
起因
公司内部需要实现一个量子算法(量子真机),需要使用对称矩阵的矩阵特征值与特征向量的分解算法,我尝试了go语言原生包:gonum,实测边长为1000的矩阵需要的时间为10分钟以上,于是开始寻求c语言或者c++编写的并行算法,首先尝试了OpenBlas,对接用了差不多一星期(因为我不熟悉cgo,太菜),实测边长为10000的矩阵求解时间是两个半小时,只测了一次我就知道不行,因为团队里的另一位工程师用matlab只需要一分钟左右就可以求解相同的矩阵,于是转变思路开始集成cuda的算法,尝试使用gpu进行求解。
算子
cuda算子在windows系统上比较恶心,它对于cuda版本有严格的要求(我用的版本是cuda12.8版本,为了编译时能够兼容更多的版本,所以只能用最新版cuda),不过幸好还有visual studio可以救一手,下面直接贴cuda代码:
//Kernel.cu
#include "Kernel.cuh"
#include <stdio.h>
extern "C" __declspec(dllexport) int computeEigen(float* h_matrix, float* h_eigenvalues, float* h_eigenvectors, int n) {
cusolverDnHandle_t handle;
cusolverStatus_t status = CUSOLVER_STATUS_SUCCESS;
cudaError_t cudaStat;
// 创建cuSOLVER句柄
status = cusolverDnCreate(&handle);
if (status != CUSOLVER_STATUS_SUCCESS) return -1;
// 分配设备内存
float* d_matrix, * d_eigenvalues, * d_work;
