如何使用 SQL 视图和子查询进行复杂查询
前几篇我们一起学习了 SQL 如何对表进行创建、更新和删除操作、SQL SELECT WHERE 语句如何指定一个或多个查询条件 和 SQL 如何插入、删除和更新数据 等数据库的基本操作方法。
从本文开始,我们将会在这些基本方法的基础上,学习一些实际应用中的方法。
本文将以此前学过的 SELECT 语句,以及嵌套在 SELECT 语句中的视图和子查询等技术为中心进行学习。由于视图和子查询可以像表一样进行使用,因此如果能恰当地使用这些技术,就可以写出更加灵活的 SQL 了。
一、视图
本节重点
从 SQL 的角度来看,视图和表是相同的,两者的区别在于表中保存的是实际的数据,而视图中保存的是
SELECT语句(视图本身并不存储数据)。使用视图,可以轻松完成跨多表查询数据等复杂操作。
可以将常用的
SELECT语句做成视图来使用。创建视图需要使用
CREATE VIEW语句。视图包含“不能使用
ORDER BY”和“可对其进行有限制的更新”两项限制。删除视图需要使用
DROP VIEW语句。
1.1 视图和表
我们首先要学习的是一个新的工具——视图。
视图究竟是什么呢?如果用一句话概述的话,就是“从 SQL 的角度来看视图就是一张表”。
实际上,在 SQL 语句中并不需要区分哪些是表,哪些是视图,只需要知道在更新时它们之间存在一些不同就可以了,这一点之后会为大家进行介绍。
至少在编写 SELECT 语句时并不需要特别在意表和视图有什么不同。
那么视图和表到底有什么不同呢?区别只有一个,那就是“是否保存了实际的数据”。
通常,我们在创建表时,会通过 INSERT 语句将数据保存到数据库之中,而数据库中的数据实际上会被保存到计算机的存储设备(通常是硬盘)中。
因此,我们通过 SELECT 语句查询数据时,实际上就是从存储设备(硬盘)中读取数据,进行各种计算之后,再将结果返回给用户这样一个过程。
但是使用视图时并不会将数据保存到存储设备之中,而且也不会将数据保存到其他任何地方。
实际上视图保存的是 SELECT 语句(图 1)。我们从视图中读取数据时,视图会在内部执行该 SELECT 语句并创建出一张临时表。
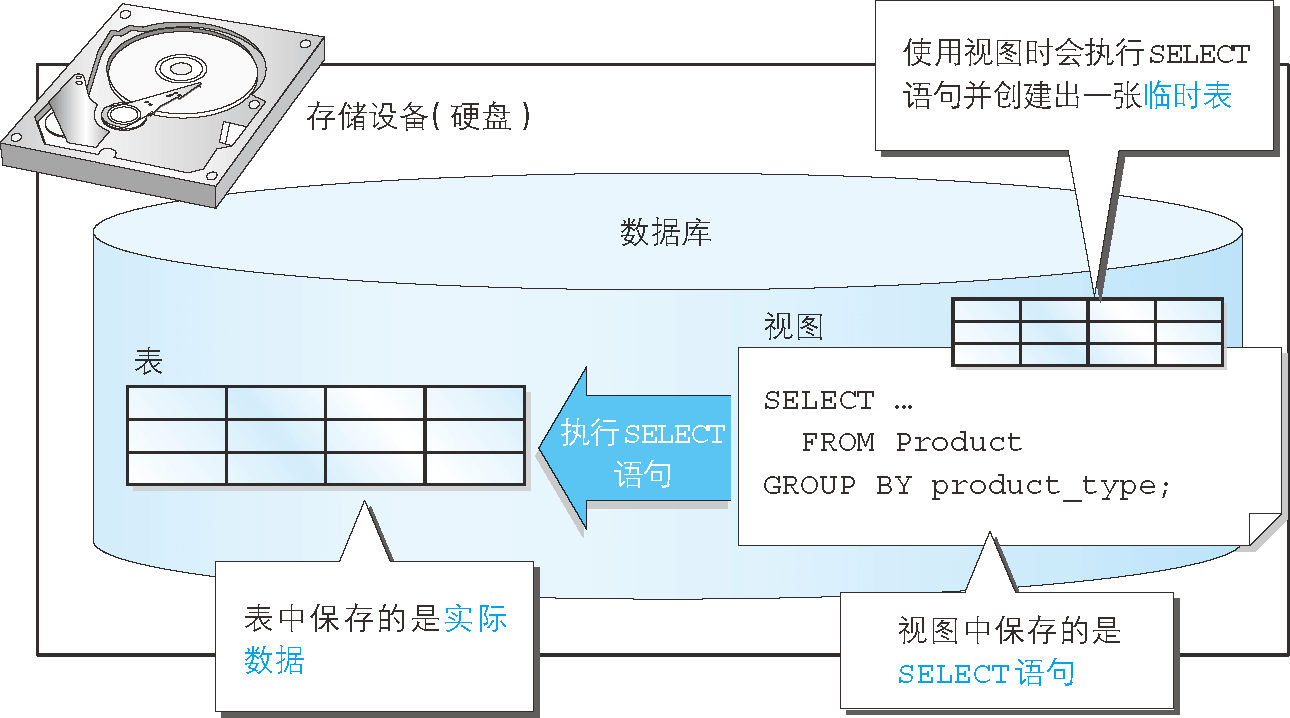
图 1 视图和表
-
视图的优点
视图的优点大体有两点。
第一点是由于视图无需保存数据,因此可以节省存储设备的容量。
例如,我们在 SQL 如何插入、删除和更新数据 中创建了用来汇总商品种类(
product_type)的表。由于该表中的数据最终都会保存到存储设备之中,因此会占用存储设备的数据空间。
但是,如果把同样的数据作为视图保存起来的话,就只需要代码清单 1 那样的
SELECT语句就可以了,这样就节省了存储设备的数据空间。代码清单 1 通过视图等 SELECT 语句保存数据
SELECT product_type, SUM(sale_price), SUM(purchase_price) FROM Product GROUP BY product_type;由于本示例中表的数据量充其量只有几行,所以使用视图并不会大幅缩小数据的大小。但是在实际的业务中数据量往往非常大,这时使用视图所节省的容量就会非常可观了。
法则 1
表中存储的是实际数据,而视图中保存的是从表中取出数据所使用的
SELECT语句。第二个优点就是可以将频繁使用的
SELECT语句保存成视图,这样就不用每次都重新书写了。创建好视图之后,只需在
SELECT语句中进行调用,就可以方便地得到想要的结果了。特别是在进行汇总以及复杂的查询条件导致SELECT语句非常庞大时,使用视图可以大大提高效率。而且,视图中的数据会随着原表的变化自动更新。视图归根到底就是
SELECT语句,所谓“参照视图”也就是“执行SELECT语句”的意思,因此可以保证数据的最新状态。这也是将数据保存在表中所不具备的优势 [1]。
法则 2
应该将经常使用的
SELECT语句做成视图。
1.2 创建视图的方法
创建视图需要使用 CREATE VIEW 语句,其语法如下所示。
语法 1 创建视图的 CREATE VIEW 语句
CREATE VIEW 视图名称(<视图列名1>, <视图列名2>, ……)
AS
<SELECT语句>
SELECT 语句需要书写在 AS 关键字之后。
SELECT 语句中列的排列顺序和视图中列的排列顺序相同,SELECT 语句中的第 1 列就是视图中的第 1 列,SELECT 语句中的第 2 列就是视图中的第 2 列,以此类推。
视图的列名在视图名称之后的列表中定义。
备忘
接下来,我们将会以此前使用的
Product(商品)表为基础来创建视图。如果大家已经根据之前章节的内容更新了
Product表中的数据,请在创建视图之前将数据恢复到初始状态。操作步骤如下所示。① 删除
Product表中的数据,将表清空DELETE FROM Product;② 执行代码清单 6(向 Product 表中插入数据)中的 SQL 语句,将数据插入到空表
Product中
下面就让我们试着来创建视图吧。和此前一样,这次我们还是将 Product 表(代码清单 2)作为基本表。
代码清单 2 ProductSum 视图

