基于HAMi的容器GPU虚拟化
CUDA
CUDA英文全称为Compute Unified Device Architecture,中文翻译是“计算统一设备架构”,是英伟达专门为GPU开发的一套统一计算架构,核心思路是利用GPU强大并行计算能力来实现大规模计算任务的加速,使GPU可以像CPU一样能够解决复杂的计算问题。
一句话总结就是CUDA允许开发者编写直接在支持CUDA的GPU上运行的代码,并增加了控制GPU并行处理的功能,可以精确分配和控制数据在GPU核心上的处理,实现高效并行计算。
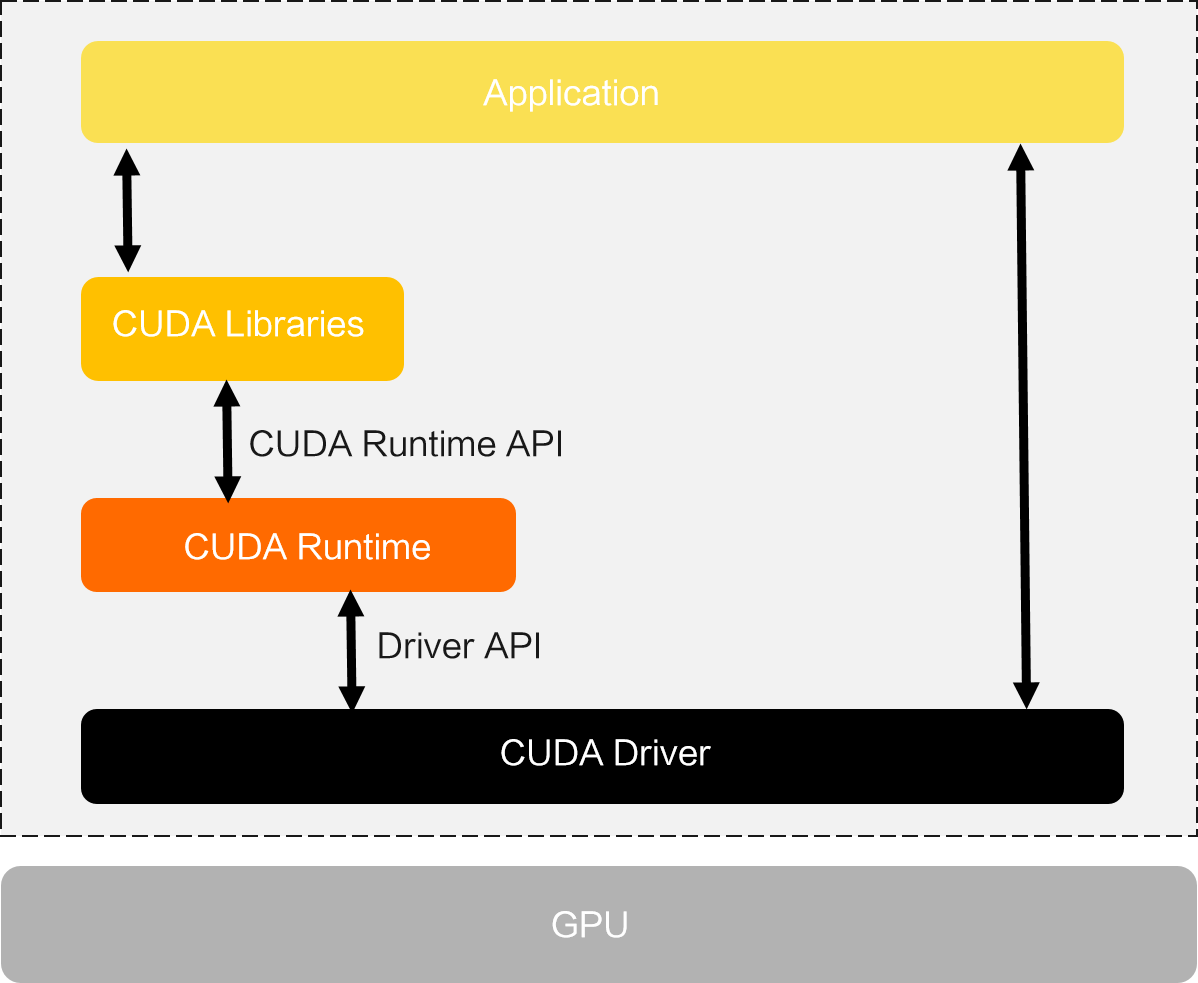
从CUDA体系结构来看,可概括为三个部分,分别是GPU驱动、运行环境和开发库;具体见下表
| CUDA架构 | 运行的内容 | 支持开发的功能 |
|---|---|---|
| 开发库 | 提供标准数学运算库,如CUFFT和CUBLAS,解决大规模并行计算问题 | 开发人员可以基于这些库快速构建自己的计算应用并在CUDA技术基础上扩展更多的开发库 |
| 运行环境 | 提供应用开发接口和运行期组件,支持程序代码在CPU和GPU上运行 | 涵盖了数据类型定义、内存管理、设备访问和执行调度等功能,帮助开发人员实现各种计算需求 |
| 驱动支持 | CUDA应用需要NVIDIA CUDA-enable硬件支持驱动程序提供了不同版本GPU之间的设备抽象层接口 | 通过这一层,CUDA可以实现硬件设备的各种功能和计算任务的执行 |
以PyTorch使用CUDA为例,需要先在服务器或PC安装英伟达GPU驱动,根据驱动安装支持的CUDA版本。(还需要安装CUDNN,基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算)。
在Python中导入torch包,print(torch.cuda.is_available())输出为True即可确认使用CUDA。
然后在PyTorch使用中可以调用CUDA,将训练任务准到GPU上,CUDA起到承上启下的作用。
x = torch.tensor([1, 2, 3])
x = x.cuda(0) # 使用.cuda()可以将CPU上的Tensor转换(复制)到GPU上,调用第一张GPU。
HAMi
首先看一下k8s中容器如何使用GPU:
首先在 k8s 中资源是和节点绑定的,对于 GPU 资源,使用 NVIDIA 提供的 device-plugin (以DaemonSet形式运行在所有节点)进行感知,并上报到 kube-apiserver,这样就能在 Node 对象上看到对应的资源了。
