4.CSV 文件参数化和__CSVRead函数(函数助手参数化),计数器参数化
一:CSV Date参数化--循环由线程和循环器共同决定,一般用循环器控制
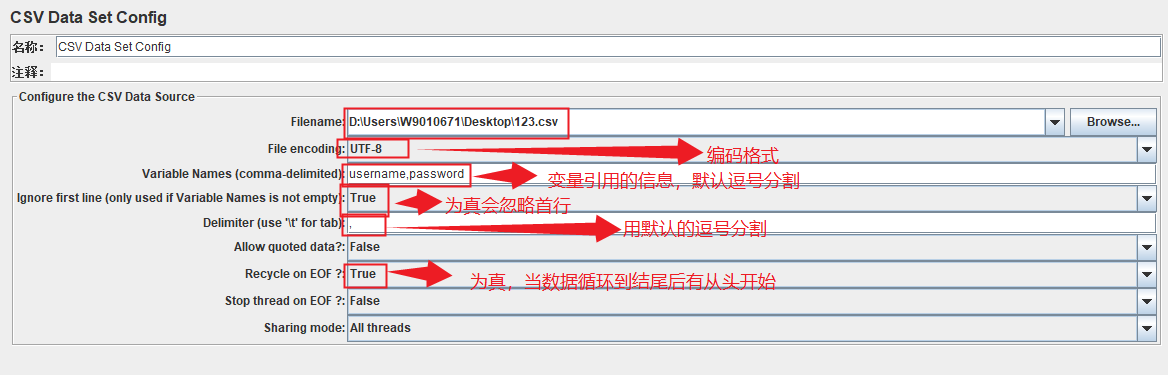
CSV Data Set Config---位置在配置元件下(当线程数为1,一定要放在循环控制器下面,不然只读第一行的数据,循环控制器指定次数)

Filename:文件路径
1:在txt文件里输入首行的名称信息逗号分割---配合需要忽略首行
2:txt保存为UTF-8的格式,然后重命名为csv格式
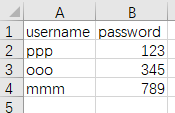
3:在csv文件中写入数据
1:csv配置
注意:变量引用可以是全部,可以是一个或多个。编码格式(UTF-8,utf-8都可以)
2:jmeter读取csv中文乱码,应该csv文件编码设置为gbk(GBK)

二:__CSVRead函数--(读的是csv文件每列的值,值是确定的)--线程组控制
优点:相较于CSV Data不需要配置。缺点是不能忽略首行
txt文件先保存ANSI格式在重命名csv保存
数据(包含中文)
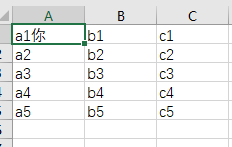

它是由线程组中线程数去定义循环遍历的
线程数为1,循环控制器为3,结果

线程数为7,循环控制器为1,结果遍历到第5次全部数据读完,有重新开始

三:函数参数化(每次读的值是不确定的)--如果需要用到函数参数化每循环一次对应的值相同--可以定义用户参数(在前置处理器下--在迭代下(循环器和线程组下使用))
一个随机值跑完整个接口自动化流程(一个线程流程的随机值都一样,另一个线程生成新的随机值,跑完这个线程)
用户参数------是有线程组决定的,一个线程组读一个用户,与循环器无关----必须勾选每次迭代更新一次,不然和用户定义变量一样

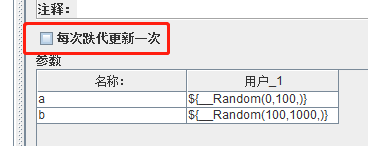
1:不勾选

2:勾选--一个线程组相同的值跑完一个流程

四:计数器(在配置元件下)
相较于__count函数的优势是可以自定义初始值
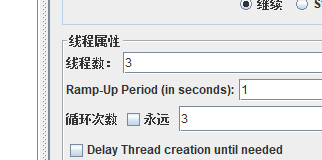

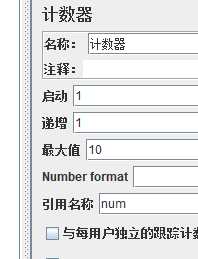
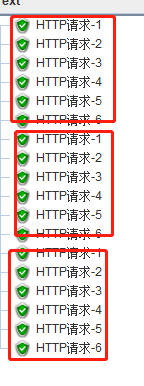
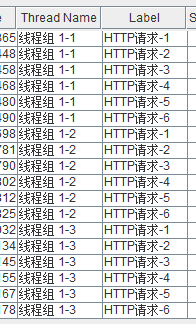
1:未勾选每个用户独立计数--3*3*2=18
2:勾选每个用户,
3个线程组,每个线程循环6次
第一个线程组先循环6次 -1到6
第二个线程组先循环6次 -1到6
五:__RandomString函数,由线程和循环器共同决定

六:计数器函数__counter从1开始
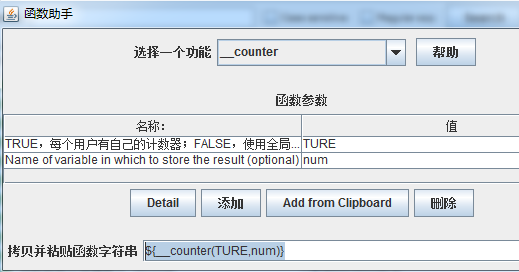
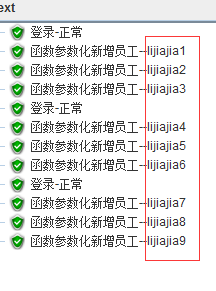
为TURE ,每个用户单独计数(用户数由线程数决定),循环器(决定每个用户循环次数),每请求一次计数会加自动+1





每个用户每请求一次计数会加一
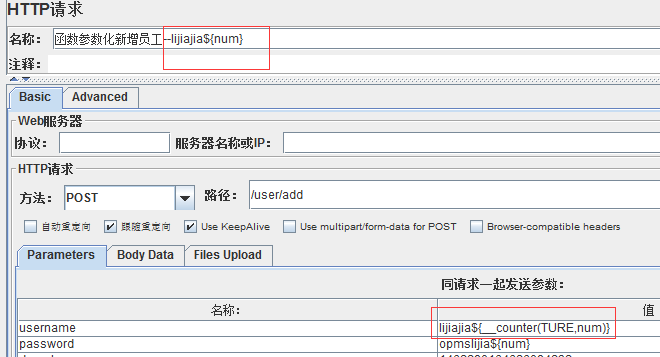
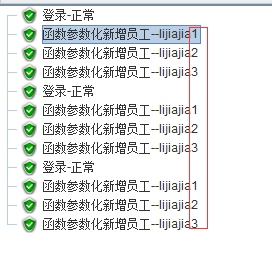
为FALSE,每个用户(线程)不用单独计数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号