

Futoshiki求解
Futoshiki求解
Futoshiki是对于一个n的方阵,需要满足如下条件:
·每一行和每一列的元素都不能重复,即每一行和每一列1到n,n个数字都出现,且只出现一次。
·同一行或同一列中相邻两个元素需要满足预先设定的一些关系,比如大于、小于等等。
例如,有以下样例:

这是一个5的方阵,方阵中元素为0的元素表示该元素为空,即还没有放置1-n中的某个数字。初始方阵中有些元素已经被放置了,这些元素不能被修改。同一行的元素被|字符间隔,同时也有<和>关系符,来规定相邻两个元素的关系。同样,同一列的元素被-字符间隔,同时^和v字符用来规定相邻两个元素间的关系。
对应于上面的初始方阵,有以下一个结果,符合Futoshiki规定:

这是其中之一的结果,对于一个初始方阵来说,可能有很多种结果。在后面的程序中,我们将说明如何求解第一个结果和如何求解所有的结果。
初始方阵存储在文件中,诸如一下格式:

第一行是数值n,表示为n方阵。后面是2*n-1行,记录整个n方阵的数据。
我们要做的是,首先读取数据文件,并将其保存。然后我们需要判断该初始方阵是否是未完成的,所谓未完成就是其中有的元素值为0,即表示该元素位置还没有被放置数字。如果存在为0的元素,那么该方阵是未完成的。如果初始方阵是完成的,那么还分为两种情况,第一种是该方阵是满足其中的约束条件的,比如大于、小于等关系,或者同一行或同一列不存在重复元素,那么该初始方阵不需要进行求解,即便求解也没关系,求解的话得到的也是初始方阵。第二种情况是该方阵不满足约束条件,因为已经是完成的了,不用进行进一步求解,这是一种无效的初始方阵,如果进行求解,那么同样无法得到结果。
如果初始方阵是未完成的,也同样分为两种情况,第一种情况是该方阵是无效的,那么即便求解也是无效的。第二种情况是该方阵是有效的,那么可以对其进行进一步求解,求解的结果还分为两种情况,第一种是得到有效的结果,第二种情况是没有得到有效的结果。
一般情况下,我们处理的情况是,初始方阵是未完成的,有效的,求解后得到有效的结果。
下面给出初始方阵的几种情况处理方式:
初始方阵是完成的
是有效的
是无效的
初始方阵是未完成的
是无效的
是有效的——进行求解
求解后得到有效的结果(这是我们常见的情况)
求解后得到无效的结果
下面,我们根据程序进行逐步讲解。最后我们将附上我们的程序,在程序中有相当可观的注释,可供查阅参考。
1.数据结构的设计
首先是数据结构的设计,用于存储方阵。我们对于方阵中的每个元素设定了以下几个属性:
·自身的值,0表示为空,其范围为1-n
·与左边元素的关系
·与上边元素的关系
·用于检测其所在行是否存在重复元素
·用于检测器所在列是否存在重复元素
另外,为了求解初始方阵对应的所有结果,我们还定义了一个存储所有结果的链表。
2.读取数据,并保存
我们根据给定的文件名,从文件中读取初始方阵。在读取的过程中,检测该方阵是否已经完成还是未完成,该初始方阵是有效的还是无效的。
在读取中,如果碰到一个元素为0,则将其设置为未完成的。如果有元素小于0或者大于n,则将其设置为无效的。如果同一行或同一列中存在重复元素,那么也将其设置为无效的。另外,我们还要检测同一行和同一列中相邻两个元素之间约束关系,如果没有满足特定的约束关系,那么我们要将初始方阵设置为无效的。
3.求解
我们首先给出求解一个结果的过程。整个求解过程相当于是对树的深度优先搜索。树的根节点是初始方阵,树中的每个节点是方阵的某个状态,一直深度搜索下去,如果搜索到叶子节点,并且符合约束条件,那么该叶子节点就是初始方阵的求解结果。
我们这里的求解过程是求解初始方阵对应的第一个结果。整个深度优先搜索是一个递归的过程,这个过程类似于《约束条件下的优化问题》、《图的建立、广度优先遍历和深度优先遍历》和《多叉树的设计、建立、层次优先遍历和深度优先遍历》中有关深度优先搜索问题。
下面,我们讲解一下具体的求解过程。
首先深度递归求解函数的参数step表示递归求解的步数,其记录递归求解结束的条件,即step>=n*n,step的初值为0。
如果当前元素,或者说是树中第step深度的节点状态不为0且满足约束条件,则进行下一步的求解。
如果当前元素为0,则对当前元素进行从1-n的逐个测试,在测试的过程中,还要检测每一行和每一列是否存在重复数,如果不存在重复数,且符合约束条件,则进行递归调用,如果调用成功,则返回1。这里保证了只求解第一个有效结果即终止,对于后面的结果不在求解。如果递归调用后没有得到正确结果,则需要将当前元素还原(退栈),继续检测下一个1-n的数。
4.求解所有的结果
求解所有的结果和求解第一个结果最大的不同在于对当前元素进行递归调用的时候,不管递归调用得到的结果是否有效还是无效,都不返回,而是继续检测下一个1-n的数。这样最终传进来的初始方阵没有得到改变,因为对于状态树的深度优先搜索,最终还是回溯到树的根节点上。
以上是我们对Futoshiki问题的相关求解。
对于递归函数参数和变量的说明
