Flink 的 RocksDB 状态后端在 vivo 的实践
作者: 互联网大数据团队- Chen Rui
本文简要介绍了特征拼接在实时推荐中的重要作用,并讲述了vivo实时推荐系统中特征拼接模块的架构演进过程以及采用现有的“基于RocksDB的大状态解决方案”的原因,重点叙述了该方案所遇到的一系列问题,包括TM Lost、RocksDB性能调优门槛高、TM初始化慢、状态远程存储HDFS RPC飙高等,并给出了这些问题的现象以及解决方案。
1分钟看图掌握核心观点👇

一、背景
在推荐系统中,样本拼接是衔接在线服务与算法模型的重要一个环节,主要职责是样本拼接和业务相关的ETL处理等,模块位置如下图红框所示。

推荐系统通过学习埋点数据来达到个性化精准推荐的目的,因此需要知道服务端推荐下发的内容,是否有一系列的行为(曝光,点击,播放,点赞,收藏,加购等等),把被推荐内容的埋点数据与当下的特征拼接起来的过程,一般称为样本拼接,一个简化的流程如下:

推荐的过程可以检验概括为以下几点:
- 后台服务rank 推荐内容给app客户端,同时把内容对应的特征快照保存起来;
- app接收到内容后,埋点日志被上报到消息中间件;
- 样本拼接负责将特征与埋点日志拼接起来,定义正负样本,格式转换;
- 模型接收样本训练,将使用最新的模型做推荐。
为了保证较高的拼接率和稳定性,我们的拼接架构也经过了长时间的迭代,这篇文章我将给大家介绍vivo特征拼接架构的发展历程、当前方案、当前方案遇到的问题和解决方案,以及未来的规划和展望,希望能帮助到业内的同学。
二、拼接方案选型
2.1 小时粒度拼接
小时拼接是将埋点日志和特征快照都保存到Hive并以小时分区,每小时调度一个Spark任务来处理两个表相应分区的数据做拼接,由于是小时拼接,实时性较低,Spark作业本身也依赖于上游Hive表小时分区生成,每个小时末尾的请求埋点有可能是落在当前小时,也有可能落在下个小时。举个例子:19点50分下发了一个视频,客户端在19:59分点击了,但是视频播放却是在20点03分完成的,这个时候就会存在拼接不上的问题。

2.2 基于 Redis 的流式拼接
为了提升拼接率,且达到实时拼接,节点故障容灾,完备监控等特性,Flink是一个很好的替代方案,也是最近几年比较主流的实现。最初在实时推荐场景中,Kafka中的特征快照通过Flink任务写入到Redis,另一个Flink任务消费曝光埋点数据和点击埋点数据并读取存在Redis中的特征快照数据做拼接,拼接后的数据作为拼接特征被写入到下游的Kafka中,提供给后续的算法做模型的训练,架构图如下:

经过一段时间实践,以上的方案出现了两个痛点:
- Redis中存储了几十T的数据,Redis的成本高;
- 业务数据流量会波动,经常需要DBA对Redis集群进行扩容,涉及大量数据的迁移,运维成本高。
2.3 基于 RocksDB 大状态流式拼接
为了解决基于Redis的作为中间数据的存储存在的问题,我们采用Flink状态来存储特征快照,整个架构中不再需要外部的Redis,由于我们需要存储的数据量达几十T,这里我们选用适合大数据量存储的RocksDB类型的状态后端,调整后架构更加简洁,如下图所示:
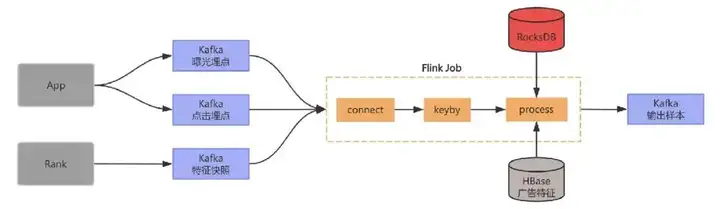
流程如下:
- 首先将曝光流点点击流以及特征在Flink 任务中做union并做keyby;
- 在processElement方法中如果接收到曝光流就将数据保存到state中,如果接收到曝光流就将数据保存到state中,如果接收到特征就去state中查询相应的曝光和点击数据;
- 如果能找到就发送到下游并将状态数据清理掉,没找到就将特征保存到state中,并注册一个定时器;
- 定时器触发时去state中查询相应的曝光和点击数据,如果找到就发到下游,并将状态数据清理掉。
由于RocksDB可以同时利用内存和磁盘来存储数据,所以对于内存的使用量大幅下降,由于RocksDB是嵌入式的数据库,每个TM上的RocksDB数据库只存储shuffe到该TM上的数据,无需再关注扩缩容的问题。当然随着数据上涨,Flink流式拼接在实际的生产过程中也遇到了一系列的问题,为了保证业务的可用性,我们花了较长的时间对这些问题进行攻克,目前任务稳定性达到99.99% ,拼接率长期稳定在99%以上,对拼接效果提升较大。下面我将列举我们遇到的问题和解决方案,希望能够帮助到业内的其他团队。
三、问题及解决方案
3.1 TM Lost问题
3.1.1 现象
在方案实施之初,我们发现这些特征拼接的任务频繁出现TM was Lost异常导致任务重启,我们看了日志,发现都是TM内存超出了YARN的内存限制被kill。
3.1.2 问题分析
那么我们的疑问就来了,为啥这部分任务的内存很容易超出,超出的那部分内存又是谁在用呢?下面这张图是来自Flink的官网,因为我们在平台使用Flink的时,我们只设置了总的内存,并没有关注其他各个局部的内存,那么这些部位的内存是如何分配的?为了搞清楚这个问题,有必要梳理一下每个模块内存计算的逻辑。
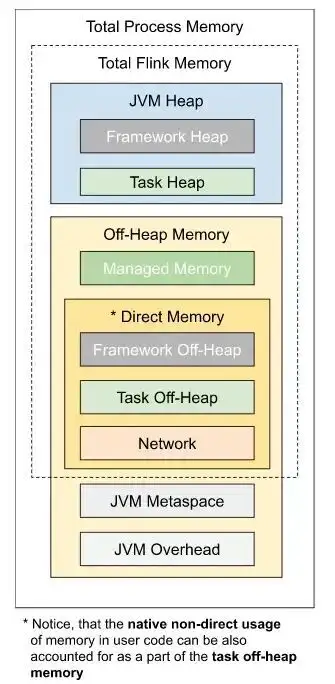
Flink内存分配逻辑
一般在YARN上提交的任务是含有taskmanager.memory.process.size 参数的配置的,所以Flink在分配内存时,会以调用deriveProcessSpecWithTotalProcessMemory 方法分配。
通过配置参数获得meatspace 的大小,通过jobmanager.memory.jvm-overhead.fraction 的比例计算overhead的内存,totalFlinkMemory通过总的进程的内存减去meatspace + overhead的内存得到。
通过配置中的参数获取 frameworkHeapMemory-
Size、frameworkOffHeapMemorySize 、task-
OffHeapMemorySize 的大小。
通过managedmemory的配置获取托管内存的值, 通过networkbuffer的配置获取networkbuffer的值 。totalFlinkMemory 减去所有需要排除的内存,剩下的内存分配给堆。内存分配逻辑,以及每块内存的设置方法如下图:
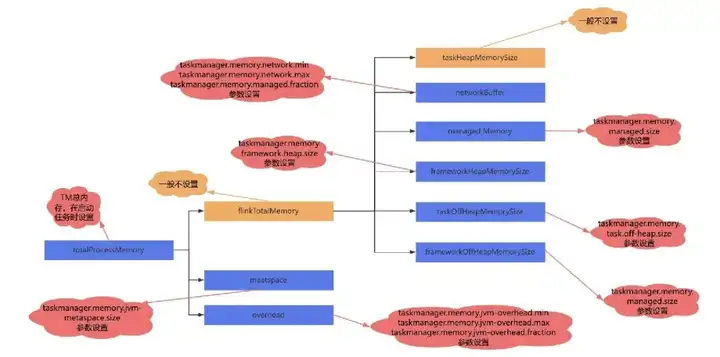
