20242309实验四《Python程序设计》实验报告
20242309 2024-2025-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 2324
姓名: 邱贤达
学号:20242309
实验教师:王志强
实验日期:2025年5月14日
必修/选修: 公选课
一、需求分析
老师在教室中用笔记本作为麦克风录制的视频声音噪音较大,且随着老师的走动声音时大时小,这对同学人声辨别能力要求较高。因此我想到写一个实时降噪程序,用户只需要安装VB Cable音频重定向软件即可改善任何网页上的声音质量。
二、实验内容
-
实现声音实时降噪输出
-
在华为ECS服务器(OpenEuler系统)执行
三、 实验过程及结果
(一)将浏览器播放的音频重定向到虚拟输入设备
1)配置 VB-Cable 虚拟音频线
-
下载安装 VB-Audio Cable
-
打开“设置”->“系统”->“声音”,在 “输出” 栏,选择 “CABLE Input” ,在 “录制” 栏,选择 “CABLE Output” 。
2)播放音频到虚拟声卡
-
安装依赖
pip install pyaudio sounddevice numpy==1.26.4和pip install pydub -
列出所有可用的音频输出设备
def list_audio_output_devices(): p = pyaudio.PyAudio() for i in range(p.get_device_count()): # p.get_device_count()获取系统上可用的音频设备总数 device_info = p.get_device_info_by_index(i) # 返回一个包含设备详细信息的字典 # 检查设备是否支持音频输出(maxOutputChannels > 0表示有输出能力) if device_info["maxOutputChannels"] > 0: device_name = device_info['name'] print(f"设备索引: {i}, 设备名称: {device_name}, 采样率: {device_info['defaultSampleRate']}") -
编写声音检测程序
import sounddevice as sd import numpy as np # 音频参数 SAMPLE_RATE = 44100 #人类听觉范围20-20kHz的奈奎斯特采样率 CHUNK_SIZE = 1024 def print_level(indata, frames, time, status): rms = np.sqrt(np.mean(indata**2)) # 计算RMS值 print(f"输入电平: {rms*1000:.1f} mV ", end='\r') # 实时刷新显示,'\r'表示回到行首 # 捕获音频数据 with sd.InputStream(callback=print_level, #callback向print_level传入参数 blocksize=CHUNK_SIZE, samplerate=SAMPLE_RATE): print("开始监听") while True: sd.sleep(1000)当运行程序并播放声音时,声音不会外放,但会听到终端电平的变化
(二)Python捕获虚拟设备的音频流
1)学习音频相关知识
-
几个重要的变量
-
sample_rate / samplerate 采样率 标准CD音质采样率为44100
-
chunk_size / blocksize 每次处理帧数
-
channels 声道数 (单声道减少数据量)
-
dtype 音频数据的格式 标准音频格式为float32
-
device 音频输入设备的ID或名称
-
-
相关函数 (numpy)
-
np.zeros 创建一个全零的数组
-
np.roll 沿指定轴“滚动”数组元素(类似环形移位)
-
torch.from_numpy 将NumPy数组转换为PyTorch张量
-
2)编写捕获类
import sounddevice as sd
import numpy as np
from queue import Queue, Empty
import threading
class AudioCapturer:
def __init__(self, device_name="CABLE Output", chunk_size=1024):
self.device_id = self._find_device(device_name)
self.sample_rate = 44100 # 标准CD音质采样率
self.chunk_size = chunk_size # 每次处理1024帧
self.audio_queue = Queue(maxsize=100) # 音频数据队列
self.running = False # 运行状态标志
def _find_device(self, name):
"""根据名称查找音频设备ID"""
for i, dev in enumerate(sd.query_devices()):
if name in dev['name'] and dev['max_input_channels'] > 0:
print(f"找到设备: {dev['name']} (ID={i})")
return i
raise ValueError(f"设备'{name}'未找到") #主动抛出异常
def _audio_callback(self, indata, frames, time, status):
"""音频数据到达时的自动回调"""
if status:
print(f"警告: {status}")
try:
# 如果队列接近满,清空一些旧数据
if self.audio_queue.qsize() >= self.audio_queue.maxsize - 1:
try:
while self.audio_queue.qsize() > self.audio_queue.maxsize // 2:
self.audio_queue.get_nowait()
except Empty:
pass
# 将数据拷贝后放入队列
self.audio_queue.put(indata.copy(), block=False)
except:
print("队列处理异常")
def start_capture(self):
"""启动音频捕获线程"""
if self.running:
return
self.running = True
self.capture_thread = threading.Thread(target=self._capture_loop)
# 创建线程 避免阻塞主线程
self.capture_thread.start()
def _capture_loop(self):
"""音频捕获主循环"""
with sd.InputStream(
device=self.device_id,
samplerate=self.sample_rate,
blocksize=self.chunk_size,
channels=1, # 单声道减少数据量
dtype='float32', # 标准音频格式
callback=self._audio_callback
):
print("音频捕获已启动...")
