

09>>>内置模块
模块的定义
什么是模块与包?
模块是具有一定功能的代码集合。模块可以是py文件,也可以是多个py文件的组合,即文件夹(也叫作包)。
想要使用模块,首先要导入模块。
导入模块的本质
导入模块后,会执行模块内的代码并产生一个该模块的名称空间。将代码执行过程中的名字存放该名称空间中,然后给导入模块的语句一个模块名,该模块名指向模块的名称空间。
举个栗子:
# b.py文件中 import aaa # aaa.py文件中 name = 'joe' def index(): pass
从之前学习的名称空间来看,内部逻辑是这样的:
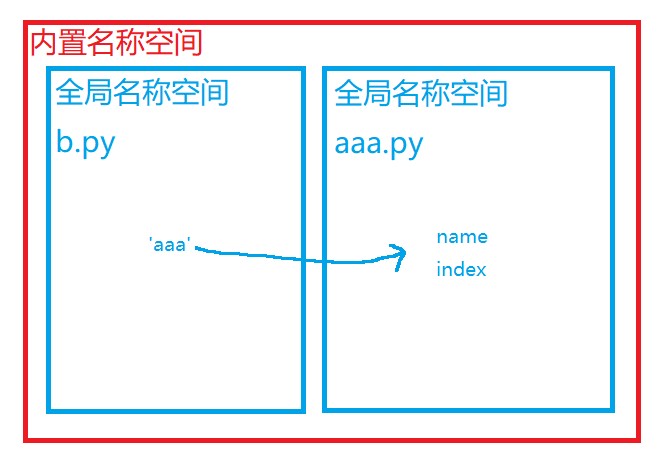
通过模块名进入模块的全局空间中寻找需要的数据。
这种导入模块的用法是文件与文件之间互相读取数据。如果是单个文件内,当然还是定义函数更好使。
需要注意的是:重复导入相同的模块,只会执行一次。
导入模块的两种句式
import 模块名
可以通过模块名点出所有的名字。
from 模块名 import 子名1,子名2
只能指名道姓地使用import后面导入的子模块名,并且还存在冲突的风险。
from句式主要用于模块与当前文件不在同一级目录下使用。
如果模块名较长或者不符合个人使用习惯,可以起别名:
import 模块名 as 别名 # 或者 from 模块名 import 子名 as 别名 eg: import asjdkjkasdjaskdkasdasdjsjdksadksajdkasjd as ad from d1.d2 import f1 as fff
强调
在创建py文件的时候文件名一定不能跟模块名冲突!!!
常见内置模块
时间模块
时间模块可以帮助我们操控程序内部的时间。
在程序最开头先要导入时间模块。
import time # 导入时间模块
1.打印时间戳
time.time() # 打印时间戳 eg: print(time.time()) # 1633507562.5619586,系1970年1月1日至今的秒数(忽略闰秒)
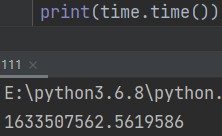
打印出来的数字即为时间戳,是从1970年1月1日(UTC/GMT的午夜)开始所经过的秒数,不考虑闰秒。
选择从1970年1月1日作为起始也是有讲究的,该年是Unix系统元年。
(关于为何选用1970年1月1日,可以看这篇文章https://zhuanlan.zhihu.com/p/72516872)
2.打印当前时间
time.strftime('%Y-%m-%d') # 获取年月日 time.strftime('%Y-%m-%d %H:%M:%S') # 获取年月日时分秒 eg: print(time.strftime('%Y-%m-%d')) # 2021-10-06 print(time.strftime('%Y-%m-%d %H:%M:%S')) # 2021-10-06 16:10:47
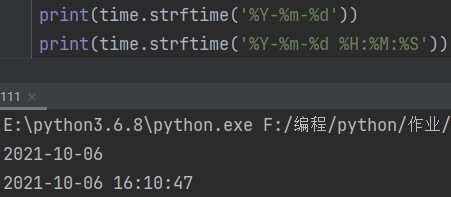
这里需要记一下语句中用到的关键字。
%Y 年 %m 月 %d 日 %H 时 %M 分 %S 秒
3.程序暂停
time.sleep(暂停秒数) eg: print('该睡了') time.sleep(3) print('睡醒了')
这个功能无法通过图片展示出来,还是需要亲身体验一下。
不太理解这个程序的用途,那么我们来这样一道题目来帮助你了解其用法:
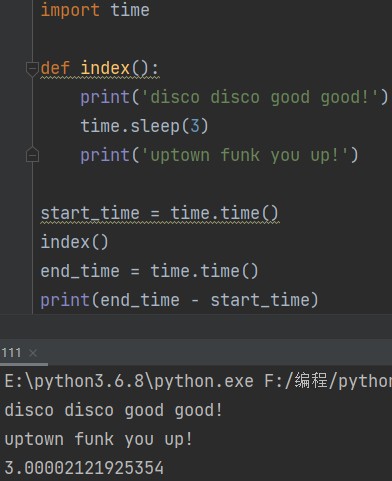
现在有这样一个函数——
def index(): print('disco disco good good!') time.sleep(3) print('uptown funk you up!')