$ kubectl describe node gpu01|grep Capacity -A 7
Capacity:
cpu: 128
ephemeral-storage: 879000896Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 1056457696Ki
nvidia.com/gpu: 8 # 该节点有8个GPU
pods: 110
然后就可以在创建 Pod 时申请对应的资源了,比如申请一个 GPU:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: gpu-container
image: nvidia/cuda:11.0-base # 一个支持 GPU 的镜像
resources:
limits:
nvidia.com/gpu: 1 # 申请 1 个 GPU
command: ["nvidia-smi"] # 示例命令,显示 GPU 的信息
restartPolicy: OnFailure
apply 该 yaml 之后,kube-scheduler 在调度该 Pod 时就会将其调度到一个拥有足够 GPU 资源的 Node 上。
同时该 Pod 申请的部分资源也会标记为已使用,不会再分配给其他 Pod。即:Node 上的 GPU 资源被 Pod 申请之后,在 k8s 中就被标记为已消耗了,后续创建的 Pod 会因为资源不够导致无法调度。
这就造成部分GPU资源的浪费,有些GPU 性能比较好,原本可以支持多个 Pod 共同使用。因此,HAMi这种GPU虚拟化方案应运而生。
HAMi 全称是:Heterogeneous AI Computing Virtualization Middleware,HAMi 给自己的定位或者希望是做一个异构算力虚拟化平台,vGPU是其现在最核心也最完善的功能。
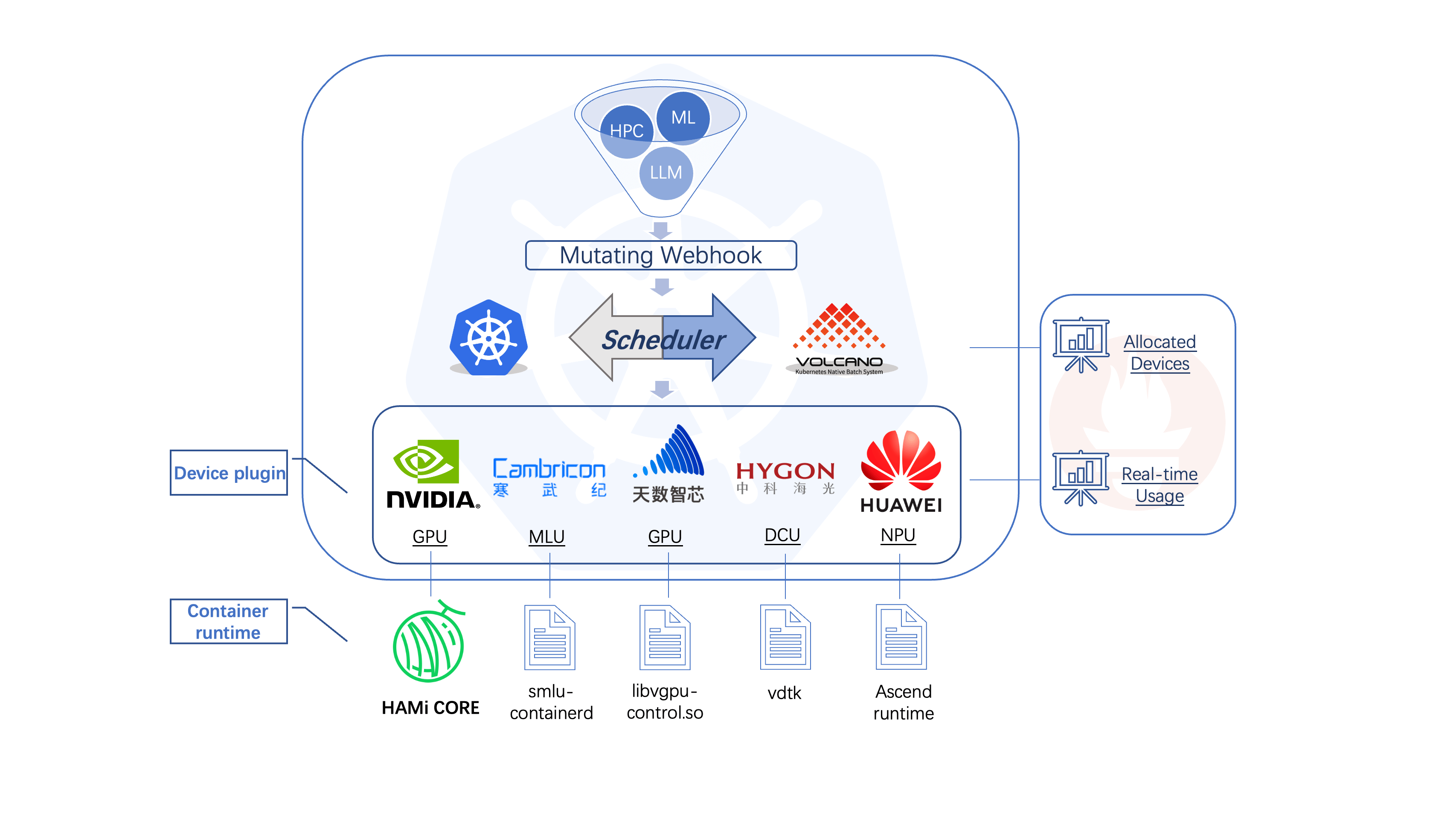
HAMi 最大的一个功能点就是可以实现 GPU 的细粒度的隔离,可以对 core 和 memory 使用 1% 级别的隔离。
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: ubuntu-container
image: ubuntu:18.04
command: ["bash", "-c", "sleep 86400"]
resources:
limits:
nvidia.com/gpu: 1 # 请求1个vGPUs
nvidia.com/gpumem: 3000 # 每个vGPU申请3000m显存 (可选,整数类型)
