
深入理解系统调用
一 实验内容
找一个系统调用,系统调用号为学号最后2位相同的系统调用
通过汇编指令触发该系统调用
通过gdb跟踪该系统调用的内核处理过程
重点阅读分析系统调用入口的保存现场、恢复现场和系统调用返回,以及重点关注系统调用过程中内核堆栈状态的变化
二 实验环境
虚拟机:VMware® Workstation 12 Pro
Linux:ubuntu-18.04.4-desktop-amd64
三 实验过程
1 环境搭建
1.1 安装开发工具
1 sudo apt install build-essential 2 sudo apt install qemu # install QEMU 3 sudo apt install libncurses5-dev bison flex libssl-dev libelf-dev
1.2 下载内核源代码
1 sudo apt install axel 2 axel -n 20 https://mirrors.edge.kernel.org/pub/linux/kernel/v5.x/ 3 linux-5.4.34.tar.xz 4 xz -d linux-5.4.34.tar.xz 5 tar -xvf linux-5.4.34.tar 6 cd linux-5.4.34
1.3 配置内核选项
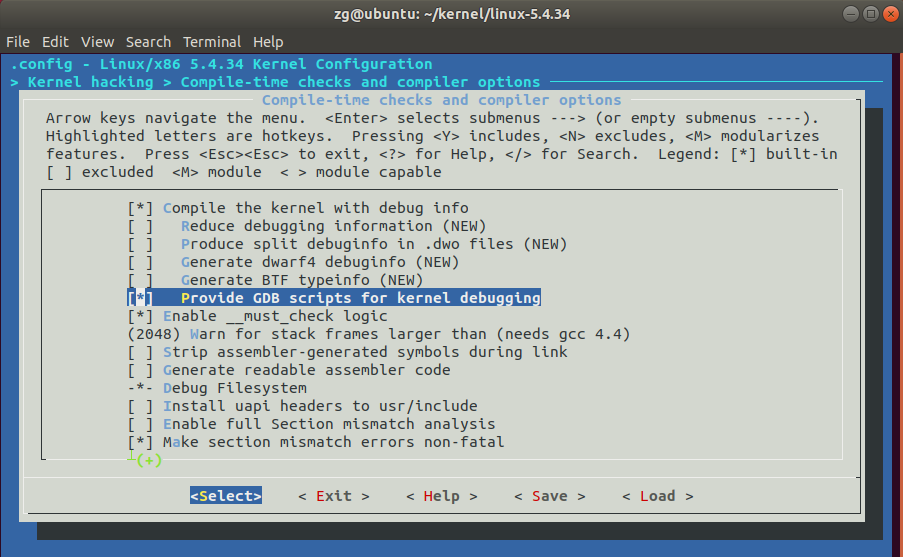
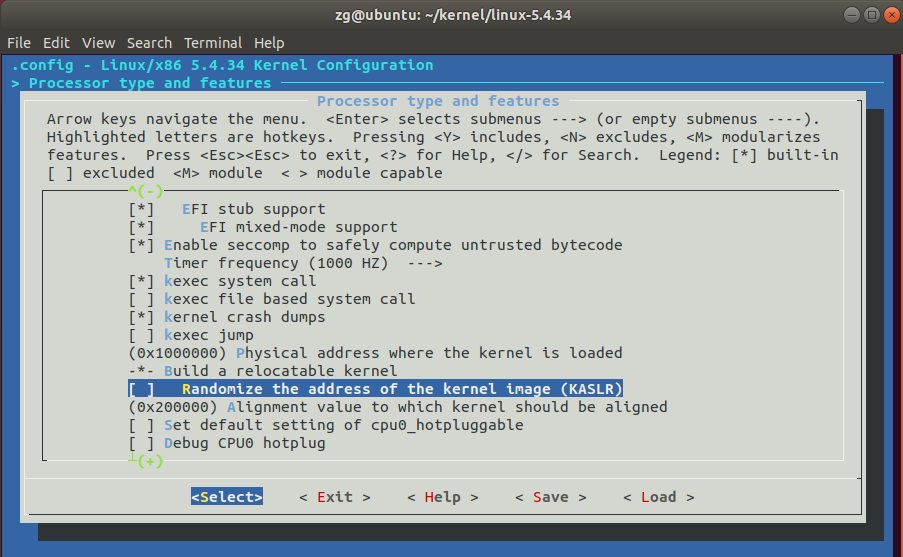
1 make defconfig # Default configuration is based on 'x86_64_defconfig' 2 make menuconfig 3 # 打开debug相关选项 4 Kernel hacking ---> 5 Compile-time checks and compiler options ---> 6 [*] Compile the kernel with debug info 7 [*] Provide GDB scripts for kernel debugging 8 [*] Kernel debugging 9 # 关闭KASLR,否则会导致打断点失败 10 Processor type and features ----> 11 [] Randomize the address of the kernel image (KASLR)
1.4 编译内核并测试啮合是否正常加载运行