现在想要统计index函数执行的时间,该怎么做?
答:
start_time = time.time() index() end_time = time.time() print(end_time - start_time)
时间模块还存在一个亲兄弟,叫做datetime。
import datetime
它的作用也是获取本地时间,不过比time模块更精确。
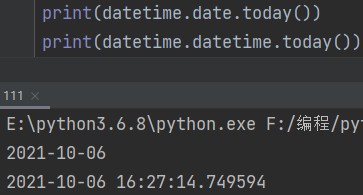
datetime.date.today() # 获取本地时间,年月日 datetime.datetime.today() # 获取本地时间,年月日时分秒 eg: print(datetime.date.today()) # 2021-10-06 print(datetime.datetime.today()) # 2021-10-06 16:27:14.749594
除此之外,datetime模块还能用来编写定时类操作:
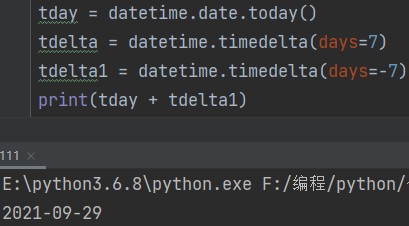
tday = datetime.date.today() # 获得本地日期,年月日 tdelta = datetime.timedelta(days=7) # 定义操作时间,day=7也就是可以对另一个时间对象加7天或者减少7点 tdelta1 = datetime.timedelta(days=-7) print(tday + tdelta1)
os模块
os模块是与操作系统交互的一个接口。通过该模块,我们就可以利用python来操作文件和文件夹。
首先还是要导入模块。
import os
1.创建文件夹
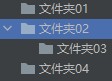
os.mkdir('文件夹名称') # 默认使用的是相对路径 os.makedirs('父文件夹名称\子文件夹名称') eg: os.mkdir(r'文件夹01') # 只能创建单级目录 os.makedirs(r'文件夹02\文件夹03') # 创建多级目录需要改成makedirs os.makedirs(r'文件夹04') # makedirs也可以创建单级目录
2.删除文件夹
os.rmdir('文件夹名称') # 默认使用的是相对路径 os.removedirs('父文件夹名称\子文件夹名称') eg: os.rmdir(r'文件夹01') os.rmdir(r'文件夹02\文件夹03') # 默认只能删一级空目录 os.removedirs(r'文件夹02\文件夹03') # 可以删除多级空目录
3.查看文件夹
# 查看指定路径下所有的文件及文件夹 os.listdir('文件夹路径') eg: print(os.listdir()) # 默认为当前程序文件的保存目录 print(os.listdir('D:\\')) # 查看当前所在的路径 print(os.getcwd()) # 切换当前操作路径 os.chdir('文件夹路径') eg: os.chdir(r'文件夹03')
4.判别文件夹
# 判断是否是文件夹 os.path.isdir('文件路径/文件名.后缀') eg: print(os.path.isdir(r'a.txt')) # 默认为当前程序文件的保存目录 print(os.path.isdir(r'文件夹04')) # 判断是否是文件 os.path.isfile('文件路径/文件名.后缀') print(os.path.isfile(r'a.txt')) # 默认为当前程序文件的保存目录 print(os.path.isfile(r'文件夹04')) # 判断当前路径是否存在 os.path.exists('文件路径/文件名.后缀') print(os.path.exists(r'a.txt')) # 默认为当前程序文件的保存目录 print(os.path.exists(r'文件夹03'))
5.路径拼接
