Python (NUDT&&educoder特别关心版)
Python (NUDT&&educoder特别关心版)
主题:浅谈程序设计与算法基础
(一份融合Io Wiki与educoder实训作业的整理笔记报告)
报告人:4p11b彭轩昂(这个不重要)
Part 1 总述与回顾(Overview and Review)
学习Python的优势
Python 的优点
-
Python 是一门 解释型 语言:Python 不需要编译和链接,可以在一定程度上减少操作步骤。
-
Python 是一门 交互式 语言:Python 解释器实现了交互式操作,可以直接在终端输入并执行指令。
-
Python 易学易用:Python 提供了大量的数据结构,也支持开发大型程序。
-
Python 兼容性强:Python 同时支持 Windows、macOS 和 Unix 操作系统。
-
Python 实用性强:从简单的输入输出到科学计算甚至于大型 WEB 应用,都可以写出适合的 Python 程序。
-
Python 程序简洁、易读:Python 代码通常比实现同种功能的其他语言的代码短。
-
Python 支持拓展:Python 会开发 C 语言程序(即 CPython),支持把 Python 解释器和用 C 语言开发的应用链接,用 Python 扩展和控制该应用。
-
Python 的设计理念和语法结构 与一些其他语言的差异较大,隐藏了许多底层细节,所以呈现出实用而优雅的风格。
For us :
-
写代码的时间开销要求,空间开销要求不高,不需要理解底层细节
-
期望写代码的代码复杂度和思维复杂度尽可能底(
重点) -
那么问题来了,面对一道题,如何尽快写出好的代码呢?
-
接下来,我们的工作就是找到写代码的思路,并总结归纳
Part 2 进入正题 一些炫技代码(My flashy code)
模拟
本块将简要介绍模拟算法。
简介
模拟就是用计算机来模拟题目中要求的操作。
模拟题目通常具有码量大、操作多、思路繁复的特点。由于它码量大,经常会出现难以查错的情况,如果在考试中写错是相当浪费时间的。
技巧
写模拟题时,遵循以下的建议有可能会提升做题速度:
-
在动手写代码之前,在草纸上尽可能地写好要实现的流程。(流程图题)
-
在代码中,尽量把每个部分模块化,写成函数、结构体或类。 (即面向对象,现阶段主要是函数)
-
对于一些可能重复用到的概念,可以统一转化,方便处理:如,某题给你 "YY-MM-DD 时:分" 把它抽取到一个函数,处理成秒,会减少概念混淆。
-
调试时分块调试。模块化的好处就是可以方便的单独调某一部分。
-
写代码的时候一定要思路清晰,不要想到什么写什么,要按照落在纸上的步骤写。
-
实际上,上述步骤在解决其它类型的题目时也是很有帮助的。
-
典型例题(浮点数、冯·诺依曼体系结构模拟、幻方)
例题1 浮点数
相关知识
提示:
myCoding库是专门为本实训编写的一个库,你可以根据需要使用库中函数:
ZhenToDing_int(z):将真实值z转换为原码形式的 8 位定点整数(即第 1 关任务),如z为'+10'时,返回值为'00000010';ZhenToDing_point(z):将真实值z转换为原码形式的 8 位定点小数(即第 4 关任务),如z为'-0.111'时,返回值为'11110000';YuanToBu(y):将 8 位原码y转换成 8 位补码(即第 3 关部分任务),如y为'11110000'时,返回值为'10010000'。编程要求
在 Begin-End 区间实现
ZhenToFu(z)函数,具体要求见上。测试说明
例如,测试集 1 的输入为:
-11.1测试集 1 的输出为:
-11.1 -> 00000010 10010000
开始你的任务吧,祝你成功!
