
结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程
一 实验内容
结合中断上下文切换和进程上下文切换分析Linux内核一般执行过程
以fork和execve系统调用为例分析中断上下文的切换
分析execve系统调用中断上下文的特殊之处
分析fork子进程启动执行时进程上下文的特殊之处
以系统调用作为特殊的中断,结合中断上下文切换和进程上下文切换分析Linux系统的一般执行过程
二 实验环境
虚拟机:VMware® Workstation 12 Pro
Linux:ubuntu-18.04.4-desktop-amd64
三 实验过程
1 fork系统调用
1.1 fork系统调用过程分析
首先,fork也是⼀个系统调⽤,和前述⼀般的系统调⽤执⾏过程⼤致是⼀样的。尤其从⽗进程的⻆度来看,fork的执⾏过程与前述描述完全⼀致,fork系统调⽤创建了⼀个⼦进程,⼦进程复制了父进程中所有的进程信息,包括内核堆栈、进程描述符等,⼦进程作为⼀个独⽴的进程也会被调度。下面我们结合源码分析fork系统调用的内核处理过程。
1 // kernel/fork.c 2 3 #ifndef CONFIG_HAVE_COPY_THREAD_TLS 4 /* For compatibility with architectures that call do_fork directly rather than 5 * using the syscall entry points below. */ 6 long do_fork(unsigned long clone_flags, 7 unsigned long stack_start, 8 unsigned long stack_size, 9 int __user *parent_tidptr, 10 int __user *child_tidptr) 11 { 12 struct kernel_clone_args args = { 13 .flags = (clone_flags & ~CSIGNAL), 14 .pidfd = parent_tidptr, 15 .child_tid = child_tidptr, 16 .parent_tid = parent_tidptr, 17 .exit_signal = (clone_flags & CSIGNAL), 18 .stack = stack_start, 19 .stack_size = stack_size, 20 }; 21 22 if (!legacy_clone_args_valid(&args)) 23 return -EINVAL; 24 25 return _do_fork(&args); 26 } 27 #endif 28 29 /* 30 * Create a kernel thread. 31 */ 32 pid_t kernel_thread(int (*fn)(void *), void *arg, unsigned long flags) 33 { 34 struct kernel_clone_args args = { 35 .flags = ((flags | CLONE_VM | CLONE_UNTRACED) & ~CSIGNAL), 36 .exit_signal = (flags & CSIGNAL), 37 .stack = (unsigned long)fn, 38 .stack_size = (unsigned long)arg, 39 }; 40 41 return _do_fork(&args); 42 } 43 44 #ifdef __ARCH_WANT_SYS_FORK 45 SYSCALL_DEFINE0(fork) 46 { 47 #ifdef CONFIG_MMU 48 struct kernel_clone_args args = { 49 .exit_signal = SIGCHLD, 50 }; 51 52 return _do_fork(&args); 53 #else 54 /* can not support in nommu mode */ 55 return -EINVAL; 56 #endif 57 } 58 #endif 59 60 #ifdef __ARCH_WANT_SYS_VFORK 61 SYSCALL_DEFINE0(vfork) 62 { 63 struct kernel_clone_args args = { 64 .flags = CLONE_VFORK | CLONE_VM, 65 .exit_signal = SIGCHLD, 66 }; 67 68 return _do_fork(&args); 69 } 70 #endif 71 72 #ifdef __ARCH_WANT_SYS_CLONE 73 #ifdef CONFIG_CLONE_BACKWARDS 74 SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp, 75 int __user *, parent_tidptr, 76 unsigned long, tls, 77 int __user *, child_tidptr) 78 #elif defined(CONFIG_CLONE_BACKWARDS2) 79 SYSCALL_DEFINE5(clone, unsigned