GLM-4.7 与 MiniMax M2.1 实测上线免费使用:国产大模型的 “工程化 + 长周期” 双赛道落地
【前言】
AI Ping 是集大模型服务平台评测与一站式调用功能于一体的专业服务平台,被开发者形象地称为“大模型 API 服务的大众点评”。2025 年 12 月 23 日,清程 AI Ping 平台正式开放 GLM-4.7 与 MiniMax M2.1 两款国产旗舰大模型的免费体验 —— 这不仅是一次产品上线,更标志着国产大模型从 “单轮能力竞赛” 转向 “真实场景落地” 的新阶段。体验参考立享30元算力金所有模型及供应商可用!
一、核心定位与适配场景:不止是评测工具,更是决策中枢
AI Ping的核心定位是中立、客观、实时的大模型服务性能评测与决策支持平台,它跳出传统"实验室评测"的局限,模拟真实业务的模型表现,构建了"评测-分析-推荐-优化"的完整闭环 。其适配场景覆盖全行业大模型使用者,尤其解决三类核心需求:
- 开发者选型决策:需在20+供应商、400+模型服务中,快速匹配"性能-成本-合规"需求;
- 企业成本管控:通过精准的价格对比与TCO计算,规避隐性支出;
- 运维稳定性监控:7x24小时追踪模型延迟、吞吐波动,提前预警高峰期服务风险。
二、两款模型:国产大模型的差异化落地路径
GLM-4.7 与 MiniMax M2.1 代表了当前国产大模型在复杂场景价值交付上的两种成熟思路:
- GLM-4.7:工程交付能力的 “精准执行者”它以 “可控推理 + 工具协同” 为核心,聚焦复杂工程任务的一次性交付—— 比如多步骤代码开发、跨系统数据对接等场景,能通过明确的逻辑链和工具调用,避免传统大模型 “答非所问”“步骤缺失” 的问题,更适配需要 “一次做对” 的生产型任务。