nvidia.com/gpucores: 30 # 每个vGPU的算力为30%实际显卡的算力 (可选,整数类型)
HAMi不是采用的TimeSlicing时分复用方案,因为时分复用没有做隔离会存在资源竞争,而是通过vCUDA实现GPU core 和 memory 隔离、限制。
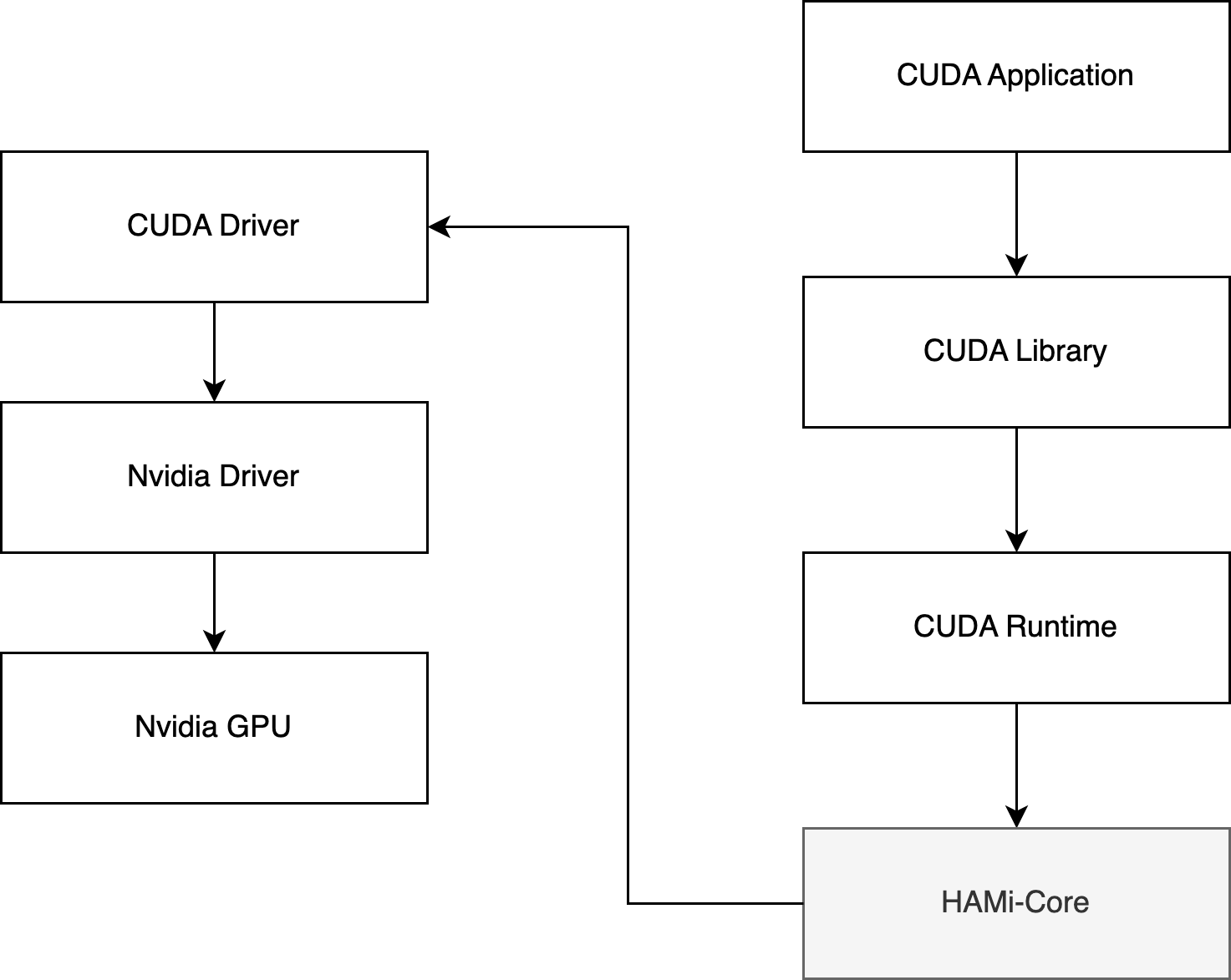
HAMi 使用的是软件层面的 vCUDA 方案,对 NVIDIA 原生的 CUDA 驱动进行重写(libvgpu.so),然后挂载到 Pod 中进行替换,然后在自己的实现的 CUDA 驱动中对 API 进行拦截,实现资源隔离以及限制的效果。
例如:原生 libvgpu.so 在进行内存分配时,只有在 GPU 内存真的用完的时候才会提示 CUDA OOM,但是对于 HAMi 实现的 libvgpu.so 来说,检测到 Pod 中使用的内存超过了 Resource 中的申请量就直接返回 OOM,从而实现资源的一个限制。
然后在执行 nvidia-smi 命令查看 GPU 信息时,也只返回 Pod Resource 中申请的资源,这样在查看时也进行隔离。
K8S部署HAMi
简要介绍下k8s部署HAMi的过程和各种组件。
部署GPU-Opeartor
GPU-Operator 旨在简化在 Kubernetes 环境中使用 GPU 的过程,通过自动化的方式处理 GPU 驱动程序安装、Controller Toolkit、Device-Plugin 、监控等组件。HAMi依赖英伟达的整套驱动。
部署HAMi
通过Helm可以一键部署HAMi,主要是hami-device-plugin和hami-scheduler两个pod。
查看与测试GPU使用
同样查看节点GPU情况
$ kubectl get node xxx -oyaml|grep capacity -A 7
capacity:
cpu: "4"
ephemeral-storage: 206043828Ki
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: 15349120Ki
nvidia.com/gpu: "10" # GPU 的分割数,每一张GPU 都不能分配超过其配置数目的任务。若其配置为N的话,每个 GPU 上最多可以同时存在 N 个任务。默认值10。
pods: "110"
起一个pod验证GPU挂载
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: ubuntu-container
