语义分割丨PSPNet源码解析「训练阶段」
引言
之前一段时间在参与语义分割的项目,最近有时间了,正好把这段时间的所学总结一下。
在代码上,语义分割的框架会比目标检测简单很多,但其中也涉及了很多细节。在这篇文章中,我以PSPNet为例,解读一下语义分割框架的代码。搞清楚一个框架后,再看别人的框架都是大同小异。
工程来自https://github.com/speedinghzl/pytorch-segmentation-toolbox
框架中一个非常重要的部分是evaluate.py,即测试阶段。但由于篇幅较长,我将另开一篇来阐述测试过程,本文关注训练过程。
整体框架
pytorch-segmentation-toolbox
|— dataset 数据集相关
|— list 存放数据集的list
|— datasets.py 数据集加载函数
|— libs 存放pytorch的op如bn
|— networks 存放网络代码
|— deeplabv3.py
|— pspnet.py
|— utils 其他函数
|— criterion.py 损失计算
|— encoding.py 显存均匀
|— loss.py OHEM难例挖掘
|— utils.py colormap转换
|— evaluate.py 网络测试
|— run_local.sh 训练脚本
|— train.py 网络训练
train.py
网络训练主函数,主要操作有:
- 传入训练参数;通常采用argparse库,支持脚本传入。
- 网络训练;包括定义网络、加载模型、前向反向传播、保存模型等。
- 将训练情况可视化;使用tensorboard绘制loss曲线。
import argparse
import torch
import torch.nn as nn
from torch.utils import data
import numpy as np
import pickle
import cv2
import torch.optim as optim
import scipy.misc
import torch.backends.cudnn as cudnn
import sys
import os
from tqdm import tqdm
import os.path as osp
from networks.pspnet import Res_Deeplab
from dataset.datasets import CSDataSet
import random
import timeit
import logging
from tensorboardX import SummaryWriter
from utils.utils import decode_labels, inv_preprocess, decode_predictions
from utils.criterion import CriterionDSN, CriterionOhemDSN
from utils.encoding import DataParallelModel, DataParallelCriterion
torch_ver = torch.__version__[:3]
if torch_ver == '0.3':
from torch.autograd import Variable
start = timeit.default_timer()
#由于使用了ImageNet的预训练权重,因此需要在数据预处理过程减去ImageNet上的均值。
IMG_MEAN = np.array((104.00698793,116.66876762,122.67891434), dtype=np.float32)
#这些超参数可在sh脚本中定义。
BATCH_SIZE = 8
DATA_DIRECTORY = 'cityscapes'
DATA_LIST_PATH = './dataset/list/cityscapes/train.lst'
IGNORE_LABEL = 255
INPUT_SIZE = '769,769'
LEARNING_RATE = 1e-2
MOMENTUM = 0.9
NUM_CLASSES = 19
NUM_STEPS = 40000
POWER = 0.9
RANDOM_SEED = 1234
RESTORE_FROM = './dataset/MS_DeepLab_resnet_pretrained_init.pth'
SAVE_NUM_IMAGES = 2
SAVE_PRED_EVERY = 10000
SNAPSHOT_DIR = './snapshots/'
WEIGHT_DECAY = 0.0005
def str2bool(v):
if v.lower() in ('yes', 'true', 't', 'y', '1'):
return True
elif v.lower() in ('no', 'false', 'f', 'n', '0'):
return False
else:
raise argparse.ArgumentTypeError('Boolean value expected.')
def get_arguments():
"""Parse all the arguments provided from the CLI.
Returns:
A list of parsed arguments.
"""
parser = argparse.ArgumentParser(description="DeepLab-ResNet Network")
parser.add_argument("--batch-size", type=int, default=BATCH_SIZE, #Batch Size
help="Number of images sent to the network in one step.")
parser.add_argument("--data-dir", type=str, default=DATA_DIRECTORY, #数据集地址
help="Path to the directory containing the PASCAL VOC dataset.")
parser.add_argument("--data-list", type=str, default=DATA_LIST_PATH, #数据集清单
help="Path to the file listing the images in the dataset.")
parser.add_argument("--ignore-label", type=int, default=IGNORE_LABEL, #忽略类别(未使用)
help="The index of the label to ignore during the training.")
parser.add_argument("--input-size", type=str, default=INPUT_SIZE, #输入尺寸
help="Comma-separated string with height and width of images.")
parser.add_argument("--is-training", action="store_true", #是否训练 若不传入为false
help="Whether to updates the running means and variances during the training.")
parser.add_argument("--learning-rate", type=float, default=LEARNING_RATE, #学习率
help="Base learning rate for training with polynomial decay.")
parser.add_argument("--momentum", type=float, default=MOMENTUM, #动量系数,用于优化参数
help="Momentum component of the optimiser.")
parser.add_argument("--not-restore-last", action="store_true", #是否存储最后一层(未使用)
help="Whether to not restore last (FC) layers.")
parser.add_argument("--num-classes", type=int, default=NUM_CLASSES, #类别数
help="Number of classes to predict (including background).")