在递归函数中,如果数据需要共用的话,则进行引用传递,需要进栈退栈,不同的递归调用间是相互关联的。
如果数据不需要共用的话,则进行值传递,不需要倒退,值传递是多份拷贝,不同递归调用的状态是相互独立的。
相关程序实现细节请阅读代码和注释。
// Futoshiki #include <stdio.h> #include <stdlib.h> typedef struct { int val; // 值 char leftRel; // 与左边元素的关系 char upRel; // 与上边元素的关系 char rowFlag; // 用于检测该元素所在的行中是否存在重复数,重复数作为该元素的列坐标 char colFlag; // 用于检测该元素所在的列中是否存在重复数,重复数作为该元素的行坐标 } cell_t; typedef struct result { cell_t** scheme; struct result* next; } Result; // 检测关系 int check_relations(cell_t** scheme, int row, int col) { int val = scheme[row][col].val; char sep = 0; if (col > 0 && scheme[row][col - 1].val != 0) { sep = scheme[row][col].leftRel; // 获取左边的关系符 if (sep == '<' && scheme[row][col - 1].val > val) // 不用检测=的情况,因为每行数据不存在重复数 { return 0; } if (sep == '>' && scheme[row][col - 1].val < val) { return 0; } } if (row > 0 && scheme[row - 1][col].val != 0) { sep = scheme[row][col].upRel; // 获取上面的关系符 if (sep == '^' && scheme[row - 1][col].val > val) { return 0; } if (sep == 'v' && scheme[row - 1][col].val < val) { return 0; } } return 1; } // 读取数据 // complete表示正确方案下是否完成 // valid表示初始方案是否是有效的 cell_t** load_futoshiki(char* name, int* dim, int* complete, int* valid) { cell_t** scheme = NULL; int n = 0, i = 0, j = 0, val = 0; char sep[10]; FILE* fp = NULL; fp = fopen(name, "r"); fscanf(fp, "%d", &n); scheme = (cell_t**)malloc(n * sizeof (cell_t*)); if (scheme == NULL) { fprintf(stderr, "Memory error!\n"); exit(1); return NULL; } for (i = 0; i < n; ++i) { scheme[i] = (cell_t*)malloc(n * sizeof (cell_t)); if (scheme[i] == NULL) { fprintf(stderr, "Memory error!\n"); exit(1); return NULL; } for (j = 0; j < n; ++j) { scheme[i][j].val = 0; scheme[i][j].leftRel = '|'; scheme[i][j].upRel = '-'; scheme[i][j].rowFlag = 0; scheme[i][j].colFlag = 0; } } *dim = n; *complete = 1; *valid = 1; for (i = 0; i < n; ++i) { if (i > 0) { for (j = 0; j < n; ++j) { fscanf(fp, "%s", sep); scheme[i][j].upRel = sep[0]; if (j < n - 1) { fscanf(fp, "%*s"); // 将中间的间隔符-忽略 } } } for (j = 0; j < n; ++j) { if (j > 0) { fscanf(fp, "%s", sep); scheme[i][j].leftRel = sep[0]; } fscanf(fp, "%d", &val); scheme[i][j].val = val; // 三种情况分支 if (val == 0) { *complete = 