
该项目完整代码在 https://github.com/hithejunwei/-Opencv-
首先我了解了LBP二值化方法,可以用来处理曝光度较高的图片。
在应用SVM进行图片分类的时候遇到的问题是识别率非常低,不知道是哪里出了问题。经过两天的查找资料和详细了解SVM原理,发现问题是因为文件路径包含中文,因此SVM算法不能正常应用从而导致低识别率。调好之后SVM识别率较高,达到了0.99
.
但是看每类图像的分类结果的话,发现第7类和17类图像分类结果较差,其他类的准确率基本都为100%
 (第七类)
(第七类)
 (第17类)
(第17类)
将这个模型应用于另外四张图片,识别率仍为100%
.
之后我试验了高斯滤波,均值滤波等数据处理方法,效果都不错。然后我了解了SMOTE算法的效果和思想,就是一种运用于数据不均衡时的过采样方法,可能比简单过采样和欠采样效果要好得多。不过我目前遇到的问题是图像用SMOTE处理之后得到的新的图像无法用相关图像软件查看,而是显示内容过大或已损坏。
在这个过程中,我多次见到直方图这个概念,一开始我以为只是一维向量的形象说法,后来发现其实是图像特征的一种统计方法,比如灰度直方图统计的是每个像素的数量分布,HOG是方向梯度直方图。后者和SVM结合好像能达到强力效果(如行人检测,有待后面验证)。在学习HOG概念之后,我对前面LBP又进行了回顾,可以说这两个是很相似的,LBP是检测边缘(纹理),而HOG是检验梯度。
之后我接触了k折交叉验证的概念,在接触这个概念之前首先要弄明白训练集测试集验证集的区别,训练集用于训练模型参数,测试集用于估计模型对样本的泛化误差,验证集用于“训练”模型的超参数。就比如训练集是平时各种大考小考,验证集是考前看考场,调整各种不能由训练提升的条件如宾馆位置(超参数),测试集是最后的高考,用于验证训练成果。我们不能由训练集选择超参数,因为这样没有意义,只有在非训练集上进行超参数调整才有意义。k折交叉验证在数据量较小时意义很大,不过耗时较长,如果我们比赛不限时的话那大可采用该方法调参。
当然,我们构建的模型基本都要调参,我学习了自动调参工具网格搜索,在sklearn里面已经被封装好了,甚至能和交叉验证一起用一行代码实现,只要在网格搜索函数初始化时设定fold数就行了。当然参数范围还是需要手动设定。
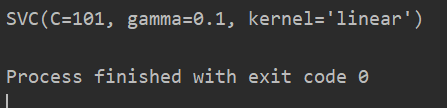
最后得到的最优参数范围是:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号