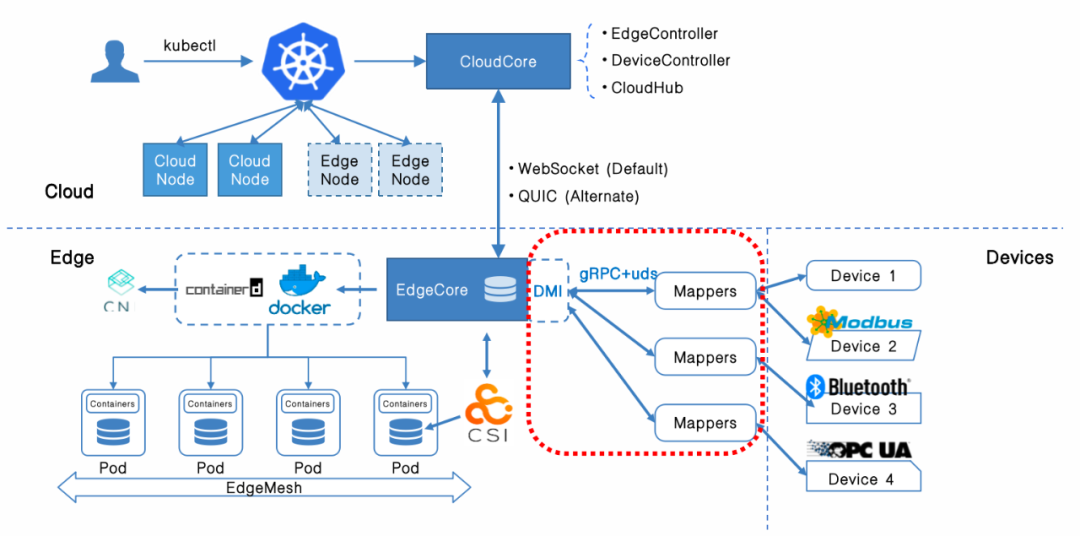
KubeEdge
整体架构
KubeEdge 是一个开源的云原生边缘计算平台,它将 Kubernetes 的功能扩展到了边缘设备。它允许在边缘设备上部署和管理容器化应用程序,并通过云端管理和监控边缘设备。
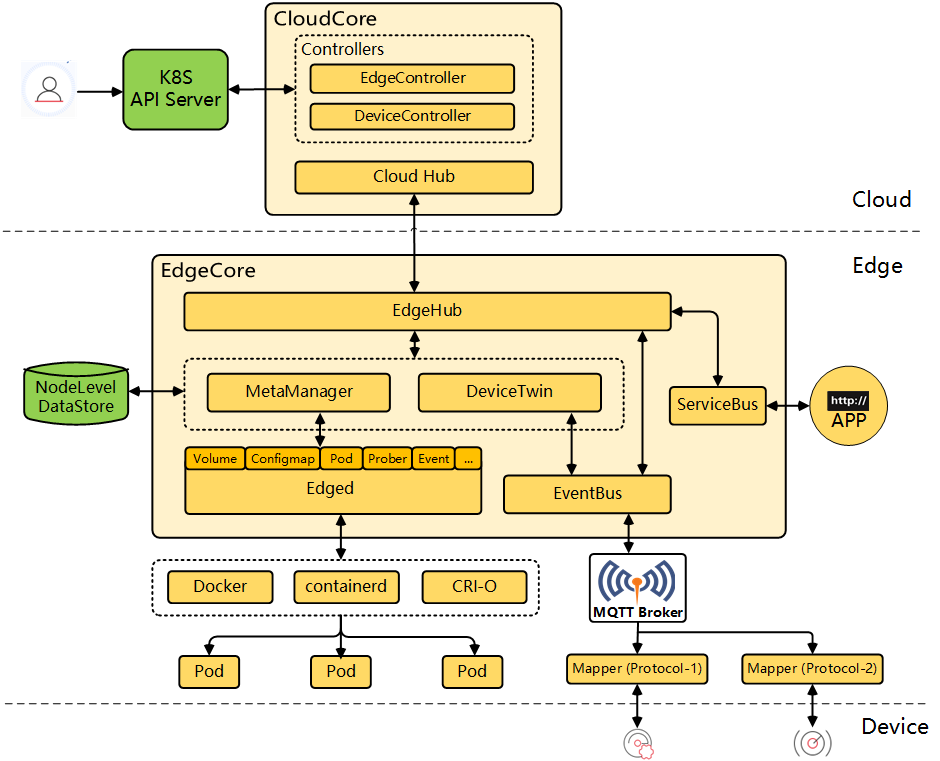
云端组件:
CloudHub: Web 套接字服务器,负责在云端缓存信息、监视变更,并向 EdgeHub 端发送消息。
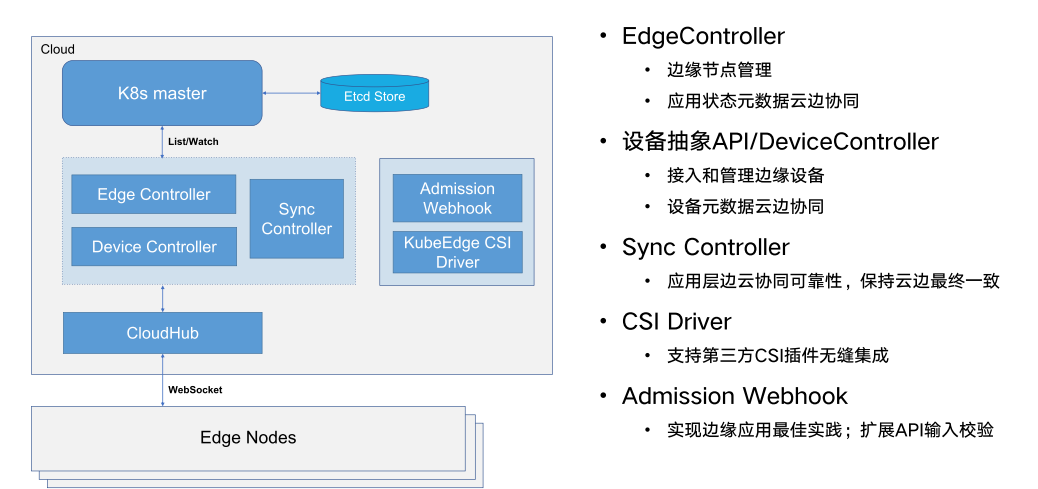
EdgeController: kubernetes 的扩展控制器,用于管理边缘节点和 pod 的元数据,以便可以将数据定位到对应的边缘节点。
DeviceController: 一个扩展的 kubernetes 控制器,用于管理边缘 IoT 设备,以便设备元数据/状态数据可以在 edge 和 cloud 之间同步。
边缘组件:
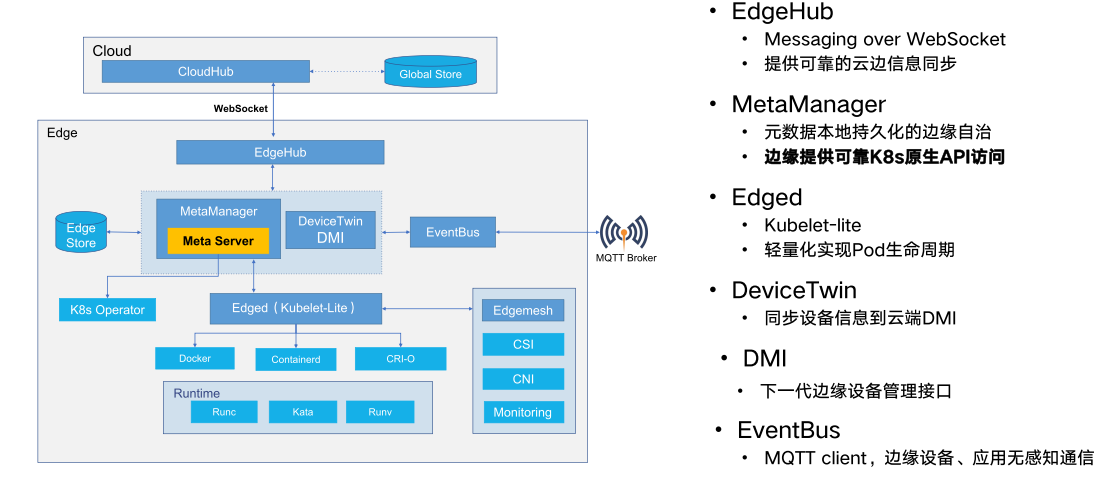
EdgeHub: Web 套接字客户端,负责与 Cloud Service 进行交互以进行边缘计算(例如 KubeEdge 体系结构中的 Edge Controller)。这包括将云侧资源更新同步到边缘,并将边缘侧主机和设备状态变更报告给云。
Edged: 在边缘节点上运行并管理容器化应用程序的代理。
DeviceTwin: 负责存储设备状态并将设备状态同步到云端。它还为应用程序提供查询接口。
MetaManager: Edged 端和 Edgehub 端之间的消息处理器。它还负责将元数据存储到轻量级数据库(SQLite)或从轻量级数据库(SQLite)检索元数据。
ServiceBus: 用于与 HTTP 服务器 (REST) 交互的 HTTP 客户端,为云组件提供 HTTP 客户端功能,以访问在边缘运行的 HTTP 服务器。
云端组件
边缘组件
EdgeMesh
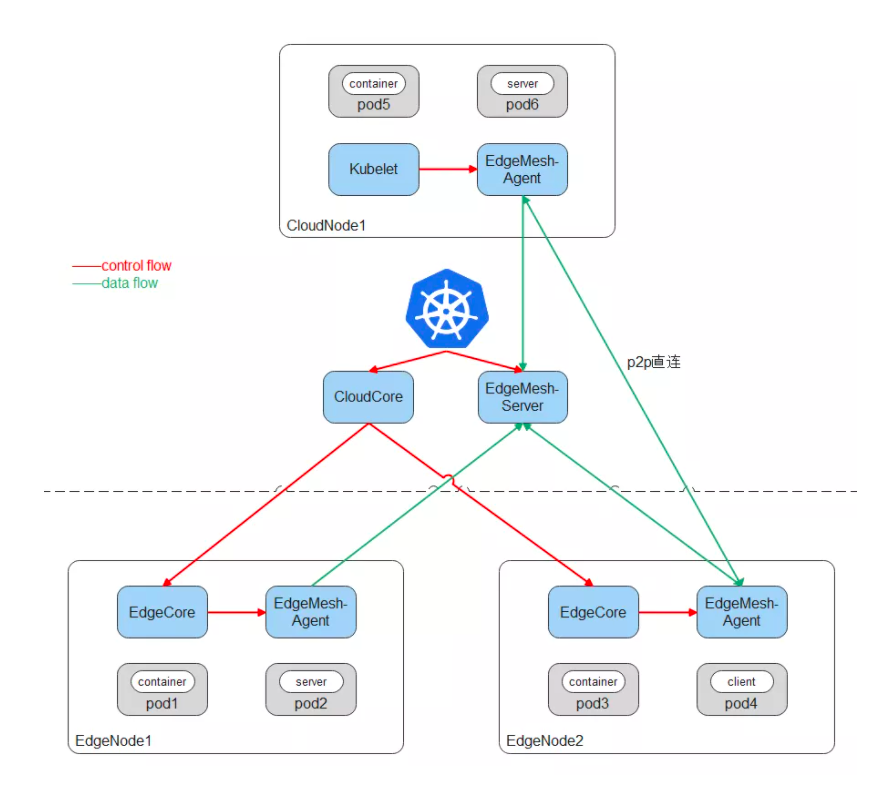
