类型系统与程序语言——简单类型
简单类型
经过上一篇类型系统与程序语言——无类型系统的学习,已经对 Lambda 表达式初窥门径,但在使用时却会产生一些问题,比如可能产生 stuck 语句。上一章定义链表时用到了许多参数,但是如果不知道上下文,很难直接了解每个参数的含义。这时候一个类型系统就可以帮助我们规避这种错误和麻烦。
基本上专业的代码编辑器都会配有类型检查,而这一章所做的就是学习类型检查的基本规则。
有类型算数表达式
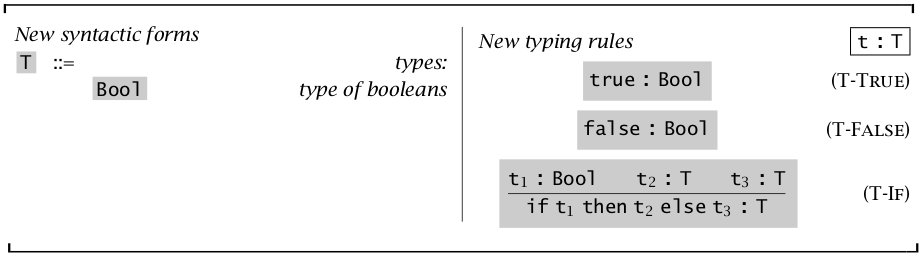
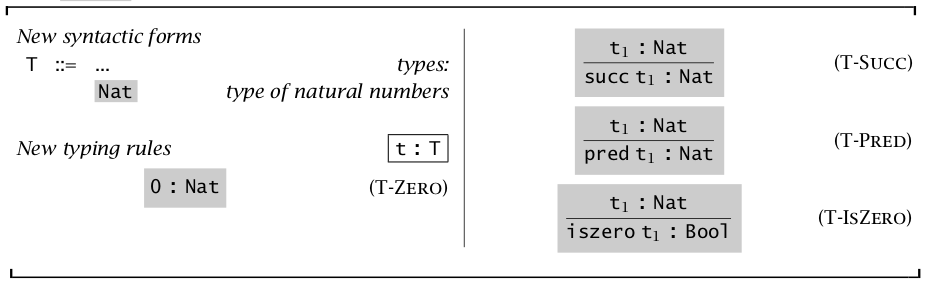
“\(:\)” 号代表有着什么类型。比如 \(\rm T\text-P\scriptsize RED\) 就说明:如果 \(t_1\) 是 \(Nat\) 类型,那么 \(\operatorname{pred} t_1\) 也是 \(Nat\) 类型。
同时定理【类型关系的唯一性】表明:一个 term 有且只有一个类型。定理【类型关系的倒置】表明:\(false:R\) 时,\(R=Bool\);\(\operatorname{succ} t_1:R\),则 \(R=Nat\) 并且 \(t_1=Nat\)。对其他关系同理。
Safety = Progress + Preservation
类型系统的第一要义是安全性,要达成这一点,就要保证不出现 stuck 的状态,也就是每个 term 都能够被归约为 value。
对于小标题,Safety = Progress + Preservation 其实也是一个归纳论证。
-
Safety:有类型(well-typed)的 term 都能够被归约为 value。
-
Progress:有类型的 term 要么是 value,要么能进行单步求值。
\[\begin{align*} \text{if $t:T$ for some $T$, then either $t$ is a value or $t\to t'$ for some $t'$} \end{align*} \] -
