

06>>>字符编码与文件操作
字符编码
首先来回忆一下计算机的工作原理。
计算机是基于电工作的,而电信号只有高低电平两种状态。
也就是说计算机只认识两种状态,人为的定义为数字0和1,即为二进制。
所以为了让电脑可以识别人类输入的文字、数字和其他符号,字符编码便出现了。
字符编码就是将人类的字符与数字之间制定出对应关系,相当于发电报是用于破解密文的密码本一样。

字符编码经历了长久的发展,其过程主要可以分为三个阶段。
1.一家独大
现代电子计算机是美国人发明的,美国人使用英语,所以最开始美国人只需要让计算机可以识别英语就足够使用了。
ASCII码:内部记录了英文与数字的对应关系。

2.群雄割据
随着计算机技术的扩散,不止是美国人,渐渐地欧洲、亚洲以及更多地区的人们都开始使用计算机了。根据国别和语言的不同,各国计算机专家根据本国需要制定各自的字符编码。
比如说:
中国大陆制定了GBK码,内部记录了英文,中文与数字的对应关系。
韩国人制定了Euc_kr码,内部记录了英文,韩文与数字的对应关系。
日本人制定shift_JIS码,内部记录了英文,日文与数字的对应关系。

可是这样就导致了一个问题。如果玩过早期日本或台湾电脑游戏的读者,应该还记得游戏中所有的文本都是乱码无法正常阅读的情况。
其实这种现象就是因为这些游戏的文本在制作时使用的字符编码是shift_JIS码或者Big5码(港澳台地区使用的字符编码)。所以那个时代的玩家都需要另行下载shift_JIS码或者Big5码才可以正常阅读游戏中的文本。

3.天下一统
为了避免这种鸡同鸭讲的窘境,世界各国的计算机专家聚在一起商讨应该编制一套可以兼容世界各国语言的通用编码,于是unicode码出现了,也被称为万国码。
内部记录了各个国家文字与数字的对应关系。

不过unicode也有小瑕疵。unicode码规定了各国语言至少占用2bytes。这导致使用unicode码编写的英文文件占用空间比ascii时代多了一倍。
于是根据需求,在unicode码的基础上又推出了utf8编码,在书写英文和数字时,像ascii码一样只占用1bytes,其他文字继承unicode的规则。
utf8成为了目前默认使用的字符编码,利于世界各地人民通过互联网交流、查询、分享数据。
1.以后文本文件如果出现了乱码肯定是因为字符编码选错了
尝试着切换字符编码即可
编码与解码
在战争片中,经常会有各方谍报人员对照着一本小册子向总部发送电报的镜头。这种小册子上面记载着明文与密文的对应关系,叫做秘钥。
通过秘钥,可以将明文转为密文防止敌人截获消息,也可以将密文破解为可以理解的正确信息,所以抢夺敌谍密码本或是破解密钥也是常见戏码。
说来也巧,在二战中英军为了破解德军使用的“恩尼格玛机”(信息加密装置),研制了破译机“炸弹机”,随后又研制出了巨人计算机。这巨人计算机比美军使用的ENIAC早诞生了两年,所以学界依然还在争论究竟谁才是真正的第一台电子计算机。

而巨人计算机的研发,就有大名鼎鼎的计算机科学之父艾伦·图灵的参与。

说回密钥密码。其实人类文字和二进制的关系也类似于秘钥,通过实现定制好的编码表,可以把文字转为计算机能识别的二进制数据,也可以把二进制数据转为人类能通读的文字。这就是编码和解码的概念。
编码:按照指定的编码本将人类的字符编程成计算机能够识别的二进制数据。
解码:按照指定的编码本将计算机的二进制数据解析成人类能够读懂的字符。
现在我们来用代码实现编码和解码的效果。
首先随便写一段中文作为字符串。
res = '一二三四五,上山打老虎。'
