寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践W班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 1.阅读《构建之法》并提问 2.设计一个程序,能够满足一些词频统计的需求。 |
| 其他参考文献 | 《构建之法》... |
part1:阅读《构建之法》并提问
基本要求
第一题
主治医师模式的退化: 在一些学校里, 软件工程的团队模式往往退化为“一个学生干活, 其余学生跟着打酱油”
主治医师模式运用到极点, 可以蜕化为明星模式, 在这里明星的光芒盖过了团队其他人。
如何让团队的利益最大化, 而不是明星的利益最大化? 如何让团队的价值在明星陨落之后仍然保持?
主治医师模式可以表述成一个人主导,其他人都是为他辅助,一般情况下,这个主治医师应该有相当大的权威性。第一句话中:我认为学生团队中应该不会存在这种情况,每个人之间都是平等的,一个人的能力再强,其他人可能也有不同的意见。而且如果辅助主治医师的人都打酱油了,主治医师的活就干不下去了。所以我认为这里说到的退化并不是很合理;第二句话中:我认为主治医师模式一定会是明星模式。而不是运用到极致;第三句话不是很明白,明星的利益对应的是什么,明星陨落后还是明星模式吗,要让团队的利益最大化,在这种模式下,应该是要么让明星更亮,要么让其他人更亮。那么应该考虑的是如何在明星的影响下,提高其他人的能力,类似于鲶鱼效应。
第二题
其实, 大部分成功的创新者都不是先行者, 例如搜索引擎, Google 是很晚才进入这个领域的。 例如APPLE 的音乐播放器 iPod. 它是2001 年10 月23 日发布的, 在它之前市面上已经有很多产品了。
Google在搜索引擎领域,苹果在音乐播放器领域都不是先行者的话,那么他们为什么能够赶上其他竞争者,最终可以说是成为了该行业的标杆呢?在创新-王屋村的魔方们一章中,有提到:
- 当市场处于饱和状态, 这时的后来者 (second mover) 要赶上领先者, 必须要花很多心思改变游戏规则。
那么Google和苹果是怎么改变游戏规则的?我认为还是创新。如iPod,它的创新点不在于发明了音乐播放器,而是改进它。更大的硬盘容量,更简洁美观的外形设计,与华纳音乐合作解决音乐版权问题。更早出的Rio便携式MP3只能储存24首歌,并且被诉讼侵权。这些创新使得它能够在市场中脱颖而出。
第三题
软件行业的竞争有”赢者通吃”的规律
为什么说软件行业赢者通吃?像电商领域,市场上就有淘宝,京东,拼多多等大公司,并且都发展的不错。赢者通吃那不是会形成垄断吗?我查了资料,有这些说法:所谓赢者的意思就是占据了大部分市场份额,当你占据了大部分市场份额就说明你拥有了话语权。比如操作系统,用的人多那提供软件的人就多,受益的就是消费者,消费者受益了就会宣传这个操作系统,这个操作系统用的人就更多,这是一个相对良性的循环。那剩下的竞争者市场份额就会越来越小,乃至最终消失。在这种行业规律下,应该防止这些大型企业形成垄断优势,阻碍公平竞争,获取超额收益。
第四题
如果你的团队很弱, 那么强行把Scrum (或者其它高级方法)套在上面也没有用, 也许还会适得其反,往往需要多次Sprint 才能让Scrum 走上正轨。换句话说, 如果你的团队已经是这么厉害 (self-managing, self-organizing, cross-functional)的一帮人, 那么用不用Scrum 都能写好软件!