这样我们就在数据库中创建出了一幅名为 ProductSum(商品合计)的视图。
请大家一定不要省略第 2 行的关键字 AS。这里的 AS 与定义别名时使用的 AS 并不相同,如果省略就会发生错误。虽然很容易混淆,但是语法就是这么规定的,所以还是请大家牢记。
接下来,我们来学习视图的使用方法。视图和表一样,可以书写在 SELECT 语句的 FROM 子句之中(代码清单 3)。
代码清单 3 使用视图

执行结果:
product_type | cnt_product
--------------+------------
衣服 | 2
办公用品 | 2
厨房用具 | 4
通过上述视图 ProductSum 定义的主体(SELECT 语句)我们可以看出,该视图将根据商品种类(product_type)汇总的商品数量(cnt_product)作为结果保存了起来。
这样如果大家在工作中需要频繁进行汇总时,就不用每次都使用 GROUP BY 和 COUNT 函数写 SELECT 语句来从 Product 表中取得数据了。
创建出视图之后,就可以通过非常简单的 SELECT 语句,随时得到想要的汇总结果。并且如前所述,Product 表中的数据更新之后,视图也会自动更新,非常灵活方便。
之所以能够实现上述功能,是因为视图就是保存好的 SELECT 语句。
定义视图时可以使用任何 SELECT 语句,既可以使用 WHERE、GROUP BY、HAVING,也可以通过 SELECT * 来指定全部列。
-
使用视图的查询
在
FROM子句中使用视图的查询,通常有如下两个步骤:① 首先执行定义视图的
SELECT语句② 根据得到的结果,再执行在
FROM子句中使用视图的SELECT语句也就是说,使用视图的查询通常需要执行 2 条以上的
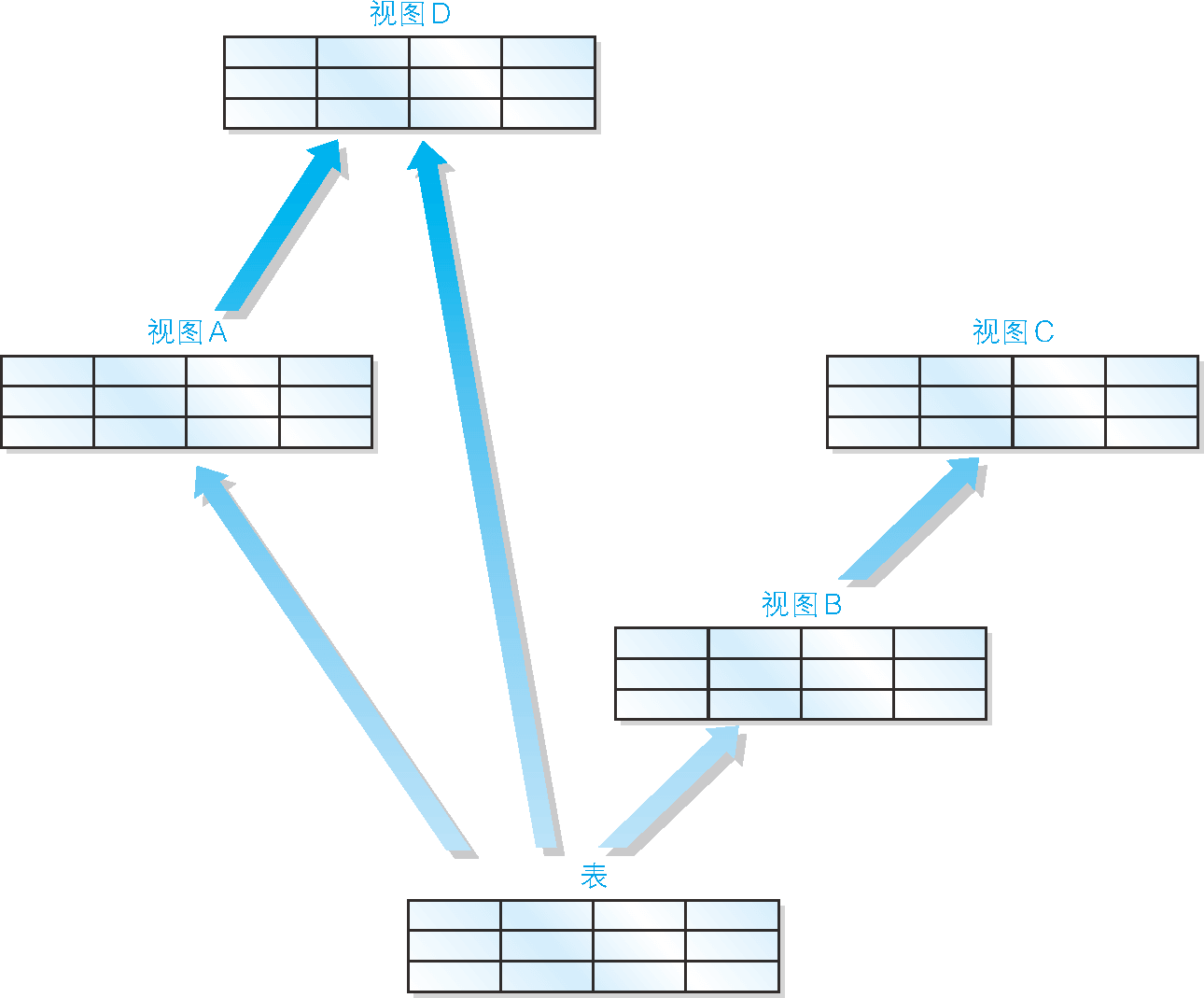
SELECT语句 [2]。这里没有使用“2 条”而使用了“2 条以上”,是因为还可能出现以视图为基础创建视图的多重视图(图 2)。
例如,我们可以像代码清单 4 那样以
ProductSum为基础创建出视图ProductSumJim。![可以在视图的基础上创建视图]()
图 2 可以在视图的基础上创建视图
代码清单 4 视图 ProductSumJim
![代码清单 4 视图 ProductSumJim]()
-- 确认创建好的视图 SELECT product_type, cnt_product FROM ProductSumJim;执行结果:
product_type | cnt_product --------------+------------ 办公用品 | 2虽然语法上没有错误,但是我们还是应该尽量避免在视图的基础上创建视图。这是因为对多数 DBMS 来说,多重视图会降低 SQL 的性能。因此,希望大家(特别是刚刚接触视图的读者)能够使用单一视图。
法则 3
应该避免在视图的基础上创建视图。
除此之外,在使用时还要注意视图有两个限制,接下来会给大家详细介绍。