Preservation:有类型的 term 进行单步求值后依旧是类型良好的。
\[\begin{align*} \text{if $t:T$ and $t\to t'$, then $t':T$} \end{align*} \]
有类型 Lambda 表达式
我们先从 Boolean 开始,关于 Boolean 的类型可以由下列语法表示
比如类型 \(Bool \to Bool\) 就表示接受一个 \(Bool\) 参数,返回一个 \(Bool\) 值的函数;再如 \((Bool \to Bool) \to Bool\) 表示接受上一个类型的函数作为参数,返回一个 \(Bool\) 值的函数。
将前一篇中的无类型 Lambda 表达式添加显式类型,\(\lambda x:T.t\) 表示接受一个 \(T\) 类型参数的函数。
同样可以定义一系列推理规则
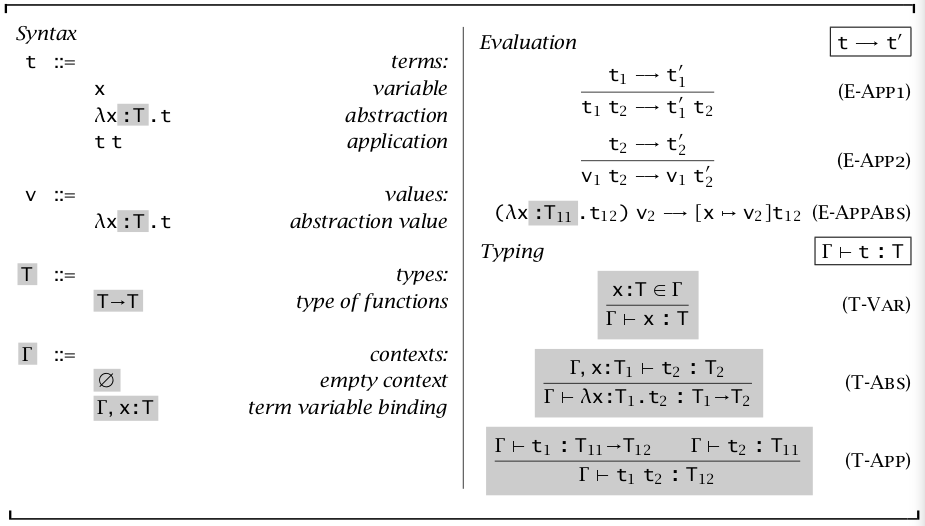
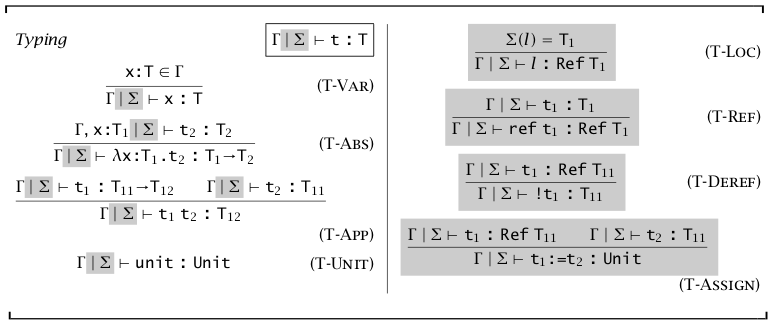
由于添加了类型,我们需要一个东西来管理类型,即 \(\Gamma\) 和 \(\vdash\),\(\Gamma\) 表示一系列自由变量的类型假设(type asSigmaptions),称为类型上下文(type context)。\(\Gamma\vdash t:T\) 就是对 \(t\) 中所有自由变量的假设可得出 \(t\) 为类型 \(T\),也可称为 \(\Gamma\) 指派 \(t\) 为 \(T\),而 \(\vdash t:T\) 等同于 \(\varnothing\vdash t:T\)。
同有类型算数表达式一样,也具有定理【类型关系的唯一性】和【类型关系的倒置】。
使用分类讨论证明定理 Progress:对于一个封闭的 \(t\),要么 \(t\) 是一个 value,要么存在 \(t'\) 使得 \(t\to t'\)