在阅读这一章的时候,SCRUM MASTER这个词出现多次,但是没有解释是什么意思。我查了资料,它的意思是这样的:敏捷专家或者敏捷大师,即熟悉敏捷开发模式及敏捷实施流程的人员。一般可由敏捷团队当中的开发负责人担任,最好都是由技术能力较强的人员担任。还有一个问题是上面描述中,SCRUM不适合用在弱的团队中,厉害的团队也不需要SCRUM,那么SCRUM的意义是什么?我查了资料,有这样的说法:Scrum,就是为了保护“猪”这种角色,兼顾“鸡”的感受,从而确保整个项目正常交付。它是一套敏捷开发流程。我的理解是这个流程是为了让员工自己管控自己,减少项目经理等角色的影响,然后这个开发过程由master来管控,并且多次迭代周期也符合敏捷的思想,能够需求求迅速变化情况下也能顺利进行下去。弱的团队可能自控能力不足,效率就会较低。
第五题
结对编程有如下的好处:
(1)在开发层次,结对编程能提供更好的设计质量和代码质量,两人合作能有更强的解决问题的能力。
(2)对开发人员自身来说,结对工作能带来更多的信心,高质量的产出能带来更高的满足感。
(3)在心理上, 当有另一个人在你身边和你紧密配合, 做同样一件事情的时候, 你不好意思开小差, 也不好意思糊弄。
(4)在企业管理层次上,结对能更有效地交流,相互学习和传递经验,能更好地处理人员流动。因为一个人的知识已经被其他人共享。
如果结对合作有这么多的好处,而且磨合期不会很长,那么是否要优于团队合作?俗话说:一个和尚挑水吃,两个和尚抬水吃,三个和尚没水吃;两个人的效率要高于一个人,省力,而多个人磨合期一定比两人长,效率就会降低。但是,在大的项目中,两个人的能力往往是不够的,这时候就需要团队合作,那么如果在团队合作中用上结对合作,是否能够减少磨合期的长度,使得效率提高呢?
附加题
史上第一款电脑病毒,竟然是由防御技术专家Fred Cohen亲手设计出来的。他创造电脑病毒的目的仅仅是为了证明程序对电脑感染的可行性,从未希望借此对电脑造成任何危害。但这款程序却能够对电脑进行感染,并且能通过软盘等移动介质在不同计算机之间进行传播,因而命名为病毒。后来,他又创造出一种主动式电脑病毒,主要目的是帮助电脑用户找到未受感染可执行文件。
part2:WordCount编程
Github项目地址
PSP表格
| Personal Software Process Stages | 预估耗时(分钟)| 实际耗时(分钟)
--|:--😐--😐--:
Planning|计划|30|
Estimate|估计这个任务需要多少时间|30|
Development|开发|1500|
Analysis|需求分析 (包括学习新技术)|40|
Design Spec|生成设计文档|10|
Design Review|设计复审|20|
Coding Standard|代码规范 (为目前的开发制定合适的规范)|40|
Design|具体设计|40|
Coding|具体编码|800|
Code Review|代码复审|30|
Test|测试(自我测试,修改代码,提交修改)|480|
Reporting|报告|10|
Test Repor|测试报告|10|
Size Measurement|计算工作量|10|
Postmortem & Process Improvement Plan|事后总结, 并提出过程改进计划|10|
||合计|1560|
解题思路
要实现四个功能,统计字符、单词、行数和词频top10。首先要从文件中读入数据,可以采用BufferedReader来读取(查阅资料:BufferedReader会一次性从物理流中读取8k(默认数值,可以设置)字节内容到内存,对物理流的每次读取,都有IO操作。IO操作是最耗费时间的。)读入后可对数据进行操作,统计字符可读入一个字符,计数器加1;统计单词可读入一段字符串至碰到非数字或字母,就该字符串判断是否为单词,判断是否为单词,可采用正则表达式或if语句;统计行数也可使用正则表达式或if语句;(查阅资料:正则表达式(Regular Expression)是用于描述一组字符串特征的模式,用来匹配特定的字符串。)统计词频top10要将单词和出现次数相对应,可采用HashMap,以键值对的形式保存,对填充完单词的HashMap进行排序(查阅资料:1、将map.entrySet()转换成list 2、通过StreamApi进行排序处理 3、TreeMap的自动排序);最后将所有统计数据写入输出文件中,依然采用BufferedWriter进行缓冲字符流操作。
