模型 - 超简易 - 推理流程 - 示例
前提:
数据集概念
模型的推理规则,由数据训练而来
流程:

以下是一个最基础、无需训练的 K近邻(KNN)分类器,并用它来对经典的鸢尾花数据集进行分类
数据集:经典的鸢尾花数据集,它包含150朵花的4个特征(花萼长宽、花瓣长宽)和3个类别标签
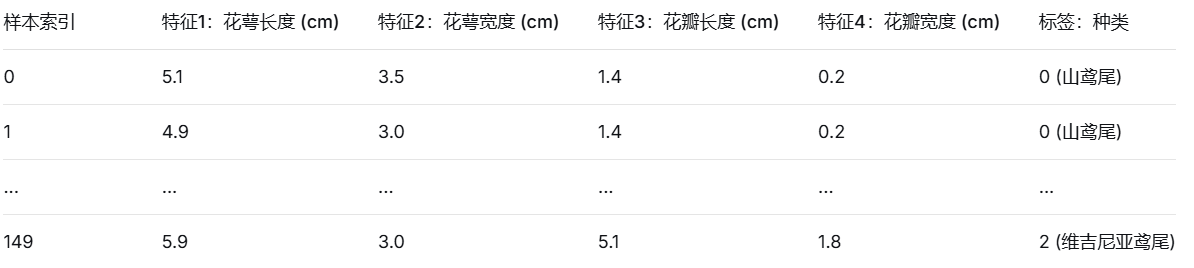
特征矩阵(X):二维数组(150,4),float类型
标签向量(Y):一维向量,映射为int类型

推理规则:KNN算法【非逻辑分支if/then/else】,基于空间几何和统计的两步推理过程
【距离度量—— 欧氏距离(也可以是其它)】->【投票决策 —— 基于邻域的统计共识】
示例代码:simple_knn.py


"""
K近邻(KNN)分类器
功能:使用纯Python实现KNN算法,并在鸢尾花数据集上测试
"""
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
import numpy as np
from collections import Counter
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
class SimpleKNN:
"""K近邻分类器"""
def __init__(self, k=3, distance_metric='euclidean'):
"""
初始化KNN模型
参数:
- k: 邻居数量,默认3
- distance_metric: 距离度量方式,可选 'euclidean'(欧氏) 或 'manhattan'(曼哈顿)
"""
self.k = k
self.distance_metric = distance_metric
self.X_train = None
self.y_train = None
def fit(self, X, y):
"""
"训练"模型:实际只是记住训练数据
这是基于实例的学习,没有参数优化过程
参数:
- X: 训练特征,形状 (n_samples, n_features)
- y: 训练标签,形状 (n_samples,)
"""
self.X_train = np.array(X)
self.y_train = np.array(y)
print(f"[训练完成] 模型已记住 {len(X)} 个训练样本")
return self
def _compute_distance(self, x1, x2):
"""
计算两个样本点之间的距离
参数:
- x1, x2: 两个样本的特征向量
返回:
- 距离值
"""
if self.distance_metric == 'euclidean':
# 欧氏距离:sqrt(Σ(x1_i - x2_i)²)
return np.sqrt(np.sum((x1 - x2) ** 2))
elif self.distance_metric == 'manhattan':
# 曼哈顿距离:Σ|x1_i - x2_i|
return np.sum(np.abs(x1 - x2))
else:
raise ValueError(f"不支持的距离度量方式: {self.distance_metric}")
def _predict_one(self, x):
"""
预测单个样本的类别
参数:
- x: 单个样本的特征向量
返回:
- 预测的类别标签
"""
# 1. 计算与所有训练样本的距离
distances = []
for i, train_sample in enumerate(self.X_train):
dist = self._compute_distance(x, train_sample)
distances.append((dist, i))
# 2. 按距离排序,取最近的k个邻居
distances.sort(key=lambda x: x[0])
k_nearest_indices = [idx for _, idx in distances[:self.k]]
# 3. 获取这些邻居的标签
k_nearest_labels = [self.y_train[idx] for idx in k_nearest_indices]
# 4. 投票:返回最常见的标签
label_counts = Counter(k_nearest_labels)
return label_counts.most_common(1)[0][0]
def predict(self, X):
"""
预测多个样本的类别
参数:
- X: 待预测样本的特征矩阵,形状 (n_samples, n_features)
返回:
- 预测的类别标签数组
"""
return np.array([self._predict_one(x) for x in X])
def evaluate(self, X_test, y_test):
"""
评估模型性能
参数:
- X_test: 测试特征
- y_test: 测试标签
返回:
- 准确率
"""
predictions = self.predict(X_test)
accuracy = np.sum(predictions == y_test) / len(y_test)
return accuracy, predictions
def main():
"""主函数:执行完整的机器学习流程"""
print("=" * 60)
print("K近邻(KNN)分类器 - 完整实现")
print("=" * 60)
# ==================== 1. 数据准备 ====================
print("\n1. 加载数据集...")