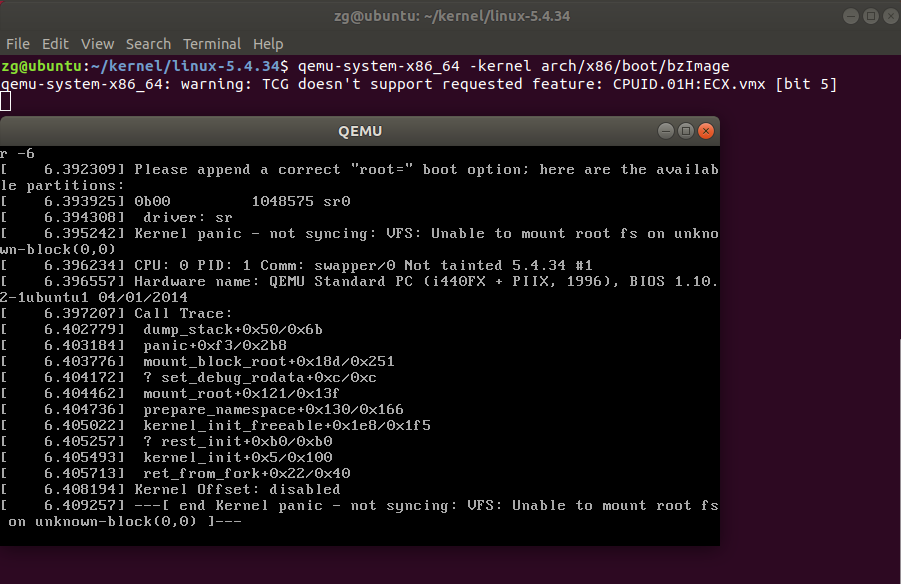
1 make -j$(nproc) # nproc gives the number of CPU cores/threads available 2 # 测试⼀下内核能不能正常加载运⾏,因为没有⽂件系统最终会kernel panic 3 qemu-system-x86_64 -kernel arch/x86/boot/bzImage
1.5 制作根文件系统——下载busybox源码并编译
电脑加电启动⾸先由bootloader加载内核,内核紧接着需要挂载内存根⽂件系统,其中包含必要的设备驱动和⼯具,bootloader加载根⽂件系统到内存中,内核会将其挂载到根⽬录/下,然后运⾏根⽂件系统中init脚本执⾏⼀些启动任务,最后才挂载真正的磁盘根⽂件系统。
我们这⾥为了简化实验环境,仅制作内存根⽂件系统。这⾥借助BusyBox 构建极简内存根⽂件系统,提供基本的⽤户态可执⾏程序。
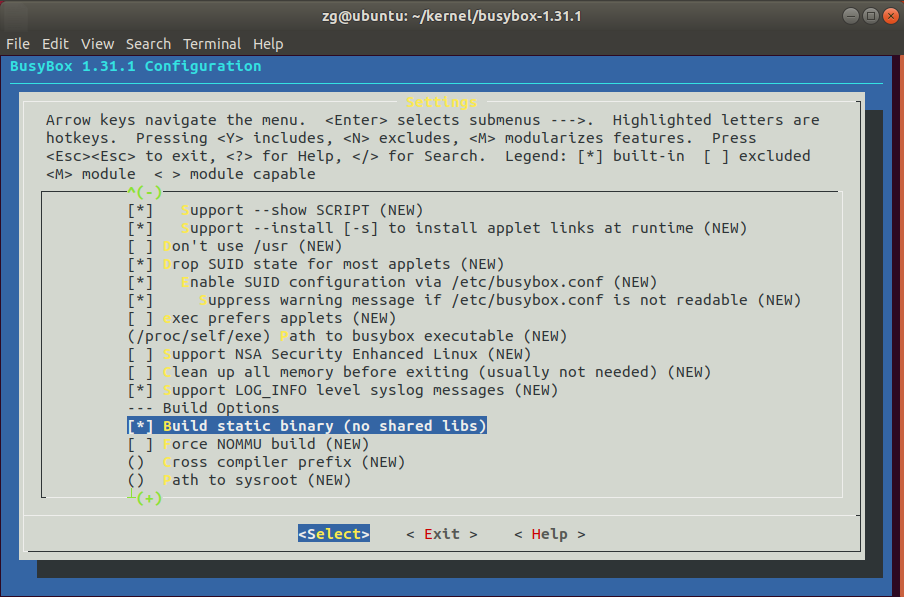
1 # 下载 2 axel -n 20 https://busybox.net/downloads/busybox-1.31.1.tar.bz2 3 tar -jxvf busybox-1.31.1.tar.bz2 4 5 # 进入busybox目录并编译 6 cd busybox-1.31.1 7 make menuconfig 8 9 # 记得要编译成静态链接,不⽤动态链接库。 10 Settings ---> 11 [*] Build static binary (no shared libs) 12 13 # 然后编译安装,默认会安装到源码⽬录下的 _install ⽬录中。 14 make -j$(nproc) && make install
1.6 制作内存根⽂件系统镜像
1 mkdir rootfs 2 cd rootfs 3 cp ../busybox-1.31.1/_install/* ./ -rf 4 mkdir dev proc sys home 5 sudo cp -a /dev/{null,console,tty,tty1,tty2,tty3,tty4} dev/
1.7 准备init脚本⽂件放在根⽂件系统根⽬录下(rootfs/init),添加如下内容到init⽂件