image: ubuntu:18.04
command: ["bash", "-c", "sleep 86400"]
resources:
limits:
nvidia.com/gpu: 1 # 请求1个vGPUs
nvidia.com/gpumem: 3000 # 每个vGPU申请3000m显存 (可选,整数类型)
nvidia.com/gpucores: 30 # 每个vGPU的算力为30%实际显卡的算力 (可选,整数类型)
进入pod,使用nvidia-smi(一个命令行实用程序,用于查询和控制NVIDIA GPU的状态和配置。它是NVIDIA GPU驱动程序包的一部分,允许用户查看关于系统上安装的GPU、其当前状态、运行的进程以及其他相关信息的详细报告)查看GPU信息。
[HAMI-core Msg(16:139711087368000:libvgpu.c:836)]: Initializing.....
Mon Apr 29 06:22:16 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.14 Driver Version: 550.54.14 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 On | 00000000:00:07.0 Off | 0 |
| N/A 33C P8 15W / 70W | 0MiB / 3000MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
[HAMI-core Msg(16:139711087368000:multiprocess_memory_limit.c:434)]: Calling exit handler 16
PyTorch使用HAMi提供的GPU
HAMi会替换CUDA的驱动文件实现CUDA API劫持,但HAMi不会提供完整的CUDA,需要镜像中自带CUDA,如pytorch/pytorch:2.4.1-cuda11.8-cudnn9-runtime。
apiVersion: v1
kind: Pod
metadata:
name: hami-30
namespace: default
spec:
containers:
- name: simple-container
image: pytorch/pytorch:2.4.1-cuda11.8-cudnn9-runtime
command: ["python", "/mnt/imagenet/main.py", "-a", "resnet18", "--dummy"]