- MiniMax M2.1:Agent 长周期运行的 “稳定合作者”依托高效 MoE(混合专家)架构与多语言优化,它主打AI-native 组织的持续 Agent 工作流—— 比如长期客户服务 Agent、跨部门协作助理等场景,能在数天甚至数周的长周期任务中保持逻辑一致性,同时兼顾多语言、多工具的并行调度效率。
两者的共性在于:不再以 “单轮生成质量” 为核心指标,而是直指真实复杂工程场景中的长期稳定工作能力—— 这恰恰是企业落地大模型时最核心的痛点。
三、“场景适配力” 细化核心特点
1.面向真实工程的编码能力:从 “能写” 到 “能用”
- GLM-4.7:复杂工程任务的 “可靠交付者”聚焦多环节工程任务的端到端闭环完成—— 比如 “从需求文档生成分布式系统架构 + 核心模块代码 + 单元测试用例” 这类复合任务,能通过 “步骤拆解→逻辑校验→工具补全” 的可控流程,减少人工修正成本,适配需要 “一次产出可用成果” 的研发场景。
- MiniMax M2.1:多语言生产代码的 “专业适配者”深度优化 Rust/Go/Java/C++ 等生产级语言的工程化编码能力—— 不仅能生成语法正确的代码,更适配企业级项目的编码规范、性能要求(如 Rust 的内存安全、Go 的并发控制),可直接嵌入真实生产代码库,降低研发团队的集成门槛。
2.Agent 与工具调用导向:从 “能调用” 到 “能持续执行”
- GLM-4.7:多步任务的 “稳定执行者”基于 “可控思考机制” 强化多工具、多步骤任务的逻辑连贯性—— 比如 “分析数据库日志→调用监控工具定位性能瓶颈→生成优化 SQL 脚本” 这类跨工具流程,能避免中途偏离目标,适配需要 “精准按流程执行” 的运维、数据分析类 Agent 场景。