parser.add_argument("--start-iters", type=int, default=0, #起始iter数
help="Number of classes to predict (including background).")
parser.add_argument("--num-steps", type=int, default=NUM_STEPS, #训练步数
help="Number of training steps.")
parser.add_argument("--power", type=float, default=POWER, #power系数,用于更新学习率
help="Decay parameter to compute the learning rate.")
parser.add_argument("--random-mirror", action="store_true", #数据增强 翻转
help="Whether to randomly mirror the inputs during the training.")
parser.add_argument("--random-scale", action="store_true", #数据增强 多尺度
help="Whether to randomly scale the inputs during the training.")
parser.add_argument("--random-seed", type=int, default=RANDOM_SEED, #随机种子
help="Random seed to have reproducible results.")
parser.add_argument("--restore-from", type=str, default=RESTORE_FROM, #模型断点续跑
help="Where restore model parameters from.")
parser.add_argument("--save-num-images", type=int, default=SAVE_NUM_IMAGES, #保存多少张图片(未使用)
help="How many images to save.")
parser.add_argument("--save-pred-every", type=int, default=SAVE_PRED_EVERY, #每多少次保存一次断点
help="Save summaries and checkpoint every often.")
parser.add_argument("--snapshot-dir", type=str, default=SNAPSHOT_DIR, #模型保存位置
help="Where to save snapshots of the model.")
parser.add_argument("--weight-decay", type=float, default=WEIGHT_DECAY, #权重衰减系数,用于正则化
help="Regularisation parameter for L2-loss.")
parser.add_argument("--gpu", type=str, default='None', #使用哪些GPU
help="choose gpu device.")
parser.add_argument("--recurrence", type=int, default=1, #循环次数(未使用)
help="choose the number of recurrence.")
parser.add_argument("--ft", type=bool, default=False, #微调模型(未使用)
help="fine-tune the model with large input size.")
parser.add_argument("--ohem", type=str2bool, default='False', #难例挖掘
help="use hard negative mining")
parser.add_argument("--ohem-thres", type=float, default=0.6,
help="choose the samples with correct probability underthe threshold.")
parser.add_argument("--ohem-keep", type=int, default=200000,
help="choose the samples with correct probability underthe threshold.")
return parser.parse_args()
args = get_arguments() #加载参数
#poly学习策略
def lr_poly(base_lr, iter, max_iter, power):
return base_lr*((1-float(iter)/max_iter)**(power))
#调整学习率
def adjust_learning_rate(optimizer, i_iter):
"""Sets the learning rate to the initial LR divided by 5 at 60th, 120th and 160th epochs"""
lr = lr_poly(args.learning_rate, i_iter, args.num_steps, args.power)
optimizer.param_groups[0]['lr'] = lr
return lr
#将BN设置为测试状态
def set_bn_eval(m):
classname = m.__class__.__name__
if classname.find('BatchNorm') != -1:
m.eval()
#设置BN动量
def set_bn_momentum(m):
classname = m.__class__.__name__
if classname.find('BatchNorm') != -1 or classname.find('InPlaceABN') != -1:
m.momentum = 0.0003
#网络训练主函数
def main():
"""Create the model and start the training."""
writer = SummaryWriter(args.snapshot_dir) #定义SummaryWriter对象来可视化训练情况。
if not args.gpu == 'None':
os.environ["CUDA_VISIBLE_DEVICES"]=args.gpu
h, w = map(int, args.input_size.split(',')) #769, 769
input_size = (h, w) #(769, 769)