EdgeMesh 的定位是 KubeEdge 用户数据面轻量化的通讯组件,完成节点之间网络的 Mesh,在边缘复杂网络拓扑上的节点之间建立 P2P 通道,并在此通道上完成边缘集群中流量的管理和转发,最终为用户 KubeEdge 集群中的容器应用提供与 K8s Service 一致的服务发现与流量转发体验。
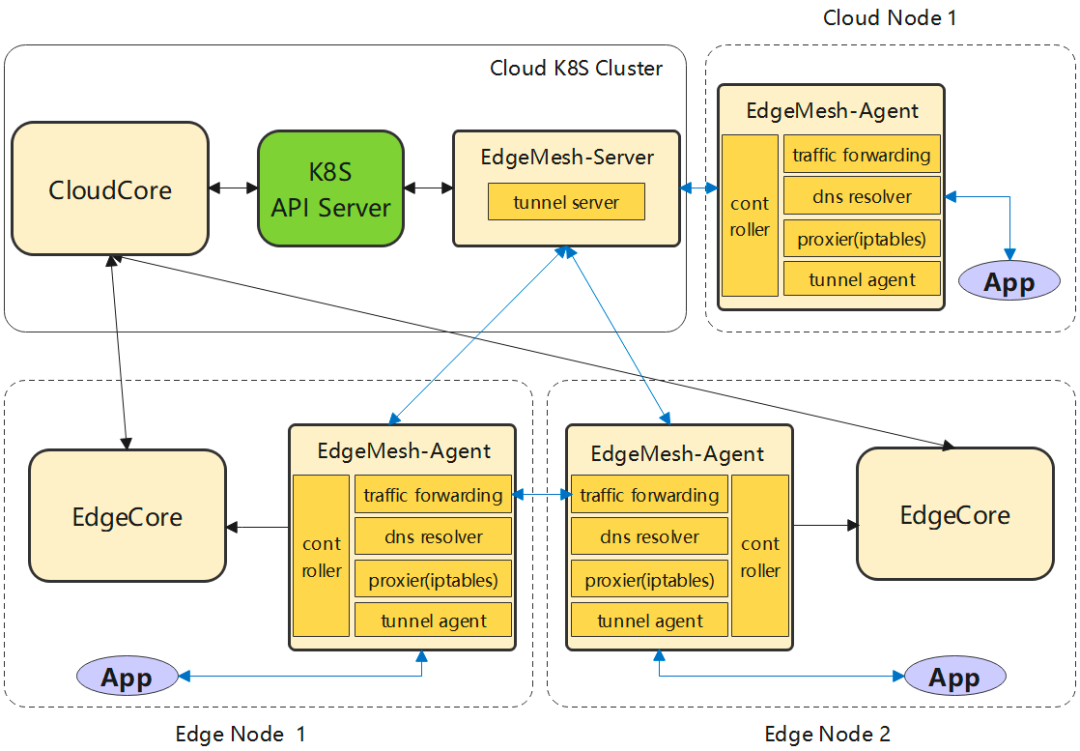
EdgeMesh 包含两个微服务:edgemesh-server 和 edgemesh-agent。
EdgeMesh-Server:
- EdgeMesh-Server 运行在云上节点,具有一个公网 IP,监听来自 EdgeMesh-Agent 的连接请求,并协助 EdgeMesh-Agent 之间完成 UDP 打洞,建立 P2P 连接;
- 在 EdgeMesh-Agent 之间打洞失败的情况下,负责中继 EdgeMesh-Agent 之间的流量,保证 100% 的流量中转成功率。
EdgeMesh-Agent:
- EdgeMesh-Agent 的 DNS 模块,是内置的轻量级 DNS Server,完成 Service 域名到 ClusterIP 的转换。
- EdgeMesh-Agent 的 Proxy 模块,负责集群的 Service 服务发现与 ClusterIP 的流量劫持。
- EdgeMesh-Agent 的 Tunnel 模块,在启动时,会建立与 EdgeMesh-Server 的长连接,在两个边缘节点上的应用需要通信时,会通过 EdgeMesh-Server 进行 UDP 打洞,尝试建立 P2P 连接,一旦连接建立成功,后续两个边缘节点上的流量不需要经过 EdgeMesh-Server 的中转,进而降低网络时延。
核心优势:
- 跨子网边边 / 边云服务通信: 无论应用部署在云上,还是在不同子网的边缘节点,都能够提供通 K8s Service 一致的使用体验。
- 低时延: 通过 UDP 打洞,完成 EdgeMesh-Agent 之间的 P2P 直连,数据通信无需经过 EdgeMesh-Server 中转。
- 轻量化: 内置 DNS Server、EdgeProxy,边缘侧无需依赖 CoreDNS、KubeProxy、CNI 插件等原生组件。