首先需要注意的是:不同的操作系统路径分隔符是不一样的。
在windows是\,而在mac中是/。
os.path.join('文件路径','文件名.后缀') # 该方法可以针对不同的操作系统自动切换分隔符 eg: res = os.path.join('D:\\','a.txt')
6.获取文件大小
os.path.getsize('文件名.后缀') eg: print(os.path.getsize(r'a.txt')) # 按照字节数计算
hashlib模块
hashlib模块是一款加密模块。将明文数据按照一定的逻辑转换成密文数据,一般情况下密文都是由数字字母随机组合而成。
这里又牵扯到加密算法的概念。
加密算法即是指将明文数据按照一定的逻辑(每个算法内部逻辑都不一样)转换成密文数据,加密之后的密文不能反解密出明文。算法生成的密文越长表示该算法越复杂。
常见的加密算法有:md5、base64、hmac、sha系列等等……
现在我们就来学习如何用模块加密。
1.md5加密
首先还是要导入模块:
import hashlib
1.导入模块之后,首先要选择加密算法,一般情况下采用md5即可。
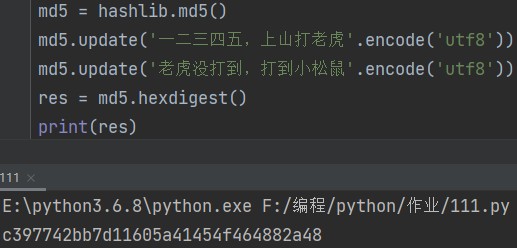
md5 = hashlib.md5()
2.将待加密的数据传入算法中。
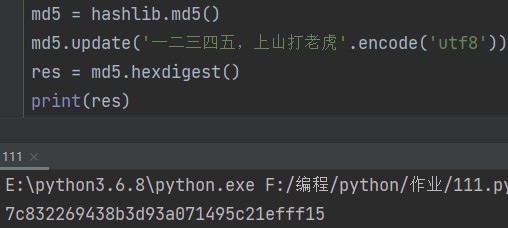
md5.update(b'数字或英文字符') # 数据必须是bytes类型(二进制),数字或英文就在前面加b md5.update('其他语言字符'.encode('字符编码')) # 如果要加密中文则需要编码 eg: md5.update(b'hello') md5.update('一二三四五,上山打老虎'.encode('utf8'))
3.获取加密之后的密文。
res = md5.hexdigest() print(res)
2.加盐处理
加盐处理是指在对用户真实数据加密之前再往里添加额外的干扰数据。
1.首先还是要选择加密算法:一般情况下采用md5即可。
md5 = hashlib.md5()
2.将待加密的数据传入算法中。
3.加盐处理。
md5.update(自己定制的盐(不固定,可随机改变)) # 先加盐 md5.update(需要加密的数据) # 再加密数据 eg: md5.update('一二三四五,上山打老虎'.encode('utf8')) md5.update('老虎没打到,打到小松鼠'.encode('utf8')) res = md5.hexdigest() # 获取加密之后的密文 print(res)
random模块
接下来要讲的模块非常好玩,大家一定会喜欢它。
这个模块就是random模块,也叫随机数模块。
第一步当然还是导入模块。
import random
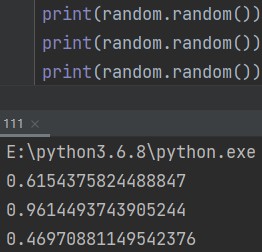
1.随机返回0~1之间的小数
random.random() eg: print(random.random())
2.随机返回指定区间的整数(包含首尾)
random.randint(起始数,终止数) eg: print(random.randint(1, 6))
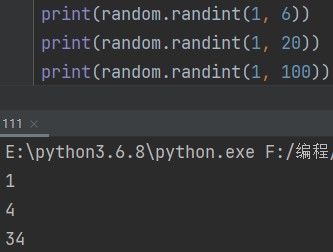
想必大家已经看出来了,没错,这个用法就是投骰子。游戏中的各种随机数判定也基本都是用这个模块来完成的。
3.随机抽取一个元素
random.choices([元素1,元素2……]) eg: print(random.choices(['一等奖','二等奖','谢谢回顾']))