int* d_info, lwork;
cudaStat = cudaMalloc((void**)&d_matrix, n * n * sizeof(float));
cudaStat = cudaMalloc((void**)&d_eigenvalues, n * sizeof(float));
cudaStat = cudaMalloc((void**)&d_info, sizeof(int));
if (cudaStat != cudaSuccess) { cusolverDnDestroy(handle); return -2; }
// 数据拷贝到设备
cudaMemcpy(d_matrix, h_matrix, n * n * sizeof(float), cudaMemcpyHostToDevice);
// 计算工作空间大小
status = cusolverDnSsyevd_bufferSize(handle, CUSOLVER_EIG_MODE_VECTOR, CUBLAS_FILL_MODE_LOWER,
n, d_matrix, n, d_eigenvalues, &lwork);
if (status != CUSOLVER_STATUS_SUCCESS) { cudaFree(d_matrix); cusolverDnDestroy(handle); return -3; }
// 分配工作空间
cudaStat = cudaMalloc((void**)&d_work, lwork * sizeof(float));
if (cudaStat != cudaSuccess) { cudaFree(d_matrix); cusolverDnDestroy(handle); return -4; }
// 执行特征分解
status = cusolverDnSsyevd(handle, CUSOLVER_EIG_MODE_VECTOR, CUBLAS_FILL_MODE_LOWER,
n, d_matrix, n, d_eigenvalues, d_work, lwork, d_info);
// 同步设备并检查结果
int info;
cudaMemcpy(&info, d_info, sizeof(int), cudaMemcpyDeviceToHost);
if (info != 0 || status != CUSOLVER_STATUS_SUCCESS) {
cudaFree(d_work); cudaFree(d_matrix); cusolverDnDestroy(handle);
return (info < 0) ? -5 : -6; // 参数错误或收敛失败
}
// 拷贝结果回主机
cudaMemcpy(h_eigenvalues, d_eigenvalues, n * sizeof(float), cudaMemcpyDeviceToHost);
cudaMemcpy(h_eigenvectors, d_matrix, n * n * sizeof(float), cudaMemcpyDeviceToHost);
// 释放资源
cudaFree(d_matrix);
cudaFree(d_eigenvalues);
cudaFree(d_work);
cudaFree(d_info);
cusolverDnDestroy(handle);
return 0;
}
cuh头文件:
//Kernel.cuh
#pragma once
#include "cuda_runtime.h"
#include "cusolverDn.h"
