


从LSM-Tree、COLA-Tree谈到StackOverflow、OSQA
从LSM-Tree、COLA-Tree谈到StackOverflow、OSQA
作者:July,chx/@罗勍
出处:结构之法算法之道blog
导读
- 第一部分从最基本的LSM-Tree的C0C1两组件算法,谈到多组件算法( LSM-Tree最适用于那些索引插入频率远大于查询频率的情况,比如,对于历史记录表和日志文件来说,就属于这种情况),再稍稍提下COLA-tree,让读者对COLA有个印象。
- 第二部分则是讲讲最近我和几个朋友利用OSQA(OSQA为仿照StackOverflow的开源系统)搭建的一个仿照StackOverflow的问答系统,分享实践开发过程中遇到的一些问题及其解决方式,此部分主要由chx/@罗勍编写。
第一部分、LSM-Tree、COLA-Tree
1.0、哪里用到了LSM-Tree
最初看到LSM-Tree这个树结构,是从友情站点NoSQLFan上一篇介绍有着高性能key-value的数据库nessDB的文章内了解到的。nessDB是一个小巧、高性能、可嵌入式的key/value存储引擎,使用标准C开发,支持Linux, *BSD, OS X and Solaris等系统,无第三方库依赖。同时nessDB还提供一个服务端,支持Redis的 PING, SET, MSET, GET, MGET, DEL, EXISTS, INFO, SHUTDOWN 命令,你可以使用任何一款Redis客户端来连接和操作nessDB。
而整个引擎基于LSM-Tree思想开发,对随机写非常友好。为提高随机读,nessDB使用了Level LRU和Bloom Filter策略。我们知道,现在一般主流的数据库索引一般都是用的B/B+树系列,包括MySQL及NoSQL中的MongoDB。而这个nessDB为何例外,LSM-Tree有何特别呢?抱着对它的好奇,便研究学习了下此LSM-Tree。
甚至包括现在另一种比较火/流行的数据库Cassandra 以及与众多类BigTable存储一样,都采用的是LSM-Tree 结构来存储数据,简单来说就是将原来的直接维护索引树变为增量写的方式,这样能够保证对磁盘的操作是顺序的。
再后来,看到了一篇论文:The Log-Structured Merge-Tree,这篇论文原英文有30多页,看了两个下午。下面,本文第一部分就结合这篇论文及星星的译作,从最基本的LSM-Tree的C0C1两组件算法,谈到多组件算法,让读者对LSM-Tree这个树结构的原理有个充分的认识与理解。
1.1、什么是LSM-Tree
相信随着NoSQL据库,尤其是类BigTable系统的流行,LSM-Tree这个树结构,大家很快就不会再如此时这般陌生了。blog内已经详细阐述过B/B+树,那么这个LSM跟B树系列相比,有什么不同呢,它的优势在哪,适用于何种情况?一切,请听我慢慢道来。
此处的Log-Structured这个词源于Ousterhout和Rosenblum在1991年发表的经典论文<<The Design and Implementation of a Log-Structured File System >>,这篇论文提出了一种新的磁盘存储管理方式,在这种结构下,针对磁盘内容的所有更新将会被顺序地写入一个类日志的结构中,从而加速文件写入和回收速度。该日志包含了一些索引信息以保证文件可以快速地读出。日志会被划分为多个段来进行管理。这种方式非常适合于存在大量小文件写入的场景。
LSM-Tree具体是一种什么样的树结构呢,具体来说,LSM-Tree通过使用某种算法(两组件C0C1及多组件算法),对索引变更进行延迟及批量处理,并通过一种类似于归并排序的方式高效地将更新迁移到磁盘。
