

03>>>朴素贝叶斯模型、SVM模型、K均值聚类、DBSCAN(密度)聚类、GBDT模型
朴素贝叶斯模型
朴素贝叶斯模型思想和理论
该分类器的实现思想非常简单,即通过已知类别的训练数据集,计算样本的先验概率,然后利用贝叶斯概率公式测算未知类别样本属于某个类别的后验概率,最终以最大后验概率所对应的类别作为样本的预测值。
精简版理解:先利用已知数据测算出已知数据的概率(先验概率),然后根据已知数据概率推测出未知数据的概率(后验概率)。
朴素贝叶斯模型的分类
1.高斯贝叶斯分类器

适用于自变量为连续数值类型的情况。
例题:

思路
1.计算总概率
2.依据年龄和收入分别计算出不放贷和放贷的均值
3.依据年龄和收入分别计算出不放贷和放贷的标准差
4.依据年龄和收入分别计算出不放贷和放贷的概率
5.将不放贷和放贷的概率分别相乘,最终得出的便是金融公司决定给客户放贷的最终概率

2.多项式贝叶斯分类器(h4)

适用于自变量为离散型数据(非数据类型)类型的情况。
例题

思路
1.计算总概率
2.分别计算出岗位是公务员、学历是硕士、收入为高的条件下相亲与否的概率
3.将这三者相乘可得出硕士学历高收入公务员的相亲与否概率

3.伯努利贝叶斯分类器

适用于自变量为01二元值的情况。
例题
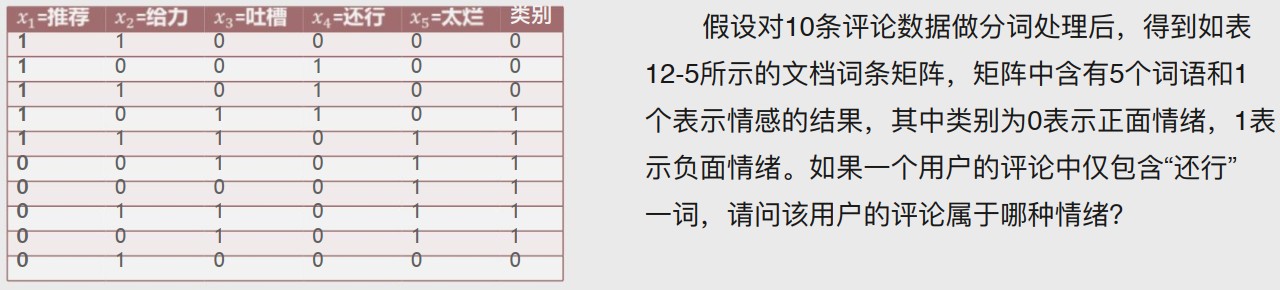
思路
1.计算总概率
2.将每个x和两种类别分别相除,得出十种情况的概率
3.将类别为0和1的情况的概率分别相乘,得到两种类别(即正负面情绪)的概率

补充一点:分类器的选择与实际遇到的问题之间并非必然联系,这里只是推荐特定问题使用特定解法,因为更简便。
朴素贝叶斯模型实战案例
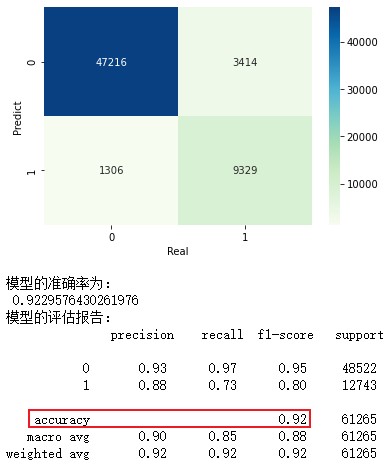
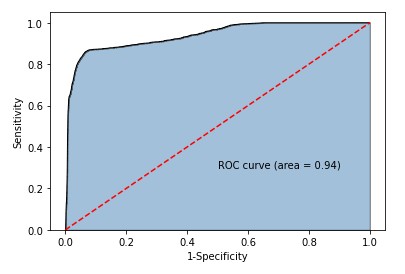
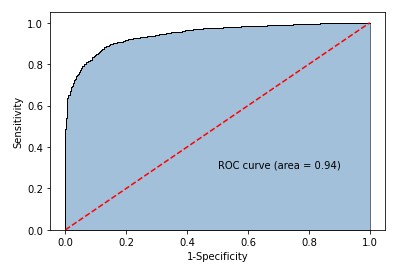
1.皮肤识别——高斯贝叶斯分类器