iris = datasets.load_iris()
X, y = iris.data, iris.target
feature_names = iris.feature_names
target_names = iris.target_names
print(f" 数据集: {iris.DESCR[:200]}...")
print(f" 特征: {feature_names}")
print(f" 类别: {target_names}")
print(f" 数据形状: X={X.shape}, y={y.shape}")
print(f" 样本数: {X.shape[0]}, 特征数: {X.shape[1]}")
# ==================== 2. 数据分割 ====================
print("\n2. 分割训练集和测试集...")
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
print(f" 训练集: {X_train.shape[0]} 个样本")
print(f" 测试集: {X_test.shape[0]} 个样本")
# ==================== 3. 创建和训练模型 ====================
print("\n3. 创建并训练KNN模型...")
knn_model = SimpleKNN(k=3, distance_metric='euclidean')
knn_model.fit(X_train, y_train)
# ==================== 4. 预测和评估 ====================
print("\n4. 在测试集上进行预测...")
accuracy, predictions = knn_model.evaluate(X_test, y_test)
print(f" 模型准确率: {accuracy:.2%}")
# 对比真实标签和预测标签
print("\n 测试集详细结果:")
print(" " + "-" * 50)
print(" 序号 | 真实类别 | 预测类别 | 是否正确")
print(" " + "-" * 50)
correct_count = 0
for i in range(min(10, len(y_test))): # 只显示前10个结果
true_name = target_names[y_test[i]]
pred_name = target_names[predictions[i]]
is_correct = y_test[i] == predictions[i]
if is_correct:
correct_count += 1
print(f" {i+1:4d} | {true_name:10s} | {pred_name:10s} | {'✓' if is_correct else '✗'}")
if len(y_test) > 10:
print(f" ... (其余 {len(y_test)-10} 个样本)")
# ==================== 5. 深入分析一次预测 ====================
print("\n5. 深入分析一次预测过程:")
sample_idx = 0
sample = X_test[sample_idx]
true_label = y_test[sample_idx]
print(f"\n 测试样本 {sample_idx+1}:")
for i, (name, value) in enumerate(zip(feature_names, sample)):
print(f" {name}: {value:.2f}")
print(f" 真实类别: {target_names[true_label]}")
# 手动计算距离
print(f"\n 计算与训练集前5个样本的距离:")
for i in range(min(5, len(knn_model.X_train))):
dist = knn_model._compute_distance(sample, knn_model.X_train[i])
train_label = knn_model.y_train[i]
print(f" 训练样本{i+1} ({target_names[train_label]}): 距离 = {dist:.4f}")
# 进行预测
pred_label = knn_model._predict_one(sample)
print(f"\n 最终预测: {target_names[pred_label]}")
print(f" 预测是否正确: {'是' if true_label == pred_label else '否'}")
# ==================== 6. 实验不同参数 ====================
print("\n6. 实验不同参数对性能的影响:")
print(" " + "-" * 50)
# 测试不同的k值
k_values = [1, 3, 5, 7, 9]
print("\n 不同k值的准确率:")
for k in k_values:
test_model = SimpleKNN(k=k)
test_model.fit(X_train, y_train)
accuracy, _ = test_model.evaluate(X_test, y_test)
print(f" k={k}: {accuracy:.2%}")
# 测试不同的距离度量
print("\n 不同距离度量的准确率:")
for metric in ['euclidean', 'manhattan']:
test_model = SimpleKNN(k=3, distance_metric=metric)
test_model.fit(X_train, y_train)
accuracy, _ = test_model.evaluate(X_test, y_test)
print(f" {metric}: {accuracy:.2%}")
# ==================== 7. 与sklearn的KNN对比 ====================
print("\n7. 与sklearn官方KNN实现对比:")
try:
from sklearn.neighbors import KNeighborsClassifier
sklearn_knn = KNeighborsClassifier(n_neighbors=3)
sklearn_knn.fit(X_train, y_train)
sklearn_accuracy = sklearn_knn.score(X_test, y_test)
print(f" KNN准确率: {accuracy:.2%}")
print(f" sklearn KNN准确率: {sklearn_accuracy:.2%}")
if abs(accuracy - sklearn_accuracy) < 0.01:
print(" ✓ 两者性能接近,实现正确!")