from myCoding import *
N = 8 #位数为8
########## Begin ##########
def ZhenToFu(z):
if(z[0]=='0' or z[0]=='1'): z='+'+z
ans1,idx,ok1,ok2='',0,0,0
for i in range (len(z)):
if(z[i]!='+' and z[i]!='-' ):
if z[i]=='1' and ok1==0: ok1=1
if z[i]=='.' and ok1==0: ok1=-1
if z[i]=='1' and ok1==-1: ok2=1
if z[i]=='.' and ok1==1: ok2=1
if z[i]!='.' and (ok1==1 or ok2==1): ans1+=z[i] ## 确定尾数
if z[i]!='.' and ok1!=0 and ok2!=1: idx+=ok1 ## 确定阶码
jz=2 if idx>0 else 3
jz2='+' if idx>0 else '-'
ans=YuanToBu(ZhenToDing_int(jz2+bin(idx)[jz:]))+' '
ans+=YuanToBu(ZhenToDing_point(z[0]+'0.'+ans1)) ## 合并
return ans
########## End ##########
z = input() #真实值
f = ZhenToFu(z) #转换成浮点数
print('%s -> %s' % (z, f))
例题2 冯·诺依曼体系结构模拟 (
一个浪费寿命的题目)本关任务是将前面关卡的功能结合起来,模拟一个程序在 CPU 中的完整执行过程。
编程要求
仔细阅读右侧编辑器给出的代码框架及注释,在指定的 Begin-End 区间编写程序,将使用 TOY 计算机指令集编写的
.toy文件,根据给定的主存地址address加载到主存mem指定区域(连续存放),并控制 CPU 执行.toy文件中的程序代码,得到执行结果。 你需要补充完整 5 个函数:
- 函数
loadProgram(file, mem, address)实现程序加载功能:从主存mem的address地址开始存放file文件,无返回值。- 函数
fetch(mem, pReg)实现取指令功能:根据程序计数器给出的地址取出主存对应的指令放入指令寄存器,程序计数器自增 1,函数返回pReg和iReg的值。- 函数
decode(iReg)实现指令译码功能:解析指令寄存器中的指令,不存在的操作数置为None,函数返回操作码opcode,和 2 个操作数op1,op2。- 函数
execute(opcode, op1, op2, reg, mem, address)实现执行和写结果功能:根据指令解析的操作码执行对应的操作,若为停机指令返回False,其余指令返回True。特别说明: 1)执行跳转指令jmp和jz时,需要考虑程序中代码的逻辑地址(.toy 文件中指令前面的编号)和放入主存后的物理地址的不一致之处,两个地址间存在固定的偏移量差值(address); 2)指令mov1和mov2读写的是主存中存放的数据(不是指令),这里直接使用指令中给出的物理地址实现读写访问。- 函数
run(file, addr)实现完整过程模拟功能:程序加载、取指令、指令译码、指令执行和写结果,无返回值。注意,在执行程序前,需要将第一条指令代码在主存中的地址(即addr)放入程序计数器pReg中,为第一次取指令做好准备。#add.toy 000 mov3 1 12 001 mov3 2 13 002 add 1 2 003 out 1 004 halt开始你的任务吧,祝你成功!
#模拟 CPU 执行完整程序代码的全部过程
#初始化主存、通用寄存器、指令寄存器和程序计数器
mem = ['']*1000 #主存
reg = [0]*10 #通用寄存器
pReg = 0 #程序计数器
iReg = '' #指令寄存器
def loadProgram(file, mem, address):
txt = open(file,'r')
line = txt.read()
line = line.replace('\n',' \n ')
line = line.split(' ')
f=False
for i in range(len(line)):
if (line[i]!='' and line[i]!='\n'):
if mem[address] == '' and 1-f: f=True
elif f and mem[address] == '': mem[address] = line[i]
elif f: mem[address] = mem[address] + ' ' + line[i]
elif (line[i]=='\n'): address+=1;f=False
txt.close()
def decode(iReg):
tmp=iReg.split(' ')
if (len(tmp)==1): ans=(tmp[0],None,None)
if (len(tmp)==2): ans=(tmp[0],int(tmp[1]),None)
if (len(tmp)==3): ans=(tmp[0],int(tmp[1]),int(tmp[2]))
return ans
def execute(opcode, op1, op2, reg, mem, address):
global pReg
if opcode=='mov1': reg[op1] = mem[op2]
elif opcode=='mov2': mem[op1] = reg[op2]
elif opcode=='mov3': reg[op1] = op2
elif opcode=='add': reg[op1] = reg[op1]+reg[op2]
elif opcode=='sub': reg[op1] = reg[op1]-reg[op2]
elif opcode=='mul': reg[op1] = reg[op1]*reg[op2]
elif opcode=='div': reg[op1] = reg[op1]//reg[op2]
elif opcode=='jmp': pReg = op1
elif opcode=='jz' and reg[op1]==0: pReg = op2
elif opcode=='in': reg[op1] = int(input())
elif opcode=='out': print(reg[op1])
elif opcode=='halt': return False
return True
def run(file, addr):
global pReg, iReg
loadProgram(file,mem,addr)
iReg=mem[addr];pReg=+1
opcode,op1,op2=decode(iReg)
while execute(opcode,op1,op2, reg, mem, addr):
# print(opcode,op1,op2,reg)
iReg=mem[pReg+addr];pReg+=1
opcode,op1,op2=decode(iReg)
# run('a1.txt', 20)
file = input()
address = int(input())
run(file, address)
枚举
本块将简要介绍枚举算法。
简介
-
枚举(英语:Enumerate)是基于已有知识来猜测答案的一种问题求解策略。
-
枚举的思想是不断地猜测,从可能的集合中一一尝试,然后再判断题目的条件是否成立。
要点
1.给出解空间
- 建立简洁的数学模型。
- 枚举的时候要想清楚:可能的情况是什么?要枚举哪些要素?