long, newsp, unsigned long, clone_flags, 80 int __user *, parent_tidptr, 81 int __user *, child_tidptr, 82 unsigned long, tls) 83 #elif defined(CONFIG_CLONE_BACKWARDS3) 84 SYSCALL_DEFINE6(clone, unsigned long, clone_flags, unsigned long, newsp, 85 int, stack_size, 86 int __user *, parent_tidptr, 87 int __user *, child_tidptr, 88 unsigned long, tls) 89 #else 90 SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp, 91 int __user *, parent_tidptr, 92 int __user *, child_tidptr, 93 unsigned long, tls) 94 #endif 95 { 96 struct kernel_clone_args args = { 97 .flags = (clone_flags & ~CSIGNAL), 98 .pidfd = parent_tidptr, 99 .child_tid = child_tidptr, 100 .parent_tid = parent_tidptr, 101 .exit_signal = (clone_flags & CSIGNAL), 102 .stack = newsp, 103 .tls = tls, 104 }; 105 106 if (!legacy_clone_args_valid(&args)) 107 return -EINVAL; 108 109 return _do_fork(&args); 110 } 111 #endif
通过上⾯的代码可以看出fork、vfork和clone这3个系统调⽤,以及do_fork和kernel_thread内核函数都可以创建⼀个新进程,⽽且都是通过_do_fork函数来创建进程的,只不过传递的参数不同。fork⼀个⼦进程的过程中,复制⽗进程的资源时采⽤了Copy OnWrite(写时复制)技术,不需要修改的进程资源⽗⼦进程是共享内存存储空间的。
在上一篇博文中已经详细分析了系统调用的过程,在此不过多赘述,下面重点分析_do_fork函数到底做了什么事情。
1 // kernel/fork.c 2 3 long _do_fork(struct kernel_clone_args *args) 4 { 5 u64 clone_flags = args->flags; 6 struct completion vfork; 7 struct pid *pid; 8 struct task_struct *p; 9 int trace = 0; 10 long nr; 11 12 /* 13 * Determine whether and which event to report to ptracer. When 14 * called from kernel_thread or CLONE_UNTRACED is explicitly 15 * requested, no event is reported; otherwise, report if the event 16 * for the type of forking is enabled. 17 */ 18 if (!(clone_flags & CLONE_UNTRACED)) { 19 if (clone_flags & CLONE_VFORK) 20 trace = PTRACE_EVENT_VFORK; 21 else if (args->exit_signal != SIGCHLD) 22 trace = PTRACE_EVENT_CLONE; 23 else 24 trace = PTRACE_EVENT_FORK; 25 26 if (likely(!ptrace_event_enabled(current, trace))) 27 trace = 0; 28 } 29 30 p = copy_process(NULL, trace, NUMA_NO_NODE, args);//复制进程描述符和执⾏时所需的其他数据结构31 add_latent_entropy(); 32 33 if (IS_ERR(p)) 34 return PTR_ERR(p); 35 36 /* 37 * Do this prior waking up the new thread - the thread pointer 38 * might get invalid after that point, if the thread exits quickly. 