cudnn.enabled = True
# Create network.
deeplab = Res_Deeplab(num_classes=args.num_classes) #定义网络
print(deeplab)
saved_state_dict = torch.load(args.restore_from) #加载模型 saved_state_dict['conv1.weight'] = {Tensor}
new_params = deeplab.state_dict().copy() #模态字典,建立层与参数的映射关系 new_params['conv1.weight']={Tensor}
for i in saved_state_dict: #剔除预训练模型中的全连接层部分
#Scale.layer5.conv2d_list.3.weight
i_parts = i.split('.') #['conv1', 'weight', '2']
# print i_parts
# if not i_parts[1]=='layer5':
if not i_parts[0]=='fc':
new_params['.'.join(i_parts[0:])] = saved_state_dict[i]
deeplab.load_state_dict(new_params) #剔除后,加载模态字典,完成模型载入
#deeplab.load_state_dict(torch.load(args.restore_from)) #若无需剔除
model = DataParallelModel(deeplab) #多GPU并行处理
model.train() #设置训练模式,在evaluate.py中是model.eval()
model.float()
# model.apply(set_bn_momentum)
model.cuda() #会将模型加载到0号gpu上并作为主GPU,也可自己指定
#model = model.cuda(device_ids[0])
if args.ohem: #是否采用难例挖掘
criterion = CriterionOhemDSN(thresh=args.ohem_thres, min_kept=args.ohem_keep)
else:
criterion = CriterionDSN() #CriterionCrossEntropy()
criterion = DataParallelCriterion(criterion) #多GPU机器均衡负载
criterion.cuda() #优化器也放在gpu上
cudnn.benchmark = True #可以提升一点训练速度,没有额外开销,一般都会加
if not os.path.exists(args.snapshot_dir):
os.makedirs(args.snapshot_dir)
#数据加载,该部分见datasets.py
trainloader = data.DataLoader(CSDataSet(args.data_dir, args.data_list, max_iters=args.num_steps*args.batch_size, crop_size=input_size,
scale=args.random_scale, mirror=args.random_mirror, mean=IMG_MEAN),
batch_size=args.batch_size, shuffle=True, num_workers=4, pin_memory=True)
#优化器
optimizer = optim.SGD([{'params': filter(lambda p: p.requires_grad, deeplab.parameters()), 'lr': args.learning_rate }],
lr=args.learning_rate, momentum=args.momentum,weight_decay=args.weight_decay)
optimizer.zero_grad() #清空上一步的残余更新参数值
interp = nn.Upsample(size=input_size, mode='bilinear', align_corners=True) #(未使用)
for i_iter, batch in enumerate(trainloader):
i_iter += args.start_iters
images, labels, _, _ = batch
images = images.cuda()
labels = labels.long().cuda()
if torch_ver == "0.3":
images = Variable(images)
labels = Variable(labels)
optimizer.zero_grad() #清空上一步的残余更新参数值
lr = adjust_learning_rate(optimizer, i_iter) #调整学习率
preds = model(images) #[x, x_dsn]
loss = criterion(preds, labels) #计算误差
loss.backward() #误差反向传播
optimizer.step() #更新参数值
#用之前定义的SummaryWriter对象在Tensorboard中绘制lr和loss曲线
if i_iter % 100 == 0:
writer.add_scalar('learning_rate', lr, i_iter)
writer.add_scalar('loss', loss.data.cpu().numpy(), i_iter)
#是否将训练中途的结果可视化
# if i_iter % 5000 == 0:
# images_inv = inv_preprocess(images, args.save_num_images, IMG_MEAN)
# labels_colors = decode_labels(labels, args.save_num_images, args.num_classes)
# if isinstance(preds, list):
# preds = preds[0]
# preds_colors = decode_predictions(preds, args.save_num_images, args.num_classes)
# for index, (img, lab) in enumerate(zip(images_inv, labels_colors)):
# writer.add_image('Images/'+str(index), img, i_iter)
# writer.add_image('Labels/'+str(index), lab, i_iter)
# writer.add_image('preds/'+str(index), preds_colors[index], i_iter)
print('iter = {} of {} completed, loss = {}'.format(i_iter, args.num_steps, loss.data.cpu().numpy()))
if i_iter >= args.num_steps-1: #保存最终模型
print('save model ...')
torch.save(deeplab.state_dict(),osp.join(args.snapshot_dir, 'CS_scenes_'+str(args.num_steps)+'.pth'))
break
if i_iter % args.save_pred_every == 0: #每隔一定步数保存模型
print('taking snapshot ...')
torch.save(deeplab.state_dict(),osp.join(args.snapshot_dir, 'CS_scenes_'+str(i_iter)+'.pth')) #仅保存学习到的参数
#torch.save(deeplab, PATH) #保存整个model及状态
end = timeit.default_timer()
print(end-start,'seconds')
if __name__ == '__main__':
main()
datasets.py
在pytorch中数据加载到模型的操作顺序如下:
- 创建一个Dataset对象,一般重载
__len__和__getitem__方法。__len__返回数据集大小,__getitem__支持索引,以便Dataset[i]获取第i个样本。 - 创建一个DataLoader对象,将Dataset作为参数传入。
- 循环这个DataLoader对象,将img、label加载到模型中进行训练。
这里展示一个简单的例子:
dataset = MyDataset()
dataloader = DataLoader(dataset)
num_epoches = 100
for epoch in range(num_epoches):
for img, label in dataloader:
我们还需在Dataset对象中定义数据预处理,这里采用:
-
0.7-1.4倍的随机尺度缩放
-
各通道减去ImageNet的均值
-
随机crop下769x769大小
-
镜像随机翻转
注意:为了让Image和Label对应,也要对Label作相应的预处理,具体过程详见代码。
import os
import os.path as osp
import numpy as np
import random
import collections
import torch
import torchvision
import cv2
from torch.utils import data
#Cityscapes数据集加载
#crop_size(769,769)、max_iters = num_steps * batch_size = 8 * 40000 = 320000
class CSDataSet(data.Dataset):
def __init__(self, root, list_path, max_iters=None, crop_size=(321, 321), mean=(128, 128, 128), scale=True, mirror=True, ignore_label=255):