while self.running:
sd.sleep(100) # 代码暂停执行,降低 CPU 占用率,但因为捕获是异步的,仍会进行
def stop_capture(self):
"""安全停止捕获"""
self.running = False
if self.capture_thread.is_alive():
self.capture_thread.join()
print("音频捕获已停止")
def get_audio_data(self, timeout=1):
"""从队列获取音频数据"""
try:
return self.audio_queue.get(timeout=timeout)
except Empty:
return None
(三)对音频流进行分块处理降噪
1)降噪技术介绍
我采用的是Demucs AI降噪集成,它利用深度学习模型,通过频谱和波形损失优化音频质量,并通过数据增强和优化设计实现高效的降噪和音源分离。
2)相关函数介绍
-
get_model('htdemucs') 加载预训练的 Demucs 模型。
-
self.model.eval() 将模型设置为评估模式(关闭模型的训练相关功能)
-
torch.from_numpy(inp) 将 NumPy 数组转换为 PyTorch 张量,适用于后续处理
-
torch.no_grad() 禁用梯度计算,减少内存占用
-
self.model(wav) 将输入张量 wav 传递给 Demucs 模型进行推理
3)整体降噪代码
# NoiseReducer2.py
import numpy as np
import torch
import demucs
class DemucsReducer:
def __init__(self, sample_rate=44100, chunk_size=512, device='cpu'):
self.sample_rate = sample_rate # 音频采样率
self.chunk_size = chunk_size # 每次处理的音频块大小
self.device = device # 计算设备,默认CPU
self._init_model()
self._buffer = np.zeros(chunk_size * 4, dtype=np.float32) # Demucs 需要较长帧
self._buf_pos = 0
def _init_model(self): # 加载预训练模型
from demucs.pretrained import get_model
self.torch = torch # PyTorch 它是一个开源的深度学习框架
self.model = get_model('htdemucs').cpu() if self.device == 'cpu' else get_model('htdemucs').cuda()
self.model.eval() # 设置为评估模式(不计算梯度),更加高效
def process_frame(self, frame):
# 累积到足够长度再处理
n = len(frame)
if self._buf_pos + n > len(self._buffer):
# 空间不足时,左移缓冲区丢弃最早的数据
shift = self._buf_pos + n - len(self._buffer)
self._buffer = np.roll(self._buffer, -shift)
self._buf_pos -= shift
# 将新数据存入缓冲区
self._buffer[self._buf_pos:self._buf_pos+n] = frame
self._buf_pos += n # 更新缓冲区位置指针
# Demucs 推荐最少0.5秒音频,这里用缓冲区
if self._buf_pos < self.sample_rate // 2:
return frame # 缓冲不够,直接返回原始
# Demucs 处理
inp = self._buffer[:self._buf_pos]
wav = torch.from_numpy(inp).float().unsqueeze(0).unsqueeze(0) # 准备输入数据:转换为PyTorch张量并添加批次和通道维度 [1, 1, T]
#开始降噪
with torch.no_grad():
enhanced = self.model(wav)[0, 0].cpu().numpy()
# 只返回最新处理的部分
out = enhanced[-n:]