# 导入第三方包 import pandas as pd # 读入数据 skin = pd.read_excel(r'Skin_Segment.xlsx') # 设置正例和负例 skin.y = skin.y.map({2:0,1:1}) # 设置一个映射关系,将2映射成0 skin.y.value_counts() # 查看末尾20行数据 skin.tail(20) # 导入第三方模块 from sklearn import model_selection # 样本拆分 X_train,X_test,y_train,y_test = model_selection.train_test_split(skin.iloc[:,:3], skin.y, test_size = 0.25, random_state=1234) # 导入第三方模块 from sklearn import naive_bayes # 调用高斯朴素贝叶斯分类器的“类” gnb = naive_bayes.GaussianNB() # 模型拟合 gnb.fit(X_train, y_train) # 模型在测试数据集上的预测 gnb_pred = gnb.predict(X_test) # 各类别的预测数量 pd.Series(gnb_pred).value_counts() # 导入第三方包 from sklearn import metrics import matplotlib.pyplot as plt import seaborn as sns # 构建混淆矩阵 cm = pd.crosstab(gnb_pred,y_test) # 绘制混淆矩阵图 sns.heatmap(cm, annot = True, cmap = 'GnBu', fmt = 'd') # 去除x轴和y轴标签 plt.xlabel('Real') plt.ylabel('Predict') # 显示图形 plt.show() print('模型的准确率为:\n',metrics.accuracy_score(y_test, gnb_pred)) print('模型的评估报告:\n',metrics.classification_report(y_test, gnb_pred)) 10.皮肤识别 混淆矩阵和准确率 # 计算正例的预测概率,用于生成ROC曲线的数据 y_score = gnb.predict_proba(X_test)[:,1] fpr,tpr,threshold = metrics.roc_curve(y_test, y_score) # 计算AUC的值 roc_auc = metrics.auc(fpr,tpr) # 绘制面积图 plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black') # 添加边际线 plt.plot(fpr, tpr, color='black', lw = 1) # 添加对角线 plt.plot([0,1],[0,1], color = 'red', linestyle = '--') # 添加文本信息 plt.text(0.5,0.3,'ROC curve (area = %0.2f)' % roc_auc) # 添加x轴与y轴标签 plt.xlabel('1-Specificity') plt.ylabel('Sensitivity') # 显示图形 plt.show()
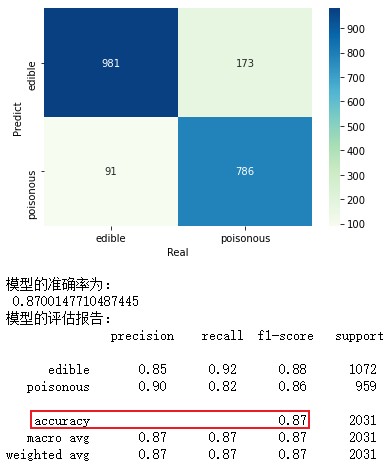
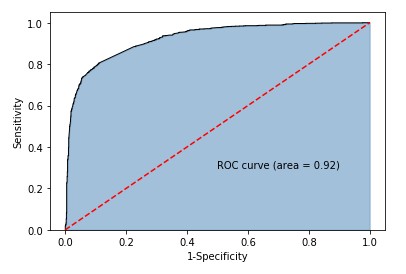
2.毒蘑菇识别——多项式贝叶斯分类器
# 导入第三方包 import pandas as pd # 读取数据 mushrooms = pd.read_csv(r'mushrooms.csv') # 数据的前5行 mushrooms.head() ################################################################## # 将字符型数据作因子化处理,将其转换为整数型数据(类似于哑变量,但有区别) columns = mushrooms.columns[1:] for column in columns: mushrooms[column] = pd.factorize(mushrooms[column])[0] mushrooms.head() ################################################################## from sklearn import model_selection # 将数据集拆分为训练集合测试集 Predictors = mushrooms.columns[1:] X_train,X_test,y_train,y_test = model_selection.train_test_split(mushrooms[Predictors], mushrooms['type'], test_size = 0.25, random_state = 10) from sklearn import naive_bayes from sklearn import metrics import seaborn as sns import matplotlib.pyplot as plt # 构建多项式贝叶斯分类器的“类” mnb = naive_bayes.MultinomialNB() # 基于训练数据集的拟合 mnb.fit(X_train, y_train) # 基于测试数据集的预测 mnb_pred = mnb.predict(X_test) # 构建混淆矩阵 cm = pd.crosstab(mnb_pred,y_test) # 绘制混淆矩阵图 sns.heatmap(cm, annot = True, cmap = 'GnBu', fmt = 'd') # 去除x轴和y轴标签 plt.xlabel('Real') plt.ylabel('Predict') # 显示图形 plt.show() # 模型的预测准确率 print('模型的准确率为:\n',metrics.accuracy_score(y_test, mnb_pred)) print('模型的评估报告:\n',metrics.classification_report(y_test, mnb_pred)) from sklearn import metrics # 计算正例的预测概率,用于生成ROC曲线的数据 y_score = mnb.predict_proba(X_test)[:,1] fpr,tpr,threshold = metrics.roc_curve(y_test.map({'edible':0,'poisonous':1}), y_score) # 计算AUC的值 roc_auc = metrics.auc(fpr,tpr) # 绘制面积图 plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black') # 添加边际线 plt.plot(fpr, tpr, color='black', lw = 1) # 添加对角线 plt.plot([0,1],[0,1], color = 'red', linestyle = '--') # 添加文本信息 plt.text(0.5,0.3,'ROC curve (area = %0.2f)' % roc_auc) # 添加x轴与y轴标签 plt.xlabel('1-Specificity') plt.ylabel('Sensitivity') # 显示图形 plt.show()
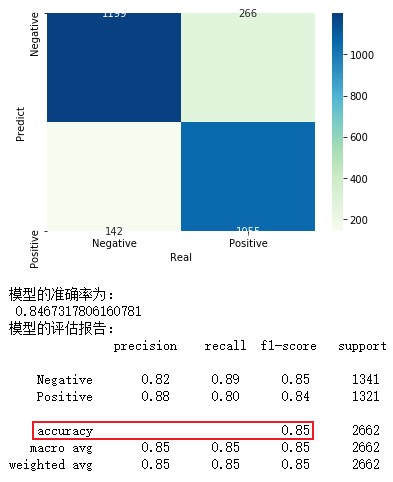
