结对编程—四则运算in python(梁朗章,林启鹏)
github address:https://github.com/langliang/-arithmetic.git
PSP:
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
30 |
30 |
|
· Estimate |
· 估计这个任务需要多少时间 |
20 |
20 |
|
Development |
开发 |
540 |
600 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
60 |
90 |
|
· Design Spec |
· 生成设计文档 |
30 |
30 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
30 |
30 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
15 |
20 |
|
· Design |
· 具体设计 |
30 |
30 |
|
· Coding |
· 具体编码 |
540 |
600 |
|
· Code Review |
· 代码复审 |
30 |
30 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
60 |
90 |
|
Reporting |
报告 |
120 |
90 |
|
· Test Report |
· 测试报告 |
30 |
30 |
|
· Size Measurement |
· 计算工作量 |
20 |
20 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
20 |
20 |
|
合计 |
|
1575 |
1730 |
三.效能分析:
我在效能分析上大约花费了将近3个小时,主要思路为:python语言中列表的传递都是引用传递,在函数中改变列表,势必会对原列表也造成不可逆转的改变,所以如何合理规划函数调用的顺序很关键。过多使用切片,会造成空间时间效率低,不使用切片就要选择其他方法保护原列表,我在get_answer函数中对操作数列表有delete操作,最后operands列表只剩最终计算结果,所以选择先将问题写入exercise文件,再get answer,就避免了切片的开销。在对operator优先级的排序中,本来使用较为简单的lamda函数,但是为了提高效率,改用numpy库中的numpy.lexsort同时对两个列表进行排序,加快了速率。
使用ipython shell进行效能分析:
生成一万道题和答案,生成十次,平均1.57秒一次:

生成100万道题和答案:

以上的测试只是对整个程序的性能测试。由于是在虚拟机中测试,速度会比较慢,所以对每行代码分析所占时间比才最为重要
通过cprofiler对show_questions_and_answers函数每个调用进行效能分析,由于该函数通过调用其他函数,实现了所以的问题答案生成和写入功能,因此对该函数每个调用进行分析就能知道性能瓶颈
here we go:
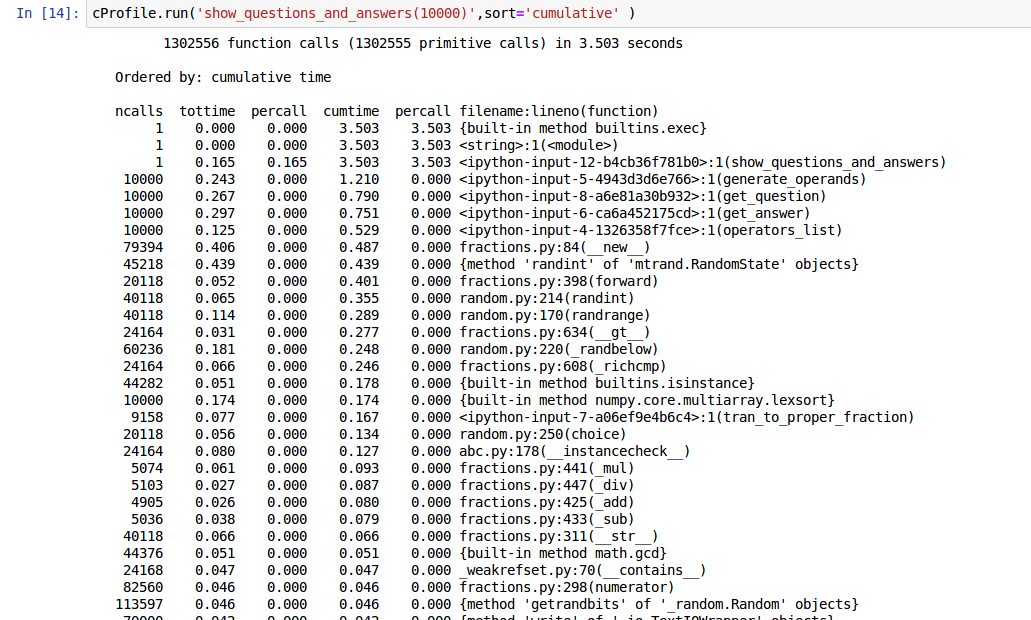
通过分析,在写入问题时将问题操作数转化为string花费较多时间,还有random.randint方法,前者可通过较少不必要的str()操作,后者可用numpy里面的方法代替或者减少不必要操作。
好像看的还不是很清楚,使用可视化组件gprof2dot和graphviz来更清楚的分析:
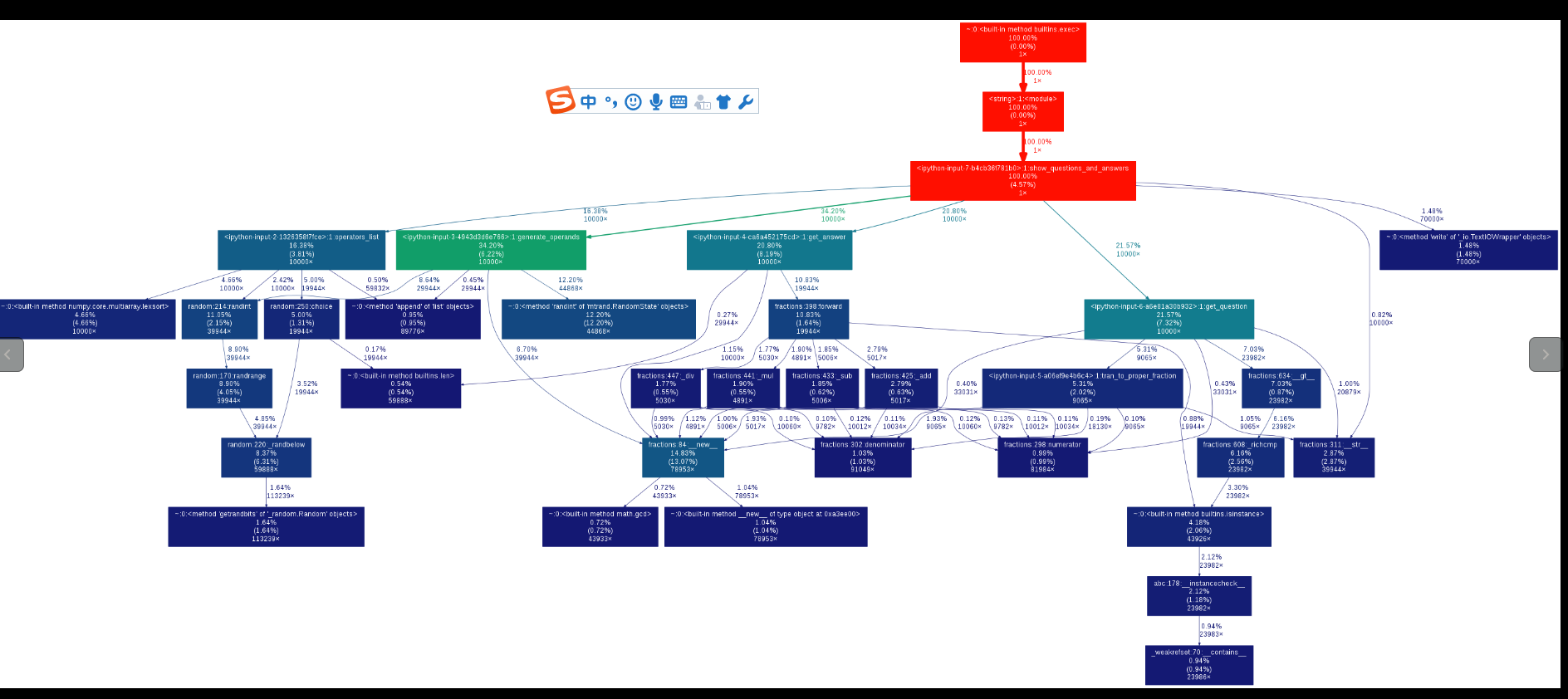
从图像可知,生成操作数的方法居然占到了34%,而我原本以为较占用时间的生成答案的方法只占到20%,令我非常意外,而34%里面竟然有将近24%是random.randint方法占据的,可见此方法的效率之低,将原本整数或小数的标记符的random.randint改为random.choice
然后:
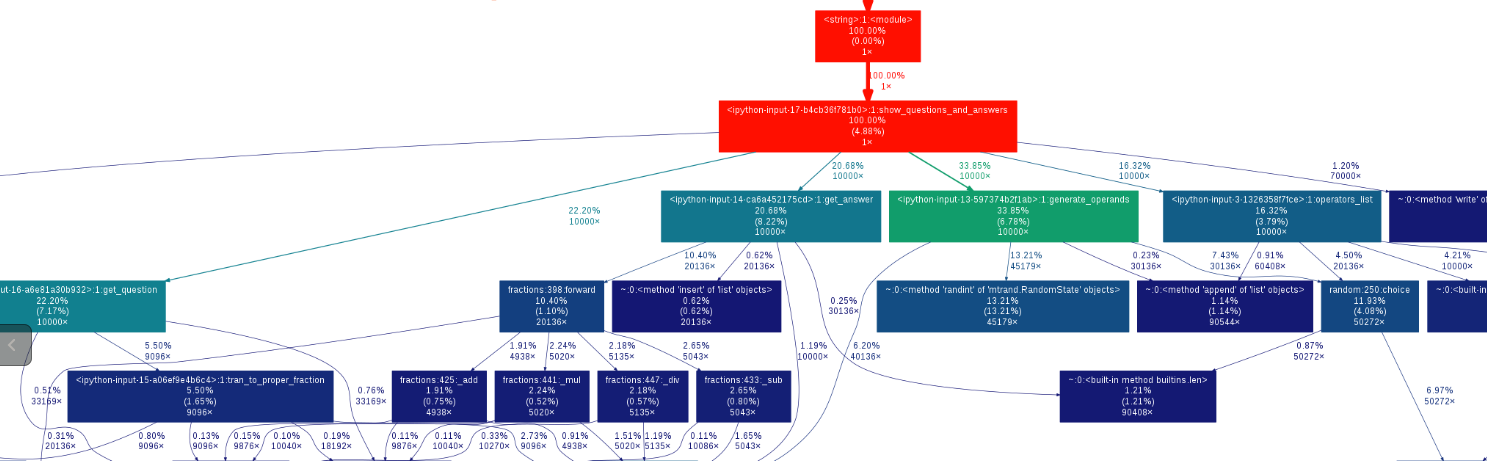
生成操作数的方法占比减少1%,虽然不多,还是有用的XDD。
接下来还可以对get——question方法减少str()操作来提高效率,在一顿操作后,10000道题的时间减少为1.43秒!
四.设计实现过程:
顺序:
def operators_list():随机生成1-3个操作符
def generate_operands(num):根据生成操作符的个数随机生成n+1个操作数
def get_answer(op_list, operands, index_list, priority):根据生成的操作符和操作数,和操作符的优先级(先按操作符优先级,再按索引号),计算结果
def get_question(op, operands):根据操作符和操作数,生成问题的字符串,以写入到文件
def tran_to_proper_fraction(a, fract):将大于一的分数转化为真分数
def show_questions_and_answers(number):通过重复调用 get_answer和get_question方法,得到n个问题和答案,并写入到相应文件中
def check_answers(exefile, ansfile):检查答案是否正确
五.代码说明:
# 生成操作符,并先根据操作符本身的优先级排序,然后再根据索引号排序,返回优先级索引列表和操作符个数,操作符列表,操作符原索引列表(用来确定操作符对应的操作数)
1 # In[13]: 2 # A method generating a operators list 3 4 def operators_list(): 5 # operators number should range from 1 to 3 6 num_op = random.randint(1, 3) 7 # a list stored random operators 8 arithmetic_operators_list = [] 9 index_list = [] 10 priority_list = [] 11 for i in range(num_op): 12 op = random.choice(['+', '-', '*', '/']) 13 if op == '*' or op == '/': 14 priority_list.append(0) 15 else: 16 priority_list.append(2) 17 index_list.append(i) 18 arithmetic_operators_list.append(op) 19 priority = numpy.lexsort((index_list, priority_list)) # sorted by priorities and then indexes 20 return num_op, arithmetic_operators_list, index_list, priority
生成答案:
# 根据优先级索引列表,确定先处理的操作符,根据操作符原索引列表,确定其对应的操作数,例如索引号为【2】的操作符,对应的操作数索引号为【2】和【3】,
其后删除使用过的操作数,并把刚刚得到的中间结果插入操作数列表中,例如【2】【3】的操作数,插入到【2】中,迭代n次处理完所有操作符后,操作数列表就只剩下最终结果,返回即可
1 def get_answer(op_list, operands, index_list, priority): 2 outcome = Fraction(0) 3 for i in range(len(op_list)): 4 index = index_list[priority[i]] # currently processing operator according to priority 5 if op_list[priority[i]] == '+': 6 outcome = operands[index] + operands[index+1] 