同样通过分类讨论和归纳法证明定理类型替换的 Preservation:\(\text{if }\Gamma, x:S\vdash t:T\text{ and }\Gamma \vdash s:S\text{, then }\Gamma\vdash[x\mapsto s]t:T\),即带入 \(x\) 的值不会改变 \(t\) 的类型
证明定理 Preservation:\(\text{if }\Gamma\vdash t:T\text{ and }t\to t'\text{, then }\Gamma\vdash t':T\)
同样可以通过分类和归纳论证,具体过程不列出了,需要考虑 \(t\to t'\) 的所有可能,充分使用类型关系的倒置等定理考虑。
简单类型拓展
在这一系统中添加新类型的方法:
- 给出新类型的类型规则;
- 给出新类型 preservation 和 progress 的证明。
在下列的类型拓展中,都会遵守以上规则。
基本类型(Base Types)

基本类型(也称原子类型)是简单且无结构的值,如数字(Nat)、布尔值(Bool)、字符串(String)、浮点数(Float)。
在我们创造的语言中,基本类型可以被定义为一个集合 \(\mathcal A\)(也可以是其他字符)。这一类型完全没有任何操作,只是一种标记。
比如 \(\lambda x:A.x\) 为类型 \(A\to A\),\(\lambda f:A\to A.\lambda x:A.f\ f\ x\) 为类型 \((A\to A)\to A\to A\)。
单例类型(Singleton Types)
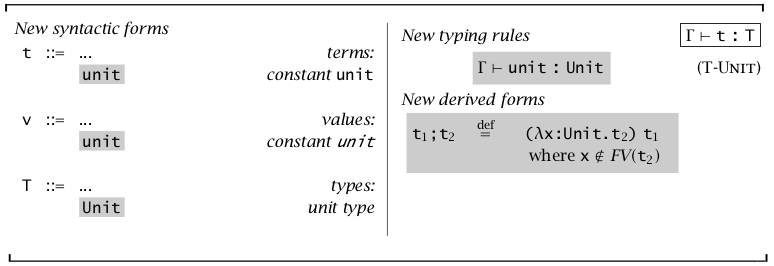
Unit 类型只有 unit 一个成员。事实上,包含 Unit 类型的演算的结果只会是 unit。在这门语言中使用 unit 就如同在 C 语言中使用 void 一样。它的主要作用是产生副作用。对于某些函数,我们并不关心它的返回值,而关注它的副作用(比如输入输出函数),这种函数的返回值就是 unit。