# 使用 sleep infinity 保持容器持续运行
resources:
requests:
cpu: "4"
memory: "32Gi"
nvidia.com/gpu: "1"
nvidia.com/gpucores: "30"
nvidia.com/gpumem: "20000"
limits:
cpu: "4"
memory: "32Gi"
nvidia.com/gpu: "1" # 1 个 GPU
nvidia.com/gpucores: "30" # 申请使用 30% 算力
nvidia.com/gpumem: "20000" # 申请 20G 显存(单位为 MB)
env:
- name: GPU_CORE_UTILIZATION_POLICY
value: "force" # 设置环境变量 GPU_CORE_UTILIZATION_POLICY 为 force,限制算力使用,默认的限制策略是该 GPU 只有一个 Pod 在使用时就不会做算力限制,可以提升 GPU 利用率
volumeMounts:
- name: imagenet-volume
mountPath: /mnt/imagenet # 容器内挂载点
- name: shm-volume
mountPath: /dev/shm # 挂载共享内存到容器的 /dev/shm
restartPolicy: Never
volumes:
- name: imagenet-volume
hostPath:
path: /root/lixd/hami/examples/imagenet # 主机目录路径,使用 PyTorch 提供的 Examples 作为测试脚本,https://github.com/pytorch/examples.git
type: Directory
- name: shm-volume
emptyDir:
medium: Memory # 使用内存作为 emptyDir
HAMi组件与原理
HAMi-device-plugin-nvidia
HAMi用自己实现的device plugin取代了原来NVIDIA GPU-Operator部署的device plugin,主要在三个地方进行修改:
- Register:两个作用:将插件注册到 Kubelet 的;感知 Node 上的 GPU 信息并传给 kube-apiserver ,将这部分信息以 annotations 的形式添加到 Node 对象上,以便后续 hami-scheduler 使用。参数 ResourceName 比较重要,HAMi会将GPU信息呈现为 –resource-name=nvidia.com/vgpu。
