
HADOOP HA 搭建
1. 准备三台虚拟机
修改host文件
[root@localhost ~]# vi /etc/hosts
192.168.2.151 bigdata1 192.168.2.152 bigdata2 192.168.2.153 bigdata3
查看防火墙状态
[root@bigdata1 ~]# systemctl status firewalld
关闭防火墙
[root@bigdata1 ~]# systemctl stop firewalld
开机防火墙不启动
[root@bigdata1 ~]# systemctl disable firewalld
2. 设置静态ip/主机名/重启
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="static" DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens33" UUID="f543d854-9cf6-43e5-9746-74658a75e808" DEVICE="ens33" ONBOOT="yes" IPADDR=192.168.2.151 #对应的ip NETMASK=255.255.255.0 GATEWAY=192.168.2.2 DNS1=8.8.8.8 DNS2=114.114.114.114
[root@localhost ~]# hostnamectl set-hostname <newhostname> [root@localhost ~]# reboot
3. 编写群发脚本,便于发送
[root@bigdata1 ~]# vi /bin/xsync
#!/bin/bash #获取输入参数个数,如果没有参数,直接退出 pcount=$# if((pcount==0)); then echo no arg; exit; fi #获取文件名称 p1=$1 fname=`basename $p1` echo fname=$fname #获取上级目录的绝对路径 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #4获取当前用户名称 user=`whoami` #5循环 for((host=1;host<4;host++)); do echo ------------------- bigdata$host ------------------- rsync -av $pdir/$fname $user@bigdata$host:$pdir done
修改脚本使其具有执行权限
[root@bigdata1 ~]# chmod +x /bin/xsync
3. 创建安装目录
[root@bigdata1 ~]# mkdir -p /opt/module/ [root@bigdata1 ~]# mkdir -p /opt/software/
4. 角色分配
| bigdata1 | bigdata2 | bigdata3 |
| NameNode | NameNode | |
| JournalNode | JournalNode | JournalNode |
| DataNode | DataNode | DataNode |
| Zookeeper | Zookeeper | Zookeeper |
| ResourceManeger | ResourceManeger | |
| NodeManager | NodeManager | NodeManager |
5. 下载
jdk下载地址:https://www.oracle.com/java/technologies/javase-jdk15-downloads.html
zookeeper下载地址:https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.6.1/apache-zookeeper-3.6.1-bin.tar.gz
hadoop下载地址:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz
下载完毕全部上传到 /opt/software/ 目录
6. JDK安装
查看已安装JDK
[root@bigdata1 ~]# rpm -qa | grep java javapackages-tools-3.4.1-11.el7.noarch java-1.8.0-openjdk-headless-1.8.0.262.b10-0.el7_8.x86_64 java-1.8.0-openjdk-devel-1.8.0.262.b10-0.el7_8.x86_64 python-javapackages-3.4.1-11.el7.noarch tzdata-java-2020a-1.el7.noarch java-1.8.0-openjdk-1.8.0.262.b10-0.el7_8.x86_64
卸载已安装JDK
[root@bigdata1 ~]# rpm -qa | grep java | xargs rpm -e --nodeps
解压安装
[root@bigdata1 ~]# tar -zxvf /opt/software/jdk-15_linux-x64_bin.tar.gz -C /opt/module/
配置JDK环境变量
[root@bigdata1 ~]# vi /etc/profile
#JAVA_HOME export JAVA_HOME=/opt/module/jdk-15 export PATH=$PATH:$JAVA_HOME/bin
远程复制JDK、环境变量到另外两台主机 bigdata2、bigdata3 上并刷新环境变量
[root@bigdata1 ~]# xsync /opt/module/jdk-15/ [root@bigdata1 ~]# xsync /etc/profile
[root@bigdata1 ~]# source /etc/profile [root@bigdata2 ~]# source /etc/profile [root@bigdata3 ~]# source /etc/profile
验证是否安装成功
[root@bigdata1 jdk-15]# java -version
java version "15" 2020-09-15
Java(TM) SE Runtime Environment (build 15+36-1562)
Java HotSpot(TM) 64-Bit Server VM (build 15+36-1562, mixed mode, sharing)
7. 安装zookeeper
解压安装
[root@bigdata1 ~]# tar -zxvf /opt/software/apache-zookeeper-3.6.1-bin.tar.gz /opt/module/
切换到conf目录
[root@bigdata1 ~]# cd /opt/module/apache-zookeeper-3.6.1-bin/conf
拷贝zoo_sample.cfg目录命名为zoo.cfg
[root@bigdata1 conf]# cp zoo_sample.cfg zoo.cfg
修改zoo.cfg配置文件
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/opt/module/apache-zookeeper-3.6.1-bin/data clientPort=2181 server.1=bigdata1:2888:3888 server.2=bigdata2:2888:3888 server.3=bigdata3:2888:3888
在 bigdata1 上创建data目录和myid文件
[root@bigdata1 ~]# mkdir /opt/module/apache-zookeeper-3.6.1-bin/data [root@bigdata1 ~]# echo 1 > /opt/module/apache-zookeeper-3.6.1-bin/myid
远程复制zookeeper到另外两台主机 bigdata2、bigdata3 上并修改myid文件