2.减少枚举的空间
- 枚举的范围是什么?是所有的内容都需要枚举吗?
- 在用枚举法解决问题的时候,一定要想清楚这两件事,否则会带来不必要的时间开销。
3.选择合适的枚举顺序
根据题目判断。比如例题中要求的是最大的符合条件的素数,那自然是从大到小枚举比较合适。
例题3 哥德巴赫猜想
背景
1742 年,哥德巴赫在给欧拉的信中提出了一个猜想:任一大于 2 的整数都可写成三个素数之和,希望欧拉能给出证明。实际上,哥德巴赫猜想的证明难度远远超过了人们的想象,从欧拉到 200 多年后的今天一直未被破解,成为了世界三大数学猜想中剩下的唯一一个未被解决的问题。 但是,在哥德巴赫猜想的证明过程中,涌现出一系列杰出的数学家,比如我国著名数学家陈景润,同时也催生了许多先进的数学理论与方法,推动了数学领域的发展,这其实也是哥德巴赫猜想的重要意义。
任务
哥德巴赫猜想现在普遍采用的表述是:任一大于 2 的偶数都可写成两个素数之和。本关任务就是试着验证一下这个说法。 具体来说,本关任务是实现
Goldbach函数,该函数的功能是将一个大于 2 的偶数 N 分解为满足以下条件的 N1 和 N2: 1)N1 和 N2 都是素数,即除了 1 和本身外再没有其他约数的数,规定 1 不是素数; 2)N1+N2=N; 3)N1 要尽可能小。 此外,你可以利用本关程序尝试不同的 N,如果某个 N 不能按要求分解成 N1 和 N2,那你就解决了困扰人们 200 多年的哥德巴赫猜想,但是,目前还没人发现这样的 N。
在每个测试集中,系统会给定一个大于 2 的偶数 N(用变量N表示),
例如,测试集 1 的输入是:10程序的功能是将其分解为两个素数之和,例如,测试集 1 的运行结果为:
10 = 3 + 7
开始你的任务吧,祝你成功!
########## Begin ##########
Prime = []
def initPrime(n):
for i in range(2,n):
if num[i]:
Prime.append(i)
for j in range(i+i,n,i):
num[j] = False
def Goldbach(N):
initPrime(N)
for i in Prime:
if(num[N-i]):
return (i,N-i)
# def Goldbach(N):
# for i in range(int(N/2)):
# if Prime(i) and Prime(N-i):
# return (i,N-i)
########## End ##########
N=int(input(''))
num = [True for i in range(N)]
N1,N2 = Goldbach(N)
print('%d = %d + %d' % (N, N1, N2))
例题4 打印素数表
- 打印 \(1 - n\)内的素数表
方案 1
def prime(n):## 根据素数定义模拟素数判断过程
# flag = True ## 事先不知道是否为素数,那就假定不是
for i in range(2,n):
if n%i==0:## 可以枚举从小到大的每个数看是否能整除
# flag = False ## 这就说明不是素数
# break ## 时间优化点,省略后续判断
return False ## 代码优化点,不需要用变量Flag
# return Flag
return True
n=10000
primes=[]
for i in range(2,n+1):
if (prime(i)):## 枚举每一个整数,判断是否为素数
primes.append(i)
# primes = [i for i in range(2, n + 1) if prime(n)] ## 代码优化点,利用列表推导式
print(primes)
这样做是十分稳妥了,但是真的有必要每个数都去判断吗?