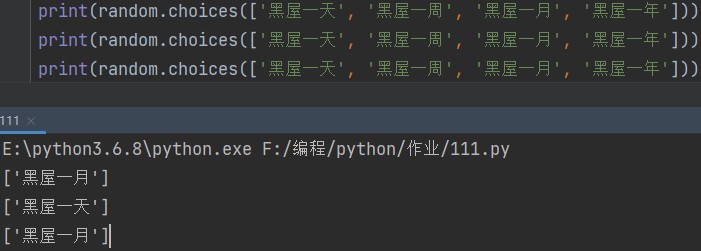
这让我回想起了学校小卖部卖的各种小玩具抽奖。
4.随机抽取指定样本个数
print(random.sample([111, 222, 333, 444, 555, 666, 777], 2))
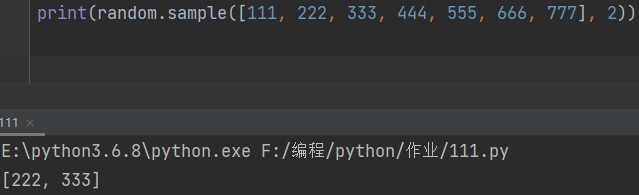
5.随机打乱元素
random.shuffle(需打乱的列表) eg: l = [2, 3, 4, 5, 6, 7, 8, 9, 10, "J", "Q", "K", "A", "小王", "大王"] random.shuffle(l) # 打乱列表l中元素的排列顺序 print(l)
可以看出来,列表l中的数据都来自于扑克牌。利用这条语句确实可以写出棋牌中洗牌的操作了。
根据上面这些random模块,实际上我们已经能够做出一款随机产生验证码的小程序了。
小练习
产生一个五位数随机验证码,每一位都可以是数字\小写字母\大写字母(这道题是搜狗笔试题)。
import random def get_code(n): code = '' for i in range(n): # 循环五次决定是几位验证码 # 每一次循环都应该是三选一 # 随机的数字 random_int = str(random.randint(0, 9)) # 随机的小写字母 random_lower = chr(random.randint(97, 122)) # 随机的大写字母 random_upper = chr(random.randint(65, 90)) # 随机选择一个作为一位验证码 temp = random.choice([random_int, random_lower, random_upper]) code += temp return code print(get_code(5))
logging模块
这是一款日志模块。
import logging
1.显示日志
现在我们来看一下如何让python自动记录日志。
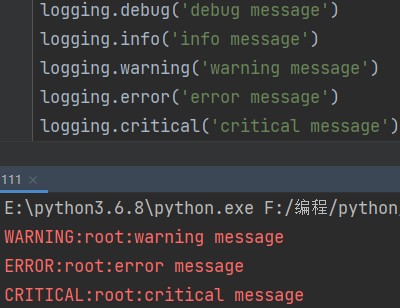
写了五条指令怎么只显示了三条?
这是因为日志在记录是存在等级的概念。
# 日志的级别 logging.debug('debug message') # 调试信息 logging.info('info message') # 正常信息 logging.warning('warning message') #警告信息 logging.error('error message') # 报错信息 logging.critical('critical message') # 事故信息
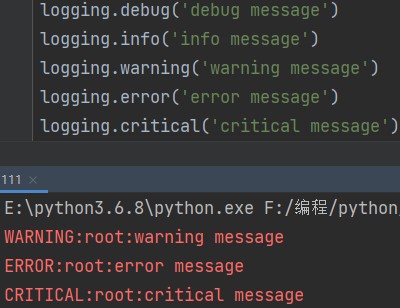
这五个等级从低到高依次递进,最低的两级因为不涉及出错,所以不显示。
2.日志配置(了解)
file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf-8',) # 定义文件名,读写模式,字符编码 logging.basicConfig( format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', # 定义警报格式 datefmt='%Y-%m-%d %H:%M:%S %p', # 定义时间格式,其中%p也是时间模块中会的时间关键词——上下午 handlers=[file_handler,], level=logging.ERROR # 定义日志级别 ) logging.error('警告') # 定义警报内容
最后生成的警报如图所示:

3.日志切割(了解)
为了便于保存和日后查找,我们规定每一篇日志写入一定量的数据。