1.3 视图的限制 ①——定义视图时不能使用 ORDER BY 子句
虽然之前我们说过在定义视图时可以使用任何 SELECT 语句,但其实有一种情况例外,那就是不能使用 ORDER BY 子句,因此下述视图定义语句是错误的。

为什么不能使用 ORDER BY 子句呢?这是因为视图和表一样,数据行都是没有顺序的。
实际上,有些 DBMS 在定义视图的语句中是可以使用 ORDER BY 子句的 [3],但是这并不是通用的语法。因此,在定义视图时请不要使用 ORDER BY 子句。
法则 4
定义视图时不要使用
ORDER BY子句。
1.4 视图的限制 ② ——对视图进行更新
之前我们说过,在 SELECT 语句中视图可以和表一样使用。那么,对于 INSERT、DELETE、UPDATE 这类更新语句(更新数据的 SQL)来说,会怎么样呢?
实际上,虽然这其中有很严格的限制,但是某些时候也可以对视图进行更新。标准 SQL 中有这样的规定:如果定义视图的 SELECT 语句能够满足某些条件,那么这个视图就可以被更新。
下面就给大家列举一些比较具有代表性的条件。
① SELECT 子句中未使用 DISTINCT
② FROM 子句中只有一张表
③ 未使用 GROUP BY 子句
④ 未使用 HAVING 子句
在前几章的例子中,FROM 子句里通常只有一张表。因此,大家可能会觉得 ② 中的条件有些奇怪,但其实 FROM 子句中也可以并列使用多张表。大家在学习完 SQL 如何使用内联结、外联结和交叉联结 的操作之后就明白了。
其他的条件大多数都与聚合有关。简单来说,像这次的例子中使用的 ProductSum 那样,使用视图来保存原表的汇总结果时,是无法判断如何将视图的更改反映到原表中的。