1 #!/bin/sh 2 mount -t proc none /proc 3 mount -t sysfs none /sys 4 echo "Wellcome ZGOS!" 5 echo "--------------------" 6 cd home 7 /bin/sh
1.8 给init脚本添加可执⾏权限
1 chmod +x init
1.9 打包成内存根⽂件系统镜像
1 find . -print0 | cpio --null -ov --format=newc | gzip -9 > ../rootfs.cpio.gz
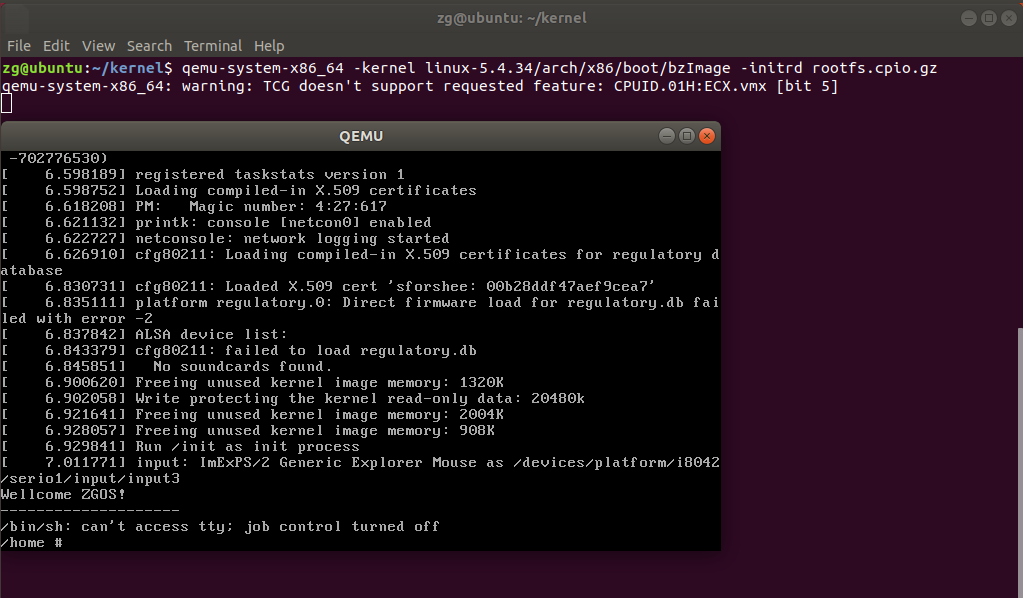
1.10 回到上级目录,测试挂载根⽂件系统,看内核启动完成后是否执⾏init脚本
1 qemu-system-x86_64 -kernel linux-5.4.34/arch/x86/boot/bzImage -initrd rootfs.cpio.gz
2 进行实验
2.1 在arch/x86/entry/syscalls/syscall_64.tbl文件中查看学号尾号为72所对应的系统调用。fcntl功能描述:用来对已打开的文件描述符进行各种控制操作来改变打开文件的各种属性。 对应内核处理函数为__x64_sys_fcntl。

2.2 通过汇编指令触发该系统调用
在rootfs/home/目录下创建文件testFCNTL.c和example_fc_acc,后者是要读取的示例文件
1 //testFCNTL.c 2 #include <unistd.h> 3 #include <stdio.h> 4 #include <stdlib.h> 5 #include <fcntl.h> 6 #include <sys/types.h> 7 #include <sys/stat.h> 8 9 10 int main(int argc, char *argv[]) 11 { 12 int ret; 13 int access_mode; 14 int fd; 15 int para = F_GETFL; 16 17 if ((fd = open("example_fc_acc", O_CREAT | O_TRUNC | O_RDWR, S_IRWXU)) == -1) { 18 perror("open failed!"); 19 exit(1); 20 } 21 22 // 获取文件打开方式 23 asm volatile( 24 "movq %1, %%rdi\n\t" //将第一个参数传入RDI寄存器 25 "movq %2, %%rsi\n\t" //将第二个参数传入RSI寄存器 26 "movl $0x48,%%eax\n\t" //使⽤EAX传递系统调⽤号 27 "syscall\n\t" //触发系统调⽤ 28 "movq %%rax,%0\n\t" //保存返回值 29 : "=m"(ret) 30 : "a"(&fd),"b"(¶) 31 ); 32 printf("ret = %d\n", ret); 33 34 // 输出文件打开方式 35 access_mode = ret & O_ACCMODE; 36 if (access_mode == O_RDONLY) { 37 printf("example_fc_acc access mode: read only"); 38 } else if (access_mode == O_WRONLY) { 39 printf("example_fc_acc access mode: write only"); 40 } else if (access_mode == O_RDWR) { 41 printf("example_fc_acc access mode: read + write"); 42 } 43 44 if (ret & O_APPEND) { 45 printf(", append"); 46 } 47 if (ret & O_NONBLOCK) { 48 printf(", nonblock"); 49 } 50 if (ret & O_SYNC) { 51 printf(", sync"); 52 } 53 printf("\n"); 54 close(fd); 55 56 return 0; 57 }
// example_fc_acc This is a test example Testing
2.3 使用gcc进行静态编译
1 gcc -o testFCNTL testFCNTL.c -static
2.4 重新制作根文件系统镜像
1 find . -print0 | cpio --null -ov --format=newc | gzip -9 > ../rootfs.cpio.gz
3 GDB调试
3.1 纯命令行下启动QEMU
1 qemu-system-x86_64 -kernel linux-5.4.34/arch/x86/boot/bzImage -initrd rootfs.cpio.gz -S -s -nographic -append "console=ttyS0"