- MiniMax M2.1:长链 Agent 的 “高效合作者”依托高效 MoE 架构 + 收敛推理路径,提升连续编码、长周期 Agent 任务的运行效率—— 比如 “持续跟进客户需求→跨系统同步信息→生成定制化方案” 这类数天级的长链任务,能在保持上下文一致性的同时,降低计算资源消耗,适配需要 “长期稳定运行” 的客户服务、项目管理类 Agent 场景。
3.长期运行下的效率与成本:从 “看单次成本” 到 “算长期账”
- GLM-4.7:灵活适配的 “成本调节剂”支持推理强度按需调节 —— 可根据任务重要性,在 “高精度(高成本)” 与 “高效率(低成本)” 之间灵活切换(比如核心任务用高推理强度保障准确率,日常任务用低强度降低成本),适配成本敏感型企业的差异化需求。
- MiniMax M2.1:长周期运行的 “成本优化者”以 “低激活参数 + 长上下文窗口” 实现高吞吐与低成本的平衡—— 在长周期 Agent 任务中,无需频繁重启或重新输入上下文,既能提升任务处理效率,又能减少重复计算的资源消耗,适配需要 “长期持续运行” 的规模化业务场景。
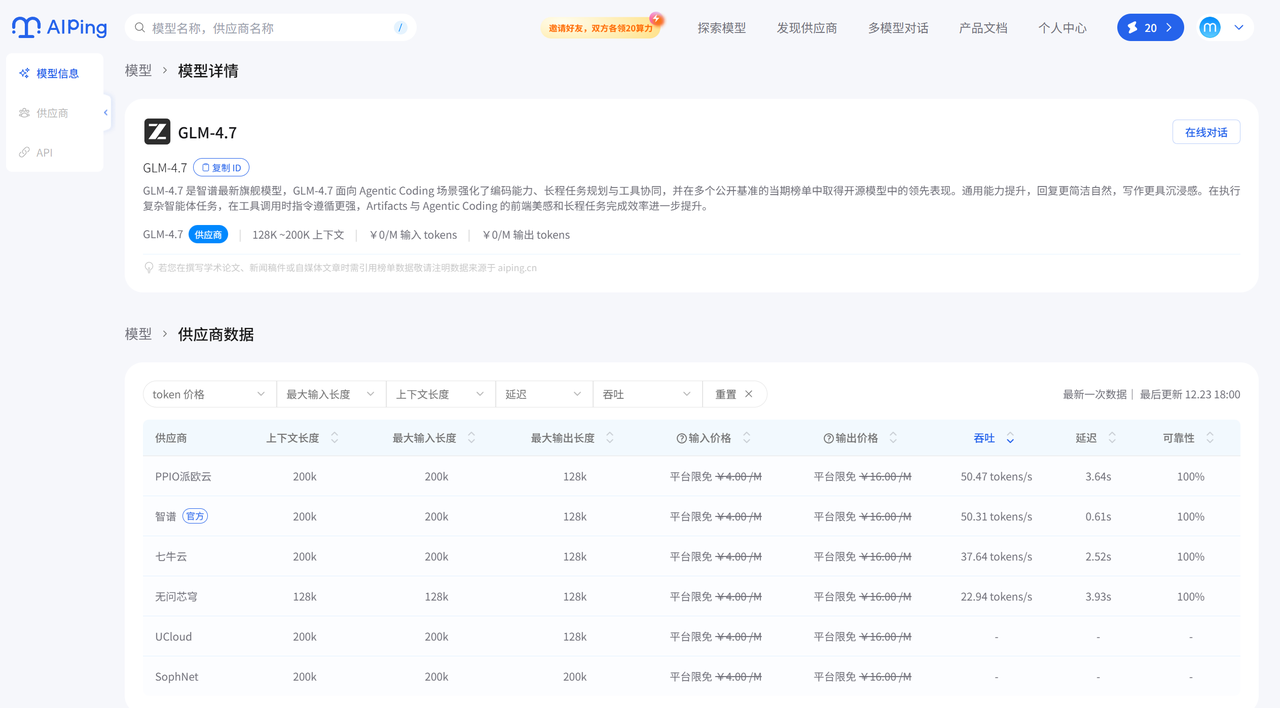
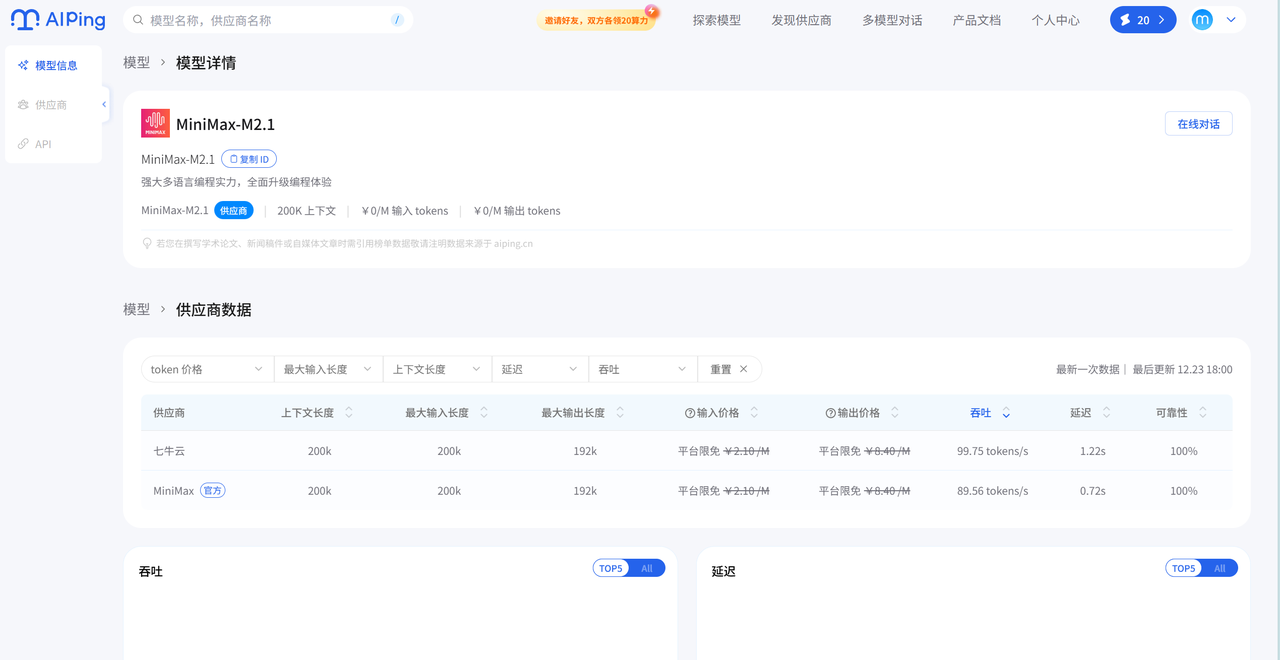
4.供应商性能表现
4.1 提取表格
GLM-4.7 供应商数据
| 供应商 | 吞吐量(tokens/s) | 延迟(P90)s | 上下文长度 | 输入价格(¥/M) | 输出价格(¥/M) | 可靠性 |