Unit 类型添加了一种新的形式,\(\overset{def}{=}\) 表示一种缩写,也称为语法糖。表明 \(t_1;t_2\) 就是 \((\lambda x:Unit.t_2)\ t_1\text{ where }x\notin FV(t_2)\) 的缩写。
顺序结构(Sequence)
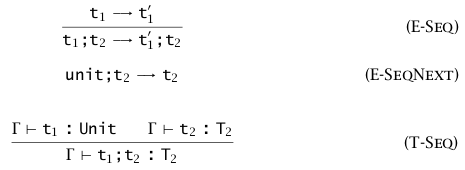
接着 Unit 类型,支持副作用的函数可能在一行函数中书写多个语句。一个形如 \(t_1;t_2\) 的语句将会先求值 \(t_1\),但最终并且抛弃它的结果,接着求值 \(t_2\)。这一表达式可以将副作用函数作为 \(t_1\)。图中的三个求值规则和 Unit 类型定义的规则是等价的,表明 Sequence 实际上并没有添加任何新规则,只是作为一个语法糖。
通配符(Wildcard)
在 Unit 中的 \((\lambda x:Unit.t_2)\ t_1\text{ where }x\notin FV(t_2)\) 表达得比较麻烦,将来会使用 \(\lambda\_:S.t\),表示 \(\lambda x:S.t\text{ where }x\notin FV(t)\),即 \(\_\) 是一个不会在 \(t\) 中出现的变量,称为通配符(wildcard)
类型归属(Type Ascription)
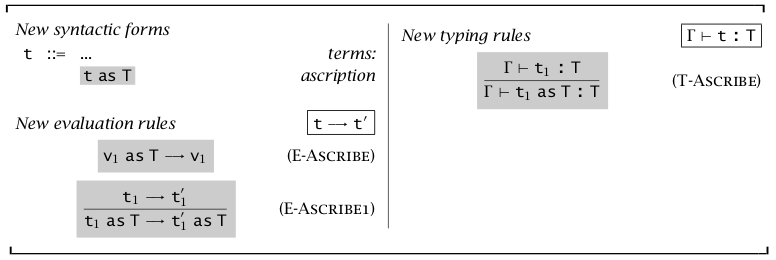
很多语言会提供一个运算符将一个表达式显式地归属到一种类型上,比如 Python 语言中的类型注释。
在这门语言中,使用 \(t\ as\ T\) 表示将表达式 \(t\) 归属到类型 \(T\) 上。从它的求值规则可以看出,这一特性对求值本身没有影响。
