
Python3.6支付宝账单爬虫
Python3.6支付宝账单爬虫
2020年8月31日
https://blog.csdn.net/Vision_Tung/article/details/108327448
最新版本,可用,持续更新。
邮箱:1023006144@qq.com
----------------------------以下版本已失效----------------------
2019年6月13日版本:
当前版本仍然可用,但由于个人原因不再提供更新。
邮箱:1023006144@qq.com
2019年3月15日版本:
发现网上有人抄袭我的博客,请大家爱护好自己财产!
源码由Python实现,可在Linux or Windows上稳定,支持个人账户和企业账户,支持Python2+ or 3+,可稳定运行
[申明]:本人还是学生,只支持双休日维护,见谅!
运行视频:
https://weibo.com/tv/v/Hl3Q9B0nt?fid=1034:4350196369281581
这视频是IDLE下打印的,现在已经接上Mysql数据库:

![]()
24小时无限登陆测试:
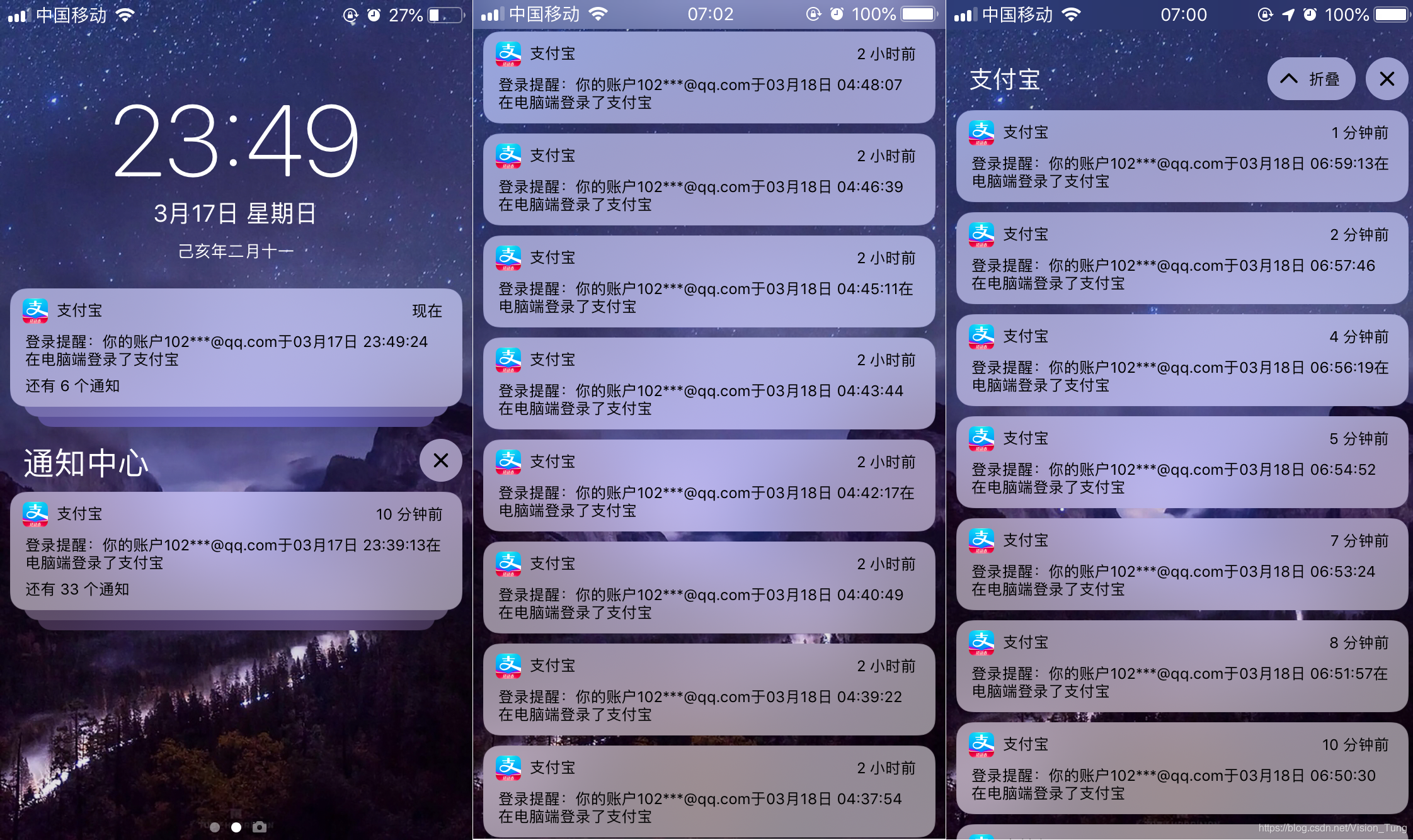
搜索到本文的你,一定明白,支付宝最麻烦的是登录验证,所以我唯一解决的就是登录问题。源码功能可以实现多账户自动登录,不需要验证码、二维码,中途也不会出现。可以无监督运行。
由于许多人不会Python,所以我接上了数据库,这样,你们只需在服务器上运行此脚本,然后通过轮询数据库来实现你们想要的功能。
2019.03.15 20:23 Vision_Tung 留
--------以下为原文,先阶段的代码和逻辑已经和下文相差甚远---------
本人认为支付宝爬虫其实是没有任何意义的,因为只能爬取自己的信息。如果爬别人的信息,首先,马云爸爸不同意,其次,这个方向就已经不是网络爬虫,而是网络黑客,我也不会。
以下内容如果是用于学习,仅供参考,如若是闲着无聊,您老人家就在此结束吧!
重点:此方法没有使用烦人的Cookies,硬刚爬虫!
分析:
- 先进入支付宝网页了解下情况(传送门:登陆-支付宝)
- 有两种方式登陆 扫码 or 账号,选择后者(因为自动登陆)
- 如果你有幸成功进入主页,那么算你运气好
- 如果你需要再次扫码,那么这就是需要我们解决的第一个问题