0; } else if (val < 0 || val > n) { *valid = 0; } else // val在1到n之间 { if (scheme[i][val - 1].rowFlag++) // 用于检测同一行中是否存在重复数,若存在,则该方案失效 { *valid = 0; } if (scheme[val - 1][j].colFlag++) // 用于检测同一列中是否存在重复数,若存在,则该方案失效 { *valid = 0; } if (check_relations(scheme, i, j) == 0) { *valid = 0; } } } } fclose(fp); return scheme; } void print_futoshiki(cell_t** scheme, int n) { int i = 0, j = 0; for (i = 0; i < n; ++i) // { if (i > 0) // 如果不是第一行 { for (j = 0; j < n; ++j) // 打印行上面的间隔符 { printf("%c", scheme[i][j].upRel); if (j < n - 1) { printf(" - "); // 间隔符间的间隔符 } } printf("\n"); } for (j = 0; j < n; ++j) { if (j > 0) { printf(" %c ", scheme[i][j].leftRel); // 打印数值左边的间隔符 } printf("%d", scheme[i][j].val); // 打印具体数值 } printf("\n"); } printf("\n"); } // 求解结果 // 该函数只得到一个结果,并保存到scheme中 // 该结果是所有结果中的第一个结果 int solve_futoshiki(cell_t** scheme, int n, int step) { int i = 0, j = 0, k = 0, rowUsed = 0, colUsed = 0; i = step / n; j = step % n; if (step >= n * n) // 终止 { // 如果step=n*n,此时说明将n*n个元素都已检测完,并且均合法,所以得到可行的方案 // 因为这里只是得到第一个可行的结果,所以对应于for循环的实现 return 1; } // 如果step的步骤小于n*n // 检测当前元素 if (scheme[i][j].val) // 如果当前值不为0 { if (check_relations(scheme, i, j)) // 如果检测成功 { return solve_futoshiki(scheme, n, step + 1); // 递归调用,继续检测下一个元素 } else { // 检测不成功,返回失败 return 0; } } // 如果当前值为0 for (k = 1; k <= n; ++k) { scheme[i][j].val = k; rowUsed = scheme[i][k - 1].rowFlag++; colUsed = scheme[k - 1][j].colFlag++; if (rowUsed == 0 && colUsed == 0 && check_relations(scheme, i, j) == 1) // 如果行和列都不存在重复数,并且关系合法 { // 这里如果检测到第一个成功的则返回 // 如果失败了,则不能返回,倒退,继续检测下一个数 // 如果想得到所有的正确结果,则不需要返回,直接递归调用 // 三种处理方式 if (solve_futoshiki(scheme, n, step + 1)) // 继续检测下一个,如果合法返回1 { // 如果检测下一个元素合法,则直接返回,所以,如果一直合法下去,那么后面的将k退出没有被执行 return 1; } // 上面的solve_futoshiki检测成功,则直接返回1 // 结果是只得到第一个可行的结果 // 后面可行的结果被忽略 // 如果我们想得到所有的可行结果,可以在这里进行修改 // 请看求解函数2:solve_futoshiki_2 // 将其直接返回,如果solve_futoshiki为真,则和上面的等价 // 如果为假,则返回0,导致不再检测下一个k,不应该这样做 // return solve_futoshiki(scheme, n, step + 1); } // 将当前k退出,继续检测下一个k scheme[i][j].val = 0; --scheme[i][k - 1].rowFlag; --scheme[k - 1][j].colFlag; } // 如果将k都检测完,此时k=n+1,还没有找到合适的,说明检测失败,返回0 // 比如前面设置5,后面必须还要有5,但是因为不能重复,所以最终导致k越界,没有找到合法的,这时返回失败 // 不再对后面的节点进行检测 return 0; } cell_t** copyscheme(cell_t** src, int n) { cell_t** ret = NULL; int i = 0, j = 0; ret = (cell_t**)malloc(n * sizeof (cell_t*)); if (ret == NULL) { fprintf(stderr, "Memory error!