- 非侵入: 使用原生 K8s Service 定义,无需自定义 CRD,无需自定义字段,降低用户使用成本。
- 适用性强: 不需要边缘站点具有公网 IP,不需要用户搭建 VPN,只需要 EdgeMesh-Server 部署节点具有公网 IP 且边缘节点可以访问公网。
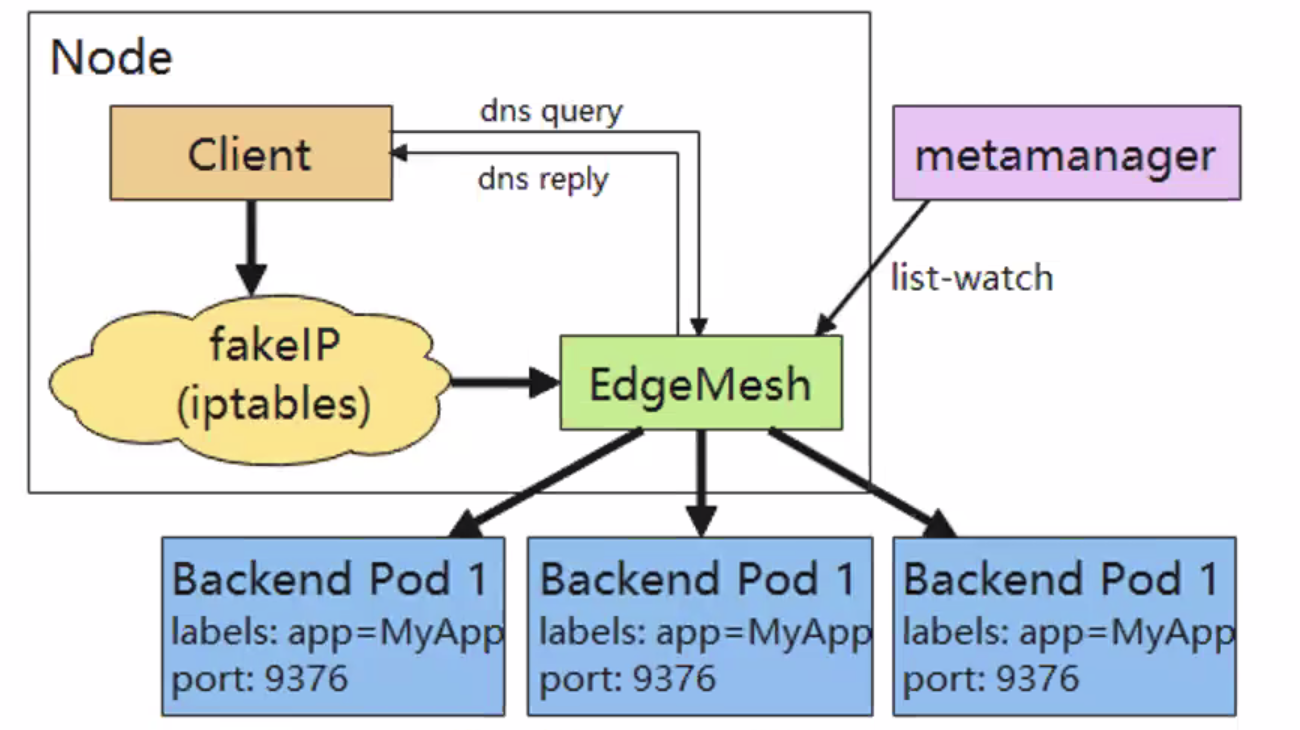
- edgemesh通过kubeedge边缘侧list-watch的能力,监听service、endpoints等元数据的增删改,再根据service、endpoints的信息创建iptables规则
- edgemesh使用域名的方式来访问服务,因为fakeIP不会暴露给用户。fakeIP可以理解为clusterIP,每个节点的fakeIp的CIDR都是9.251.0.0/16网段(service网络)
- 当client访问服务的请求到达节点后首先会进入内核的iptables
- edgemesh之前配置的iptables规则会将请求重定向,全部转发到edgemesh进程的40001端口里(数据包从内核台->用户态)
- 请求进入edgemesh程序后,由edgemesh程序完成后端pod的选择(负载均衡在这里发生),然后将请求发到这个pod所在的主机上
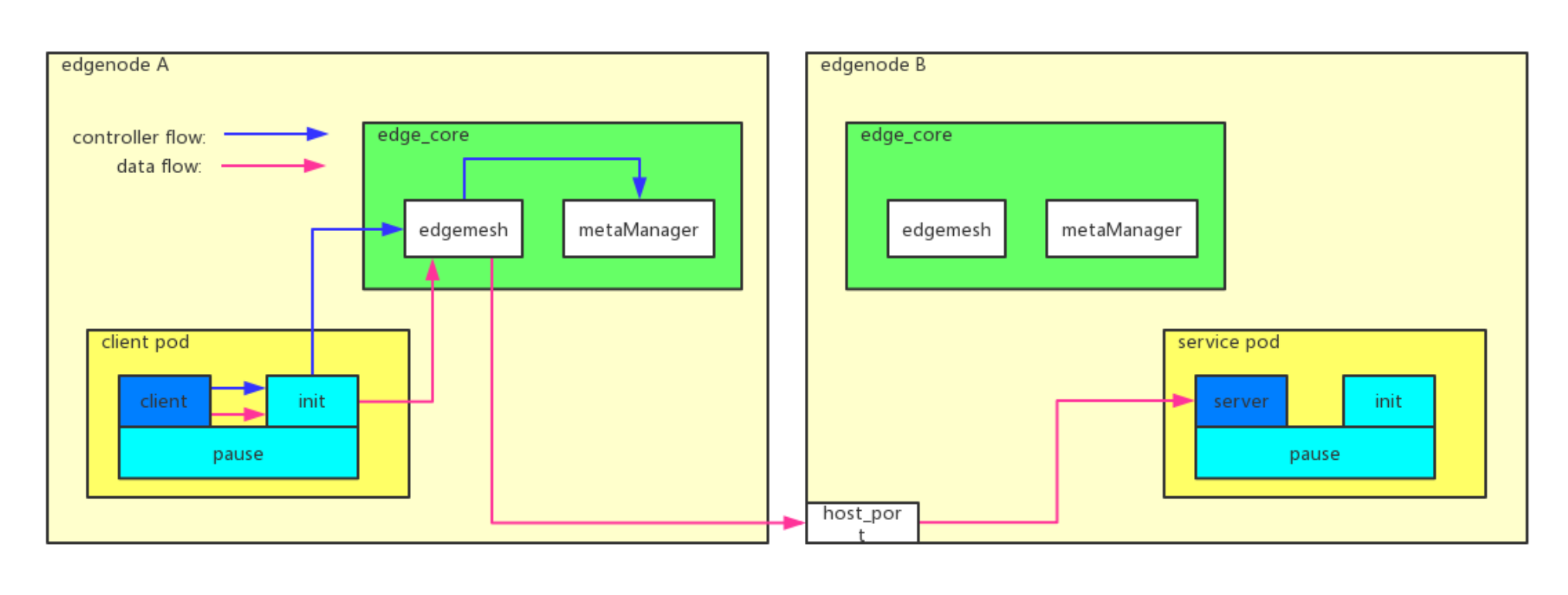
client pod是请求方,service pod是服务方。client pod里面有一个init container,类似于istio的init container。client先把流量打入到init container,init container这边会做一个流量劫持,它会把流量转到edge mesh里面去,edge mesh根据需要进行域名解析后转到对应节点的pod里面去。
NodeGroup与EdgeApplication
KubeEdge提供了边缘节点分组管理能力,来解决在跨地域应用部署中运维复杂度的问题。
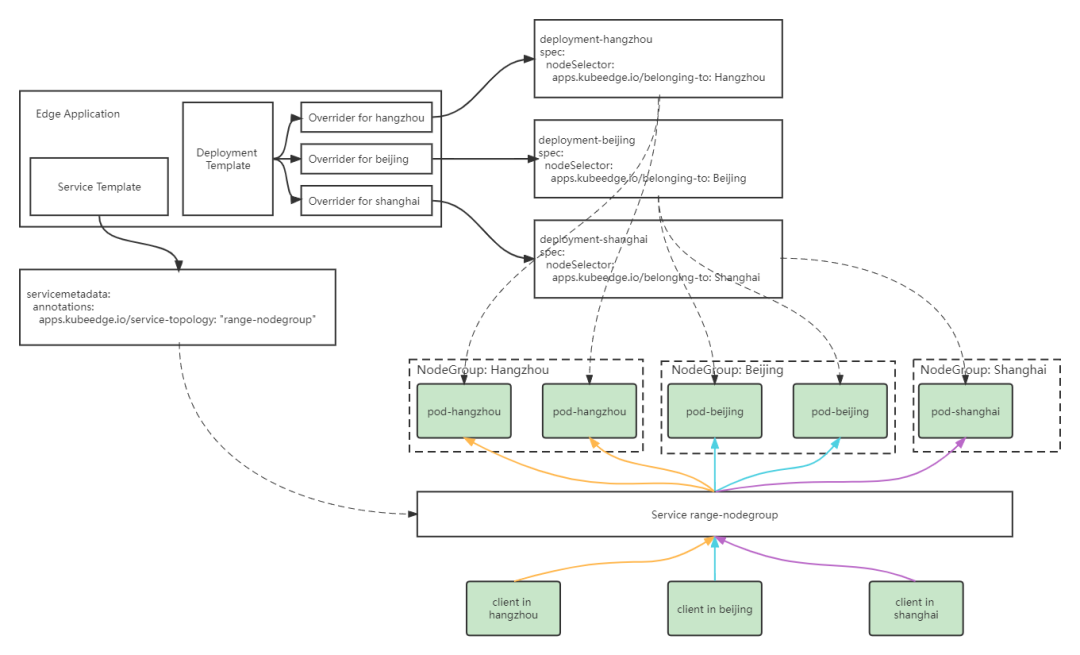
节点分组
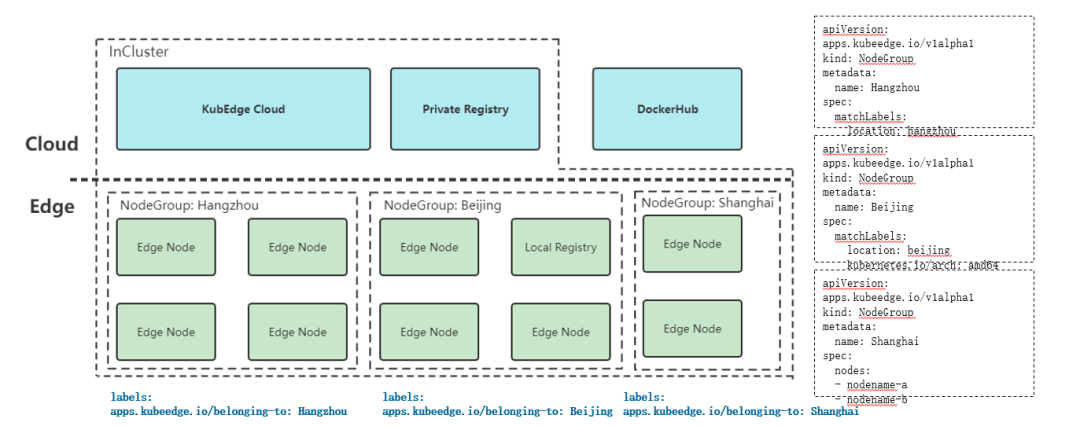