它的主要作用就是提高可读性,比如令 \(UU=Unit\to Unit\),则 \(\lambda f:Unit\to Unit.f\) 和其类型 \((Unit\to Unit)\to(Unit\to Unit)\) 可以简写为 \(\lambda f:UU.f\) 和 \(UU\to UU\)。
类型归属同样可以写作一种语法糖
Let 绑定(Let Binding)
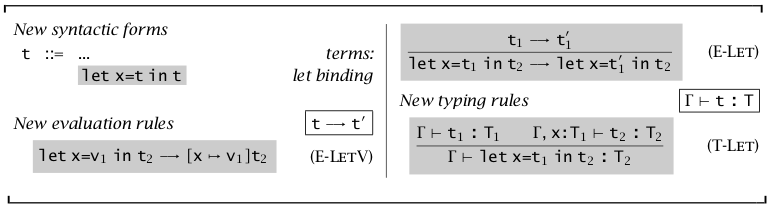
let 绑定可以方便变量的使用,它的作用是限制变量的作用域。\(\text{let }x=v_1\text{ in }t_2\to[x\mapsto v_1]t_2\) 表示在将 \(t_1\) 绑定在 \(x\) 的基础上对 \(t_2\) 进行求值,其中 \(t_1\) 会先进行求值。
事实上 \(\text{let }x=v_1\text{ in }t_2\overset{def}=(\lambda x:T_1.t_2)\ t_1\);但这种定义方式多了一个 \(T_1\) 类型,这一类型需要通过类型检查获得,所以 let 的类型规则可以由前述的规则得到。
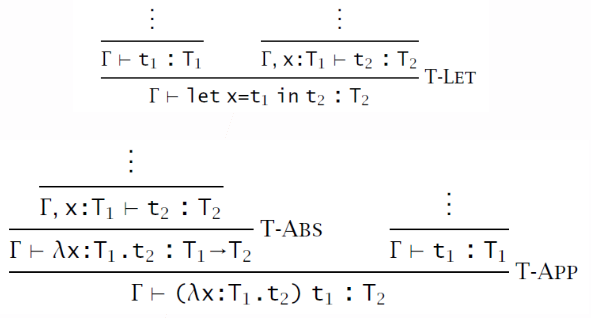
序偶(Pairs)
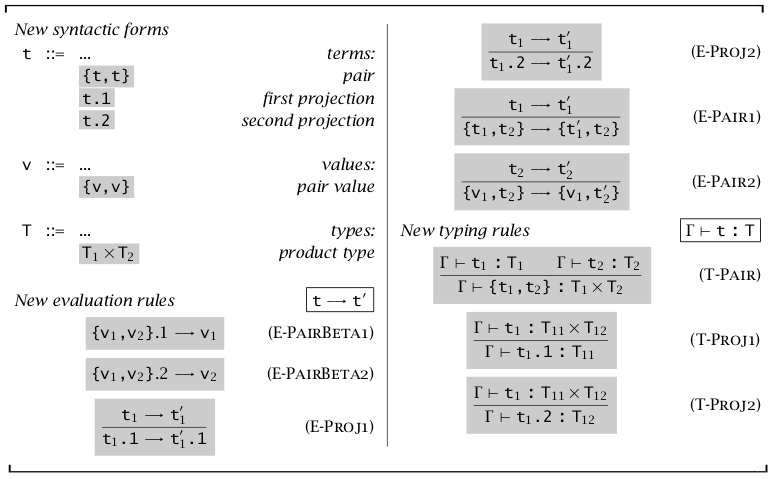
最简单的组合类型就是序偶了。虽然序偶的定义比较长,但它的思想却很简单,包括 \(\lbrace\rbrace/\times\) 进行组合和 \(.1/.2\) 进行选择。
元组(Tuples)
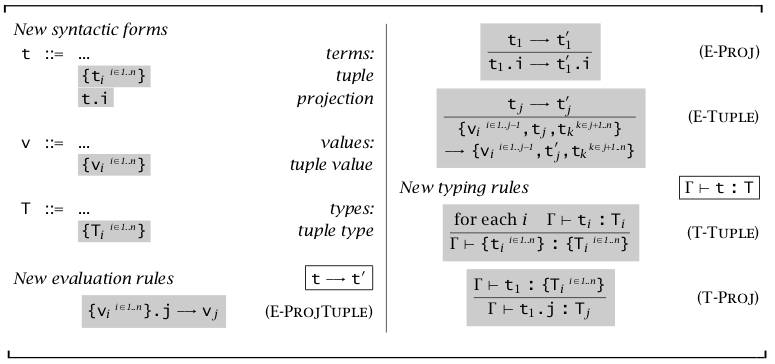
从序偶,也就是二元组,很容易引出元组。令 \(n=0\) 可以获得空元组。
记录(Records)
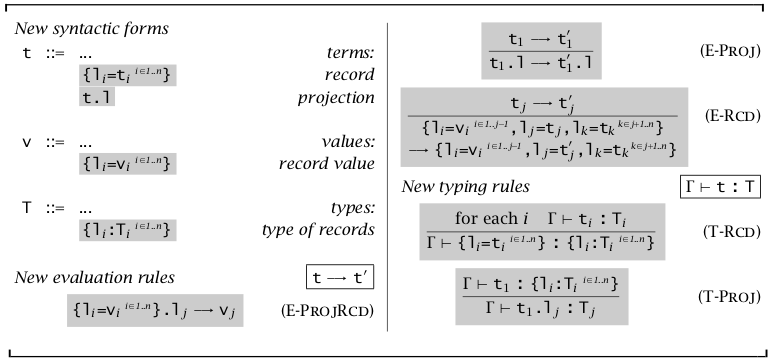
记录与元组的区别在于将索引从数字变为任意符号,类似 C 语言中的 struct。