[root@bigdata1 ~]# xsync /opt/module/apache-zookeeper-3.6.1-bin/
[root@bigdata2 ~]# echo 2 > /opt/module/apache-zookeeper-3.6.1-bin/data/myid [root@bigdata3 ~]# echo 3 > /opt/module/apache-zookeeper-3.6.1-bin/data/myid
配置三台主机zookeeper环境变量
[root@bigdata1 ~]# vi /etc/profile
#ZOOKEEPER_HOME export ZOOKEEPER_HOME=/opt/module/apache-zookeeper-3.6.1-bin export PATH=$PATH:$ZOOKEEPER_HOME/bin
[root@bigdata1 ~]# xsync /etc/profile
[root@bigdata1 ~]# source /etc/profile [root@bigdata2 ~]# source /etc/profile [root@bigdata3 ~]# source /etc/profile
启动
在三台主机上分别执行如下命令
[root@bigdata1 ~]# zkServer.sh start ZooKeeper JMX enabled by default Using config: /opt/module/apache-zookeeper-3.6.1-bin/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [root@bigdata2 ~]# zkServer.sh start ZooKeeper JMX enabled by default Using config: /opt/module/apache-zookeeper-3.6.1-bin/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [root@bigdata3 ~]# zkServer.sh start ZooKeeper JMX enabled by default Using config: /opt/module/apache-zookeeper-3.6.1-bin/bin/../conf/zoo.cfg Starting zookeeper ... STARTED
查询运行状态
[root@bigdata1 ~]# zkServer.sh status ZooKeeper JMX enabled by default Using config: /opt/module/apache-zookeeper-3.6.1-bin/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Mode: follower [root@bigdata2 ~]# zkServer.sh status /usr/bin/java ZooKeeper JMX enabled by default Using config: /opt/module/apache-zookeeper-3.6.1-bin/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Mode: leader [root@bigdata3 ~]# zkServer.sh status /usr/bin/java ZooKeeper JMX enabled by default Using config: /opt/module/apache-zookeeper-3.6.1-bin/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Mode: follower
8. 配置免密登陆
执行ssh-keygen -t rsa时按回车即可
[root@bigdata1 ~]# ssh-keygen -t rsa [root@bigdata1 ~]# ssh-copy-id bigdata1 [root@bigdata1 ~]# xsync /root/.ssh/