3.产品用户评价分析——伯努利贝叶斯分类器
import pandas as pd # 读入评论数据 evaluation = pd.read_excel(r'Contents.xlsx',sheet_name=0) # 查看数据前10行 evaluation.head(10) # 运用正则表达式,将评论中的数字和英文去除 evaluation.Content = evaluation.Content.str.replace('[0-9a-zA-Z]','') evaluation.head() # 导入结巴分词模块分隔语句 # !pip3 install jieba !pip install jieba # 导入第三方包 import jieba # 加载自定义词库 jieba.load_userdict(r'all_words.txt') # 读入停止词 with open(r'mystopwords.txt', encoding='UTF-8') as words: stop_words = [i.strip() for i in words.readlines()] # 构造切词的自定义函数,并在切词过程中删除停止词 def cut_word(sentence): words = [i for i in jieba.lcut(sentence) if i not in stop_words] # 切完的词用空格隔开 result = ' '.join(words) return(result) # 对评论内容进行批量切词 words = evaluation.Content.apply(cut_word) # 前5行内容的切词效果 words[:5] # 导入第三方包 from sklearn.feature_extraction.text import CountVectorizer # 计算每个词在各评论内容中的次数,并将稀疏度为99%以上的词删除 counts = CountVectorizer(min_df = 0.01) # 文档词条矩阵 dtm_counts = counts.fit_transform(words).toarray() # 矩阵的列名称 columns = counts.get_feature_names() # 将矩阵转换为数据框--即X变量 X = pd.DataFrame(dtm_counts, columns=columns) # 情感标签变量 y = evaluation.Type X.head() from sklearn import model_selection from sklearn import naive_bayes from sklearn import metrics import matplotlib.pyplot as plt import seaborn as sns # 将数据集拆分为训练集和测试集 X_train,X_test,y_train,y_test = model_selection.train_test_split(X,y,test_size = 0.25, random_state=1) # 构建伯努利贝叶斯分类器 bnb = naive_bayes.BernoulliNB() # 模型在训练数据集上的拟合 bnb.fit(X_train,y_train) # 模型在测试数据集上的预测 bnb_pred = bnb.predict(X_test) # 构建混淆矩阵 cm = pd.crosstab(bnb_pred,y_test) # 绘制混淆矩阵图 sns.heatmap(cm, annot = True, cmap = 'GnBu', fmt = 'd') # 去除x轴和y轴标签 plt.xlabel('Real') plt.ylabel('Predict') # 显示图形 plt.show() # 模型的预测准确率 print('模型的准确率为:\n',metrics.accuracy_score(y_test, bnb_pred)) print('模型的评估报告:\n',metrics.classification_report(y_test, bnb_pred)) # 计算正例Positive所对应的概率,用于生成ROC曲线的数据 y_score = bnb.predict_proba(X_test)[:,1] fpr,tpr,threshold = metrics.roc_curve(y_test.map({'Negative':0,'Positive':1}), y_score) # 计算AUC的值 roc_auc = metrics.auc(fpr,tpr) # 绘制面积图 plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black') # 添加边际线 plt.plot(fpr, tpr, color='black', lw = 1) # 添加对角线 plt.plot([0,1],[0,1], color = 'red', linestyle = '--') # 添加文本信息 plt.text(0.5,0.3,'ROC curve (area = %0.2f)' % roc_auc) # 添加x轴与y轴标签 plt.xlabel('1-Specificity') plt.ylabel('Sensitivity') # 显示图形 plt.show()
SVM模型
SVM模型主要用于解决分类问题。
SVM模型的思想和理论
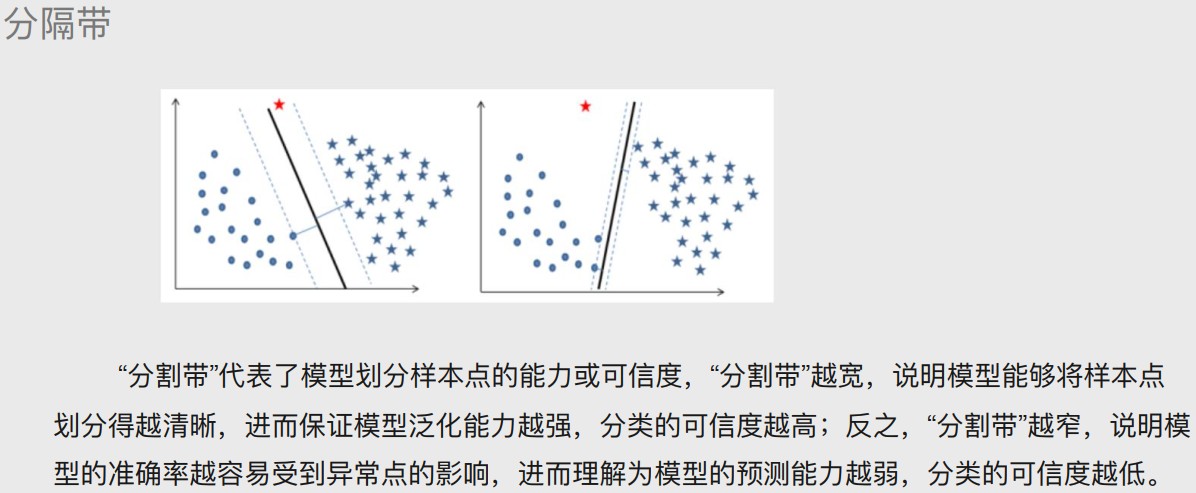
超平面的概念
将样本点划分成不同的类别(三种表现形式:点、线、面)。
超平面最优解
1.先随机选一条直线li。
2.分别计算两边距离该直线最短点的距离d1和d2,取更小的。
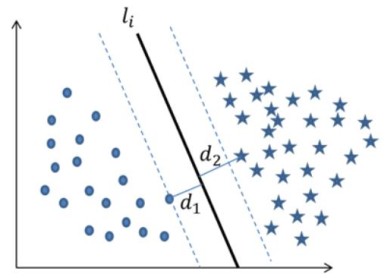
3.以该距离在左右两边做分隔带。
4.依次执行上述三个步骤得出N多个分隔带,最优的就是分隔带最宽的。
SVM模型函数
LinearSVC(tol=0.0001, C=1.0, multi_class='ovr', fit_intercept=True, intercept_scaling=1, class_weight=None, max_iter=1000)
常用参数
tol:用于指定SVM模型迭代的收敛条件,默认为0.0001。
C:用于指定目标函数中松弛因子的惩罚系数值,默认为1。
fit_intercept:bool类型参数,是否拟合线性“超平面”的截距项,默认为True。
intercept_scaling:当参数fit_intercept为True时,该参数有效,通过给参数传递一个浮点值,就相当于在自变量X矩阵中添加以常数列,默认该参数值为1。
class_weight:用于指定因变量类别的权重,如果为字典,则通过字典的形式{class_label:weight}传递每个类别的权重;如果为字符串'balanced',则每个分类的权重余实际样本中的比例成反比,当各分类存在严重不平衡时,设置为'balanced'会比较好;如果为None,则表示每个分类的权重相等。
max_iter:指定模型求解过程中的最大迭代次数,默认为1000。
线性可分与非线性可分
线性可分:一条直线分隔开类别。
非线性可分:一条直线无法直接分隔,需要抬升一个维度再做划分。
核函数