很容易发现这样一个事实:如果 \(x\) 是 \(a\) 的约数,那么\(\frac{a} {x}\)也是 \(a\)的约数。
这个结论告诉我们,对于每一对 \((x, \frac{a} {x} )\),只需要检验其中的一个就好了。为了方便起见,我们之考察每一对里面小的那个数。不难发现,所有这些较小数就是 $[1, \sqrt{a}] $这个区间里的数
由于 \(1\) 肯定是约数,所以不检验它。
偶数肯定是约数,设步长为 \(2\) 。
方案 2
def prime(n):## 根据素数定义模拟素数判断过程
for i in range(2,int(n**0.5)+1,2): ## 时间优化点 + 1
if n%i==0: return False
return True
n=100000
primes = [i for i in range(2, n + 1) if prime(i)] ## 代码优化点,利用列表推导式
print(primes)
难道就到此为止了???(显然是)
-
优化的本质实际就是省略不必要的运算,我们发现每个数都进行了单独的判断,这些判断会有许多不必要的重复过程
-
经过思考 我们发现其实不仅偶数是素数,而且3的倍数也是素数,4的倍数也是素数(但它和2的倍数本质一样),······,以此类推,其实我们没必要对素数的倍数进行判断
-
我们可以设计一种算法,利用这些性质吗?(
显然不可以)
一个思路:
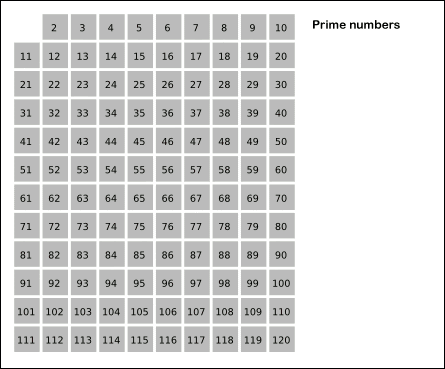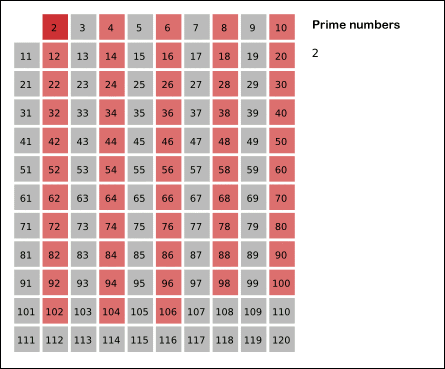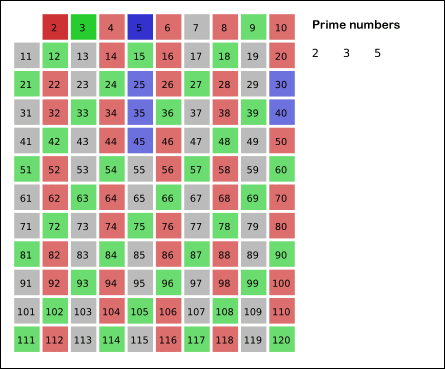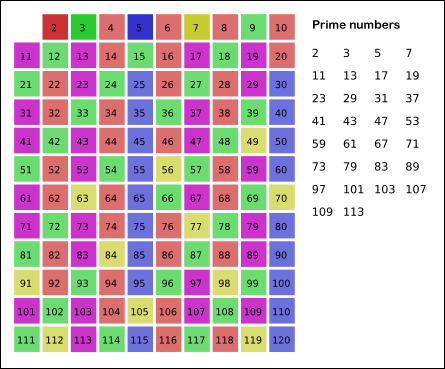
举个例子,比如我们要筛选出100以内的所有素数,我们知道2是最小的素数,我们先用2可以筛掉所有的偶数。
然后往后遍历到3,3是被2筛剩下的第一个数,也是素数,我们再用3去筛除所有能被3整除的数。
筛完之后我们继续往后遍历,第一个遇到的数是7,所以7也是素数,我们再重复以上的过程,直到遍历结束为止。
结束的时候,我们就获得了100以内的所有素数。
(这就是埃拉托斯特尼算法,即eratosthenes发明的用来筛选素数的方法,为了方便我们一般简称为埃式筛法或者筛法)
方案 3
def eratosthenes(n):
for i in range(2, n+1):
if is_prime[i]:
primes.append(i) ## 用当前素数i去筛掉所有能被它整除的数
for j in range(i * 2, n+1, i):
is_prime[j] = False ## 素数的倍数标记为False
n=1000000
primes = []
is_prime = [True] * (n + 1)
eratosthenes(n)
print(primes)
当然我们还可以进一步优化,达到极致优化效果,有兴趣可以进一步了解
不过利用\(filter\)和\(functools\)提供的\(reduce\)可以极大优化代码复杂度,使这个优秀的算法只需一行完成
方案 4
from functools import reduce
n = 1000001 ## 一行版
primes = reduce(lambda r, x: list(filter(lambda a: a % x != 0 or a == x, r)) if x in r else r, range(2, int(n**0.5) + 1), list(range(2, n+1)))
print(primes)
递归 & 分治
本块将介绍递归与分治算法的区别与结合运用。
递归
定义
递归(英语:Recursion),在数学和计算机科学中是指在函数的定义中使用函数自身的方法,在计算机科学中还额外指一种通过重复将问题分解为同类的子问题而解决问题的方法。
引入
要理解递归,就得先理解什么是递归。
- 递归的基本思想是某个函数直接或者间接地调用自身,这样原问题的求解就转换为了许多性质相同但是规模更小的子问题。求解时只需要关注如何把原问题划分成符合条件的子问题,而不需要过分关注这个子问题是如何被解决的。
以下是一些有助于理解递归的例子:
什么是递归?
