【【以鸢尾花数据集为例,执行决策树模型】】
from sklearn import datasets
import numpy as np
iris = datasets.load_iris() //导入sklearn 包中自带的鸢尾花
数据集,这是一个包含了三种鸢尾花(山鸢尾、维吉尼亚鸢尾和变色鸢尾)的各50个数据样本的多元数据集,每个样本都有四个特征(或者说变量)。
data= iris.data // n行4列的数组(样本量为n)
target= iris.target // 1行n列的数组,unique取值为0,1,2
from sklearn.model_selection import cross_validate
from sklearn.model_selection import train_test_split
train, test, t_train, t_test = train_test_split(data, target,test_size=0.2, random_state=0)
# target:所要划分的样本结果。
# test_size:样本占比,如果是整数的话就是样本的数量。
# random_state:随机数种子,在需要重复试验的时候,保证得到一组一样的随机数。比如每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。
#stratify:是为了保持split前类的分布。将stratify=X就是按照X中的比例分配 ,将stratify=y就是按照y中的比例分配 。
from sklearn import metrics
from sklearn.tree import DecisionTreeClassifier //导入决策树模型
model = DecisionTreeClassifier()
model.fit(train,t_train) //第一个数组为训练数据,第二个数组为类别标签
expected = t_test
predicted = model.predict(test) //使用决策树模型来预测,获得预测值
# summarize the fit of the model
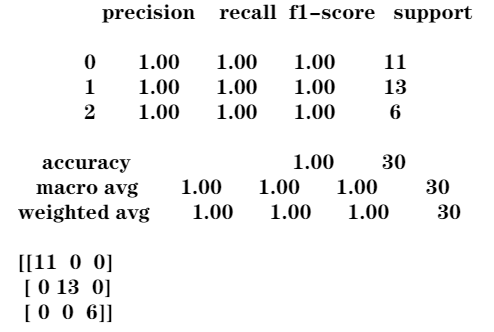
print(metrics.classification_report(expected, predicted)) //报告精确度、召回率、F1指数、准确度
print(metrics.confusion_matrix(expected, predicted)) //报告n行n列的数组,行为预测标签,列为实际标签
//报告结果//
False Negative和False Positive都为0,测试集的所有样本都得到了正确的预测
测试集中有11个0类,13个1类,6个2类,预测标签与实际标签全部一致
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号