使用记录并添加一个新的关键字 match 可以对 let 进行拓展。
和类型(Sums)
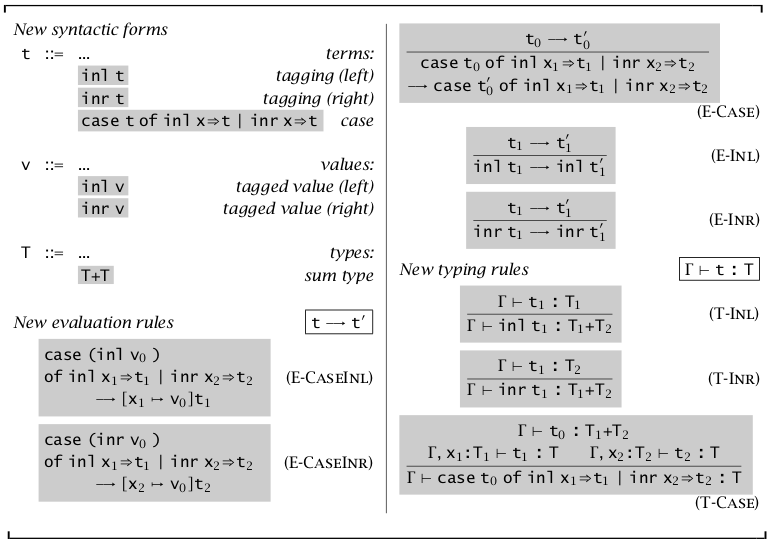
很多语言需要处理异构类型,类似 C 语言中的 union。
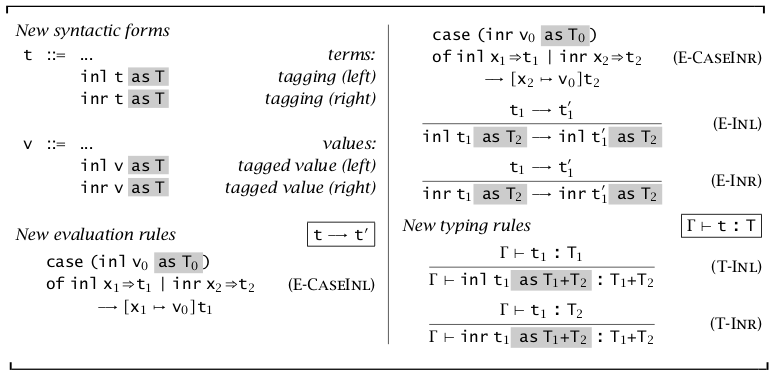
和类型的定义方法和序偶很像,通过 \(+\) 进行组合和 \(\text{case-of},\text{inl,inr}\) 进行提取。最值得注意的是 inl 和 inr(inject-left, inject-right),可以说是一种标记,只在 \(\text{case-of}\) 表达式中才有意义,表明选择左右表达式。
由于 inl 和 inr 可以将一个类型变为和类型,但和类型的另一个类型可以是任意的,这与类型的唯一性定理冲突。我们将使用前述的类型归属来解决,这要求写程序的人显式地写出类型。
变体类型(Variants)
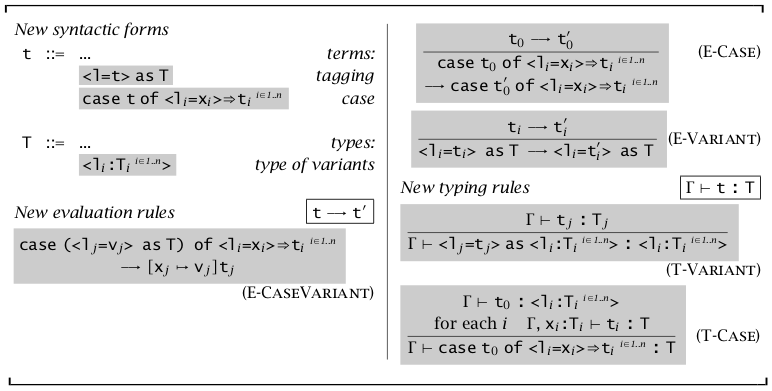
为和类型加上标签,就得到了变体类型。改变和类型中的写法,\(T_1+T_2\) 变为 \(\langle l_1:T_1,l_2:T_2\rangle\),\(\text{inl }t\text{ as }T_1+T_2\) 变为 \(\langle l_1=t\rangle\text{ as }\langle l_1:T_1,t_2:T_2\rangle\)
因此在 \(\text{case-of}\) 不使用 \(\text{inl,inr}\) 来选择左右,而是选择任意一个 \(l_n\)。
下举变体类型的多种应用。
在很多语言中有 Optional 类型,比如 C# T? 和 Rust Optional<T>,就可以表达为 \(\langle none:Unit,some:T\rangle\)。
也可以定义枚举,在枚举中,每个标签才是有意义的量,值都是 Unit 类型。