先来看看编码,也就是将人类使用的字符转换成计算机能看懂的二进制数据。
# 编码 res1 = res.encode('gbk') print(res1)
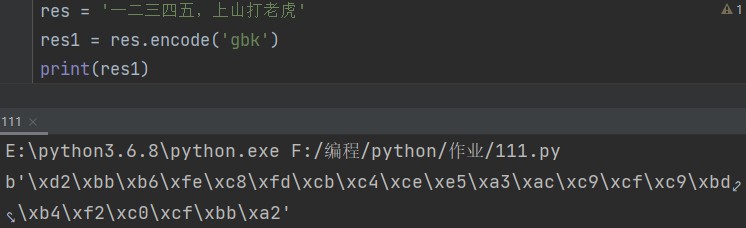
显然这么一长串火星文地球人是看不懂的……
接下来是解码,也就是将计算机使用的二进制数据转换成人类能看懂的字符。
# 解码 res1 = res1.decode('gbk') print(res2)
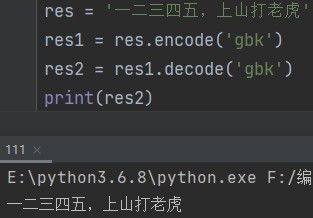
字符编码解码只是开胃小菜,接下来讲到的知识才是重点。
文件操作
接下来我们就来学学如何用python操作电脑上的文件。听起来非常高大上,但实际语法很简单,并且有两种。
第一种:文件操作固定句式
with open(r'文件路径','读写模式',encodint='字符编码') as 变量名: f.读写模式()
第二种(不必掌握,了解即可)
变量名 = open(r'文件路径','读写模式',encoding='字符编码') f.'读写模式' 变量名.close()
我们常用的是第一种语法格式,第二种只需要了解即可。不过光知道文件操作的语法格式还不够,还需要了解它们的用法。
文件路径
这里还需要补充一下文件路径的相关知识。
文件路径分两种:
1.相对路径
2.绝对路径
相对路径需要有一个参考系才可以正常使用。比如说我想去楼下街对面的小店买包烟,“楼下街对面的小店”就是相对于我现在住所的相对路径。不需要知道这家小店的具体门牌号,我只要走下楼再穿过马路就能立马找到这家店。但是这个参考系只对于我或者和我住在同一栋楼的邻居们有效,如果把它交给米国大统领拜登看就不可能精确定位了。
绝对路径则不需要参考系。就相当于我详细地写下同样那家小店的具体地址,按“地球→亚洲→中国→上海→××区→××路×××号”的格式详细写出来。这样不光我和我的邻居们知道怎么走,即便是外星人也可以顺着我给出的地址来入侵这家店铺抓试验品:D。
拿同一个文件来举例:
相对路径:111.py
绝对路径:F:\编程\python\作业\111.py
具体用哪种路径,就结合实际情况来自行判断了。
转义符
还有些读者留意到了,在操作文件的两种句式中,文件路径的引号前面还加了个小写的r,这个r又是什么意思?
这个r的意思是转义符。
我们来看一个例子:
print('disco disco good good!\nuptown\tfunk\tyouup!')
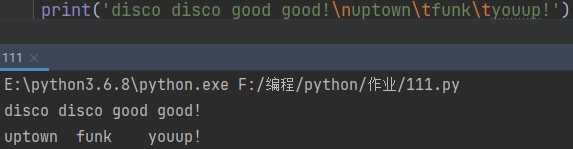
在计算机的世界中有很多\(注意是反斜杠)和英文字母的组合是有特殊含义的。在这个范例中出现的\n表示换行符,\t表示制表符。
在有些时候,代表地址分隔的\就会和文件名称产生化学反应,比如:
print('F:\编程\python\作业\aaa.py')
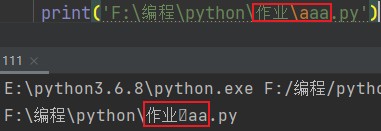
可以看到文件名并没有正常显示,因为\a是有特殊含义的,python在处理语句时会优先将其识别为一个具有特殊含义的字符。
有时候不想产生特殊含义,我们就可以取消转义。r就是其中之一,叫做元字符r,作用就是取消转义。
print(r'F:\编程\python\作业\aaa.py\n\t')
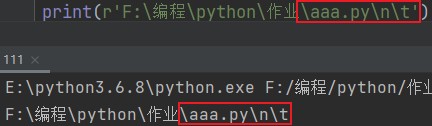
取消转义之后,路径便能完整显示了,效果立竿见影!