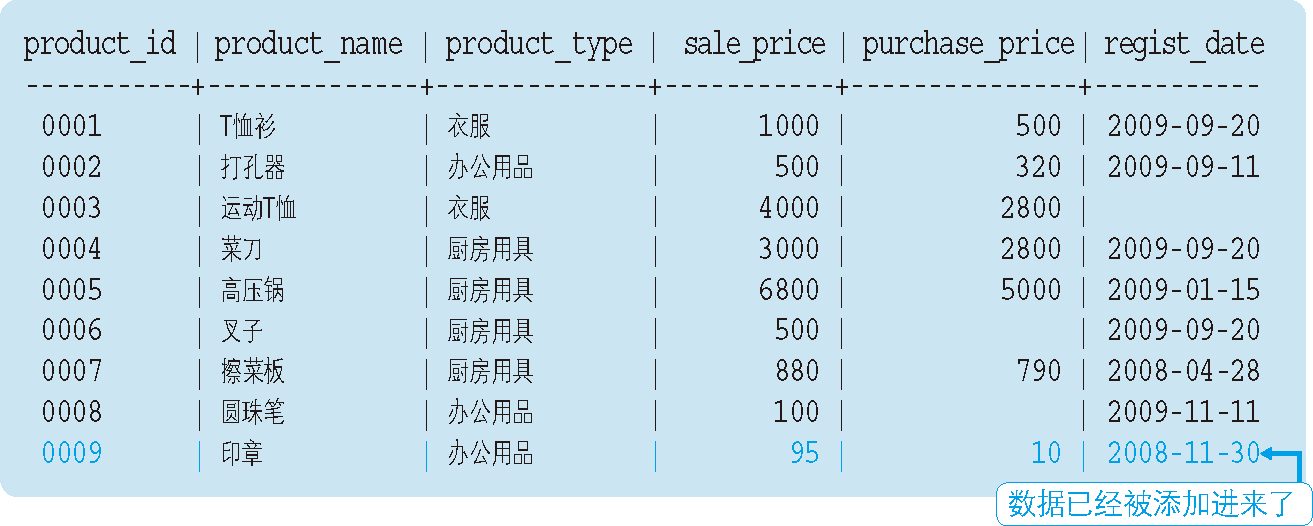
例如,对 ProductSum 视图执行如下 INSERT 语句。
INSERT INTO ProductSum VALUES ('电器制品', 5);
但是,上述 INSERT 语句会发生错误。这是因为视图 ProductSum 是通过 GROUP BY 子句对原表进行汇总而得到的。为什么通过汇总得到的视图不能进行更新呢?
视图归根结底还是从表派生出来的,因此,如果原表可以更新,那么视图中的数据也可以更新。反之亦然,如果视图发生了改变,而原表没有进行相应更新的话,就无法保证数据的一致性了。
使用前述 INSERT 语句,向视图 ProductSum 中添加数据 ('电器制品',5) 时,原表 Product 应该如何更新才好呢?按理说应该向表中添加商品种类为“电器制品”的 5 行数据,但是这些商品对应的商品编号、商品名称和销售单价等我们都不清楚(图 3)。数据库在这里就遇到了麻烦。
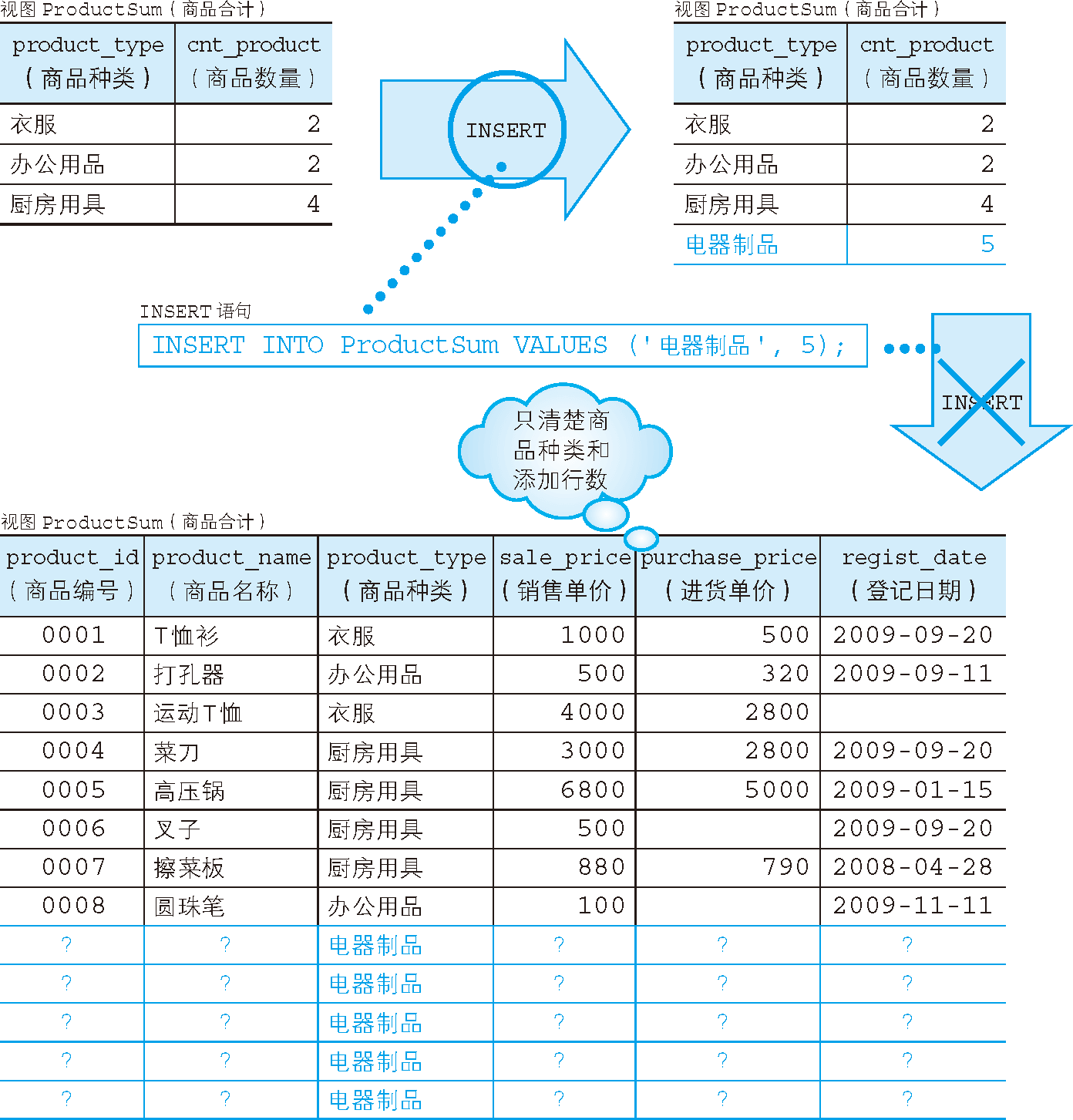
图 3 通过汇总得到的视图无法更新
法则 5
视图和表需要同时进行更新,因此通过汇总得到的视图无法进行更新。
-
能够更新视图的情况
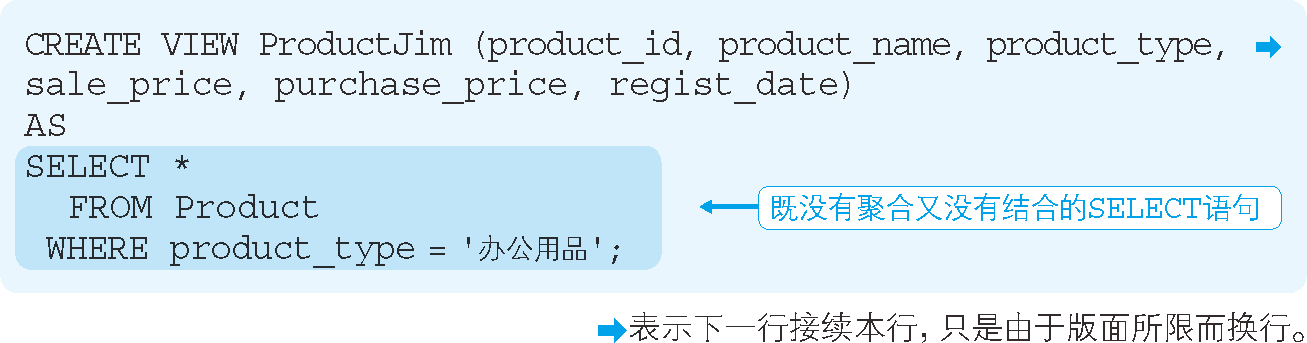
像代码清单 5 这样,不是通过汇总得到的视图就可以进行更新。
代码清单 5 可以更新的视图
![代码清单 5 可以更新的视图]()
对于上述只包含办公用品类商品的视图
ProductJim来说,就可以执行类似代码清单 6 这样的INSERT语句。代码清单 6 向视图中添加数据行
![代码清单 6 向视图中添加数据行]()