# 为什么只取最后 n 个样本?
# 模型处理的是整个缓冲区,但只需返回与当前输入帧长度 n 匹配的部分
self._buffer = np.roll(self._buffer, -n)
self._buf_pos -= n
return out
(四)将处理后的音频发送到物理输出设备
1)通过索引找到输出设备,如耳机
def list_audio_output_devices():
p = pyaudio.PyAudio()
for i in range(p.get_device_count()): # p.get_device_count()获取系统上可用的音频设备总数
device_info = p.get_device_info_by_index(i)# 返回一个包含设备详细信息的字典
# 检查设备是否支持音频输出(maxOutputChannels > 0表示有输出能力)
if device_info["maxOutputChannels"] > 0:
device_name = device_info['name']
print(f"设备索引: {i}, 设备名称: {device_name}, 采样率: {device_info['defaultSampleRate']}")
我的耳机设备索引为6。
2)编写程序
# main.py
import sounddevice as sd
from AudioCapturer2 import AudioCapturer
from NoiseReducer2 import EchoReducer, DemucsReducer # 新增 DemucsReducer
capturer = AudioCapturer(chunk_size=512) # 必须与降噪器块大小一致
reducer = DemucsReducer(sample_rate=44100, chunk_size=512)
capturer.start_capture()
try:
with sd.OutputStream(samplerate=44100, channels=1, blocksize=512, dtype='float32',device=6) as stream:
while True:
chunk = capturer.get_audio_data()
if chunk is not None:
processed = reducer.process_frame(chunk.flatten())