self.root = root #数据集地址
self.list_path = list_path #数据集列表
self.crop_h, self.crop_w = crop_size #剪裁尺寸
self.scale = scale #尺度
self.ignore_label = ignore_label #忽略类别
self.mean = mean #数据集各通道平均值
self.is_mirror = mirror #是否镜像
# self.mean_bgr = np.array([104.00698793, 116.66876762, 122.67891434])
self.img_ids = [i_id.strip().split() for i_id in open(list_path)] #列表 存放每张图像及其标签在数据集中的地址
if not max_iters==None: #训练时根据max_iter数将列表翻倍 if max_iter=320000、len(trainset)=2975
#每一个iter训练一张图,要计算max_iter要训练多少轮trainset
self.img_ids = self.img_ids * int(np.ceil(float(max_iters) / len(self.img_ids))) # 2975 * (32000/2975) = 321300
self.files = [] #用来放数据的列表
# for split in ["train", "trainval", "val"]:
for item in self.img_ids: #遍历每一张训练样本
image_path, label_path = item #图像、标签地址
name = osp.splitext(osp.basename(label_path))[0]
img_file = osp.join(self.root, image_path)
label_file = osp.join(self.root, label_path)
self.files.append({ #列表的每一项是一个字典
"img": img_file,
"label": label_file,
"name": name #aachen_000000_000019_leftImg8bit.png
})
#19类与官方给定类别的转换
self.id_to_trainid = {-1: ignore_label, 0: ignore_label, 1: ignore_label, 2: ignore_label,
3: ignore_label, 4: ignore_label, 5: ignore_label, 6: ignore_label,
7: 0, 8: 1, 9: ignore_label, 10: ignore_label, 11: 2, 12: 3, 13: 4,
14: ignore_label, 15: ignore_label, 16: ignore_label, 17: 5,
18: ignore_label, 19: 6, 20: 7, 21: 8, 22: 9, 23: 10, 24: 11, 25: 12, 26: 13, 27: 14,
28: 15, 29: ignore_label, 30: ignore_label, 31: 16, 32: 17, 33: 18}
print('{} images are loaded!'.format(len(self.img_ids)))
def __len__(self): #数据集长度
return len(self.files) #321300
#生成不同尺度下的样本和标签
def generate_scale_label(self, image, label):
f_scale = 0.7 + random.randint(0, 14) / 10.0 # 0.7 + (0~1.4)
image = cv2.resize(image, None, fx=f_scale, fy=f_scale, interpolation = cv2.INTER_LINEAR)
label = cv2.resize(label, None, fx=f_scale, fy=f_scale, interpolation = cv2.INTER_NEAREST)
return image, label
#实现类别数和trainId的相互转换:如第19类对应trainId 33
def id2trainId(self, label, reverse=False):
label_copy = label.copy()
if reverse: #trainId2id
for v, k in self.id_to_trainid.items():
label_copy[label == k] = v
else: #id2trainId
for k, v in self.id_to_trainid.items():
label_copy[label == k] = v
return label_copy
#返回一张样本
def __getitem__(self, index):
datafiles = self.files[index]
image = cv2.imread(datafiles["img"], cv2.IMREAD_COLOR) #shape(1024,2048,3)
label = cv2.imread(datafiles["label"], cv2.IMREAD_GRAYSCALE) #shape(1024,2048)
label = self.id2trainId(label) #label图像(-1~33) 转化为数组(0~19)
size = image.shape #[1024,2048,3]
name = datafiles["name"]
if self.scale: #若采用多尺度
image, label = self.generate_scale_label(image, label)
image = np.asarray(image, np.float32)
image -= self.mean #减去均值
img_h, img_w = label.shape #1024, 2048
pad_h = max(self.crop_h - img_h, 0) #max(769-1024, 0)
pad_w = max(self.crop_w - img_w, 0) #max(769-2048, 0)
if pad_h > 0 or pad_w > 0: #若尺度缩放后的尺寸比crop_size尺寸小,则对边界进行填充
img_pad = cv2.copyMakeBorder(image, 0, pad_h, 0,
pad_w, cv2.BORDER_CONSTANT,
value=(0.0, 0.0, 0.0))
label_pad = cv2.copyMakeBorder(label, 0, pad_h, 0,
pad_w, cv2.BORDER_CONSTANT,
value=(self.ignore_label,))
else:
img_pad, label_pad = image, label
img_h, img_w = label_pad.shape #1024、2048
h_off = random.randint(0, img_h - self.crop_h) #生成随机数如100
w_off = random.randint(0, img_w - self.crop_w) #20
# roi = cv2.Rect(w_off, h_off, self.crop_w, self.crop_h);
image = np.asarray(img_pad[h_off : h_off+self.crop_h, w_off : w_off+self.crop_w], np.float32) #任意扣下([100:100+769, 20:20+769])
label = np.asarray(label_pad[h_off : h_off+self.crop_h, w_off : w_off+self.crop_w], np.float32) #([100:100+769, 20:20+769])
#image = image[:, :, ::-1] # change to BGR
image = image.transpose((2, 0, 1)) #shape(3, 769, 769)
if self.is_mirror: #镜像随机翻转
flip = np.random.choice(2) * 2 - 1 #flip = 1 or -1
image = image[:, :, ::flip]
label = label[:, ::flip]
return image.copy(), label.copy(), np.array(size), name #image.shape(3, 769, 769)、label.shape(769, 769)
上面定义了一个Dataset对象CSDataSet,之后我们在train.py中定义DataLoader对象trainloader,并将CSDataSet作为参数传入。
trainloader = data.DataLoader(CSDataSet(args.data_dir, args.data_list, max_iters=args.num_steps*args.batch_size, crop_size=input_size,
scale=args.random_scale, mirror=args.random_mirror, mean=IMG_MEAN),
batch_size=args.batch_size, shuffle=True, num_workers=4, pin_memory=True)
为更清楚这些参数的含义,可以参考一下DataLoader类的定义。
class DataLoader(object):
r"""
Data loader. Combines a dataset and a sampler, and provides
single- or multi-process iterators over the dataset.