读写模式
从操作txt文件开始讲起。
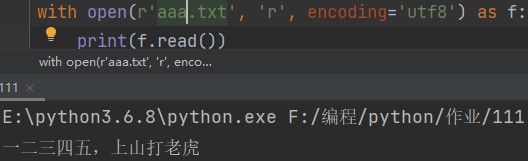
首先我们创建一个aaa.txt文件,在里面随便写点东西。
一二三四五,上山打老虎
随后便是有趣的实验课。
1.只读模式
特点:
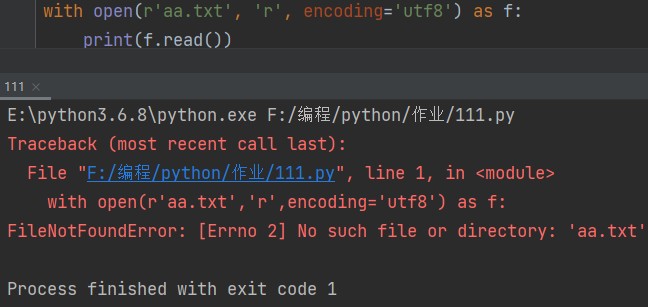
1.如果文件路径不存在会直接报错。
2.如果文件存在则打开并可读取文件内容。光标在文件开头。
我们来验证一下:
with open(r'aa.txt', 'r', encoding='utf8') as f: print(f.read()) # 一次性读取文件内容
with open(r'aaa.txt', 'r', encoding='utf8') as f: print(f.read()) # 一次性读取文件内容
2.只写模式
特点:
1.如果文件路径不存在会自动创建。
2.如果文件路径存在会先清空该文件内容然后再写入。
with open(r'aa.txt', 'w', encoding='utf8') as f: f.write('Disco disco good good!\n')

with open(r'aaa.txt', 'w', encoding='utf8') as f: f.write('Disco disco good good!\n')
3.只追加模式
1.如果文件路径不存在会自动创建。
2.如果文件路径存在,光标会移动到文件末尾写入新增的内容。
with open(r'aa.txt', 'a', encoding='utf8') as f: f.write('uptown funk you up!')
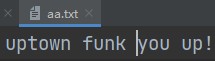
with open(r'aaa.txt', 'a', encoding='utf8') as f: f.write('uptown funk you up!')

读取优化
读写文件的步骤是首先将数据记录在内存中,随后再保存到硬盘里。所以在读取大容量文件时且自己配置不好内存容量较少时,很有可能把内存的容量全部填塞满。不堪重负的电脑在这个时候为了保护自身,便会选择重启电脑等操作,以此来保护自己不因过于庞大的运算量而自我烧毁。这种情况被称为内存溢出。