9. 编写查看全部机器java进程脚本
[root@bigdata1 ~]# vi /bin/jps-all
#!/bin/bash for((host=1;host<4;host++)); do echo ------------------- bigdata$host ------------------- ssh bigdata$host "source /etc/profile && jps" done
修改脚本使其具有执行权限
[root@bigdata1 ~]# chmod +x /bin/jps-all
发送到其他机器
[root@bigdata1 ~]# xsync jps-all
10. HADOOP安装
解压安装
[root@bigdata1 ~]# tar -zxvf /opt/software/hadoop-2.10.0.tar.gz -C /opt/module/
HADOOP环境变量配置
[root@bigdata1 ~]# vi /etc/profile
#HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-2.10.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HAME/sbin
环境变量分发、刷新
[root@bigdata1 ~]# xsync /etc/profile
[root@bigdata1 ~]# source /etc/profile [root@bigdata2 ~]# source /etc/profile [root@bigdata3 ~]# source /etc/profile
验证是否生效
[root@bigdata1 ~]# hdfs Usage: hdfs [--config confdir] [--loglevel loglevel] COMMAND where COMMAND is one of: dfs run a filesystem command on the file systems supported in Hadoop. classpath prints the classpath namenode -format format the DFS filesystem secondarynamenode run the DFS secondary namenode namenode run the DFS namenode journalnode run the DFS journalnode zkfc run the ZK Failover Controller daemon datanode run a DFS datanode debug run a Debug Admin to execute HDFS debug commands dfsadmin run a DFS admin client dfsrouter run the DFS router dfsrouteradmin manage Router-based federation haadmin run a DFS HA admin client fsck run a DFS filesystem checking utility balancer run a cluster balancing utility jmxget get JMX exported values from NameNode or DataNode. mover run a utility to move block replicas across storage types oiv apply the offline fsimage viewer to an fsimage oiv_legacy apply the offline fsimage viewer to an legacy fsimage oev apply the offline edits viewer to an edits file fetchdt fetch a