else:
print(" ⚠ 性能有差异,检查距离计算或投票逻辑")
except ImportError:
print(" 无法导入sklearn,跳过对比")
print("\n" + "=" * 60)
print("\n脚本执行完成!")
print("=" * 60)
if __name__ == "__main__":
main()
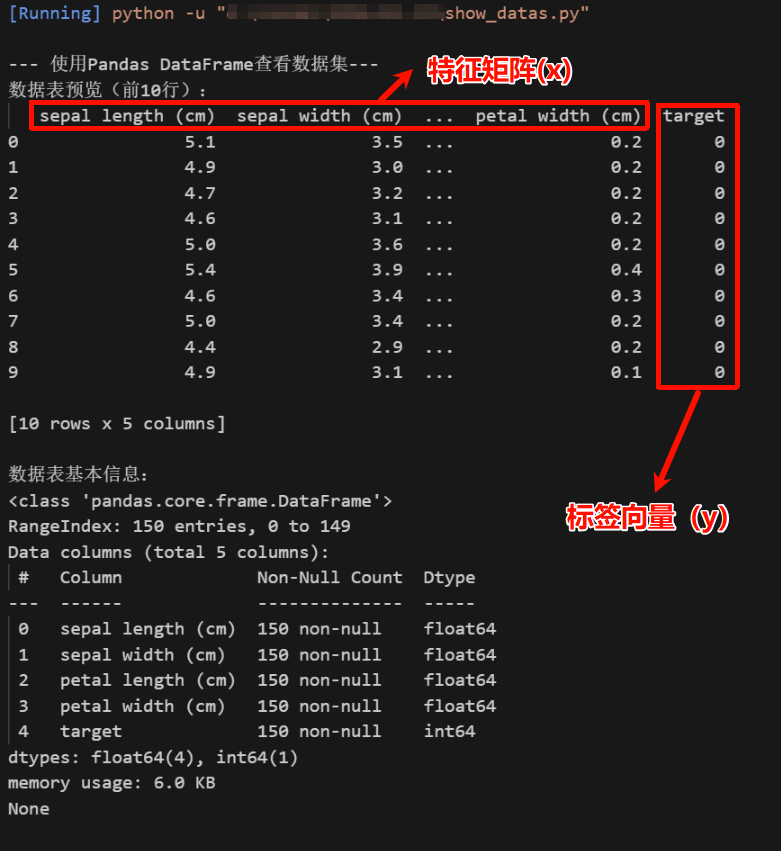
PS:数据集的数据展示
import sys
import io
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
import numpy as np
from sklearn import datasets
import pandas as pd
def main():
iris = datasets.load_iris()
print("\n--- 使用Pandas DataFrame查看数据集---")
# 1. 先用特征数据创建DataFrame
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
# 2. 追加显示对应的标签列
iris_df['target'] = iris.target
print("数据表预览(前10行):")
print(iris_df.head(10))
# iris_df.to_csv('iris_data.csv', index=False, encoding='utf-8')
print("\n数据表基本信息:")
print(iris_df.info())
if __name__ == "__main__":
main()
作者:人间春风意
扫描左侧的二维码可以赞赏

本作品采用署名-非商业性使用-禁止演绎 4.0 国际 进行许可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号