到此TM的各个内存模块的内存已经划分完成。有上面的分析我们可以得出以下的结论:
totalProcessMemorySize = totalFlinkMemorySize + JvmMetaspaceSize + JvmOverheadSize
totalFlinkMemorySize = frameworkOffHeapMemorySize + taskOffHeapMemorySize + managedMemorySize + networkMemorySize + frameworkHeapMemorySize + taskHeapMemorySize
这里重点将一下JVMOverhead,JVMOverhead并没有具体的作用,是一个预留值,它是一个缓冲区,可以避免在Flink运行在容器中是因为短时时间的内存超出了容器的限制而被kill。
frameworkOffHeapMemorySize和taskOff-
HeapMemorySize 也是预留值,offheap在概念上的主要是指native内存。frameworkHeap-
MemorySize 也是预留值。由此可以看出虽然Flink官方将TM的内存划分的较细致,但是像JvmOverheadSize frameworkOffHeap-
MemorySize,taskOffHeapMemorySize,
frameworkHeapMemorySize 都只是逻辑上的预留,并没有从操作系统层面实现隔离。
RocksDB内存分配逻辑
因为堆内存不足时一般会报out of memory的异常,所以到这一步我们推测应该是堆外内存溢出了,而堆外内存最大的一块就是RocksDB使用的,而从Flink的官网的介绍可以知道托管内存就是给RocksDB使用的,下面我们再看一下托管内存是如何分配给RocksDB的。
cacheMemory = (1-(1/3)*(writeBufferRatio))* managedMemory
bufferMemory = (2/3)*(writeBufferRatio)* managedMemory
读写缓存总内存 = bufferMemory + cacheMemory = (1 +(1/3)*(writeBufferRatio))* managedMemory
由上面的代码可以看出,managed memory 是通过一定的比例给RocksDB的各个部分来分配内存的,writeBufferRatio会影响读缓存和写缓存的大小,理论上读写缓存总内存有可能会超过managedMemory的大小。通过上面的公式可以看出读写缓存总内存最多超出managedMemory的1/3,这里很容易想到,那么我们在排查overhead的时候配置大于managedMemory的1/3不就能你面内存溢出了,但是在实践中,我们这样配置并并没有完全的解决物理内存溢出的问题,下面关于RocksDB内存的资料,终于找到了是还有哪部分内存容易溢出了,是因为部分区域的内存难以限制导致的。
RocksDB 的内存占用有 4 个部分:
- Block Cache: OS PageCache 之上的一层缓存,缓存未压缩的数据 Block;
- Indexes and filter blocks: 索引及布隆过滤器,用于优化读性能;