将索引节点放置到磁盘上的这一过程进行延迟处理,是最根本的,LSM-Tree结构通常就是包含了一系列延迟放置机制。LSM-Tree结构也支持其他的操作,比如删除,更新,甚至是那些具有long latency的查询操作。只有那些需要立即响应的查询会具有相对昂贵的开销。LSM-Tree的主要应用场景就是,查询频率远低于插入频率的情况(大多数人不会像开支票或存款那样经常查看自己的账号活动信息)。在这种情况下,最重要的是降低索引插入开销;与此同时,也必须要维护一个某种形式的索引,因为顺序搜索所有记录是不可能的。
因此,LSM-Tree最适用于那些索引插入频率远大于查询频率的情况,比如,对于历史记录表和日志文件来说,就属于这种情况。OK,接下来,咱们就来截杀这个两组件C0C1算法,以及多组件算法。
1.2、LSM-Tree之两组件C0C1算法
由上文,我们已经知道,LSM-Tree通过使用某种算法(两组件C0C1及多组件算法),对索引变更进行延迟及批量处理,并通过一种类似于归并排序的方式高效地将更新迁移到磁盘。更进一步,LSM-Tree由两个或多个类树的数据结构组件构成。我们先考虑简单的两个组件的情况,如下图所示:
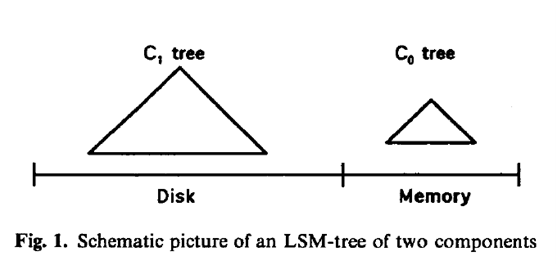
如上,便是LSM-Tree之两组件C0C1算法的示意图。C1树在左边,存在于磁盘Disk上,C0树在右边,存在于内存Memory上。
在每条历史记录表中的记录生成时,会首先向一个日志文件中写入一个用于恢复该插入操作的日志记录。然后针对该历史记录表的实际索引节点会被插入到驻留在内存中的C0树,之后它将会在某个时间从右到左被移到磁盘上的C1树中。对于某条记录的检索,将会首先在C0中查找,然后是C1。在记录从C0移到C1中间肯定存在一定时间的延迟,这就要求能够恢复那些crash之前还未被移出到磁盘的记录。
向驻留在内存中的C0树插入一个索引条目不会花费任何IO开销。但是,用于保存C0的内存的成本要远高于磁盘,这就限制了它的大小。这就需要一种有效的方式来将记录迁移到驻留在更低成本的存储设备上的C1树中。为了实现这个目的,在当C0树因插入操作而达到接近某个上限的阈值大小时,就会启动一个rolling merge过程,来将某些连续的记录段从C0树中删除,并merge到磁盘上的C1树中。如下图所示:
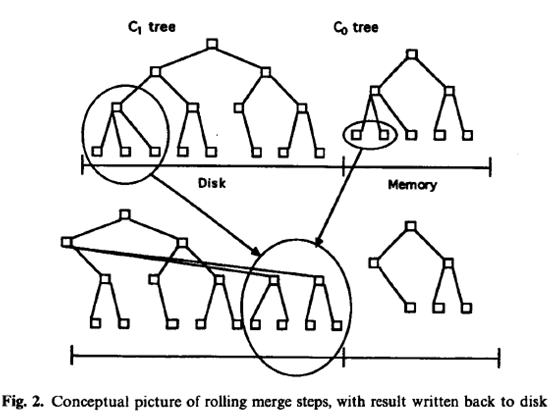
如上,Rolling merge实际上由一系列的merge步骤组成。首先会读取一个包含了C1树中叶节点的multi-page block,这将会使C1中的一系列记录进入缓存。之后,每次merge将会直接从缓存中以磁盘页的大小读取C1的叶节点,将那些来自于叶节点的记录与从C0树中拿到的叶节点级的记录进行merge,这样就减少了C0的大小,同时在C1树中创建了一个新的merge好的叶节点。
磁盘上的C1树具有一个类似于B-树的目录结构,但是它是为顺序性的磁盘访问优化过的,所有的节点都是100%满的,同时为了有效利用磁盘,在根节点之下的所有的单页面节点都会被打包(pack)放到连续的多页面磁盘块(multi-page block)上;类似的优化也被用在SB-树中。对于rolling merge和长的区间检索的情况将会使用multi-page block io,而在匹配性的查找中会使用单页面节点以最小化缓存需求。对于root之外的节点使用256Kbytes的multi-page block大小(root节点根据定义通常都只是单个的页面)。
1.2.2、LSM-Tree之内存上C0树的选择
LSM-tree从诞生那一刻开始的整个变化过程如下,我们首先从针对C0的第一次插入开始。与C1树不同,C0树不一定要具有一个类B-树的结构。首先,它的节点可以具有任意大小:没有必要让它与磁盘页面大小保持一致,因为C0树永不会位于磁盘上(位于哪?内存上阿),因此我们就没有必要为了最小化树的深度而牺牲CPU的效率(如果看下B-树,就可以知道实际上它为了降低树的高度,牺牲了CPU效率。所以,在当整个数据结构都是在内存中时(别忽略了这个前提),一棵普通的2-3树(2-3-4树和B树的前身)或AVL树足矣,且不必使用B树查找,因为B树更适合外存查找(当然,在B树查找数据时,把数据从磁盘导入到内存后,由于B树表的结构是有序的,可以直接二分查找)。