\n"); exit(1); return NULL; } for (i = 0; i < n; ++i) { ret[i] = (cell_t*)malloc(n * sizeof (cell_t)); if (ret[i] == NULL) { fprintf(stderr, "Memory error!\n"); exit(1); return NULL; } // 在这里执行失败 //for (j = 0; j < n; ++i) //{ // ret[i][j] = src[i][j]; //} } for (i = 0; i < n; ++i) { for (j = 0; j < n; ++j) { ret[i][j] = src[i][j]; } } return ret; } // 释放结果 void destroyresult(cell_t** src, int n) { int i = 0; for (i = 0; i < n; ++i) { free(src[i]); } free(src); } // 求解所有的结果 // results是有头结点的指针 int solve_futoshiki_2(cell_t** scheme, int n, int step, Result* results, int* total) { int i = 0, j = 0, k = 0, rowUsed = 0, colUsed = 0; Result* tmp = NULL; i = step / n; j = step % n; if (step >= n * n) { ++*total; // 将结果记录 tmp = (Result*)malloc(sizeof (Result)); if (tmp == NULL) { fprintf(stderr, "Memory error!\n"); exit(1); return 0; } // 拷贝结果 tmp->next = results->next; tmp->scheme = copyscheme(scheme, n); results->next = tmp; return 1; } if (scheme[i][j].val != 0) { if (check_relations(scheme, i, j)) { return solve_futoshiki_2(scheme, n, step + 1, results, total); } else { return 0; } } for (k = 1; k <= n; ++k) { scheme[i][j].val = k; rowUsed = scheme[i][k - 1].rowFlag++; colUsed = scheme[k - 1][j].colFlag++; if (rowUsed == 0 && colUsed == 0 && check_relations(scheme, i, j) == 1) { // 这里不直接返回solve_futoshiki_2 // 也不根据solve_futoshiki_2的值返回结果 // 而是直接调用solve_futoshiki_2 // 共有三种处理方式 // 即便成功也不返回,失败也不返回,该循环不负责返回 solve_futoshiki_2(scheme, n, step + 1, results, total); // 成功就返回 //if (solve_futoshiki_2(scheme, n, step + 1, results, total)) //{ // return 1; //} // 不管成功与否都返回 //return solve_futoshiki_2(scheme, n, step + 1, results, total); } scheme[i][j].val = 0; // 原来是0,现在也要还原,如果不还原,回溯不到之前的状态 --scheme[i][k - 1].rowFlag; --scheme[k - 1][j].colFlag; } // 如果k>n则检测失败 return 0; } int main(int argc, char* argv[]) { int i = 0, n = 0, valid = 0, valid2 = 0, complete = 0; cell_t** scheme = NULL, **backup = NULL; Result* results = NULL, *res1 = NULL, *res2 = NULL; int total = 0; if (argc != 2) { fprintf(stderr, "Error in passing arguments!