Atcoder ABC268 题解&总结
rank:479
AC:ABCDF
D. Unique Username
发现最多有 \(8\) 个,那么我们可以直接暴力枚举一下这 \(8\) 个串的全排列,在中间插入几个 _,然后可以选择直接用 set 暴力判重。
E. Chinese Restaurant (Three-Star Version)
考虑一个人的影响,可以发现从那个人开始,是 \(1,2,\dots,\frac n2,\dots,2,1\),所以可以画出大致这样的图像:
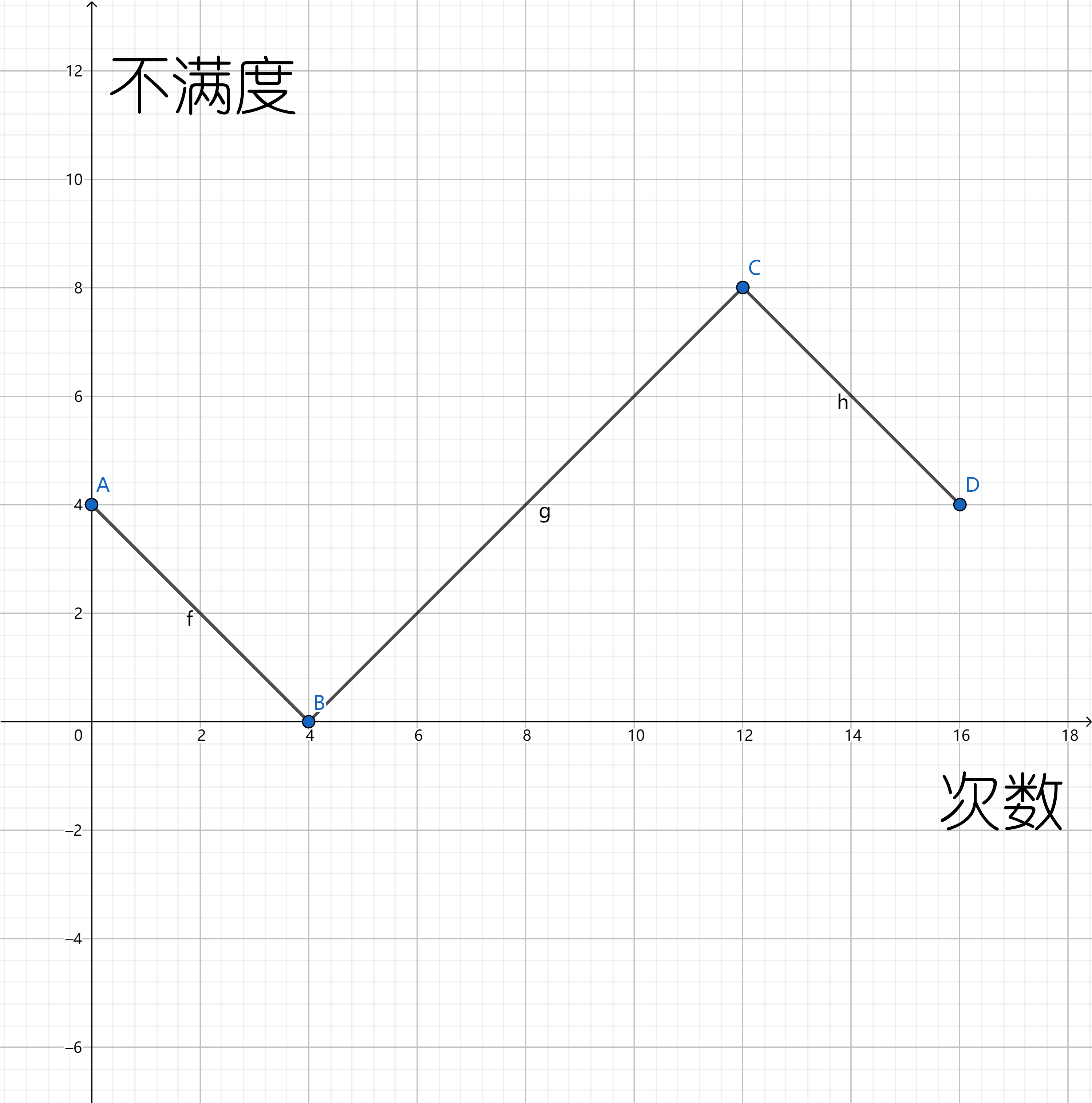
为了方便,我们将环复制一遍,这样每个点可以是后面上升与下降的两个函数,一个函数的 \(k\) 和 \(b\) 是不变的,并且具有可加性,所以这样就好弄多了。
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
ll b[400100],k[400100];
int p[200100];
ll ans=1e14;
int main()
{
int n;
int i;
cin>>n;
for(i=0; i<n; i++)
scanf("%d", &p[i]);
for(i=0; i<n; i++)
{
int x=(p[i]-i+n)%n; // 转到对应位置(不满值为 0)的次数
// 差分
b[x]-=x; b[x+n/2+1]+=x;
k[x]+=1; k[x+n/2+1]-=1;
b[x+n/2+1]+=x+n; b[n+x]-=x+n;
k[x+n/2+1]-=1; k[n+x]+=1;
}
for(i=0; i<n*2; i++)
b[i]+=b[i-1],k[i]+=k[i-1];
for(i=0; i<n; i++)
ans=min(ans, b[i]+k[i]*i+b[i+n]+k[i+n]*(i+n));
cout<<ans;
return 0;
}
F. Best Concatenation
假设每个字符串里面有 \(a\) 个 X,前面加一个 X 的贡献是 \(b\)。首先我们把每个字符串里面的 X 对当前字符串的贡献直接加进去,这部分肯定是不变的,只需要考虑与其它字符串的影响。
假设当前有两个串 \(x\),\(y\),设前面已经有了 \(A\) 个 X,当前答案为 \(ans\),那么如果 \(x\) 比 \(y\) 优,要满足下面的式子:
直接排序即可。
G. Random Student ID
对于一名学生,他的排名是比他小的学生的数量,所以我们只需要找到每名学生小于他的概率即可。
我们分为三种情况来讨论(设当前为 \(x\))
- 如果是 \(x\) 的前缀,那么可以知道他一定比 \(x\) 小,那么概率就是 \(1\)。
- 如果 \(x\) 是当前串的前缀,那么可以知道 \(x\) 一定比他小,概率就是 \(0\)。
- 否则,证明一定有一位两者不一样,那也就是根据这一位上的两个不同的字母比较大小。因为是全排列都有可能,也就是两个字母要不就是这个大,要不就是这个小,所以概率是 \(0.5\)。
如果设有 \(pre\) 个是 \(x\) 的前缀,有 \(nxt\) 个 \(x\) 他们的前缀,那么排名就是