说的细一点,则是内存不用B树系列,外存则用B树系列。你知道,IO操作是影响整个B树查找效率的决定因素,更多细节请参看此文第3小节:从B 树、B+ 树、B* 树谈到R 树。
这样,一个2-3树或者是AVL树就可以作为C0树使用的一个数据结构。当C0首次增长到它的阈值大小时,最左边的一系列记录将会从C0中删除(这应是以批量处理的模式完成,而不是一次一条记录),然后被重新组织成C1中的一个100%满(满的意思就是节点允许最多多少个子节点便有多少个子节点)的叶子节点。后续的叶节点会按照从左到右的顺序放到缓存中的一个multi-page block的初始页面中,直到该block填满为止;之后,该block会被写到磁盘中,成为C1树的磁盘上的叶级存储的第一部分。随着后续的叶节点的加入,C1树会创建出一个目录节点结构。具体细节请参看原论文:The Log-Structured Merge-Tree。
读者朋友@猪婆的猪公反馈:B树的确存在你上述所说的问题,尤其是批量插入的数据大量分散在不同叶结点时。但如果系统中有通用的缓存机制,那一个叶结点页面在插入一条数据后不必立即写出,只有缓冲区已满需要替换时才需要写出,此时可能已有多条数据插入到同一叶结点页面。当然,B树最适用的操作是等值查找和范围查找,维护操作代价的确是高了。
1.3、LSM-Tree之多组件算法
当在LSM-tree index上执行一个需要理解响应的精确匹配查询或者range查询时,首先会到C0中查找所需的那个或那些值,然后是C1中。这意味着与B-树相比,会有一些额外的CPU开销,因为现在需要去两个目录中搜索。对于那些具有超过两个组件的LSM-tree来说,还会有IO上的开销。具体做法是,我们将一个具有组件C0,C1,C2…Ck-1和Ck的多组件LSM-tree,索引树的大小伴随着下标的增加而增大,其中只有C0是驻留在内存中的,其他则是在磁盘上。
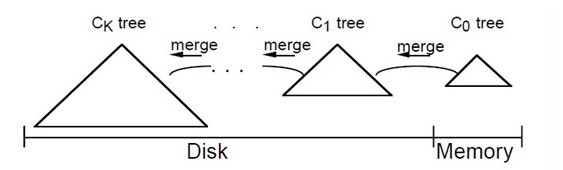
在所有的组件对(Ci-1,Ci)之间都有一个异步的rolling merge过程负责在较小的组件Ci-1超过阈值大小时,将它的记录移到Ci中。一般来说,为了保证LSM-tree中的所有记录都会被检查到,对于一个精确匹配查询和range查询来说,需要访问所有的Ci组件。当然,也存在很多优化方法,可以使搜索限制在这些组件的一个子集上。
所以,LSM-Tree之多组件算法便是:我们将一个具有组件C0,C1,C2…Ck-1和Ck的多组件LSM-tree,索引树的大小伴随着下标的增加而增大,其中C0是驻留在内存中的,其他则是在磁盘上。在所有的组件对(Ci-1,Ci)之间都有一个异步的rolling merge过程负责在较小的组件Ci-1超过阈值大小时,将它的记录移到Ci中。
1.3.1、LSM-Tree之插入与删除
LSM-Tree之插入首先,如果生成逻辑可以保证索引值是唯一的,比如使用时间戳来进行标识时,如果一个匹配查找已经在一个早期的Ci组件中找到时那么它就可以宣告完成了。再比如,如果查询条件里使用了最近时间戳,那么我们可以让那些查找到的值不要向最大的组件中移动。当merge游标扫描(Ci,Ci+1)对时,我们可以让那些最近某个时间段(比如τi秒)内的值依然保留在Ci中,只把那些老记录移入到Ci+1。
在那些最常访问的值都是最近插入的值的情况下,很多查询只需要访问C0就可以完成,这样C0实际上就承担了一个内存缓冲区的功能。比如,用于短期事务UNDO日志的索引访问模式,在中断事件发生时,通常都是针对相对近期的数据的访问,这样大部分的索引就都会是仍处在内存中。通过记录每个事务的启动时间,就可以保证所有最近的τ0秒内发生的事务的所有日志都可以在C0中找到,而不需要访问磁盘组件。