代码规范制定链接
设计与实现过程
类和函数的设计
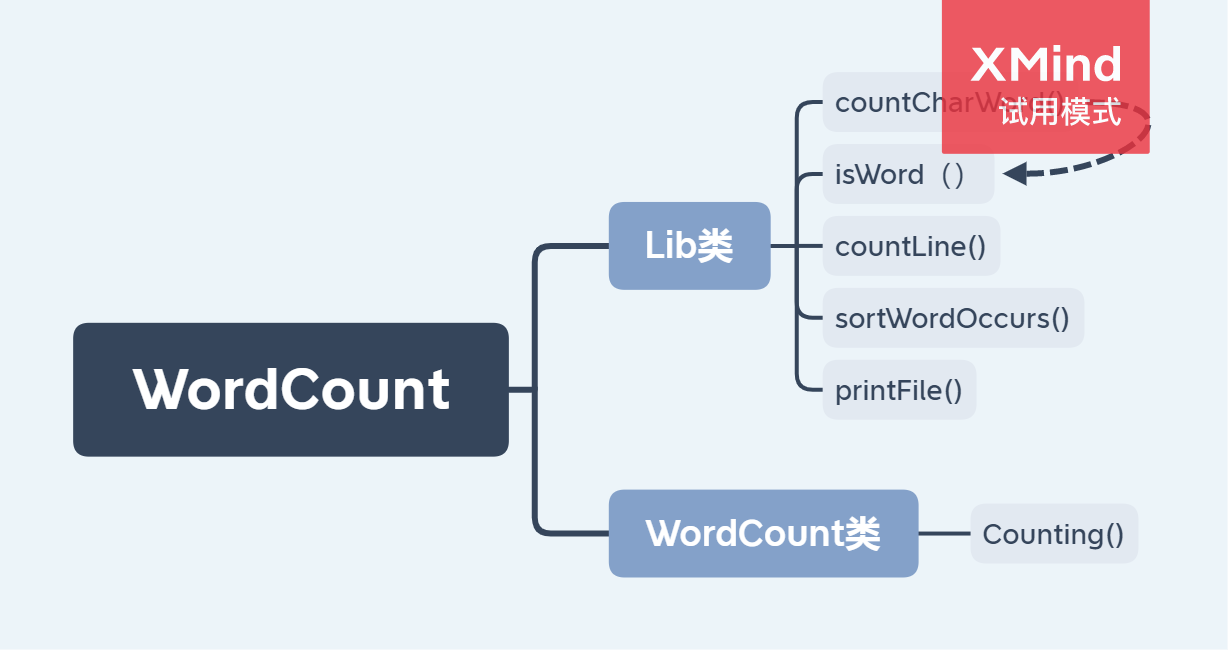
Lib类中将统计字符和单词的功能合并,因为统计字符过程较为简单,而且两个功能合并后只需要遍历一遍文件数据,即可统计完,可提高效率。因为本次要求中只出现ASCII码 0~127,所以可直接读入时就判断是否符合字符的要求,统计单词即以非数字或字母字符为分割点,判断是否符合单词要求,符合则转化为小写后填入HashMap中,一直循环至文件结束。
public void countCharWord() throws IOException {
......
while((str=reader.read()) >= 0 && str <= 127 ) {
charCount++;
builder.append((char)str);
if (Character.isLetterOrDigit(str)) {
buffer += (char)str;
}
else {
if (isWord(buffer)) {
wordCount++;
String lowerBuffer = buffer.toLowerCase();
if (hashMap.containsKey(lowerBuffer)) {
int occurs = hashMap.get(lowerBuffer);
hashMap.put(lowerBuffer, occurs+1);
}
else {
hashMap.put(lowerBuffer, 1);
}
lowerBuffer = "";
}
buffer = "";
}
}
reader.close();
}
单词判断方法:正则表达式(性能改进前)
if(buffer.matches(WORD_REGEX_RULE))
return true;
else
return false;
统计行数方法:正则表达式
注:之前使用过String.IndexOf('\n', position)) != -1方法遍历字符串判断换行符\n的位置来统计行数,性能较正则表达式要好,但是发现不能排除空行,弃之。
public void countLine() throws IOException {
Matcher matcher = linePattern.matcher(builder);
while (matcher.find()) {
lineCount++;
}
}
排序HashMap方法:通过Stream进行排序处理
public void sortWordOccurs() {
hashMaps = hashMap.entrySet().stream()
.sorted(Map.Entry.<String, Integer>comparingByValue()
.reversed().thenComparing(Map.Entry.comparingByKey())).limit(MAX_NUM)
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue
, (e1, e2) -> e1, LinkedHashMap::new));
List = new ArrayList <HashMap.Entry <String, Integer> > (hashMaps.entrySet());
}
最后是将统计结果输出:
public void printFile() throws IOException {
writer=new BufferedWriter(new FileWriter(fileOutPath));
writer.write("characters: " + charCount + "\n");