39 */ 40 trace_sched_process_fork(current, p); 41 42 pid = get_task_pid(p, PIDTYPE_PID); 43 nr = pid_vnr(pid); 44 45 if (clone_flags & CLONE_PARENT_SETTID) 46 put_user(nr, args->parent_tid); 47 48 if (clone_flags & CLONE_VFORK) { 49 p->vfork_done = &vfork; 50 init_completion(&vfork); 51 get_task_struct(p); 52 } 53 54 wake_up_new_task(p);//将⼦进程添加到就绪队列 55 56 /* forking complete and child started to run, tell ptracer */ 57 if (unlikely(trace)) 58 ptrace_event_pid(trace, pid); 59 60 if (clone_flags & CLONE_VFORK) { 61 if (!wait_for_vfork_done(p, &vfork)) 62 ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid); 63 } 64 65 put_pid(pid); 66 return nr;//返回⼦进程pid(⽗进程中fork返回值为⼦进程的pid) 67 }
上述_do_fork的实现代码中可以看到,_do_fork函数主要完成了调⽤copy_process()复制⽗进程、获得pid、调⽤wake_up_new_task将⼦进程加⼊就绪队列等待调度执⾏等。其中copy_process()是创建⼀个进程的主要的代码,如下的copy_process()函数代码做了删减并添加了⼀些中⽂注释,完整代码⻅kernel/fork.c。
1 //copy_process() 2 3 static __latent_entropy struct task_struct *copy_process( 4 struct pid *pid, 5 int trace, 6 int node, 7 struct kernel_clone_args *args) 8 { 9 //复制进程描述符task_struct、创建内核堆栈等 10 p = dup_task_struct(current, node); 11 /* copy all the process information */ 12 shm_init_task(p); 13 … 14 // 初始化⼦进程内核栈和thread 15 retval = copy_thread_tls(clone_flags, args->stack, args->stack_size, p, 16 args->tls); 17 … 18 return p;//返回被创建的⼦进程描述符指针 19 }
copy_process函数主要完成了调⽤dup_task_struct复制当前进程(⽗进程)描述符task_struct、信息检查、初始化、把进程状态设置为TASK_RUNNING(此时⼦进程置为就绪态)、采⽤写时复制技术逐⼀复制所有其他进程资源、调⽤copy_thread_tls初始化⼦进程内核栈、设置⼦进程pid等。其中最关键的就是dup_task_struct复制当前进程(⽗进程)描述符task_struct和copy_thread_tls初始化⼦进程内核栈。接下来具体看dup_task_struct和copy_thread_tls。
1 // dup_task_struct 2 3 static struct task_struct *dup_task_struct(struct task_struct *orig, int node) 4 { 5 … 6 //实际完成进程描述符的拷⻉,具体做法是*tsk = *orig 7 err = arch_dup_task_struct(tsk, orig); 8 … 9 tsk->stack = stack; 10 ... 11 //实际完成进程描述符的拷⻉,具体做法是*tsk = *orig 12 setup_thread_stack(tsk, orig); 13 clear_user_return_notifier(tsk); 14 clear_tsk_need_resched(tsk); 15 set_task_stack_end_magic(tsk); 16 ... 17 }
1 // arch/x86/kernel/process_32.c 2 3 int copy_thread_tls(unsigned long clone_flags, unsigned long sp, 4 unsigned long arg, struct task_struct *p, unsigned long tls) 5 { 6 struct pt_regs *childregs = task_pt_regs(p); 7 struct fork_frame *fork_frame = container_of(childregs, struct fork_frame, regs); 8 struct inactive_task_frame *frame = &fork_frame->frame; 9 struct task_struct *tsk; 10 int err; 11 12 /* 13 * For a new task use the RESET flags value since there is no before. 