根据边缘节点的地理分布特点,可以把同一区域的边缘节点分为一组,将边缘节点以节点组的形式组织起来,同一节点同时只能属于一个节点组。节点分组可以通过matchLabels字段,指定节点名或者节点的Label两种方式对节点进行选择。节点被包含到某一分组后,会被添加上apps.kubeedge.io/belonging-to:nodegroup的Label。
边缘应用
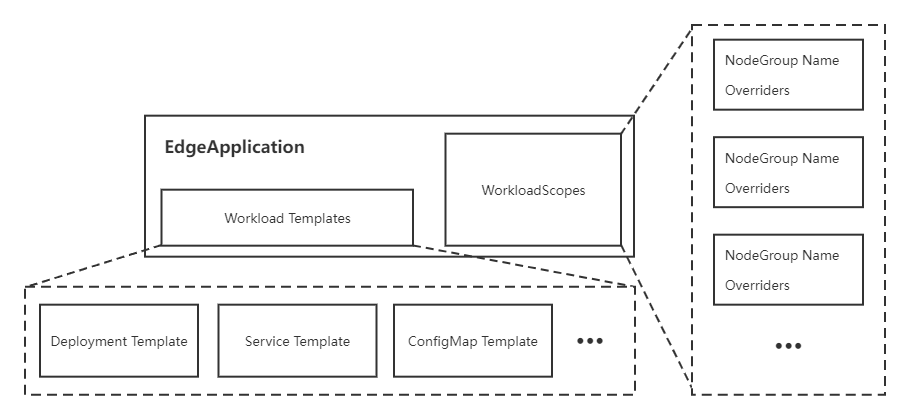
边缘应用用于将应用资源打包,按照节点组进行部署,并满足不同节点组之间的差异化部署需求。该部分引入了一个新的CRD: EdgeApplication,主要包括两个部分:
- Workload Templates。主要包括边缘应用所需要的资源模板,例如Deployment Template、Service Template和ConfigMap Template等;
- WorkloadScopes。主要针对不同节点组的需求,用于资源模板的差异化配置,包括副本数量差异化配置(Replicas Overrider)和镜像差异化配置(Image Overrider),其中Image Overrider包括镜像仓库地址、仓库名称和标签。
对于应用主体,即Deployment,会根据Deployment Template以及差异化配置Overrider生成每组所需的Deployment版本,通过调整nodeSelector将其分别部署到指定分组中。对于应用依赖的其他资源,如ConfigMap和Service,则只会在集群中通过模板创建一个相应的资源。边缘应用会对创建的资源进行生命周期管理,当删除边缘应用时,所有创建的资源都会被删除。
流量闭环
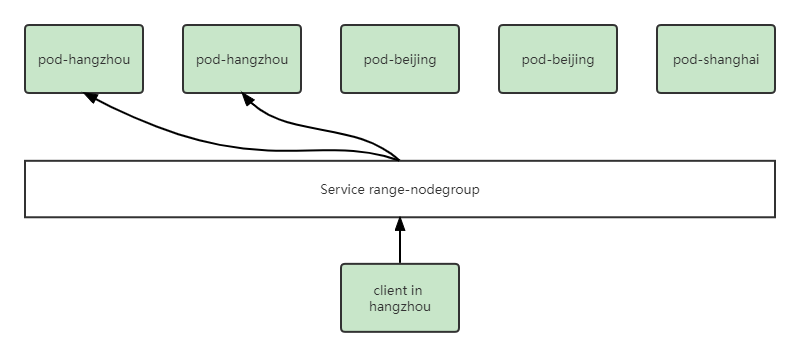
通过流量闭环的能力,将服务流量限制在同一节点组内,在一个节点组中访问Service时,后端总是在同一个节点组中。当使用EdgeApplication中的Service Template创建Service时,会为Service添上service-topology:range-nodegroup的annotation,KubeEdge云上组件CloudCore会根据该annotation对Endpoint和Endpointslice进行过滤,滤除不在同一节点组内的后端,之后再下发到边缘节点。
