d、e、f、g 中,...)
你发现了什么?从这些数据中你能多精确地确定这个序列的总和?仅从前 20 个部分和可以吗?**
30.3 绝对收敛条件
表征级数其行为最能传达一般级数行为的是等比级数。 这是关于变量 x 的幂级数,其项是 x 的未修饰幂。
G = 1 + x + x² + ... + x^n + ...
它具有一个很好的特性,即如果你从中减去 1,然后除以 x,你会得到它本身。

这个级数具有绝对收敛性,当 |x| < 1 时,并且当 x 为 1 时具有奇点。它的公式在 x = 1 处无限,级数本身变为 1 + 1 + 1 + ...,显然发散。
确定给定级数是否绝对收敛的最一般方法称为比较测试:您将您的系列与另一个系列进行比较。如果另一个系列绝对收敛并且您的系列中的每个项的绝对值小于其中相应的项,则您的系列也将绝对收敛。
同样,如果另一个系列不是绝对收敛的,并且您的每个项的绝对值大于另一个系列中相应的项,则您的系列也将发散。
几何级数为这个测试提供了一个基本的比较序列。由于它在 x < 1 时收敛,我们可以得出结论,对于连续项的比率 始终至多为某个 x 值,其中 x < 1,将绝对收敛。
始终至多为某个 x 值,其中 x < 1,将绝对收敛。
此声明定义了绝对收敛的比值测试。
当连续项的比率始终大于 1 时,很明显该级数不会绝对收敛。从现在开始,让我们假设我们序列中的所有项都是正的。(这既不帮助也不妨碍绝对收敛。)有了这个假设,我们可以讨论普通收敛,实际上我们在谈论绝对收敛。
当连续项的比率随着 n 的增加接近 1 时,或者当它在 1 周围波动时,会出现有趣的问题。
调和级数提供了这样一个序列的良好例子。
由于其第 n 项是 ,连续项的比率是
,连续项的比率是 这对于收敛来说不够小,因为这个级数发散。
这对于收敛来说不够小,因为这个级数发散。
这里有一个看出它发散的简单方法。注意,在第一个项之后,还有一个更大的项(即第二个项),再加上两个更大的项,四个更大的项,八个更大的项,依此类推。通常,将部分序列的长度从 n 加倍到 2n 会提供 n 个至少为 的新项。因此,每次将项数加倍都会使部分和至少增加
的新项。因此,每次将项数加倍都会使部分和至少增加 。因此,永远持续下去的总和是无界的。
。因此,永远持续下去的总和是无界的。
我们可以通过比较部分和与积分来确定此级数的部分和在第 n 项增加时会发生什么。下面是方法。
我们可以通过直方图的面积表示任何正元素序列的前 n 项的和,元素 a[j]对应于位于 x 轴上的 j-1 和 j 之间的宽度为 1、高度为 a[j]的矩形。
每个矩形的右上角的坐标为  。 每个矩形的左上角的坐标类似地为
。 每个矩形的左上角的坐标类似地为  。
。
请注意,由  定义的曲线通过前面的每个点,并且完全位于直方图上方,而曲线
定义的曲线通过前面的每个点,并且完全位于直方图上方,而曲线  通过第二个序列的点,并且完全位于直方图内部。
通过第二个序列的点,并且完全位于直方图内部。
现在让我们考虑从 1 到 n 的积分 
这个积分可以进行,并且答案是 ln(n)。 由于  的曲线明显位于该级数的 n-1 项直方图之上的直方图上方。 我们可以得出结论
的曲线明显位于该级数的 n-1 项直方图之上的直方图上方。 我们可以得出结论

由于矩形的左端点都与曲线  相交,并且从 0 到 n - 1 延伸到直方图下方的区域完全位于直方图的 n-1 之前,我们可以类似地得出结论
相交,并且从 0 到 n - 1 延伸到直方图下方的区域完全位于直方图的 n-1 之前,我们可以类似地得出结论

因此

随着 n 的增加,ln(n)趋向于无穷大。 因此,我们已经证明了调和级数发散,但其部分和与 ln(n)之间的差异略小于 1。
练习 30.4 s[n]与 ln(n)之间的差称为欧拉常数,用希腊字母γ表示,利用电子表格找出这个级数的前 128 个部分和,比较部分和 s[1]、s[2]、s[4]、s[8]、...、s[128]。 使用外推法消除这些部分和之间以 2、4、16、64 等因子下降的差异。 使用这些来估算γ。
这种确定收敛性的方法同样适用于任何项递减且系数代表可积函数的级数。 它被称为积分测试。
在直方图的左上角与矩形相交的函数将位于其下方,而在直方图的右上角相交的函数将位于其上方,其第一个项之后,因此级数的收敛等价于相应函数的积分的收敛。
从这个例子可以清楚地看出,项与项之间按比例下降是不足以导致正数序列收敛的。 另一方面,这个积分测试表明,任何正数 z 的按比例下降为  对于收敛是足够的,因为相应的积分将收敛。
对于收敛是足够的,因为相应的积分将收敛。
练习 30.5 通过展示适当的积分来验证此断言。
30.4 幂级数与收敛半径
假设我们有一个关于变量 x 的幂级数。
如果它对某个 x 的值收敛,那么它将(通过比较测试)对任何更小的 x 值收敛。
因此,级数将收敛到某个最大值的 x,对于该值,连续项的比率变为 1。
级数收敛的最大 |x| 值称为其收敛半径。
很明显,同一个级数代表的函数对于其收敛半径严格小于其绝对值的所有 x 值都是收敛的,并且是无限可微的。
另一方面,在复平面中通常存在一个距离原点给定收敛半径的值 x,此处级数是奇异的。
因此,级数的收敛半径表示从展开点到函数奇点的最近距离。
例如,x 的几何级数((1-x)^(-1) 的级数)在 x = 1 处发散,1 是其收敛半径,这种行为是所有幂级数的典型特征。
同样的函数 (1-x)^(-1) 可以在参数 -1 处展开为幂级数。由于-1 和奇异点 x = 1 之间的距离为 2,因此该级数的收敛半径为 2。

练习:
30.6 通过从右侧减去  并将结果除以
并将结果除以  ,并重新排列得到的结果来证明这个陈述。
,并重新排列得到的结果来证明这个陈述。
30.7 找出在 x + 3 的幂级数中展开相同函数的可比较级数。
30.8 关于原点展开的指数级数的收敛半径是多少?
幂级数的另一个好处是,如果你从函数 f 开始,你可以根据泰勒定理推导出关于点 z 的级数展开。f 将有以下展开式

其中 f^((k))(z) 是函数 f 在参数 z 处的第 k 阶导数,求和从 k = 0 开始。
练习 30.9 通过使用泰勒定理,在 x = -3 处计算其导数,找到以 (1-x)^(-1) 为展开点的级数展开。
30.5 操纵绝对收敛级数
绝对收敛级数的一个好处是,你可以随心所欲地操纵和重新排列它们。
因此,给定这样一个幂级数,你可以在其绝对收敛的收敛半径内逐项积分或逐项微分,其中它绝对收敛。
假设我们从几何级数开始
(1-x)^(-1) = 1 + x + x² + ... + x^n + ...
并且对两边进行积分,对右边的每一项进行积分。
我们得到

练习 30.10 对两边再次积分,并使用恒等式  重新排列并解释右边。
重新排列并解释右边。
我们也可以逐项对几何级数进行微分。
注意,积分后,项比原来更收敛一些。在微分时,它们变得稍微不那么收敛,但不足以影响收敛半径。
(1-x)^(-2) = 1 + 2x + 3x² + ... + (n+1)x^n + ...
练习 30.11 再次在这里两边求导,找到关于变量 x 的级数展开式!。检查 x = 0 和 时的结果
时的结果
30.6 计算级数部分和
通过电子表格或程序,计算级数的部分和的值非常容易。
当一个级数的连续项比率 小于某个小于 1 的 r 时,随着 j 的增加,项以 r 的指数速度减少,计算级数的值到任意精度时很少出现问题。
小于某个小于 1 的 r 时,随着 j 的增加,项以 r 的指数速度减少,计算级数的值到任意精度时很少出现问题。
当连续项的比率接近 1 时,收敛速度变慢,人们可以通过调整它们来提高计算的准确性。
当第 j 个部分和的收敛速度表现为 j^(-k)时,你可以通过外推来提高收敛速度。
一种方法,正如在许多情况下已经注意到的那样,是用 替换部分和,它也可以写成
替换部分和,它也可以写成
当级数的系数是 j 的标准函数时,这通常发生在整数值的 k 处。
你可以轻松地检查那些索引相差 2 倍的项的差异比率,以查看部分和是如何收敛的,并选择一个合适的 k 进行外推。连续这样做可以大大提高计算的准确性。
你甚至可以通过类似外推来确定发散级数的部分和的增长速度。
例如,考虑 j²的和,显然是发散的。
通过观察形式为 2^k 的 j 的部分和 s[j],你可以得出以下推论:
1. 随着 j 加倍,项大约增加 8 倍。这表明主导项与 n³成正比。(这你可能应该知道。)
2. 通过观察部分和与 的比率并进行外推,你可以看到
的比率并进行外推,你可以看到 的系数
的系数
3. 通过计算部分和的差值 ,你可以得到另一个序列,其比率随着 n 加倍大约增加 4 倍。
,你可以得到另一个序列,其比率随着 n 加倍大约增加 4 倍。
4. 观察这些比率与 n²的比值,你可以找到 n²的系数,即
5. 通过观察部分和的差异与  你可以发现它是
你可以发现它是 
因此,你可以找到公式

对于这个级数,仅通过数值电子表格操作就可以找到它的前 n 项。
毫无疑问,有更简单的方法来得到这个结果,但如果你习惯于电子表格操作,这种方法确实非常轻松。
当级数收敛时,你可以通过外推得到准确答案,而且几乎不费力气。
通过观察 2 的幂,你可以首先消除部分和与误差之间随着 2 的主导幂减小的差异,然后是下一个,再下一个等等,直到答案精确到你的标准为止。
练习:
30.12 对从 1 开始的系列执行上述步骤,其中 (n+1) 阶项明确为 n²。然后对 (n+1) 阶项 n³ 做同样的操作。
30.13 通过适当的外推法,找到 n^(-3) 的和(从 n = 1 开始),精确到十位小数。
30.7 幂级数的系数表达式
到目前为止,我们大部分讨论了当遇到级数时该怎么做。你可以测试其收敛性,估计其极限,并尝试找到它所代表的函数,如果它是幂级数的话。
另一个重要问题是:如何找到给定函数在某个展开点附近的幂级数展开中的系数?
我们从我们在第 10.2 节中对泰勒级数的研究中知道,第 j 项的系数将是函数在展开点处的 j 阶导数除以 j 的阶乘。
这是一个有用的事实,但并不总是足够有用,部分因为计算或计算复杂函数的高阶导数可能很麻烦。
幸运的是,我们的标准函数可以在复平面中定义,在其中我们可以利用留数定理给出幂级数的系数的积分表示。
假设我们有一个函数 f(z) 并希望将其在点 z' 处展开成级数。我们知道,任何函数在复平面中围绕一个孤立奇点 z'(且没有其他奇点)的简单闭合路径的积分是 2 i 倍其在 z' 处的留数,而 z' 处的留数是 f 在点 z' 处幂级数展开中
i 倍其在 z' 处的留数,而 z' 处的留数是 f 在点 z' 处幂级数展开中  的系数。
的系数。
因此,我们可以推断出 f(z) 在 z' 处的幂级数展开中的系数  ,即
,即  在 z = z' 处的留数,是
在 z = z' 处的留数,是  乘以 在不包括 f 的任何奇点的 z' 周围的任何简单闭合路径上的积分
乘以 在不包括 f 的任何奇点的 z' 周围的任何简单闭合路径上的积分

这种积分可以在没有太大困难的情况下为任何 n 数值地求解。
30.8 傅里叶级数
假设我们有一个在原点周围单位圆中非奇异的函数 f(z)。那么它将具有以下形式的幂级数展开式

其收敛半径至少为 1。
如果我们在单位圆上观察这个函数,其中  ,这个级数的形式为
,这个级数的形式为  ,这样如果我们定义
,这样如果我们定义  ,我们有
,我们有