Arguments:
dataset(Dataset): 传入的数据集
batch_size(int, optional): 每个batch有多少个样本
shuffle(bool, optional): 在每个epoch开始的时候,对数据进行重新排序
sampler(Sampler, optional): 自定义从数据集中取样本的策略,如果指定这个参数,那么shuffle必须为False
batch_sampler(Sampler, optional): 与sampler类似,但是一次只返回一个batch的indices(索引),需要注意的是,一旦指定了这个参数,那么batch_size,shuffle,sampler,drop_last就不能再制定了(互斥——Mutually exclusive)
num_workers (int, optional): 这个参数决定了有几个进程来处理data loading。0意味着所有的数据都会被load进主进程。(默认为0)
collate_fn (callable, optional): 将一个list的sample组成一个mini-batch的函数
pin_memory (bool, optional): 如果设置为True,那么data loader将会在返回它们之前,将tensors拷贝到CUDA中的固定内存(CUDA pinned memory)中.
drop_last (bool, optional): 如果设置为True:这个是对最后的未完成的batch来说的,比如你的batch_size设置为64,而一个epoch只有100个样本,那么训练的时候后面的36个就被扔掉了…
如果为False(默认),那么会继续正常执行,只是最后的batch_size会小一点。
timeout(numeric, optional): 如果是正数,表明等待从worker进程中收集一个batch等待的时间,若超出设定的时间还没有收集到,那就不收集这个内容了。这个numeric应总是大于等于0。默认为0
worker_init_fn (callable, optional): 每个worker初始化函数 If not None, this will be called on each
worker subprocess with the worker id (an int in [0, num_workers - 1]) as
input, after seeding and before data loading. (default: None)
.. note:: By default, each worker will have its PyTorch seed set to
``base_seed + worker_id``, where ``base_seed`` is a long generated
by main process using its RNG. However, seeds for other libraies
may be duplicated upon initializing workers (w.g., NumPy), causing
each worker to return identical random numbers. (See
:ref:`dataloader-workers-random-seed` section in FAQ.) You may
use ``torch.initial_seed()`` to access the PyTorch seed for each
worker in :attr:`worker_init_fn`, and use it to set other seeds
before data loading.
.. warning:: If ``spawn`` start method is used, :attr:`worker_init_fn` cannot be an
unpicklable object, e.g., a lambda function.
"""
__initialized = False
def __init__(self, dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None,
num_workers=0, collate_fn=default_collate, pin_memory=False, drop_last=False,
timeout=0, worker_init_fn=None):
self.dataset = dataset
self.batch_size = batch_size
self.num_workers = num_workers
self.collate_fn = collate_fn
self.pin_memory = pin_memory
self.drop_last = drop_last
self.timeout = timeout
self.worker_init_fn = worker_init_fn
if timeout < 0:
raise ValueError('timeout option should be non-negative')
if batch_sampler is not None:
if batch_size > 1 or shuffle or sampler is not None or drop_last:
raise ValueError('batch_sampler option is mutually exclusive '
'with batch_size, shuffle, sampler, and '
'drop_last')
self.batch_size = None
self.drop_last = None
if sampler is not None and shuffle:
raise ValueError('sampler option is mutually exclusive with '
'shuffle')
if self.num_workers < 0:
raise ValueError('num_workers option cannot be negative; '
'use num_workers=0 to disable multiprocessing.')