-
如何给一堆数字排序?答:分成两半,先排左半边再排右半边,最后合并就行了,至于怎么排左边和右边,请重新阅读这句话。
-
你今年几岁?答:去年的岁数加一岁,1999 年我出生。
-
一个用于理解递归的例子
-
递归在数学中非常常见。例如,集合论对自然数的正式定义是:1 是一个自然数,每个自然数都有一个后继,这一个后继也是自然数。
递归代码最重要的两个特征:结束条件和自我调用。自我调用是在解决子问题,而结束条件定义了最简子问题的答案(边界条件)。
def fac(n):
if n==1: return 1
return n*fac(n-1)
def fac(n): return 1 if n==1 else n*fac(n-1) ## 一行版
## 求阶乘
print(fac(10))
def mycos(x,n=30):
if n==0: return 0
return mycos(x,n-1)+(-1)**n*x**(2*n)/fac(2*n)
def mycos(x,n=30): return 1 if n==0 else mycos(x,n-1)+(-1)**n*x**(2*n)/fac(2*n) ## 一行版
## 用泰勒级数求余弦值
print(mycos(3.1415926535/3))
def gcd (m,n):
if n==0: return m
return gcd(n,m%n)
def gcd (m,n): return m if n==0 else gcd(n,m%n) ## 一行版
## 辗转相除法求最大公约数
print(gcd(36,24))
# 总结:
# def func(传入数值):
# if 终止条件: return 最小子问题解
# return func(缩小规模)
为什么要写递归
-
结构清晰,可读性强。
-
显然,递归版本比非递归版本更易理解。递归版本的做法一目了然,而非递归版本看起来不知所云,充斥着各种难以理解的边界计算细节,特别容易出 bug,且难以调试。
练习分析问题的结构。当发现问题可以被分解成相同结构的小问题时,递归写多了就能敏锐发现这个特点,进而高效解决问题。
递归的缺点
在程序执行中,递归是利用堆栈来实现的。每当进入一个函数调用,栈就会增加一层栈帧,每次函数返回,栈就会减少一层栈帧。而栈不是无限大的,当递归层数过多时,就会造成 栈溢出 的后果。
递归的优化
搜索优化 和 记忆化搜索
比较初级的递归实现可能递归次数太多,容易超时。这时需要对递归进行优化。
例题 三个数的最大公约数、快乐数
例5 快乐数
编写一个算法来判断一个数
n是不是快乐数。
快乐数定义为:
- 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。
- 然后重复这个过程直到这个数变为
1,也可能是无限循环但始终变不到1。- 如果这个过程 结果为
1,那么这个数就是快乐数。- 如果
n是快乐数就返回True;不是,则返回False。
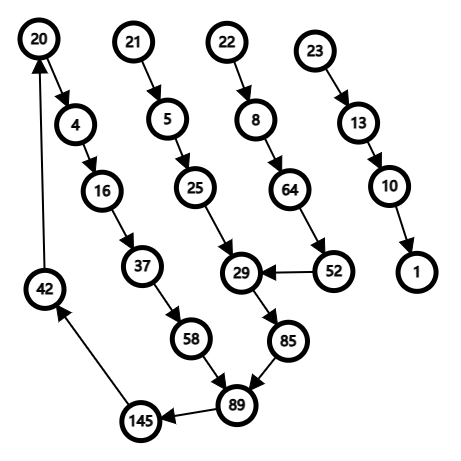
H={}
def isHappy(n):
print('%d\n%d'%(n,n),end='->')
if n==1: return True
if n in H: return H[n] ## 记忆化,如果记录过这种情况,直接返回
tmp,m= n,0
while tmp>0:
m+=(tmp%10)**2
tmp=tmp//10 ## 解决问题
H[n]=False ## 标记状态
H[n]=isHappy(m) ## 缩小规模并更新
return H[n]
# n = int(input())
n=20
def solve(n):
print()
if isHappy(n): return n
return solve(n+1)
print('%d 后的第一个开心数是 %d' % (n, solve(n)));
分治
定义
分治(英语:Divide and Conquer),字面上的解释是「分而治之」,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。
过程
分治算法的核心思想就是「分而治之」。
大概的流程可以分为三步:分解 -> 解决 -> 合并。
分解原问题为结构相同的子问题。
分解到某个容易求解的边界之后,进行递归求解。
将子问题的解合并成原问题的解。
分治法能解决的问题一般有如下特征:
该问题的规模缩小到一定的程度就可以容易地解决。
该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质,利用该问题分解出的子问题的解可以合并为该问题的解。
该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子问题。