LSM-Tree之删除需要指出的是删除操作可以像插入操作那样享受到延迟和批量处理带来的好处。当某个被索引的行被删除时,如果该记录在C0树中对应的位置上不存在,那么可以将一个删除标记记录(delete node entry)放到该位置,该标记记录也是通过相同的key值进行索引,同时指出将要被删除的记录的Row ID(RID)。实际的删除可以在后面的rolling merge过程中碰到实际的那个索引entry时执行:也就是说delete node entry会在merge过程中移到更大的组件中,同时当碰到相关联的那个entry,就将其清除。与此同时,查询请求也必须在通过该删除标记时进行过滤,以避免返回一个已经被删除的记录。
该过滤很容易进行,因为删除标记就是位于它所标识的那个entry所应在的位置上,同时在很多情况下,这种过滤还起到了减少判定记录是否被删除所需的开销(比如对于一个实际不存在的记录的查找,如果没有该删除标记,需要搜索到最大的那个Ci组件为止,但是如果存在一个删除标记,那么在碰到该标记后就可以停止了)。对于任何应用来说,那些会导致索引值发生变化(比如一条记录包含了ID和name,同时是以ID进行索引的,那么如果是name更新了,很容易,只需要对该记录进行一个原地改动即可,但是如果是ID该了,那么该记录在索引中的位置就要调整了,因此是很棘手的)的更新都是不平凡的,但是这样的更新却可以被LSM-tree一招化解,通过将该更新操作看做是一个删除操作+一个插入操作。
1.3.2、LSM-Tree多组件算法的开销

这里我们主要关注插入性能,因为我们假设LSM-tree通常使用在插入为主的场景中。对于三组件或者多组件LSM-tree来说,查找操作性能上会有降低,通常一个磁盘组件将会带来一次额外的页面IO。
通常情况下,可以通过最小化LSM-tree的总开销(用于C0的内存开销加上用于C1的磁盘空间/IO能力开销)来确定C0的大小。为了达到这种最小化的开销,我们通常从一个比较大的C0组件开始,同时让C1组件大小接近于所需空间的大小。在C0组件足够大的情况下,对于C1的IO压力就会很小。现在,我们可以开始试着通过减少C0的大小,来在昂贵的内存和廉价磁盘之间进行权衡,直到减低到当前C1所能提供的IO能力完全被利用为止。此时,如果再降低C0的内存开销,将会导致磁盘存储开销的增加,因为需要扩充C1组件以应对磁盘负载的增加,最终将会达到一个最小开销点。
现在,对于两组件LSM-tree来说,这个典型的C0组件大小从内存使用的角度上看开销仍是比较高的。一个改进的方案是,采用一个三组件或者多组件LSM-tree。简单来说,如果C0太大以至于内存开销成为主要因素,那么我们可以考虑在两组件LSM-tree的C0和C1之间加入一个中间大小的基于磁盘的组件,这就允许我们在降低了C0大小的同时还能够限制住磁盘磁臂的开销。
我们知道,对于B树来说,每条记录的插入通常需要对该记录所属的节点进行两次IO(一次读出一次写入),与此相比,可以向每个叶子中一次插入多条记录就是一个优势。插入的叶子节点在从B树中读入后之后短暂地在内存中停留,在它被再一次使用时它已不在内存了。因此对于B树索引来说就没有一种批量处理的优势:每个叶节点被读入内存,然后插入一条记录,然后写出去。
但是在一个LSM-tree中,只要与C1组件相比C0组件足够大,总是会有一个批量处理效果。比如,对于16字节的索引记录大小来说,在一个4Kbytes的节点中将会有250条记录。如果C0组件的大小是C1的1/25,那么在每个具有250条记录的C1节点的Node IO中,将会有10条是新记录(也就是说在此次merge产生个node中有10条是在C0中的,而C0中的记录则是用户之前插入的,这相当于将用户的插入先暂存到C0中,然后延迟到merge时写入磁盘,这样这一次的Node IO实际上消化了用户之前的10次插入,的确是将插入批量化了)。很明显,由于这两个因素,与B-树相比LSM-tree效率更高,而rolling merge过程则是其中的关键。