if batch_sampler is None:
if sampler is None:
if shuffle:
sampler = RandomSampler(dataset) //将list打乱
else:
sampler = SequentialSampler(dataset)
batch_sampler = BatchSampler(sampler, batch_size, drop_last)
self.sampler = sampler
self.batch_sampler = batch_sampler
self.__initialized = True
def __setattr__(self, attr, val):
if self.__initialized and attr in ('batch_size', 'sampler', 'drop_last'):
raise ValueError('{} attribute should not be set after {} is '
'initialized'.format(attr, self.__class__.__name__))
super(DataLoader, self).__setattr__(attr, val)
def __iter__(self):
return _DataLoaderIter(self)
def __len__(self):
return len(self.batch_sampler)
pspnet.py
在pytorch中自定义网络,集成nn.Module类并重载__init__(self)和forward,分别定义网络组成和前向传播,这里有一个简单的例子。
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
下面先看一下PSPNet的论文介绍,网络结构非常简单,在ResNet之后接一个PPM模块。
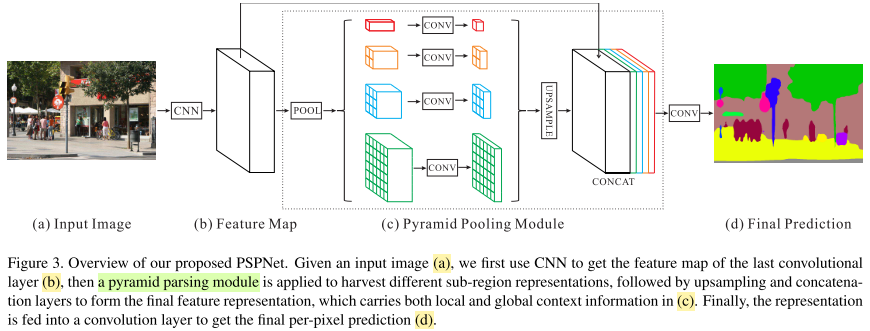
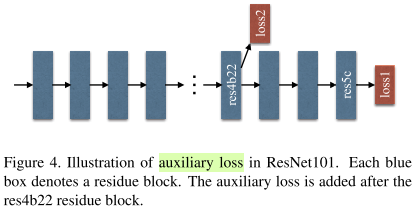
此外PSPNet还采用了辅助损失分支。
import torch.nn as nn
from torch.nn import functional as F
import math
import torch.utils.model_zoo as model_zoo
import torch
import numpy as np
from torch.autograd import Variable
affine_par = True
import functools
import sys, os
from libs import InPlaceABN, InPlaceABNSync
BatchNorm2d = functools.partial(InPlaceABNSync, activation='none')
def conv3x3(in_planes, out_planes, stride=1):
"3x3 convolution with padding"
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
#ResNet的Bottleneck
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, dilation=1, downsample=None, fist_dilation=1, multi_grid=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=dilation*multi_grid, dilation=dilation*multi_grid, bias=False)
self.bn2 = BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=False)
self.relu_inplace = nn.ReLU(inplace=True)
self.downsample = downsample
self.dilation = dilation
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out = out + residual
out = self.relu_inplace(out)
return out
#PPM模块
class PSPModule(nn.Module):
"""
Reference:
Zhao, Hengshuang, et al. *"Pyramid scene parsing network."*
"""
def __init__(self, features, out_features=512, sizes=(1, 2, 3, 6)):
super(PSPModule, self).__init__()
self.stages = []
self.stages = nn.ModuleList([self._make_stage(features, out_features, size) for size in sizes])
self.bottleneck = nn.Sequential(
nn.Conv2d(features+len(sizes)*out_features, out_features, kernel_size=3, padding=1, dilation=1, bias=False),
InPlaceABNSync(out_features),
nn.Dropout2d(0.1)
)
def _make_stage(self, features, out_features, size):
prior = nn.AdaptiveAvgPool2d(output_size=(size, size))
conv = nn.Conv2d(features, out_features, kernel_size=1, bias=False)
bn = InPlaceABNSync(out_features)
return nn.Sequential(prior, conv, bn)
def forward(self, feats):
h, w = feats.size(2), feats.size(3)
priors = [F.upsample(input=stage(feats), size=(h, w), mode='bilinear', align_corners=True) for stage in self.stages] + [feats]
bottle = self.bottleneck(torch.cat(priors, 1))
return bottle
#PSPNet网络整体
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes):
self.inplanes = 128
super(ResNet, self).__init__()
self.conv1 = conv3x3(3, 64, stride=2)
self.bn1 = BatchNorm2d(64)
self.relu1 = nn.ReLU(inplace=False)
self.conv2 = conv3x3(64, 64)
self.bn2 = BatchNorm2d(64)
self.relu2 = nn.ReLU(inplace=False)
self.conv3 = conv3x3(64, 128)
self.bn3 = BatchNorm2d(128)
self.relu3 = nn.ReLU(inplace=False)
#
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.relu = nn.ReLU(inplace=False)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True) # change
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=1, dilation=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=1, dilation=4, multi_grid=(1,1,1))
self.head = nn.Sequential(PSPModule(2048, 512),
nn.Conv2d(512, num_classes, kernel_size=1, stride=1, padding=0, bias=True))
#辅助损失
self.dsn = nn.Sequential(
nn.Conv2d(1024, 512, kernel_size=3, stride=1, padding=1),
InPlaceABNSync(512),
nn.Dropout2d(0.1),