-
线性核函数
-
多项式核函数
-
高斯核函数
-
Sigmoid核函数
多数情况下可以选用高斯核函数,支持无穷维。
核函数介绍
SVC(C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0, tol=0.001, class_weight=None, verbose=False, max_iter=-1, random_state=None)
常用参数
C:用于指定目标函数中松弛因子的惩罚系数值,默认为1。 kernel:用于指定SVM模型的核函数,该参数如果为'linear',就表示线性和函数;如果为'poly',就表示多项式核函数,和函数中的r和p值分别使用degree参数和gamma参数指定;如果为'rbf',表示径向基核函数,核函数中的r参数值仍然通过gamma参数指定;如果为'sigmoid',表示Sigmoid核函数,核函数中的r参数值需要通过gamma参数指定;如果为'precomputed',表示计算一个核矩阵。 degree:用于指定多项式核函数中的p参数值。 gamma:用于指定多项式核函数或径向基核函数或Sigmoid核函数中的r参数值。 coef0:用于指定多项式核函数或Sigmoid和函数中的r参数值。 tol:用于指定SVM模型迭代的收敛条件,默认为0.001。 class_weight:用于指定因变量类别的权重,如果为字典,则通过字典的形式{class_label:weight}传递每个类别的权重;如果为字符串'balanced',则每个分类的权重与实际样本中的比例成反比,当各分类存在严重不平衡时,设置为'balanced'会比较好;如果为None,则表示每个分类的权重相等。 max_iter:指定模型求解过程中的最大迭代次数,默认为-1,表示不限制迭代次数。
SVM模型实战
手写体字母识别
# 导入第三方模块 from sklearn import svm import pandas as pd from sklearn import model_selection from sklearn import metrics # 读取外部数据 letters = pd.read_csv(r'letterdata.csv') # 数据前5行 letters.head() # 将数据拆分为训练集和测试集 predictors = letters.columns[1:] X_train,X_test,y_train,y_test = model_selection.train_test_split(letters[predictors], letters.letter, test_size = 0.25, random_state = 1234) # 选择线性可分SVM模型 linear_svc = svm.LinearSVC() # 模型在训练数据集上的拟合 linear_svc.fit(X_train,y_train) # 模型在测试集上的预测 pred_linear_svc = linear_svc.predict(X_test) # 模型的预测准确率 metrics.accuracy_score(y_test, pred_linear_svc) # 选择非线性SVM模型 nolinear_svc = svm.SVC(kernel='rbf') # 模型在训练数据集上的拟合 nolinear_svc.fit(X_train,y_train) # 模型在测试集上的预测 pred_svc = nolinear_svc.predict(X_test) # 模型的预测准确率 metrics.accuracy_score(y_test,pred_svc)
森林火灾烧毁面积预测
# 读取外部数据 forestfires = pd.read_csv(r'forestfires.csv') # 数据前5行 forestfires.head() # 删除day变量 forestfires.drop('day',axis = 1, inplace = True) # 将月份作数值化处理 forestfires.month = pd.factorize(forestfires.month)[0] # 预览数据前5行 forestfires.head() # 导入第三方模块 import seaborn as sns import matplotlib.pyplot as plt from scipy.stats import norm # 绘制森林烧毁面积的直方图 sns.distplot(forestfires.area, bins = 50, kde = True, fit = norm, hist_kws = {'color':'steelblue'}, kde_kws = {'color':'red', 'label':'Kernel Density'}, fit_kws = {'color':'black','label':'Nomal', 'linestyle':'--'}) # 显示图例 plt.legend() # 显示图形 plt.show() # 导入第三方模块 from sklearn import preprocessing import numpy as np from sklearn import neighbors # 对area变量作对数变换 y = np.log1p(forestfires.area) # 将X变量作标准化处理 predictors = forestfires.columns[:-1] X = preprocessing.scale(forestfires[predictors]) # 将数据拆分为训练集和测试集 X_train,X_test,y_train,y_test = model_selection.train_test_split(X, y, test_size = 0.25, random_state = 1234) # 构建默认参数的SVM回归模型 svr = svm.SVR() # 模型在训练数据集上的拟合 svr.fit(X_train,y_train) # 模型在测试上的预测 pred_svr = svr.predict(X_test) # 计算模型的MSE metrics.mean_squared_error(y_test,pred_svr) # 使用网格搜索法,选择SVM回归中的最佳C值、epsilon值和gamma值 epsilon = np.arange(0.1,1.5,0.2) C= np.arange(100,1000,200) gamma = np.arange(0.001,0.01,0.002) parameters = {'epsilon':epsilon,'C':C,'gamma':gamma} grid_svr = model_selection.GridSearchCV(estimator = svm.SVR(max_iter=10000),param_grid =parameters, scoring='neg_mean_squared_error',cv=5,verbose =1, n_jobs=2) # 模型在训练数据集上的拟合 grid_svr.fit(X_train,y_train) # 返回交叉验证后的最佳参数值 print(grid_svr.best_params_, grid_svr.best_score_) # 模型在测试集上的预测 pred_grid_svr = grid_svr.predict(X_test) # 计算模型在测试集上的MSE值 metrics.mean_squared_error(y_test,pred_grid_svr)
K均值聚类