7 elif op_list[priority[i]] == '-': 8 outcome = operands[index] - operands[index+1] 9 elif op_list[priority[i]] == '*': 10 outcome = operands[index] * operands[index+1] 11 else: 12 outcome = operands[index] / operands[index+1] 13 del operands[index] # delete the used operands 14 del operands[index] 15 for j in range(len(index_list)): # index minus 1 16 if index_list[j] > index: 17 index_list[j] -= 1 18 operands.insert(index, outcome) # intermediate result stored to the list as an operand 19 return operands[0]
转化成真分数:
# 在将问题写入到文件时,要将形如3/2这样的分数转换为1'1/2这样的形式,为了不影响后续的计算,操作数使用切片深度复制。
1 def tran_to_proper_fraction(a, fract): 2 b = fract.numerator // fract.denominator 3 k = str(b) + "'" + str(Fraction(a, fract.denominator)) + ' ' 4 return k
将问题和答案写入到文件中:
# 循环生成n个问题和答案,并写入到文件中
1 ef show_questions_and_answers(number): 2 ef = open('Exercises', 'w') 3 af = open('Answers', 'w') 4 for i in range(number): 5 number_op, operators, a, b = operators_list() 6 operands_list = generate_operands(number_op) 7 question = get_question(operators, operands_list) 8 # write the question to exefile 9 ef.write('%d. ' % i) 10 ef.write(question) 11 ef.write(' =? ') 12 ef.write('\n') 