GitHub 今日 +2299 Star,这个工具让 AI 读代码不再像翻字典

上个月我在一个 6 万行的 TypeScript 项目里让 Claude Code 帮我找「所有和支付相关的错误处理逻辑」。它扫了一圈,给我返回了几个 catch 块,但漏掉了三处关键的错误码转换层——那些函数名叫 mapApiResponse,压根没有 payment 这个词。
这不是 Claude Code 的问题,是这类问题本身的结构决定了向量搜索会在这里栽跟头。
两周前,一个叫 Understand-Anything 的项目在 GitHub 单日涨了 2,299 个 Star,总 Star 数达到 22,600,登上 TypeScript Trending 榜首。它的核心主张只有一句话:图谱会教你代码,而不只是展示代码。
这篇文章想搞清楚的不是「怎么用这个工具」,而是背后一个更本质的问题:为什么代码理解需要知识图谱,embedding 到底在哪里失效了?
向量搜索在代码里的静默失败
大多数工程师第一次给 AI 工具接入自己代码库,都会选向量 RAG——把代码文件切块、embedding、存进向量库,查询时用语义相似度检索。逻辑上说得通,实际上到处是坑。
第一个问题:语义相似不等于结构相关。
processPayment() 函数调用了 validateCard(),这是一个确定的结构关系。但在 embedding 空间里,这两个函数不一定挨着——它们的文本描述可能差得很远。你问「支付流程里的校验逻辑是什么」,向量搜索返回的是语义上和「校验」相近的所有代码块,而不是和 processPayment 调用链直接相关的那些。
第二个问题:切块破坏上下文。
代码不是文章,不能随意切块。一个函数必须带着它的签名、类型声明、调用的依赖一起理解。把 200 行的 Go 文件切成 50 行一块,一个函数可能横跨两个 chunk,LLM 拿到半截代码只能硬猜另一半在干什么。
第三个问题:跨文件依赖是盲区。
A 文件的接口定义在 B 文件实现,C 文件调用了 A 的接口但只 import 了接口类型——这条依赖链,向量相似度根本追不到。结果就是:AI 给你回答「这个接口怎么用」,但它不知道真正的实现在哪。
最近有篇 arxiv 论文(Chinthareddy, 2026)专门对比了三种代码检索方案:纯向量 RAG、LLM 生成的知识图谱、以及 AST 确定性图谱。结论很直接:纯向量 RAG 在架构级查询上的幻觉率最高,而 AST 确定性图谱在多跳依赖查询上的准确性最好,且构建成本远低于 LLM 生成的图谱。
实测数据是:LLM 生成方案在 Shopizer 项目上漏掉了 377 个文件的索引,而 AST 确定性方案覆盖率几乎是 100%。

图:向量 RAG 把代码当文本,图谱把代码当结构——两种范式下 AI 理解代码库的本质差异
Understand-Anything 在做什么
Understand-Anything 的技术思路不复杂,但工程细节讲究。
它的核心是一个 7 Agent 串行流水线,每个 Agent 负责一层理解:
project-scanner → file-analyzer → architecture-analyzer →