为了避免这种情况,我们可以在读取操作的结构中加上一条限制防止内存溢出的情况。
with open(r'aaa.txt', 'r', encoding='utf8') as f: for line in f: # 一行行读取文件内容 能够避免内存溢出 print(line)
只看结果是察觉不到有何区别的。在原理上便是限制了python只能一行行地读取文件以防读取过多数据导致内存溢出。
操作模式
其实上面已经讲了一种操作模式,也就是操控txt文件的t模式(文本模式)。
1.t模式
文本模式(也是上述三种读写模式默认的模式)
rt # 只读模式 wt # 只写模式 at # 只追加模式
特点:
1.该模式只能操作文本文件。
2.该模式下必须指定encoding参数。
3.读写都是以字符串为单位。
2.b模式
二进制模式,在此模式下所有类型的文件都会被读写成二进制数据的格式,不依靠其他方法直接看是看不懂的。图片可以直接参考上文编码一章的效果图。
二进制模式使用的关键词和文本模式大相径庭,尾字母不同而矣。
rb
wb
ab
特点:
1.该模式可以操作任意类型的文件。
2.该模式下不需要指定encoding参数。
3.读写都是以bytes(二进制)为单位。
现在以我的博客园头像为例,看看二进制模式下读取图片有怎样的效果。
with open(r'C:\Users\2\Desktop\头像.jpg', 'rb') as f: print(f.read())
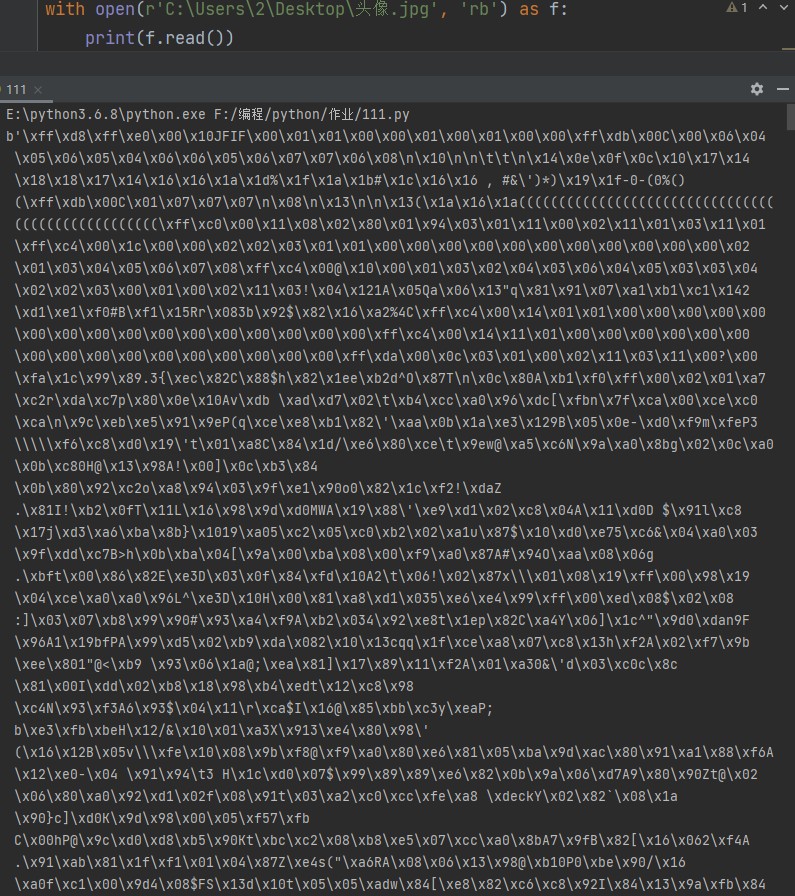
又是一大串教人看不懂的火星文……
文件操作其他方法
1.快速保存
f.flush() # 将内存中的数据立刻刷到硬盘 相当于ctrl+s
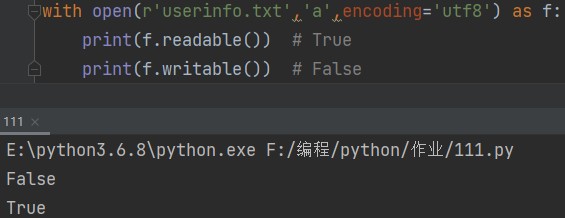
2.判断可否读写
f.readable() # 判断文件是否可读 f.writable() # 判断文件是否可写 eg: with open(r'userinfo.txt','a',encoding='utf8') as f: print(f.readable()) # True print(f.writable()) # False
3.多元素写入
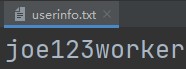