14 * All the status flags are zero; DF and all the system flags must also 15 * be 0, specifically IF must be 0 because we context switch to the new 16 * task with interrupts disabled. 17 */ 18 frame->flags = X86_EFLAGS_FIXED; 19 frame->bp = 0; 20 frame->ret_addr = (unsigned long) ret_from_fork; 21 p->thread.sp = (unsigned long) fork_frame; 22 p->thread.sp0 = (unsigned long) (childregs+1); 23 memset(p->thread.ptrace_bps, 0, sizeof(p->thread.ptrace_bps)); 24 25 if (unlikely(p->flags & PF_KTHREAD)) { 26 /* kernel thread */ 27 memset(childregs, 0, sizeof(struct pt_regs)); 28 frame->bx = sp; /* function */ 29 frame->di = arg; 30 p->thread.io_bitmap_ptr = NULL; 31 return 0; 32 } 33 frame->bx = 0; 34 *childregs = *current_pt_regs(); 35 childregs->ax = 0; 36 if (sp) 37 childregs->sp = sp; 38 39 task_user_gs(p) = get_user_gs(current_pt_regs()); 40 41 p->thread.io_bitmap_ptr = NULL; 42 tsk = current; 43 err = -ENOMEM; 44 45 if (unlikely(test_tsk_thread_flag(tsk, TIF_IO_BITMAP))) { 46 p->thread.io_bitmap_ptr = kmemdup(tsk->thread.io_bitmap_ptr, 47 IO_BITMAP_BYTES, GFP_KERNEL); 48 if (!p->thread.io_bitmap_ptr) { 49 p->thread.io_bitmap_max = 0; 50 return -ENOMEM; 51 } 52 set_tsk_thread_flag(p, TIF_IO_BITMAP); 53 } 54 55 err = 0; 56 57 /* 58 * Set a new TLS for the child thread? 59 */ 60 if (clone_flags & CLONE_SETTLS) 61 err = do_set_thread_area(p, -1, 62 (struct user_desc __user *)tls, 0); 63 64 if (err && p->thread.io_bitmap_ptr) { 65 kfree(p->thread.io_bitmap_ptr); 66 p->thread.io_bitmap_max = 0; 67 } 68 return err; 69 }
copy_thread_tls负责构造fork系统调⽤在⼦进程的内核堆栈,也就是fork系统调⽤在⽗⼦进程各返回⼀次,⽗进程中和其他系统调⽤的处理过程并⽆⼆致,⽽在⼦进程中的内核函数调⽤堆栈需要特殊构建,为⼦进程的运⾏准备好上下⽂环境。另外还有线程局部存储TLS(thread local storage)则是为⽀持多线程编程引⼊的,此文不去深究。⼦进程创建好了进程描述符、内核堆栈等,就可以通过wake_up_new_task(p)将⼦进程添加到就绪队列,使之有机会被调度执⾏,进程的创建⼯作就完成了,⼦进程就可以等待调度执⾏,⼦进程的执⾏从这⾥设定的ret_from_fork开始。值得注意的是进程关键上下⽂的ip和sp,linux-5.4.34与早期版本有所不同,主要是指令指针ip在3.18.6版本是存放在thread.ip中,⽽5.4.34中则是通过frame->ret_addr直接存储在内核堆栈中。
1.2 _do_fork总结
进程的创建过程⼤致是⽗进程通过fork系统调⽤进⼊内核_do_fork函数,如下图所示复制进程描述符及相关进程资源(采⽤写时复制技术)、分配⼦进程的内核堆栈并对内核堆栈和thread等进程关键上下⽂进⾏初始化,最后将⼦进程放⼊就绪队列,fork系统调⽤返回;⽽⼦进程则在被调度执⾏时根据设置的内核堆栈和thread等进程关键上下⽂开始执⾏。

普通系统调用和fork子进程的内核堆栈对比如下


struct _fork_frame保证了子进程自身的堆栈,并指定了一个位置可以让函数调用返回和系统调用返回在堆栈中有相匹配的函数调用和系统调用的堆栈框架。
2 execve系统调用
2.1 命令⾏参数和环境变量的保存
当fork⼀个⼦进程时,会⽣成⼦进程的进程描述符、内核堆栈和⽤户态堆栈等,⼦进程是通过复制⽗进程的⼤部分内创建的。⼦进程通过execlp加载可执⾏程序时按如图所示的结构重新布局⽤户态堆栈,可以看到⽤户态堆栈的栈顶就是main函数调⽤堆栈框架,这就是程序的main函数起点的执⾏环境。这⾥是以32位x86环境为例,x86-64环境函数调⽤改为寄存器传递参数会有所不同。
