

第四周总结
第四周总结
python对象
定义类
class Student:
# 相同的数据
school = '清华大学'
# 相同的功能
def choice_course(self):
print('选课')
定义类的语法结构
1.class是定义类的关键字
2.Student是类的名字:类名在python中推荐首字母大写
3.缩进代码块:对象相同的数据和功能
产生对象:类名加括号(实例化)
obj1 = Student() # 每次都会产生一个新的对象
obj2 = Student()
obj3 = Student()
访问数据和功能
查看内部具有的属性和方法
print(Student.__dict__)
print(obj1.__dict__)
调用属性和方法(句点符)
print(obj1.school)
print(obj1.choose_course())
独有的数据
类的部分
定义类
class Wizard:
call = '法师'
# 让对象具有独有的数据
def __init__(self,name,mp,spell):
self.name = name
self.mp = mp
self.spell = spell
# 绑定给对象的方法(绑定方法):对象调用时自动将对象当做参数传入
def spelling(self):
spelling_tip = '%s正在施放%s!'
print(spelling_tip % (self.name,self.spell))
对象的部分
产生对象:类名加括号(实例化) mage1 = Wizard('Raistlin',15,'火球术') # 每次都会产生一个新的对象 mage2 = Wizard('Elminster',22,'闪电束') mage3 = Wizard('Mordenkainen',28,'气泉喷升')
补充
父类:多个类相同的数据和功能的结合体。
继承:一个类可以继承多个父类并拥有多个父类里所有的东西。
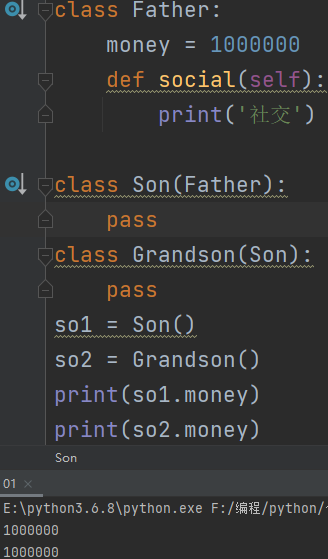
对象查找数据和方法的顺序:先从对象自身开始找,再去产生对象的类里面找,再去父类里面找,如果还找不到就会报错。对象>类>父类>报错
异常分类
1.语法错误(invalid syntax)不被允许的,出现了应立刻改正。在pycharm里会直接漂红线。
2.逻辑错误允许发生的(就是bug)。
异常信息分析
第一行 traceback 异常的追踪信息
第二行 显示出错位置,点击可直接传送至改行
第三行 异常类型和出错原因
异常捕获语法结构 try: 被检测的代码 except 错误类型 as 变量名: 分支代码(变量名指代的就是错误的具体信息)
注意:
1.异常捕获在程序中尽量少用
2.try检测的代码要尽可能的少
其它关键字
else:
try检测的代码没有异常时会执行
finally:
无论是否有异常最终都会执行
数据库存储数据的演变过程
1.文件:既能存数据,也能取数据。有数据库的雏形
缺点
1.数据格式千差万别,导致程序兼容性很差
2.数据安全性较弱,容易丢失
2.单机程序:数据保存在本地的一个文件夹内,数据格式由程序设计者定义好
缺点
1.数据彼此之间无法共享(如:游戏进度、用户数据等等)
2.数据安全性较弱,容易丢失
3.联网程序:数据保存在玩家暂时不知道的地方,数据是可以共享的,并且安全性较高
1.c/s架构
c:client客户端
s:sever服务端
比喻:客户端就像一位位客人,服务端可以看成一家家饭店。单机游戏将客户端服务端整合在一起,网络游戏则是分开。
2.b/s架构
b:broswer浏览器
s:服务器(端)
比喻:浏览器相当于可以去多家店里消费的客人,服务器相当于一家家店。
b/s架构本质也是c/s架构,但浏览器泛用性更强。
数据库其实就是一款c/s架构的软件。
数据库操作数据可以简单地理解为就是基于网络远程的操作文件。
客户端:基于网络通信(可以是互联网也可以是局域网,甚至是单机)
服务端:基于网络通信(可以是互联网也可以是局域网,甚至是单机)
由于数据库就是一款c/s架构的软件,所以数据库软件其实有很多,可以分为两类:
1.关系型数据库
具有固定的表结构,并且表与表之间可以建立外键关系(像excel表格)
主要有:MySQL、Oracle、PostgreSQL、sql server、sqlite、MariaDB、access等等……