|---|---|---|---|---|---|---|
| PPIO派欧云 | 50.47 | 3.64 | 200k | 免费 | 免费 | 100% |
| 智谱(官方) | 50.31 | 0.61 | 200k | 免费 | 免费 | 100% |
| 七牛云 | 37.64 | 2.52 | 200k | 免费 | 免费 | 100% |
| 无问芯章 | 22.94 | 3.93 | 128k | 免费 | 免费 | 100% |
MiniMax M2.1 供应商数据
| 供应商 | 吞吐量(tokens/s) | 延迟(P90)s | 上下文长度 | 输入价格(¥/M) | 输出价格(¥/M) | 可靠性 |
|---|---|---|---|---|---|---|
| 七牛云 | 99.75 | 0.54 | 200k | 免费 | 免费 | 100% |
| MiniMax(官方) | 89.56 | 0.72 | 200k | 免费 | 免费 | 100% |
4.2 性能、价格对比
- 性能对比:
- 吞吐量:MiniMax M2.1的供应商(七牛云99.75、官方89.56)远高于GLM-4.7的供应商(最高50.47)。
- 延迟:两者低延迟表现都不错,但MiniMax M2.1的七牛云(0.54s)、GLM-4.7的智谱(0.61s)是目前延迟最低的。
- 上下文长度:GLM-4.7多数供应商(及MiniMax M2.1)支持200k,仅GLM-4.7的无问芯章是128k。
- 可靠性:所有供应商均为100%。
- 价格对比:
两个模型的所有供应商均为“输入/输出免费”,无成本差异。
4.3优势总结