此时QEMU会暂停在启动界面
3.2 运行gdb,进入调试环境
1 cd linux-5.4.34/ 2 # 启动 3 gdb vmlinux 4 (gdb) target remote:1234 5 # 在fcntl处打断点 6 (gdb) b __x64_sys_fcntl 7 # 继续运行 8 (gdb) c
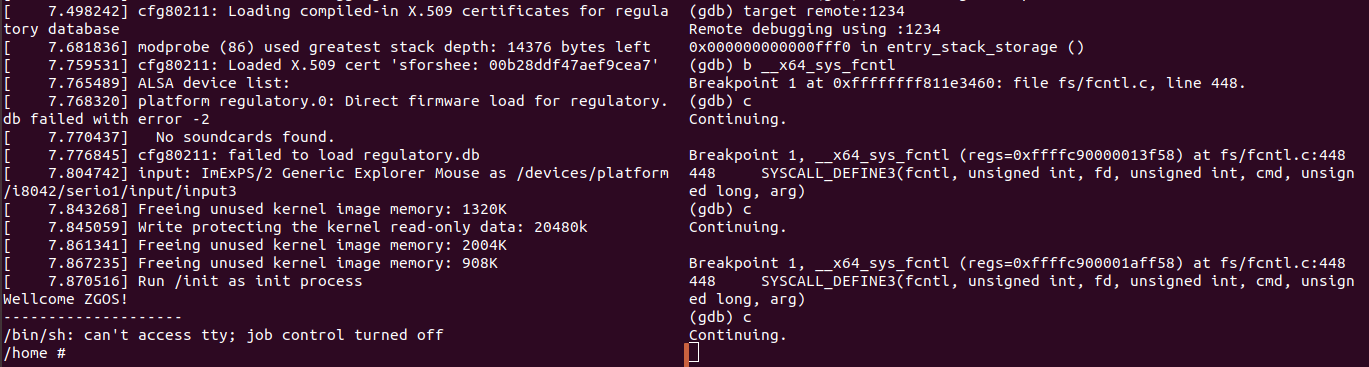
3.3 在QEMU虚拟机运行界面运行testFCNTL程序

3.4 gdb单步调试
通过l命令从第一行开始列出源码,n命令单步执行,bt命令查看函数堆栈,step命令单步调试,如果有函数调用,则进入函数
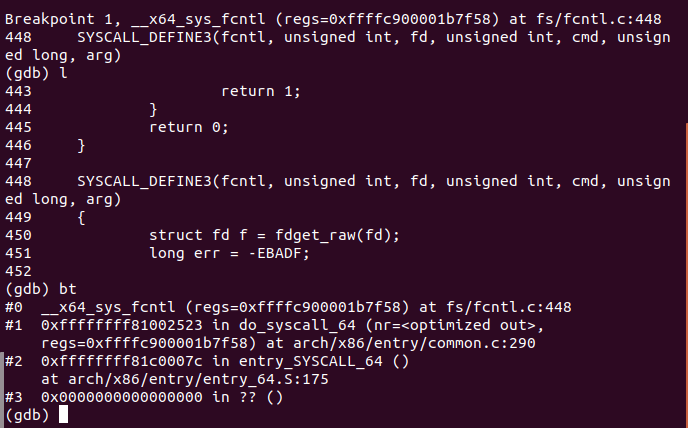
此时函数堆栈:
第一层(顶层):__x64_sys_fcntl系统调用执行函数
第二层:do_syscall_64获取系统调用号
第三层:entry_syscall_64中断入口,保存上下文
第四层:OS相关,本文暂不讨论
断点定位在fs/fcntl.c文件的448行
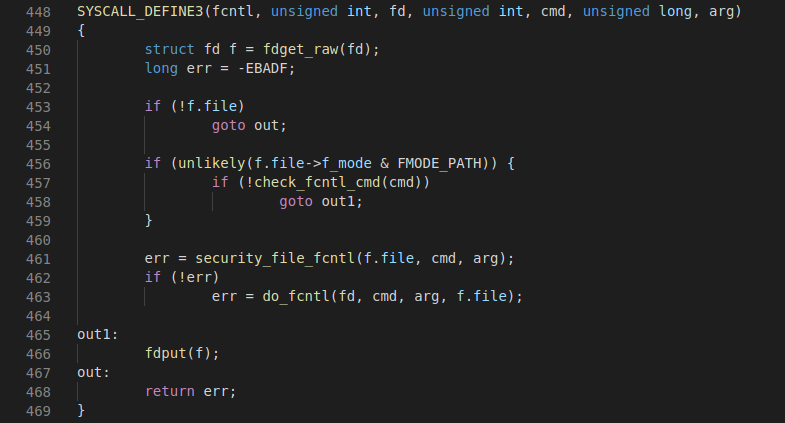
进入do_fcntl函数查看,这是完成实际系统调用功能的部分,保存现场的工作在之前已经完成
1 static long do_fcntl(int fd, unsigned int cmd, unsigned long arg, 2 struct file *filp) 3 { 4 void __user *argp = (void __user *)arg; 5 struct flock flock; 6 long err = -EINVAL; 7 8 switch (cmd) { 9 case F_DUPFD: 10 err = f_dupfd(arg, filp, 0); 11 break; 12 case F_DUPFD_CLOEXEC: 13 err = f_dupfd(arg, filp, O_CLOEXEC); 14 break; 15 case F_GETFD: 16 err = get_close_on_exec(fd) ? FD_CLOEXEC : 0; 17 break; 18 case F_SETFD: 19 err = 0; 20 set_close_on_exec(fd, arg & FD_CLOEXEC); 21 break; 22 case F_GETFL: 