- MemTable: 类似写缓存;
- Blocks pinned by Iterator: 触发 RocksDB 遍历操作(比如遍历 RocksDBMapState 的所有 key)时,Iterator 在其生命周期内会阻止其引用到的 Block 和 MemTable 被释放,导致额外的内存占用。
前三个区域的内存都是可配置的,但 Iterator 锁定的资源则要取决于应用业务使用模式,且没有提供一个硬限制,因此 Flink 在计算 RocksDB StateBackend 内存时没有将这部分纳入考虑,其次是 RocksDB Block Cache 的一个 bug,它会导致 Cache 大小无法严格控制,有可能短时间内超出设置的内存容量,相当于软限制,原来是迭代器的内存限制的不好,导致的内存溢出。
3.1.3 解决方案
我们在使用Flink 的RocksDB状态后端时,是通过managed memory来控制RocksDB各个部分的内存的,所以managed memory内存越小分配给各个部分的内存也就越小,迭代器内存越不容易溢出。到此我们对Flink的RocksDB状态后端的内存有了一定的认知:当性能可以满足的情况下,Flink的Manaed memory应该越小越好。但是上满形成的经验很难高效的在业务上落地,原因是“Flink的Manaed memory应该越小越好”很难去确定。
于是我们联想到了之前的JVMoverhead,在我们的实际实践中过程中,我们是通过调大JVMoverhead,和jemalloc内存分配器来解决内存溢出问题的。在Flink1.12之后Flink on k8s的内存分配器已经默认改成了jemalloc,可以避免内存的分配过程中出现64M问题。
但是要注意:由于我们的Java版本是JAVA8小版本是192,在最新版本的jemalloc5.3上出现了死锁的问题,后来我们采用jemalloc4.5 就没有问题了。据了解业界有些公司使用的JAVA8小版本是256采用jemalloc5.3没有遇到死锁问题。
3.2 RocksDB 的性能监控问题
3.2.1 现象
Flink RocksDB大状态的任务经常出现延迟,但是我们很难知道性能的瓶颈在哪块,从而优化响应的环节。
3.2.2 解决方案
其实Flink提供了一系列对于RocksDB的性能的监控指标,我们只需要加上参数开启即可,这里我只结局我觉得最有参考意义的指标开启的参数:
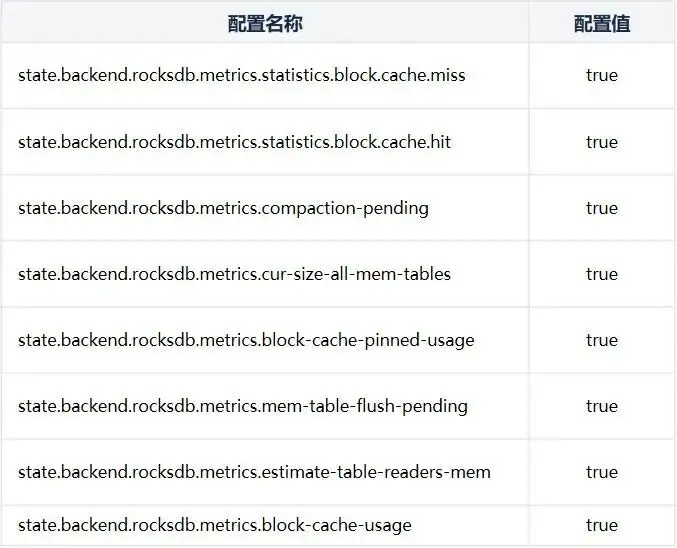
下面是相关指标的监控页面:
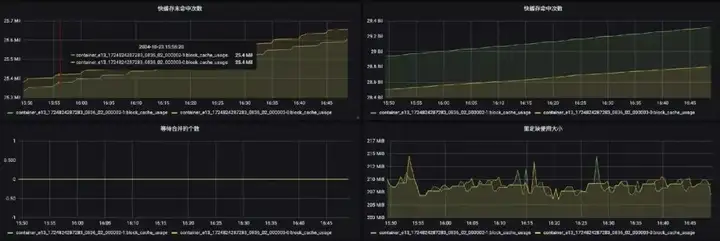
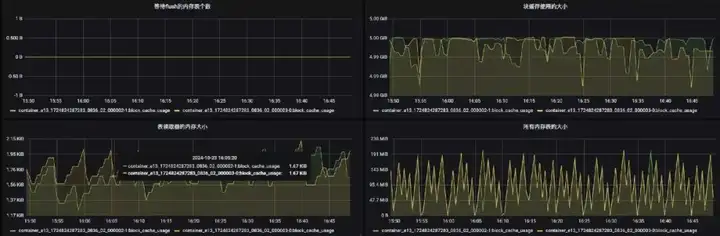
3.3 任务出现延迟
3.3.1 现象
Flink RocksDB大状态的任务经常出现延迟,调优参数高达近百个,如何系统性的调优,难度较大。
3.3.2 解决方案
要想对RocksDB的性能做优化,我们有必要先了解一下RocksDB的读写流程。
RocksDB的读流程
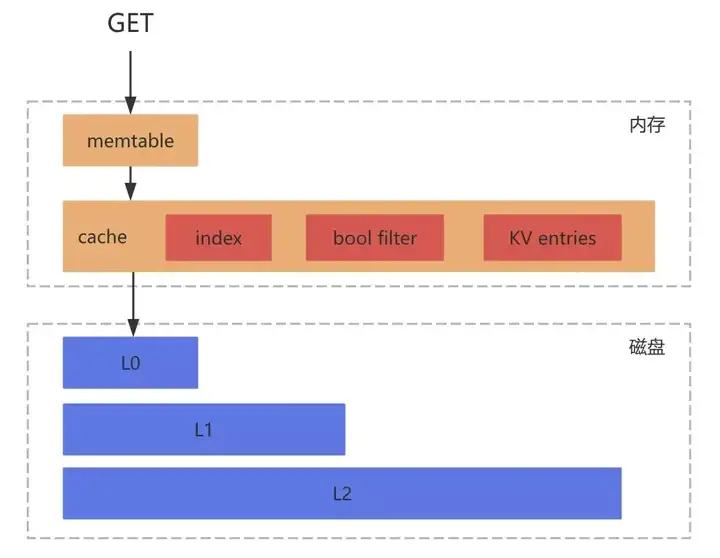
