第二次
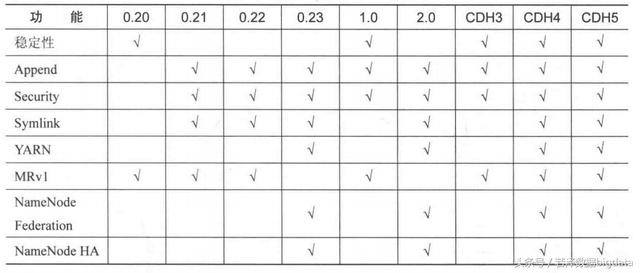
1.了解对比Hadoop不同版本的特性,可以用图表的形式呈现。
2.Hadoop生态的组成、每个组件的作用、组件之间的相互关系,以图例加文字描述呈现。
| 组件名 | 功能及作用 | 优势 | 局限 | 应用场景 | 相关功能组件 |
|---|---|---|---|---|---|
| HDFS | 分布式文件系统。存储是大数据技术的基础 | (1)高吞吐量访问; (2)高容错性; (3)容量扩充 | (1)不适合低延迟数据访问; (2)不适合存储大量小文件; (3)不支持多用户写入及任意修改文件(只能执行追加操作,写操作只能在文件末位完成) | 可处理超大文件,可运行于廉价的商用机器集群。 | hadoop文件系统包含local(支持有客户端校验和的本地文件系统)、har(构建在其他文件系统上进行归档文件的文件系统,在hadoop主要被用来减少namenode的内存使用)、kfs(cloudstroe前身是Kosmos文件系统,是类似于HDFS和Google的GFS的文件系统)、ftp(由FTP服务器支持的文件系统) |
| Mapreduce | 计算模型 | (1)被多台主机同事处理,速度快; (2)擅长处理少量大数据; (3)容错性,节点故障导致失败作业时,mapreduce计算框架会自动将作业安排到健康的节点 | (1)不适合大量小数据; (2)过于底层化,编程复杂; (3)JobTracker单点瓶颈,JobTracker负责作业的分发、管理和调度,任务量多会造成其内存和网络带宽的快速消耗,最终使其成为集群的单点瓶颈; (4)Task分配容易不均; (5)作业延迟高(TaskTracker汇报资源和运行情况,JobTracker根据其汇报情况分配作业等过程); (6)编程框架不够灵活; (7)Map池和Reduce池区分降低了资源利用率; | 日志分析、海量数据排序、在海量数据中查找特定模式等 | 可用hive简化操作,完成简单任务 |
| Yarn | 改善MapReduce的缺陷 | (1)分散了JobTracker任务,提高了集群的扩展性和可用性; (2)扩大了MapReduce编程人员范围; (3)在资管管理器故障时,可快速重启恢复状态; (4)不再区分Map池和Reduce池,提高了资源利用率; | |||
| Hive | 数据仓库 | (1)易操作; (2)能处理不变的大规模数据级上的批量任务; (3)可扩展性(可自动适应机器数目和数据量的动态变化); (4)可延展性(结合mapreduce和用户定义的函数库); (5)良好的容错性; (6)低约束的数据输入格式 | (1)不提供数据排序和查询功能; (2)不提供在线事务处理; (3)不提供实时查询; (4)执行延迟 | ||
| Hbase | 数据仓库 | 数据库,存储松散型数据。向下提供存储,向上提供运算。 | (1)海量存储; (2)列式存储; (3)极易扩展(基于RegionServer上层处理能力的扩展和基于HDFS存储的扩展); (4)高并发; (5)稀疏,列数据为空时,不会占用存储空间。 | (1)对多表关联查询支持不足; (2)不支持sql,开发难度加大 | 查询简单、不涉及复杂关联的场景,如海量流水数据、交易记录、数据库历史数据 |
| Pig | 数据分析平台,侧重数据查询和分析,而不是对数据进行修改和删除等。需要把真正的查询转换成相应的MapReduce作业 | (1)处理海量数据的速度快 (2)相较mapreduce,使用Pig Latin编写程序时,不需关心程序如何更好地在hadoop云平台上运行,因为这些都有pig系统自行分配。 (3)在资管管理器故障时,可快速重启恢复状态; (4)不再区分Map池和Reduce池,提高了资源利用率; | 处理系统内日志文件、处理大型数据库文件、处理特定web数据 | 可看做简化mapreduce的高级语言 | |
| Zookeeper | 协调服务 | (1)高吞吐量 (2)低延迟 (3)高可靠 (4)有序性,每一次更新操作都有一个全局版本号 | 控制集群中的数据,如管理hadoop集群中的NameNode、Hbase中的Mster Election、Server见的状态同步 | ||
| Avro | 基于二进制数据传输高性能的中间件。数据序列化系统,可以将数据结构或对象转化成便于存储或传输的格式,以节约数据存储空间和网络传输贷款。适用于远程或本地大批量数据交互。 | (1)模式和数据在一起,反序列化时写入的模式和独处的模式都是已知的; (2)多语言支持; (3)可有效减少大规模存储较小的数据文件的数据量; (4)丰富的数据结构类型 | hadoop的RPC | ||
| Chukwa | 数据收集系统,帮助hadoop用户清晰了解系统运行的状态,分析作业运行的状态及HDFS的文件存储状态 | Scribe存储在中央存储系统(NFS)、Kafka、Flume。看到一篇对于日志系统讲的比较清晰的,也做了分类比较,再次引用给大家。 |
3.官网学习Hadoop的安装与使用,用文档的方式列出步骤与注意事项。
解压Hadoop安装包(只在master做)
确保network网络已经配置好,使用Xftp等类似工具进行上传,把hadoop-2.7.5.tar.gz上传到/opt/hadoop目录内。
上传完成后,在master主机上执行以下代码:
cd /opt/hadoop进入/opt/hadoop目录后,执行解压缩命令:
tar -zxvf hadoop-2.7.5.tar.gz回车后系统开始解压,屏幕会不断滚动解压过程,执行成功后,系统在hadoop目录自动创建hadoop-2.7.5子目录。
然后修改文件夹名称为“hadoop”,即hadoop安装目录,执行修改文件夹名称命令:
mv hadoop-2.7.5 hadoop注意:也可用Xftp查看相应目录是否存在,确保正确完成。
我们进入安装目录,查看一下安装文件,如果显示如图文件列表,说明压缩成功
配置env文件(只在master做)
请先看如下命令(并且记住它们,后续操作大量用到,并且不再赘述):
A. 进入编辑状态:insert
B. 删除:delete
C. 退出编辑状态:ctrl+[
D. 进入保存状态:ctrl+]
E. 保存并退出:" :wq " 注意先输入英文状态下冒号
F. 不保存退出:" :q! " 同上
大概执行顺序:A→B→C→D→E
配置jdk文件
执行命令:
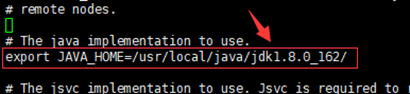
vi /opt/hadoop/hadoop/etc/hadoop/hadoop-env.sh找到 “ export JAVA_HOME ” 这行,用来配置jdk路径
修改为:export JAVA_HOME=/usr/local/java/jdk1.8.0_162/
配置核心组件文件(只在master做)
Hadoop的核心组件文件是core-site.xml,位于/opt/hadoop/hadoop/etc/hadoop子目录下,用vi编辑core-site.xml文件,需要将下面的配置代码放在文件的<configuration>和</configuration>之间。
执行编辑core-site.xml文件的命令:
vi /opt/hadoop/hadoop/etc/hadoop/core-site.xml需要在<configuration>和</configuration>之间加入的代码:
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoopdata</value>
</property>编辑完成后,退出并保存即可!
配置文件系统(只在master做)
Hadoop的文件系统配置文件是hdfs-site.xml,位于/opt/hadoop/hadoop/etc/hadoop子目录下,用vi编辑该文件,需要将以下代码放在文件的<configuration>和</configuration>之间。
执行编辑hdfs-site.xml文件的命令:
vi /opt/hadoop/hadoop/etc/hadoop/hdfs-site.xml需要在<configuration>和</configuration>之间加入的代码:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>编辑完成后,退出保存即可!
配置 yarn-site.xml 文件(只在master做)
Yarn的站点配置文件是yarn-site.xml,位于/opt/hadoop/hadoop/etc/hadoop子目录下,依然用vi编辑该文件,将以下代码放在文件的<configuration>和</configuration>之间。
执行编辑yarn-site.xml文件的命令:
vi /opt/hadoop/hadoop/etc/hadoop/yarn-site.xml需要在<configuration>和</configuration>之间加入的代码:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>配置MapReduce计算框架文件(只在master做)
在/opt/hadoop/hadoop/etc/hadoop子目录下,系统已经有一个mapred-site.xml.template文件,我们需要将其复制并改名,位置不变。
执行复制和改名操作命令:
cp /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml.template /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml然后用vi编辑mapred-site.xml文件,需要将下面的代码填充到文件的<configuration>和</configuration>之间。
执行命令:
vi /opt/hadoop/hadoop/etc/hadoop/mapred-site.xml需要在<configuration>和</configuration>之间加入的代码:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>编辑完毕,保存退出即可!
配置master的slaves文件(只在master做)
slaves文件给出了Hadoop集群的slave节点列表,该文件十分的重要,因为启动Hadoop的时候,系统总是根据当前slaves文件中的slave节点名称列表启动集群,不在列表中的slave节点便不会被视为计算节点。
执行编辑slaves文件命令:
vi /opt/hadoop/hadoop/etc/hadoop/slaves注意:用vi编辑slaves文件,应该根据读者您自己所搭建集群的实际情况进行编辑。
例如:我这里已经安装了slave0和slave1,并且计划将它们全部投入Hadoop集群运行。
所以应当加入以下代码:
slave0
slave1注意:删除slaves文件中原来localhost那一行!