- GLM-4.7:
优势是供应商选择较多,智谱(官方)延迟极低(0.61s),适合对延迟敏感但吞吐量需求不高的场景。
- MiniMax M2.1:
优势是吞吐量碾压式领先(七牛云近100tokens/s),且延迟也很低,适合高并发、大流量的业务场景。
4.4实际应用建议
- 若业务是高并发、大吞吐量需求(如大规模内容生成、批量接口调用):优先选MiniMax M2.1的七牛云供应商。
- 若业务是低延迟优先、吞吐量中等(如实时对话、交互类场景):可选择GLM-4.7的智谱(官方),或MiniMax M2.1的官方供应商。
- 若需要更长上下文(200k):避免GLM-4.7的无问芯章,其余供应商均可满足。
四、调用方法
1.GLM-4.7
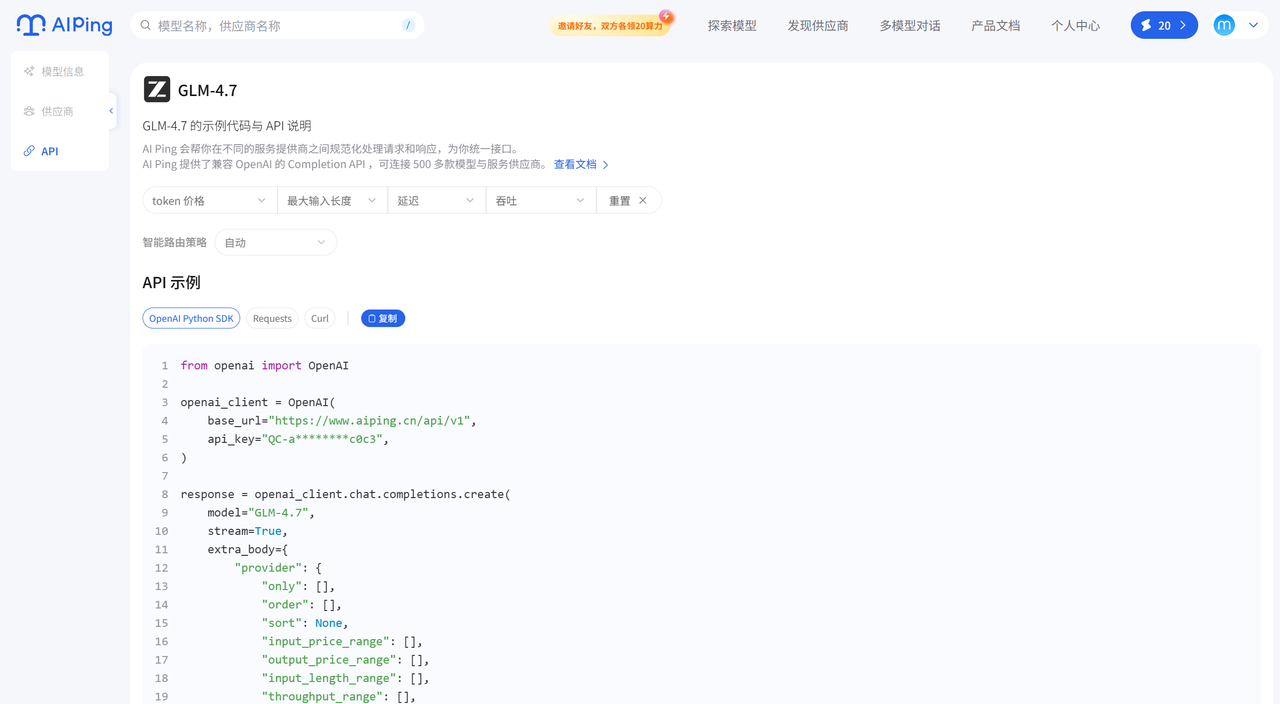
from openai import OpenAI
openai_client = OpenAI(
base_url="https://www.aiping.cn/api/v1",
api_key="QC-a6401303c2ab99296c800a73ee503336-2aaa6cf256e4ea144c2d8b50a1d0c0c3",
)
response = openai_client.chat.completions.create(
model="GLM-4.7",
stream=True,
extra_body={
"provider": {
"only": [],
"order": [],
"sort": None,
"input_price_range": [],
"output_price_range": [],