有监督学习与无监督学习
有监督学习:有明确需要研究的因变量Y。
无监督学习:没有明确需要研究的因变量Y(典型:聚类算法)。
聚类步骤
1.从数据中随机挑选k个样本点作为原始的簇中心。
2.计算剩余样本与簇中心的距离,并把各样本标记为离k个簇中心最近的类别。
3.重新计算各簇中样本点的均值,并以均值作为新的k个簇中心。
4.不断重复第二步和第三步,知道簇中心的变化趋于稳定,形成最终的k个簇。
在K均值聚类模型中,对于指定的k个簇,只有簇内样本越相似,聚类效果才越好(例如做不同人种间的比较,应当保持黑种人一组、白种人一组、黄种人一组)。
K值的求解
K表示分成几类。
1.拐点法
计算不同K值下簇内的离差平方和,找到拐点,拐点对应的值是最佳的K值(看斜率,变化越明显越好)。
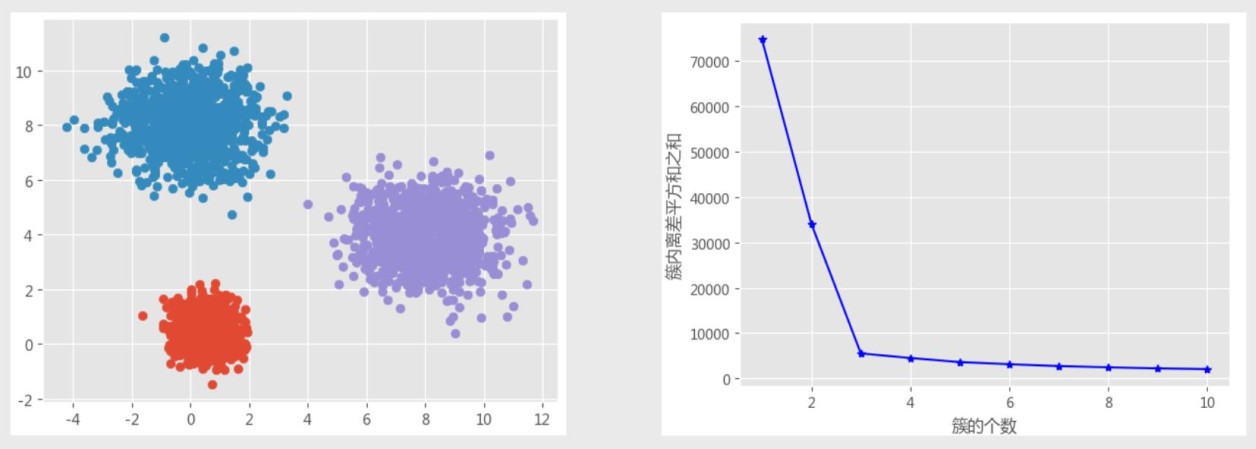
如图所示,簇的个数在为3时折线发生了明显的变化,故k值取3最合适。
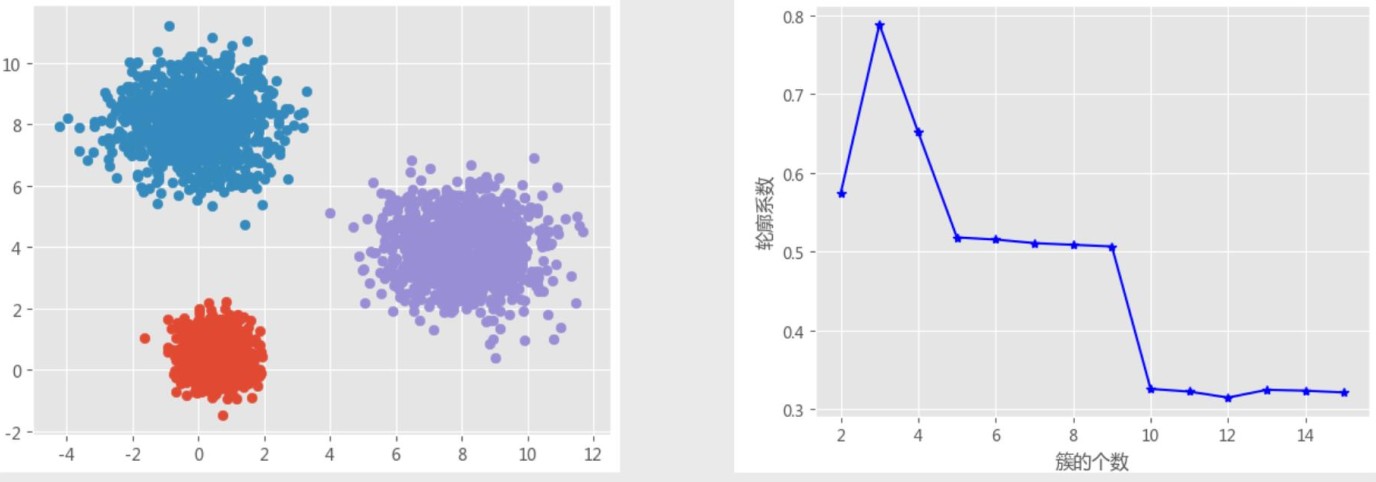
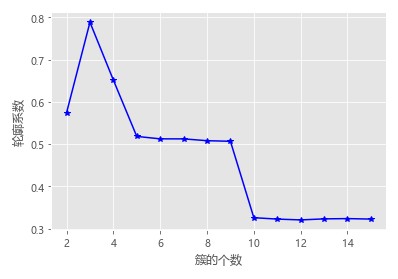
2.轮廓系数法
计算轮廓系数(看系数大小,越大越好)。
K均值聚类函数
KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001)
常用参数
n_clusters:用于指定聚类的簇数。 init:用于指定初始的簇中心设置方法,如果为'k-means++',则表示设置的初始簇中心之间相距较远;如果为'random',则表示从数据集中随机挑选k个样本作为初始簇中心;如果为数组,则表示用户指定具体的簇中心。 n_init:用于指定K均值算法运行的次数,每次运行时都会选择不同的初始簇中心,目的是防止算法收敛于局部最优,默认为10。 max_iter:用于指定单次运行的迭代次数,默认为300。 tol:用于指定算法收敛的阈值,默认为0.0001。
K均值聚类实战
NBA球员聚类
# 导入第三方包 import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn import metrics # 随机生成三组二元正态分布随机数 np.random.seed(1234) mean1 = [0.5, 0.5] cov1 = [[0.3, 0], [0, 0.3]] x1, y1 = np.random.multivariate_normal(mean1, cov1, 1000).T mean2 = [0, 8] cov2 = [[1.5, 0], [0, 1]] x2, y2 = np.random.multivariate_normal(mean2, cov2, 1000).T mean3 = [8, 4] cov3 = [[1.5, 0], [0, 1]] x3, y3 = np.random.multivariate_normal(mean3, cov3, 1000).T # 绘制三组数据的散点图 plt.scatter(x1,y1) plt.scatter(x2,y2) plt.scatter(x3,y3) # 显示图形 plt.show() # 构造自定义函数,用于绘制不同k值和对应总的簇内离差平方和的折线图 def k_SSE(X, clusters): # 选择连续的K种不同的值 K = range(1,clusters+1) # 构建空列表用于存储总的簇内离差平方和 TSSE = [] for k in K: # 用于存储各个簇内离差平方和 SSE = [] kmeans = KMeans(n_clusters=k) kmeans.fit(X) # 返回簇标签 labels = kmeans.labels_ # 返回簇中心 centers = kmeans.cluster_centers_ # 计算各簇样本的离差平方和,并保存到列表中 for label in set(labels): SSE.append(np.sum((X.loc[labels == label,]-centers[label,:])**2)) # 计算总的簇内离差平方和 TSSE.append(np.sum(SSE)) # 中文和负号的正常显示 plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.rcParams['axes.unicode_minus'] = False # 设置绘图风格 plt.style.use('ggplot') # 绘制K的个数与GSSE的关系 plt.plot(K, TSSE, 'b*-') plt.xlabel('簇的个数') plt.ylabel('簇内离差平方和之和') # 显示图形 plt.show() # 将三组数据集汇总到数据框中 X = pd.DataFrame(np.concatenate([np.array([x1,y1]),np.array([x2,y2]),np.array([x3,y3])], axis = 1).T) # 自定义函数的调用 k_SSE(X, 15) # 构造自定义函数,用于绘制不同k值和对应轮廓系数的折线图 def k_silhouette(X, clusters): K = range(2,clusters+1) # 构建空列表,用于存储个中簇数下的轮廓系数 S = [] for k in K: kmeans = KMeans(n_clusters=k) kmeans.fit(X) labels = kmeans.labels_ # 调用字模块metrics中的silhouette_score函数,计算轮廓系数 S.append(metrics.silhouette_score(X, labels, metric='euclidean')) # 中文和负号的正常显示 plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.rcParams['axes.unicode_minus'] = False # 设置绘图风格 plt.style.use('ggplot') # 绘制K的个数与轮廓系数的关系 plt.plot(K, S, 'b*-') plt.xlabel('簇的个数') plt.ylabel('轮廓系数') # 显示图形 plt.show() # 自定义函数的调用 k_silhouette(X, 15)
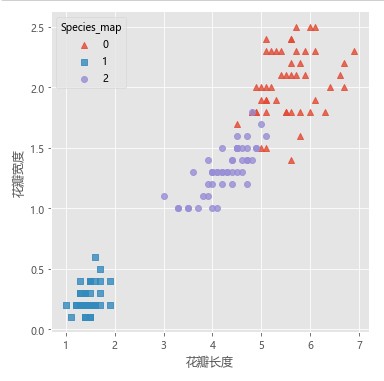