注意事项
由于 PostgreSQL 中的视图会被初始设定为只读,所以执行代码清单 6 中的
INSERT语句时,会发生下面这样的错误:ERROR: 不能向视图中插入数据 HINT: 需要一个无条件的ON INSERT DO INSTEAD规则这种情况下,在
INSERT语句执行之前,需要使用代码清单 A 中的指令来允许更新操作。在 DB2 和 MySQL 等其他 DBMS 中,并不需要执行这样的指令。代码清单 A 允许 PostgreSQL 对视图进行更新
PostgreSQL
CREATE OR REPLACE RULE insert_rule AS ON INSERT TO ProductJim DO INSTEAD INSERT INTO Product VALUES ( new.product_id, new.product_name, new.product_type, new.sale_price, new.purchase_price, new.regist_date);
下面让我们使用 SELECT 语句来确认数据行是否添加成功吧。
-
视图
-- 确认数据是否已经添加到视图中 SELECT * FROM ProductJim;执行结果:
![执行结果]()
-
原表
-- 确认数据是否已经添加到原表中 SELECT * FROM Product;执行结果:
![执行结果]()

UPDATE 语句和 DELETE 语句当然也可以像操作表时那样正常执行,但是对于原表来说却需要设置各种各样的约束(主键和 NOT NULL 等),需要特别注意。
1.5 删除视图
删除视图需要使用 DROP VIEW 语句,其语法如下所示。
语法 2 删除视图的 DROP VIEW 语句
DROP VIEW 视图名称(<视图列名1>, <视图列名2>, ……)
例如,想要删除视图 ProductSum 时,就可以使用代码清单 7 中的 SQL 语句。
代码清单 7 删除视图
DROP VIEW ProductSum;
特定的 SQL
在 PostgreSQL 中,如果删除以视图为基础创建出来的多重视图,由于存在关联的视图,因此会发生如下错误:
ERROR: 由于存在关联视图,因此无法删除视图productsum DETAIL: 视图productsumjim与视图productsum相关联 HINT: 删除关联对象请使用DROP…CASCADE这时可以像下面这样,使用
CASCADE选项来删除关联视图:DROP VIEW ProductSum CASCADE;
备忘
下面我们再次将
Product表恢复到初始状态(8 行)。请执行如下DELETE语句,删除之前添加的 1 行数据。-- 删除商品编号为0009(印章)的数据 DELETE FROM Product WHERE product_id = '0009';
二、子查询
本节重点
一言以蔽之,子查询就是一次性视图(
SELECT语句)。与视图不同,子查询在SELECT语句执行完毕之后就会消失。由于子查询需要命名,因此需要根据处理内容来指定恰当的名称。
标量子查询就是只能返回一行一列的子查询。
2.1 子查询和视图
前一节我们学习了视图这个非常方便的工具,本节将学习以视图为基础的子查询。子查询的特点概括起来就是一张一次性视图。
我们先来复习一下视图的概念,视图并不是用来保存数据的,而是通过保存读取数据的 SELECT 语句的方法来为用户提供便利。
反之,子查询就是将用来定义视图的 SELECT 语句直接用于 FROM 子句当中。
接下来,就让我们拿前一节使用的视图 ProductSum(商品合计)来与子查询进行一番比较吧。
首先,我们再来看一下视图 ProductSum 的定义和视图所对应的 SELECT 语句(代码清单 8)。
代码清单 8 视图 ProductSum 和确认用的 SELECT 语句
-- 根据商品种类统计商品数量的视图
CREATE VIEW ProductSum (product_type, cnt_product)
AS
SELECT product_type, COUNT(*)
FROM Product
GROUP BY product_type;
-- 确认创建好的视图
SELECT product_type, cnt_product
FROM ProductSum;
能够实现同样功能的子查询如代码清单 9 所示。
代码清单 9 子查询

特定的 SQL
在 Oracle 的
FROM子句中,不能使用AS(会发生错误),因此,在 Oracle 中执行代码清单 9 时,需要将 ① 中的“) AS ProductSum;”变为“) ProductSum;”
两种方法得到的结果完全相同。
执行结果:
product_type | cnt_product
--------------+------------
衣服 | 2
办公用品 | 2
厨房用具 | 4
如上所示,子查询就是将用来定义视图的 SELECT 语句直接用于 FROM 子句当中。
虽然“AS ProductSum”就是子查询的名称,但由于该名称是一次性的,因此不会像视图那样保存在存储介质(硬盘)之中,而是在 SELECT 语句执行之后就消失了。
实际上,该 SELECT 语句包含嵌套的结构,首先会执行 FROM 子句中的 SELECT 语句,然后才会执行外层的 SELECT 语句(图 4)。

图 4 SELECT 语句的执行顺序
① 首先执行 FROM 子句中的 SELECT 语句(子查询)
SELECT product_type, COUNT(*) AS cnt_product
FROM Product
GROUP BY product_type;
② 根据 ① 的结果执行外层的 SELECT 语句
SELECT product_type, cnt_product
FROM ProductSum;
法则 6
子查询作为内层查询会首先执行。
-
增加子查询的层数
由于子查询的层数原则上没有限制,因此可以像“子查询的
FROM子句中还可以继续使用子查询,该子查询的FROM子句中还可以再使用子查询……”这样无限嵌套下去(代码清单 10)。代码清单 10 尝试增加子查询的嵌套层数
SQL Server DB2 PostgreSQL MySQL
SELECT product_type, cnt_product FROM (SELECT * FROM (SELECT product_type, COUNT(*) AS cnt_product FROM Product GROUP BY product_type) AS ProductSum -----① WHERE cnt_product = 4) AS ProductSum2; -----------②特定的 SQL
在 Oracle 的
FROM子句中不能使用AS(会发生错误),因此,在 Oracle 中执行代码清单 10 时,需要将 ① 中的“) AS ProductSum”变为“) ProductSum”,将 ② 中的“) AS ProductSum2;”变为“) ProductSum2;”。执行结果:
product_type | cnt_product --------------+------------ 厨房用具 | 4最内层的子查询(
ProductSum)与之前一样,根据商品种类(product_type)对数据进行汇总,其外层的子查询将商品数量(cnt_product)限定为 4,结果就得到了 1 行厨房用具的数据。但是,随着子查询嵌套层数的增加,SQL 语句会变得越来越难读懂,性能也会越来越差。因此,请大家尽量避免使用多层嵌套的子查询。
2.2 子查询的名称
之前的例子中我们给子查询设定了 ProductSum 等名称。原则上子查询必须设定名称,因此请大家尽量从处理内容的角度出发为子查询设定恰当的名称。
在上述例子中,子查询用来对 Product 表的数据进行汇总,因此我们使用了后缀 Sum 作为其名称。
为子查询设定名称时需要使用 AS 关键字,该关键字有时也可以省略 [4]。
2.3 标量子查询
接下来我们学习子查询中的标量子查询(scalar subquery)。
2.3.1 什么是标量
标量就是单一的意思,在数据库之外的领域也经常使用。
上一节我们学习的子查询基本上都会返回多行结果(虽然偶尔也会只返回 1 行数据)。由于结构和表相同,因此也会有查询不到结果的情况。
而标量子查询则有一个特殊的限制,那就是必须而且只能返回 1 行 1 列的结果,也就是返回表中某一行的某一列的值,例如“10”或者“东京都”这样的值。
法则 7
标量子查询就是返回单一值的子查询。
细心的读者可能会发现,由于返回的是单一的值,因此标量子查询的返回值可以用在 = 或者 <> 这样需要单一值的比较运算符之中。这也正是标量子查询的优势所在。下面就让我们赶快来试试看吧。
2.3.2 在 WHERE 子句中使用标量子查询
在 SQL 如何插入、删除和更新数据 中,我们练习了通过各种各样的条件从 Product(商品)表中读取数据。大家有没有想过通过下面这样的条件查询数据呢?
“查询出销售单价高于平均销售单价的商品。”
或者说想知道价格处于上游的商品时,也可以通过上述条件进行查询。
然而这并不是用普通方法就能解决的。如果我们像下面这样使用 AVG 函数的话,就会发生错误。

虽然这样的 SELECT 语句看上去能够满足我们的要求,但是由于在 WHERE 子句中不能使用聚合函数,因此这样的 SELECT 语句是错误的。
那么究竟什么样的 SELECT 语句才能满足上述条件呢?
这时标量子查询就可以发挥它的功效了。首先,如果想要求出 Product 表中商品的平均销售单价(sale_price),可以使用代码清单 11 中的 SELECT 语句。
代码清单 11 计算平均销售单价的标量子查询
SELECT AVG(sale_price)
FROM Product;
执行结果:
avg
----------------------
2097.5000000000000000
AVG 函数的使用方法和 COUNT 函数相同,其计算式如下所示。
(1000+500+4000+3000+6800+500+880+100) / 8 = 2097.5
这样计算出的平均单价大约就是 2100 元。不难发现,代码清单 11 中的 SELECT 语句的查询结果是单一的值(2097.5)。
因此,我们可以直接将这个结果用到之前失败的查询之中。正确的 SQL 如代码清单 12 所示。
代码清单 12 选取出销售单价(sale_price)高于全部商品的平均单价的商品