23 err = filp->f_flags; 24 break; 25 case F_SETFL: 26 err = setfl(fd, filp, arg); 27 break; 28 #if BITS_PER_LONG != 32 29 /* 32-bit arches must use fcntl64() */ 30 case F_OFD_GETLK: 31 #endif 32 case F_GETLK: 33 if (copy_from_user(&flock, argp, sizeof(flock))) 34 return -EFAULT; 35 err = fcntl_getlk(filp, cmd, &flock); 36 if (!err && copy_to_user(argp, &flock, sizeof(flock))) 37 return -EFAULT; 38 break; 39 #if BITS_PER_LONG != 32 40 /* 32-bit arches must use fcntl64() */ 41 case F_OFD_SETLK: 42 case F_OFD_SETLKW: 43 #endif 44 /* Fallthrough */ 45 case F_SETLK: 46 case F_SETLKW: 47 if (copy_from_user(&flock, argp, sizeof(flock))) 48 return -EFAULT; 49 err = fcntl_setlk(fd, filp, cmd, &flock); 50 break; 51 case F_GETOWN: 52 /* 53 * XXX If f_owner is a process group, the 54 * negative return value will get converted 55 * into an error. Oops. If we keep the 56 * current syscall conventions, the only way 57 * to fix this will be in libc. 58 */ 59 err = f_getown(filp); 60 force_successful_syscall_return(); 61 break; 62 case F_SETOWN: 63 err = f_setown(filp, arg, 1); 64 break; 