- 获取当前时刻的SuperVersion,SuperVersion是RocksDB内针对于所有SST文件列表以及内存中的MemTable和Immutable MemTable的一个版本;
- 获取当前的序号来决定当前读操作依赖的数据快照;
- 尝试从第一步SuperVersion中引用的MemTable以及Immutable MemTable中获取对应的值。首先会经过布隆过滤器,假如不存在则一定不存在,反之假如返回存在则不一定存在;
- 尝试从Block Cache中读取;
- 尝试从SST文件中获取。
RocksDB的写流程
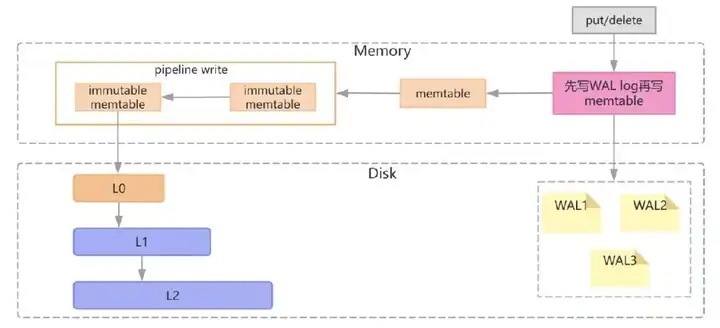
- 将写入操作顺序写入WAL日志中,接下来把数据写到 MemTable中(采用SkipList结构实现)
MemTable达到一定大小后,将这个 MemTable 切换为不可更改的 immutable MemTable,并新开一个 MemTable 接收新的写入请求; - 这个 immutable MemTable进行持久化到磁盘,成为L0 层的 SSTable 文件;
- 每一层的所有文件总大小是有限制的,每下一层大十倍。一旦某一层的总大小超过阈值了,就选择一个文件和下一层的文件合并。
注意: 所有下一层被影响到的文件都会参与 Compaction。合并之后,保证 L1 到 L6 层的每一层的数据都是在 key 上全局有序的,而 L0 层是可以有重叠的,写流程的约束; - 日志文件用于崩溃恢复;
- 每个MemTable及SST文件中的Key都是有序的(字符顺序的升序);
- 日志文件中的Key是无序的;
- 删除操作是标记删除,是插入操作的一种,真正的删除要在Compaction的时候实现;
- 无更新实现,记录更新通过插入一条新记录实现;
当任务出现延迟时,由于我们已经有了RocksDB性能指标的监控也了解RocksDB的原理,我们在做性能优化时就可以对症下药了。
读性能优化
当任务出现延迟且块缓存命中率下降时,说明是读的性能下降导致延迟,我们可以通过提升缓存命中率的方式来提升读性能,RocksDB任务缓存命中率的优化思路如下:
- 托管内存小于TM内存20%,可以调大托管内存:state.backend.rocksdb.memory.managed 到 20%;
- Flink内部对RocksDB的优化已经沉淀了多组参数,建议使用配置:
state.backend.rocksdb.predefined-options =
SPINNING_DISK_OPTIMIZED_HIGH_MEM;
- Flink中使用state.backend.rocksdb.memory
.write-buffer-ratio参数来管理写缓存,调小该参数,能够提升读缓存,该参数默认0.5;
- RocksDB 会有一写索引和过滤器放在内存中,用这个参数开启:state.backend.rocksdb
.memory.partitioned-index-filters 默认 false,并且可以调节索引和过滤器占用的内存比例,参数是:state.backend.rocksdb.memory
.high-prio-pool-ratio默认为0.1。