执行结果:
product_id | product_name | sale_price
------------+--------------+-----------
0003 | 运动T恤 | 4000
0004 | 菜刀 | 3000
0005 | 高压锅 | 6800
前一节我们已经介绍过,使用子查询的 SQL 会从子查询开始执行。因此,这种情况下也会先执行下述计算平均单价的子查询(图 5)。
-- ① 内层的子查询
SELECT AVG(sale_price)
FROM Product ;
子查询的结果是 2097.5,因此会用该值替换子查询的部分,生成如下 SELECT 语句。
-- ② 外层的查询
SELECT product_id, product_name, sale_price
FROM Product
WHERE sale_price > 2097.5
大家都能看出该 SQL 没有任何问题可以正常执行,结果如上所述。
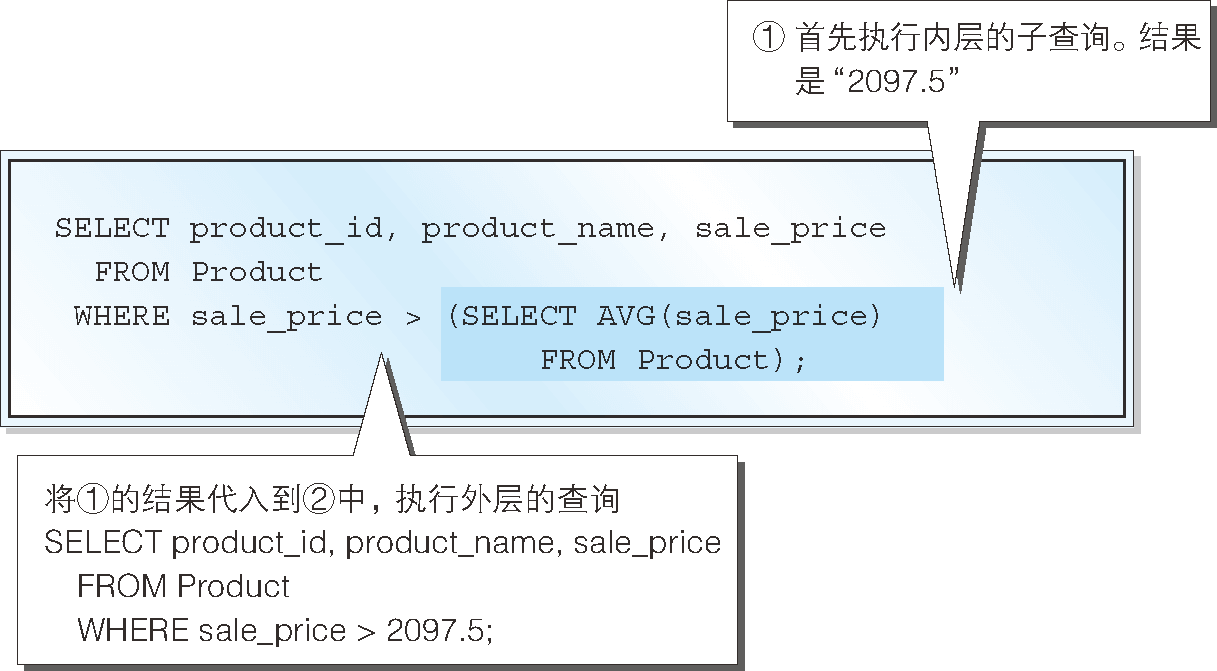
图 5 SELECT 语句的执行顺序(标量子查询)
2.4 标量子查询的书写位置
标量子查询的书写位置并不仅仅局限于 WHERE 子句中,通常任何可以使用单一值的位置都可以使用。也就是说,能够使用常数或者列名的地 方,无论是 SELECT 子句、GROUP BY 子句、HAVING 子句,还是 ORDER BY 子句,几乎所有的地方都可以使用。
例如,在 SELECT 子句当中使用之前计算平均值的标量子查询的 SQL 语句,如代码清单 13 所示。
代码清单 13 在 SELECT 子句中使用标量子查询
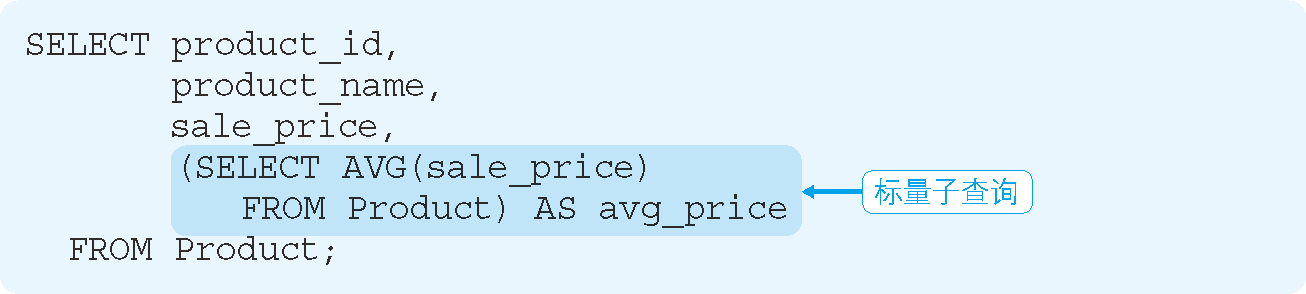
执行结果:
product_id | product_name | sale_price | avg_price
------------+---------------+------------+----------------------
0001 | T恤衫 | 1000 | 2097.5000000000000000
0002 | 打孔器 | 500 | 2097.5000000000000000
0003 | 运动T恤 | 4000 | 2097.5000000000000000
0004 | 菜刀 | 3000 | 2097.5000000000000000
0005 | 高压锅 | 6800 | 2097.5000000000000000
0006 | 叉子 | 500 | 2097.5000000000000000
0007 | 擦菜板 | 880 | 2097.5000000000000000
0008 | 圆珠笔 | 100 | 2097.5000000000000000
从上述结果可以看出,在商品一览表中加入了全部商品的平均单价。有时我们会需要这样的单据。
此外,我们还可以像代码清单 14 中的 SELECT 语句那样,在 HAVING 子句中使用标量子查询。
代码清单 14 在 HAVING 子句中使用标量子查询