- ListAndWatch:感知节点上的设备并上报给 Kubelet。由于需要将同一个 GPU 切分给多个 Pod 使用,因此 HAMi 的 device plugin 也会有类似 TimeSlicing 中的 Device 复制操作。
- Allocate(核心):控制device plugin 将 GPU 分配给 Pod ,根据 Pod Resource 中的申请资源数量设置对应的环境变量,以及挂载 libvgpu.so 以替换 Pod 中的原生驱动
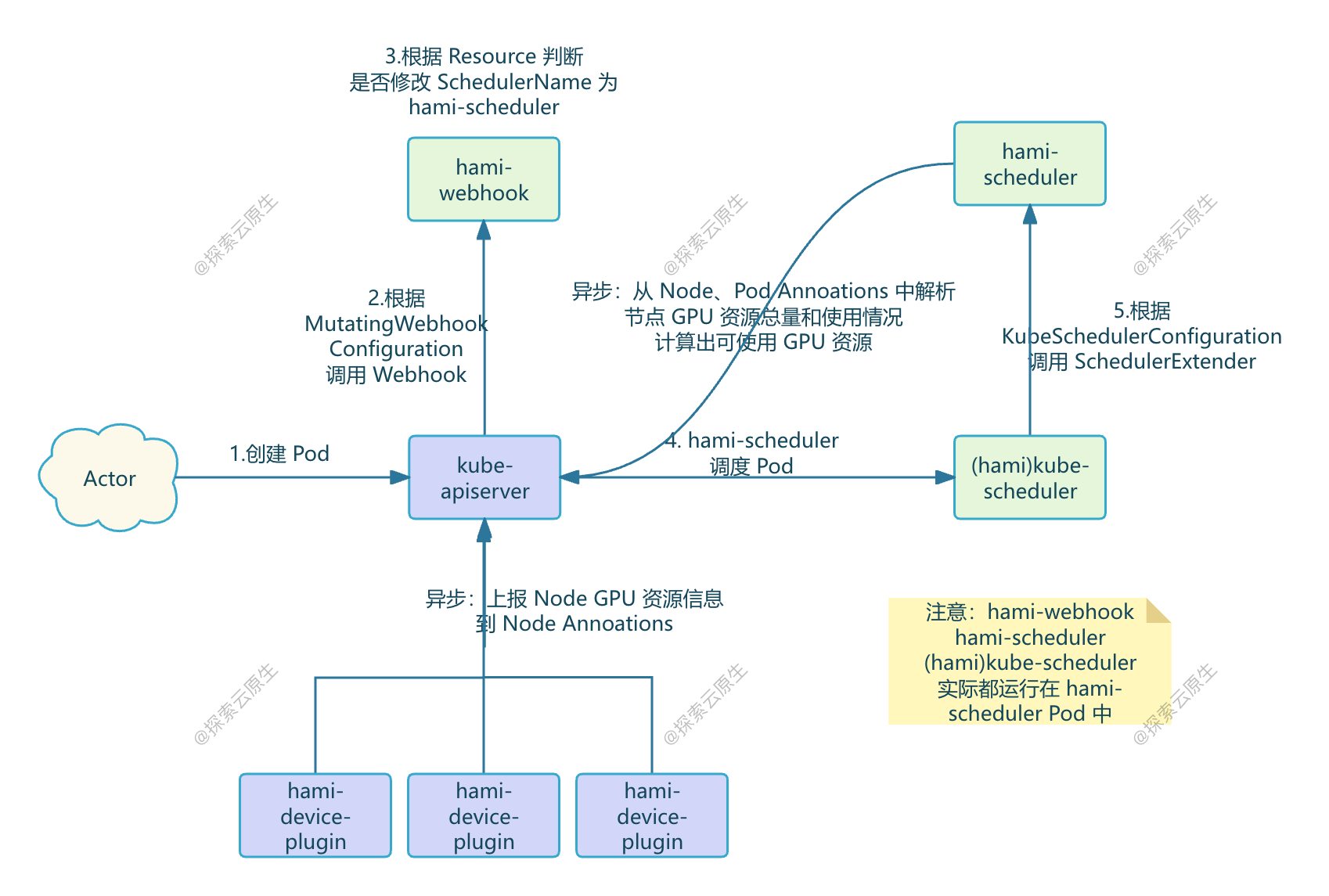
HAMi-Scheduler
-
用户创建 Pod 并在 Pod 中申请了 vGPU 资源
-
kube-apiserver 根据 MutatingWebhookConfiguration 配置请求 HAMi-Webhook
-
HAMi-Webhook 检测 Pod 中的 Resource,如果申请的由 HAMi 管理的 vGPU 资源,就会把 Pod 中的 SchedulerName 改成了 hami-scheduler,这样这个 Pod 就会由 hami-scheduler 进行调度了。
[!NOTE]
对于特权模式的 Pod,Webhook 会直接跳过不处理
对于使用 vGPU 资源但指定了 nodeName 的 Pod,Webhook 会直接拒绝
-
hami-scheduler 进行 Pod 调度,不过就是用的 k8s 的默认 kube-scheduler 镜像,因此调度逻辑和默认的 default-scheduler 是一样的,但是 kube-scheduler 还会根据 KubeSchedulerConfiguration 配置,调用 Extender Scheduler 插件。
这个 Extender Scheduler 就是 hami-scheduler Pod 中的另一个 Container,该 Container 同时提供了 Webhook 和 Scheduler 相关 API。
当 Pod 申请了 vGPU 资源时,kube-scheduler 就会根据配置以 HTTP 形式调用 Extender Scheduler 插件,这样就实现了自定义调度逻辑。
-
Extender Scheduler 插件包含了真正的 hami 调度逻辑, 调度时根据节点剩余资源量进行打分选择节点。
-
异步任务,包括 GPU 感知逻辑