1.4、CacheObliviousBTree
这个缓存忘却CacheOblivious算法在算法导论第18章B树的最后的本章注记中也已提到:为了如何让B树更有效的执行,他们提出了一个缓存忘却CacheOblivious算法,该算法在不需要明确知道存储器层次中数据传输规模的情况下,也可以高效的工作。更多请参见:http://en.wikipedia.org/wiki/Cache-oblivious_algorithm。
COLA便是CacheObliviousBTree作为一个无处不B-树的替代品,COLA的创造者们实现了一个cache-oblivious的动态搜索树。他们用二叉树的“van Emde Boas”的布局,其叶节点指向“packed memory structure”中的时间间隔。这棵cacheObliviousBTree支持高效的查询,以及高效的批次插入和删除。
B-树的有效实施,需要对高速缓存行的大小和页面大小和一个特定的内存层次结构进行了优化。相比之下,cacheObliviousBTree包含不依赖于机器的变量,以及执行上的任何内存层次结构,并要求最少的用户级别的内存管理。cacheObliviousBTree随机插入数据/数据结构,性能优于B-树的Berkeley DB,且能良好的执行一系列操作。
这个数据结构的另一个优点是,存储器阵列保持在排列顺序的数据,允许在高速行驶时连续读取、插入、和写入、删除一些数据。此外,此数据结构也很容易实现,因为它使用的是内存映射,而不是存储在磁盘上的数据是单级存储。 我们也可以把CacheObliviousBTree的键设计得很长(想象一个关键,如DNA序列,这比内存更大),从而支持快速批量插入。
第一部分,完。
除了近几天一直在看上面这个LSM-Tree/CacheObliviousBTree之外,这个月组织几个朋友一直在开发StackOverflow/OSQA,以使我的群友们/读者们有一个好的交流之地。OK,接下来,进入本文第二部分。
第二部分、OSQA开发日志
2.1、中国的StackOverflow
- 一条是银河系至始至终用java自己开发,
- 第二条线则是选择在开源框架OSQA上直接搭建,修改完善。
2.2、第二条线之OSQA搭建
chx/@罗勍
搭建过程基本没什么,直接按照wiki:http://wiki.osqa.net/display/docs/Home,根据自己的系统来选择安装。我用的ubuntu+python2.6+django1.3(1.4能用,但是需要改很多地方)安装过程可以参考wiki,解释得已经很详细。过程中出现no module之类的都easy_install就可以了。
Osqa下载之后要配几个地方
settings_local.py.dist重命名成settings_local.py
settings_local.py需要修改的地方:
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'osqa', 'USER': 'root', 'PASSWORD': 'root', 'HOST': '127.0.0.1', 'PORT': '3306', } }#根据自己的设置填写- APP_URL = 'http://127.0.0.1:8000'
- LANGUAGE_CODE = 'cn'#汉化得已经很不错了
- DJANGO_VERSION = 1.3#填写自己的django版本
- DISABLED_MODULES = ['mysqlfulltext','books', 'recaptcha', 'project_badges']#trunk的默认用的是mysql全文索引,需要把这个加到diabledmodule!