执行结果:
product_type | avg
--------------+----------------------
衣服 | 2500.0000000000000000
厨房用具 | 2795.0000000000000000
该查询的含义是想要选取出按照商品种类计算出的销售单价高于全部商品的平均销售单价的商品种类。
如果在 SELECT 语句中不使用 HAVING 子句的话,那么平均销售单价为 300 元的办公用品也会被选取出来。
但是,由于全部商品的平均销售单价是 2097.5 元,因此低于该平均值的办公用品会被 HAVING 子句中的条件排除在外。
2.5 使用标量子查询时的注意事项
最后我们来介绍一下使用标量子查询时的注意事项,那就是该子查询绝对不能返回多行结果。
也就是说,如果子查询返回了多行结果,那么它就不再是标量子查询,而仅仅是一个普通的子查询了,因此不能被用在 = 或者 <> 等需要单一输入值的运算符当中,也不能用在 SELECT 等子句当中。
例如,如下的 SELECT 子查询会发生错误。

发生错误的原因很简单,就是因为会返回如下多行结果:
avg
----------------------
2500.0000000000000000
300.0000000000000000
2795.0000000000000000
在 1 行 SELECT 子句之中当然不可能使用 3 行数据。因此,上述 SELECT 语句会返回“因为子查询返回了多行数据所以不能执行”这样的错误信息 [5]。
三、关联子查询
本节重点
关联子查询会在细分的组内进行比较时使用。
关联子查询和
GROUP BY子句一样,也可以对表中的数据进行切分。关联子查询的结合条件如果未出现在子查询之中就会发生错误。
3.1 普通的子查询和关联子查询的区别
按此前所学,使用子查询就能选取出销售单价(sale_price)高于全部商品平均销售单价的商品。
这次我们稍稍改变一下条件,选取出各商品种类中高于该商品种类的平均销售单价的商品。
3.1.1 按照商品种类与平均销售单价进行比较
只通过语言描述可能难以理解,还是让我们来看看具体示例吧。我们以厨房用具中的商品为例,该分组中包含了表 1 所示的 4 种商品。
表 1 厨房用具中的商品
| 商品名称 | 销售单价 |
|---|---|
| 菜刀 | 3000 |
| 高压锅 | 6800 |
| 叉子 | 500 |
| 擦菜板 | 880 |
因此,计算上述 4 种商品的平均价格的算术式如下所示。
(3000 + 6800 + 500 + 880) / 4 = 2795 (元)
这样我们就能得知该分组内高于平均价格的商品是菜刀和高压锅了,这两种商品就是我们要选取的对象。
我们可以对余下的分组继续使用同样的方法。衣服分组的平均销售单价是:
(1000 + 4000) / 2 = 2500 (元)
因此运动T恤就是要选取的对象。办公用品分组的平均销售单价是:
(500 + 100) / 2 = 300 (元)
因此打孔器就是我们要选取的对象。
这样大家就能明白该进行什么样的操作了吧。我们并不是要以全部商品为基础,而是要以细分的组为基础,对组内商品的平均价格和各商品的销售单价进行比较。
按照商品种类计算平均价格并不是什么难事,我们已经学习过了,只需按照代码清单 15 那样,使用 GROUP BY 子句就可以了。
代码清单 15 按照商品种类计算平均价格
SELECT AVG(sale_price)
FROM Product
GROUP BY product_type;
但是,如果我们使用前一节(标量子查询)的方法,直接把上述 SELECT 语句使用到 WHERE 子句当中的话,就会发生错误。
-- 发生错误的子查询
SELECT product_id, product_name, sale_price
FROM Product
WHERE sale_price > (SELECT AVG(sale_price)
FROM Product
GROUP BY product_type);
出错原因前一节已经讲过了,该子查询会返回 3 行结果(2795、2500、300),并不是标量子查询。在 WHERE 子句中使用子查询时,该子查询的结果必须是单一的。
但是,如果以商品种类分组为单位,对销售单价和平均单价进行比较,除此之外似乎也没有其他什么办法了。到底应该怎么办才好呢?
3.1.2 使用关联子查询的解决方案
这时就轮到我们的好帮手——关联子查询登场了。
只需要在刚才的 SELECT 语句中追加一行,就能得到我们想要的结果了 [6]。事实胜于雄辩,还是让我们先来看看修改之后的 SELECT 语句吧(代码清单 16)。
代码清单 16 通过关联子查询按照商品种类对平均销售单价进行比较