- devicePlugin 中的后台 Goroutine 定时上报 Node 上的 GPU 资源并写入到 Node 的 Annoations
- 除了 DevicePlugin 之外,还使用异步任务以 Patch Annotation 方式提交更多信息
- Extender Scheduler 插件根据 Node Annoations 解析出 GPU 资源总量、从 Node 上已经运行的 Pod 的 Annoations 中解析出 GPU 使用量,计算出每个 Node 剩余的可用资源保存到内存供调度时使用
HAMi-Core
HAMi-core(libvgpu.so)项目就是 vCUDA 的核心实现,作用在CUDA-Runtime(libcudart.so) 和 CUDA-Driver(libcuda.so)之间。
libvgpu.so 是怎么生效的?
- 1)device plugin 在 Allocate 方法中使用 hostPath 方式将宿主机上的 libvgpu.so 挂载到 Pod 中
- 2)并通过 LD_PRELOAD 方式实现优先加载上一步中挂载的 libvgpu.so 库,使其生效
CUDA API 怎么拦截的?
通过重写 dlsym 函数,以劫持 NVIDIA 动态链接库(如 CUDA 和 NVML)的调用,特别是针对以 cu 和 nvml 开头的函数进行拦截。
gpu memory 是怎么限制的?
首先是拦截 NVMLAPI 中的 _nvmlDeviceGetMemoryInfo,实现在执行 nvidia-smi 命令时只展示申请的 Memory(来源于CUDA_DEVICE_MEMORY_LIMIT_X)。
然后是拦截内存分配相关的 CUDA API,比如:cuMemoryAllocate 和 cuMemAlloc_v2。
分配内存之前,增加了 oom_check,当前 Pod 的 GPU 内存使用量 超过 限制的内存使用量(来源于CUDA_DEVICE_MEMORY_LIMIT_X)时直接返回 OOM。
gpu core 是怎么限制的?
同理,拦截提交 Kernel 相关的 CUDA API,例如:cuLaunchKernel。
提交 Kernel 之前,增加 rate_limit 逻辑,具体算法类似令牌桶,每次提交 kernel 都会消耗 Token,直到某次提交 kernel 发现没有 Token 时就会直接 sleep, 一段时间之后 Token 恢复了,又可以继续提交任务了。
恢复 Token 时就会用到CUDA_DEVICE_SM_LIMIT 环境变量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号