\n"); exit(1); } scheme = load_futoshiki(argv[1], &n, &complete, &valid); backup = copyscheme(scheme, n); if (complete) { printf("Complete scheme.\n"); if (valid) { printf("Valid solution.\n"); } else { printf("Invalid solution.\n"); } } else { printf("Incomplete scheme.\n"); if (valid) { valid2 = solve_futoshiki(scheme, n, 0); // 求解完结果后,只得到了一个结果,也就是状态数中的第一个合法的叶子节点 // 后面的合法结果没有继续检测,scheme保存的是第一个合法结果 // 可以对其改进,将所有的结果都得到 } //printf("\n%d\n", valid); if (valid2) { printf("Solution:\n"); print_futoshiki(scheme, n); } else { printf("A solution does not exist.\n"); } } // 将futoshiki消毁释放 for (i = 0; i < n; ++i) { free(scheme[i]); } free(scheme); // ========================================= // 获取所有结果 if (complete) { // 如果是完整的,如果是有效的,则输入1 if (valid) { printf("%d\n", 1); } else // 如果是无效的,则输出0 { printf("%d\n", 0); } } else // 如果不是完整的 { // 这时结果可能是有效的,也可能是无效的,如果无效的,则直接返回0 if (!valid) { printf("%d\n", 0); } else // 如果是有效的,则计算结果个数 { scheme = copyscheme(backup, n); // 对结果分配头结点 results = (Result*)malloc(sizeof (Result)); results->next = NULL; results->scheme = NULL; //print_futoshiki(scheme, n); solve_futoshiki_2(scheme, n, 0, results, &total); // 执行solve_futoshiki_2后,scheme还是初始状态 // 因为最后回溯到了状态树的根节点 //print_futoshiki(scheme, n); // 将结果输出 //res1 = results->next; //while(res1 != NULL) //{ // print_futoshiki(res1->scheme, n); // res1 = res1->next; //} printf("\n%d\n", total); // 消毁释放 destroyresult(scheme, n); destroyresult(backup, n); res1 = results->next; while (res1 != NULL) { res2 = res1->next; destroyresult(res1->scheme, n); res1 =res2; } free(results); } } return EXIT_SUCCESS; }
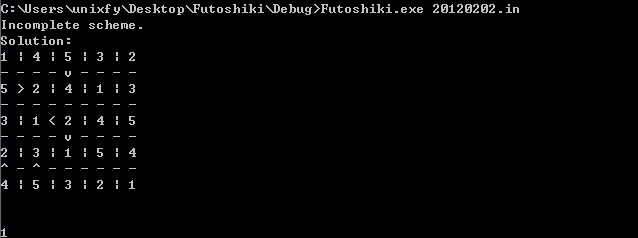
20120202.in

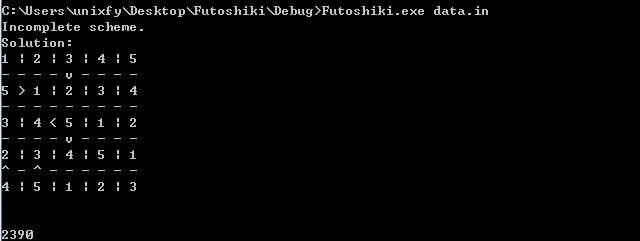
data.in

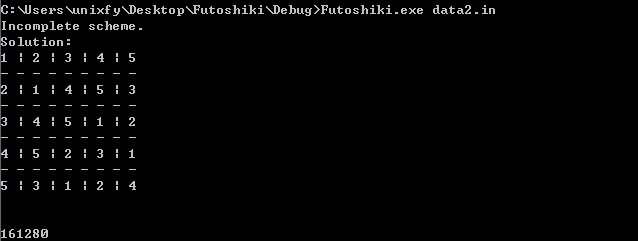
data2.in

(完)
文档信息
·版权声明:自由转载-非商用-非衍生-保持署名 | Creative Commons BY-NC-ND 3.0
·博客地址:http://www.cnblogs.com/unixfy
·博客作者:unixfy
·作者邮箱:goonyangxiaofang(AT)163.com
·如果你觉得本博文的内容对你有价值,欢迎对博主 小额赞助支持


 浙公网安备 33010602011771号
浙公网安备 33010602011771号