delegation token from the NameNode getconf get config values from configuration groups get the groups which users belong to snapshotDiff diff two snapshots of a directory or diff the current directory contents with a snapshot lsSnapshottableDir list all snapshottable dirs owned by the current user Use -help to see options portmap run a portmap service nfs3 run an NFS version 3 gateway cacheadmin configure the HDFS cache crypto configure HDFS encryption zones storagepolicies list/get/set block storage policies version print the version Most commands print help when invoked w/o parameters.
切换到HADOOP配置目录
[root@bigdata1 ~]# cd /opt/module/hadoop-2.10.0/etc/hadoop/
配置hadoop-env.sh文件
[root@bigdata1 hadoop]# vim hadoop-env.sh
export JAVA_HOME=/opt/module/jdk-15
配置slaves文件
[root@bigdata1 hadoop]# vi slaves
bigdata1
bigdata2
bigdata3
配置core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.10.0/data/tmp</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>bigdata1:2181,bigdata2:2181,bigdata3:2181</value> </property> </configuration>
配置hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 完全分布式集群名称 --> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!-- 集群中NameNode节点 --> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>bigdata1:8020</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>bigdata2:8020</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>bigdata1:9870</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>bigdata2:9870</value> </property> <!-- 指定NamNode云数据在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://bigdata1:8485;bigdata2:8485;bigdata3:8485/mycluster</value> </property> <!-- 配置隔离机制,即同一时刻只能又一台服务器对外响应 --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- 使用隔离机制时需要ssh无密钥登录 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!