鸢尾花花瓣数据
# 读取iris数据集 iris = pd.read_csv(r'iris.csv') # 查看数据集的前几行 iris.head() # 提取出用于建模的数据集X X = iris.drop(labels = 'Species', axis = 1) # 构建Kmeans模型 kmeans = KMeans(n_clusters = 3) kmeans.fit(X) # 聚类结果标签 X['cluster'] = kmeans.labels_ # 各类频数统计 X.cluster.value_counts() # 导入第三方模块 import seaborn as sns # 三个簇的簇中心 centers = kmeans.cluster_centers_ # 绘制聚类效果的散点图 sns.lmplot(x = 'Petal_Length', y = 'Petal_Width', hue = 'cluster', markers = ['^','s','o'], data = X, fit_reg = False, scatter_kws = {'alpha':0.8}, legend_out = False) plt.scatter(centers[:,2], centers[:,3], marker = '*', color = 'black', s = 130) plt.xlabel('花瓣长度') plt.ylabel('花瓣宽度') # 图形显示 plt.show() # 增加一个辅助列,将不同的花种映射到0,1,2三种值,目的方便后面图形的对比 iris['Species_map'] = iris.Species.map({'virginica':0,'setosa':1,'versicolor':2}) # 绘制原始数据三个类别的散点图 sns.lmplot(x = 'Petal_Length', y = 'Petal_Width', hue = 'Species_map', data = iris, markers = ['^','s','o'], fit_reg = False, scatter_kws = {'alpha':0.8}, legend_out = False) plt.xlabel('花瓣长度') plt.ylabel('花瓣宽度') # 图形显示 plt.show()
NBA球员命中率数据
# 读取球员数据 players = pd.read_csv(r'players.csv') players.head() # 绘制得分与命中率的散点图 sns.lmplot(x = '得分', y = '命中率', data = players, fit_reg = False, scatter_kws = {'alpha':0.8, 'color': 'steelblue'}) plt.show() from sklearn import preprocessing # 数据标准化处理 X = preprocessing.minmax_scale(players[['得分','罚球命中率','命中率','三分命中率']]) # 将数组转换为数据框 X = pd.DataFrame(X, columns=['得分','罚球命中率','命中率','三分命中率']) # 使用拐点法选择最佳的K值 k_SSE(X, 15) # 使用轮廓系数选择最佳的K值 k_silhouette(X, 10) # 将球员数据集聚为3类 kmeans = KMeans(n_clusters = 3) kmeans.fit(X) # 将聚类结果标签插入到数据集players中 players['cluster'] = kmeans.labels_ # 构建空列表,用于存储三个簇的簇中心 centers = [] for i in players.cluster.unique(): centers.append(players.ix[players.cluster == i,['得分','罚球命中率','命中率','三分命中率']].mean()) # 将列表转换为数组,便于后面的索引取数 centers = np.array(centers) # 绘制散点图 sns.lmplot(x = '得分', y = '命中率', hue = 'cluster', data = players, markers = ['^','s','o'], fit_reg = False, scatter_kws = {'alpha':0.8}, legend = False) # 添加簇中心 plt.scatter(centers[:,0], centers[:,2], c='k', marker = '*', s = 180) plt.xlabel('得分') plt.ylabel('命中率') # 图形显示 plt.show()
K均值聚类的缺点
1.聚类效果容易受到异常样本点的影响。
2.无法准确地将非球形样本进行合理的聚类。
解决方案:可以采用密度聚类。
DBSCAN(密度)聚类
密度聚类的概念
核心对象:内部含有大于等于最少样本点的样本。
非核心对象:内部少于最少样本点的样本。
直接密度可达:在核心对象内部的样本点到核心对象的距离。(可类比为一条地铁线上的直达站点)