f.writelines() # 括号内放列表 多个元素都会被依次写入 eg: with open(r'userinfo.txt','a',encoding='utf8') as f: f.writelines(['joe','123','worker'])
光标移动
光标的概念在读写模式中就介绍过,不过在那些用法中无法自主指定光标的所在位置,只能按规定的来。学会了这个条目,我们就可以用seek方法手动控制光标在哪里就位了。
seek(offset,whence) # offset用来控制移动的位数;whence是操作模式
whence关键词则有三种用法:
0:既可以用在文本模式也可以用在二进制模式,移动到文件开头
1:只可以在二进制模式下使用,当前位置
2:只可以在二进制模式下使用,移动到文件末尾
用实例来演示一下:
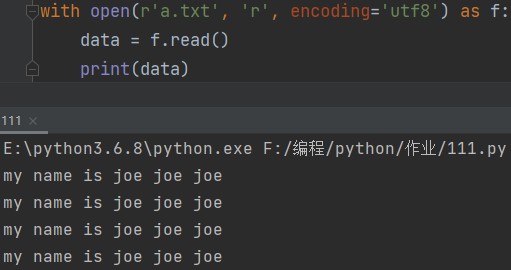
首先随便写一个文件a.txt,里面随便写一点内容。
with open(r'a.txt', 'r', encoding='utf8') as f: data = f.read() print(data)
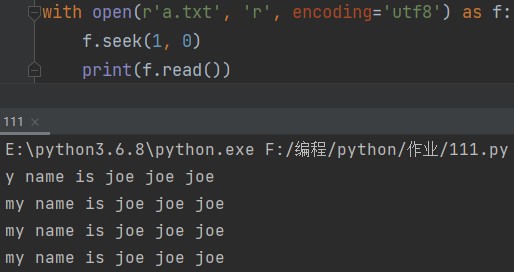
然后移动光标:
# 控制光标移动 f.seek(1, 0) # 移动到文件开头并往后再移动一个字符 print(f.read())
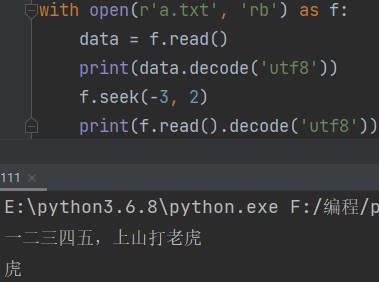
接下来看看二进制模式下读取中文的表现如何:
with open(r'a.txt', 'rb') as f: data = f.read() print(data.decode('utf8')) # 控制光标移动 f.seek(-3, 2) # 二进制模式下移动的是二进制位(字节数) print(f.read().decode('utf8'))
看起来没什么问题,再进给点看看有没有变化。
f.seek(-6, 2) print(f.read().decode('utf8'))
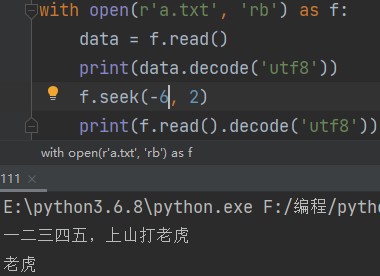
似乎可以得出结论,utf8码中的汉字字符是3个字节的。那如果我们进给量不足3的倍数会怎么样?