下面介绍一个很简单的 \(O(n)\) 求 \(pre\) 和 \(nxt\)(不得不说太神奇了)
我们首先对每个串后面添加一个大于 z 的字符(例如 |),然后与原串一块放到一个数组,排个序。原串当成左括号,添加后的当成右括号,可以发现两者之间的就是 \(nxt\),而没有闭合的左括号就是 \(pre\)。
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const ll p = 998244353;
const ll inv2 = 499122177;
pair<string,int> a[1000100];
int pre[1000100],nxt[1000100];
int idx[1000100];
int cnt;
int main()
{
int n;
int i;
cin>>n;
for(i=1; i<=n; i++)
{
string s;
cin>>s;
a[i]=make_pair(s, i);
a[i+n]=make_pair(s+'|', i);
}
sort(a+1, a+1+n*2);
for(i=1; i<=2*n; i++)
{
string s=a[i].first;
if(s[s.size()-1]!='|')
{
++cnt;
idx[a[i].second]=i;
pre[a[i].second]=cnt;
}
else
{
--cnt;
nxt[a[i].second]=(i-idx[a[i].second])/2;
}
}
for(i=1; i<=n; i++)
printf("%lld\n", (pre[i]+n-nxt[i])*inv2%p);
return 0;
}
EX. Taboo
题意
给定一个字符串 \(S\),和 \(n\) 个字符串 \(T\),最少需要将多少个 \(s_i\) 变为 * 可以使 \(S\) 没有子串为 \(T\)。
分析
首先我们可以发现每个位置可以匹配一些字符串,那么也就是一些区间,我们需要将这些区间用最少的点覆盖掉。那么对于同一个点,如果长度较小的区间被覆盖,那么长度比较大的区间一定也被覆盖。根据这个性质,我们只需要找到每个点最短的那个区间就可以了,也就是以这个点为起点,最短的匹配串。
求出每个点最短的匹配串后,我们可以贪心的选点,对于一个点,肯定越靠后,这个点可能覆盖的区间越多。
那么怎么求每个位置的最短匹配串呢?Atcoder 官方给的是使用后缀数组求,具体方法没怎么研究(主要本人后缀数组比较垃圾)。这里选择使用 AC 自动机去求。我们首先将 \(T\) 构建 AC 自动机,然后匹配 \(S\),如果有结束标记,设这个长度为 \(len_j\),对于每个位置,我们一样跳 \(fail\) 边,然后可以得到:
根本没有什么性质!!!如果暴力跳 \(fail\) 肯定 TLE,所以可以将所有串翻转一下,这是就变成了:
也就是 \(a_{n-i+1}\) 是失配树上一直到根节点的一段路径的最小值,此时就好维护多了,我们直接存一下每个节点有哪些位置,然后遍历失配树就可以了。最后跑一边贪心直接出答案~
#include<bits/stdc++.h>