单标签变体类型(Single Field Variants)\(V=\langle l:T\rangle\) 可以用来避免一些类型上的错误。
一般递归(General Recursion)
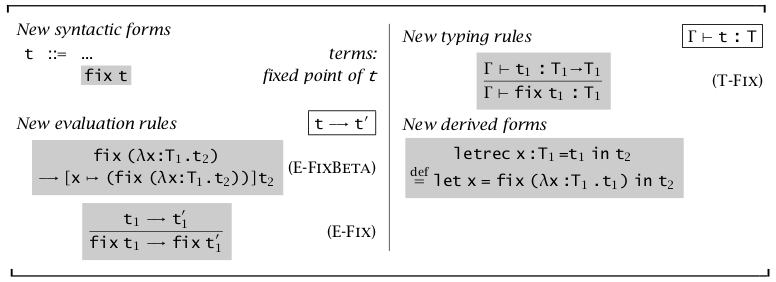
前述递归是通过 \(fix=\lambda f.(\lambda x.f\ (\lambda y.x\ x\ y))\ (\lambda x.f\ (\lambda y.x\ x\ y))\) 函数达成的,但 \(fix\) 无法用简单类型表示。
为了让 \(fix\) 融入类型系统,将 \(fix\) 作为一种额外成分单独定义它的规则。并引入 \(letrec\) 语法糖。
链表(Lists)
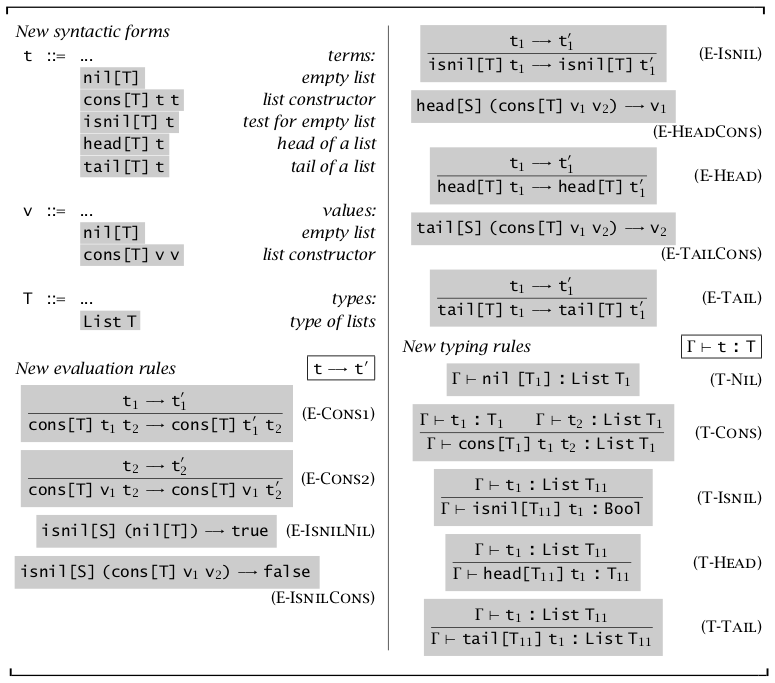
前文已经叙述了无类型系统中的链表,这里将链表作为单一类型的链表定义,为各种操作附加上类型 \(T\)。
引用(References)
引用是函数式语言中本不该出现的特性,但引用具有许多用处,包括输入输出、做出非本地跳跃、进程交互等我们需要的副作用(side effects)。现在就让我们来描述引用在语言中的准确定义。
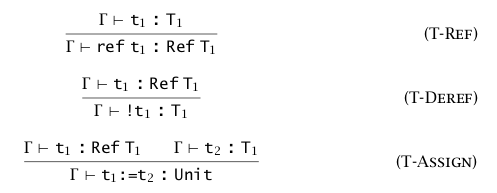
引用类型具有三种操作:
- 分配(Allocation) \(r=ref\ t_1\),\(r:Ref\ T_1\)
- 解引用(Dereferencing) \(!r\),类型为 \(T_1\)
- 赋值(Assignment) \(r:=t_1\),由于赋值运算的结果为 unit,可以使用顺序结构 \(r:=succ(!r);!r\),就是先自增后解引用。
引用和别名(References and Aliasing)
表达式 \(s=r\) 表示 \(s\) 和 \(r\) 是对同一单元的别名(aliases),对其中一个的赋值本质上是改变了那片单元,通过解引用可以查看这种改变。