tour-builder → graph-reviewer → domain-analyzer → article-analyzer
第一层(project-scanner):发现文件树,识别语言和框架。这一步决定后续 Agent 用什么解析策略。
第二层(file-analyzer):这是最关键的一层。用 Tree-sitter 对每个文件做确定性 AST 解析——提取函数、类、import、export、调用关系,生成图的节点和边。注意:这一步是确定性的,同样的代码解析结果永远一样,没有 LLM 幻觉。
第三层(architecture-analyzer):识别架构层次——API 层、Service 层、Data 层、UI 层、Utility 层。这是从结构信息里推导出语义分类,不是靠文件名猜。
第四层(tour-builder):生成依赖顺序的学习路径。新人第一天开始读代码库,应该从哪里读起——这个问题有了图谱之后就有确定性答案了。
第五层(graph-reviewer):验证图谱完整性,确保没有孤立节点和断裂边。
第六/七层:domain-analyzer 抽取业务工作流(代码结构 → 业务语义),article-analyzer 处理 wiki 知识库文档。
最终输出是 .understand-anything/knowledge-graph.json——一个普通的 JSON 文件,包含所有节点和边。Dashboard 独立运行,不依赖 LLM,查询图谱不消耗任何 token。
v2.7.3(2026 年 5 月 19 日发布)把节点类型从 13 种扩展到了 21 种,边类型增加到 35 种,覆盖结构关系、行为关系、数据流、语义关系等六个维度。
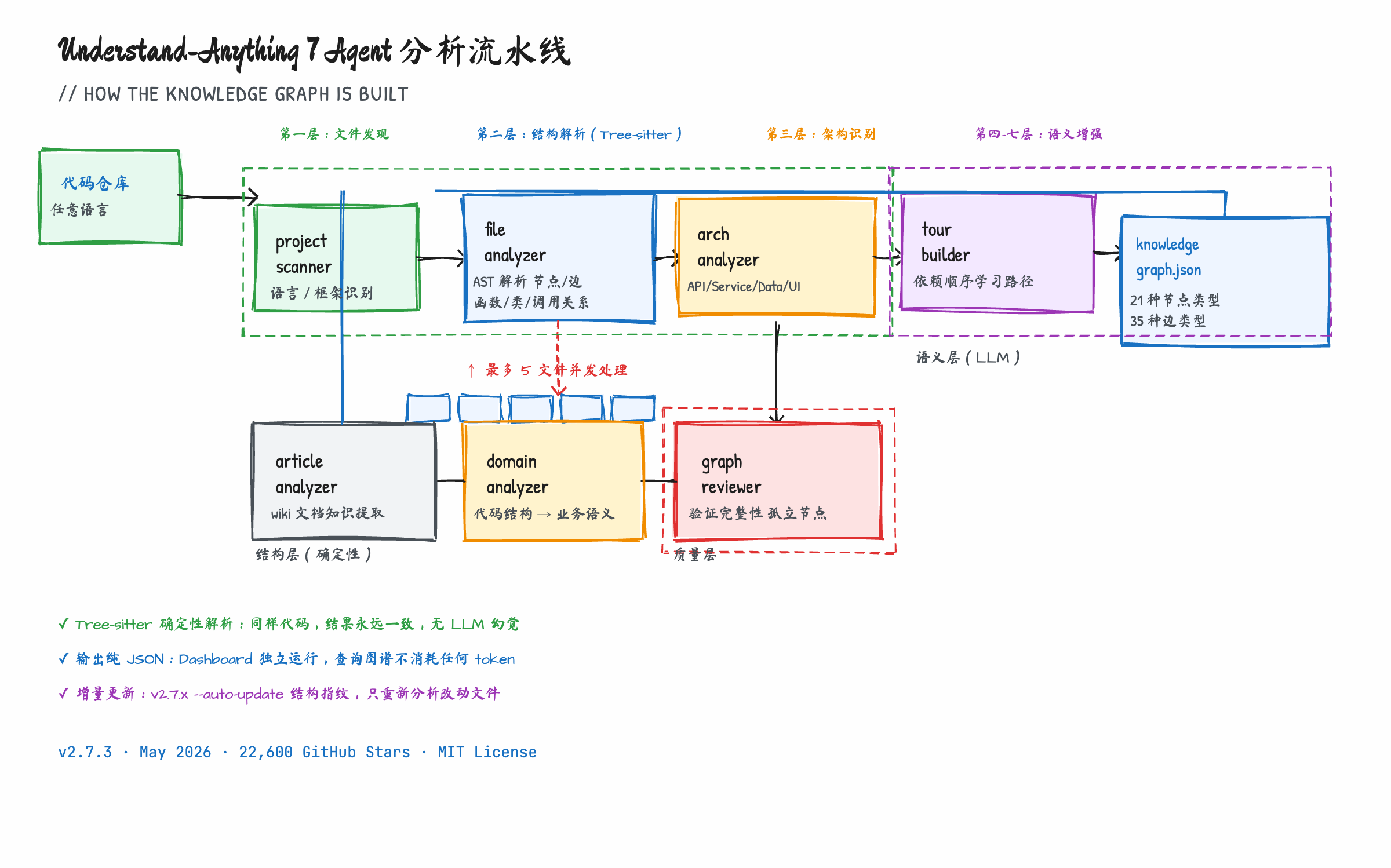
图:7 Agent 串行流水线——前三层做结构解析,中间两层做质量保障,后两层做语义提升
图谱 vs 向量:工程本质差异在哪里
我见过两种典型场景,让这个差异特别清楚。
场景一:「改这个函数,会影响哪些地方?」
用向量搜索:找到和这个函数名相似的代码段,大致猜出可能的调用者。准确率取决于命名一致性,leaky abstraction 一多就废了。
用图谱:impact_radius(function_id) 一次图遍历,返回所有直接和间接调用者,确定性的,没有漏网之鱼。CodeGraph 在 VS Code 代码库上的测试数据是:回答「Extension Host 和主进程的通信机制」,向量方案需要 52 次工具调用,图谱方案需要 3 次。
场景二:「这个模块的业务含义是什么?」
代码里有个叫 UserSessionManager 的类,向量搜索能找到它,但不知道它在整体架构里的位置。图谱知道:它属于 Service 层,被 API 层的 5 个 handler 调用,依赖 Data 层的 2 个 repository,是整个鉴权流程的核心节点。
这里有个架构决策值得说一下:Understand-Anything 选择把确定性解析(Tree-sitter)和语义理解(LLM)分两层做,而不是全部用 LLM 做。原因是分层之后,结构层的结果可以缓存、可以增量更新——只有改动的文件需要重新解析。v2.7.x 的 --auto-update 就是基于这个:结构指纹变了才重新跑对应文件,没变的直接复用。