此外,在下发集群中默认的Master Service “Kubernetes”所关联的Endpoint和Endpointslice时,会将其维护的IP地址修改为边缘节点MetaServer地址,用户在边缘应用中list/watch集群资源时,可以兼容K8s流量访问方式,实现无缝迁移和对接。
边缘设备管理
在 KubeEdge 的设备管理整体架构中,设备是通过云原生的方式进行操作,并最终由 Mappers 这个可插拔组件进行具体控制。
首先,需要使用 Kubernetes 的 CRD(Custom Resources Definition) 来定义一个新设备,用户就能通过云原生的方式来操作这个设备。在边缘设备管理中,一般有两个设备相关的 CRD。一个是设备模型,它定义了一些常用的定义,例如设备属性,该属性类似于温度、湿度和启用计数器;另一个 CRD 是设备实例,它定义了与特定设备相关的详细定义。
Mapper 包含的功能:
Configmap parser:解析 Configmap
Event process:订阅、发布 Mqtt、消息接收和处理
Timer:定期调用函数
Driver:设备访问 (初始化、读、写、健康状态或连接状态)
Device Model 用以描述一类边缘设备共同的设备属性。按照物模型的定义,Device Model 中新增了设备属性描述、设备属性类型、设备属性取值范围、设备属性单位等字段。
apiVersion: devices.kubeedge.io/v1beta1
kind: DeviceModel
metadata:
name: beta1-model
spec:
properties:
- name: temp # define device property
description: beta1-model
type: INT # date type of device property
accessMode: ReadWrite
maximum: "100" # range of device property (optional)
minimum: "1"