这种类型的级数,或者,或者形式的级数

被称为傅里叶级数。
每种情况中右侧的级数周期为 2。
通过在正弦或余弦的指数中添加一个常数因子,您还可以创建具有其他周期的傅里叶级数(例如替换  您可以使周期为 L)。
您可以使周期为 L)。
这里的系数 a[n] 可以通过上一节的积分公式确定。
在单位圆中积分,我们可以积分  以获得
以获得

b[n] 和 c[n] 的类似公式为

和

练习 30.14 通过找到  的 b 和 c 来验证这些公式的正确性
的 b 和 c 来验证这些公式的正确性
函数的傅里叶级数表示在几个方面非常有用。
首先,余弦和指数函数易于微分。将一个函数表示为指数函数的和实际上是将其表示为导数算子的本征函数的和。这类似于在普通向量空间中使用一组基,其成员都是该空间上某个重要线性变换的特征向量。
第二,如果您分析振荡器(或类似系统)对固定频率的外部强迫响应,您可以通过找到实际强迫函数的傅里叶级数(有时为傅里叶变换,对于非周期函数是类似的东西),找到您系统对实际强迫函数的响应。
当您学习微分方程时,您会更多地了解这一点。
显然,并非所有函数都存在傅里叶级数  ,并且对于在积分范围内奇异的函数也不需要存在。
,并且对于在积分范围内奇异的函数也不需要存在。
此外,由于 对于所有 n 值都是
对于所有 n 值都是 的偶函数,而
的偶函数,而 是其奇函数,因此正弦和余弦级数分别适用于奇函数和偶函数 g。
是其奇函数,因此正弦和余弦级数分别适用于奇函数和偶函数 g。
您可以将系数的公式应用于任何函数,包括不连续的函数,例如,对于使得 x > 0 的角度,为 ,否则为
,否则为 的阶跃函数。
的阶跃函数。
所有正弦和余弦函数都是连续的,因此阶跃函数的傅里叶级数的部分和必须是连续的。 这意味着它们在不连续点周围的某个区间内都可能非常错误。 这些区间通常会随着部分和指数的增加而缩小。
如果我们围绕单位圆积分 f 乘以其复共轭,并且其傅里叶级数几乎收敛于它,那么积分应该等于通过将级数代入 g 及其复共轭的积分得到的项之和。
在后者的级数中,所有交叉项都不产生贡献,我们得到了在将级数代入 g 后的结果

由于右侧级数中的项都是正数,所以其部分和必定都小于左侧两个积分中的任意一个。
数学家们已经付出了大量的努力来理解傅里叶级数何时收敛。
练习:
30.15 推导正弦和余弦级数的类似结果。
30.16 计算阶跃函数的傅里叶系数,即
30.17 将刚才声称的方程应用于这些系数的序列。 你找到了什么?
第三十一章:进行面积、表面积和体积积分
介绍
你遇到的大多数积分都不需要你评估它们。然而,培养一些评估经验是个好主意,以增强你的信心。其中一个通常是通过进行多重积分来完成的,这意味着一系列的普通积分。要做到这一点,你必须做三件事:确定作为你的积分变量的函数的被积函数;确定积分的面积或体积元素;以及找到获得普通积分的适当积分上限。一旦完成了这些步骤,你就可以执行普通积分。我们在这里讨论这些步骤。
主题
31.1 介绍
31.2 将曲面参数化或以适当的形式进行积分
31.3 确定被积函数
31.4 确定面积或体积元素
31.5 设置正确的积分上限
31.6 进行积分
31.1 介绍
在许多学科中会遇到表面和体积积分以及高维空间中类似的积分。
它们可用于确定表面和体积的面积,例如在力学中感兴趣的惯性矩、概率分布的矩、区域内的质量和电荷、给定电荷分布的电势、通过曲面的流量,以及许多其他事情。
我们将在这里考虑两种类型的积分:通量积分和体积积分。在二维中进行面积积分可以被视为通量积分的简单特殊情况。
以下是你可能会遇到的一些积分示例:
计算高为 h、半径为 r 和密度为  的右圆柱的惯性矩。
的右圆柱的惯性矩。
计算轴长为 A、B 和 C 的椭球的体积。
计算球面上均匀电荷分布的电势 a。
计算在 0 和 h 之间以半径 r = z² 的圆锥形状的表面积。
曲面可以用几种不同的方式描述。
你可能对曲面有定性描述(它是一个平面或某个位置的球面或圆柱面或锥面等),或者它可以由一个方程来定义:f(x, y, z) = 0。
或者你可以有关于每个 x、y 和 z 的参数表达式。
最简单的情况发生在你的曲面由一个方程描述,并且你可以解方程得到 z 作为 x 和 y 的显式函数,(z = z(x, y)),这样你就可以将 x 和 y 作为两个参数使用。
31.2 以参数方式表达曲面或以适当形式进行积分
要处理定性描述,您需要能够写出所讨论表面的方程或参数表示。您应该准备以这种方式处理的重要表面有:平面、球面和椭球面、圆柱面和圆锥面。
我们简要回顾每一个。
平面由线性方程描述
ax + by + cz = d
你总是可以用另外两个变量的形式解出一个变量。系数由平面上给定的条件确定。
以(x', y', z')为中心的半径为 A 的球面由满足方程的空间点组成

一般椭球的表面特征为

以轴平行于 z 轴、起始于 z = B、终止于 z = C 的半径为 A 的圆柱体的表面由方程表示

中心线平行于 z 轴的圆锥的表面由描述

31.3 确定被积函数
通常形式的通量积分

现在假设我们有 S 的参数表示,这意味着我们有方程 x = x(u, v),y = y(u, v) 和 z = z(u, v),这定义了我们的曲面。
我们可以将(W ****n)dS 表示为关于 u 和 v 的显式函数乘以 dudv,并确定结果积分的顺序和限制,将这个积分简化为一系列关于 u 和 v 的普通积分。
****n)dS 表示为关于 u 和 v 的显式函数乘以 dudv,并确定结果积分的顺序和限制,将这个积分简化为一系列关于 u 和 v 的普通积分。
这个过程的第一步很直接:
形成向量

以及类似地

然后,对 u 和 v 进行积分,可以将被积函数写成由W的分量, 乘以适当符号的行列式的绝对值。
乘以适当符号的行列式的绝对值。
原因请参见第 24.1 节。(这里的向量n通常表示相对于某个区域的外向法线,积分的符号是这样的,如果W与这个外向方向的点积为正,则结果为正。)
适当的符号必须单独确定,但只需从原始积分的上下文中确定一次。
因此,至少在符号上,积分变为

尽管这种简化很直接,但实际执行所需的步骤涉及足够多的代数操作,以至于我几乎总是在执行过程中至少犯一次错误,因此很少能得到相同的答案两次。
幸运的是,在最常见的情况下有一个计算上更简单的答案,即 u 和 v 实际上是你的原始变量之一,比如 x 和 y。
在这种情况下,向量变为 ,它们的叉乘变为
,它们的叉乘变为
然后被积函数和面积元素可以写成

这个结果更容易应用。我们在这里假设符号应该是正的,指向 z 方向向上,如果这个假设是错误的,符号必须被反转。
如果你的曲面由方程 f(x, y, z) = 0 描述,那么相应的具有相同符号假设的公式变为

(当 时,你必须对另外两个变量进行积分,比如 y 和 z 而不是 x 和 y。)
时,你必须对另外两个变量进行积分,比如 y 和 z 而不是 x 和 y。)
这里给出的答案既给出了被积函数又给出了面积元素。
唯一需要担心面积元素的时候是当你想要改变变量并且必须确定面积元素 dxdy 在其他变量 u 和 v 中的含义时。
这里有一个例子:我们想要计算通过由方程定义的曲面向外的矢量(x, y, z)的通量

(这个曲面被称为一个椭球。)
我们将仅对 z > 0 的曲面部分进行积分,并将结果加倍,因为曲面的下部提供相同的通量。
将这个写成 f = 0,我们计算 并且被积函数变为,根据最后的公式,
并且被积函数变为,根据最后的公式, ,在这种情况下是
,在这种情况下是 ,即
,即
因此,我们的积分变为

在适当的积分限制下。这些限制是由我们在 xy 平面上积分的区域确定的边界(我们将在下面讨论),也就是,积分中分母为正的区域。
31.4 确定面积或体积元素
到目前为止,我们已经解决了进行通量积分时出现的问题。
在体积积分的情况下,到目前为止讨论的问题不存在。
被积函数是被积函数本身,即一个标量场,体积元素是 dxdydz。
然而,当你改变变量时,如何表达这个体积元素的问题确实存在,我们在这里考虑这个问题。这个问题及其答案在任何维度中都是相似的。
此时我们注意到,面积积分是通量积分的简单特例。如果我们想要在 xy 平面上的区域 A 上积分 f(x, y)dA,我们可以在 k 方向上想象出一个第三个维度,并想象我们正在通过该平面上的曲面 A 积分向量 f(x, y)k的通量。
这将是(f(x, y)k)!图片ndS 的积分,如果n = k在 xy 平面上,这个通量积分就成为 f dxdy 的积分。在这种情况下,与体积情况一样,将表面积分减少到 dxdy 的积分问题是不存在的。
现在假设我们有一个体积或通量积分,并希望从 x、y(如果是体积积分还有 z)变量改变到 u、v(如果是相同的话还有 w)。
当我们认为这样做使被积函数更容易处理时,或者有时如果简化了积分的限制条件时,我们就这样做。
我们希望确定如何用 dudv 或 dudvdw 来表示 dxdy 或 dxdydz。
我们已经注意到了如何做到这一点,但由于其重要性,我们在这里重复一次。
在 u 中做一个小的改变会导致 x、y 和 z 的变化,可以用方程描述为

类似的表达式描述了由于 v 和 w 的变化引起的位置变化 dP[v]和 dP[w]。
由小的变化 du、dv 和 dw 引起的 xyz 空间中的体积是平行六面体的体积,其边为 dP[u]、dP[v]和 dP[w],这是行或列是这些向量的行列式的大小。
我们可以将 dudvdw 从向量中提取出来,并获得dxdydz = Jdudvdw,其中 J 是由 x、y 和 z 对 u、v 和 w 的导数形成的行列式的大小。
在面积的情况下,可比较的表达式是相同的:一个变量集合的面积元素 dxdy 与另一个变量集合 dudv 的比值是由 x 和 y 对 u 和 v 的导数形成的行列式的大小。在每种情况下,这个行列式的大小,也称为绝对值,被称为这种变量转换的雅可比行列式。
设置正确的积分限
要做到这一点,您必须首先决定您希望执行积分的顺序。
有时这并不重要,有时积分的难易程度差异很大。但是,如果您对您的选择不满意,您总是可以决定改变积分的顺序。
所以假设我们有一个面积积分,我们希望先对变量 x 积分,然后对 y 积分。
决定积分限制的第一步,也是最重要的一步,是画出您希望进行积分的区域的图形。该区域通常由一组曲线界定。
对于某些变量 y 的选择,积分限制 x 通常是位于这些边界曲线的两个值,用于此 y 值。你要对 y 进行积分,对于 y 的值,你会得到相同的 x 边界曲线区间。然后你确定每个区间内的一个 y 值。
在大多数情况下,你希望进行积分的 x 值将形成位于这些曲线之间的区间。你必须确定这些曲线是哪些(有时它们是相同的曲线),然后解出每个曲线方程以得到它的 x 值,假设 y 值已知。这些将是你的 x 积分的限制,对于此 y 值。
在某些情况下,x 上的限制涉及到不同的曲线对于不同的 y 值。你必须相应地选择你的 x 积分。
所有这些无疑听起来都很模糊和令人恐惧的困难。
实际上,如果你画一个图,通常是非常容易的。没有图片,确实很难准确理解。而且很容易搞错。
我们考虑一些例子:
假设首先你希望对三角形进行积分,其底边为 y = 0,边由方程 x = 0 和 x + y =1 确定。
对于所有 y 值介于 0 和 1 之间,都有一个 x 区间需要进行积分。
如果你固定 y 在 0 到 1 之间,你将对 x 在 x = 0 和 x + y = 1 之间进行积分,这意味着 x = 1 - y。
因此积分变为

假设你想要对三角形区域进行积分,其界定为 y = x,y = 0 和 x = 1。
再次,你要计算 x 区域的 y 值介于 y = 0 和 y = 1 之间,对于该区间内的任何 y 值,你要对 x 进行积分,x 的取值范围为 x = y 到 x = 1。
然后积分的限制为