-- 声明journalnode服务器存储目录 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/module/hadoop-2.10.0/data/jn</value> </property> <!-- 关闭权限检查 --> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> <!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式 --> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration>
HADOOP分发
[root@bigdata1 ~]# xsync /opt/module/hadoop-2.10.0/
切换到hadoop根目录
[root@bigdata1 ~]# cd /opt/module/hadoop-2.10.0/
启动journalnode
[root@bigdata1 hadoop-2.10.0]# sbin/hadoop-daemons.sh start journalnode
查看进程
[root@bigdata1 hadoop-2.10.0]# jps-all ------------------- bigdata1 ------------------- 65764 QuorumPeerMain 70681 Jps 70430 JournalNode ------------------- bigdata2 ------------------- 63064 JournalNode 60569 QuorumPeerMain 63275 Jps ------------------- bigdata3 ------------------- 56518 QuorumPeerMain 59019 JournalNode 59245 Jps
格式化NameNode
[root@bigdata1 hadoop-2.10.0]# bin/hdfs namenode -format
初始化HA在Zookeeper中状态
[root@bigdata1 hadoop-2.10.0]# bin/hdfs zkfc -formatZK
启动HDFS集群
[root@bigdata1 hadoop-2.10.0]# sbin/start-dfs.sh
启动第二个NameNode
[root@bigdata2 hadoop-2.10.0]# bin/hdfs namenode -bootstrapStandby [root@bigdata2 hadoop-2.10.0]# sbin/hadoop-daemon.sh start namenode
查看进程
[root@bigdata1 hadoop-2.10.0]# jps-all ------------------- bigdata1 ------------------- 79107 JournalNode 80739 NameNode 65764 QuorumPeerMain 90506 Jps 81452 DFSZKFailoverController 80991 DataNode ------------------- bigdata2 ------------------- 76889 Jps 60569 QuorumPeerMain 67752 DFSZKFailoverController 65885 JournalNode 69117 NameNode 67484 DataNode ------------------- bigdata3 ------------------- 56518 QuorumPeerMain 62426 DataNode 60876 JournalNode 71599 Jps
查看NameNode的状态
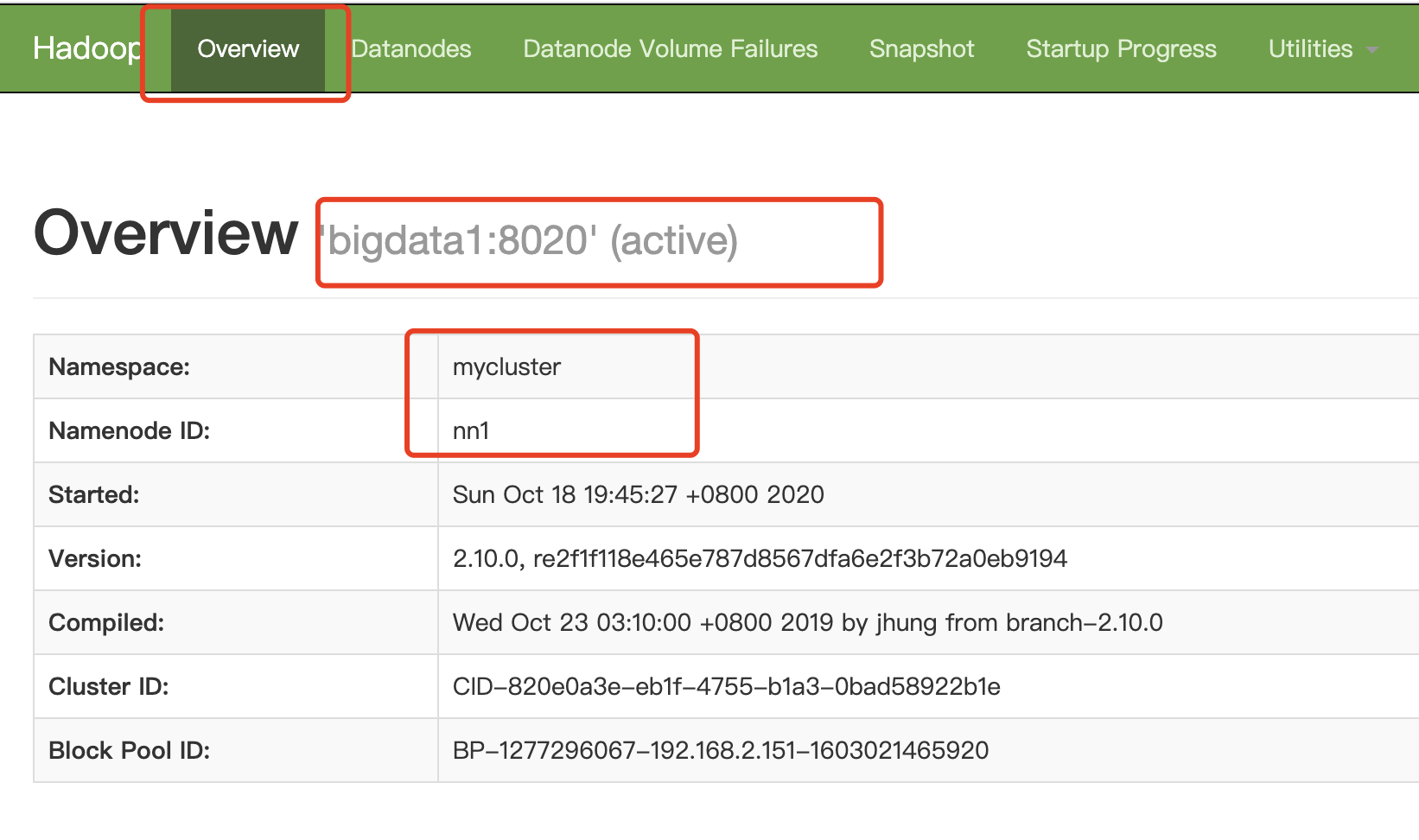
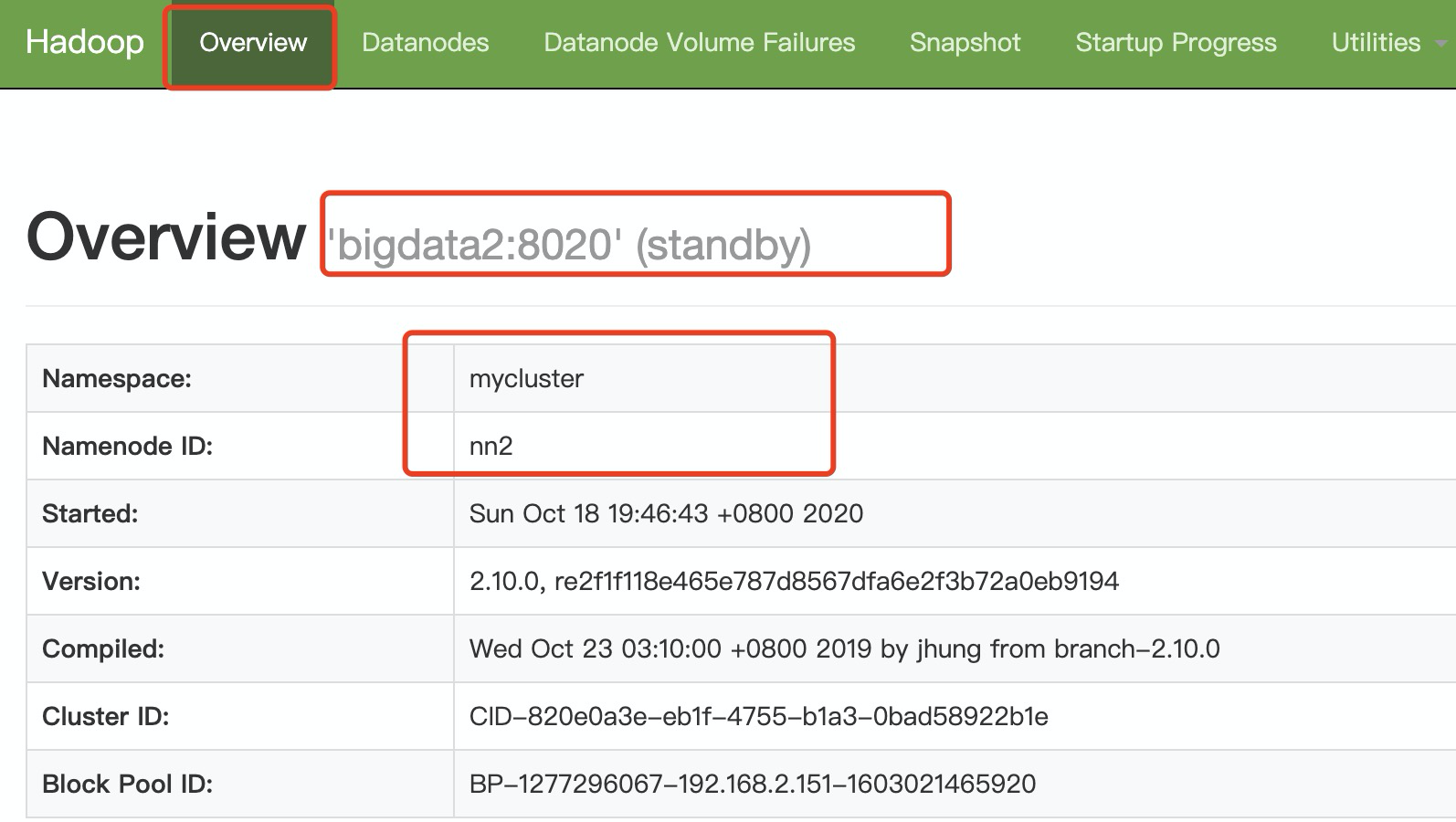