using namespace std;
struct ACTrie
{
int tr[500100][26];
int fail[500100];
bool flag[500100];
int len[500100];
int cnt=1;
vector<int> v[500100];
vector<int> p[500100];
int *a;
void insert(char s[])
{
int n=strlen(s+1); reverse(s+1, s+1+n);
int u=1;
for(int i=1; i<=n; i++)
{
int c=s[i]-'a';
if(!tr[u][c]) tr[u][c]=++cnt;
u=tr[u][c];
}
flag[u]=1; len[u]=n;
}
void build()
{
queue<int> q;
for(int i=0; i<26; i++) tr[0][i]=1;
q.push(1);
while(q.size())
{
int u=q.front(); q.pop();
for(int i=0; i<26; i++)
{
int v=tr[u][i];
if(!v)
{
tr[u][i]=tr[fail[u]][i];
continue;
}
fail[v]=tr[fail[u]][i];
q.push(v);
}
}
for(int i=1; i<=cnt; i++)
v[fail[i]].push_back(i);
}
void search(char s[])
{
int n=strlen(s+1); reverse(s+1, s+1+n);
int u=1;
for(int i=1; i<=n; i++)
{
u=tr[u][s[i]-'a'];
p[u].push_back(n-i+1);
}
}
void dfs(int x, int k)
{
if(flag[x]) k=min(k, len[x]);
for(int y : p[x])
a[y]=k;
for(int y : v[x])
dfs(y, k);
}
};
char s[500100],ss[500100];
ACTrie t;
int a[500100];
int ans,minn=1e9;
int main()
{
int n,m;
int i;
scanf("%s%d", s+1, &n); m=strlen(s+1);
for(int i=1; i<=n; i++)
{
scanf("%s", ss+1);
t.insert(ss);
}
t.build();
memset(a, 0x3f, sizeof(a)); t.a=a;
t.search(s); t.dfs(1, 1e9);
for(i=1; i<=m; i++) // 贪心
{
minn=min(minn, i+a[i]-1);
if(minn==i)
++ans,minn=1e9;
}
cout<<ans;
return 0;
}
至此,ABC268 全面完工!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号