复制master上的Hadoop到slave节点(只在master做)
通过复制master节点上的hadoop,能够大大提高系统部署效率,假设我们有200台需要配置…笔者岂不白头
由于我这里有slave0和slave1,所以复制两次。
复制命令:
scp -r /opt/hadoop root@slave0:/opt
scp -r /opt/hadoop root@slave1:/optHadoop集群的启动-配置操作系统环境变量(三个节点都做)
回到用户目录命令:
cd /opt/hadoop然后用vi编辑.bash_profile文件,命令:
vi ~/.bash_profile最后把以下代码追加到文件的尾部:
#HADOOP
export HADOOP_HOME=/opt/hadoop/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH保存退出后,执行命令:
source ~/.bash_profilesource ~/.bash_profile命令是使上述配置生效
提示:在slave0和slave1使用上述相同的配置方法,进行三个节点全部配置。
创建Hadoop数据目录(只在master做)
创建数据目录,命令是:
mkdir /opt/hadoop/hadoopdata通过Xftp可查看该hadoopdata
格式化文件系统(只在master做)
执行格式化文件系统命令:
hadoop namenode -format启动和关闭Hadoop集群(只在master做)
首先进入安装主目录,命令是:
cd /opt/hadoop/hadoop/sbin提示:目前文件位置可在Xshell顶部栏观察
然后启动,命令是:
start-all.sh执行命令后,系统提示 ” Are you sure want to continue connecting(yes/no)”,输入yes,之后系统即可启动。
注意:可能会有些慢,千万不要以为卡掉了,然后强制关机,这是错误的。
如果要关闭Hadoop集群,可以使用命令:
stop-all.sh下次启动Hadoop时,无须NameNode的初始化,只需要使用start-dfs.sh命令即可,然后接着使用start-yarn.sh启动Yarn。
实际上,Hadoop建议放弃(deprecated)使用start-all.sh和stop-all.sh一类的命令,而改用start-dfs.sh和start-yarn.sh命令。
验证Hadoop集群是否启动成功
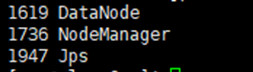
读者您可以在终端执行jps命令查看Hadoop是否启动成功。
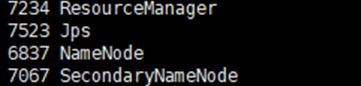
在master节点,执行:
jps如果显示:SecondaryNameNode、 ResourceManager、 Jps 和NameNode这四个进程,则表明主节点master启动成功
然后分别在slave0和slave1节点下执行命令:
jps如果成功显示:NodeManager、Jps 和 DataNode,这三个进程,则表明从节点(slave0和slave1)启动成功
4.评估华为hadoop发行版本的特点与可用性。
特点:
华为FusionInsight HD发行版紧随开源社区的最新技术,快速集成最新组件,并在可靠性、安全性、管理性等方面做企业级的增强,持续改进,持续保持技术领先。
FusionInsight HD的企业级增强主要表现在以下几个方面。
安全
- 架构安全
FusionInsight HD基于开源组件实现功能增强,保持100%的开放性,不使用私有架构和组件。
- 认证安全
- 基于用户和角色的认证统一体系,遵从帐户/角色RBAC(Role-Based Access Control)模型,实现通过角色进行权限管理,对用户进行批量授权管理。
- 支持安全协议Kerberos,FusionInsight HD使用LDAP作为帐户管理系统,并通过Kerberos对帐户信息进行安全认证。
- 提供单点登录,统一了Manager系统用户和组件用户的管理及认证。
- 对登录FusionInsight Manager的用户进行审计。
- 文件系统层加密
Hive、HBase可以对表、字段加密,集群内部用户信息禁止明文存储。
- 加密灵活:加密算法插件化,可进行扩充,亦可自行开发。非敏感数据可不加密,不影响性能(加密约有5%性能开销)。
- 业务透明:上层业务只需指定敏感数据(Hive表级、HBase列族级加密),加解密过程业务完全不感知。
可靠
- 所有管理节点组件均实现HA(High Availability)
业界第一个实现所有组件HA的产品,确保数据的可靠性、一致性。NameNode、Hive Server、HMaster、Resources Manager等管理节点均实现HA。
- 集群异地灾备
业界第一个支持超过1000公里异地容灾的大数据平台,为日志详单类存储提供了迄今为止可靠性最佳实践。
- 数据备份恢复
表级别全量备份、增量备份,数据恢复(对本地存储的业务数据进行完整性校验,在发现数据遭破坏或丢失时进行自恢复)。
易用
- 统一运维管理
Manager作为FusionInsight HD的运维管理系统,提供界面化的统一安装、告警、监控和集群管理。
- 易集成
提供北向接口,实现与企业现有网管系统集成;当前支持Syslog接口,接口消息可通过配置适配现有系统;整个集群采用统一的集中管理,未来北向接口可根据需求灵活扩展。
- 易开发
提供自动化的二次开发助手和开发样例,帮助软件开发人员快速上手。
可用性:金融领域,运营商领域。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号