- 如果用spinx做全文搜索的话,追加
SPHINX_API_VERSION = 0x116 #refer to djangosphinx documentation SPHINX_SEARCH_INDICES=('search_question_index',) #a tuple of index names remember about a #comma after the SPHINX_SERVER='localhost' SPHINX_PORT=9312 并且在settings.py INSTALLED_APPS = [ 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.sites', 'django.contrib.admin', 'django.contrib.humanize', 'django.contrib.sitemaps', 'django.contrib.markup', 'forum', 'djangosphinx', ]
当然,要用sphinx就easy_install django-sphinx和sphinxsearch。到此,基本配置都已完成,不管用apache还是简单的manage.py runserver的方式都可以启动,看到界面了。配置邮件可以参考:http://support.google.com/mail/bin/answer.py?hl=en&answer=13287
接下来,注意到添加感兴趣标签的时候,输入标签名点击添加就可以看到刚才的标签已经在上面了,可是刷新之后发现不见了。于是查看代码之后发现这句:
froum\views\commands.py line 536
try:
t = Tag.objects.get(name=tag)
mt = MarkedTag(user=request.user, reason=reason, tag=t)
mt.save()
except :
pass
就是说,如果该标签不存在在数据库,不是已有的标签,就会静静地pass,而前端还能显示能加到。
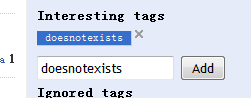
官网也是这个样子……….这样的方式不太友好,在没有该标签的时候应该给用户一个友好提示…
2.3、Coreseek实现OSQA的搜索
2.3.1、Mysql全文索引不堪重用
第二个问题,搜索问题显示没有match的。即使输入的是某个标题的关键字也搜不到,最后几天便一直卡在这个问题上。
Google了N多,试了又试,无意间在settings.py所在的目录看到有个log文件夹。里面有个django.osqa.log文件 Tail -f django.osqa.log,在页面发一个搜索请求,看到了它其实用的是mysql的全文索引。如果表里没有数据,则搜索不到问题。
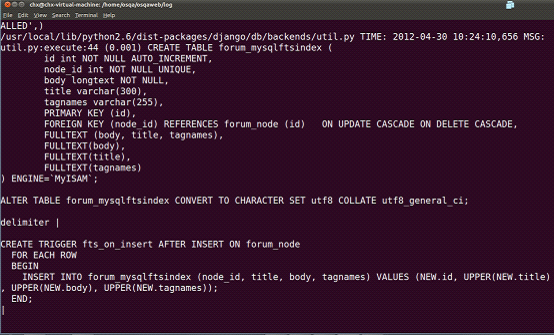
后来终于在/home/osqa/osqaweb/log目录下的django.osqa.log文件中看到这句,这个表forum_mysqlftsindex就是用mysql做全文索引建的表,建个trigger在每次人问问题和回答问题,都会触发这个触发器,并且重新将该问题相关的全部内容都重新更新到索引表:
接下来试试搜索问题 也能看到这样:
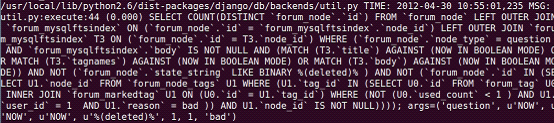
所以,很明显,默认的用的是mysqlfulltext,搜索的时候也走的这条线。在这之前,试图很多次开启sphinxfulltext模块的时候,settings等地方需要都改了,需要配的都配了,但是始终在sphinx的服务端没有看到任何请求过来,coreseek虽然是第一次使用,但是对sphinx已经用了很久,所以能肯定sphinx的server端肯定是没有问题的。在看到上面的log之后就确定是默认走的是mysql的全文索引,于是在disabledmodule里将mysqlfulltext加上。就试了试搜索,就看到如下的结果:

应该走的是django的模糊匹配,我的keyword是 ask,它就到forum_node这个问题表中用like ‘%ask%’这样的模糊匹配去取数据,当然,直接去这里找当然能找到了,页面也能显示相应的问题了,但是like毕竟不是长久之计,本身也对MySQL数据库产生巨大的压力,也就是说,表forum_mysqlftsindex就是用mysql做全文索引建的表,那么现在咱们得废掉这个MySQL本身提供的全文索引,寻找一种更为有效的全文索引方式或解决方案。
2.3.2、基于sphinx之上的Coreseek实现搜索
下面就考虑给osqa的搜索用sphinx实现。因为包含中文搜索,虽然sphinx可以通过设定编码和有效字符集支持中文,但是中文分词搞不定,就用coreseek来实现,coreseek整合了分词+搜索。
- 第一步安装coreseek:http://www.coreseek.cn/
coreseek官网稳定版是3.2.14,是基于sphinx0.9.9的。
安装过程也没什么我直接参照:http://www.coreseek.cn/products/products-install/install_on_bsd_linux/,先安装分词模块mmseg,出现如下所示的结果就可以了:
$ /usr/local/mmseg3/bin/mmseg -d /usr/local/mmseg3/etc src/t1.txt
中文/x 分/x 词/x 测试/x
中国人/x 上海市/x
Word Splite took: 1 ms
- 第二部分是csft,看到如下所示表示已经安装成功
$ /usr/local/coreseek/bin/indexer -c /usr/local/coreseek/etc/sphinx-min.conf.dist
##以下为正常测试时的提示信息:
Coreseek Fulltext 3.2 [ Sphinx 0.9.9-release (r2117)]
Copyright (c) 2007-2010,
Beijing Choice Software Technologies Inc (http://www.coreseek.com)
using config file '/usr/local/coreseek/etc/sphinx-min.conf.dist'...
total 0 reads, 0.000 sec, 0.0 kb/call avg, 0.0 msec/call avg
total 0 writes, 0.000 sec, 0.0 kb/call avg, 0.0 msec/call avg
2.4、OSQA内Sphinx配置文件
接下来为我们的问题搜索写sphinx配置文件,我的配置文件如下:
#源定义
source base_source
{
type = mysql
sql_host = localhost
sql_user = root
sql_pass = root
sql_db = osqa
sql_port = 3306
sql_query_pre = SET NAMES utf8
sql_query_pre = SET SESSION query_cache_type=OFF
sql_query_info_pre = SET NAMES utf8
sql_range_step = 1000
sql_query =
}
#index定义
index base_index
{
path=
source = base_source #对应的source名称
docinfo = extern
mlock = 0
morphology = none
min_word_len = 1
html_strip = 0
#中文分词配置,详情请查看:http://www.coreseek.cn/products-install/coreseek_mmseg/
charset_dictpath = /usr/local/mmseg3/etc/ #BSD、Linux环境下设置,/符号结尾
#charset_dictpath = etc/ #Windows环境下设置,/符号结尾,最好给出绝对路径,例如:C:/usr/local/coreseek/etc/...