密度可达:多个直接密度可达连接了多个核心对象,首尾点叫密度可达。(可类比为不同地铁线的换乘站点)

密度相连:两边的点由中间的核心对象分别密度可达。(可类比为远途飞行的转机站点)

密度聚类的过程
1.为密度聚类算法设置一个合理的半径ε以及ε领域内所包含的最少样本量MinPts。
2.从数据集中随机挑选一个样本点p,检验其在ε领域内是否包含指定的最少样本量,如果包含就将其定性为核心对象,并构成一个簇C;否则,重新挑选一个样本点。
3.对于核心对象p所覆盖的其它样本点q,如果点q对应的ε领域内仍然包含最少样本量MinPts,就将其覆盖的样本点统统归于簇C。
4.重复3,将最大的密度相连所包含的样本点聚为一类,形成一个大簇。
5.完成4后,重新回到2,并重复3和4,直到没有新的样本点可以生成新簇时算法结束。
算法
算法就是研究问题的解决方法,算法工程师就是在研究解决某问题的最优解。
密度聚类函数
cluster.DBSCAN(eps=0.5, min_sample=5, metric='euclidean', p=None)
常用参数
eps:用于设置密度聚类中的e领域,即半径,默认为0.5。 min_samples:用于设置e领域内最少的样本量,默认为5。 metric:用于指定计算点之间的距离的方法,默认为欧氏距离。 p:当参数metric为闵可夫斯基('minkowski')距离时,p=1,表示计算点之间的曼哈顿距离;p=2,表示计算点之间的欧氏距离;该参数的默认值为2。