- 进入页面后是这样的

- 主页只有七条数据,而我们要的是全部
- 进入账单页面

- OK 了解,具体步骤见下



具体流程如下:
![]()

核心代码:
- 自动登陆(老生常谈,不多赘述)
ali_num = '******'# 账号密码
ali_pad= '*****' #密码
driver.find_element_by_xpath('//*[@id="J-input-user"]').clear()
time.sleep(3)
for i in ali_num:
driver.find_element_by_xpath('//*[@id="J-input-user"]').send_keys(i)
time.sleep(0.5)
driver.find_element_by_xpath('//*[@id="password_rsainput"]').clear()
driver.find_element_by_xpath('//*[@id="password_rsainput"]').click()
for i in ali_pad:
driver.find_element_by_xpath('//*[@id="password_rsainput"]').send_keys(i)
time.sleep(0.5)
driver.find_element_by_xpath('//*[@id="password_rsainput"]').text
driver.find_element_by_xpath('//*[@id="J-login-btn"]').click()- 循环进入账单页面
driver.get('https://consumeprod.alipay.com/record/standard.htm')
time.sleep(2)
keep_safe(driver)
cnt = 0
for i in range(100):
'''
注意!!!!!!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
--Vision_Tung
2018年10月25日
'''- 二维码检测
def keep_safe(driver):
try:
F = 1
while(F):
if F_Login==1:
'''
注意!!!!!!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
--Vision_Tung
2018年10月25日
'''
except:
pass
- 获取数据
def getInfor(driver):
global N
for num in range(10):
num = num+1
al_day_xpath = '//*[@id="J-item-'+str(num)+'"]/td[2]/p[1]' #//*[@id="J-item-1"]/td[2]/p[1] 日期
al_time_xpath = '//*[@id="J-item-'+str(num)+'"]/td[2]/p[2]' #//*[@id="J-item-1"]/td[2]/p[2] 时刻
al_way_xpath = '//*[@id="J-item-'+str(num)+'"]/td[3]/p[1]' #//*[@id="J-item-1"]/td[3]/p[1] 方式
al_payee_xpath = '//*[@id="J-item-'+str(num)+'"]/td[3]/p[2]' #//*[@id="J-item-1"]/td[3]/p[2]/span 收款人
al_snum_xpath = '//*[@id="J-tradeNo-'+str(num)+'"]' #//*[@id="J-tradeNo-1"] 号#.get_attribute("title")
al_figure_xpath = '//*[@id="J-item-'+str(num)+'"]/td[4]/span' #//*[@id="J-item-1"]/td[4]/span 金额
al_status_xpath = '//*[@id="J-item-'+str(num)+'"]/td[6]/p[1]' #//*[@id="J-item-1"]/td[6]/p[1] 交易状态
al_day = driver.find_element_by_xpath(al_day_xpath).text
al_time = driver.find_element_by_xpath(al_time_xpath).text
al_way = driver.find_element_by_xpath(al_way_xpath).text
al_payee = driver.find_element_by_xpath(al_payee_xpath).text
al_snum = driver.find_element_by_xpath(al_snum_xpath).get_attribute("title")
al_figure = driver.find_element_by_xpath(al_figure_xpath).text
al_status = driver.find_element_by_xpath(al_status_xpath).text
print(str(N)+'.'+'日期'+':'+al_day+'\t时间'+':'+al_time+'\t方式'+':'+al_way+'\t收款人'+':'+al_payee+'\t流水号'+':'+al_snum+'\t金额'+':'+al_figure+'\t交易状态'+':'+al_status)
N = N +1唯一需要注意的是流水号并不在text里,而是在title属性中
效果:
![]()