charset_type = zh_cn.utf-8
ngram_len = 0
}
source search_question_source: base_source
{
sql_query_range = select min(id),max(id) from forum_node
sql_query = SELECT question.id, question.title, author.username, question.tagnames, question.body,\
GROUP_CONCAT(answer.body) as answer_bodies FROM forum_node AS question, forum_node AS answer,\
auth_user AS author WHERE answer.parent_id = question.id AND question.author_id = author.id \
And question.id >= $start and question.id < $end GROUP BY question.id
# sql_attr_uint = group_id #从SQL读取到的值必须为整数,we should add the number of answer
# and update date to rank these questions
# sql_attr_timestamp = date_added #从SQL读取到的值必须为整数,作为时间属性
}
source delta_search_question_source: search_question_source
{
sql_query_range = select min(id),max(id) from forum_node where added_at > DATE_FORMAT(NOW(),'%Y-%m-%d')
}
index search_question_index : base_index
{
source= search_question_source
path= /ROOT/sphinx/index/search_question
}
index delta_search_question_index : search_question_index
{
source= delta_search_question_source
path= /ROOT/sphinx/index/delta_search_question
}
#全局index定义
indexer
{
mem_limit = 128M
}
#searchd服务定义
searchd
{
listen = 9312
read_timeout = 5
max_children = 30
max_matches = 1000
seamless_rotate = 0
preopen_indexes = 0
unlink_old = 1
pid_file = /ROOT/sphinx/log/searchd_osqa.pid #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/...
log = /ROOT/sphinx/log/searchd_osqa.log #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/...
query_log = /ROOT/sphinx/log/query_osqa.log #请修改为实际使用的绝对路径,例如:/usr/local/coreseek/var/...可以放在任何文件夹下 只要建索引的时候指定就好。比如我的是放在/ROOT/sphinx/conf/sphinx_osqa.conf,接下来建索引: indexer -c /ROOT/sphinx/conf/sphinx_osqa.conf --all –rotate
Base_index的警告可以忽略,然后启动守护进程 searchd –c /ROOT/sphinx/conf/sphinx_osqa.conf
到此,sphinx的服务端都已经弄好,守护进程searchd在9312端口等待客户端发query。可以简单测试一下 search –c /ROOT/sphinx/conf/sphinx_osqa.conf keywords。
2.5、Sphinx服务端配置的几个问题
Sphinx服务端配置已经完成,虽然自从diable掉mysqlfulltext之后就可以搜到问题,但是用的是Like %keyword%形式的请求。我们现在需要改的有三处:
在/forum/models/question.py
- 在Question类加入
search = SphinxSearch( index ='search_question_index', mode='SPH_MATCH_ALL', ),自己根据需求配置,比如设置权重之类的。 - 加入sphinxsearch引用 from djangosphinx.models import SphinxSearch
- QuestionManager类加入queryset = Question.search.query(keywords)
将命中的id取出来存成list结构,比如,存到变量ids里,然后直接返回
return False,self.filter(id__in=ids)
这样就返回了命中的id的所有问题。当然这种in的方式如果ids的数据量小的时候还可以,大了之后也不行,所以,后续应该考虑分页的方式来呈现更多的结果。
当然,最终能在服务器端上看到已经有收到请求了,如下图所示:
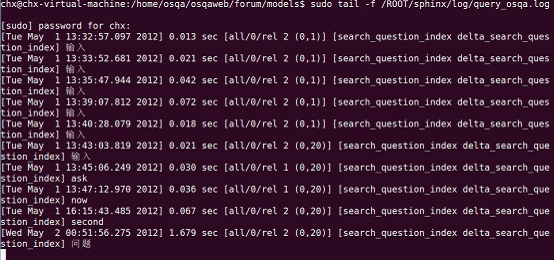
至此,之前搜到不到关键词/tag的问题成功解决。也就是说,咱们的StackOverflow的原型OSQA已经搭建完成,接下来,便是一系列修改完善优化的工作。感谢技术知己之一罗勍:http://weibo.com/u/1909128871。(项目已终止,2012.07.17)。
参考文献及相关链接
- The Log-Structured Merge-Tree,Patrick O’Neil &Edward Cheng etc.1996。
- http://www.springerlink.com/content/rfkpd5yej9v5chrp/?MUD=MP。
- http://duanple.blog.163.com/blog/#m=0&t=3&c=lsm-tree,phylips@bmy 2011-12-25。
- COLA,http://supertech.csail.mit.edu/cacheObliviousBTree.html 。
- 三五杆枪,可干革命,三五个人,可以创业
- 从B树、B+树、B*树谈到R 树 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号