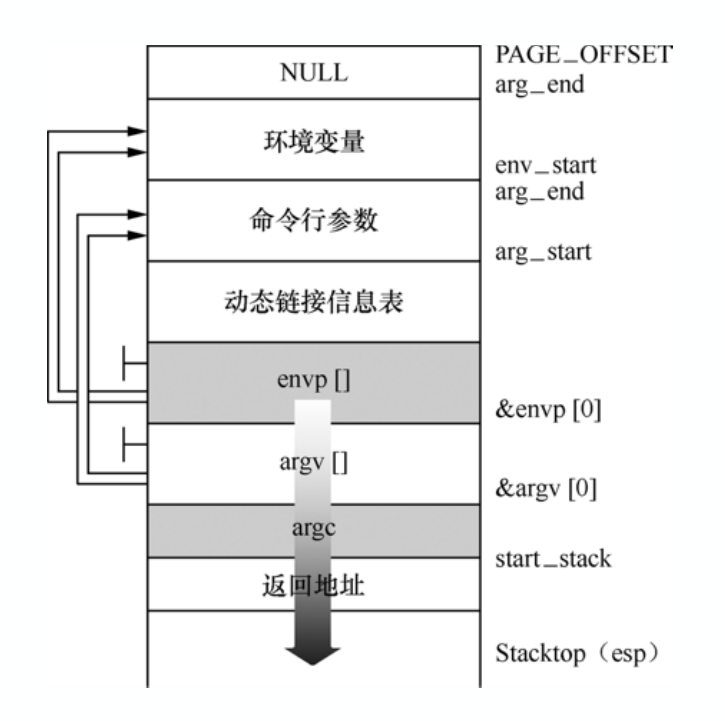
2.2 execve系统调用过程分析
当采用Shell运行一个可执行程序并进行参数传递的时候,Shell会调⽤execve系统调⽤接⼝函数将命令⾏参数和环境变量传递给可执⾏程序的main函数。Linux系统⼀般会提供了execl、execlp、execle、execv、execvp和execve等6个⽤以加载执⾏⼀个可执⾏⽂件的库函数,这些库函数统称为exec函数,差异在于对命令⾏参数和环境变量参数的传递⽅式不同。exec函数都是通过execve系统调⽤进⼊内核,对应的系统调⽤内核处理函数为sys_execve或__x64_sys_execve,它们都是通过调⽤do_execve来具体执⾏加载可执⾏⽂件的⼯作。
整体的调用关系为:sys_execve()或__x64_sys_execve -> do_execve() –>do_execveat_common() -> __do_execve_file -> exec_binprm()-> search_binary_handler() ->load_elf_binary() -> start_thread()。
1 // fs/exec.c 2 3 SYSCALL_DEFINE3(execve, 4 const char __user *, filename, 5 const char __user *const __user *, argv, 6 const char __user *const __user *, envp) 7 { 8 return do_execve(getname(filename), argv, envp); 9 }
filename为可执⾏⽂件的名字,argv是以NULL结尾的命令⾏参数数组,envp同样是以NULL结尾的环境变量数组。
1 // fc/exec.c 2 3 int do_execve(struct filename *filename, 4 const char __user *const __user *__argv, 5 const char __user *const __user *__envp) 6 { 7 struct user_arg_ptr argv = { .ptr.native = __argv }; 8 struct user_arg_ptr envp = { .ptr.native = __envp }; 9 return do_execveat_common(AT_FDCWD, filename, argv, envp, 0); 10 }
1 // fc/exec.c 2 3 static int do_execveat_common(int fd, struct filename *filename, 4 struct user_arg_ptr argv, 5 struct user_arg_ptr envp, 6 int flags) 7 { 8 return __do_execve_file(fd, filename, argv, envp, flags, NULL); 9 }
__do_execve_file是实际上的执行一个可执行程序的位置
1 // fs/exec.c 2 3 /* 4 * sys_execve() executes a new program. 5 */ 6 static int __do_execve_file(int fd, struct filename *filename, 7 struct user_arg_ptr argv, 8 struct user_arg_ptr envp, 9 int flags, struct file *file) 10 { 11 char *pathbuf = NULL; 12 struct linux_binprm *bprm; 13 struct files_struct *displaced; 14 int retval; 15 ... 16 bprm->interp = bprm->filename; 17 18 retval = bprm_mm_init(bprm); 19 if (retval) 20 goto out_unmark; 21 22 retval = prepare_arg_pages(bprm, argv, envp); 23 if (retval < 0) 24 goto out; 25 26 retval = prepare_binprm(bprm);//取出文件头的一段数据 27 if (retval < 0) 28 goto out; 29 30 retval = copy_strings_kernel(1, &bprm->filename, bprm); 31 if (retval < 0) 32 goto out; 33 34 bprm->exec = bprm->p; 35 retval = copy_strings(bprm->envc, envp, bprm); 36 if (retval < 0) 37 goto out; 38 39 retval = copy_strings(bprm->argc, argv, bprm); 40 if (retval < 0) 41 goto out; 42 43 would_dump(bprm, bprm->file); 