练习:
31.1 假设你想要在这个相同的三角形区域先对 y 进行积分,然后对 x 进行积分。在这种情况下,适当的限制是什么?
31.2 假设我们想要从 y 到 2 进行 x 的积分,然后从 y = 0 到 1 进行 y 的积分。这定义了一个梯形。如果我们想要先对 y 进行积分,积分的限制是什么?
棘手的事情可能会发生,这里有一些要看的例子:
1. 由 x = 1,x = 2,y = x 和 y = 0 确定的区域。如果你先对 y 进行积分,这很简单。但如果你先对 x 进行积分,你会发现积分必须分成两部分。
在 y = 0 和 y = 1 之间,你必须对 x 在 x = 0 和 x = 1 之间进行积分;在 y = 1 和 y = 2 之间,你必须对 x 在 x = y 和 x = 2 之间进行积分。
2. 由  确定的区域。
确定的区域。
如果你先对 x 进行积分,那么对于 y 在 0 到  之间,你将从
之间,你将从  积分
积分
对于 y 大于,你必须在 之间进行积分,这代表着 y = sin x 的边界曲线上的两个点。
之间进行积分,这代表着 y = sin x 的边界曲线上的两个点。
从这些例子中可以清楚地看出,如果没有足够的图像,几乎不可能正确地完成这些事情。
下面是一个用于尝试不同矩形和极坐标下限的 applet。在上述示例和以下区域上试用它:
练习:
31.3 考虑半径为 A、以原点为中心的圆的内部。x 和 y 或 r 和 的限制是什么?
的限制是什么?
31.4 先对 x 积分然后对 y 积分,反之亦然,找到 y = x³、x = 1、x = 2 和 y = -x³ 之间区域的积分上限。
31.5 找到椭圆边界为 的积分上限,还有其他潜在的变量是什么?
的积分上限,还有其他潜在的变量是什么?
对于体积的积分可以以完全相同的方式进行。
首先,根据您对哪种顺序最方便的猜测,选择一个积分顺序。
然后你创建一个积分区域的图像,并从最后一个积分变量开始确定积分区间,然后逐步向前推进。
对于最后一个,确定它的哪些值对应于您希望在每个固定的边界表面集之间进行积分的区域。
然后你想象,比如说变量 y,在每个这样的区间内是固定的,然后继续下一个变量(最后一个要积分的变量)并在通过固定 y 获得的曲面上做同样的事情。
当你处理直角坐标时,这将是由曲线界定的区域,其余步骤与之前完全相同:
找到 z 的适当区间边界,然后想象在每个相关区间内固定了一个 z 值,然后确定 x 的限制。
考虑对半径为 A 的球进行积分,其边界表达式为
如果我们选择先积分 x 再积分 z 再积分 y,我们首先注意到 y 的取值范围是从 -A 到 A。
给定一个 y 的值,z 可以从 变化,固定 z 后,x 可以从
变化,固定 z 后,x 可以从 变化。
变化。
当然,球在极坐标下有更整洁的积分上限

矩形限制尽管勉强可以接受。
练习:
31.6 如果您希望对一个边界为 的椭球进行积分,确定适当的积分上限。
的椭球进行积分,确定适当的积分上限。
- 31.7 确定矩形和柱坐标系中圆锥内部区域的适当限制,其边界为 z = 1 和 z = r²。(原点是该区域的底部顶点。)
- 31.6 做积分
-
一旦你在变量上建立了积分限制,并且有了被积函数和正确的微分集合,你就可以开始积分了。然后你就得靠自己了。
-
练习 31.8 确定圆锥体和上述椭球体形状的物体关于 z 轴的惯性矩。假设质量密度在物体内部是恒定的。(物体的惯性矩是其密度乘以体积元到 z 轴的距离的平方的积分。但是,它总是表示为体的质量的函数,而不是密度。因此,你必须取积分确定惯性矩,以及确定质量之间的比率,以得到两者之间的关系。)
第三十二章:一些线性代数
介绍
本章包含线性代数基础知识的复习:线性方程的解、矩阵求逆、行列式、变换、不变量、特征值和对角化。
主题
32.1 线性方程
32.2 矩阵
32.3 矩阵的逆
32.4 更多关于行列式的内容
32.5 矩阵和变换
32.6 变换的不变量
32.7 对角化的其他概念
32.8 计算特征值和特征向量
32.9 应用于二次形式和弹簧系统
32.10 在电子表格上计算特征值和特征向量
32.11 猜测特征向量
32.1 线性方程
假设我们有一组线性方程,例如

我们希望 找到一个解决方案,这意味着找到 使这些方程全部成立的显式值的 x、y 和 z。
允许我们找到解决方案的基本事实是这些:
1. 给定任何方程,你都可以将其乘以任意非零数(即,在其左右两边的每个项都乘以)而不改变其含义。
2. 给定任意两个方程,我们定义它们的和为其左手边的和为两个左手边的和,其右手边的和为两个右手边的和的方程。
然后你可以用其中一个方程的和替换另一个方程,而加上另一个方程的任意倍数,而不改变它们的含义。
例如:你可以通过从中减去第三个方程来将上面的顶部方程替换为 3x + 4y = 6;(减去方程等同于加上它的 -1 倍)
练习 32.1 证明这里的断言 2。 解答
你可以通过使用刚才提到的这种类型的操作的一系列操作来解方程,将方程转化为 x = a,y = b,z = c 的形式,这是它们的解。
你应该使用什么样的操作顺序来解方程?
注意在上面的示例中选择的减法是为了使 z 不出现在被减的方程中,即 3x + 4y = 6。
如果我们对第二个方程做适当倍数的第三个方程的加法,那么结果的和方程中的 z 项也可以类似地被消除;结果是 x - 3y = 6。
我们从三个变量的三个方程开始。
经过这些操作,我们已经从两个方程中消除了 z,并且得到了两个变量的两个方程。
通过类似的操作,我们可以消除 x,例如,通过从第一个方程中减去第二个方程的三倍。然后得到的方程是 13y = -12。
将此方程除以 13,然后我们得到了关于 y 的表达式。
我们可以将其替换为 y,然后代入前两个方程中的任一个,并解出所得方程的 x。
我们得到  将 x 和 y 替换为任何原始方程中的值,然后给出
将 x 和 y 替换为任何原始方程中的值,然后给出  我们有了方程的完整解。
我们有了方程的完整解。
通常你可以逐个变量地系统地消去所有方程,将 n 个未知数的方程减少为(n-1)个未知数的方程,并重复该过程,直到你可以解出一个未知数的一个方程,然后替换回去以找到其他未知数,一个接一个。
这个过程称为“高斯消元法”。
练习 32.2 对以下方程组执行高斯消元以找到解

解答
请注意,在进行这些操作时很容易出错,明智的做法是一旦得到答案,就在所有原始方程中检查你的答案,看它们是否满足。
这个过程可能失败吗?
如果你开始的方程一致,它们将产生唯一的解 除非 当你试图通过从另一个方程减去一个方程的倍数来消去一个变量时,你消去了整个方程。
也就是说,在某个阶段,你的一个方程是另一个方程的倍数,减去这个倍数就消去了整个方程。
如果在开始时你的一个方程可以表示为一个或多个其他方程的倍数之和,则会发生这种情况。(最简单的发生方式是当两个方程相同时)
在这种情况下,你的方程的左侧被称为线性相关。
否则,当方程有唯一解时,左侧被称为线性独立。
当你的方程线性相关时(并且你开始的方程数与你的未知数数相同),你会发现你没有足够的方程来确定唯一的解。
这并不是一场灾难,但这意味着有很多解,至少有一整条线。
继续高斯消元过程,直到你只剩下一个非零方程,其中有两个或更多个变量。那么,任何解这个方程的解都是原方程组的解,这被称为欠定方程组。
例如,假设你的最后一个方程是 x = 2y + 3。
然后你可以选择任意值给 y,计算 x,然后继续使用你的其他方程来计算你的其他未知数,这将是一个解,尽管当然不是唯一可能的解。像这样的方程的解形成了 xy 平面上的一条线。
32.2 矩阵
矩阵提供了描述线性方程的便捷方式。因此,如果你将未知数的系数按某种标准顺序排列为矩阵的行元素,你就为任何一组方程定义了系数矩阵。
对于上面的示例方程,系数矩阵,称为 M,是按照 x、y 和 z 的标准顺序排列的

我们可以将原方程写成单一矩阵方程

使用矩阵乘法的定义,即:将第一个矩阵的行与第二个矩阵的列(这里是单列)进行点积,以产生乘积的相应元素,你应该验证这个矩阵方程与我们最初的三个方程完全相同。
高斯消元法可以应用于这种矩阵形式。规则是:
1. 你可以将整行(方程两侧)乘以任意非零数,而不改变方程的内容。
2. 你可以将任意行的倍数加到另一行上,而不改变方程的内容。但是,你必须完全跨越整行,包括矩阵的另一侧。
在这种形式下,这些操作被称为"初等行操作",高斯消元被称为行简化。
在这里你要做的是执行足够多的第 2 种操作,在主对角线的一侧形成矩阵中的 0。当这样做时,你可以确定一个未知数,然后逐步代入找到其他未知数。
你也可以尝试执行这些操作直到矩阵主对角线之外的所有元素都是 0,对角线元素为 1。在这种情况下,右侧向量是相应变量的解,你无需回代找到所有未知数。
对角元素为 1,非对角元素为 0 的 n 维矩阵称为n 维单位矩阵,通常写为I,除非可能引起混淆,此时会写为I[n]。
它具有这样的性质,即其与相同维度的任何矩阵 M 的矩阵乘积是 M 本身,并且其对任何 n 维向量v的操作是v本身。
因此,如果你从矩阵方程Mv = r开始,并通过行简化找到另一组相同方程的表示,其中 M 已被简化为单位矩阵 I,你会得到Iv = r',其中r'是右侧方程上的相同行操作的结果,这些操作将 M 简化为 I。
你因此得到解,v = r'。
32.3 矩阵的逆
如果两个方阵 M 和 A 满足MA = I(在无限维度中,你还需要条件 AM = I),那么A 和 M 被称为彼此的逆,我们写为 A = M^(-1)和 M= A^(-1)。
正如我们所描述的,行简化的一个很棒的特性是,当你有一个矩阵方程 AB = C 时,你可以将 A 的简化操作同时应用于 A 和 C 的行,而忽略 B,你得到的结果与你开始的一样正确。
这正是当 B 是列向量,其分量等于我们的未知数 x,y 和 z 时所做的事情,但对于任何矩阵 B 来说同样成立。
因此,假设你从矩阵方程AA^(-1) = I开始。
如果我们对 A 进行行简化,使其成为单位矩阵 I,那么这里的左侧变为 IA^(-1),即 A^(-1),A 的逆矩阵。然而右侧是如果你应用必要的行操作将 A 简化为单位矩阵,从单位矩阵 I 开始,你会得到的结果。
我们可以得出结论,逆矩阵A^(-1)可以通过将使 A 成为 I 的行简化操作应用于 I 开始的矩阵 A 来获得。
例子: 我们给出一个二维的例子,但这种方法和思想在任何维度都适用,当 n 为数百甚至数千时,计算机可以对 n 乘 n 矩阵进行这样的操作。
假设我们想要以下矩阵的逆矩阵。