注意
如果各子问题是不独立的,则分治法要重复地解公共的子问题,也就做了许多不必要的工作。此时虽然也可用分治法,但一般用 动态规划 较好。
要点
写递归的要点
明白一个函数的作用并相信它能完成这个任务,千万不要跳进这个函数里面企图探究更多细节, 否则就会陷入无穷的细节无法自拔,人脑能压几个栈啊。
区别
递归与枚举的区别
递归和枚举的区别在于:枚举是横向地把问题划分,然后依次求解子问题;而递归是把问题逐级分解,是纵向的拆分。
递归与分治的区别
递归是一种编程技巧,一种解决问题的思维方式;分治算法很大程度上是基于递归的,解决更具体问题的算法思想。
例 6 13队查人
13队有4个p,总共13个b,求总人数
- 思路 1 分治
- 把所有人分成2个部分查人后汇总
- 把部分再分成2个部分查人后汇总
- 分到不可分为止
- 思路 2 递归
- 各b查人
- 我们b有x人,那么总人数为我们b人数加上剩余班人数
- 如果没有其它b了,总人数就是我们b人数
People=[0,12,11,11,12,11,11,12,12,13,12,12,12,7]
def check_people1(l,r): ## 分治查人法
if l==r: return People[l]
total=0
total+=check_people1(l,(l+r)//2)
total+=check_people1((l+r)//2+1,r) ##分成两部分
return total ## 汇总
def check_people2(n): ## 递归查人法
if n==1: return People[n]
return People[n]+check_people2(n-1) ## 我们b加剩余b人数
print(check_people1(1,13))
print(check_people2(13))
Part 3 题外话(Let's have fun)
郑重说明:如果学习累了,不妨放松一下
大计考试就是授人以鱼,考人以鱽鱾鲀鱿鲃鲂鲉鲌鲄鲆鲅鲇鲏鲊鲋鲐鲈鲍鲎鲝鲘鲙鲗鲓鲖鲞鲛鲒鲚鲜鲟鲔鲕鲑鲧鲬鲪鲫鲩鲣鲨鲡鲢鲤鲠鲥鲦鲺鲯鲹鲴鲶鲳鲮鲭鲵鲲鲰鲱鲻鲷鲸鳋鳊鳁鳀鲾鲼鳈鳉鳃鳄鲿鳇鳂鳆鳅鲽鳌鳒鳎鳏鳑鳐鳍鳘鳛鳕鳓鳙鳗鳚鳔鳖鳜鳟鳞鳝鳡鳠鳢鳣鳤……
这个世界上有10种人:看得懂这句话的人,看不懂这句话的人。
这个世界上有10种人:看得懂这句话的人,看不懂这句话的人,还有认为这句话是二进制的人。
这个世界上有有10种人:看得懂这句话的人,看不懂这句话的人,认为这是个二进制笑话的人,认为这是个三进制笑话的人,认为这是个四进制笑话的人,认为这是个五进制笑话的人,认为这是个六进制笑话的人,认为这是个七进制笑话的人,认为这是个八进制笑话的人,认为这是个九进制笑话的人
西江月 证明
即得易见平凡,仿照上例显然。
留作习题答案略,读者自证不难。
反之亦然同理,推证自然成立。
略去过程QED,由上可知证毕。
江城子 挂科
一夜复习两茫茫。看一句,忘三行。
路遇友人,脸色皆凄凉。
视死如归入考场,心里慌,手中忙。
考完之后心凉凉。左右曰,今必亡。
查成绩,众人皆过我独亡。
再顾昔时左右人,这一群,装逼朗。
这个手刹不太灵
泰尼号坦克
哈利波特与凤凰传奇
妇产科联盟
变形钢筋4
家乐福海盗
魂断蓝翔
忠犬洪七公
梁山伯与朱丽叶
大侦探福尔马斯
拯救大兵张嘎
唐伯虎点蚊香
决战杀马特
钢筋侠
午夜闹铃
这里是领航员空间站 现在面向全球做最后播报
在过去的三十六小时里 人类经历了有史以来最大的生存危机
在全球各国一百五十万救援人员的拼搏和牺牲下71%的推进发动机和100%转向发动机被全功率重启
但遗憾的是目前的木星引力 已经超过全部发动机的总输出功率 地球错失了最后的逃逸机会
为了人类文明之延续 莫斯将启动火种计划
领航员空间站冷藏了三十万人类的受精卵和一亿颗基础农作物的种子 储存着全球已知的动植物DNA图谱 并设有全部人类文明的数字资料库 以确保在新的移民星球重建完整的人类文明
你们都是地球的英雄 我们谨记于心 以你们为荣 我们将肩负着你们全部的希望 飞向两千五百年后的新家园
在过去的三十六小时里, 中学生经历了有史以来最大的生存危机。
在全国各省一百五十多万教师的不懈催促下,71%的初中生和100%的高中生被全功率重启。
但遗憾的是,目前的寒假作业量,已经超过了全部学生的总输出功率。
中学生,失去了最后的写完作业的机会。
在最后的这七天里, 大家回家吧, 抱抱自己的父母,尽情享受剩下的日子。
播报完毕。
哪儿来的七天啊!不到18小时高三狗就会被学校全部剥离!
哪儿来的七天! 我们还有最后一个机会,作业的成分百分之90都是纸, 在暴露于地球大气的情况下,点燃只需要一根火柴!
爆燃产生2333马赫以上的冲击波产生的动能足以推开开学的危机来吧!我们点燃作业!