processed = processed.astype('float32') # 转换数据类型为float32
stream.write(processed.reshape(-1, 1)) #将一维的音频数据数组转换为二维数组再输出
# 健壮性增强
except KeyboardInterrupt: # 捕获Ctrl+C中断
print("\n程序被用户中断")
capturer.stop_capture()
except Exception as e: # 捕获其他异常
print(f"\n发生错误: {e}")
capturer.stop_capture()
(五)实验结果
-
首先录制一段试验音频,再运行主程序,将试验音频输入到CABLE input,录制python输出的结果。
-
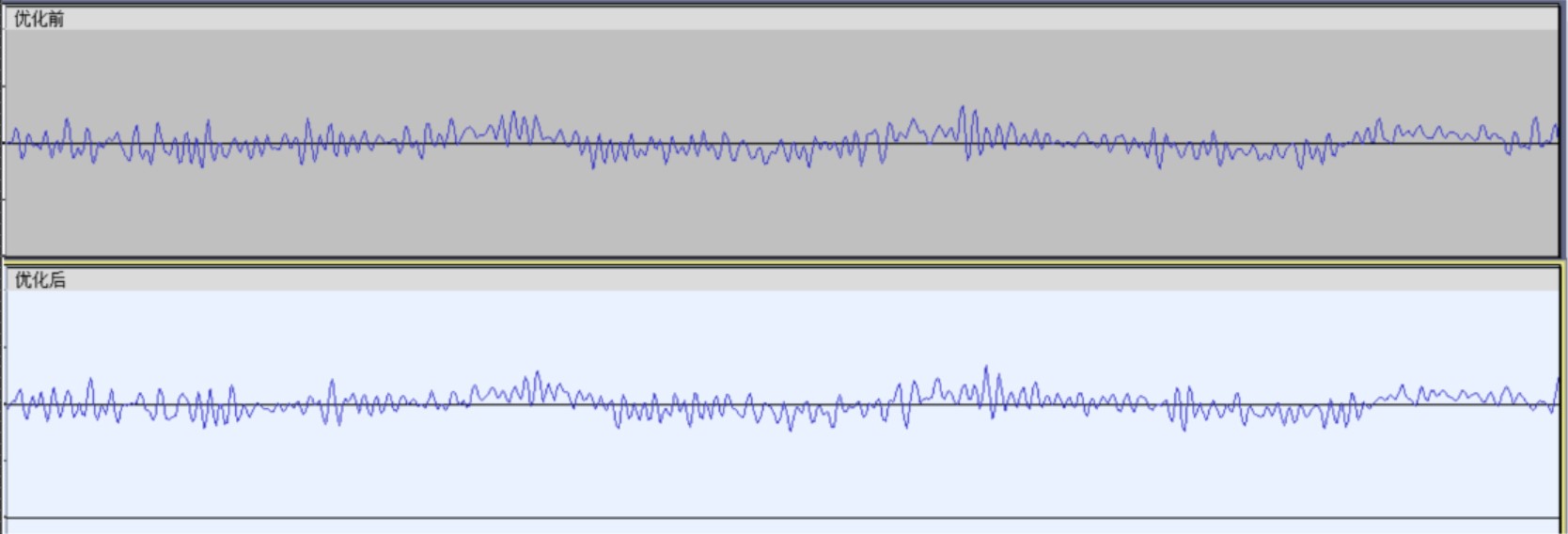
在Audacity中,对比两段录音,有优化效果
![]()
-
优化前后的音频对比,上传在gitee上
-
视频展示
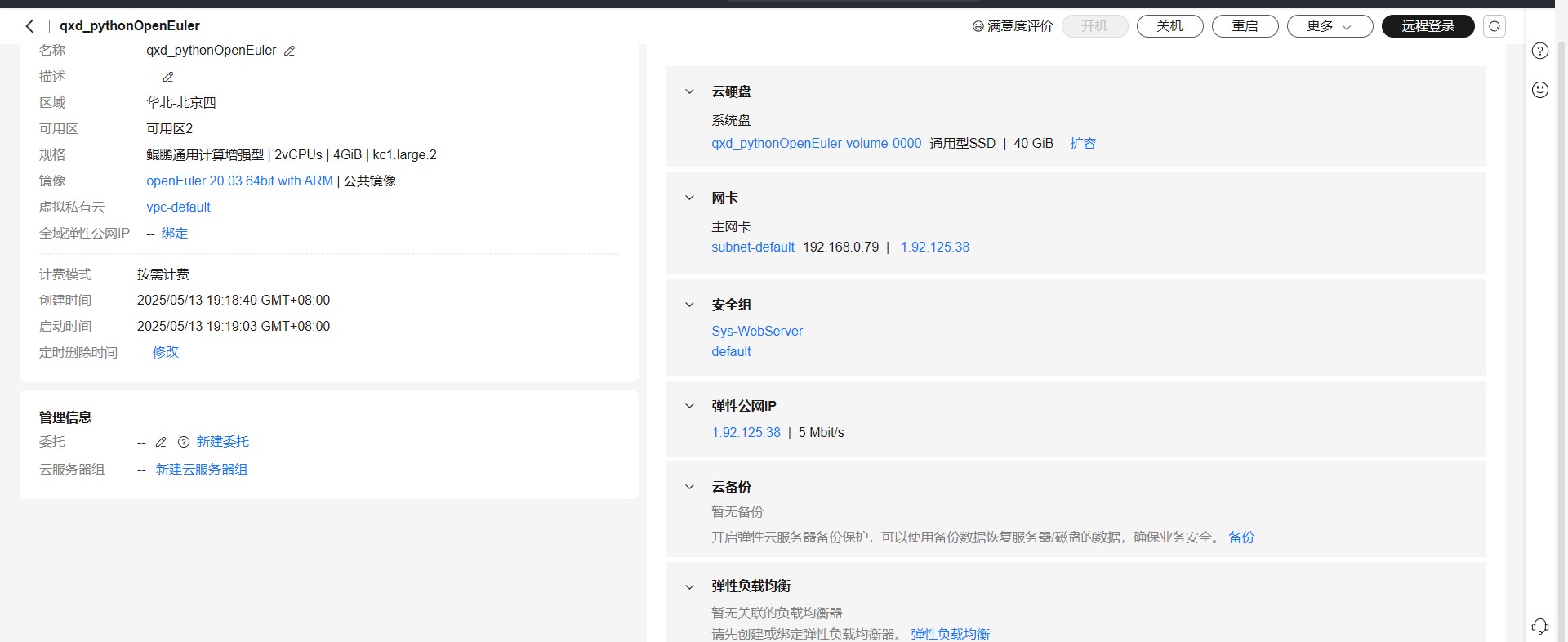
(六)在华为云ESC上运行
1)配置服务器
2)写入python文件
下载库文件 pip3 install --user demucs numpy torch sounddevice
发现demucs需要python3.8以上的版本,因此先安装pytho
wget https://www.python.org/ftp/python/3.9.4/Python-3.9.4.tgz
tar -xvf Python-3.9.4.tgz
cd Python-3.9.4
./configure --enable-optimizations
make
sudo make altinstall
遗憾的是,无论在华为云服务器还是本地虚拟机上,我无法将声音直接输出到耳机,因此我运行了一个外壳。
使用vim编辑器,输入vim AudioCapturer2.py、vim NoiseReducer2.py、vim mainn.py,按i进入插入模式,将代码复制粘贴后按Esc + :wq保存退出。效果如下:
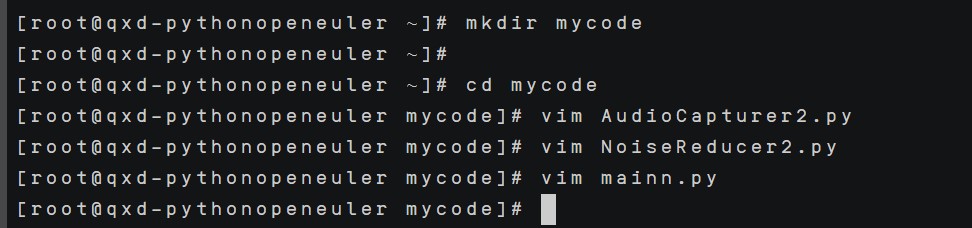
运行,结果如下:

3. 实验过程中遇到的问题和解决过程
- 问题1:如何录制由vb cable传入,python从耳机输出的声音?