我们可以在其旁边放置一个单位矩阵,并同时对两者进行行操作。这里我们首先从第二行减去第一行的 5 倍,然后将第二行除以-9,然后从第一行减去第二行的三倍。


最后一个矩阵是我们原始矩阵 A 的逆矩阵。
注意A 的行和 A^(-1)的列彼此之间的点积要么为 1,要么为 0,A^(-1)的行和 A 的列也是如此。 这当然是逆矩阵的定义特性。
练习 32.3 找到矩阵 B 的逆矩阵,其行为(2 4);第二行为(1 3)。 解答
矩阵的逆矩阵在解方程时非常有用,当你需要用不同的右侧解相同的方程时。如果你只想解方程一次,那么这就有点大材小用了。
如果你的原始方程形式为 Mv = r,通过将两边乘以 M^(-1),你会得到v = Iv = M^(-1)Mv = M^(-1)r,因此你只需将逆矩阵 M^(-1)乘以右侧的r,就可以得到方程的解。
如果你考虑在这里计算逆矩阵时所做的事情,并意识到在这个过程中 M^(-1)的不同列根本不相互作用,你本质上是在解非齐次方程 Mv = r,其中 r 由单位矩阵的三列给出,并将结果排列在一起。
所以我们在这里说的是,为了解一般的方程r,只需对 I 的每一列求解,然后一般线性组合 r 的解是相同的线性组合的相应解。
什么矩阵有逆?
并非每个矩阵都有逆。
正如我们所看到的,当 M 的行线性相关时,M 定义的方程组没有唯一解,这意味着对于某些右手边,有很多解,而对于某些右手边则没有解。如果是这样,矩阵 M 没有逆。
在三维中刻画行(如果行是线性相关的,则列,如果矩阵是方的,那么列也是线性相关的)的线性相关性的一种方法是,由 M 的行(或列)形成的平行六面体的体积为零。
M 的行形成的平行六面体的体积在第二种行操作下不会改变,即向另一行添加倍数的行,尽管如果你将一行的每个元素乘以 c,则会变化为|c|的因子。
体积始终是正数的事实,所以绝对值|c|出现在这里有些尴尬,因此惯例上定义了一个量,当它为正时是这个体积,但具有线性性质:如果你将一列乘以 c,它的变化因子为 c 而不是|c|。这个量(在任何维度上都有类似的量)被称为矩阵 M 的行列式。
因此,M 的行列式的绝对值是:
在一维中 M 的单个矩阵元素的绝对值。
在二维中,由 M 的行(或者如果您愿意,列)给出的平行四边形的面积。
在三维中,以 M 的行(或者列的交替排列)作为边的平行六面体的体积。
在更高的维度中,以 M 的行(或列)作为边界的区域的“超体积”或高维模拟体积。
在0 维中我们给出它的值为 1。
行列式 M 的行或列中的任何一个都是线性的,并且在用任何其他行的任意倍数的和替换其中一行,比如 q 时保持不变。
这些陈述规定了行列式的符号。根据约定,行列式对于恒等矩阵 I 的符号被确定为正,其行列式总是 1。
M 具有逆的条件是:M 的行列式不为零。
我们很快将看到如何计算行列式,以及如何用行列式来表示矩阵的逆。
32.4 关于行列式的更多信息
我们已经定义了矩阵的行或列的行列式为线性函数,其大小是由其列或行给出的边界的区域的超体积。
行列式有一些重要的性质如下:
我们将列出它们然后提供它们的证明。
1. 列的线性性: 如果我们有列向量 c(k)和 d(k),对于 k = 1 到 n,并选择这个范围内的任意 j,则 n 维行列式满足条件
det (c(1), …c(j - 1), ac(j) + bd(j), c(j + 1),…,c(n)) = adet (c(1), …c(j - 1), c(j), c(j + 1),...,c(n)) + bdet (c(1), …c(j-1), d(j), c(j + 1),...,c(n)).
2. 行的线性性: 请自己写出这个。
3. 如果两列相同,则行列式为 0。(行也是如此。)换句话说,如果交换两行(或列),行列式会改变符号。
4. 行列式可以通过类似行变换的过程来计算。可以将一行的倍数加到另一行,直到主对角线一侧的所有元素都为 0。
然后对角线元素的乘积就是行列式。
5. 两个矩阵的乘积的行列式等于它们的行列式的乘积。
6. 对于矩阵 M 中的任意一列元素,比如 M[1j],M[2j],...
行列式可以表示为
det M = M[1j]C(1, j) + M[2j]C(2, j) + ...
这里出现的量C(i, j)被称为矩阵 M 的余子式。
C(i, j)必须对 M 的除第 i 行和第 j 列外的所有行和所有列都是线性的,并且如果这两行或列相同,则必须为 0;因此它与从 M 中删除第 i 行和第 j 列得到的矩阵的行列式成比例。比例常数结果为(-1)^(i+j)。
7. 矩阵 M 的逆矩阵是其(i, j)-th 元素为 的矩阵。
的矩阵。
8. 如果有一组形如 Mv = c的方程组,则v的第 i 个分量由取 M 并用 c 替换 M 的第 i 列得到的矩阵的行列式除以 M 的行列式给出。(这个陈述被称为克莱姆法则。)
9. 矩阵的行列式为 0 的条件意味着由列确定的区域的超体积为 0,这意味着它们线性相关,并且意味着存在一个非零线性组合的列是零向量。这意味着对于这个向量v,我们有 Mv = 0。
10. 行列式不受坐标旋转的影响。
11. 在 x 中的 n 次多项式由det(M - xI)定义,称为矩阵 M 的特征多项式。其根(满足 it = 0 的解)称为 M 的特征值。
现在我们对这些说法进行评论。
前三个立即由行列式的定义作为超体积的线性版本得出。
由此可知,可以在不改变行列式的情况下,将一行的倍数加到另一行上:因为根据线性性,变化必须是具有两个相同行的矩阵的行列式的倍数。
但是你可以一直这样做,直到矩阵是对角线矩阵,此时行列式,再次通过线性性,是对角线元素的乘积乘以单位矩阵的行列式(为 1)。
两个矩阵乘积的行列式是行列式乘积的陈述**是重要且有用的。这可以通过以下两点观察得出:
1. 如果矩阵 A 是对角线矩阵,那么 det A 是 A 的对角线元素的乘积。
另一方面,AB 的行只是 B 的行,每个都乘以 A 的对角线元素。
然后通过线性性,AB 的行列式是 A 的对角线元素的乘积乘以 B 的行列式,也就是 A 的行列式和 B 的行列式的乘积,正如我们所声称的。
2. 如果我们对 A 应用一个行操作(不允许将行乘以常数)如上述属性 4 中讨论的,得到一个新矩阵 A',并对 (AB) 应用相同的行操作得到 (AB)',我们将有
(A'B) = (AB)'
我们将有 det A = det A',以及 det AB = det A'B。
我们可以一直这样做,直到 A 是对角线矩阵,此时我们可以使用这里的第一个陈述告诉我们:(det A') * (det B) = det A'B,从而得出我们的结论。
关于余子式的陈述只是明确了在每行和每列中线性的含义。
符号因子可以从这样一个事实中推导出来,即如果你考虑第一行和第一列,(想想单位矩阵)你可以交换行和列与它们的邻居 i - 1 和 j - 1 次,重新排列事物,使得第 i 行和第 j 列成为第一行,其他所有行列保持原始顺序。
这将导致 i + j - 2 个符号变化,这给出了所述的符号因子。
如前所述,逆的余子式公式是关于逆的行与原始矩阵的列的点积的陈述。对角线乘积必须为 1,这可以从行列式的余子式公式中得出,而非对角线乘积必须为零,因为根据相同的公式,它们代表具有两个相同列或行的矩阵的行列式。
克莱姆法则是观察到,根据逆的定义,所需系数是矩阵 M 的逆的第 i 行与向量 c 的点积。但根据余子式公式,这是余子式矩阵的第 i 列与向量 c 的点积,除以 M 的行列式,这就是克莱姆法则的两个行列式的比率。
32.5 矩阵和变换
矩阵最重要的用途在于表示向量空间上的线性变换。
如何?
一个矩阵表示了将第一个基向量转换为矩阵的第一列,第二个基向量转换为矩阵的第二列,第 j 个基向量转换为矩阵的第 j 列。
它对其他向量做了什么?
记住,任何其他向量,比如v,都可以表示为基向量的线性组合:v通过变换转换为矩阵的列向量的同一线性组合。
例如,前两个基向量的和被映射为矩阵的前两列的和;两个基向量的平均值被映射为列的平均值,依此类推。
请注意,如果使用不同的基,作用于向量的相同变换通常会由不同的矩阵描述。
示例
32.6 变换的不变量
由于相同的变换通常可以用许多不同的矩阵来表示,取决于所选择的基,因此可以提出以下问题:
矩阵的哪些属性是独立于基的相同,是矩阵所代表的变换的固有属性?
什么时候两个矩阵代表相同的变换但使用不同的基?
实际上,对于每个问题,都可以提出几个问题,因为我们可以描述元素全部为实数的矩阵,或者允许复数元素,并且我们可以坚持使用正交规范基(任何基向量与自身的点积为 1,与任何其他基向量的点积为 0)或允许更一般的基,包括具有复数分量的基。
答案在考虑的上下文不同时略有不同,但基本上是相似的。
我们这里只考虑实矩阵和实正交规范基。
将我们的原始基向量转换为另一组正交规范基向量的矩阵称为正交矩阵;其列必须相互正交并且与自身的点积为 1,因为这些列必须形成正交规范基。
这些条件意味着正交矩阵的转置就是它的逆!(两个矩阵互为逆矩阵的条件是一个矩阵的行与另一个矩阵的列正交,除了具有相同索引的行和列之外,它们的点积为 1)
我们接下来要讨论的问题是:当正交变换 A 应用于原始基向量时,矩阵 M 会发生什么变化?
A 将初始基转换为 A 的列。我们想知道矩阵 M 对这些列向量做了什么。那就是矩阵 MA对原始列基向量所做的事情。A 将它们带入新的基向量,然后 M 将这些向量转换为它们所做的任何事情。
然而,乘积 MA 表达了 M 对新基向量的作用以旧基向量为基础的线性组合;其列给出了 M 对新基向量的作用,作为旧基向量的线性组合。
我们希望将这些列重新表达为新基向量的线性组合。
我们该如何做到这一点?
最容易看到的方法是观察当 M 是单位矩阵 I 时会发生什么。这是一个将任何向量映射为自身的矩阵。在基变换后,它仍然必须将任何向量映射为自身,因此它仍然是单位矩阵。
但如果 M = I,那么 MA 就是 IA 或 A 本身,这就是 I 在旧基中的表达方式。这就是说 A 的列告诉了新基向量在旧基中的样子。
要用新基来重新表示 I,您必须做一些将 AI 返回到 I 的事情。 这样做的方法是左乘 A^(-1),即 A^T。
我们推断左乘 A^(-1) 执行了所需的重新表达对于 I 和因此对于任何矩阵 M。 我们得出结论,在新基中,矩阵 M 变为A^TMA。
矩阵的转置是通过交换其行和列而获得的矩阵。
矩阵在这样的变换之后仍然相同,它就是对称的。
我们刚刚看到正交变换将矩阵 M 变为形式 A^TMA,其中 A^TA = I,并且矩阵 A 的列由新基在旧基中表示而成的正交归一化基给出。
这种变换的一个好处是如果 M 是对称的,那么在任何这样的变换后它仍然保持对称。
练习 32.4 证明这个声明:如果 A^TMA 是对称的,则 M 是对称的。
这告诉我们可能可以通过这种变换使对角化的唯一矩阵是对称的; 因为当它们是对角的时,它们显然是对称的。
如果一个矩阵是对角的,它的特征向量就是基向量。因此,我们已经证明只有对称矩阵具有实正交基。
另一方面,任何对称矩阵都可以通过正交变换对角化。 另一种说法是每个对称矩阵都有一个实特征向量的正交归一化基。 此声明的证明
我们已经回答了我们的第一个问题:哪些矩阵可以通过选择一个新的正交归一化基来对角化?答案是任何对称矩阵。 将矩阵放入这种形式的方法是找到其特征向量并选择其中的正交集。
我们的第二个问题是:两个这样的矩阵何时会成为不同基中相同变换的表示。答案是,当它们的特征方程相同时,它们的特征值相同且具有相同的重数时。
32.7 对角化的其他概念
我们已经注意到,我们的第一个问题有许多变体,当使用这些变体时,我们将注意到答案的变化。
当我们允许复数矩阵元素和复向量时,我们可以对更广泛的矩阵进行对角化。
当一个向量具有复值元素时,我们仍然希望将其长度解释为其与自身的点积的平方根。我们希望这个值是正的。
因此,我们重新定义点积:复向量与自身的点积是其条目的绝对值的平方之和。
我们将这个推广到一行向量和一列向量的点积,通过将它定义为行向量的复共轭与列向量的相应分量的乘积之和。
因此,具有条目(a + ib, c + id)的列向量与相同行向量的点积是
(a - ib)(a + ib)+(c - id)(c + id)
或
a² + b² + c² + d²
与(e + if, g + ih)相同的列向量的点积反而是
(e - if)(a + ib)+(g - ih)(c + id)
请注意,按照这个定义,点积不再对称。但是如果你交换行和列并且取复共轭,它不会改变,因为不对称性在于取行的复共轭而不是列。
用复向量,我们定义一个正交归一基,使得每列与其他列中的条目的复共轭的点积都为零。
这意味着按照这个定义,一个矩阵,将给定的基转换为另一个正交归一基在这个背景下具有其复共轭转置为其逆的属性。
这样的矩阵称为酉矩阵,而将一个正交归一复基转换到另一个的线性变换称为酉变换。
由于与之前相同的论证,酉矩阵 U 描述的酉变换对矩阵 M 的影响现在是 U^t * MU,(当然,实数酉矩阵是正交的)。
再次我们可以问,哪些矩阵可以被一个酉变换对角化? 一个初步的问题是:哪些矩阵可以被对角化,以便它的特征值,也就是在对角化时出现在对角线上的值,都是实数?
现在的答案是,任何矩阵它自己的转置的复共轭将具有此属性:这意味着如果 M 是 n 乘以 n,M 具有 n 个实特征值和一组特征向量的正交基。
这样的矩阵称为厄米矩阵。
再次,这个条件的必要性来自于“厄米性”被酉变换保留,而实对角矩阵是厄米的。
厄米矩阵具有特殊重要性,因为它们有可能在物理系统中表示可测的实观测量。在量子力学中确实如此。
对于一般问题的回答,不涉及实特征值是该矩阵必须与其复共轭转置交换。
这个条件再次在酉变换下保持不变,并且它是对角线矩阵的一个属性,因为所有对角线矩阵彼此交换,所以它绝对是必要的。
另一个问题是,何时可以通过任何基础变换使矩阵对角化,而不需要关于正交性的任何要求;也就是说,何时存在矩阵 M 的任何类型的特征向量的基?
有一个简单的答案,而且可以很容易地看到是必要的。假设 a[1]、a[2]、...、a[k] 是 M 的 不同特征值。
任何向量都可以写成基向量的和。
如果每个基向量都是 M 的特征向量,对应于特征值 a[j],那么 M - a[j]I 作用于它将得到零向量。
另一方面,对于 a[h] 不同于 a[j] 的情况,M - a[h]I 对其的作用仅仅是将其乘以 a[j] - a[h]。
因此,如果存在由 M 的特征向量组成的基,则 从 1 到 k 的所有 j 的乘积 (M - a[j]I) 必须是零矩阵,因为它在作用于每个基向量时必须得到 0。
这个乘积称为 M 的最小多项式,它为零矩阵的方程称为 M 的最小方程。因此,如果 M 遵循其自己的最小方程,则它具有特征向量的基。
顺便说一下,一个有趣而奇特的事实是 每个矩阵都遵循其自己的特征方程(也就是说,如果您用 M 替换变量 x,您将得到 0 矩阵)。
32.8 计算特征值和特征向量
我们在这里解决以下问题:
1. 我们如何实际计算给定矩阵的特征值和特征向量?
2. 我们如何将我们对矩阵的了解应用到二次函数(也称为二次形式)?以及临界点和鞍点。
3. 我们描述了一种特征向量游戏:学会如何只看一个矩阵就猜出一个特征向量!
如何计算大型矩阵的特征值和特征向量是数值分析中的一个重要问题。我们将仅仅浅尝辄止小矩阵。
查找实矩阵的实特征值有一个明显的方法:您只需写出其特征多项式,绘制它并找到其解。
这在两个维度上很容易做到,在三维或四维上不难,在更多维度上对计算机来说也不是很困难。
这很简单,也很枯燥。
在两个维度中,特征方程为
x² - tr(M)x + det(M) = 0
这个方程可以使用二次方程式求解,特征值可以通过显式公式获得。
在三维中,特征方程为
x³ - tr(M)x² + Ax - det(M) = 0
其中 A 是对角元素对的和减去每个对角线元素对的相反对角线元素的乘积
A = M[11] * M[22] + M[11] * M[33] + M[22] * M[33] - M[12] * M[21] - M[13] * M[31] - M[23] * M[32]
有一个用于解这个方程的立方体公式,但可能更容易找到一个解,比如 z,数值上找到另外两个遵循二次方程