写性能优化
当任务延迟,如果出现等待flush的内存表的大小增加,或者等待合并的个数增加,因为等带flush个数达到一定的个数时写将会被阻塞,可以先关注一下磁盘io是否打满,如果已经处于高位,建议提升任务的并发。如果此磁盘io处于低位,我们可以调整flush和compation的线程数来使写的数据不再积压。提升写写性能。Flink会将flush和compation的线程数通过一个参数统一管理,参数是:state.backend
.rocksdb.thread.num,默认值是1。
3.4 任务启动慢的问题
3.4.1 现象
由于Flink任务在从状态启动时需要将存储在远程HDFS的状态文件读到本地,当TM较集中时单台机器的磁盘io很容易被打满,导致某些sub task 长时间处于INITIALIZING的状态。
3.4.2 解决方案
YARN参数的优化
YARN默认的yarn.scheduler.fair.assignmultiple参数为flase,即一次只分配一个container,但是CDH将这个参数设置成了true,yarn.scheduler.fair.max.assigr默认为-1,表示不限制,所以导致一次调度到单个节点上的container较多。我们的解决方案是将YARN配置中的yarn.scheduler.fair.assignmultiple参数设为false,一次只调度一个container,解决了TM分配较集中的问题。
Flink调度策略的优化
由于只是限制了每次分配TM的个数,还不能完全避免分配集中的问题,于是我们对Flink引擎内部做了优化,可以硬限制在某台机器上调度TM的个数,具体做法是,是当YARN返回给Flink ResourceManager container信息时,判断container是否符合要求,如果不符合可以部分拒收,再次申请资源,该功能由参数开启。

3.5 磁盘打满的问题
3.5.1 现象
由于我们实时集群的磁盘较小,大状态任务的状态达几十上百T,频繁出现磁盘使用率达到90%的告警。
3.5.2 解决方案
我们将大状态的任务的Checkpoint数据存储到磁盘资源较宽裕的离线的集群,非大状态的任务的Checkpoint数据存储在实时集群。
3.6 HDFS RPC 飙高问题
3.6.1 现象
在业务新上一批任务后,我们发现离线集群HDFS的RPC有明显的增加。
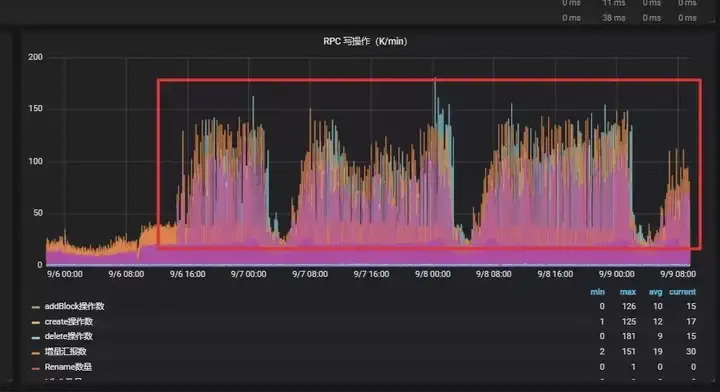
3.6.2 解决方案
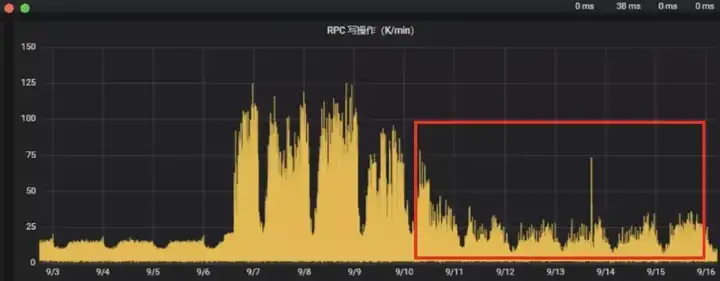
由于我们默认只会保存最近的3个Checkpoint,所以对于增量Checkpoint而言,肯定会有文件的修改和删除,据了解修改和删除是对HDFS性能影响较大的操作。我们对比这一批任务任务在HDFS上的Checkpoint文件和之前的任务对比发现,文件数量大很多,但是每个文件小很多,于是我们调整了参数:state.backend.rocksdb.compaction.level.target-file-size-base参数为256MB,这个参数默认是64MB,参数的作用控制压缩后的文件的大小。配置改参数后RPC回归正常。