"input_length_range": [],
"throughput_range": [],
"latency_range": []
}
},
messages=[
{"role": "user", "content": "Hello"}
]
)
for chunk in response:
if not getattr(chunk, "choices", None):
continue
reasoning_content = getattr(chunk.choices[0].delta, "reasoning_content", None)
if reasoning_content:
print(reasoning_content, end="", flush=True)
content = getattr(chunk.choices[0].delta, "content", None)
if content:
print(content, end="", flush=True)
2.MiniMax M2.1

from openai import OpenAI
openai_client = OpenAI(
base_url="https://www.aiping.cn/api/v1",
api_key="QC-a6401303c2ab99296c800a73ee503336-2aaa6cf256e4ea144c2d8b50a1d0c0c3",
)
response = openai_client.chat.completions.create(
model="MiniMax-M2.1",
stream=True,
extra_body={
"provider": {
"only": [],
"order": [],
"sort": None,
"input_price_range": [],
"output_price_range": [],
"input_length_range": [],
"throughput_range": [],
"latency_range": []
}
},
messages=[
{"role": "user", "content": "Hello"}
]
)
for chunk in response:
if not getattr(chunk, "choices", None):
continue
reasoning_content = getattr(chunk.choices[0].delta, "reasoning_content", None)
if reasoning_content:
print(reasoning_content, end="", flush=True)
content = getattr(chunk.choices[0].delta, "content", None)
if content:
print(content, end="", flush=True)
3.以GLM-4.7为例获取API KEY
AI Ping 官网文档介绍很详细
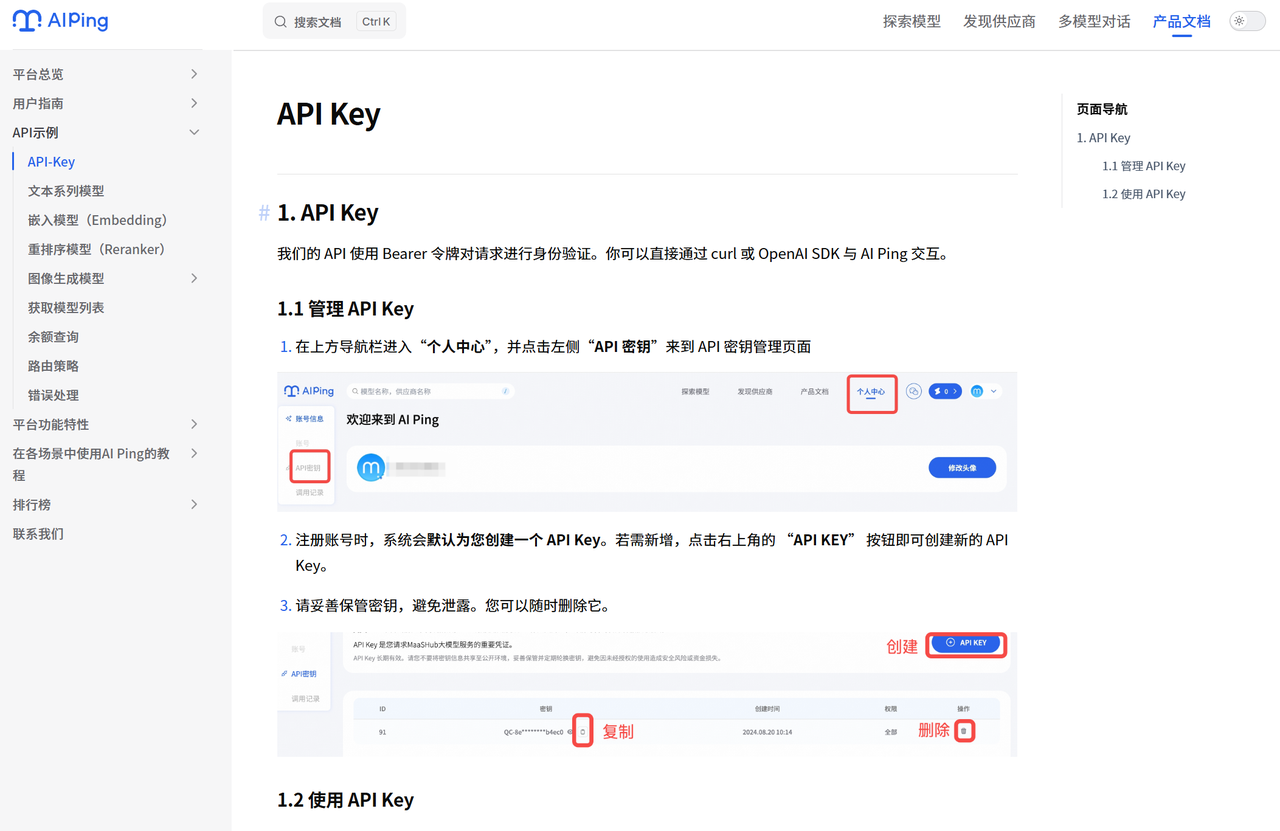
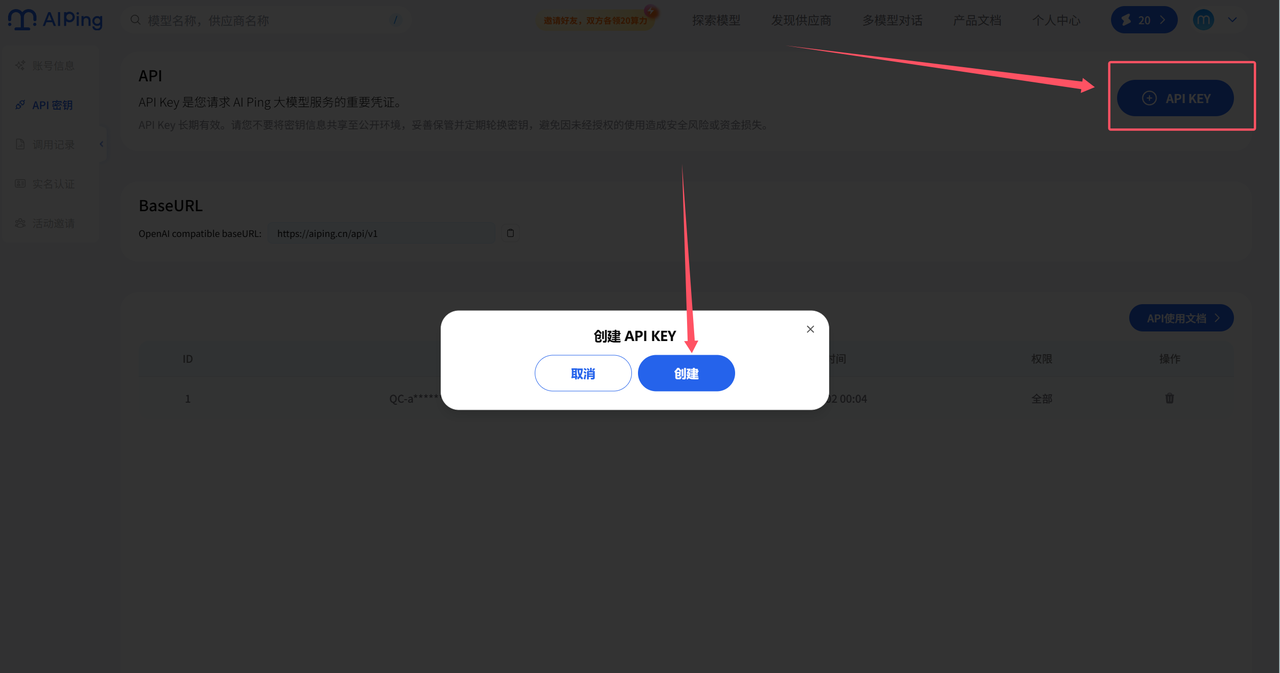
3.1先创建密钥
3.2使用Apifox进行调试