extern "C" __declspec(dllexport) int computeEigen(float* h_matrix, float* h_eigenvalues, float* h_eigenvectors, int n);
编译
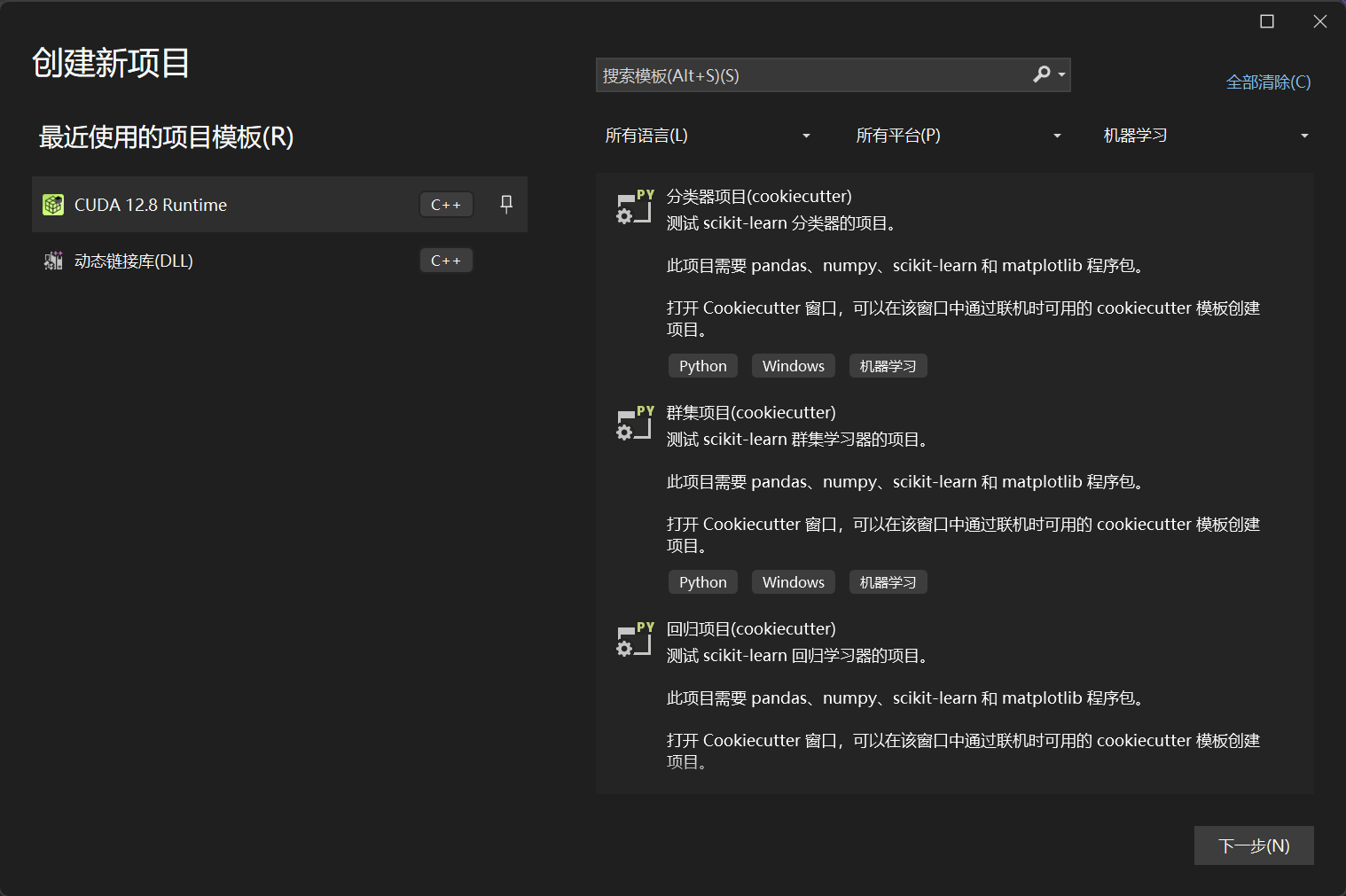
- 在vs中创建一个cuda项目
![image]()
- 将刚才的Kernel.cu代码直接粘贴到项目生成的Kernel.cu文件中,直接全部覆盖,如果有需要集成其他cuda算法的请找deepseek,让它给你生成个调用函数(乐)
![image]()
- 创建一个.cuh文件,然后把你引用到的包引用上,千万不要用尖括号的方式引用,容易出问题(也可能是我太菜~)。
![image]()
![image]()
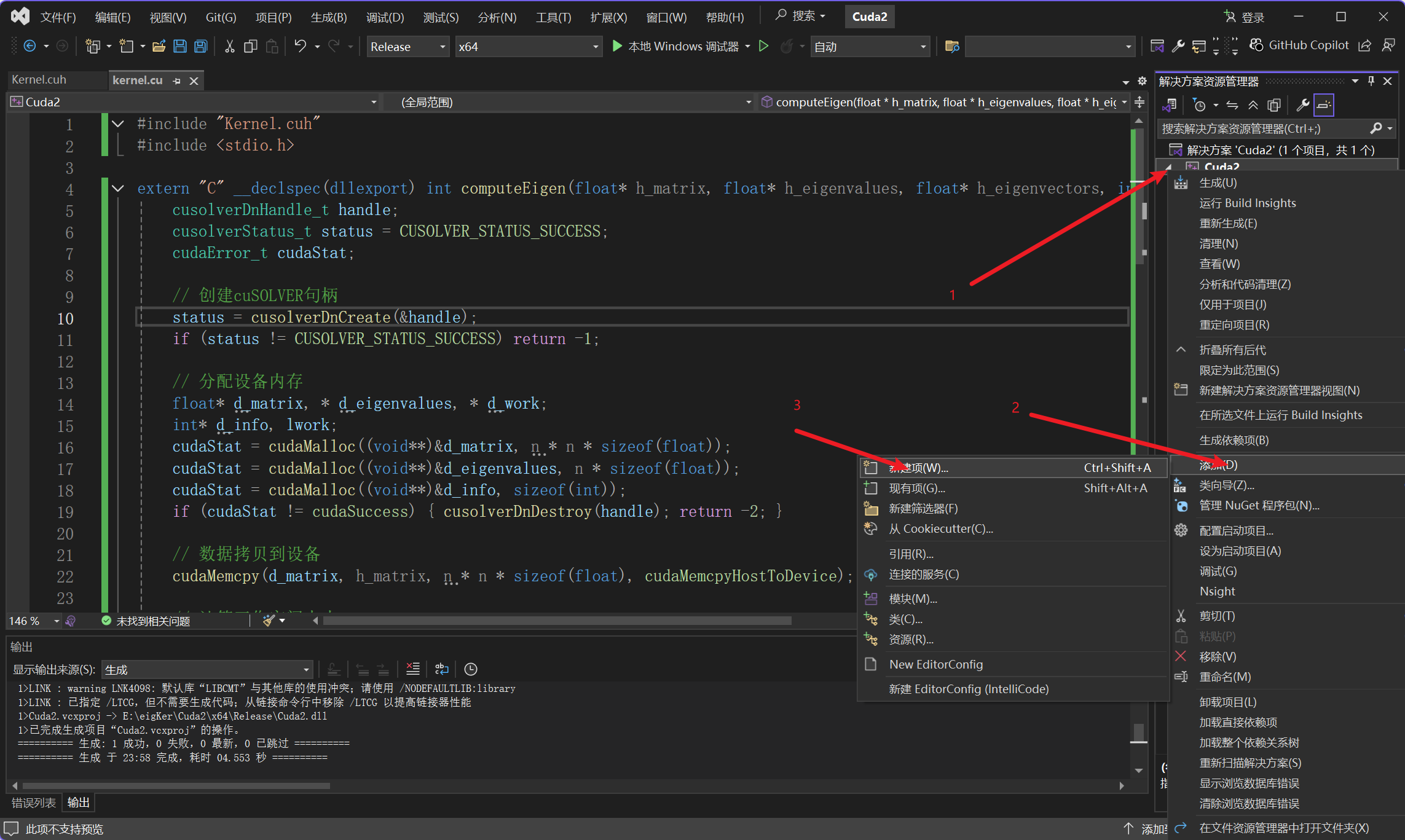
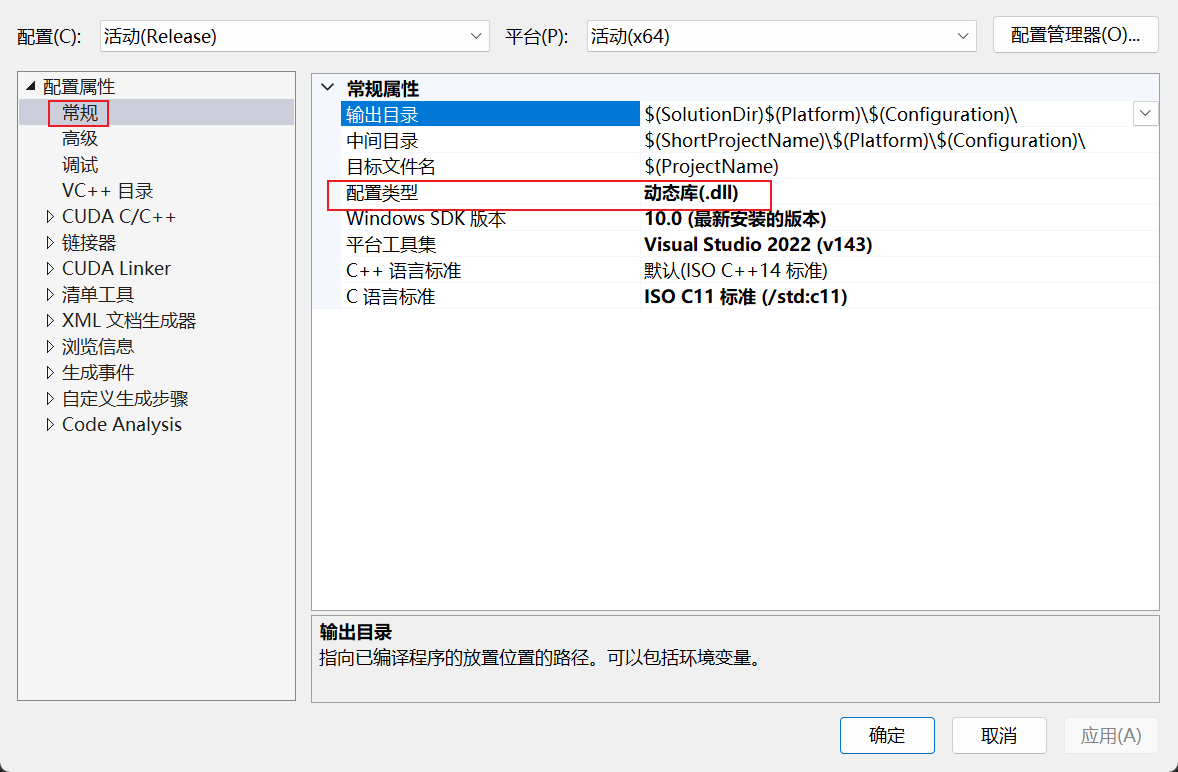
- 这一步非常重要,cuda自带的模板只会给你引入个runtime.lib库,编译的时候直接识别不到,除非你编译的是exe,exe是可以直接引用环境变量中的runtime.dll的,所以不会出异常,但我的最终目的是让其他语言引用,所以不可能使用exe的。所以首先,右键点击你项目的名字->单击属性->单击常规->配置类型选择dll
![image]()
![image]()
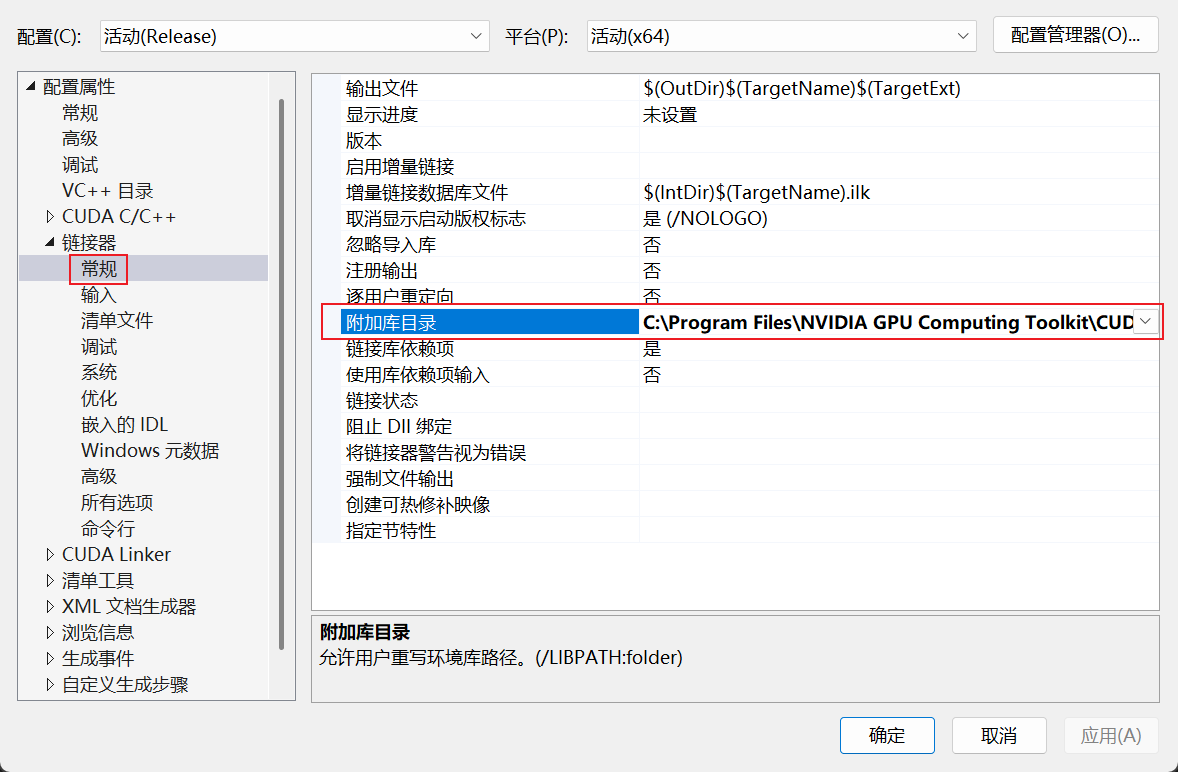
然后单击链接器->常规->附加库目录,添加自己的cuda toolkit的lib\x64或者lib\W32路径(其实我估计这一步不搞也行,模版里应该是自带了,只是你自己设置了之后原先的默认值会消失)
![image]()
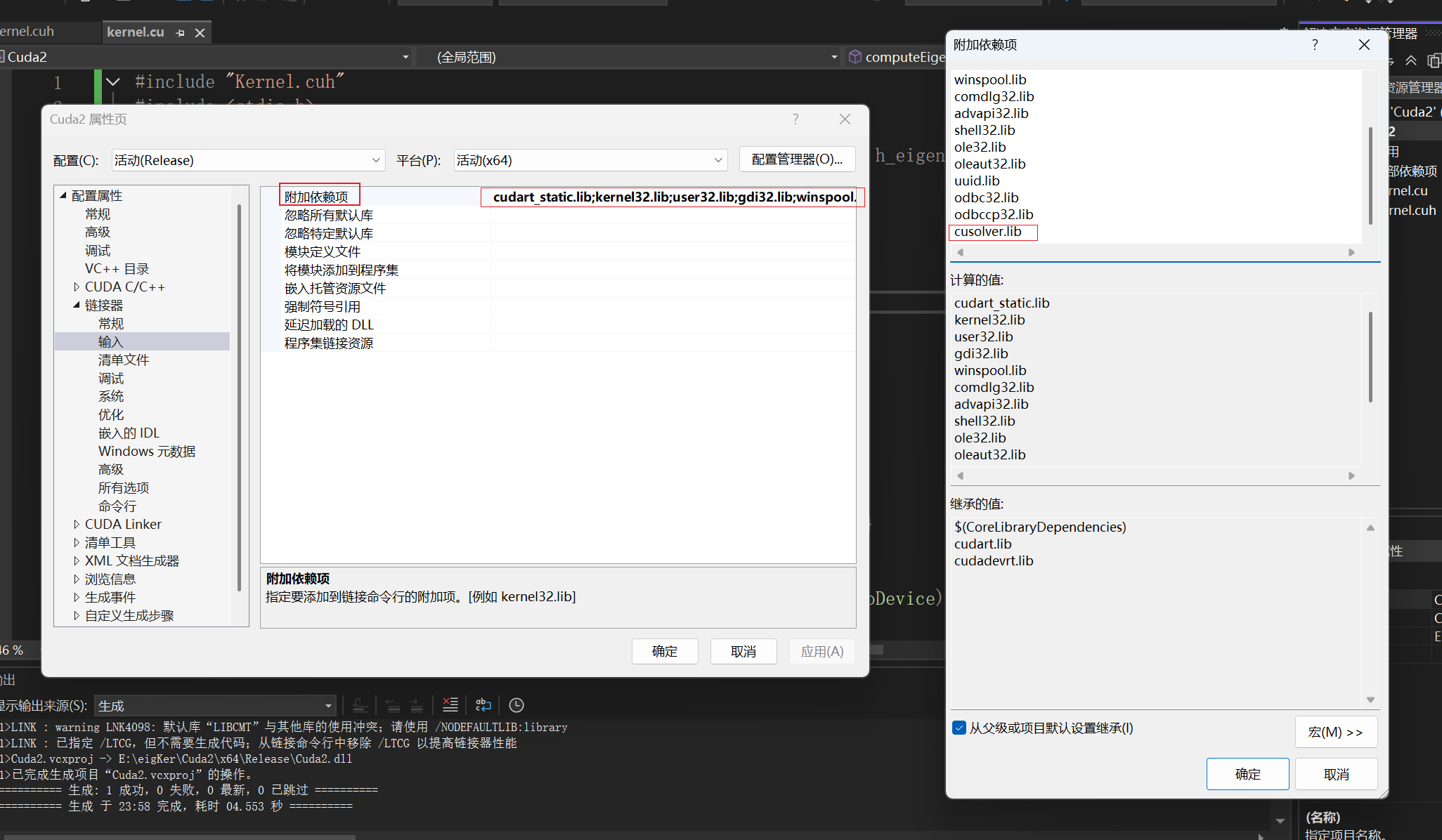