unit: "Celsius" # unit of device property
protocol: modbus # protocol for device, need to be same with device instance
一个 Device Instance 代表一个实际的设备对象。Modbus、OPC-UA、Bluetooth 等内置协议的 Mapper 仍会保留在 Mappers-go 仓库中,同时也会不断增加其他协议的内置 Mapper。
- ReportCycle 字段定义了 Mapper 向用户数据库、用户应用推送数据的频率;
- CollectCycle 字段定义了 Mapper 向云端上报数据的频率;
- ReportToCloud 字段定义了 Mapper 采集到的设备数据是否需要上报云端;
- PushMethod 字段定义了 Mapper 推送设备数据的方式。
apiVersion: devices.kubeedge.io/v1beta1
kind: Device
...
spec:
properties:
- name: temp
collectCycle: 2000 # The frequency of reporting data to cloud, 2 seconds
reportCycle: 2000 # The frequency of data push to user applications or databases, 2 seconds
reportToCloud: true # Decide whether device data needs to be pushed to the cloud
pushMethod:
mqtt: # Define the MQTT config to push device data to user app
address: tcp://127.0.0.1:1883
topic: temp
qos: 0
retained: false
visitors: # Define the configuration required by the mapper to access device properties (e.g. register address)
protocolName: modbus
configData:
register: "HoldingRegister"
offset: 2
limit: 1
protocol: # Device protocol. The relevant configuration of the modbus protocol is defined in the example.
protocolName: modbus
configData:
serialPort: '/dev/ttyS0'
baudRate: 9600
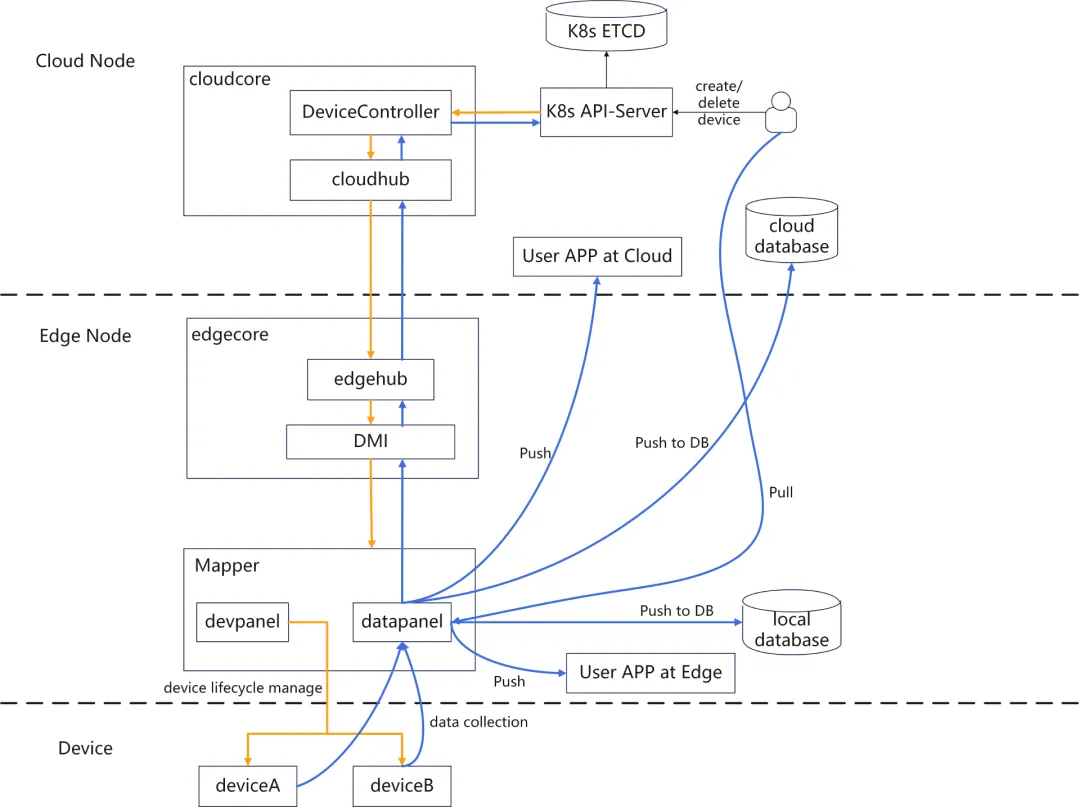
镜像预热
边缘节点网络带宽低,提前预热镜像可避免延迟。
OpenKruise是阿里开源的镜像预热工具(实际上镜像预热只是其功能之一)。

从 v0.8.0 开始,安装了 Kruise 之后,有两个在 kruise-system 命名空间下的组件:kruise-manager 与 kruise-daemon。前者是一个由 Deployment 部署的中心化组件,一个 kruise-manager 容器(进程)中包含了多个 controller 和 webhook;后者则由 DaemonSet 部署到集群中的节点上,通过与 CRI 交互来绕过 Kubelet 完成一些扩展能力(比如拉取镜像、重启容器等)。
因此,Kruise 会为每个节点(Node)创建一个同名对应的自定义资源:NodeImage,而每个节点的 NodeImage 里写明了在这个节点上需要预热哪些镜像,因此这个节点上的 kruise-daemon 只要按照 NodeImage 来执行镜像的拉取任务即可:
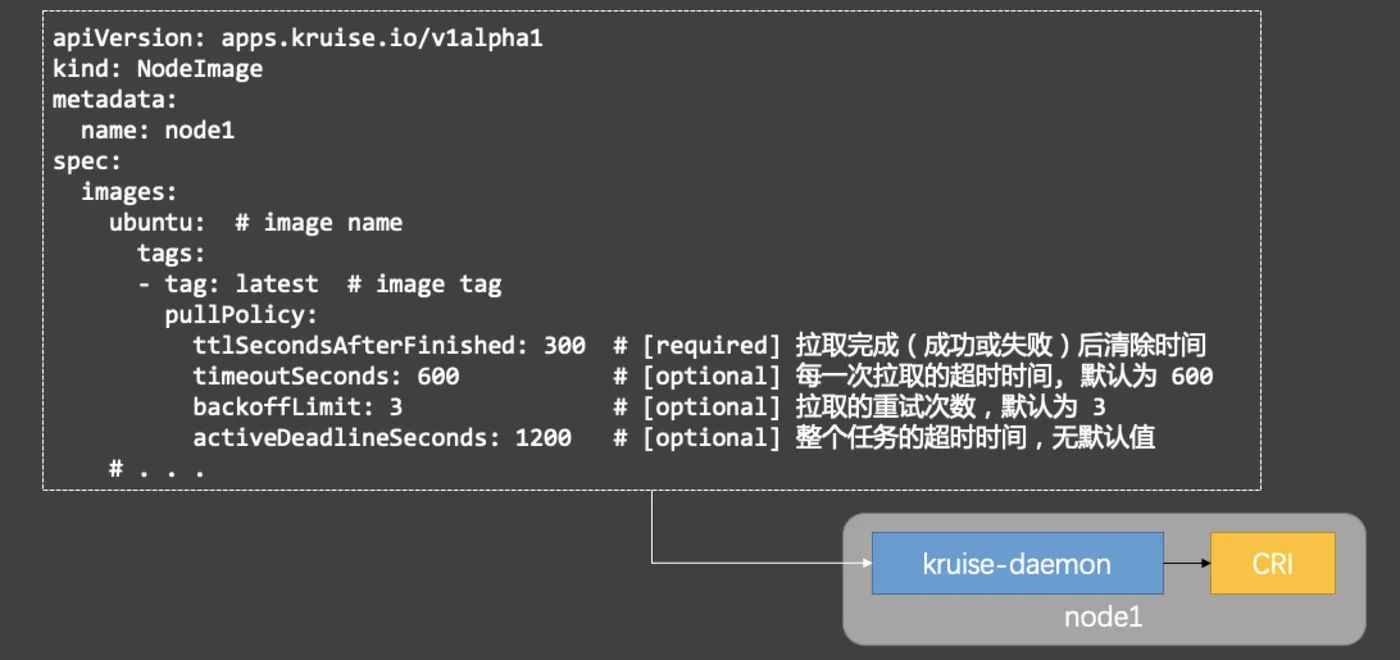
有了 NodeImage,我们也就拥有了最基本的镜像预热能力了,不过还不能完全满足大规模场景的预热需求。在一个有 5k 个节点的集群中,要用户去一个个更新 NodeImage 资源来做预热显然是不够友好的。因此,Kruise 还提供了一个更高抽象的自定义资源 ImagePullJob:
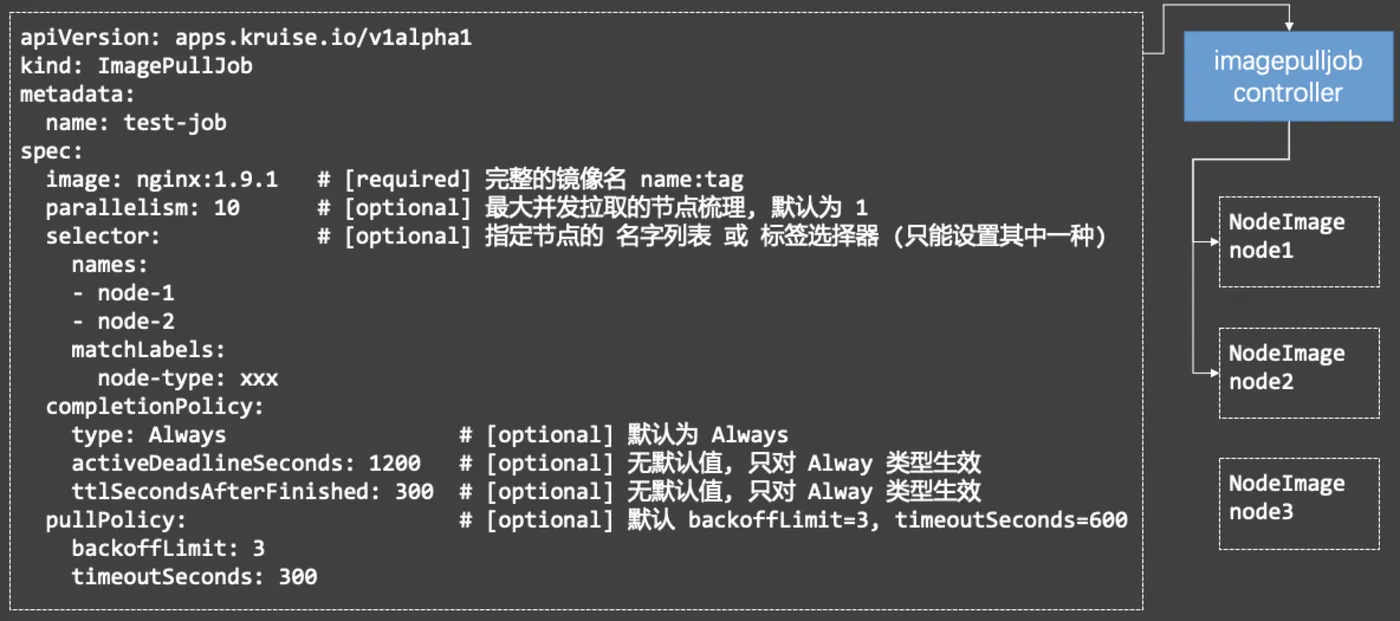