【备选】 ("学校,就是一座大房子,里面90%都是钢筋混凝土结构。”“钢筋混凝土是什么啊?""钢筋混凝土,就是爸爸做定向爆破的楼。”..."我想到了! 炸掉学校! 炸掉学校! 我们还有一个机会!")
"本计划已在12小时前由北京市第三体校学生团队提出,经计算,该计划成功的可能性为0"
“这里是教导处我们无法接受您的要求让已经放弃作业跑路的中学生重新返回教室放弃和亲人最后见面的机会去做一堆写不完的作业”
“无论最后结果将学生作业弄成什么样,我们选择不收。”
“七天是写不了作业的!”
“那我们还写什么?” (车子掉头)
一群伟大的科学家死后在天堂里玩藏猫猫,轮到爱因斯坦抓人,他数到100睁开眼睛,看到所有人都藏起来了,只见伏特趴在不远处。
爱因斯坦走过去说:“伏特,我抓住你了。”
伏特说:“不,你没有抓到我。”
爱因斯坦:“你不是伏特你是谁?”
伏特:“你看我身下是什么?”
爱因斯坦低头看到在伏特身下,居然是安培!
伏特:“我身下是安培,我俩就是伏特/安培,所以你抓住的不是我,你抓住的是….”
……
欧姆!
爱因斯坦反应迅速,于是改口喊,“欧姆,我抓住你了!”
说时迟那时快,伏特和安培一个鱼跃站了起来,但是仍然紧紧抱在一起,
爱因斯坦大惑~
他俩不紧不慢地说,现在,我们不再是欧姆,而是伏特×安培, 变成瓦特了~
爱因斯坦觉得有道理,于是喊,那我终于抓到你了,瓦特!
这时候,安培慢慢悠悠地说:“你看我俩这样抱着已经有好几秒了,所以,我们不再是瓦特,而是瓦特×秒,
我们现在是焦耳啦~”
爱因斯坦被说的哑口无言,于是默默地转过身,这时,他看到牛顿站在不远处,爱因斯坦于是跑过去说:“牛顿,我抓住你了。”
牛顿:“不,你没有抓到牛顿。”
爱因斯坦:“你不是牛顿你是谁?”
牛顿:“你看我脚下是什么?”
爱因斯坦低头看到牛顿站在一块长宽都是一米的正方形的地板砖上,不解。
牛顿:“我脚下这是一平方米的方块,我站在上面就是牛顿/平方米,所以你抓住的不是牛顿,你抓住的是帕斯卡”
爱因斯坦倍受挫折,终于忍无可忍地爆发了,于是飞起一脚,踹在牛顿身上,把牛顿踹出了那块一平米的地板砖,
然后吼到:“说!你还敢说你是帕斯卡??”
牛顿慢慢地从地上爬起来,说:“不,我已经不是帕斯卡了,你刚刚让我牛顿移动了一米的距离,所以,我现在也是焦耳了”
我们学校食堂的汤被称为斐波那契汤。
因为今天的汤是由昨天的汤与前天的混合而成的。
老婆给当程序员的老公打电话:“下班顺路买一斤包子带回来,如果看到卖西瓜的,就买一个。”当晚,程序员老公手捧一个包子进了家门……老婆怒道:“你怎么就买了一个包子?!”老公答曰:“因为看到了卖西瓜的。”
客户被绑,蒙眼,惊问:“想干什么?” 对方不语,鞭笞之,客户求饶:“别打,要钱?” 又一鞭,“十万够不?” 又一鞭,“一百万?” 又一鞭。 客户崩溃:“你们TMD到底要啥?” “要什么?我帮你做项目,写代码的时候也很想知道你TMD到底想要啥!”
记者问一位大爷说:老大爷,您保持年轻的秘诀是什么? 大爷说:白天上班,夜晚加班,节假日值班,一天五包烟,天天吃泡面。 记者问:老大爷,您是干什么工作的? 大爷说:我是程序员! 记者:啊??大爷您今年高寿? 大爷:老子今年35!
如果一个足球界的人“猝死”了,会被怀疑和赌球有关; 如果一个官员“猝死”了,会被怀疑和贪腐有关; 如果一个农民”猝死”了,会被怀疑和拆迁有关; 而如果一个程序员猝死了,那他真的猝死了。
对于各种凌乱的电脑问题,手机问题,其他行业的人,以为程序员们什么都会。 程序员中,女程序员以为男程序员什么都会。 男程序员中,一般程序员以为技术好的程序员什么都会。 技术好的程序员,每次都在网上苦苦找答案。
从前,有一个程序猿,他得到了一盏神灯。灯神答应实现他一个愿望。然后他向神灯许愿,希望在有生之年能写一个好项目。 后来…后来…他得到了永生。
今天在公司听到一句惨绝人寰骂人的话 “你TM就是一个没有对象的野指针!”