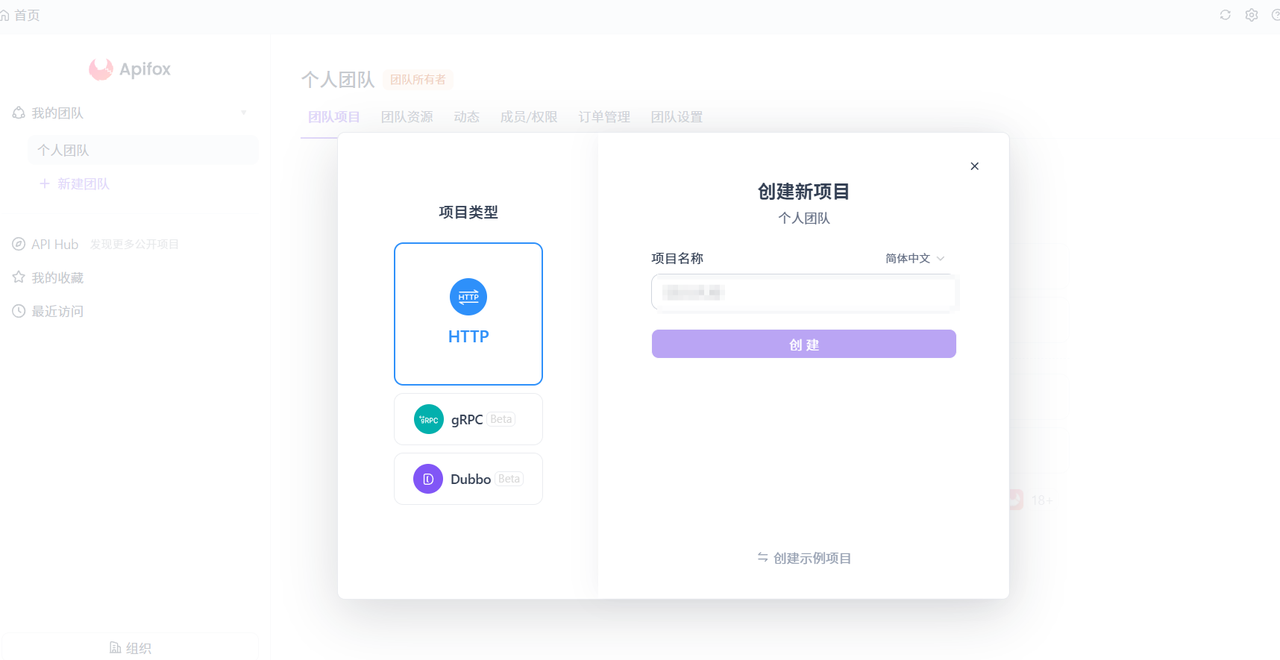
- 选择
post,进入文档查看链接
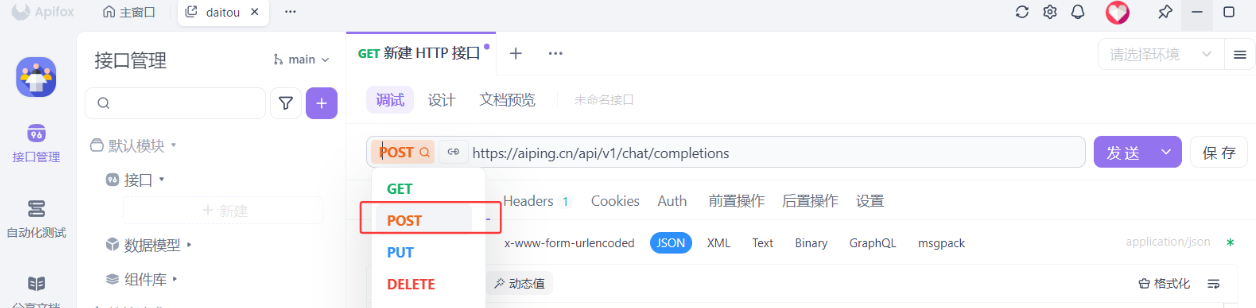
- 进入官方复制链接
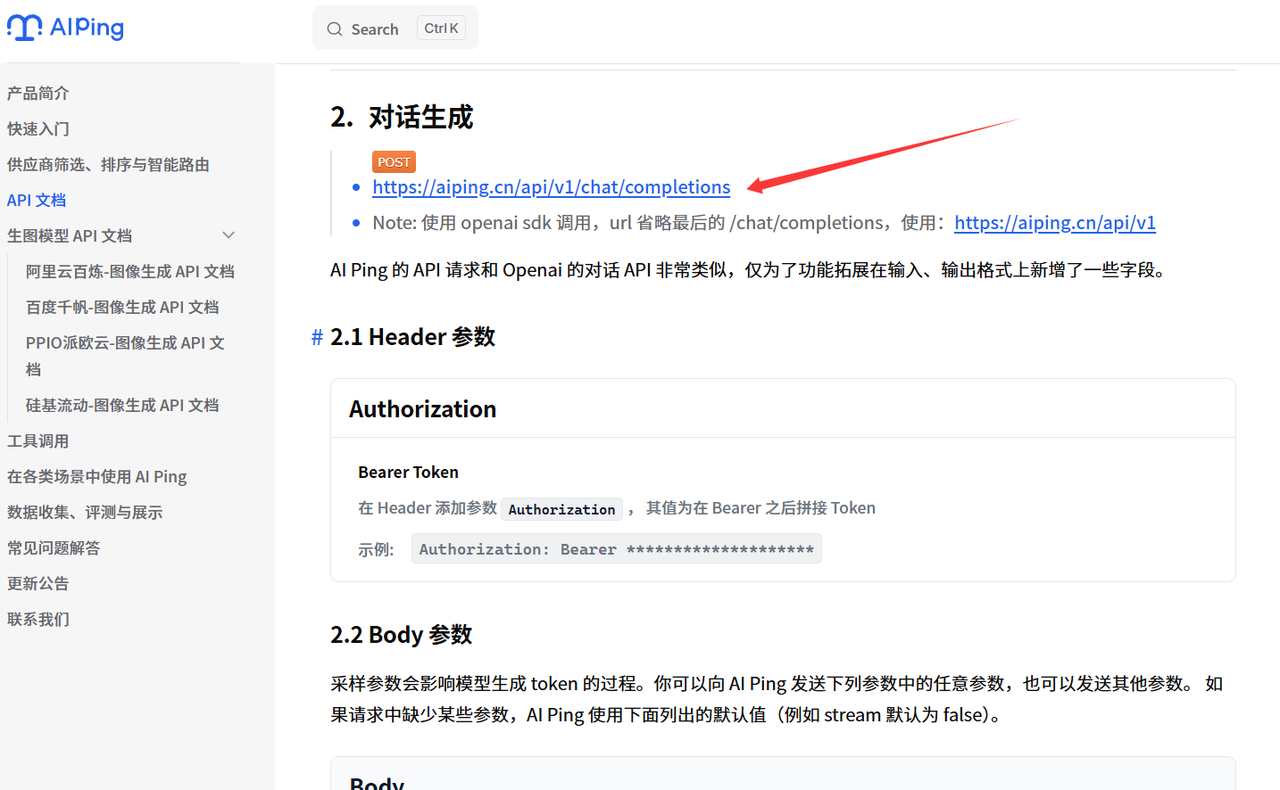
3.3 编写调用代码
- 选择Body-JSON

modle处填写自己调用的大模型
{
"model": "GLM-4.7",
"stream": true,
"messages": [
{
"role": "user",
"content": "Hello"
}
],
"extra_body": {
"enable_thinking": false
}
}
3.4 结果检查
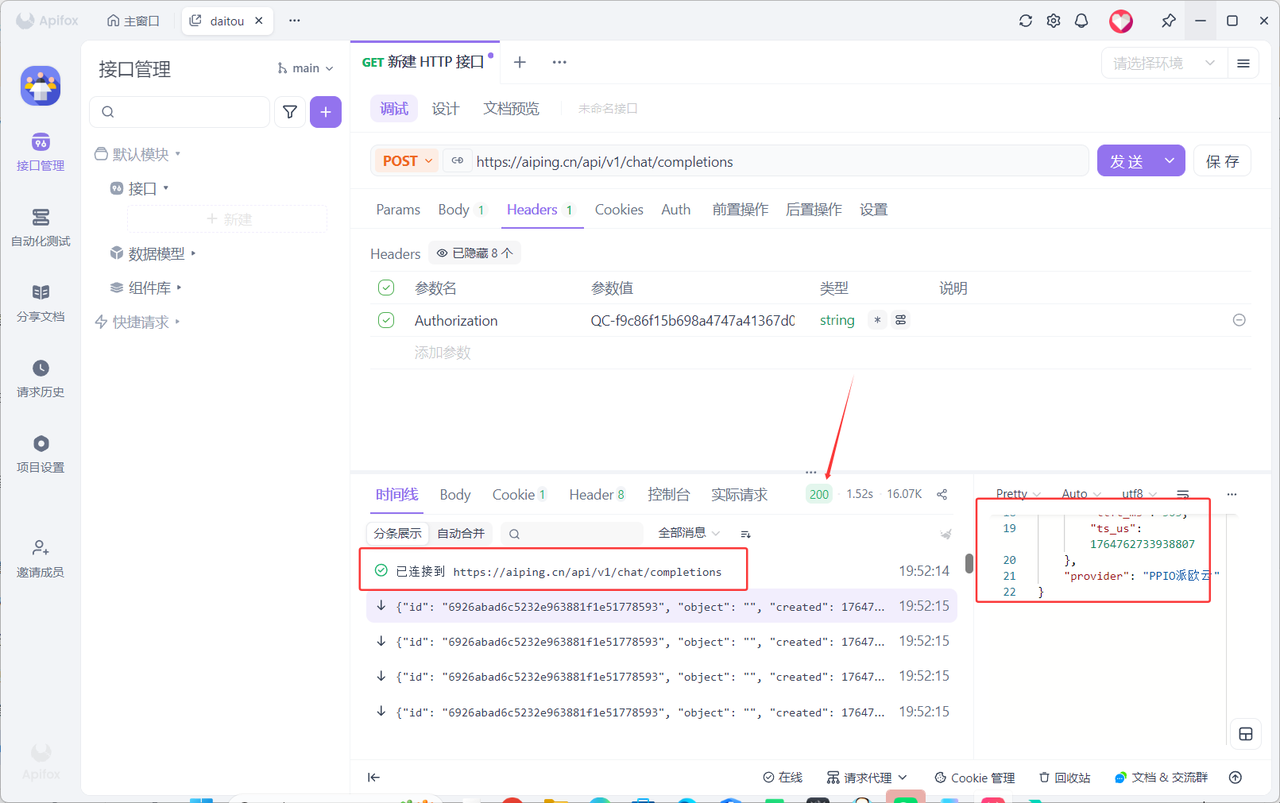
四、总结
作为两款模型的体验与调用载体,AI Ping 的核心优势在于:
- 零门槛体验:免费开放旗舰模型,无需部署算力即可测试工程 / Agent 场景的实际表现;
- 多供应商保障:接入6家供应商,通过冗余调度解决单一模型的稳定性、速度问题;
- 选型支撑:支持对比模型的任务完成率、成本等指标,帮助快速匹配业务需求;
- 实操友好:提供清晰的调用流程(以 GLM-4.7 为例),降低开发者 / 企业的落地成本。
简言之,GLM-4.7 与 MiniMax M2.1 是国产大模型 “场景适配” 的双标杆,而 AI Ping 则是连接模型与用户的 “低门槛落地工具”,共同推动国产大模型从技术到实用的落地进程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号