由于特征多项式是三次的,它在大的正和负参数方向上是相反的,所以通过从相同的地方开始并通过分而治之的方法逼近,你可以相对容易地找到任意精度的解决方案。
那么我们如何在给定特征值 z 的情况下找到一个特征向量呢?通常有一个非常简单的答案。通过取 M - zI 的任何一行的余子式,并将它们排列成一列向量,可以获得一个列特征向量。
练习:
32.5 这种方法何时会失败?
32.6 证明如果余子式不全为零,它们会提供一个列特征向量。
32.7 随机选择一个 3×3 矩阵并找到一个特征值及其相应的特征向量。
还有其他方法可以找到通常有效的特征向量和特征值。
一种方法是将矩阵提升到一个高次幂。这比听起来要容易些。
你随后会注意到矩阵的高次幂通常会趋向于具有秩为 1,并且你可以从中读取一行和一列的特征向量。
通过让矩阵作用于你找到的特征向量,你可以很容易地推导出相应的特征值。
如果存在一个特征值的数量级大于其他任何特征值,并且它只有一个特征向量(它不是 M 的特征方程的多重根),那么这种方法通常能够找到它。
你可以应用相同的方法到 M 的逆矩阵,以找到数量级最小的特征值及其特征向量。
在 Excel 电子表格上执行这些操作相对容易,因为它们具有可取两个矩阵的乘积(称为 mmult)、找到矩阵的逆(minverse)和求解矩阵的行列式(mdeterm)的函数。
使用 mmult 很容易将矩阵平方,复制该过程以将其提升到四次方,并复制两个过程将其提升到八次方,然后十六次方;将整个过程复制以提升到 256 次方等等。
对于一个四乘四的矩阵,一旦你有了两个特征值,那么你可以通过求解二次方程得到其余的,并且通常可以通过将 A 和 A^(-1) 提升到高次幂来得到数量级最大和最小的。
当然,一旦你有了数量级最大的特征值,你可以寻找第二大的特征值。这可以通过将 M 的列投影到垂直于第一行特征向量的向量上,并处理得到的矩阵来完成。
当存在两个特征向量具有相同数量级的特征值或几乎相同的特征值时,当然你会遇到问题。
我们如何找到矩阵 A,以便用于对角化 M?
A 的列是 M 的归一化特征向量。
32.9 应用于二次型和弹簧系统
矩阵在前面章节中出现的另一个地方是在讨论多个变量的函数在临界点(函数的梯度为0向量的点)的行为时。
我们随后注意到函数的行为可以由该点的函数的二阶导数矩阵描述。 这是指函数相对于第 i 和 j 个变量的二阶偏导数。
对称矩阵每个都有一个由上面证明的实特征向量组成的标准正交基,可通过正交变换获得。
如果我们检查使用这个基础的形式的矩阵的结构,我们会发现它是对角线的,因此极值的条件变得简单:
如果二阶导数矩阵的所有特征值都具有相同的符号,则函数具有局部极大值或极小值,当它们全部为正时,为极小值。
如果符号混合,则存在一个鞍点,并且当一些特征值为 0 时,有时必须查看更高阶导数。
当谈论二阶导数矩阵时,我们实际上是在谈论描述我们函数关于临界点的 Taylor 级数展开式中的二次项的二次型。
如果我们专注于二次型,我们会意识到我们可以使用更广泛的变换类来改变它们的外观,而在处理变换时我们所能使用的变换类则较少。
因此,我们可以改变各个变量的尺度来使任何正对角二次型变成具有所有(非零)特征值相同的二次型。 (因此,我们可以通过设定  来改变
来改变  )
)
这使我们能够同时对两个不同的二次型进行对角化。您可以将其中一个矩阵变成单位矩阵,然后对另一个进行对角化。
这与变换发生的情况相反。 两个变换必须可交换以同时与相同的基础对角化(显然是必要的,因为所有对角矩阵都可以彼此交换)。
(此声明的证明如下:
对矩阵 M 进行对角化。 您然后可以观察到,M 和 N 可交换的条件是所有 N 的非对角线元素都是相同的,即对角线元素为 M 的 ij-th 链接索引。
因此,如果矩阵 N 的 ij-th 元素非零,则矩阵 M 的第 i 和 j 个特征值必须相同,如果要使 N 和 M 可交换。
如果它们相同,那么就在对角化 N 方面,问题分解成了 M 的每个特征值的部分;对于每个部分,M 是单位矩阵的倍数,并且在 N 的相应块被对角化时保持对角化状态。)
给定一组弹簧和质量,将有一个二次形式代表系统的动量变量的动能,另一个代表系统的位置变量的势能。
上述说明告诉我们,总是可以选择一种规范化和坐标基,使得这两种形式都是对角的。这意味着整个系统可以被分析为一堆独立的简单一维弹簧(每个弹簧可以表示原始坐标的复杂组合)。相应的特征值确定了系统的“正常模式”。
32.10 在电子表格上计算特征值和特征向量
你可以建立一个电子表格,用于找到任何具有三个实特征值的 3x3 矩阵的特征向量,方法如下。你尝试做这个是非常值得的。
首先找到给定矩阵的迹、行列式和第二不变量(A)。
如何做呢?
迹很容易,行列式是 Excel 中的一个单一命令。
在 Excel 中获得第二个不变量也很容易:通过增加一个第四行和列,使其与第一行和列相同,并将第 44 个元素设为与第 11 个元素相同。
然后在第一、二列和行以及第二、三列和行,以及第三、四列和行中找到二乘二对角矩阵。这三者之和就是 A。
然后解特征方程。这可以通过从非常大的值开始,比如 +1000 和 -1000,并使用分而治之的方法逼近解来完成。
然后通过求解前述的二次方程找到另外两个特征值。
它们不会总是存在,因为二次方程的根可能是复数;如果是这样,就把你的矩阵改变为使它们变为实数。
几乎不可能你的矩阵不可对角化,除非两个特征值相同。否则它不会有三个特征向量。
现在找到特征向量。
如何做呢?
下面是一个不错的尝试:写下矩阵 M - zI,其中 z 是你的特征值之一。
通过将第一列复制到第四列,将第二列复制到第五列来扩展矩阵。
然后通过由前两行和列 23、34 和 45 给出的二乘二行列式来找到它们。将这些排列成一列,这应该是你的特征向量。
可能这些二乘二行列式都是 0。如果是这样,你可以尝试用第二和第三行再次尝试,甚至可以将第一行复制到第四行,对第三和第四行做同样的事情。
如果你总是失败,那意味着你有一个双重特征值(至少你的三个特征值中有两个相同)。在这种情况下,特征向量实际上更容易找到。
如果所有的特征值都相同,那么 M 是单位矩阵的倍数,每个向量都是特征向量。
否则,你可以按照描述找到该特征值的列特征向量,并通过交换行和列做同样的事情来找到一个行特征向量。
然后你双重特征值的列特征向量将是与另一个特征值的行特征向量正交的任意向量。
一旦你有了三列特征向量,你可以把它们组成一个矩阵 A,并检查 A^(-1) 和 A^(-1)MA,应该是对角的。(这些在 Excel 中使用 mmult 和 minverse 函数非常容易找到。)
32.11 猜测特征向量
这里是一个你可以在电子表格上设置的游戏。在任意地方输入一个任意的矩阵 M。
从 3x3 开始是一个很好的开始。
输入一个 3 分量列向量 v,并使用 mmult 命令(或自己计算)来计算 Mv,对于 v 的每个分量,计算 的比率。
的比率。
计算这些比率的方差(即它们的平方和减去它们的平方和的平方)。
玩家可以轮流生成原始矩阵 M 和 v;然后他们轮流通过改变 v 的一个分量来修改 v。
如果比率的方差减小,玩家得分一点,否则失去一点。当方差变得可以忽略不计时,游戏结束,比如小于 10^(-10)。
然后,这些比率将会或多或少相同,因此与特征向量相关联的特征值产生。
如果你在这方面太在行,你可以尝试用一个 5x5 的矩阵,尽管一开始输入一个矩阵会很无聊。
第三十三章:二阶微分方程
介绍
这样的方程在物理学中自然而然地产生,因为牛顿的运动方程涉及加速度,而加速度是二阶导数。
我们对这类方程进行一些简要评论,展示它们如何可以用电子表格进行数值求解,并讨论两个具体的例子:强迫谐振子(也描述了 RLC 电路的行为)和行星运动。
主题
33.1 总体评论
33.2 解二阶微分方程
33.3 强迫和阻尼振荡器
33.4 行星运动
33.1 总体评论
我们将考虑包含一个或多个依赖变量和一个单独的自变量的方程,并且我们有依赖变量的二阶导数的表达式。
一些例子是:
强迫阻尼谐振子

电路方程

行星运动

(第二项是另一个行星的影响,其位置将遵循类似的方程。)
钟摆

这两个方程都是线性方程,因为每个项对于依赖变量都是线性的,或者与之无关。
物理学家往往会通过找到变量和第一导数的组合,其时间导数为零,来攻击这类方程(如果可能的话)。这些被称为积分或运动常数。能量、角动量和动量是经常被保守的实体。这些数量的恒定性提供了可以帮助确定运动的方程。
有各种各样的方法用于解决线性微分方程,包括幂级数展开和对函数空间的“转换”。
在这里,我们限制自己指出如何在电子表格上解微分方程。有一整个课程专门研究它们。
33.2 解二阶微分方程
我们假设我们有一个以依赖变量 u 和自变量 t 为参数的二阶微分方程。谐振子或钟摆是很好的例子。我们进一步假设,我们已经给出了 u 和 u' 的初始值,以及一个关于 u、u' 和 t 的 u" 的公式。
u" = f(u, u', t)
如果 f 不涉及 u 或 u',我们可以对方程的两边进行一次积分以找到 u',再次积分以找到 u,其中线性函数 ct + d 必须从初始值中确定。
因此,我们面临的问题与执行双重积分的问题类似。然而,在电子表格上做到这一点非常容易。
我们将使用梯形法则的精度阶数的近似技术;通过类似大多数数值方法的外推可以获得改进。
我们首先描述基本方法。
我们将使用一列来表示变量 t、u、u'和 u"。这三个变量中的前三个将从这些变量的给定初始值开始;并且可以从它们计算出 u"的初始值。
在每一行中,t 将以一个常数 d 的增量增加。(当变量在一个 d 间隔内变化太大时,你可以选择使 d 比你的初始选择更小。)
我们将设定

(这些是独立于方程本身的通用声明。)
最后,我们提供了一个 u"(t + d)的表达式。在这样做时,我们不能使用 u(t + d)或 u'(t + d),否则我们的定义会循环。另一方面,我们希望使用一些东西来平均时间间隔内 t 和 t + d 之间的二阶导数(至少到某个阶数),就像上面对 u 和 u'做的那样。对于 t 处的 u"的值,我们使用 f(t, u(t), u'(t))。对于 t + d 处的 u"的值,我们使用
u"(t + d) = f(t + d, u(t) + d * u'(t), u'(t) + d * f(t, u(t), u'(t)))
因此,我们使用定义在 t 处并在 t + d 处评估的 f(t + d, u, u')对 u 和 u'进行线性近似。通过使用二次近似可以稍微改进。

这将是正确的到二阶,但是梯形法则已经在二阶出现错误,所以通常不会有太大好处。
你可以通过绘制前三列(使用电子表格程序的"图表"功能与 xy 散点图)来观察 u 和 u'作为 t 的函数的行为。通过绘制第二和第三列,即 u' vs. u,你可以观察解的"相平面"行为。
如果你做得对,你可以在一个按键中更改 d 或 f 中的参数,并观察当你更改它们时解的变化。
你可以通过相同的方法处理具有多个因变量的方程,比如行星运动的方程;在 xy 平面上的运动可以有一个列对应于 t、x、y、x'、y'、x"和 y",并且可以观察轨迹并随着参数的变化观察 xy 平面上的行为。
通过改变 d,并观察你得到的解变化的程度,你可以对其准确性有一个很好的想法。
33.3 强迫和阻尼振荡器
这个系统遵循以下方程