nn.Conv2d(512, num_classes, kernel_size=1, stride=1, padding=0, bias=True)
)
def _make_layer(self, block, planes, blocks, stride=1, dilation=1, multi_grid=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
BatchNorm2d(planes * block.expansion,affine = affine_par))
layers = []
generate_multi_grid = lambda index, grids: grids[index%len(grids)] if isinstance(grids, tuple) else 1
layers.append(block(self.inplanes, planes, stride,dilation=dilation, downsample=downsample, multi_grid=generate_multi_grid(0, multi_grid)))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, dilation=dilation, multi_grid=generate_multi_grid(i, multi_grid)))
return nn.Sequential(*layers)
def forward(self, x): #(1,3,769,769)
x = self.relu1(self.bn1(self.conv1(x))) #(1,64,385,385)
x = self.relu2(self.bn2(self.conv2(x))) #(1,64,385,385)
x = self.relu3(self.bn3(self.conv3(x))) #(1,128,385,385)
x = self.maxpool(x) #(1,128,193,193)
x = self.layer1(x) #(1,256,97,97)
x = self.layer2(x) #(1,512,97,97)
x = self.layer3(x) #(1,1024,97,97)
x_dsn = self.dsn(x) #(1,19,97,97)
x = self.layer4(x) #(1,2048,97,97)
x = self.head(x) #(1,19,769,769)
return [x, x_dsn]
def Res_Deeplab(num_classes=21):
model = ResNet(Bottleneck,[3, 4, 23, 3], num_classes)
return model
PSPNet输入1x3x769x769,1为BS、3为RGB通道、769为cropsize。并有两个输出1x19x97x97和1x19x769x769,19为类别数,预测了每个位置属于各类的概率。(注意这里尚未softmax,概率之和不为1)。
criterion.py
语义分割的损失函数主要是交叉熵。由于采用了辅助损失,所以Loss应该包含两部分。
\(total\_loss=\alpha \cdot loss1+\beta \cdot loss2\)
此外,这里还定义了OHEM的损失计算,具体实现请看loss.py
import torch.nn as nn
import math
import torch.utils.model_zoo as model_zoo
import torch
import numpy as np
from torch.nn import functional as F
from torch.autograd import Variable
from .loss import OhemCrossEntropy2d
import scipy.ndimage as nd
class CriterionDSN(nn.Module):
'''
DSN : We need to consider two supervision for the model.
我们需要考虑两种损失
'''
def __init__(self, ignore_index=255, use_weight=True, reduce=True):
super(CriterionDSN, self).__init__()
self.ignore_index = ignore_index
#交叉熵计算Loss,忽略了255类,并且对Loss取了平均
self.criterion = torch.nn.CrossEntropyLoss(ignore_index=ignore_index, reduce=reduce)
if not reduce:
print("disabled the reduce.")
#criterion(preds, labels)
def forward(self, preds, target):
h, w = target.size(1), target.size(2) #769, 769
scale_pred = F.upsample(input=preds[0], size=(h, w), mode='bilinear', align_corners=True)
loss1 = self.criterion(scale_pred, target)
scale_pred = F.upsample(input=preds[1], size=(h, w), mode='bilinear', align_corners=True)
loss2 = self.criterion(scale_pred, target)
return loss1 + loss2*0.4
#采用难例挖掘
class CriterionOhemDSN(nn.Module):
'''
DSN : We need to consider two supervision for the model.
'''
def __init__(self, ignore_index=255, thresh=0.7, min_kept=100000, use_weight=True, reduce=True):
super(CriterionOhemDSN, self).__init__()
self.ignore_index = ignore_index
self.criterion1 = OhemCrossEntropy2d(ignore_index, thresh, min_kept) #采用了新的计算方式
self.criterion2 = torch.nn.CrossEntropyLoss(ignore_index=ignore_index, reduce=reduce)
def forward(self, preds, target):
h, w = target.size(1), target.size(2) #769, 769
scale_pred = F.upsample(input=preds[0], size=(h, w), mode='bilinear', align_corners=True)
loss1 = self.criterion1(scale_pred, target)
scale_pred = F.upsample(input=preds[1], size=(h, w), mode='bilinear', align_corners=True)
loss2 = self.criterion2(scale_pred, target)
return loss1 + loss2*0.4
loss.py
OHEM目的是筛选出困难样本来训练模型,从而提升性能,其有两个超参数:\(\theta\)和\(K\)。
困难样本被定义为预测概率小于$\theta \(的像素,并且每个*minibatch*至少保证\)K$个困难样本。

具体实现是将pspnet的输出经过softmax,然后进行两次筛选。第一次筛选基于label的有效区域(非255),predict上255对应的区域将不纳入loss的计算。经第一次筛选,将label中对应predict概率大于0.7的区域也置为255。最后只有剩余区域将参与loss的计算。
import torch
import torch.nn.functional as F
import torch.nn as nn
from torch.autograd import Variable
import numpy as np
import scipy.ndimage as nd
class OhemCrossEntropy2d(nn.Module):
def __init__(self, ignore_label=255, thresh=0.7, min_kept=100000, factor=8):
super(OhemCrossEntropy2d, self).__init__()