在 ImagePullJob 中用户可以指定一个镜像要在哪些范围的节点上批量做预热,以及这个 job 的拉取策略、生命周期等。一个 ImagePullJob 创建后,会被 kruise-manager 中的 imagepulljob-controller 接收到并处理,将其分解并写入到所有匹配节点的 NodeImage 中,以此来完成规模化的预热。
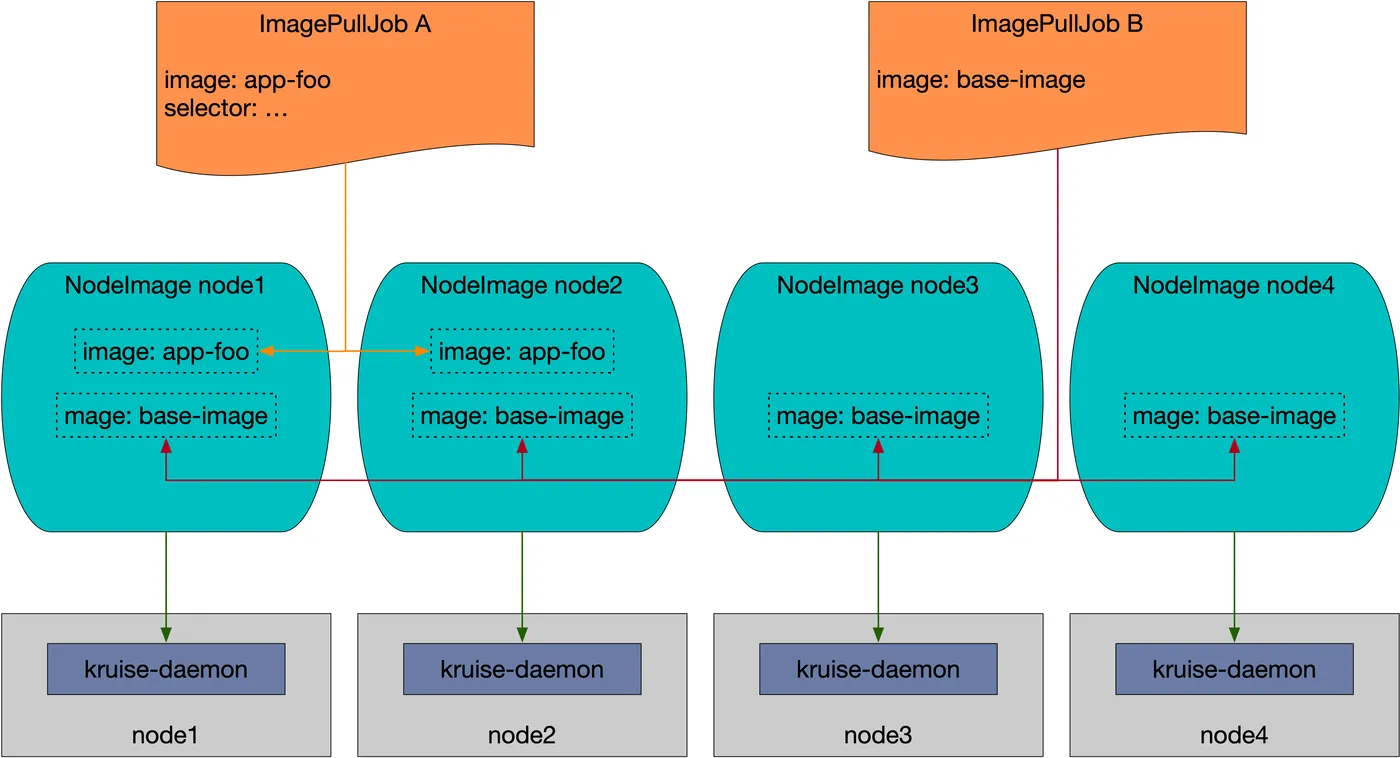
集群维度预热
apiVersion: apps.kruise.io/v1alpha1
kind: ImagePullJob
metadata:
name: base-image-job
spec:
image: xxx/base-image:latest
parallelism: 10
completionPolicy:
type: Never # Never 策略表明这个 job 持续做预热,不会结束(除非被删除);Never 策略下,ImagePullJob 每隔 24h 左右会触发在所有匹配的节点上重试拉取一次,也就是每天都会确保一次镜像存在
pullPolicy:
backoffLimit: 3
timeoutSeconds: 300
# 不配置 selector 规则,即默认整个集群维度预热
apiVersion: apps.kruise.io/v1alpha1
kind: ImagePullJob
metadata:
name: sidecar-image-job
spec:
image: xxx/sidecar-image:latest
parallelism: 20
completionPolicy:
type: Always # 所有节点做一次预热
activeDeadlineSeconds: 1800 # 整个 job 预热超时时间 30min
ttlSecondsAfterFinished: 300 # job 完成后过 5min 自动删除
pullPolicy:
backoffLimit: 3
timeoutSeconds: 300

 浙公网安备 33010602011771号
浙公网安备 33010602011771号