引用给程序性质的推理带来了麻烦,比如引用的匿名管道性质
对 \(incc,decc\) 中任何一个的调用都会改变另一个的结果。
垃圾回收机制(garbage collection)也对引用安全性有影响,如果在空间的重分配中改变了引用的类型,但是别名的类型却没有相应改变就产生了类型安全问题。
求值
将引用看做存储位置的集合 \(\mathcal L\),\(:=\) 和 \(!\) 操作就是将值存到位置的函数和从位置取值的函数,这些函数返回值都是 unit,但具有副作用,需要新的规则体现这种副作用。使用 \(\mu\) 来表示存储的状态,将 \(t\to t'\) 改写为 \(t\mid\mu\to t'\mid\mu'\) 来体现存储状态的改变。并且在 values 和 terms 中添加 location 这一成分,表示存储位置。
本质上,我们定义的抽象机升级了,它不仅进行求值,也可以存储状态了。更详细的规则定义如下图。

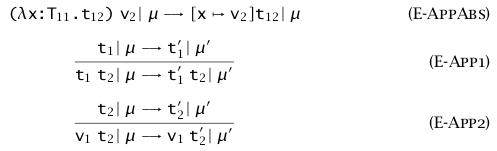

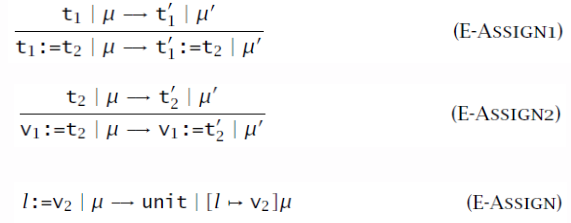
求类型
添加存储类型上下文 $$\Sigma$$ 记录所有引用的类型,但只记录类型而不记录值。

此时一个存储状态 \(\mu\) 将与 \(\Sigma\) 关联来保证安全性
小结
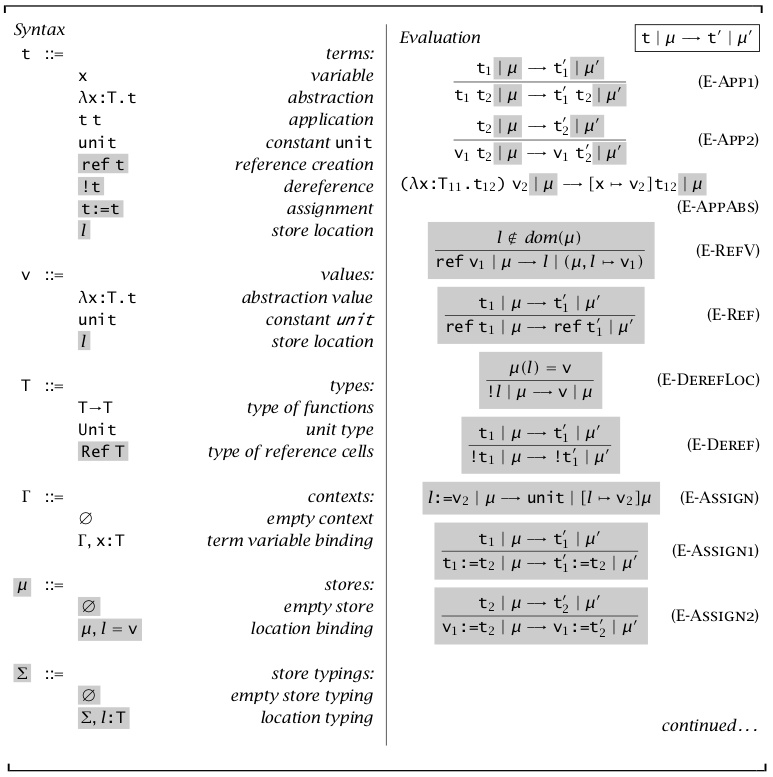
异常
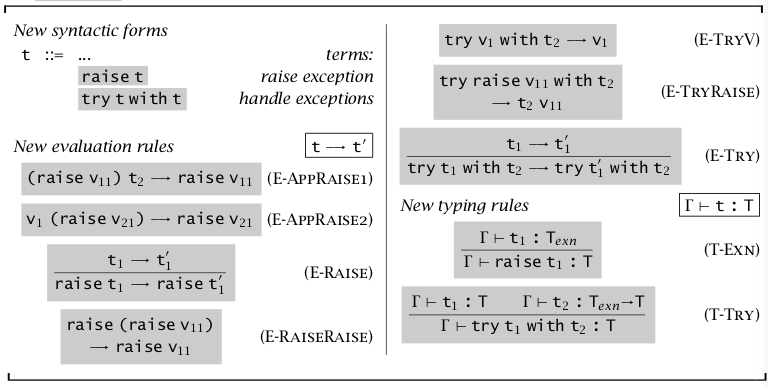
对异常的定义比较简单,包括异常的引发(raise)和捕获(try-with)。
\(\text{raise }t_1\) 表示引发一个异常,\(\text{try }t_1\text{ with }t_2\) 表示使用 \(t_2\) 处理 \(t_1\)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号