self.ignore_label = ignore_label #忽略类别255
self.thresh = float(thresh) #阈值0.7
# self.min_kept_ratio = float(min_kept_ratio)
self.min_kept = int(min_kept) #
self.factor = factor
self.criterion = torch.nn.CrossEntropyLoss(ignore_index=ignore_label)
#寻找阈值
#np_predict.shape(1, 19, 769, 769)、np_target.shape(1, 769, 769)
"""
阈值的选取主要基于min_kept,用第min_kept个的概率来确定。
且返回的阈值只能 ≥ thresh。
"""
def find_threshold(self, np_predict, np_target):
# downsample 1/8
factor = self.factor #8
predict = nd.zoom(np_predict, (1.0, 1.0, 1.0/factor, 1.0/factor), order=1) #双线性插值 shape(1, 19, 96, 96)
target = nd.zoom(np_target, (1.0, 1.0/factor, 1.0/factor), order=0) #最近临插值 shape(1, 96, 96)
n, c, h, w = predict.shape #1, 19, 96, 96
min_kept = self.min_kept // (factor*factor) #int(self.min_kept_ratio * n * h * w) #100000/64 = 1562
input_label = target.ravel().astype(np.int32) #将多维数组转化为一维 shape(9216, )
input_prob = np.rollaxis(predict, 1).reshape((c, -1)) #轴1滚动到轴0、shape(19, 9216)
valid_flag = input_label != self.ignore_label #label中有效位置(9216, )
valid_inds = np.where(valid_flag)[0] #(9013, )
label = input_label[valid_flag] #有效label(9013, )
num_valid = valid_flag.sum() #9013
if min_kept >= num_valid: #1562 >= 9013
threshold = 1.0
elif num_valid > 0: #9013 > 0
prob = input_prob[:,valid_flag] #(19, 9013) #找出有效区域对应的prob
pred = prob[label, np.arange(len(label), dtype=np.int32)] #??? shape(9013, )
threshold = self.thresh #0.7
if min_kept > 0: #1562>0
k_th = min(len(pred), min_kept)-1 #min(9013, 1562)-1 = 1561
new_array = np.partition(pred, k_th) #排序并分成两个区,小于第1561个及大于第1561个
new_threshold = new_array[k_th] #第1561对应的pred 0.03323581
if new_threshold > self.thresh: #返回的阈值只能≥0.7
threshold = new_threshold
return threshold
#生成新的labels
#predict.shape(1, 19, 97, 97)、target.shape(1, 97, 97)
"""
主要思路
1先通过find_threshold找到一个合适的阈值如0.7
2一次筛选出不为255的区域
3再从中二次筛选找出对应预测值小于0.7的区域
4重新生成一个label,label把预测值大于0.7和原本为255的位置 都置为255
"""
def generate_new_target(self, predict, target):
np_predict = predict.data.cpu().numpy() #shape(1, 19, 769, 769)
np_target = target.data.cpu().numpy() #shape(1, 769, 769)
n, c, h, w = np_predict.shape #1, 19, 769, 769
threshold = self.find_threshold(np_predict, np_target) #寻找阈值0.7
input_label = np_target.ravel().astype(np.int32) #shape(591361, )
input_prob = np.rollaxis(np_predict, 1).reshape((c, -1)) #(19, 591361)
valid_flag = input_label != self.ignore_label #label中有效位置(591361, )
valid_inds = np.where(valid_flag)[0] #(579029, )
label = input_label[valid_flag] #一次筛选:不为255的label(579029, )
num_valid = valid_flag.sum() #579029
if num_valid > 0:
prob = input_prob[:,valid_flag] #(19, 579029)
pred = prob[label, np.arange(len(label), dtype=np.int32)] #不明白这一步的操作??? (579029, )
kept_flag = pred <= threshold #二次筛选:在255中找出pred≤0.7的位置
valid_inds = valid_inds[kept_flag] #shape(579029, )
print('Labels: {} {}'.format(len(valid_inds), threshold))
label = input_label[valid_inds].copy() #从原label上扣下来shape(579029, )
input_label.fill(self.ignore_label) #shape(591361, )每个值都为255
input_label[valid_inds] = label #把二次筛选后有效区域的对应位置为label,其余为255
new_target = torch.from_numpy(input_label.reshape(target.size())).long().cuda(target.get_device()) #shape(1, 769, 769)
return new_target #shape(1, 769, 769)
def forward(self, predict, target, weight=None):
"""
Args:
predict:(n, c, h, w) (1, 19, 97, 97)
target:(n, h, w) (1, 97, 97)
weight (Tensor, optional): a manual rescaling weight given to each class.
If given, has to be a Tensor of size "nclasses"
"""
assert not target.requires_grad
input_prob = F.softmax(predict, 1) #在channel上进行一次softmax,得到概率
target = self.generate_new_target(input_prob, target) #生成新labels
return self.criterion(predict, target)
参考
Zhao H, Shi J, Qi X, et al. Pyramid scene parsing network[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 2881-2890.
Yuan Y, Wang J. Ocnet: Object context network for scene parsing[J]. arXiv preprint arXiv:1809.00916, 2018.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号