f.seek(-8, 2) print(f.read().decode('utf8'))
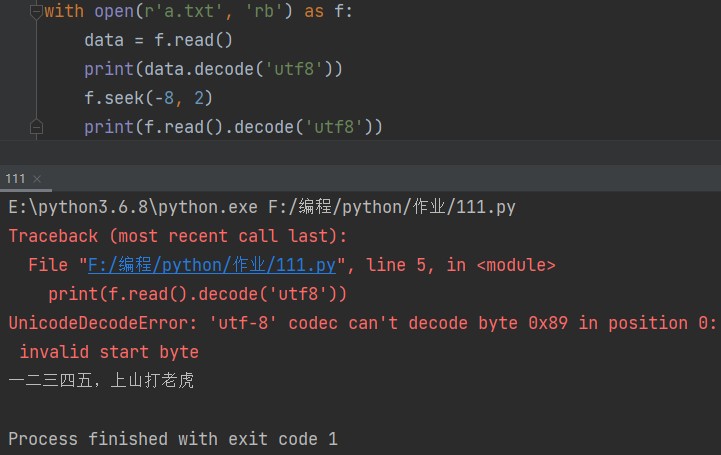
很明显报错了XD。
文件修改
硬盘读写的原理
首先我们要了解一下电脑存储数据的原理。
电脑中永久储存的数据都保存在硬盘中,硬盘是一个圆形的碟状物。
硬盘保存数据就是读写磁头在硬盘上刻录一个一个的二进制数,宏观来看保存的文件就像是各自占一块自留田圈地自萌。
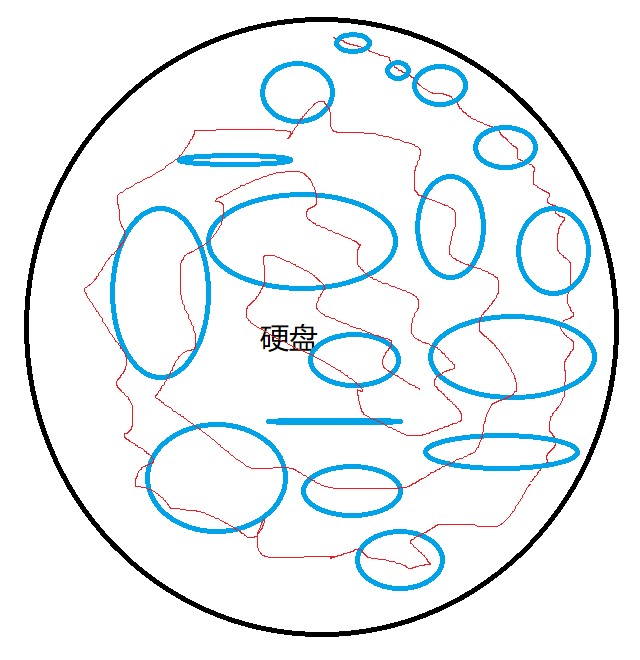
到了删除硬盘上的数据时,硬盘并不是真正的删除掉数据,而是将这块数据标记为“可占用状态”。那么接下来要存入新数据的话,新数据就会覆盖掉标记为“可占用状态”的数据。
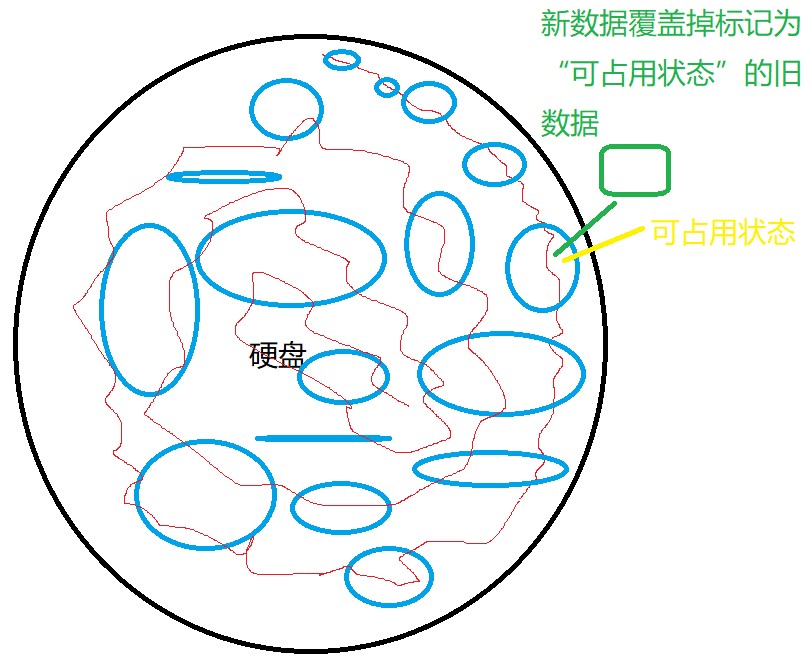
如果仅仅只是删除文件而没有进行更深度的操作,那么只是表面上的删除了,实际上数据都还存在,有心人依然有办法复原出来。
现实世界里已经发生了不止一次删除掉的文件泄露事件,原因也基本都是被泄密者不了解电脑原理而被懂技术的好事者们抓住了漏洞。现在回收旧手机的废品商之所以高价回收手机,也是为了从旧手机中设法提取信息,非法获取隐私。
那么该怎么做才能避免旧手机里的数据不会被人发现呢?
首先把旧手机里的数据全部删除掉,然后全部装满没有价值的垃圾数据(比如说全部装满新闻联播),然后再删掉。这样别人拿到你的旧手机尝试捡漏,最终恢复出来的也都只是新闻联播,彻底保证了自己的隐私不会被人扒窃。
而读取数据,就是读写磁头在磁碟上移动读取数据,就像是旧式黑胶唱片机那般运作。

而说到修改文件,实际上硬盘中的文件不能在顺着刻录着它们的“自留田”直接增改,只有两种办法:
1.抹掉原先的数据,在原先数据的基础上重写一份修改后的新文件。
2.删除原先的数据,然后另找一块地写一份修改后的文件。
修改硬盘中文件的原理就是这么麻烦。
文件修改
了解了硬盘储存数据的原理,我们可以说回正事了。
回到a.txt,多写几行方便看清效果^_^。
My name is joe joe joe. My name is joe joe joe. My name is joe joe joe. My name is joe joe joe. My name is joe joe joe.