特定的 SQL
Oracle 中不能使用
AS(会发生错误)。因此,在 Oracle 中执行代码清单 16 时,请大家把 ① 中的FROM Product AS P1变为FROM Product P1,把 ② 中的FROM Product AS P2变为FROM Product P2。
执行结果:
product_type | product_name | sale_price
---------------+---------------+------------
办公用品 | 打孔器 | 500
衣服 | 运动T恤 | 4000
厨房用具 | 菜刀 | 3000
厨房用具 | 高压锅 | 6800
这样我们就能选取出办公用品、衣服和厨房用具三类商品中高于该类商品的平均销售单价的商品了。
这里起到关键作用的就是在子查询中添加的 WHERE 子句的条件。该条件的意思就是,在同一商品种类中对各商品的销售单价和平均单价进行比较。
这次由于作为比较对象的都是同一张 Product 表,因此为了进行区别,分别使用了 P1 和 P2 两个别名。
在使用关联子查询时,需要在表所对应的列名之前加上表的别名,以“<表名>.<列名>”的形式记述。
在对表中某一部分记录的集合进行比较时,就可以使用关联子查询。
因此,使用关联子查询时,通常会使用“限定(绑定)”或者“限制”这样的语言,例如本次示例就是限定“商品种类”对平均单价进行比较。
法则 8
在细分的组内进行比较时,需要使用关联子查询。
3.2 关联子查询也是用来对集合进行切分的
换个角度来看,其实关联子查询也和 GROUP BY 子句一样,可以对集合进行切分。
大家还记得我们用来说明 GROUP BY 子句 的图(图 6)吗?
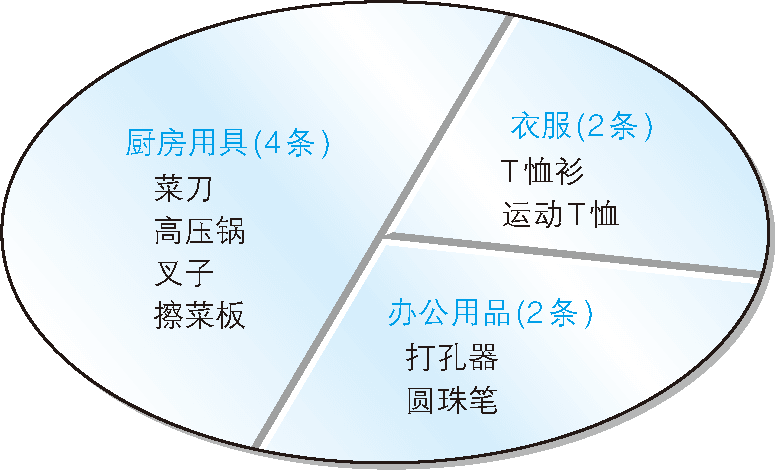
图 6 根据商品种类对表进行切分的图示
上图显示了作为记录集合的表是如何按照商品种类被切分的。使用关联子查询进行切分的图示也基本相同(图 7)。
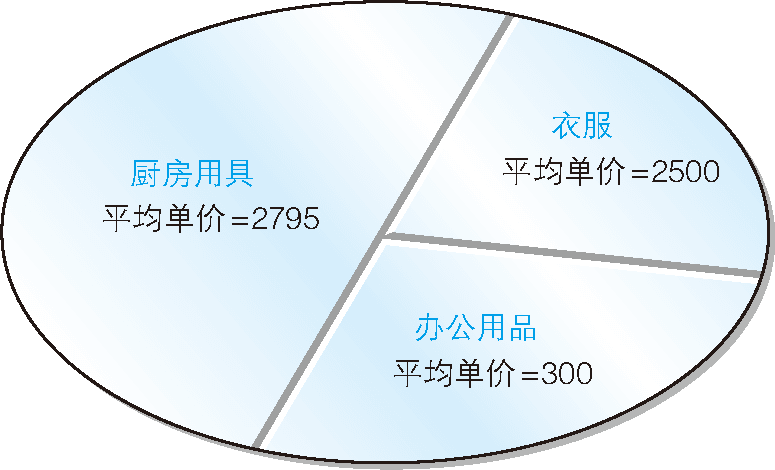
图 7 根据关联子查询进行切分的图示
我们首先需要计算各个商品种类中商品的平均销售单价,由于该单价会用来和商品表中的各条记录进行比较,因此关联子查询实际只能返回 1 行结果。
这也是关联子查询不出错的关键。关联子查询执行时,DBMS 内部的执行情况如图 8 所示。
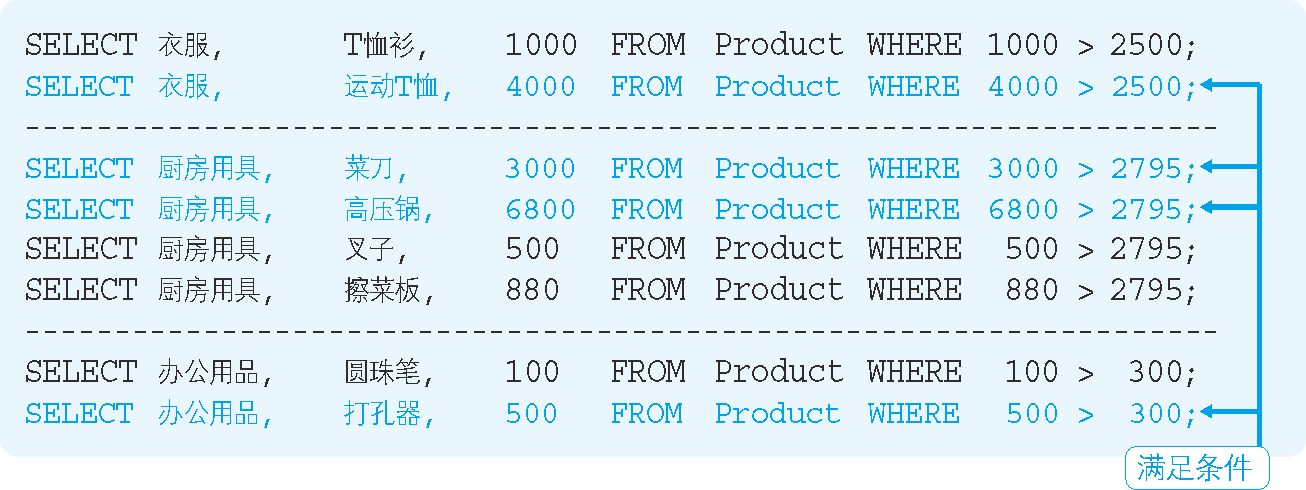
图 8 关联子查询执行时 DBMS 内部的执行情况
如果商品种类发生了变化,那么用来进行比较的平均单价也会发生变化,这样就可以将各种商品的销售单价和平均单价进行比较了。
关联子查询的内部执行结果对于初学者来说是比较难以理解的,但是像上图这样将其内部执行情况可视化之后,理解起来就变得非常容易了吧。
3.3 结合条件一定要写在子查询中
下面给大家介绍一下 SQL 初学者在使用关联子查询时经常犯的一个错误,那就是将关联条件写在子查询之外的外层查询之中。请大家看一下下面这条 SELECT 语句。

上述 SELECT 语句只是将子查询中的关联条件移到了外层查询之中,其他并没有任何更改。但是,该 SELECT 语句会发生错误,不能正确执行。
允许存在这样的书写方法可能并不奇怪,但是 SQL 的规则禁止这样的书写方法。
该书写方法究竟违反了什么规则呢?那就是关联名称的作用域。虽然这一术语看起来有些晦涩难懂,但是一解释大家就明白了。
关联名称就是像 P1、P2 这样作为表别名的名称,作用域(scope)就是生存范围(有效范围)。也就是说,关联名称存在一个有效范围的限制。
具体来讲,子查询内部设定的关联名称,只能在该子查询内部使用(图 9)。换句话说,就是“内部可以看到外部,而外部看不到内部”。
请大家一定不要忘记关联名称具有一定的有效范围。
如前所述,SQL 是按照先内层子查询后外层查询的顺序来执行的。这样,子查询执行结束时只会留下执行结果,作为抽出源的 P2 表其实已经不存在了 [7]。
因此,在执行外层查询时,由于 P2 表已经不存在了,因此就会返回“不存在使用该名称的表”这样的错误。

图 9 子查询内的关联名称的有效范围
原文链接:https://www.developerastrid.com/sql/sql-view-subqueries/
(完)
数据保存在表中时,必须要显式地执行 SQL 更新语句才能对数据进行更新。 ↩︎
但是根据实现方式的不同,也存在内部使用视图的
SELECT语句本身进行重组的 DBMS。 ↩︎例如,在 PostgreSQL 中上述 SQL 语句就没有问题,可以执行。 ↩︎
其中也有像 Oracle 这样,在名称之前使用
AS关键字就会发生错误的数据库,大家可以将其视为例外的情况。 ↩︎例如,使用 PostgreSQL 时会返回如下错误。“ERROR :副查询中使用了返回多行结果的表达式” ↩︎
事实上,对于代码清单 16 中的
SELECT语句,即使在子查询中不使用GROUP BY子句,也能得到正确的结果。这是因为在WHERE子句中追加了“P1.product_type=P2.product_type”这个条件,使得AVG函数按照商品种类进行了平均值计算。但是为了跟前面出错的查询进行对比,这里还是加上了GROUP BY子句。 ↩︎当然,消失的其实只是
P2这个名称而已,Product表以及其中的数据还是存在的。 ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号