算法是什么? 算法就是当程序员不想解释他做了什么的时候最常用到的一个词。
有人说,女程序员再淑女,一旦编程就会暴露自己的身份,习惯性的把前额的头发往上捋,露出大大的额头。 因为CPU高速运作时需要良好的散热
一氧化二氢的危险包括:
- 又叫做“氢氧基酸”,是酸雨的主要成分;
- 对泥土流失有促进作用; 对温室效应有推动作用;
- 它是腐蚀的成因; 过多的摄取可能导致各种不适;
- 皮肤与其固体形式长时间的接触会导致严重的组织损伤;
- 吸入该物质容易引发窒息;
- 发生事故时吸入也有可能致命;
- 处在气体状态时,它能引起严重灼伤;
- 在不可救治的癌症病人肿瘤中已经发现该物质;
- 人类只要一接触一氧化二氢就会发生不可逆转的上瘾,对此物质上瘾的人离开它168小时便会死亡;
- 全球每年因一氧化二氢死亡者超过37万;
- 是大多数有毒溶液的溶剂;
尽管有如此的危险,一氧化二氢常常被用于:
- 各式各样的残忍的动物研究;
- 美国海军有秘密的一氧化二氢的传播网;
- 全世界的河流及湖泊都被一氧化二氢污染;
- 常常配合杀虫剂使用;
- 洗过以后,农产品仍然被这种物质污染;
- 几乎所有食物都被其污染;
- 地球上空气全部被其污染,含量高达0.01%-0.03%,某些地区高达1%;
- 在一些“垃圾食品”和其它食品中的添加剂;
- 已知的导致癌症的物质的一部分;
然而,政府和众多企业仍然大量使用一氧化二氢,而不在乎其极其危险的特性。
班长说:走,我们去炸学校
副班长说:这个主意不错
化学课代表负责提取氢气
物理课代表负责拼装氢弹
数学课代表负责计算爆破面积
地理课代表负责策划爆破地点
信息课代表负责编写氢弹程序
历史课代表负责记录光辉场面
美术课代表负责描画壮观景致
生物课代表负责事后生态环境
政治课代表负责使用法律打官司
语文课代表负责乱写文章推卸责任
英语课代表到外国购买进口材料
为了证明蜘蛛的听觉在脚上,专家做了一个实验。
先是把一直蜘蛛放在实验台上,然后冲蜘蛛大吼了一声,蜘蛛吓跑了!
之后把这只蜘蛛又抓了回来,然后把蜘蛛的脚全部割掉,再冲蜘蛛大吼了一声,蜘蛛果然不动了!
于是,专家发表论文,证明了蜘蛛的听觉在脚上。
为了证明这位专家脑子里全是屎,我们做了一个实验。
先是把这位专家放在马桶上,专家会拉屎。
之后吧这位专家脑子切了,再放在马桶上,专家果然不拉屎了。
于是,我们发表论文,证明这位专家脑子里全是屎。
取少量学生放入试管,加入过量作业,生成学霸溶液和不溶于水的作业化学渣沉淀。
过滤,在作业化学渣中加入浓论文的四氯化碳溶液和氢气,生成学渣化氢沉淀和一氢合论文作业溶液。
过滤,在得到的学渣化氢中加入过量浓试卷的苯酚溶液,学渣迅速溶解且产生气泡,学霸则无明显现象。
有的人以为作业写完了,
但其实还没写完;
有的人以为假期没结束,
但其实已经结束了。
有的人 把作业压在学生头上:
“呵,我多牛!”
有的人
俯下身子撕掉所有作业。
有的人
把作业刻入黑板,想“不朽“;
有的人
一把火过去,学生的作业被烧。
有的人
他活着学生就会累死;
有的人
他活着是为了帮学生抄作业。
把作业压在学生头上的
学生把他摔垮;
帮学生撕作业的
学生永远记住他!
把作业刻入黑板的
作业比尸首烂得更早;
只要火把烧到的地方
到处是作业的渣渣。
他活着学生就会累死
他的下场可以看到;
他活着为了帮学生抄作业
学生把他抬举得很高,很高……
数学是火,点亮物理的灯;
物理是灯,照亮化学的路;
化学是路,通向生物的坑;
生物是坑,埋葬学理的人。
文言是火,点亮历史宫灯;
历史是灯,照亮社会之路;
社会是路,通向哲学大坑;
哲学是坑,埋葬文科生。
世有学霸,然后有附加题。
附加题常有,而学霸不常有。
故虽有难题,祗辱于学渣之手,
骈错与红叉之间,不以全对称也。
题之附加者,一题或难倒一片。
做题考不知其能加分而做也。
是题也,虽有附加之能,做不对,分不加,才美不外见,
且欲与常规题等不可得,安求其能加分也。






 浙公网安备 33010602011771号
浙公网安备 33010602011771号