(1)MySQL数据库
开源免费的,也是目前市面上使用最多的一款数据库
(2)MariaDB数据库
跟MySQL是同一个人开发的,(中间的小故事另附链接),相当于是MySQL的备用,也有很多其他功能
(3)Oracle数据库
安全性极高,但是需要收费并且维护费用也很高,只有大型互联网企业才会使用(尤其是银行)
(4)PostgreSQL数据库
可扩展性非常强,可以基于现有的功能额外开发(改装)
(5)sql server数据库
老牌数据库软件
(6)sqlite数据库
小型数据库,一般只用于本地小数据量测试
2.非关系型数据库
没有固定的表结构,数据存储格式采用的是K:V键值对的形式(像python中的字典)
主要有:redis、mongoDB、memcache
(1)redis数据库
是目前市面上最火的一款非关系型数据库软件,读取数据的速度非常快,主要用于缓存
(2)mongoDB数据库
在爬虫和大数据库领域使用广泛
(3)memcache数据库
基本被redis淘汰了
SQL语句就是用来操作关系型数据库的语言
NoSQL语句就是用来操作非关系型数据库数据库的语言
由于可以充当数据库客户端的语言非常多,为了能够兼容,数据库专门开发了一门用来与数据库打交道的语言,也就是SQL语句
也就意味着以后需要操作数据库,统一使用SQL语句。
针对关系型数据库
库 >>> 文件夹
表 >>> 文件夹里面的文件
数据 >>> 文件夹里面的文件里面的一行行记录
市面上流行的版本:
MySQL5.5 基本不用
MySQL5.6 使用较广泛
MySQL5.7 逐步过渡
MySQL8.0 最新版
官网:www.mysql.com
点击downloads
下翻到MySQL community (GPL) downloads
MySQL Community Sever,默认展示最新版,不要下
点击Looking for the latest GA version?
找不到想要的版本?点Archives
学习阶段推荐下载5.6.44
download,下载对应的压缩包
解压压缩包
bin文件夹
存储的是启动程序文件
data文件夹
存储的是数据相关的文件
my-default.ini
数据库的默认配置文件
README
类似于产品说明书
1.要想使用MySQL,首先要启动服务端
#添加环境变量
属性>高级系统设置>环境变量>path>新建>mysql里的bin文件夹
添加完环境变量后打开cmd,输入mysqld,如果正常启动便成功了
2.客户端登陆服务端
完整方式
mysql - h -P -u -p
host主机地址 端口号 username用户名 password密码
myslq # 游客模式登录(功能及权限都很少,可用于检测服务端有否启动,但不推荐使用)
3.退出游客账户采用管理员账户登录
exit/quit
管理员名户名:root;初始没有密码
完整命令
mysql -h 127.0.0.1(本机归还地址) -P 3306 -uroot -p
本地操作时可以简化
mysql -uroot -p
密码于二次输入时会加密处理防止泄露
1.如何查看计算机内部所有的系统服务?
方式1:任务栏>右键>任务管理器>服务
方式2:WIn+R,输入services.msc,回车即可
2.将MySQL服务添加到系统服务中
一定要以管理员身份打开cmd,否则安装请求会被拒绝
mysqld --install
3.添加完成后第一次需要手动启动
方式1:找到服务>鼠标右键启动
方式2:net start mysql
1.以管理员身份打开cmd窗口
2.将MySQL服务关闭
net stop mysql
3.移除系统MySQL服务
mysqld --remove
4.删除MySQL相关环境变量
5.删除MySQL相关文件夹
6.之后下载压缩包从头开始
配置文件、SQL基本语句
方式1:
cmd进入mysql,登录管理员。
set password=password('新密码');
# 该命令修改的是当前登录用户的密码
方式2:
mysqladmin -u用户名 -p原密码 password 新密码
# 在不登录的情况下修改
配置文件
my-default.ini是MySQL默认设置文件。
配置文件的后缀名:.ini,.xml,还有许多。
MySQL默认的配置文件不要修改,若想修改配置,先拷贝一份再做修改,之后换个名字作区分
在这份新文件内拷贝几行固定的配置
修改完配置一定要重启服务端!!!