要在电子表格上设置这个,我会在前几行留出一个地方来输入常数和初始条件;这些是 t[0]、x(t[0])、x'(t[0])、m、k、f、c 和 w。
然后,我会为每个 t、x、x'和 x"分配一列,首先输入初始条件,然后使用上面的公式从前一个值得到每个新值。
I like to set the second t value to t[0] + d, and then all subsequent ones to twice the previous value minus the value two before  which means that the intervals in t all have the same size.
which means that the intervals in t all have the same size.
The following chart shows how the setup might look on a spreadsheet
| Column A | Column B | Column C |
|---|---|---|
| M= | 1 | |
| k= | 1 | x0= |
| f= | 0.3 | u0= |
| d= | 0.01 | u'0= |
| c= | 1 | |
| w= | 1.5 | |
| x | U | u' |
| =D3 | =D4 | =D5 |
| =A10+B5 | =B10+(A11-A10)*(C10+C11)/2 | =C10+(A11-A10)*(D10+D11)/2 |
| =2*A11-A10 | =B11+(A12-A11)*(C11+C12)/2 | =C11+(A12-A11)*(D11+D12)/2 |
| =2*A12-A11 | =B12+(A13-A12)*(C12+C13)/2 | =C12+(A13-A12)*(D12+D13)/2 |
| =2*A13-A12 | =B13+(A14-A13)*(C13+C14)/2 | =C13+(A14-A13)*(D13+D14)/2 |
| =2*A14-A13 | =B14+(A15-A14)*(C14+C15)/2 | =C14+(A15-A14)*(D14+D15)/2 |
| =2*A15-A14 | =B15+(A16-A15)*(C15+C16)/2 | =C15+(A16-A15)*(D15+D16)/2 |
| =2*A16-A15 | =B16+(A17-A16)*(C16+C17)/2 | =C16+(A17-A16)*(D16+D17)/2 |
| =2*A17-A16 | =B17+(A18-A17)*(C17+C18)/2 | =C17+(A18-A17)*(D17+D18)/2 |
| =2*A18-A17 | =B18+(A19-A18)*(C18+C19)/2 | =C18+(A19-A18)*(D18+D19)/2 |
| =2*A19-A18 | =B19+(A20-A19)*(C19+C20)/2 | =C19+(A20-A19)*(D19+D20)/2 |
| =2*A20-A19 | =B20+(A21-A20)*(C20+C21)/2 | =C20+(A21-A20)*(D20+D21)/2 |
| =2*A21-A20 | =B21+(A22-A21)*(C21+C22)/2 | =C21+(A22-A21)*(D21+D22)/2 |
| =2*A22-A21 | =B22+(A23-A22)*(C22+C23)/2 | =C22+(A23-A22)*(D22+D23)/2 |
| =2*A23-A22 | =B23+(A24-A23)*(C23+C24)/2 | =C23+(A24-A23)*(D23+D24)/2 |
| =2*A24-A23 | =B24+(A25-A24)*(C24+C25)/2 | =C24+(A25-A24)*(D24+D25)/2 |
| =2*A25-A24 | =B25+(A26-A25)*(C25+C26)/2 | =C25+(A26-A25)*(D25+D26)/2 |
| =2*A26-A25 | =B26+(A27-A26)*(C26+C27)/2 | =C26+(A27-A26)*(D26+D27)/2 |
Column D is here
| Column D |
|---|
| 0 |
| 1 |
| 0 |
| =MIN(B1000:B2000) |
| u" |
| =(-$B\(3*B10-\)B\(4*C10+\)B\(6*SIN(\)B\(7*A10))/\)B$2 |
| =(-$B\(3*(B10+(A11-A10)*C10)-\)B\(4*(C10+(A11-A10)*D10)-\)B\(6*SIN(\)B\(7*A11))/\)B$2 |
| =(-$B\(3*(B11+(A12-A11)*C11)-\)B\(4*(C11+(A12-A11)*D11)-\)B\(6*SIN(\)B\(7*A12))/\)B$2 |
| =(-$B\(3*(B12+(A13-A12)*C12)-\)B\(4*(C12+(A13-A12)*D12)-\)B\(6*SIN(\)B\(7*A13))/\)B$2 |
| =(-$B\(3*(B13+(A14-A13)*C13)-\)B\(4*(C13+(A14-A13)*D13)-\)B\(6*SIN(\)B\(7*A14))/\)B$2 |
| =(-$B\(3*(B14+(A15-A14)*C14)-\)B\(4*(C14+(A15-A14)*D14)-\)B\(6*SIN(\)B\(7*A15))/\)B$2 |
| =(-$B\(3*(B15+(A16-A15)*C15)-\)B\(4*(C15+(A16-A15)*D15)-\)B\(6*SIN(\)B\(7*A16))/\)B$2 |
| =(-$B\(3*(B16+(A17-A16)*C16)-\)B\(4*(C16+(A17-A16)*D16)-\)B\(6*SIN(\)B\(7*A17))/\)B$2 |
| =(-$B\(3*(B17+(A18-A17)*C17)-\)B\(4*(C17+(A18-A17)*D17)-\)B\(6*SIN(\)B\(7*A18))/\)B$2 |
| =(-$B\(3*(B18+(A19-A18)*C18)-\)B\(4*(C18+(A19-A18)*D18)-\)B\(6*SIN(\)B\(7*A19))/\)B$2 |
| =(-$B\(3*(B19+(A20-A19)*C19)-\)B\(4*(C19+(A20-A19)*D19)-\)B\(6*SIN(\)B\(7*A20))/\)B$2 |
| =(-$B\(3*(B20+(A21-A20)*C20)-\)B\(4*(C20+(A21-A20)*D20)-\)B\(6*SIN(\)B\(7*A21))/\)B$2 |
| =(-$B\(3*(B21+(A22-A21)*C21)-\)B\(4*(C21+(A22-A21)*D21)-\)B\(6*SIN(\)B\(7*A22))/\)B$2 |
| =(-$B\(3*(B22+(A23-A22)*C22)-\)B\(4*(C22+(A23-A22)*D22)-\)B\(6*SIN(\)B\(7*A23))/\)B$2 |
| =(-$B\(3*(B23+(A24-A23)*C23)-\)B\(4*(C23+(A24-A23)*D23)-\)B\(6*SIN(\)B\(7*A24))/\)B$2 |
| =(-$B\(3*(B24+(A25-A24)*C24)-\)B\(4*(C24+(A25-A24)*D24)-\)B\(6*SIN(\)B\(7*A25))/\)B$2 |
| =(-$B\(3*(B25+(A26-A25)*C25)-\)B\(4*(C25+(A26-A25)*D25)-\)B\(6*SIN(\)B\(7*A26))/\)B$2 |
| =(-$B\(3*(B26+(A27-A26)*C26)-\)B\(4*(C26+(A27-A26)*D26)-\)B\(6*SIN(\)B\(7*A27))/\)B$2 |
| =(-$B\(3*(B27+(A28-A27)*C27)-\)B\(4*(C27+(A28-A27)*D27)-\)B\(6*SIN(\)B\(7*A28))/\)B$2 |
| =(-$B\(3*(B28+(A29-A28)*C28)-\)B\(4*(C28+(A29-A28)*D28)-\)B\(6*SIN(\)B\(7*A29))/\)B$2 |
| =(-$B\(3*(B29+(A30-A29)*C29)-\)B\(4*(C29+(A30-A29)*D29)-\)B\(6*SIN(\)B\(7*A30))/\)B$2 |
结果如下所示
| mu" = -ku-fu' -c sin wx | ||
|---|---|---|
| m= | 1 | |
| k= | 1 | x0= |
| f= | 0.3 | u0= |
| d= | 0.02 | u'0= |
| c= | 1 | |
| w= | 1.5 | min u in st state |
| 1 | � | |
| x | u | u' |
| 0 | 1 | 0 |
| 0.02 | 0.9997976 | -0.020239955 |
| 0.04 | 0.999185688 | -0.040951318 |
| 0.06 | 0.99815498 | -0.062119497 |
| 0.08 | 0.996696465 | -0.083731975 |
| 0.1 | 0.994801389 | -0.105775593 |
| 0.12 | 0.992461268 | -0.128236563 |
| 0.14 | 0.989667897 | -0.15110048 |
| 0.16 | 0.986413369 | -0.174352335 |
| 0.18 | 0.98269008 | -0.197976528 |
| 0.2 | 0.978490746 | -0.221956881 |
| 0.22 | 0.973808411 | -0.246276653 |
| 0.24 | 0.968636459 | -0.270918551 |
| 0.26 | 0.962968626 | -0.29586475 |
使用 Excel,我们可以通过选择前三列和第二列和第三列的 xy 散点图来展示图形。
意识到如果这样做,您可以在变化参数时实时观察发生的情况。
**练习 33.1 当 k = m = 1 且 c 非零时,找到频率 w,使得 f = 0.1 时周期稳态 u 幅度最大。 (通过分治法逼近它。)
对于 k = 2,m = 1,做同样的事情。**
33.4 行星运动
行星和太阳之间的引力相互作用由反比例中心力定律描述。
我们假设行星比太阳轻得多,因此我们可以想象太阳固定在系统中心,而行星围绕其运动。实际上,我们可以通过相对于系统质心的运动来避免这种假设,但我们不会费心这样做。
因此,我们认为太阳位于原点,坐标为(0, 0, 0)。
我们选择我们的坐标,使得行星在初始时间 t[0] 处于位置 (1, 0, 0),并且在那个时间,它的运动在 xy 平面上,也就是我们指的平面遵循z = 0。
因为行星经历的加速度始终指向太阳(原点),所以行星永远不会离开该平面,我们可以完全忽略一切的 z 分量。
这是一个经验事实,所有行星的运动都以相同的平面为近似,因此即使考虑到其他行星的引力影响,也可以用二维来描述。
物理学家通过定义守恒量(能量、动量和角动量),并使用这些值和属性来表征运动来解决这个问题。
我们的方法过去被认为是一种不可能的蛮力方法,但现在实现起来相当容易,并且为关于此问题的标准处理提供了一种令人耳目一新的补充,我们建议任何关于力学和重力下运动的标准文本。
行星的实际行为已被天文学家仔细观察了几个世纪,并且在开普勒的三大定律中得到了简洁的总结,如下所示:
1. 受相同力的行星和其他物体的运动是"圆锥曲线"轨道:椭圆或双曲线,或在非常特殊的情况下为抛物线(都以太阳为焦点),或者直线。
2. 每个轨道单位时间内扫过的面积是恒定的。
3. 椭圆轨道的周期与其半径的度量之间存在一定的具体关系,我们将不再讨论这种关系。
关于圆锥曲线、角动量守恒和开普勒第二定律
我们在这里限制自己仅展示如何在电子表格上数值地积分运动方程,并且如何绘制结果。通过这样做,你可以将 x 或 y 或 r 作为时间的函数或系统轨道来观察。
我们将看到,处理这不比处理单个一阶微分方程更困难。它与其相同之处在于它是一个二阶方程,并且我们有两个依赖变量,x 和 y,它们将是时间 t 的函数。
我们要解决的微分方程是