[root@bigdata1 ~]# hdfs haadmin -getServiceState nn1 active [root@bigdata1 ~]# hdfs haadmin -getServiceState nn2 standby
查看浏览器
http://bigdata1:9870/dfshealth.html#tab-overview
http://bigdata2:9870/dfshealth.html#tab-overview
把nn1机器重启
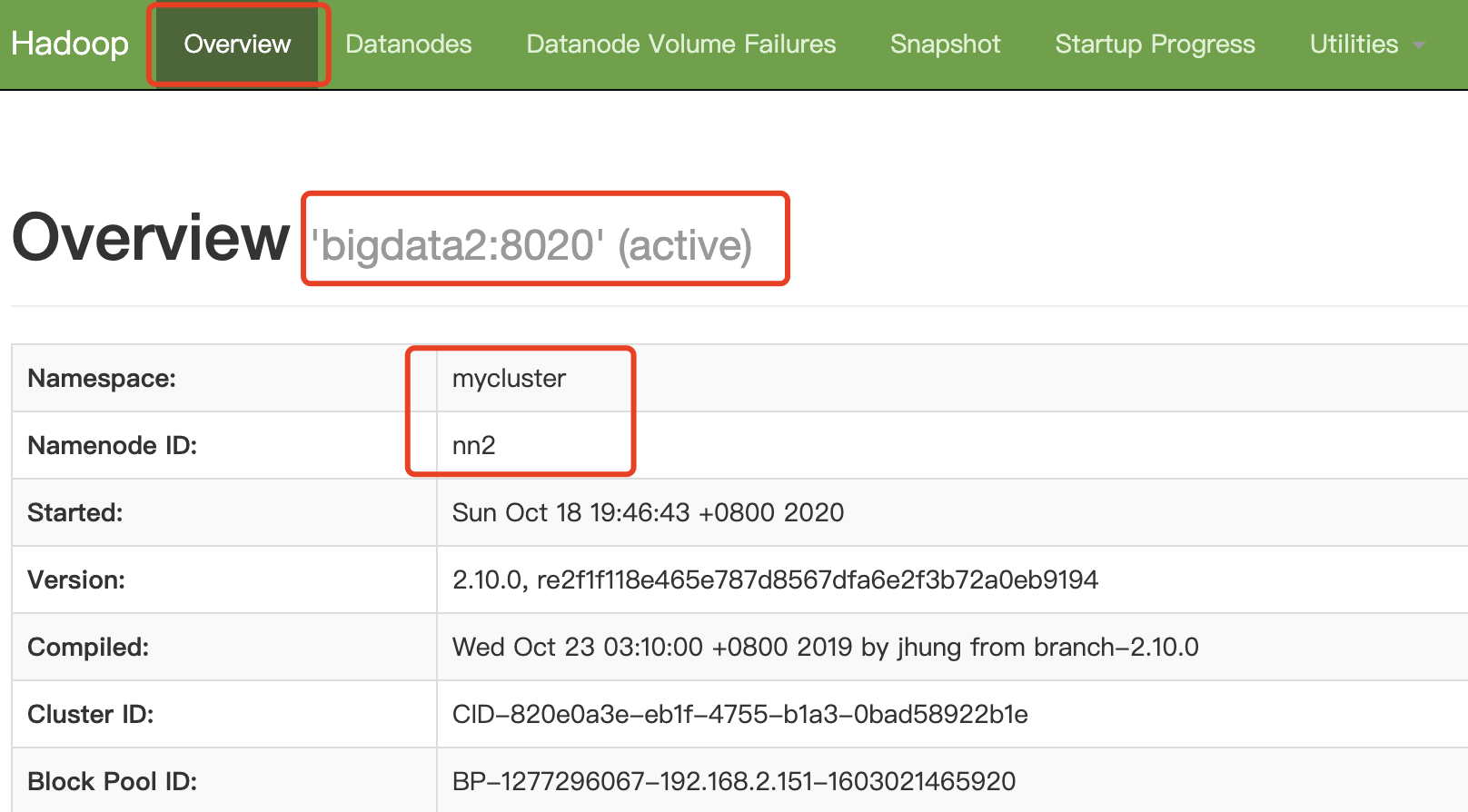
[root@bigdata1 hadoop-2.10.0]# reboot 连接断开
查看浏览器nn2变成active
http://bigdata2:9870/dfshealth.html#tab-overview
配置yarn-site.xml
<?xml version="1.0"?> <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster1</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>bigdata1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>bigdata2</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>bigdata1:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>bigdata2:8088</value> </property> <!-- zk集群 --> <property> <name>hadoop.zk.address</name> <value>bigdata1:2181,bigdata2:2181,bigdata3:2181</value> </property> <!-- 启动自动恢复 --> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!-- 指定resourcemanager的状态信息存储在zk集群 --> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore</value> </property> </configuration>
启动yarn集群
[root@bigdata1 hadoop-2.10.0]# sbin/start-yarn.sh
目前只会启动一个resourcemanager,需要手动启动另外一个
[root@bigdata2 hadoop-2.10.0]# sbin/yarn-daemon.sh start resourcemanager
查看进程
[root@bigdata2 hadoop-2.10.0]# jps-all ------------------- bigdata1 ------------------- 74465 NodeManager 72066 NameNode 72629 JournalNode 72278 DataNode 77878 Jps 72936 DFSZKFailoverController 74312 ResourceManager 70030 QuorumPeerMain ------------------- bigdata2 ------------------- 41921 DFSZKFailoverController 43249 NodeManager 41490 DataNode 41699 JournalNode 46325 ResourceManager 41334 NameNode 60569 QuorumPeerMain 46509 Jps ------------------- bigdata3 ------------------- 35601 DataNode 35810 JournalNode 37266 NodeManager 40434 Jps 56518 QuorumPeerMain
查看rm1和rm2状态