import time import logging from logging import handlers sh = logging.StreamHandler() rh = handlers.RotatingFileHandler('myapp.log', maxBytes=1024,backupCount=5) # 定义日志保存文件夹名,最大字节数,每个文件日志保存数 fh = handlers.TimedRotatingFileHandler(filename='x2.log', when='s', interval=5, encoding='utf-8') # 定义文件名,when=s这个不用管照抄就行,设定日志级别数,字符编码 logging.basicConfig( format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', # 定义警报格式 datefmt='%Y-%m-%d %H:%M:%S %p', # 定义时间格式 handlers=[fh,sh,rh], level=logging.ERROR ) for i in range(1,100000): time.sleep(1) logging.error('KeyboardInterrupt error %s'%str(i))
在程序运行时可以看到底下的运行框里会刷新红色的提示信息。
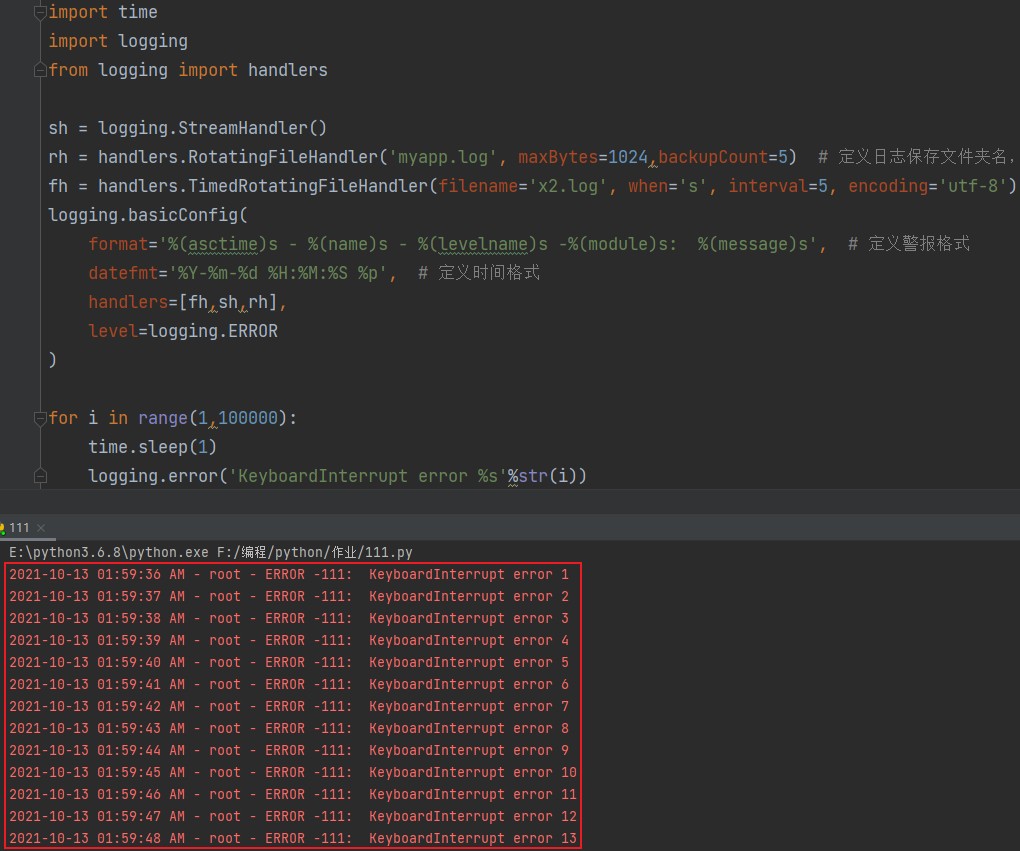
让程序写一点日志然后就可以暂停了,我们看看pychram主界面左边的文件框里有何变化。
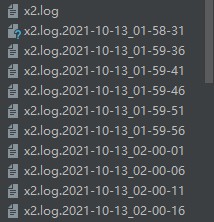
多出来了许多保存着日志的文件。
4.配置多等级日志
import logging logger = logging.getLogger() # 创建一个handler,用于写入日志文件 fh = logging.FileHandler('test.log',encoding='utf-8') # 再创建一个handler,用于输出到控制台 ch = logging.StreamHandler() formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') fh.setLevel(logging.DEBUG) fh.setFormatter(formatter) ch.setFormatter(formatter) logger.addHandler(fh) #logger对象可以添加多个fh和ch对象 logger.addHandler(ch) logger.debug('logger debug message') logger.info('logger info message') logger.warning('logger warning message') logger.error('logger error message') logger.critical('logger critical message')

其实这个模块连正经python程序员都很少用到,所以不要求我们牢牢掌握,只要了解即可。
json模块
这是一款序列化模块。
什么是序列化?可以简单地理解为将字典、列表等数据类型转换成字符串,或者将字符串转换成其他数据类型的过程。
理论定义比较复杂,我们还是根据一道示例来参悟。
d = {'username': 'jason', 'pwd': 123}
需求:将字典d保存入文件中,并且要保证从文件中取值后仍然是字典数据格式。
字典不能直接写进文本里,不然会直接报错。
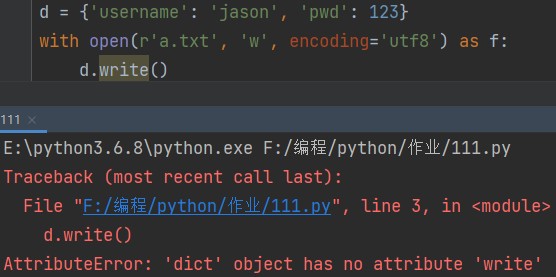
所以目前来看,这个需求没法实现。
为了解决这种窘境,于是就诞生了json模块。它的功能就是将其他数据类型转换成json格式的字符串。