- 问题1解决方案:查阅资料,了解到楼月录音软件可以直接录制计算机播放的声音。
- 问题2:网上各种降噪算法存在降噪效果不好或者时间复杂度过高导致实时播放卡顿。
- 问题2解决方案:深入查阅资料,了解到AI降噪算法,可以先加载预训练模型,后续效果好速度快。
- 问题3:在华为云安装python3.9时,出现报错
You can remove cached packages by executing 'dnf clean packages'.Error: GPG check FAILED - 问题3分析:欧拉的repo默认配置会检查gpg证书。然而在repo文件中配置的镜像源无法找到gpg文件,因此报此错误。
- 问题3解决:加一个
--nogpgcheck参数,跳过gpg检测。
感悟、思考
-
想法总在不经意间产生,用心观察生活总会有点子。
-
通过本次实验,我对python中类和对象、多线程、with结构的便捷语法有了深入学习。类和对象算是复习巩固,之前习惯于写函数,传入传出参数很麻烦,有了对象之后再调用、理解方面都便捷了很多。多线程提高了CPU的利用率,也提升了响应速度,适合这种声音实时处理;除此之外,我也学习了锁、线程优先级队列等知识,加深了我对多线程工作原理的理解。with结构确保资源(比如文件、锁)在使用后被正确释放,自动关闭,体现python的简洁性。
-
同时,我也走了很多弯路,对各种音频降噪算法都做了一些了解,在迂回前进中亦有山花烂漫。谱减法计算简单,实时性较好,但对复杂有噪音有音高音低的音频效果不佳。结合子带谱熵分析与线性预测(LPC)的混合降噪算法非常复杂,是我不断调试东拼西凑出来的,降噪效果不错,但因为算法复杂度太高,实时输出时有大量卡顿。最后想到利用一下AI,使用了Demucs AI降噪技术,才达到了不错的效果。
-
感谢@Fancy提供的灵感。
全课感想
-
Python是一门热门的课程,王老师是一位风趣而严谨的老师。我依稀记得上学期抢python课的时候,我点击“确认”时心跳加快,看着圈圈转动的忐忑不安,Python显示在我课表上时的如释重负。其实以前对Python有一种望而生畏的感觉,虽然会一点基础的语法,但了解到各种复杂的库、爬虫、通信,有一种不知道从哪里入手的感觉。然而王老师的指导让我对网络、爬虫、数据库等方面都有了初步的认识,我逐渐搭建起了Python的学习体系。虽然没有特别深入(也不可能在短期内精通各方面),但我对各方面的学习都有了方向,将来可以按照需求有针对性的学习。这门课实现了让我入门Python的目标。
-
做实验很能锻炼人。写实验报告时,从功能分析到代码解释,我将那些“好像”、”大概“等模糊的想法转化成严谨规范的语言,对抽象的逻辑进行形象的描述。每一次将思维转化成文字就好像对自己进行自我剖析,让我感到心旷神怡。做实验的过程中常遇到问题,很多并非代码问题,并非所以问题都能解决,有时候用另一种办法绕过某个问题不失为一种处理办法。
-
王老师的课堂总是充满欢乐,也能让我收获满满。上课过程中我常常跟着老师一起敲代码,自己实现整个程序,我认为这样的学习方式是高效的。在跟随着写代码实践的过程中,我感受的不仅是Python的灵活便捷,更是“优美胜于丑陋”、“间隔胜于紧凑”的计算机艺术。代码不仅仅是实现功能的工具,更是一种表达思想和逻辑的艺术形式。
-
不过,有时上课对同学的抽查占用的时间较多,有点挤占了更具魅力的授课环节。
-
总之,王老师的课程不仅让我掌握了很多Python知识,提升了我的自学能力,还强化了我语言学习的自信心,增加了我敲代码的热情。近乎完美的语言遇上近乎完美的老师,不失为一种天意。
-
最后,感谢王老师带来的精彩讲解,感谢王老师在课下为我多次的答疑解惑!
参考资料
-
Play and Record Sound with Python — python-sounddevice, version 0.5.1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号