[root@bigdata1 hadoop-2.10.0]# bin/yarn rmadmin -getServiceState rm1 active [root@bigdata1 hadoop-2.10.0]# bin/yarn rmadmin -getServiceState rm2 standby
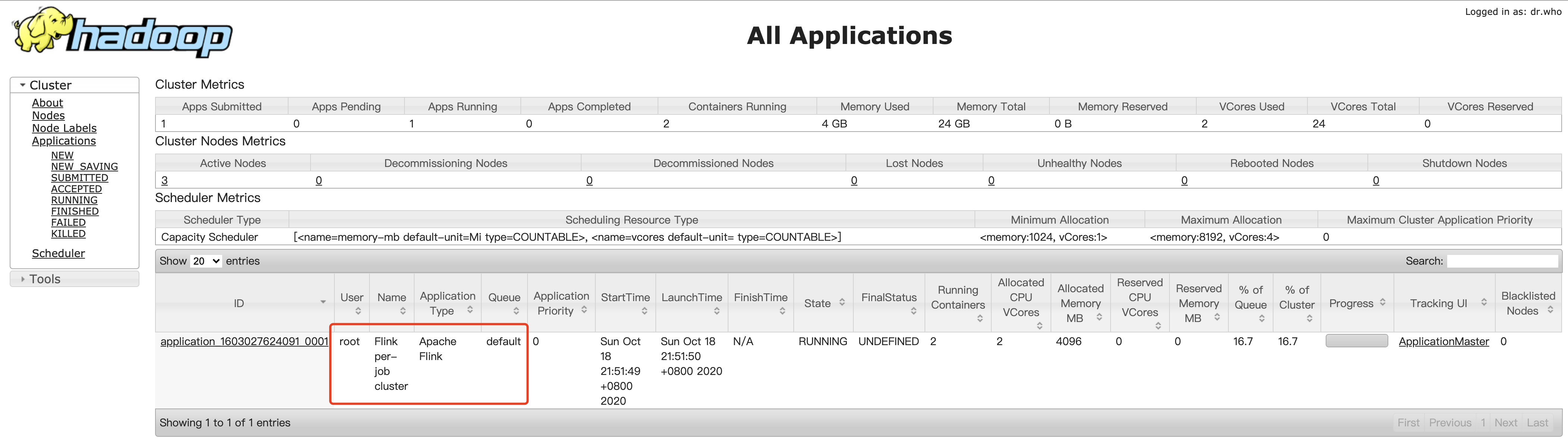
提交一个flink作业测试一下yarn集群
[root@bigdata1 bin]# ./flink run -m yarn-cluster -c org.apache.flink.streaming.examples.wordcount.WordCount /opt/module/flink-1.11.2/examples/streaming/WordCount.jar ------------------------------------------------------------ The program finished with the following exception: java.lang.IllegalStateException: No Executor found. Please make sure to export the HADOOP_CLASSPATH environment variable or have hadoop in your classpath. For more information refer to the "Deployment & Operations" section of the official Apache Flink documentation. at org.apache.flink.yarn.cli.FallbackYarnSessionCli.isActive(FallbackYarnSessionCli.java:59) at org.apache.flink.client.cli.CliFrontend.validateAndGetActiveCommandLine(CliFrontend.java:1090) at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:218) at org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:916) at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:992) at org.apache.flink.runtime.security.contexts.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:30) at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:992)
flink提交失败,原因是Flink发布了新版本1.11.0,增加了很多重要新特性,包括增加了对Hadoop3.0.0以及更高版本Hadoop的支持,不再提供“flink-shaded-hadoop-*” jars,而是通过配置YARN_CONF_DIR或者HADOOP_CONF_DIR和HADOOP_CLASSPATH环境变量完成与yarn集群的对接。
具体步骤如下:
- 确保安装有Hadoop集群,版本至少Hadoop 2.4.1
- 增加环境变量如下:
[root@bigdata1 ~]# vim /etc/profile export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export HADOOP_CLASSPATH=`hadoop classpath` [root@bigdata1 ~]# source /etc/profile
访问:http://bigdata1:8088/cluster 可查看到flink作业成功提交

 浙公网安备 33010602011771号
浙公网安备 33010602011771号