效果如图:
四、总结
4.1 遗留问题
4.1.1.RocksDB的调优的门槛较高
虽然我们在任务上使用了积累通用经验进行优化,但是有些数据量较大的任务在流量高峰期依然容易出现延迟,RocksDB的参数有几十个,要想把性能调优做到比较极致需要深入了解其原理,还有对业务特点有深入的了解,对于应用开发而言,门槛较高。
4.1.2.任务恢复慢
由于有些任务的状态高达几十T,在重启任务或者异常重启时要从Checkpoint恢复,需要从远程的HDFS下载状态到本地磁盘,单机的io很容易被打满,虽然我们做了TM打散,但是有些单个TM恢复状态就需要几十分钟,这对于特征拼接任务来讲是不可接受的。
4.1.3.SSD寿命消耗加速
我们的实时集群磁盘使用的是单块的SSD,SSD寿命是有限的,然而RcoksDB的写放大的特点加速了SSD的寿命的消耗。
4.2 规划
经过较长时间的实践我们理解了样本拼接的本质是将不同来源、不同更新频率、不同规模的特征(如基础特征、实时埋点特征、历史特征)组合成完整样本,而单一组件往往在 “延迟、存储规模、更新频率” 等维度存在短板,必须通过混合架构实现 “优势互补”。
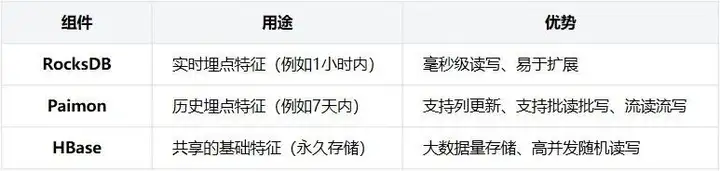
业界混合架构的案例
组件分工
拼接流程
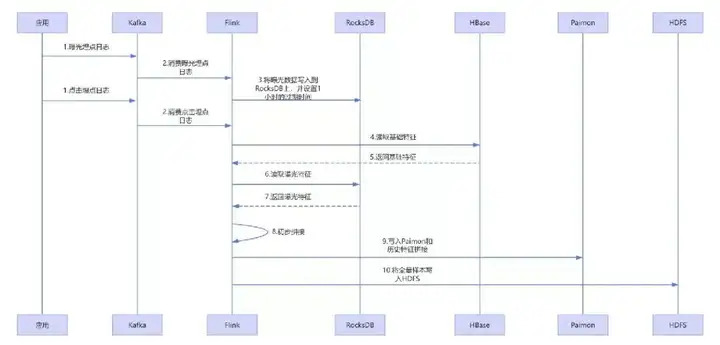
① 实时日志采集:用户点击商品的日志通过Kafka接入Flink实时作业;
② 实时数据存储:将曝光流的数据存到RocksDB和HBase中,RocksDB的TTL设置成1小时;
③ 算子内实时拼接:Flink算子从RocksDB读取用户最近1小时埋点特征,从HBase读取基础特征,初步拼接成“实时+基础”特征;
④ 历史特征融合:Flink作业将初步拼接结果写入Paimon,与Paimon中存储的“7天历史特征”融合,生成完整样本;
⑤ 样本分发:
- 实时推荐:完整样本通过Flink写入到HDFS提供给在线训练服务使用;
- 离线训练:Spark作业从Paimon读取全量完整样本,用于推荐模型的离线迭代。
下面是一个调用时序图:
核心价值
- 低延迟:RocksDB 支撑算子内毫秒级拼接,满足实时推荐的 “秒级响应” 需求;
- 大规模:HBase+Paimon 可支撑亿级用户的PB级特征存储;
- 流批协同:同一套样本既供实时推荐,又供离线训练,实现流批架构统一;
- 易于扩展:Paimon动态列支持特征迭代。
4.3 展望
近几年大数据架构已经从计算-存储紧密耦合的Map-Reduce时代,进入到了以Kubernetes容器化部署为标准的云原生世界。未来Flink将引入基于远程存储的存算分离状态管理架构,新架构主要为了解决以下问题:
- 容器化环境下计算节点受本地磁盘大小限制的问题;
- 由于RocksDB中LSM结构的周期性 Compaction 导致计算资源尖峰的问题;
- 大规模状态快速扩缩容的挑战。
我们也将持续关注Flink社区的发展,尝试采用远程存储状态后端来做为特征拼接的解决方案。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号