04_data特征预处理 of 特征工程 【day1】
0、Xmind

1、data的特征预处理
1、what is 特征处理?
统计方法,要求的data

2、 特征预处理的方式

3、sklearn.preprocessing
there are all 预处理 method
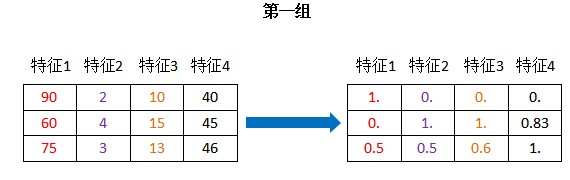
2、归一化
1. what is 归一化?
原始data -----变换、映射----> [0,1]

2. 公式

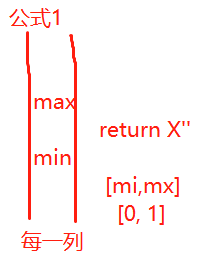
计算过程
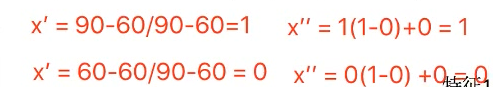
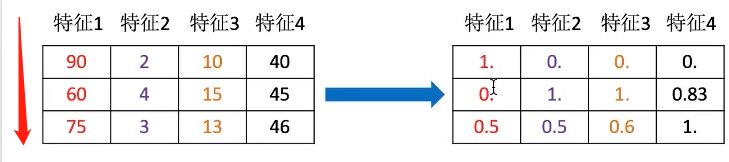
3. sklearn.preprocessing.MinMaxScalar
sklearn.preprocessing.MinMaxScalar
scalar缩放
语法

步骤
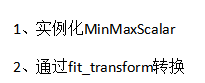
input:二维array
代码
from sklearn.preprocessing import MinMaxScaler # 归一化 def minmaxSclar(): """ 归一化处理 :return: None """ # mm = MinMaxScaler() mm = MinMaxScaler(feature_range=(2,3)) data = mm.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46]]) print(data) if __name__ == '__main__': minmaxSclar()

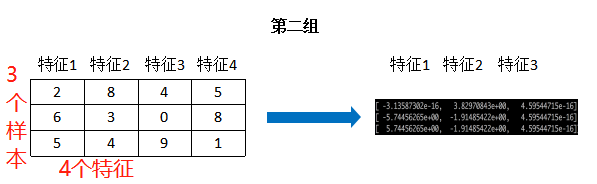
4.案例:约会对象data

三个特征同等重要的时候,进行归一化

目的:
使得某一个特征对result不会造成更大的影响
5.异常点
![]()
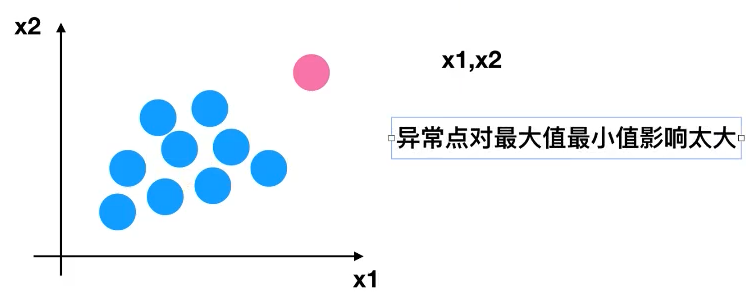

6. 归一化总结
鲁棒性较差 (稳定性不行)
传统精确小data场景 (基本无)

3、标准化
1、 what is 标准化?
原始data ----> 均值为0,方差为1

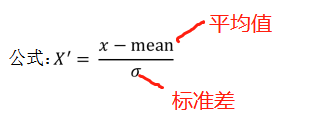
2、公式


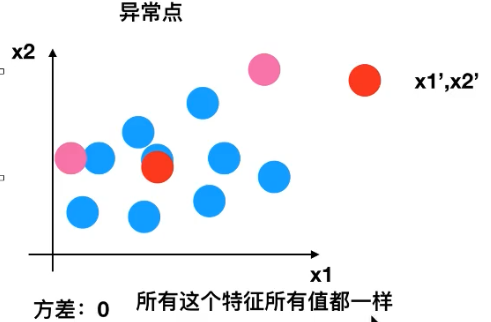
3、异常点
对mean影响不大
方差为0,所有这个特征的值基本一样

4、scikit-learn.preprocessing.StandardScalar
standard 标准化 scalar 缩放
data聚集zai 均值为0 方差为1的附近
语法

步骤
input 二维array

代码
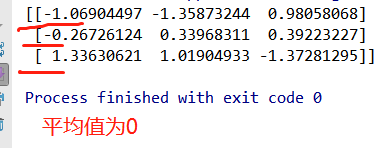
from sklearn.preprocessing import StandardScaler # 标准化 def stand(): """ 标准化缩放 :return:None """ std = StandardScaler() data = std.fit_transform([[ 1., -1., 3.],[ 2., 4., 2.],[ 4., 6., -1.]]) print(data) if __name__ == '__main__': stand()
5.总结

4、缺失值
1.如何处理数据中的缺失值?方法

2.sklearn.preprocessing.Imputer
语法

missing_values 缺失值为空值
strategy 填补策略
axis 1/0 行/列

流程

代码
import numpy as np from sklearn.preprocessing import Imputer # 缺失值 def im(): """ 缺失值处理 :return: None """ # NaN,nan 空值 im = Imputer(missing_values="NaN",strategy="mean",axis=0) data = im.fit_transform([[1, 2], [np.nan, 3], [7, 6]]) print(data) return None if __name__ == '__main__': im()
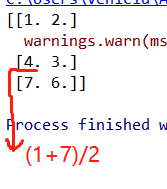
3.关于np.nan(np.NaN)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号