65 case F_GETOWN_EX: 66 err = f_getown_ex(filp, arg); 67 break; 68 case F_SETOWN_EX: 69 err = f_setown_ex(filp, arg); 70 break; 71 case F_GETOWNER_UIDS: 72 err = f_getowner_uids(filp, arg); 73 break; 74 case F_GETSIG: 75 err = filp->f_owner.signum; 76 break; 77 case F_SETSIG: 78 /* arg == 0 restores default behaviour. */ 79 if (!valid_signal(arg)) { 80 break; 81 } 82 err = 0; 83 filp->f_owner.signum = arg; 84 break; 85 case F_GETLEASE: 86 err = fcntl_getlease(filp); 87 break; 88 case F_SETLEASE: 89 err = fcntl_setlease(fd, filp, arg); 90 break; 91 case F_NOTIFY: 92 err = fcntl_dirnotify(fd, filp, arg); 93 break; 94 case F_SETPIPE_SZ: 95 case F_GETPIPE_SZ: 96 err = pipe_fcntl(filp, cmd, arg); 97 break; 98 case F_ADD_SEALS: 99 case F_GET_SEALS: 100 err = memfd_fcntl(filp, cmd, arg); 101 break; 102 case F_GET_RW_HINT: 103 case F_SET_RW_HINT: 104 case F_GET_FILE_RW_HINT: 105 case F_SET_FILE_RW_HINT: 106 err = fcntl_rw_hint(filp, cmd, arg); 107 break; 108 default: 109 break; 110 } 111 return err; 112 }
继续单步执行,直到该函数执行完毕,回到函数堆栈的上一层do_syscall_64中
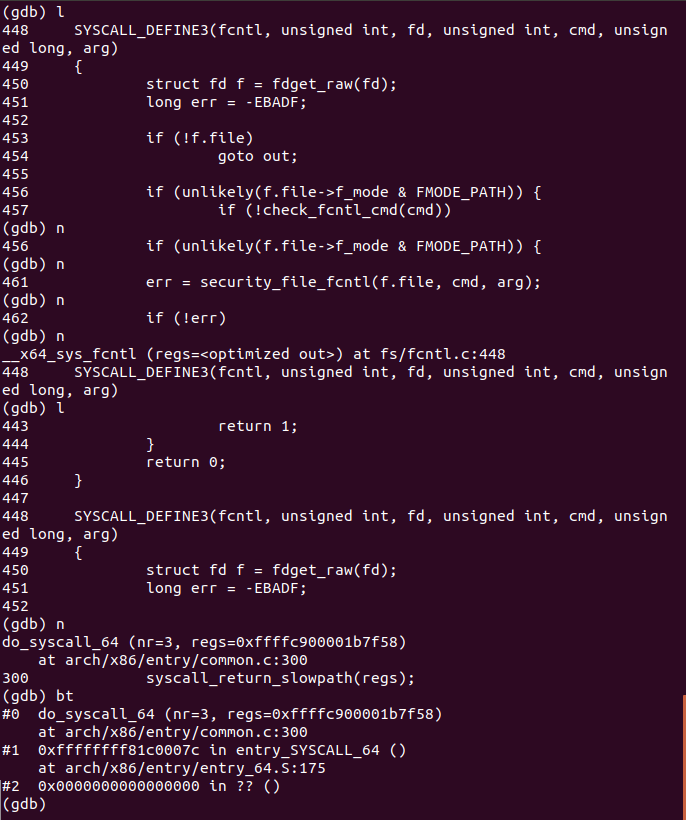