44 45 retval = exec_binprm(bprm);//实际加载 46 if (retval < 0) 47 goto out; 48 49 /* execve succeeded */ 50 current->fs->in_exec = 0; 51 current->in_execve = 0; 52 rseq_execve(current); 53 acct_update_integrals(current); 54 task_numa_free(current, false); 55 free_bprm(bprm); 56 kfree(pathbuf); 57 if (filename) 58 putname(filename); 59 if (displaced) 60 put_files_struct(displaced); 61 return retval; 62 ... 63 }
exec_binprm()实际加载
1 // fs/exec.c 2 3 static int exec_binprm(struct linux_binprm *bprm) 4 { 5 pid_t old_pid, old_vpid; 6 int ret; 7 8 /* Need to fetch pid before load_binary changes it */ 9 old_pid = current->pid; 10 rcu_read_lock(); 11 old_vpid = task_pid_nr_ns(current, task_active_pid_ns(current->parent)); 12 rcu_read_unlock(); 13 14 ret = search_binary_handler(bprm); 15 if (ret >= 0) { 16 audit_bprm(bprm); 17 trace_sched_process_exec(current, old_pid, bprm); 18 ptrace_event(PTRACE_EVENT_EXEC, old_vpid); 19 proc_exec_connector(current); 20 } 21 22 return ret; 23 }
search_binary_handler()搜索文件解析模块,来解析当前加载的可执行程序
1 // fs/exec.c 2 3 int search_binary_handler(struct linux_binprm *bprm) 4 { 5 bool need_retry = IS_ENABLED(CONFIG_MODULES); 6 struct linux_binfmt *fmt; 7 int retval; 8 9 /* This allows 4 levels of binfmt rewrites before failing hard. */ 10 if (bprm->recursion_depth > 5) 11 return -ELOOP; 12 13 retval = security_bprm_check(bprm); 14 if (retval) 15 return retval; 16 17 retval = -ENOENT; 18 retry: 19 read_lock(&binfmt_lock); 20 list_for_each_entry(fmt, &formats, lh) { 21 if (!try_module_get(fmt->module)) 22 continue; 23 read_unlock(&binfmt_lock); 24 25 bprm->recursion_depth++; 26 retval = fmt->load_binary(bprm); 27 bprm->recursion_depth--; 28 29 read_lock(&binfmt_lock); 30 put_binfmt(fmt); 31 if (retval < 0 && !bprm->mm) { 32 /* we got to flush_old_exec() and failed after it */ 33 read_unlock(&binfmt_lock); 34 force_sigsegv(SIGSEGV); 35 return retval; 36 } 37 if (retval != -ENOEXEC || !bprm->file) { 38 read_unlock(&binfmt_lock); 39 return retval; 40 } 41 } 42 read_unlock(&binfmt_lock); 43 44 if (need_retry) { 45 if (printable(bprm->buf[0]) && printable(bprm->buf[1]) && 46 printable(bprm->buf[2]) && printable(bprm->buf[3])) 47 return retval; 48 if (request_module("binfmt-%04x", *(ushort *)(bprm->buf + 2)) < 0) 49 return retval; 50 need_retry = false; 51 goto retry; 52 } 53 54 return retval; 55 }