现在我们来试着修改文件。
第一种方法
with open(r'a.txt', 'r', encoding='utf8') as f: data = f.read() with open(r'a.txt', 'w', encoding='utf8') as f: f.write(data.replace('joe','simon')) with open(r'a.txt', 'r', encoding='utf8') as f: print(f.read())
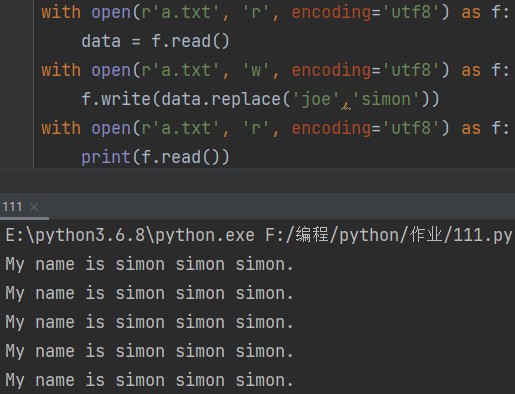
这种方法有一个缺点:如果需修改的文件很大,就有可能导致内存溢出。
第二种方法
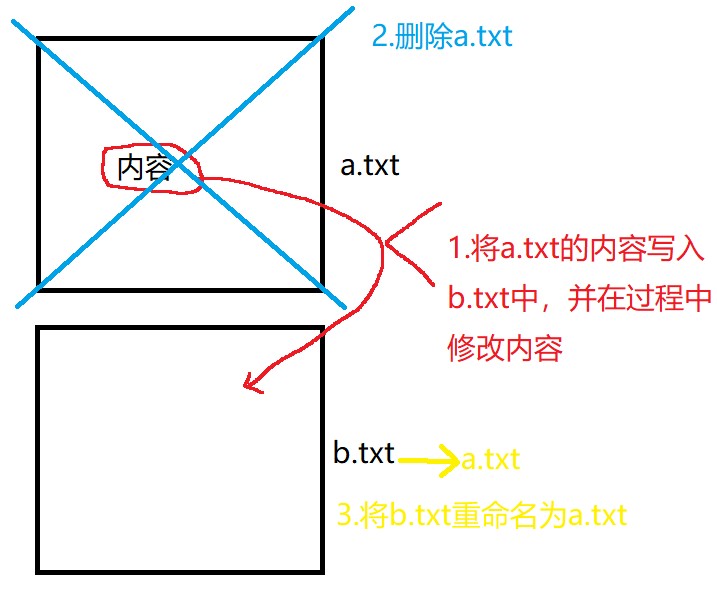
第二种方法则是分两步走:
1.创建一个新文件,将老文件内容写入新文件,过程中完成修改。
2.之后将老文件删除,并将新文件命名成老文件,从而达到修改的效果。
这样一招瞒天过海在计算及内部发生的非常快,以至于用户根本感觉不到这些步骤。
这种操作方式效率比较高也更安全,不过这种方法会牵扯到后面要学习到的模块相关内容,现在先作个了解即可。
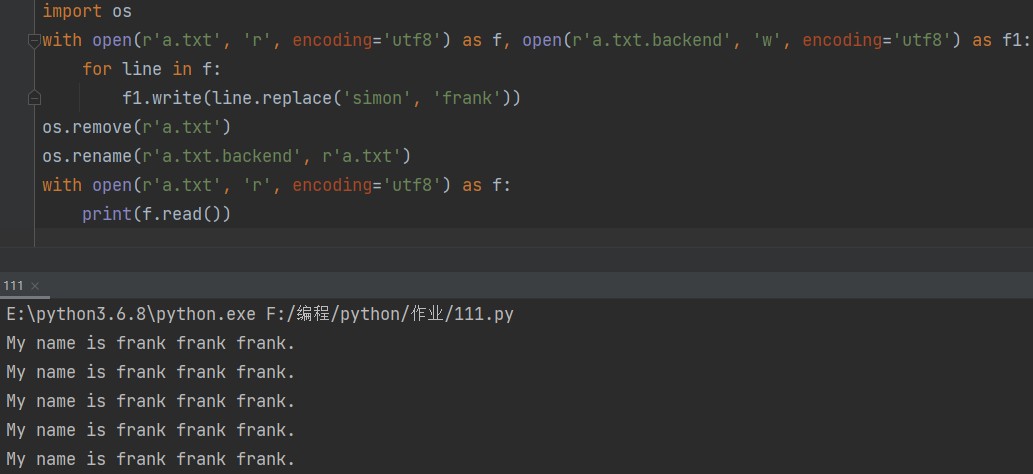
import os with open(r'a.txt', 'r', encoding='utf8') as f, open(r'a.txt.backend', 'w', encoding='utf8') as f1: for line in f: f1.write(line.replace('simon', 'frank')) os.remove(r'a.txt') os.rename(r'a.txt.backend', r'a.txt') with open(r'a.txt', 'r', encoding='utf8') as f: print(f.read())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号