执行syscall_return_slowpath函数为恢复现场做准备,继续执行发现再次回到了函数堆栈的上一层,entry_SYSCALL_64。

接下来执行的是用于恢复现场的汇编指令
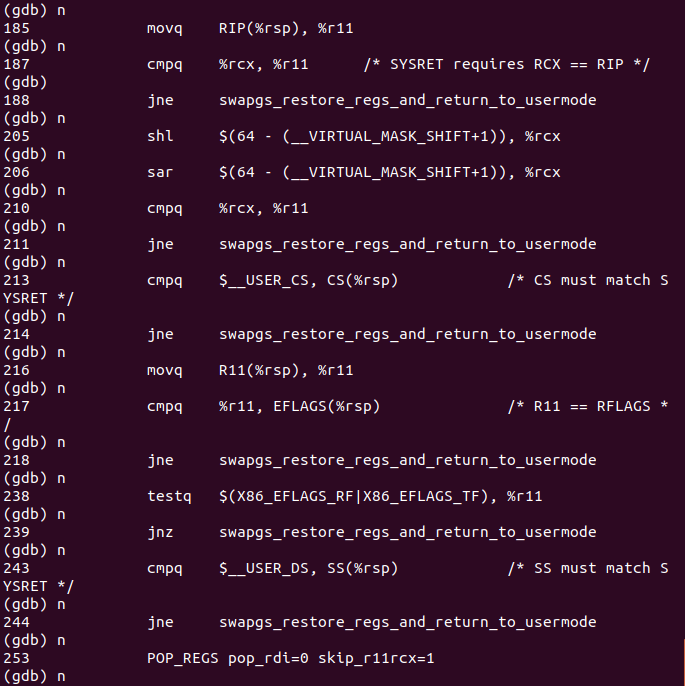
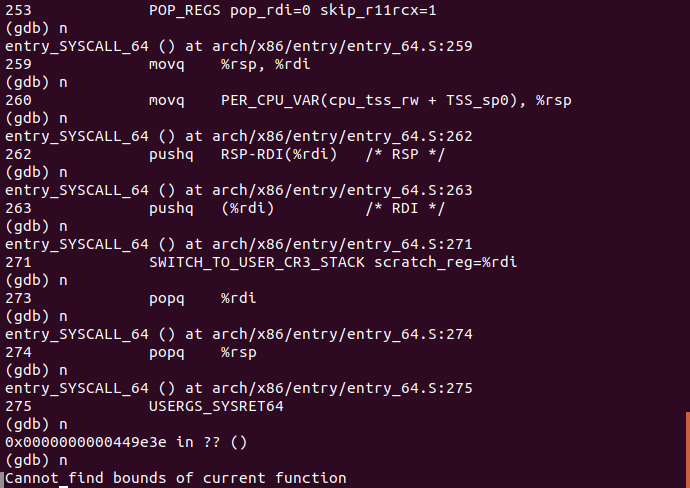
随着最后两个popq指令,恢复了rdi和rsp寄存器的内容,系统调用完成。
四 总结分析
Linux内核中设置了一组用于实现各种系统功能的子程序,称为系统调用。用户可以通过系统调用命令在自己的应用程序中调用它们。从某种角度来看,系统调用和普通的函数调用非常相似。区别仅仅在于,系统调用由操作系统核心提供,运行于核心态;而普通的函数调用由函数库或用户自己提供,运行于用户态。
系统调⽤的意义是操作系统为⽤户态进程与硬件设备进⾏交互提供了⼀组接⼝。系统调⽤具有以下功能和特性:
把⽤户从底层的硬件编程中解放出来。操作系统为我们管理硬件,⽤户态进程不⽤直接与硬件设备打交道;
极⼤地提⾼系统的安全性。如果⽤户态进程直接与硬件设备打交道,会产⽣安全隐患,可能引起系统崩溃;
使⽤户程序具有可移植性。⽤户程序与具体的硬件已经解耦合并⽤接⼝代替了,不会有紧密的关系,便于在不同系统间移植。
当⽤户态进程调⽤⼀个系统调⽤时,CPU切换到内核态并开始执⾏system_call(entry_INT80_32或entry_SYSCALL_64)汇编代码,其中根据系统调⽤号调⽤对应的内核处理函数。具体来说,在Linux中通过执⾏int $0x80或syscall指令来触发系统调⽤的执⾏,其中这条int$0x80汇编指令是产⽣中断向量为128的编程异常(trap)。另外Intel处理器中还引⼊了sysenter指令(快速系统调⽤),因为Intel专⽤AMD并不⽀持,在此不再详述。我们只关注int指令和syscall指令触发的系统调⽤,进⼊内核后,开始执⾏对应的中断服务程序entry_INT80_32或entry_SYSCALL_64。
syscall借助CPU内部的MSR寄存器来存放,所以查找系统调⽤处理⼊⼝地址会更快,因此也称为快速系统调⽤。
x86-64引⼊了swapgs指令,类似快照的⽅式将保存现场和恢复现场时的CPU寄存器也通过CPU内部的存储器快速保存和恢复,进⼀步加快了系统调⽤。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号