受初始条件r(0) = (1, 0, 0)和 的约束,其中你选择 p 和 q。
的约束,其中你选择 p 和 q。
我们使用单位使得 MG 为 1,为方便起见,但你不需要这样做,也不需要从(1, 0, 0)开始。
为了解决它,我们将 A 列用于变量 t,B 列用于 x,C 列用于 y,
我们所要做的就是在这些方程中一次插入初始条件和变化条件,并复制下来,我们就得到了我们的解。
那么我们在各列中放入什么呢?
我会从第 11 行开始操作,留下前 10 行用于注释、常数(稍后可以更改)、初始条件和基本时间间隔 d。
每个变量的初始条件可以输入到适当列的第 11 行中。
我们首先给出了做所有这些的最简单方法:
A 列:时间列 a11 = t[0], a12 = a11+b2. a13 = 2*a12-a11, 复制 a13。
B 列:x 列 b11 = x[0],b12 = b11 + e11*($b$2),复制此公式到下方的 C 列。
C 列:y 列 c11 = y[0],其余内容来自 B 列。
D 列:r 列 d11 =sqrt(b11bb11+c11c11),将其向下复制。
E 列:x 点列:e11 = dx/dt(t[0]),e12 = e11 + ($b$2)*g11,向下复制并复制到 F 列。
F 列:y 点列:f11 = dy/dt(t[0]),其余内容来自 E 列。
G 列:x 二次导数列 g11 = - b11*($d11³),向下复制并复制到 H 列。
就是这样了。
要查看轨道图,请突出显示 B 列和 C 列,然后在它们上面制作 xy 散点图。
练习 33.2 为不同的初始条件做这个,看看你得到的轨道是什么样子的(尽可能使每列尽可能长。改变 d 以获得不同的准确度)。
是否可能获得更高的准确度?
上述描述的程序类似于左手规则,同样不准确。只需稍微多花点力气,您就可以获得梯形质量的准确度。(当然,如果您真的想要,可以进行外推。)
怎么做?
通过改变 b12 来改变 B 和 C 列中的条目
b12 = b11 + (e11+e12)*($b$2)/2
并将其向下复制到右边到 C 列。
通过改变 e13 来类似地改变 E 和 F
e13 = e12 + ($b$2)(2g12-g11)
并将其向下复制到右边到 F 列。
你甚至可以通过进行更复杂的变化来做得更好。
要想了解更多,你应该学习数值方法。
这种方法可能失败吗?
是的,会。
当行星距离太阳太近时,第二导数将会变得很大,以至于在单个时间间隔内的各种变化将被非常糟糕地近似。这将导致能量的大幅变化,而行星将跳转到非常不同的轨道。
使用更小的时间间隔可以缓解这个问题。
复习练习 1 - 4
1. 给出以下五个向量:A = (1, 2, 3);B = (2, -3, 5);C = (x, y, z);D = (cos t, sin t, t²);E = (-2, 1, 0)。
分别完成以下任务:
a) 形成和:A + B + C。
b) 计算A B。
B。
c) 计算A (B+C)。
(B+C)。
d) 找到使得CA = 0 和CB = 0 的 x、y 和 z 的值。
e) 找到A和B之间的夹角的余弦。以及B和D之间的夹角(答案将是 t 的函数)。
f) 找到E在B上的投影。
g) 找到列是A, B和E的行列式;还找到列是A, B和C的行列式。
h) 假设点 P 的坐标为 x = 1,y = 2,z = 3。其球坐标为  ,
,  和
和  是多少?
是多少?
i) 具有边缘A, B和E的平行六面体的体积是多少?
j) 找到D在 xy 平面上的投影。其长度是多少?
2. 考虑上述点 A 和 B 所在的直线。
a) 给出该直线上点的参数表示。
b) 找到指向该直线方向的单位长度“切向量”。
c) 找到与该向量正交的两个方向。
d) e) 和 f) 考虑包含点 A, B 和 E 的平面:
找到平面的(双参数)参数化表示。
找到平面的法向量。
找到平面上所有点的方程。
g) 假设我们有一个新的、不同的向量积V@W,满足性质V@V = 0对于所有V,并且@在每个参数上都是线性的,以便可以应用分配律。
通过对(V + W)@(V + W)应用相同的方法,推导出关于V@W + W@V的一些结论。
3. 分别对以下函数进行相对于指定变量的求导:
a) sin (2^x)。
b) 对于固定的 y,(sin xy)e^(x+y) 关于 x 求解。
c) 对于固定的 x,对于 y 求解 x² + y² - 3xy。
d) 对于其他所有固定项,对 (sin (y + s sin t))e^(-(x+s cos t)) 求解 s。
e) 找到 (sin y)e^(-x) 的梯度。
f) 在单位向量为 (cos t, sin t) 的方向上找到这个函数的方向导数。
g) 在 x = 0 处找到 sin (e^x) 的线性近似。
h) 求解(rv)关于 t 的导数,其中 v 是  ;假设
;假设  沿着 r 的方向。那么答案是什么?
沿着 r 的方向。那么答案是什么?
i)  在哪里不可微?tan x 在哪里不可微?
在哪里不可微?tan x 在哪里不可微? 在哪里不可微?
在哪里不可微?
j) 求解 sin (e^x) 的反函数的导数(为了完全定义一个反函数,你必须指定一个范围;在这里忽略)。
4.
a) 找到函数的梯度 
b) 找到  的梯度。
的梯度。
c) 找到 cos 和 的梯度。
d) 找到 (y, z, x) 的旋度。
e) 找到  的散度。
的散度。
f) 找到相同函数的旋度。
5. a) 在 x = 1, y = 2(弧度)处找到 sin xy 的二次近似。
b) 这个函数在哪些临界点具有临界点(两个偏导数均为 0)。
c) 找到至少一个鞍点。
d) 通过交换点积和叉积,并按照相同的规则表达三重叉积,评估(ab)(ab),以获得完全基于点积的另一种表达。
e) 以下哪些函数可以在 x = 0 处定义? 
第 A 章:级数求和魔法
假设我们有一个形如

或更一般地说

对于

并想找出它的总和。
我们应该怎么做呢?
另一个问题:仅使用系列的前 5 项,或前 25 项,我们可以有多精确地求和?
答案相当惊人。你仅从前五项就可以得到比三位小数更精确的答案,而从前 25 项可以得到十位小数的答案!而且轻而易举。(通过增加更多项也可以获得更高的精度。)
如何?
显然,仅计算系列的前五项或前 25 项的部分和并将系列总和估算为第五项或第 25 项的部分和是不够的。但计算这些部分和并从中估算总和是足够的。
如何?
你可以使用电子表格轻松计算部分和。(将 A3=A2+1,B1= x 的值,C1= y 的值,B3=-(-$B\(1)^A3)/(A3)^\)C$1,以及 C3=C2+B3,并向下复制 A3、B3 和 C3,你就能在 C 列得到你的部分和。)
一旦你有了它们,你会发现奇数部分和形成一个递减序列,而偶数部分和形成一个递增序列。因此,序列和被任意一对连续部分和的值所夹住。因此,奇数部分和给出了序列和的上限,而偶数部分和给出了下限;尽管对于 x = 1,y = 1 来说这些边界会变得越来越好,但是增长速度相当缓慢。
这意味着如果你取相邻部分和的平均值,你会比它们中较差的更接近答案,因为一个明显在答案上方,一个在下方。
这些特定系列以及其他一些系列所拥有的奇特属性是,在对相邻部分和求平均后,相同的属性仍然成立:奇数项递减,偶数项递增,就像当项是相邻部分和(或相邻部分和的平均值,等等)的平均值时一样。
这意味着如果你对这些进行平均,你会更接近答案,如果你继续平均,你会永远更接近,或者直到你的机器的精度达到答案。
如何进行所有这些平均计算?只需输入 D3=(C3+C4)/2,然后将 D3 复制到以 D3 和 AE30 为角的矩形中即可。
你可以从第 3 行的条目中估算总和。当然,随着你向下进行,估计会变得更好,但每次向下移动一次,你就使用一个更进一步的部分和,因此如果你只想使用信息到第 k 个部分和,你可能就从第 C 行向右移动 k - 1 步了。 (你实际上可以做得更好,但谁在乎呢。)
你可以通过将该结果与同一对角线上的前一个结果平均来稍微提高一点。因此,与其使用 G3 作为估计值,不如使用 (G3+F4)/2. 这两种方法都利用了 E5 中的信息,因此 D6 和 C7 中的信息来自于序列中的前五项。
对于原始求和,x = 1,y = 1,在仅使用序列中的前 k 项的情况下,我们得到的最佳估计如下
| k 值 | 估计值 | 估计值来源 | 真实答案 | % 误差 |
|---|---|---|---|---|
| 1 | 1 | C3 | 0.693147... | 44.27 |
| 2 | 0.625 | D3/2+C4/2 | 0.693147 | 9.8316 |
| 3 | 0.6825 | E3/2+D4/2 | 0.693147 | 0.8147 |
| 4 | 0.692708 | F3/2+E4/2 | 0.693147 | 0.0633 |
| 5 | 0.693229 | G3/2+F4/2 | 0.693147 | 0.0118 |
换句话说,从前 5 项估算这个和的误差约为百分之一百分之一。
当 k 较大时,最好使用稍微不同的估计值(在更高的行中;即,对几项求和,然后开始平均),你可以仅查看序列的前 20 项即可将精度提高到 10¹⁰ 中的一部分。
粗略地说,在指定范围内,对于任意 x 和 y,可能都可以获得几乎相同或更好的精度。
**练习 A.1 让朋友选择一个 x 和 y 的值,并计算序列的前五项,其中第 j 项为  。
。
使用上述描述的方法仅使用此信息估算序列的和。然后让朋友使用指定的方法和 k 值为 50 来确定和的高精度,并找出你的估计误差。(如果运气好的话,你的答案将准确到千分之一,你的朋友将愿意打赌你无法仅从五项中获得这样的精度。)**
章节 B:行列式的乐趣
我们在第四章中讨论了行列式,再次在第三十二章中讨论了它。我们讨论了几种计算行列式的方法,原则上并不困难,但是如果你想手动进行,那么实际上是很烦琐的。
在这里,我们提供了一些思路,可以让我们用比写出矩阵还要少的工夫推导出几种特殊类型矩阵的行列式(虽然它们偶尔会有用)。
我们还提供了一个奇特的涉及行列式的公式,这个公式是由爱丽丝梦游仙境的作者刘易斯·卡罗尔发现的,并且基于它提出了一个神奇的计算行列式甚至逆的算法,几乎没有任何努力。
1 一些易于计算的行列式。范德蒙德行列式
当一个矩阵的元素是某些变量集合中的单项式甚至多项式时,那么它的行列式一般将是这些变量的多项式,并且这有时对于求值是有用的。
这个的典型例子是所谓的范德蒙德矩阵,其行(或者如果你愿意,列)的形式都是(1,x[j],x[j]²,x[j]³,...,x[j]^(n-1))对于某个 x[j]。
这是一个示例

通过行列式的基本性质,如果它的两行相同,则我们可以推断出范德蒙德矩阵的行列式在任意两行相同时为 0。
但是这意味着,作为一个多项式,它必须有(x[i] - x[j])作为一个因子,对于每一个 i 和 j。
这意味着这样的一个行列式必须有 作为一个因子,这里的乘积是对所有 i > j 的变量对进行的。
作为一个因子,这里的乘积是对所有 i > j 的变量对进行的。
这个因子已经是一个次数为 的多项式了(我们在处理一个 n 乘 n 的矩阵)。
的多项式了(我们在处理一个 n 乘 n 的矩阵)。
那么我们的范德蒙德行列式作为一个多项式的次数是多少?
好吧,它是条目的总和,每个条目都有每列的一个因子。因此,作为一个多项式,它的次数是 0 + 1 + ... + n - 1,即。
因此,由于我们已经看到我们的行列式必须有这个次数的一个因子,我们已经将我们的行列式评估为一个多项式,直到一个常数因子。
那么那个常数是什么呢?我们可以通过查看主对角线项来检查它:即
x[1]⁰x[2]¹x[3]²...x[n]^(n-1)
这正是我们从上述乘积的每个因子中取出第一个(正的)项所得到的。
由于这两项在行列式和乘积中具有相同的系数 1,因此乘积就是行列式,这就是我们的答案。
在我们的例子中,我们可以立即推断出行列式是 211,即 2。
2 另一个简单的例子:柯西行列式
这里有一个例子:对于 x 值 1、2、4 和 y 值 1、2、3

现在我们没有一个多项式,而是有一个关于我们变量的有理函数。
我们该怎么办?我们通过因式分解所有分母将其变成一个多项式!
同样,我们知道,如果任何两个 x 变量相同,或者任何两个 y 变量相同,它将为 0,因为这将使两行或两列相同。
因此,它必须在分子中有 的因子。
的因子。
每对索引较大的变量都有一个乘积。
在分母中,对于每一对变量,我们将有 。
。
注意,分子在我们的变量中已经有 n(n - 1)次,而分母有 n²次,比分子的次数多 n。
行列式也是如此,其所有项都是 n 个因子的乘积,每个因子在分母中有一个项,在分子中没有,因此分母中有 n 个多余的项。
实际上,到目前为止我们有的公式

前两个乘积是变量对,第一个变量具有更大索引,而分母中的乘积是所有对,这就是我们要找的行列式。
我们可以通过设置 x[j] = -y[j]来验证这一点,在这种情况下,分子中的乘积项变为矩阵中的非对角线项,并且这些与分母中的类似项相互抵消,我们最终得到分母中的 ,正是我们从行列式的对角线项中得到的。
,正是我们从行列式的对角线项中得到的。
在我们的例子中,我们可以推断我们的行列式为 (其中包括除了与分子相消的一个因子 12 之外的所有分母)。
(其中包括除了与分子相消的一个因子 12 之外的所有分母)。
**练习 B.1 还有一个更有名的例子,我们给你作为练习:
考虑一个矩阵,其(j, k)元素为 x[j],如果 j > k,则为 y[j]。
对于一个 3x3 矩阵,这看起来像**