针对库
1.查
show databases; # 查看所有的数据库名称
show create database db1; # 查看指定的数据库(了解即可)
2.增
create databases 新库的名字; #创建新数据库
3.改
alter database db1 charset='gbk'; # 修改数据库编码
4.删
drop database db1; #删除指定的数据库
针对表
# 1.如何查看当前在哪个库下
select database();
# 2.切换数据库
use 数据库名;
1.查
show tables; # 查看某个库下所有的表名(只显示名称,多个同名不同格式的文件只显示一个)
show create table t1; # 查看指定的表信息(了解即可)
describe t1; # 用于查看表结构(常用) 也可简写为 desc t1;
2.增
create table 新表(字段 类型,字段 类型); # 创建表(必须要有字段名和类型)
3.改
alter table t1 modify name varchar(16); # 修改字段类型
4.删
drop table ta; # 删除指定表
针对记录
先有库和表(最好使用自己创建的,默认自带的不要动)
含金量最高的就是记录
1.查
select * from t1; # 查看t1表中所有的数据(实际工作中不太推荐)
select id,name from t1; # 查看指定字段对应的数据
2.增
insert into t1 values(1,'jason',123); # 插入数据(表中有几个数据就需要改几条)
insert into t1(id,name) values(); # 按照指定的字段传入
3.改
update userinfo set name='jasonNB' where id=1; #将id为1的字段改为jasonNB
4.删
delete from t1 where id=4; #删除表中指定的记录
delete from t1; # 删除表中所有的记录
MySQL内部针对数据的存储有很多种不同的方式。简单的理解:我们把这些不同的存储方式叫做不同的存储引擎。
# 如何查看各类存储引擎
show engines;
事务:保证多个数据的操作要么全部完成要么全部失败。(举例:银行转账)
行锁:多一行行数据加锁,同一时间只能有一个人操作。(比喻:超市收银台)
外键:建立表与表之间的关系。
主要存储引擎
InnoDB
MySQL5.5之后的版本默认的存储引擎
支持事务、行锁、外键。 数据更安全
MyISAM
MySQL5.5之前的版本默认的存储引擎
不支持事务、外键等功能。安全性较于InnoDB低
但是存取数据的速度比InnoDB快
memory
数据直接存储在内存 速度快但是断电立刻丢失
blackhole
写入其中的数据都会丢失
不同的存储引擎生成的文件数目也不同:
1.InnoDB有两个文件
.frm 表结构
.idb 表数据、索引(书的目录)
2.MyISAM有三个文件
.frm 表结构
.MYD 表数据
.MYI 表索引
3.memory有一个文件
.frm 表结构
4.blackhole有一个文件
.frm 表结构
create table 表名(
字段名 字段类型(宽度) 约束条件,
字段名 字段类型(宽度) 约束条件,
字段名 字段类型(宽度) 约束条件
);
注意:
1.字段名和字段类型是必须的,宽度和约束条件是可选的
2.约束条件可选 并且一个字段可支持多个约束条件
3.最后结尾的字段语句不能有逗号
1.整型
tinyint
smallint
int
bigint
不同整型类型能够存储的数字范围不同。
2.浮点型
float
double
decimal
不同的浮点型存储小数的范围和精确度不一样。
精确度:float < double < decimal
3.字符类型
char
varchar
上述两个数据类型在存储数据上有本质的区别
char_length(); # 统计数据长度
char
好处:整存整取 速度快
坏处:浪费存储空间
varchar
好处:节省存储空间
坏处:存取速度较于char慢
存取数据都需要计算,消耗时间
date 年月日
time 时分秒
Datetime 年月日时分秒
Year 年
enum
多选一
set
多选多(包含多选一)
针对数字类型 宽度并不是用来限制存储长度而是用来表示展示长度。
在定义数字时无需手动添加宽度。
1.unsigned 无符号
create table 表名(字段 数据类型 unsigned);
2.zerofill # 0填充
create table表名(字段 数据类型 zerofill);
3.not null 不能为空 使用频率很高
create table 表名(字段 数据类型 not null);
4.default 默认值
create table 表名(字段 数据类型 default '匿名用户');
5.unique 唯一
单列唯一
create table 表名(字段1 数据类型 unique);
多列唯一
create table 表名(字段1 数据类型,字段2 数据类型,unique(字段1,字段2));

 浙公网安备 33010602011771号
浙公网安备 33010602011771号