13 # write the answer to ansfile 14 answer = get_answer(operators, operands_list, a, b) 15 af.write('%d. ' % i) 16 af.write('%s' % str(answer)) 17 af.write('\n') 18 # close files 19 ef.close() 20 af.close()
检查答案:
1 def check_answers(exefile, ansfile): 2 ef = open(exefile) 3 af = open(ansfile) 4 e_lines = ef.readlines() 5 a_lines = af.readlines() 6 right_num = [] 7 wrong_num = [] 8 for i in range(len(e_lines)): 9 # get your answers 10 your_answer = e_lines[i].split('?')[-1].strip() 11 # get right answer 12 right_answer = a_lines[i].split('.')[-1].strip() 13 if Fraction(your_answer) == Fraction(right_answer): 14 # marking right answers number 15 right_num.append(i) 16 else: 17 # marking wrong answers number 18 wrong_num.append(i) 19 right_num = tuple(right_num) 20 wrong_num = tuple(wrong_num) 21 ef.close() 22 af.close() 23 24 # to write down your grade 25 26 with open('grade.txt', 'w') as grade: 27 grade.write("correct: %d " % len(right_num)) 28 grade.write(str(right_num)) 29 grade.write('\n') 30 grade.write('wrong: %d' % len(wrong_num)) 31 grade.write(str(wrong_num)) 32 grade.write('\n')
检查是生成问题还是检查答案:
# 设置标记符,False则生成问题和答案,若检查答案,则吧标记符改为True
1 c_or_a = False 2 3 4 # In[18]: 5 6 7 if options.exercises != '' and options.answers != '': 8 c_or_a = True 9 check_answers(options.exercises, options.answers) 10 11 12 if not c_or_a: 13 if options.range <= 1: 14 try: 15 sys.exit(0) 16 except SystemExit: 17 sys.stderr.write('You must give a proper range value! Please try again!\n') 18 else: 19 show_questions_and_answers(options.number)
六.测试运行:
由于题目要求生成r内,但不包括r的自然数或分数,而分母也要小于r,对于1,分母为整数的情况下,分母小于1,整个分数又小于1的分数不存在,所以r=1会被当成异常来处理
n的默认值被设计为1
异常处理:
不输入r:

输入不合适的r:

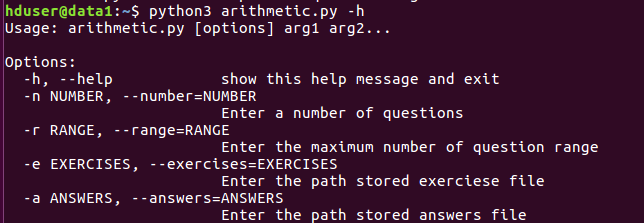
usage:
其他测试:
生成r=10,n=100
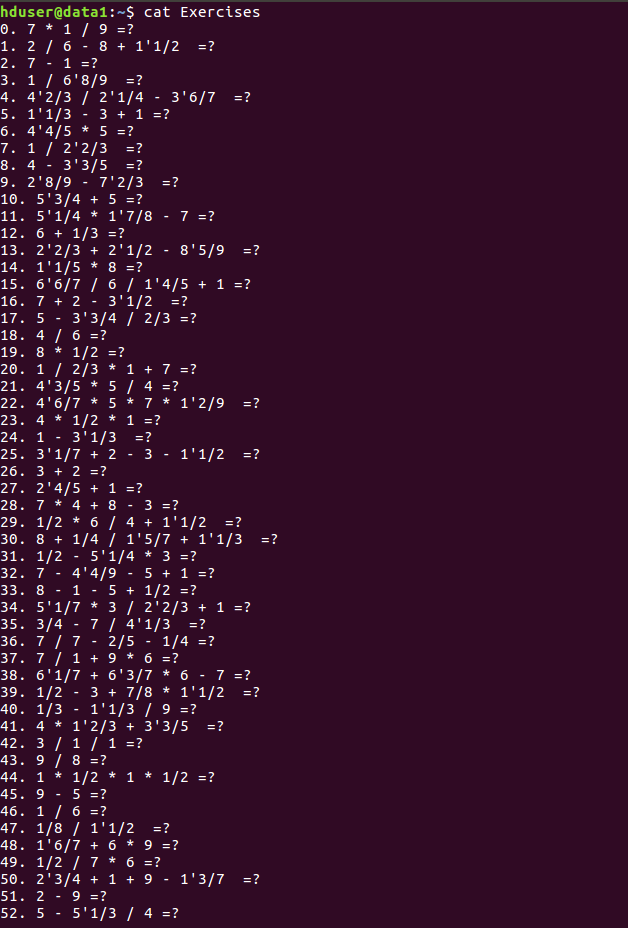
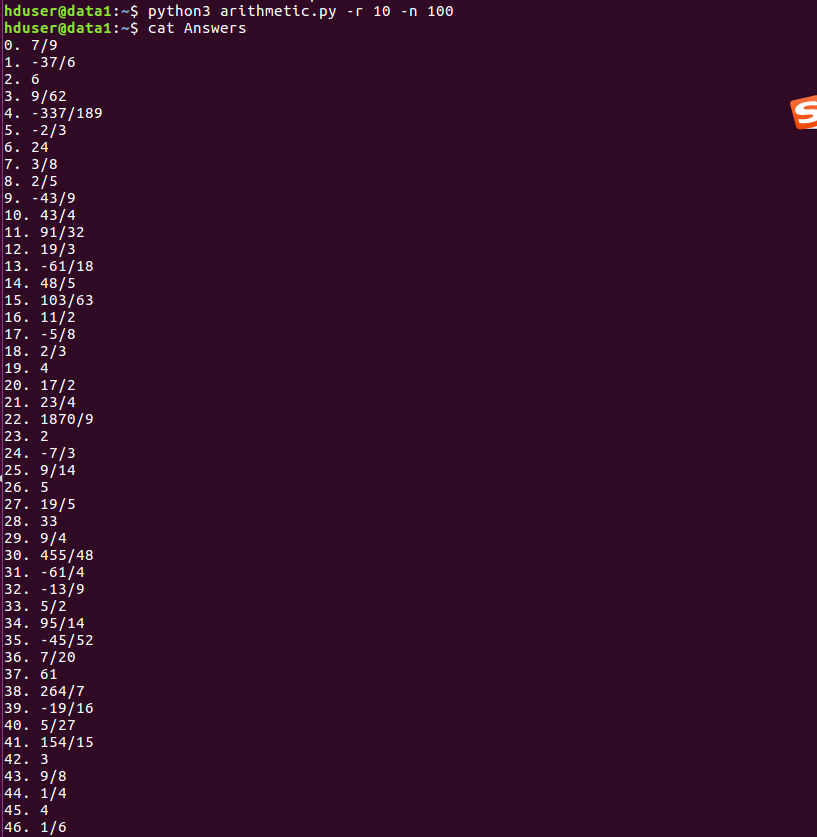
检查答案:
问题:
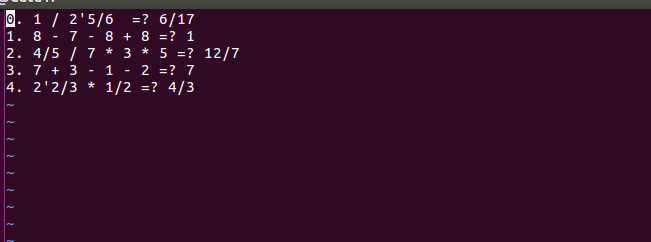
答案:

成绩:

生成一万道r=6的题目:

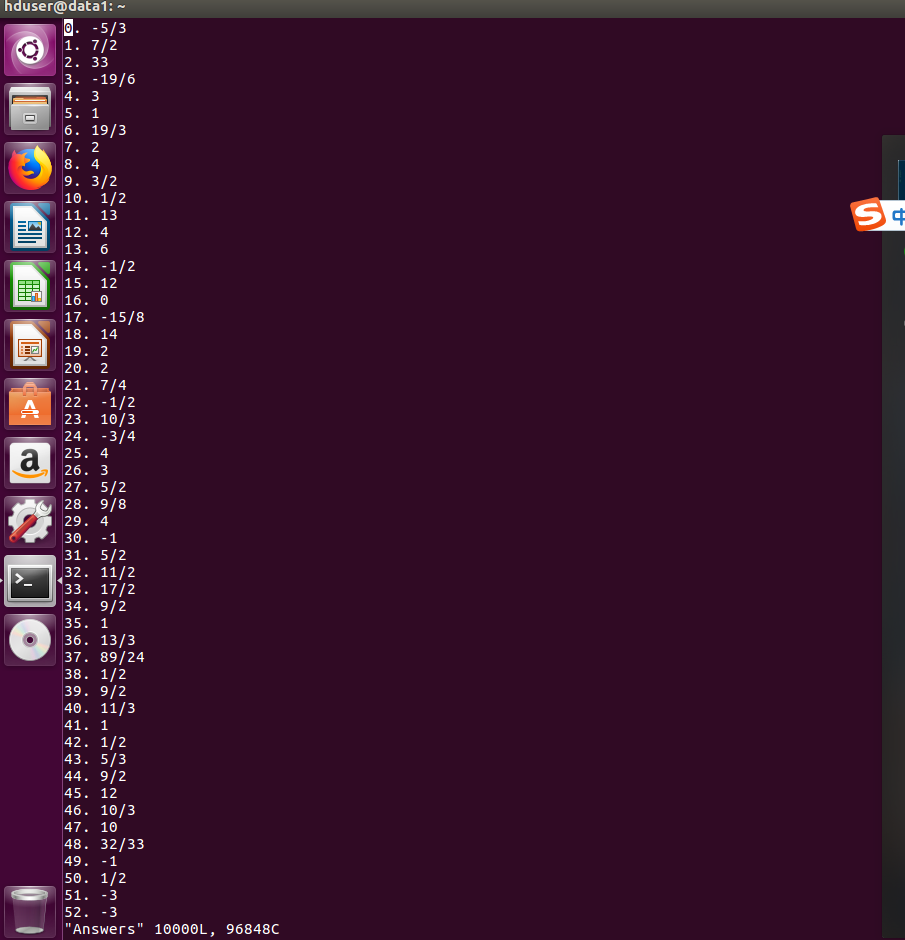
无论是 1000道还是1道,r的任何合理取值,都能生成正确答案,都能正确得出成绩,证明程序逻辑正确
七.项目小结
结对中两人的合作非常重要,特别是如何分工,一人负责算法和程序逻辑,另外一个负责实现的数据结构,可以大大提高效率,例如是用元祖列表存储还是矩阵,用eval计算结果还是用迭代.另外对程序设计语言的理解也非常重要,python语言中for item in list的循环,对item的修改不会修改到原list中的对应项,这个问题困扰了我一个多小时.另外网上的资源也十分有帮助,通过上网搜索,我获得了很多跟矩阵和numpy中二维数组的操作方法,还有用with open方法处理文件可以更方便.对于结对编程的伙伴,启鹏对整个流程的构造比较好,而我则善于实现,通过这次结对项目,收获良多.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号