![]()

全部代码:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
N = 1
F_Login = 0
def keep_safe(driver):
'''
注意!!!!!!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
--Vision_Tung
2018年10月25日
'''
def getInfor(driver):
global N
for num in range(10):
num = num+1
al_day_xpath = '//*[@id="J-item-'+str(num)+'"]/td[2]/p[1]' #//*[@id="J-item-1"]/td[2]/p[1] 日期
al_time_xpath = '//*[@id="J-item-'+str(num)+'"]/td[2]/p[2]' #//*[@id="J-item-1"]/td[2]/p[2] 时刻
al_way_xpath = '//*[@id="J-item-'+str(num)+'"]/td[3]/p[1]' #//*[@id="J-item-1"]/td[3]/p[1] 方式
al_payee_xpath = '//*[@id="J-item-'+str(num)+'"]/td[3]/p[2]' #//*[@id="J-item-1"]/td[3]/p[2]/span 收款人
al_snum_xpath = '//*[@id="J-tradeNo-'+str(num)+'"]' #//*[@id="J-tradeNo-1"] 号#.get_attribute("title")
al_figure_xpath = '//*[@id="J-item-'+str(num)+'"]/td[4]/span' #//*[@id="J-item-1"]/td[4]/span 金额
al_status_xpath = '//*[@id="J-item-'+str(num)+'"]/td[6]/p[1]' #//*[@id="J-item-1"]/td[6]/p[1] 交易状态
al_day = driver.find_element_by_xpath(al_day_xpath).text
al_time = driver.find_element_by_xpath(al_time_xpath).text
al_way = driver.find_element_by_xpath(al_way_xpath).text
al_payee = driver.find_element_by_xpath(al_payee_xpath).text
al_snum = driver.find_element_by_xpath(al_snum_xpath).get_attribute("title")
al_figure = driver.find_element_by_xpath(al_figure_xpath).text
al_status = driver.find_element_by_xpath(al_status_xpath).text
print(str(N)+'.'+'日期'+':'+al_day+'\t时间'+':'+al_time+'\t方式'+':'+al_way+'\t收款人'+':'+al_payee+'\t流水号'+':'+al_snum+'\t金额'+':'+al_figure+'\t交易状态'+':'+al_status)
N = N +1
driver = webdriver.Chrome(executable_path='chromedriver.exe')
driver.get("https://auth.alipay.com/login/index.htm?goto=https%3A%2F%2Fmy.alipay.com%2Fportal%2Fi.htm%3Freferer%3Dhttps%253A%252F%252Fauthet15.alipay.com%252Flogin%252FhomeB.htm")
driver.find_element_by_xpath('//*[@id="J-loginMethod-tabs"]/li[2]').click()
'''
注意!!!!!!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
--Vision_Tung
2018年10月25日
'''
for i in range(8):
'''
注意!!!!!!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
此块细节已影藏!!!!
--Vision_Tung
2018年10月25日
'''
 浙公网安备 33010602011771号
浙公网安备 33010602011771号