Cassandra数据建模中最重要的事情:主键
Cassandra数据建模中要了解的最重要的事情:主键
使用关系数据建模,您可以从主键开始,但是RDBMS中的有效数据模型更多地是关于表之间的外键关系和关系约束。由于Cassandra无法使用JOIN,因此创建数据模型的复杂性要低得多。Apache Cassandra的复杂性折衷在于提前了解您的查询和数据访问模式。
1.简单主键:
例子: student_id是person的主键
create table person (student_id int primary key, fname text, lname text,
dateofbirth timestamp, email text, phone text );
2.复合键
- C1:主键只有一个分区键,没有群集键。
- (C1,C2):列C1是分区键,列C2是群集键。
- (C1,C2,C3,...):列C1是分区键,列C2,C3等构成集群键。
- (C1,(C2,C3,…)):与3相同,即C1列是分区键,C2,C3…列构成集群键。
- (((C1,C2,...),(C3,C4,...))):列C1,C2作分区键,列C3,C4,…作群集键。
重要的是要注意,当复合键为C1,C2,C3时,第一个键C1成为分区键,其余键成为群集键的一部分。为了制作复合分区键,我们必须在括号中指定键,例如:((C1,C2),C3,C4)。在这种情况下,C1和C2是分区键的一部分,而C3和C4是群集键的一部分。
1.分区键
分区键的目的是识别存储该行的群集中的分区或节点。从群集读取或写入数据时,将使用一个名为Partitioner的函数来计算分区键的哈希值。该哈希值用于确定包含该行的节点/分区。
例如,分区键值范围在1000到1234之间的行可以驻留在节点A中,而分区键值范围在1235到2000之间的行可以驻留在节点B中,如图1所示。值为1233,则将其存储在节点A中。
2.集群键
集群键的目的是按排序顺序存储行数据。数据的排序基于列,这些列包含在集群键中。这种安排使使用聚类密钥检索数据变得高效。
例子1
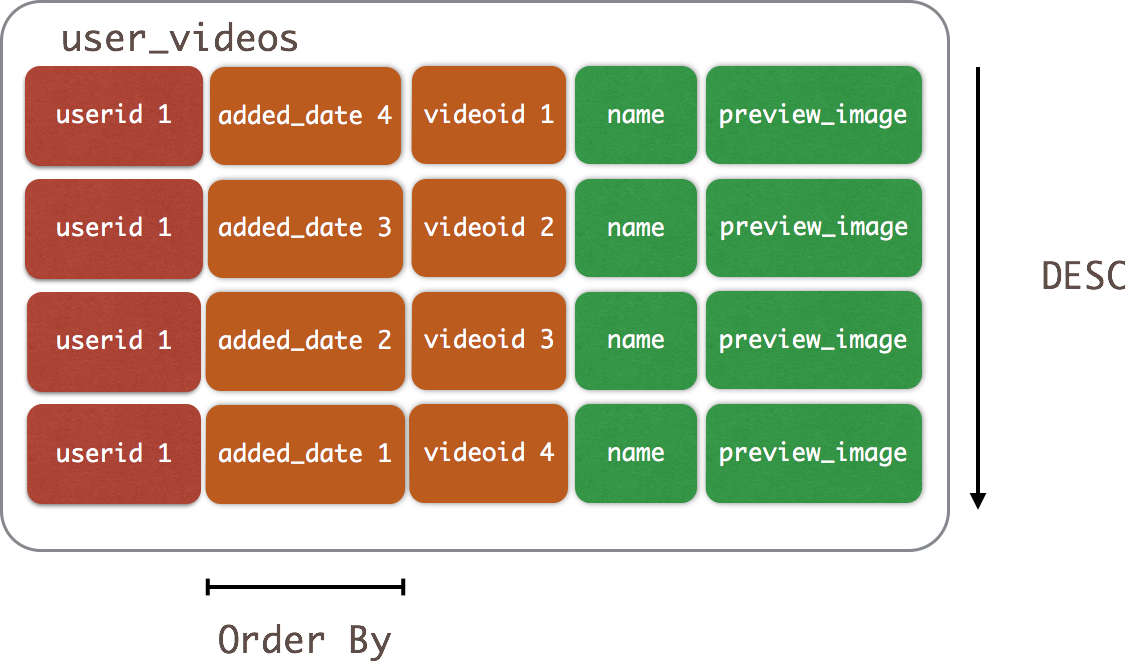
CREATE TABLE user_videos ( userid uuid, added_date timestamp, videoid uuid, name text, preview_image_location text, PRIMARY KEY (userid, added_date, videoid) ) WITH CLUSTERING ORDER BY (added_date DESC, videoid ASC);
分区userid,集群键排序方式:added_date DESC, videoid ASC
SELECT * FROM user_videos WHERE userid = 522b1fe2-2e36-4cef-a667-cd4237d08b89 LIMIT 10;
例子2
create table marks(stuid int,exam_date timestamp,marks float, exam_name text,
primary key (stuid,exam_date));
分区stuid,默认exam_date升序排序
SELECT * FROM user_videos WHERE userid = 522b1fe2-2e36-4cef-a667-cd4237d08b89 LIMIT 10;
该查询所要查询的是“用户上传的最后10部视频”,只需添加CLUSTERING ORDER BY子句即可实现非常快速,有用和高效的查询。
这可能看起来像是预先优化的,但是此添加功能启用的用例非常引人注目。
结论
Apache Cassandra的复杂性trade off在于提前了解您的查询和数据访问模式。(反模式的一种体现)
参考文章
https://dzone.com/articles/cassandra-data-modeling-primary-clustering-partiti
https://www.datastax.com/blog/2016/02/most-important-thing-know-cassandra-data-modeling-primary-key

 浙公网安备 33010602011771号
浙公网安备 33010602011771号