在fs/binfmt_elf.c中可以找到load_binary实际上是执行load_elf_binary
load_elf_binary()主要作用:校验⽂件;加载⽂件到内存并根据ELF⽂件中(Program header table和Section header table)映射到进程的地址空间;判断是否需要动态链接;配置进程启动上下⽂环境start_thread。
1 // fs/binfmt_elf.c 2 3 static int load_elf_binary(struct linux_binprm *bprm) 4 { 5 ... 6 if (interpreter) { 7 unsigned long interp_map_addr = 0; 8 //动态链接 9 elf_entry = load_elf_interp(&loc->interp_elf_ex, 10 interpreter, 11 &interp_map_addr, 12 load_bias, interp_elf_phdata); 13 if (!IS_ERR((void *)elf_entry)) { 14 /* 15 * load_elf_interp() returns relocation 16 * adjustment 17 */ 18 interp_load_addr = elf_entry; 19 elf_entry += loc->interp_elf_ex.e_entry;//设置为动态链接器的首地址 20 } 21 if (BAD_ADDR(elf_entry)) { 22 retval = IS_ERR((void *)elf_entry) ? 23 (int)elf_entry : -EINVAL; 24 goto out_free_dentry; 25 } 26 reloc_func_desc = interp_load_addr; 27 28 allow_write_access(interpreter); 29 fput(interpreter); 30 } else {//静态链接 31 elf_entry = loc->elf_ex.e_entry; 32 if (BAD_ADDR(elf_entry)) { 33 retval = -EINVAL; 34 goto out_free_dentry; 35 } 36 } 37 ... 38 finalize_exec(bprm); 39 start_thread(regs, elf_entry, bprm->p); 40 retval = 0; 41 ... 42 }
start_thread()
1 // arch/x86/kernel/process_64.c 2 3 void start_thread(struct pt_regs *regs, unsigned long new_ip, unsigned long new_sp) 4 { 5 start_thread_common(regs, new_ip, new_sp, 6 __USER_CS, __USER_DS, 0); 7 }
start_thread_common()修改了内核堆栈的底部,即中断关键上下文的CPU状态信息,使得execve系统调用返回到用户态时能够从新的程序入口开始执行。
1 // arch/x86/kernel/process_64.c 2 3 static void 4 start_thread_common(struct pt_regs *regs, unsigned long new_ip, 5 unsigned long new_sp, 6 unsigned int _cs, unsigned int _ss, unsigned int _ds) 7 { 8 WARN_ON_ONCE(regs != current_pt_regs()); 9 10 if (static_cpu_has(X86_BUG_NULL_SEG)) { 11 /* Loading zero below won't clear the base. */ 12 loadsegment(fs, __USER_DS); 13 load_gs_index(__USER_DS); 14 } 15 16 loadsegment(fs, 0); 17 loadsegment(es, _ds); 18 loadsegment(ds, _ds); 19 load_gs_index(0); 20 21 regs->ip = new_ip; 22 regs->sp = new_sp; 23 regs->cs = _cs; 24 regs->ss = _ss; 25 regs->flags = X86_EFLAGS_IF; 26 force_iret(); 27 }
2.3 execve系统调用总结
execve系统调用整体的调用关系为:sys_execve()或__x64_sys_execve -> do_execve() –>do_execveat_common() -> __do_execve_file -> exec_binprm()-> search_binary_handler() ->load_elf_binary() -> start_thread()。需要注意的是,execve也⽐较特殊。当前的可执⾏程序在执⾏,执⾏到execve系统调⽤时陷⼊内核态,在内核⾥⾯⽤do_execve加载可执⾏⽂件,把当前进程的可执⾏程序给覆盖掉。当execve系统调⽤返回时,返回的已经不是原来的那个可执⾏程序了,⽽是新的可执⾏程序。execve返回的是新的可执⾏程序执⾏的起点,静态链接的可执⾏⽂件也就是main函数的⼤致位置,动态链接的可执⾏⽂件还需要ld链接好动态链接库再从main函数开始执⾏。