再然后,单击链接器下的输入->附加依赖项->编辑,把要引用的库加上,不知道自己引用哪个库的就看看引用的头文件,文件后半段有可能不一样,需要自己在cuda tookit的lib文件夹下面多找找,实在不行把.lib文件全加上肯定不出错(玩的就是个暴力)。
![image]()
- 设置完一定要点击应用再点击确定,要不然vs一关它再给你回退设置你就笑了。
- 接下来就简单了,右键解决方案'xxxxxx',点击生成解决方案,然后到项目下面有个x64文件夹(看你配置,上面工具栏有运行图标、Release/DeBug、编译平台等设置,默认应该是Debug和x64),往里面翻一翻就能看到dll。
- 然后就简单了,把你dll所在的那个文件夹扔到你的go语言项目目录下面,然后该怎么引用就怎么引用就完事了。
go语言编写
只有在函数前加上extern "C" __declspec(dllexport)才能在dll中导出函数,我第一次成功导出dll的时候试了半天报错0x0000005,用dumpbin /exports XXX.dll才知道是导出有问题(C++也没学明白~)。
接下来是go语言代码,不使用cgo,因为cuh文件无法被nvcc编译成.h文件,所以无法使用cgo进行引用。
//main.go
package main
import (
"fmt"
"runtime"
"syscall"
"unsafe"
)
func main() {
runtime.LockOSThread()
dllPath := "./libs/Cuda2.dll"
handle, err := syscall.LoadDLL(dllPath)
if err != nil {
fmt.Println(err.Error())
}
proc, err := handle.FindProc("computeEigen")
if err != nil {
fmt.Println(err.Error())
}
callByReference := proc
const size = 10240
blockSize := size / 2
matrix := make([]int, size*size) // 一维切片(列优先存储)
// 生成分块对角矩阵
for col := 0; col < size; col++ {
for row := 0; row < size; row++ {
// 判断是否属于左上或右下的 5x5 全1块
if (row < blockSize && col < blockSize) || (row >= blockSize && col >= blockSize) {
matrix[col*size+row] = 1 // 列优先索引公式
} else {
matrix[col*size+row] = 0
}
}
}
r1 := make([]float32, size*size)
r2 := make([]float32, size*size)
i1 := uintptr(unsafe.Pointer(&matrix[0]))
r11 := uintptr(unsafe.Pointer(&r1[0]))
r22 := uintptr(unsafe.Pointer(&r2[0]))
_, _, err = callByReference.Call(
i1,
r11,
r22,
size)
if err != nil {
fmt.Println(err.Error())
}
fmt.Println(r1[0])
fmt.Println(r2[0])
}
至此,go语言集成cuda完毕。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号