找出它的行列式公式。(注意它是一个多项式,是几次多项式?在这些变量中什么时候为 0?你可以从这些问题的答案中得出答案。)
例如,考虑矩阵

你可以立即推断其行列式为 643 或 72。
3 路易斯·卡罗尔定理
二维矩阵行列式的公式

是
a[11]a[22] - a[12]a[21]
查尔斯·道奇森(路易斯·卡罗尔,《爱丽丝梦游仙境》的作者)在每个维度中找到了这个公式的类似物。
我们引入以下符号:让A[i,j]是从 A 中去除其 i-th 行和 j-th 列后获得的矩阵的行列式。如果我们省略两行和相应的列,则让 A[ij,ij]是剩下的部分的行列式,这在二维情况下什么都没有(其行列式我们定义为 1)。
然后对于一个二维矩阵 A,如上所述,我们有 A[2,2] = a[11],A[1,2] = a[21]等等。
我们上面的二维公式可以写成
(Det A) A[jk,jk] = A[kk]A[jj] - A[jk]A[kj]
(请记住,在这种情况下,因子 A[ij,ij]被定义为 1。)
就是这个公式是多次公式。他注意到,并证明,如果你选取任意两个不同的指标(比如 j 和 k)用于一个 n x n 矩阵,你会得到相同的结果
(Det A) A[jk,jk] = A[kk]A[jj] - A[jk]A[kj]
这个公式除以 A[jk,jk],给出了一个 n 乘 n 的行列式,其用更小尺寸的行列式来表示。
因此它可以用行列式的递归定义来使用。(如果你把 0 乘 0 的行列式定义为 1,把一个数字的 1 乘 1 的行列式定义为它本身,你可以使用这个定义来定义所有更高维度的行列式,只要 A[jk,jk]不为 0。)
练习 B.2 通过解决一个一般性的例子来验证 3x3 矩阵的正确性。
不仅可以这样定义行列式,而且还可以使用电子表格高效地和不可思议地计算它。
我把用于做这个的算法称为疯帽子算法。它非常高效,但有一个问题。
算法是什么?
我们构建由连续的行和列组成的所有子矩阵的行列式。
矩阵本身是一个一个行列式的矩阵。这些有 n²个。
从这些中,我们使用 Dodson 形式中的普通二维行列式公式计算(n - 1)²个 2x2 连续的行和列子行列式。
并使用同样的规则,即

我们计算所有(n-2)²个 3x3 连续的行和列子行列式,从 2x2 和 1x1 的开始;
并继续,直到我们有 4 个 n-1 乘 n-1 连续的行和列子行列式,最后一个完整的行列式。
这听起来像一个巨大的项目,但如果我们从一个 1 的方形块开始表示 0 乘 0 的行列式,然后在它下面输入我们的矩阵,我们可以用一个复制到我们的矩阵下方和下方的指令来完成所有工作。
假设,例如,我们在方框 a2 中插入 1,并将其复制到以 a2 和 j10 为角的矩形中,并在以 a11 为左上角的矩阵中输入。
(输入一个 10x10 矩阵非常无聊。我建议尝试 4x4 或 5x5 甚至 3x3。如果你想超过 10x10,你需要在顶部添加更多的 1。)
现在在方框 a21 中输入=(a11b12-a12b11)/b2
并将其复制到以 a21 和 i110 为角的矩形内。
如果你的行列式是 j 乘 j 的,它应该神奇地出现在第 a 列和第 10j+1 行的框中。
不仅如此,
如果你将j 乘 j 矩阵扩展到其后复制了前 j-1 行,然后将前 j-1 列复制到其右边,以 b 列和第 9j+2 行为左上角的 j 乘 j 框将是当 j 为奇数时的余子式矩阵,当 j 为偶数时的交替符号反转的余子式矩阵。
这真的有效吗?
如果你的矩阵足够丑陋,它就会奏效。也就是说,如果它没有任何 0 的条目,并且你在形成答案时所除的相关子行列式都不为 0,那么它就会奏效。但是如果你在形成答案时除以 0,它就会失败。
这会发生吗?
对于一个三乘三矩阵 M,只有当中间元素 m[22]为 0 时才会发生。
如果你已经将它的前两行复制到右边,它将只在所有三次尝试中失败(你将在 a31、b31 和 c31 中得到潜在答案),只有当中间行完全由零组成时,行列式才为 0。
对于一个四乘四的矩阵,如果中间元素 m[22]、m[23]、m[32]、m[33]中的任何一个为 0,或者它们的行列式为 0,则会失败;等等。
我们能使它真正起作用吗?
是的!但这需要做一些事情,这并不那么巧妙。
做什么?
我不确定该做什么是最好的。通常有效的一件事是用非常小的东西替换矩阵的零(以及在子行列式中出现的任何后续的 0),然后你可以让那个非常小的东西趋向于 0。
例如,你可以在 b1 中放入一个像 10^(-8)这样的微小数,保持一个行索引 j 和列索引 k,并将$ b$1*(j+k+1)添加到原始矩阵中。有了运气,这将消除所有的零,一切都应该正常工作。
当然,你的答案会略有偏差。然后你可以四舍五入你的答案或者改变 b1 中的内容来找出答案(你可能想到更好的办法)。
上面的建议会消除你原始矩阵中的 0,但其他 0 可能会出现在子行列式中,尽管这种情况应该很少发生。如果你担心这一点,你应该用以下基本指令替换
=if( a11b12=a12b11, $b$1, (a11b12-a12b11)/b2))
你的朋友们都不会相信你能如此整洁地评估行列式,如果你激励他们输入尽可能丑陋的矩阵,他们也不会发现除以 0 的缺陷。然后它就不会有让人讨厌的零来除。
另一方面,你有能力通过创建一个方法将要除以 0 的矩阵来使朴素的算法失败。
练习 B.3 设置这个并让它起作用,并使用它得到一个 4 乘 4 矩阵的余子式矩阵。
如果你只想评估 3 乘 3 的矩阵和叉乘,那么设置就简单得多。
就是这样
步骤 1
在 b1、b2、c1、c2、d1、d2、e1、e2 中输入 1(可以通过在 b1 中输入 1 然后复制到其余部分来完成)。
步骤 2
在 a3 a4 a5, b3 b4 b5 和 c3 c4 c5 中输入你的矩阵,或者在 a3 b3 c3 和 a4 b4 c4 中输入你想要进行叉乘的两个向量(第 5 行可以是任意内容)。
步骤 3
在 d3 中输入 =a3,然后将其复制到 d3、d4、e3 和 e4。
步骤 4
在 a6 中输入 = (a3b4-a4b3)/b1,然后将其复制到 a6 到 d6、a7 到 d7、a8 到 d8、a9 到 d9。
叉乘结果将出现在 b6、c6 和 d6 中。
并且在 a9、b9 和 c9 中的一个或全部中计算行列式。
如果没有数字出现,则行列式为 0。
顺便说一句,如果行列式为 0,那么(b7, c7, d7) 和 (b6, c6, d6)如果不全为零,则是你的矩阵的列特征向量,对应的特征值为 0。
如果你需要计算叉乘或行列式,用这种方法检查答案是一个很好的主意。
术语表
| i | 负一的平方根。 |
|---|---|
| f(x) | 函数 f 在参数 x 处的值。 |
| sin x | 参数 x 处正弦函数的值。 |
| exp x | 参数 x 处指数函数的值。通常写作 e^x。 |
| a^x | 数字 a 的 x 次幂;对于有理数 x,由反函数定义。 |
| ln x | exp x 的反函数。 |
 |
同 a^x。 |
 |
为了得到 a,必须将 b 提高到的幂; |
| cos x | 参数 x 处余弦函数的值(正弦的补角)。 |
| tan x | 计算结果为  |
| cot x | 切函数的补值或  |
| sec x | 正割函数的值,结果为  |
| csc x | 补正割的值,称为余割。其值为  |
| asin x | 在参数 x 处正弦函数的反函数值 y。意味着 x = sin y。 |
| acos x | 在参数 x 处余弦函数的反函数值 y。意味着 x = cos y。 |
| atan x | 在参数 x 处正切函数的反函数值 y。意味着 x = tan y。 |
| acot x | 在参数 x 处余切函数的反函数值 y。意味着 x = cot y。 |
| asec x | 在参数 x 处反正割函数的值 y。意味着 x = sec y。 |
| acsc x | 在参数 x 处余割函数的反函数值 y。意味着 x = csc y。 |
 |
角度的标准符号。除非另有说明,以弧度表示。特别用于描述三维空间中点的  ,其中 x、y 和 z 是用来描述点的变量。 ,其中 x、y 和 z 是用来描述点的变量。 |
| i, j, k | 分别是 x、y 和 z 方向的单位向量。 |
| (a, b, c) | 具有 x 分量 a,y 分量 b 和 z 分量 c 的向量。 |
| (a, b) | 具有 x 分量 a,y 分量 b 的向量。 |
| (a, b) | 向量 a 和 b 的点积。 |
 |
向量 a 和 b 的点积。 |
 |
向量 a 和 b 的点积。 |
| |v| | 向量 v 的大小。 |
| |x| | 数字 x 的绝对值。 |
 |
用于表示求和,通常索引和结束值会写在下面,并且上面写着上限。例如,j=1 到 n 的求和写作  ,表示 1 + 2 + ... + n。 ,表示 1 + 2 + ... + n。 |
| M | 用于表示数字或其他实体的矩阵或数组。 |
| |v> | 列向量,其分量以列形式书写并视为 k 乘 1 矩阵。 |
| <v| | 以行形式书写的向量,或者 1 乘 k 矩阵。 |
| dx | 变量 x 的“微小”或非常小的变化;同样也有 dy、dz、dr 等。 |
| ds | 距离的微小变化。 |
 |
在球坐标中到原点的变量 或距离。 或距离。 |
| r | 在三维空间或极坐标中到 z 轴的变量 或距离。 或距离。 |
| |M| | 矩阵 M 的行列式(其大小为由其列或行确定的平行区域的面积或体积)。 |
| ||M|| | 矩阵 M 的行列式的大小,即体积、面积或超体积。 |
| det M | 矩阵 M 的行列式。 |
 |
矩阵 M 的逆。 |
 |
两个向量v和w的向量积或叉积。 |
 |
向量v和w所成的角度。 |
 |
标量三重积,由列 A、B、C 形成的矩阵的行列式。 |
 |
指向向量w方向的单位向量;与 意思相同。 意思相同。 |
| df | 函数 f 的微小变化,足够小以至于所有相关函数的线性近似对这些变化成立。 |
 |
f 关于 x 的导数,即 f 的线性近似的斜率。 |
| f ' | f 关于相关变量(通常为 x)的导数。 |
 |
f 关于 x 的偏导数,保持 y 和 z 不变。一般来说,f 关于变量 q 的偏导数是当其他变量固定时 df 与 dq 的比值。当存在关于哪些变量固定的可能误解时,应明确说明。 |
 |
f 关于 x 的偏导数,保持 y 和 z 不变。 |
| grad f | 向量场,其分量为函数 f 关于 x、y 和 z 的偏导数: ;称为 f 的梯度。 ;称为 f 的梯度。 |
 |
向量算子 ,称为"del"。 ,称为"del"。 |
 |
函数 f 的梯度;其与 w 的点积是函数 f 在 w 方向上的方向导数。 |
 |
向量场 w 的散度;它是向量算符 与向量 w 的点积,或  。 。 |
| curl w | 向量算符 与向量 w 的叉乘。 |
 |
w 的旋度,其分量为  。 。 |
 |
拉普拉斯算子,微分算符: 。 。 |
| f "(x) | 关于 x 的 f 的二阶导数;f '(x) 的导数。 |
 |
关于 x 的 f 的二阶导数。 |
 |
关于 x 的 f 的另一种二阶导数形式。 |
 |
关于 x 的 k 阶导数;关于  的导数。 的导数。 |
| T | 曲线上的单位切向量;如果曲线由 r(t) 描述, 。 。 |
| ds | 曲线上的距离微分。 |
 |
曲线的曲率;其单位切向量关于曲线上的距离的导数的大小: 。 。 |
| N | 在与 T 法向量正交的方向上的单位向量。 |
| B | 法向量 T 和 N 所在平面的单位向量,即曲率平面的法向量。 |
 |
曲线的扭率; 。 。 |
| g | 重力常数。 |
| F | 力的力学标准符号。 |
| k | 弹簧的弹性系数。 |
 |
第 i 个粒子的动量。 |
| H | 物理系统的哈密顿量,即其能量用动量、位置和  表示。 表示。 |
| Q 和 H 的泊松括号。 | |
 |
f(x) 的一个反导数,表示为 x 的函数。 |
 |
从 a 到 b 的 f 的定积分。当 f 为正且 a < b 时,这是 x 轴、直线 y = a、y = b 和代表函数 f 在这些直线之间的曲线之间的面积。 |
| L(d) | 一个具有均匀间隔大小 d 和在每个子间隔的左端评估的 f 的 Reimann 和。 |
| R(d) | 一个具有均匀间隔大小 d 和在每个子间隔的右端评估的 f 的 Reimann 和。 |
| M(d) | 一个具有均匀间隔大小 d 和在每个子间隔中 f 的最大点处评估的 Reimann 和。 |
| m(d) | 一个具有均匀间隔大小 d 和在每个子间隔中 f 在 f 的最小点处评估的 Reimann 和。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号