1.序列化
反序列化:将其他数据类型转换成json格式的字符串。
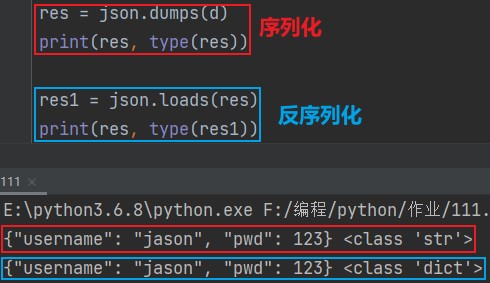
import json res = json.dumps(d) print(res, type(res)) # {"username": "jason", "pwd": 123} <class 'str'>
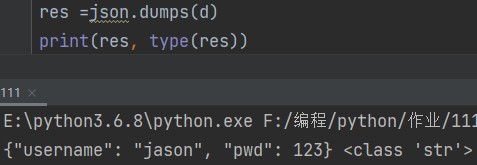
看起来好像除了数据类型变成了字符串类型,好像也没什么改变。
但是需要注意的是,其中的引号也被替换成了双引号。并且只有json格式字符串才是双引号。
可是我们不是可以自由选择书写单引号还是双引号吗?怎么这里双引号又变成json格式专用了?
不要被双眼和惯性思维蒙蔽,我们用双引号来重新写一个字典,然后打印下看看。
d1 = {"username": "jason", "pwd": 123}
print(d1)
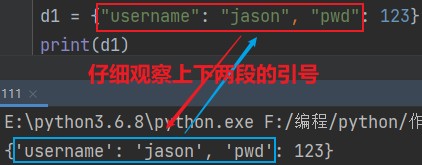
即便我们书写了双引号,在python中依然会被自动优化为单引号。
所以再度重申:只有json格式字符串才是双引号,双引号就是判断json格式字符串的重要依据。
2.反序列化
上面我们已经将字典序列化成了json格式的数据,那么接下来就该讲讲怎么把json格式的数据反序列化为原先的字典了。
反序列化:将json格式字符串转换成对应的数据类型。
res1 = json.loads(res) print(res1, type(res1)) # {'username': 'jason', 'pwd': 123} <class 'dict'>
3.文件序列化
with open(r'a.txt', 'w', encoding='utf8') as f: json.dump(d, f) # 将列表d写入文件中

用的是双引号,就表明加密成json格式的数据了。
4.文件反序列化
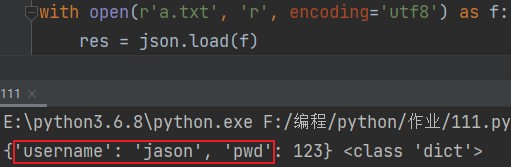
with open(r'a.txt', 'r', encoding='utf8') as f: res = json.load(f) print(res, type(res))
注意:一个json文件只能放一个字符串。
在编程领域,除了python之外编程语言是有很多的,比如说Js语言、C语言等等。
但如果我从电脑上将一个python程序甚至只是符合python语法格式的字典发送到网上,就经常有人会抱怨下载下,来的程序也不能用其他语言将其打开。
解决方法:
1.要么找翻译
2.互相用共同语言进行交流
如果想要实现不同编程语言环境下的交流,那么这个文件就需要使用js数据格式。
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+---------------+
| list, tuple | array |
+-------------------+---------------+
| str | string |
+-------------------+---------------+
| int, float | number |
+-------------------+---------------+
| True | true |
+-------------------+---------------+
| False | false |
+-------------------+---------------+
| None | null |
+-------------------+---------------+

 浙公网安备 33010602011771号
浙公网安备 33010602011771号