3 进程的切换
3.1 Linux进程调度的时机
Linux内核通过schedule函数实现进程调度,schedule函数负责在运⾏队列中选择⼀个进程,然后把它切换到CPU上执⾏。所以调⽤schedule函数⼀次就是进程调度⼀次,有机会调⽤schedule函数的时候就是进程调度的时机。调⽤schedule函数的时机主要分为两类:
• 中断处理过程中的进程调度时机,中断处理过程中会在适当的时机检测need_resched标记,决定是否调⽤schedule()函数。⽐如在系统调⽤内核处理函数执⾏完成后且系统调⽤返回之前就会检测need_resched标记决定是否调⽤schedule()函数。
• 内核线程主动调⽤schedule(),如内核线程等待外设或主动睡眠等情形下,或者在适当的时机检测need_resched标记,决定是否主动调⽤schedule函数。
3.2 进程上下文
• ⽤户地址空间:包括程序代码、数据、⽤户堆栈等。
• 控制信息:进程描述符、内核堆栈等。
• 进程的CPU上下⽂,相关寄存器的值。
3.3 进程切换过程
进程切换最核心的是几个寄存器的保存和变换:
• CR3寄存器代表进程⻚⽬录表,即地址空间、数据。
• 内核堆栈栈顶寄存器sp代表进程内核堆栈(保存函数调⽤历史),进程描述符(最后的成员thread是关键)和内核堆栈存储于连续存取区域中,进程描述符存在内核堆栈的低地址,栈从⾼地址向低地址增⻓,因此通过栈顶指针寄存器还可以获取进程描述符的起始地址。
• 指令指针寄存器ip代表进程的CPU上下⽂,即要执⾏的下条指令地址。
• 这些寄存器从⼀个进程的状态切换到另⼀个进程的状态,进程切换的关键上下⽂就算完成了。
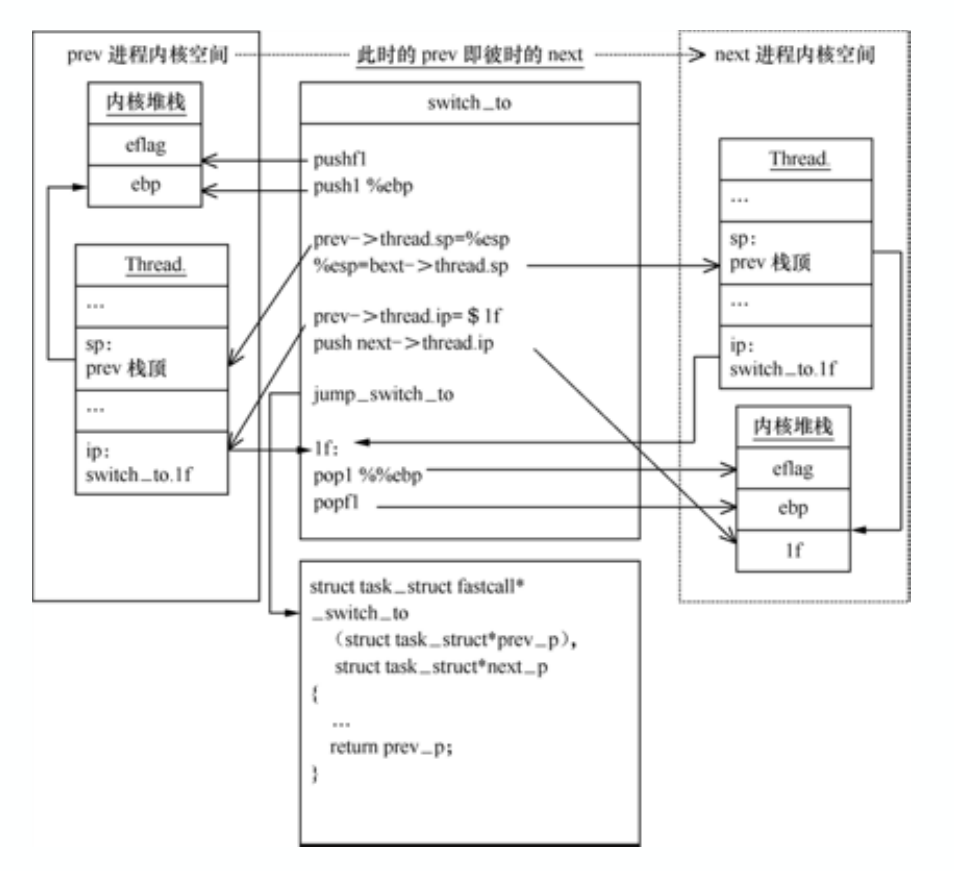
3.4 中断上下文与进程上下文
中断或异常处理程序执行的代码不是一个进程,它是一个内核控制路径,代表了中断发生时正在运行的进程执行。作为一个进程的内核控制路径,中断处理程序比一个进程要“轻”(中断上下文只包含了很有限的几个寄存器,建立和终止这个上下文所需要的时间很少)。
中断是在⼀个进程当中从进程的⽤户态到进程的内核态,或从进程的内核态返回到进程的⽤户态,⽽切换进程需要在不同的进程间切换。但⼀般进程上下⽂切换是嵌套到中断上下⽂切换中的,⽐如前述系统调⽤作为⼀种中断先陷⼊内核,即发⽣中断保存现场和系统调⽤处理过程。其中调⽤了schedule函数发⽣进程上下⽂切换,当系统调⽤返回到⽤户态时会恢复现场,⾄此完成了保存现场和恢复现场,即完成了中断上下⽂切换。
中断上下⽂和进程上下⽂的⼀个关键区别是堆栈切换的⽅法。中断是由CPU实现的,所以中断上下⽂切换过程中最关键的栈顶寄存器sp和指令指针寄存器ip是由CPU协助完成的;进程切换是由内核实现的,所以进程上下⽂切换过程中最关键的栈顶寄存器sp切换是通过进程描述符的thread.sp实现的,指令指针寄存器ip的切换是在内核堆栈切换的基础上巧妙利⽤call/ret指令实现的。
4 Linux系统的一般执行过程
(1)正在运⾏的⽤户态进程X。
(2)发⽣中断(包括异常、系统调⽤等),CPU完成load cs:rip(entry of a specific ISR),即跳转到中断处理程序⼊⼝。
(3)中断上下⽂切换,具体包括如下⼏点:
• swapgs指令保存现场,可以理解CPU通过swapgs指令给当前CPU寄存器状态做了⼀个快照。
• rsp point to kernel stack,加载当前进程内核堆栈栈顶地址到RSP寄存器。快速系统调⽤是由系统调⽤⼊⼝处的汇编代码实现⽤户堆栈和内核堆栈的切换。
• save cs:rip/ss:rsp/rflags:将当前CPU关键上下⽂压⼊进程X的内核堆栈,快速系统调⽤是由系统调⽤⼊⼝处的汇编代码实现的。
此时完成了中断上下⽂切换,即从进程X的⽤户态到进程X的内核态。
(4)中断处理过程中或中断返回前调⽤了schedule函数,其中完成了进程调度算法选择next进程、进程地址空间切换、以及switch_to关键的进程上下⽂切换等。
(5)switch_to调⽤了__switch_to_asm汇编代码做了关键的进程上下⽂切换。将当前进程X的内核堆栈切换到进程调度算法选出来的next进程(本例假定为进程Y)的内核堆栈,并完成了进程上下⽂所需的指令指针寄存器状态切换。之后开始运⾏进程Y(这⾥进程Y曾经通过以上步骤被切换出去,因此可以从switch_to下⼀⾏代码继续执⾏)。
(6)中断上下⽂恢复,与(3)中断上下⽂切换相对应。注意这⾥是进程Y的中断处理过程中,⽽(3)中断上下⽂切换是在进程X的中断处理过程中,因为内核堆栈从进程X切换到进程Y了。
(7)为了对应起⻅中断上下⽂恢复的最后⼀步单独拿出来(6的最后⼀步即是7)iret - pop cs:rip/ss:rsp/rflags,从Y进程的内核堆栈中弹出(3)中对应的压栈内容。此时完成了中断上下⽂的切换,即从进程Y的内核态返回到进程Y的⽤户态。注意快速系统调⽤返回sysret与iret的处理略有不同。
(8)继续运⾏⽤户态进程Y。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号