密度聚类会将异常点排除出簇外,所以一定程度上来说密度聚类比K均值聚类更精确些。
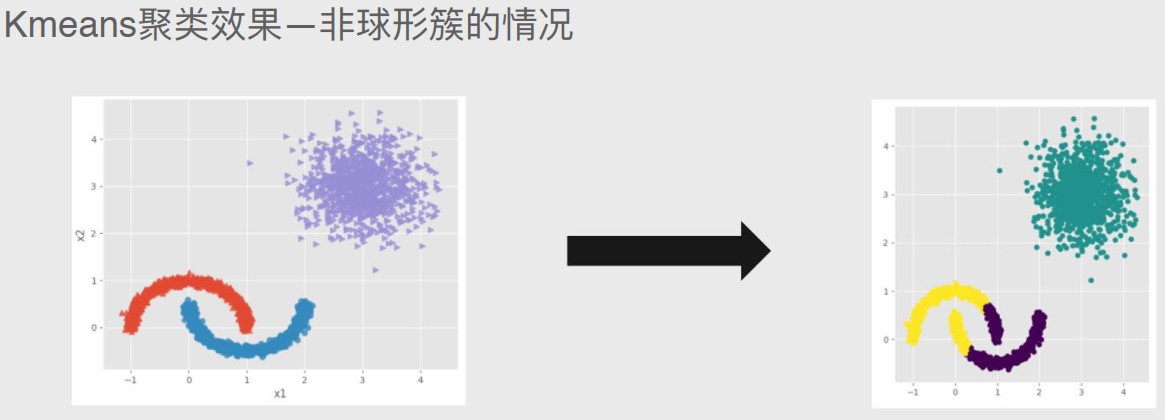
使用K均值聚类处理上图的数据分布时,会强行将两条曲线分割为两部分。
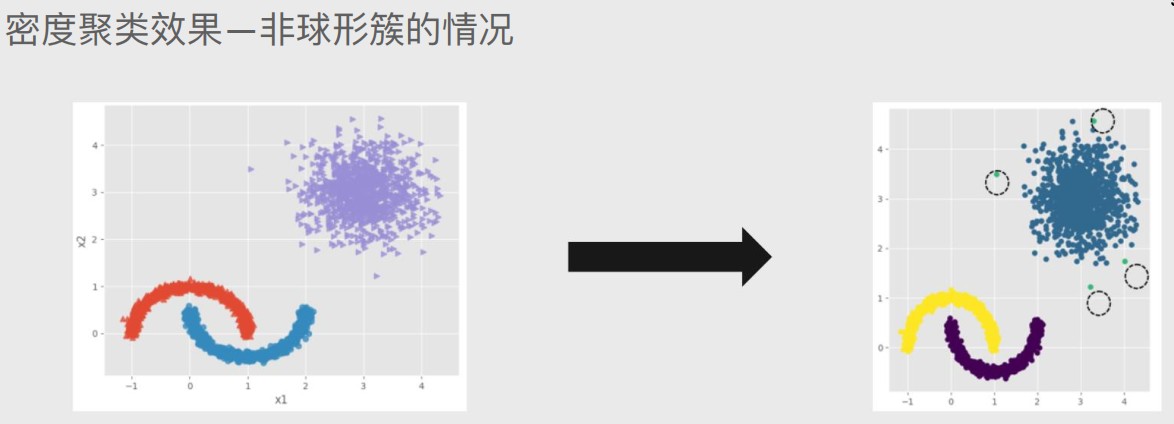
用密度聚类处理同一个项目时,曲线保持了整理性,两种情况都泾渭分明地分开来了,而右上方圈出来的青色小店也被判定为异常点。
DBSCAN密度聚类实战
# 导入第三方模块 import pandas as pd import numpy as np from sklearn.datasets.samples_generator import make_blobs import matplotlib.pyplot as plt import seaborn as sns from sklearn import cluster # 模拟数据集 X,y = make_blobs(n_samples = 2000, centers = [[-1,-2],[1,3]], cluster_std = [0.5,0.5], random_state = 1234) # 将模拟得到的数组转换为数据框,用于绘图 plot_data = pd.DataFrame(np.column_stack((X,y)), columns = ['x1','x2','y']) # 设置绘图风格 plt.style.use('ggplot') # 绘制散点图(用不同的形状代表不同的簇) sns.lmplot('x1', 'x2', data = plot_data, hue = 'y',markers = ['^','o'], fit_reg = False, legend = False) # 显示图形 plt.show() # 导入第三方模块 from sklearn import cluster # 构建Kmeans聚类和密度聚类 kmeans = cluster.KMeans(n_clusters=2, random_state=1234) kmeans.fit(X) dbscan = cluster.DBSCAN(eps = 0.5, min_samples = 10) dbscan.fit(X) # 将Kmeans聚类和密度聚类的簇标签添加到数据框中 plot_data['kmeans_label'] = kmeans.labels_ plot_data['dbscan_label'] = dbscan.labels_ # 绘制聚类效果图 # 设置大图框的长和高 plt.figure(figsize = (12,6)) # 设置第一个子图的布局 ax1 = plt.subplot2grid(shape = (1,2), loc = (0,0)) # 绘制散点图 ax1.scatter(plot_data.x1, plot_data.x2, c = plot_data.kmeans_label) # 设置第二个子图的布局 ax2 = plt.subplot2grid(shape = (1,2), loc = (0,1)) # 绘制散点图(为了使Kmeans聚类和密度聚类的效果图颜色一致,通过序列的map“方法”对颜色作重映射) ax2.scatter(plot_data.x1, plot_data.x2, c=plot_data.dbscan_label.map({-1:1,0:2,1:0})) # 显示图形 plt.show() # 导入第三方模块 from sklearn.datasets.samples_generator import make_moons # 构造非球形样本点 X1,y1 = make_moons(n_samples=2000, noise = 0.05, random_state = 1234) # 构造球形样本点 X2,y2 = make_blobs(n_samples=1000, centers = [[3,3]], cluster_std = 0.5, random_state = 1234) # 将y2的值替换为2(为了避免与y1的值冲突,因为原始y1和y2中都有0这个值) y2 = np.where(y2 == 0,2,0) # 将模拟得到的数组转换为数据框,用于绘图 plot_data = pd.DataFrame(np.row_stack([np.column_stack((X1,y1)),np.column_stack((X2,y2))]), columns = ['x1','x2','y']) # 绘制散点图(用不同的形状代表不同的簇) sns.lmplot('x1', 'x2', data = plot_data, hue = 'y',markers = ['^','o','>'], fit_reg = False, legend = False) # 显示图形 plt.show() # 构建Kmeans聚类和密度聚类 kmeans = cluster.KMeans(n_clusters=3, random_state=1234) kmeans.fit(plot_data[['x1','x2']]) dbscan = cluster.DBSCAN(eps = 0.3, min_samples = 5) dbscan.fit(plot_data[['x1','x2']]) # 将Kmeans聚类和密度聚类的簇标签添加到数据框中 plot_data['kmeans_label'] = kmeans.labels_ plot_data['dbscan_label'] = dbscan.labels_ # 绘制聚类效果图 # 设置大图框的长和高 plt.figure(figsize = (12,6)) # 设置第一个子图的布局 ax1 = plt.subplot2grid(shape = (1,2), loc = (0,0)) # 绘制散点图 ax1.scatter(plot_data.x1, plot_data.x2, c = plot_data.kmeans_label) # 设置第二个子图的布局 ax2 = plt.subplot2grid(shape = (1,2), loc = (0,1)) # 绘制散点图(为了使Kmeans聚类和密度聚类的效果图颜色一致,通过序列的map“方法”对颜色作重映射) ax2.scatter(plot_data.x1, plot_data.x2, c=plot_data.dbscan_label.map({-1:1,0:0,1:3,2:2})) # 显示图形 plt.show() # 读取外部数据 Province = pd.read_excel(r'Province.xlsx') Province.head() # 绘制出生率与死亡率散点图 plt.scatter(Province.Birth_Rate, Province.Death_Rate, c = 'steelblue') # 添加轴标签 plt.xlabel('Birth_Rate') plt.ylabel('Death_Rate') # 显示图形 plt.show() # 读入第三方包 from sklearn import preprocessing # 选取建模的变量 predictors = ['Birth_Rate','Death_Rate'] # 变量的标准化处理 X = preprocessing.scale(Province[predictors]) X = pd.DataFrame(X) X # 构建空列表,用于保存不同参数组合下的结果 res = [] # 迭代不同的eps值 for eps in np.arange(0.001,1,0.05): # 迭代不同的min_samples值 for min_samples in range(2,10): dbscan = cluster.DBSCAN(eps = eps, min_samples = min_samples) # 模型拟合 dbscan.fit(X) # 统计各参数组合下的聚类个数(-1表示异常点) n_clusters = len([i for i in set(dbscan.labels_) if i != -1]) # 异常点的个数 outliners = np.sum(np.where(dbscan.labels_ == -1, 1,0)) # 统计每个簇的样本个数 stats = str(pd.Series([i for i in dbscan.labels_ if i != -1]).value_counts().values) res.append({'eps':eps,'min_samples':min_samples,'n_clusters':n_clusters,'outliners':outliners,'stats':stats}) # 将迭代后的结果存储到数据框中 df = pd.DataFrame(res) df # 根据条件筛选合理的参数组合 df.loc[df.n_clusters == 3, :] %matplotlib # 中文乱码和坐标轴负号的处理 plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.rcParams['axes.unicode_minus'] = False # 利用上述的参数组合值,重建密度聚类算法 dbscan = cluster.DBSCAN(eps = 0.801, min_samples = 3) # 模型拟合 dbscan.fit(X) Province['dbscan_label'] = dbscan.labels_ # 绘制聚类聚类的效果散点图 sns.lmplot(x = 'Birth_Rate', y = 'Death_Rate', hue = 'dbscan_label', data = Province, markers = ['*','d','^','o'], fit_reg = False, legend = False) # 添加省份标签 for x,y,text in zip(Province.Birth_Rate,Province.Death_Rate, Province.Province): plt.text(x+0.1,y-0.1,text, size = 8) # 添加参考线 plt.hlines(y = 5.8, xmin = Province.Birth_Rate.min(), xmax = Province.Birth_Rate.max(), linestyles = '--', colors = 'red') plt.vlines(x = 10, ymin = Province.Death_Rate.min(), ymax = Province.Death_Rate.max(), linestyles = '--', colors = 'red') # 添加轴标签 plt.xlabel('Birth_Rate') plt.ylabel('Death_Rate') # 显示图形 plt.show() # 导入第三方模块 from sklearn import metrics # 构造自定义函数,用于绘制不同k值和对应轮廓系数的折线图 def k_silhouette(X, clusters): K = range(2,clusters+1) # 构建空列表,用于存储个中簇数下的轮廓系数 S = [] for k in K: kmeans = cluster.KMeans(n_clusters=k) kmeans.fit(X) labels = kmeans.labels_ # 调用字模块metrics中的silhouette_score函数,计算轮廓系数 S.append(metrics.silhouette_score(X, labels, metric='euclidean')) # 中文和负号的正常显示 plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.rcParams['axes.unicode_minus'] = False # 设置绘图风格 plt.style.use('ggplot') # 绘制K的个数与轮廓系数的关系 plt.plot(K, S, 'b*-') plt.xlabel('簇的个数') plt.ylabel('轮廓系数') # 显示图形 plt.show() # 聚类个数的探索 k_silhouette(X, clusters = 10) # 利用Kmeans聚类 kmeans = cluster.KMeans(n_clusters = 3) # 模型拟合 kmeans.fit(X) Province['kmeans_label'] = kmeans.labels_ # 绘制Kmeans聚类的效果散点图 sns.lmplot(x = 'Birth_Rate', y = 'Death_Rate', hue = 'kmeans_label', data = Province, markers = ['d','^','o'], fit_reg = False, legend = False) # 添加轴标签 plt.xlabel('Birth_Rate') plt.ylabel('Death_Rate') plt.show()
GBDT模型(了解)
Adaboost算法
由多棵基础决策树组成,彼此之间有前后关系。
既可以解决分类问题,也可以解决预测问题。
Adaboost算法函数

梯度提升树算法

SMOTE算法
通过算法将比例较少的数据样本扩大。
SMOTE算法函数

XGBoost算法



 浙公网安备 33010602011771号
浙公网安备 33010602011771号