writer.write("words: " + wordCount + "\n");
writer.write("lines: " + lineCount + "\n");
for(HashMap.Entry<String, Integer> map : List) {
writer.write(map.getKey() + ": " + map.getValue() + "\n");
}
writer.close();
}
性能改进
- 在使用正则表达式时,利用好其预编译功能有效加快正则匹配速度。而不在方法体内定义
private static final String LINE_REGEX_RULE = "(^|\n)\\s*\\S+";
private static final Pattern linePattern = Pattern.compile(LINE_REGEX_RULE);
- 将原来统计行数中的BufferedReader去掉改为在统计字符时就维持一个StringBuilder。io操作只需要进行一次。统计50万字符数较进行两次提升27%。
3.将判断单词是否符合要求的方法由正则表达式匹配->if语句判断字符数组
if (buffer.length() >= 4) {
char buf[] = buffer.toCharArray();
for (char temp : buf) {
if (!Character.isLetterOrDigit(temp)) {
return false;
}
}
return true;
} else {
return false;
}
统计5000万字符数由7.345提升至4.074左右。


单元测试
因为是补交的作业,所以很幸运的一点是可以用助教发的答案用例来测(误)
于是就发现了问题!!!判断单词是否符合要求的isWord()函数有误,更正为:
if (buffer.length() >= 4) {
char charArrayBuf[] = buffer.toCharArray();
for (int i = 0; i < 4; i++) {
if (!Character.isLetter(charArrayBuf[i])) {
return false;
}
}
return true;
} else {
return false;
}
改正后十个样例都通过了
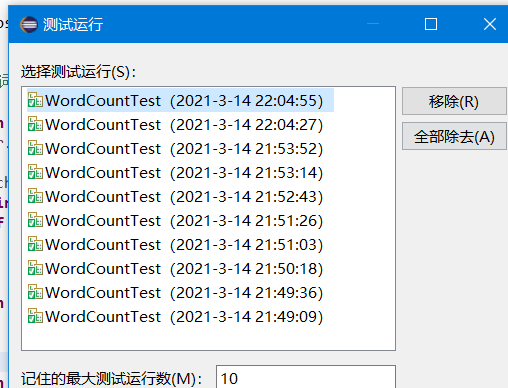
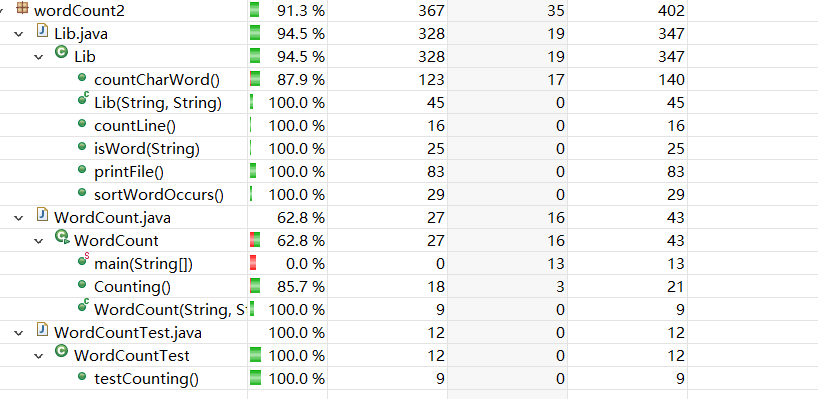
覆盖率截图
异常处理说明
主要是IOException,文件读取可能失败(文件不存在等原因)。
测试方法:将输入文件路径指向一个不存在的文件

心路历程
作业刚发布的时候,由于春节期间事情比较多加上拖延症晚期,我没有及时的去查看作业想着如何完成,结果就那么不凑巧碰上生病住院。结果没能及时提交作业,一直拖到现在。这件事给我的感受就是,要好好利用每一天,不要一直拖延想着在ddl前交完就行,因为你不知道会不会有意外发生。然后在补作业的这几天,发现一直以为这次作业最重要的部分耗时最多的应该是编程,结果在任务一提出问题、代码的性能优化和单元测试上会花费很多时间。要会提出问题,提出后要理解要查资料,而且往往是找不到答案的。而在性能优化上一点点来回改动,可能耗了好久,发现原来的更好或者路走不通(比如试图在统计字符、单词、行数上搞成多线程,从其他同学的评论区得知最好不要使用excutors创建线程池,但是用其他方法如何使得线程之间同步,试过join,但是出错了),就很浪费时间,虽然最后改动地方不多,但是耗的时间却很长,也可能是能力不足,效率不高的原因吧。
收获
- 这次作业不仅按要求完成编程的任务,还体验了性能优化和单元测试的过程。
- 学会了用JUnit4,测试很方便。
- 学会了githubdesktop,如何commit,进行版本控制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号