相比之下,纯 LLM 知识图谱方案每次都是全量重建,而且 LLM 每次抽取的结果还可能不一致。
一个容易被忽略的工程细节:graph reviewer 那一步不是装饰。我们内部维护过一个运行了三年的 Java 服务,代码里充斥着命名混乱的 util 类和没有文档的内部接口。纯向量索引这类代码库,结果就是一堆不相关的 chunk 被聚合在一起。图谱方案会暴露这种混乱——孤立节点多、调用链断裂多,某种程度上也是代码质量的显示器。
和 CodeGraph 的定位差异
GitHub 上另一个做类似事情的工具是 CodeGraph(20,300 Star),值得放在一起说。
两者都用 Tree-sitter 做 AST 解析,但产品定位完全不同:
Understand-Anything 的目标是「人和代码的交互」——可视化仪表盘、guided tour、业务域映射,图谱提交到 repo 之后团队共享,新人第一天就能用。核心用户是需要理解陌生代码库的人。
CodeGraph 的目标是「AI Agent 和代码的交互」——作为 MCP Server 给 Claude Code、Cursor 这些工具提供精确的结构查询,减少 Agent 的工具调用次数和 token 消耗。核心用户是想降低 AI 编程成本的人。实测数据:在大型仓库上平均节省 59% token、70% 工具调用次数。
这两个工具不是竞争关系,而是在同一个问题的不同截面上各自深挖。Understand-Anything 生成的图谱可以通过它的 API 给 AI Agent 用,CodeGraph 生成的图同样能给人看。
如果你的诉求是「我要看懂这个老项目的架构」,Understand-Anything 更合适。如果你的诉求是「我要降低 AI 编程的 token 成本」,CodeGraph 更直接。
| 维度 | Understand-Anything | CodeGraph |
|---|---|---|
| 核心产品形态 | 可视化 Dashboard + JSON 图谱 | MCP Server |
| 主要用户 | 需要理解代码库的工程师 | 使用 AI 编程工具的工程师 |
| 图谱节点类型 | 21 种(含业务域、文档) | 函数/类/模块/调用关系 |
| 增量更新 | ✅ --auto-update 结构指纹 |
✅ OS 文件事件监听 |
| AI Agent 集成 | 支持,非核心 | 核心,MCP 原生 |
| token 节省 | 未公布 | 59% 平均 |
| 团队协作 | ✅ 图谱提交到 repo 共享 | 本地运行 |
| GitHub Stars | 22,600 | 20,300 |
图谱有哪些真实局限
不吹不黑,说几个实际会遇到的问题。
动态语言是噩梦。 Python 的 duck typing、JavaScript 的 prototype chain——静态 AST 解析追不到运行时的动态绑定。你的 processOrder 函数在代码里调用了 this.handler.process(),AST 只能知道调用了 .process(),不知道运行时 this.handler 到底是哪个类的实例。这个问题在强类型语言(TypeScript、Java、Go)里小很多,在 Python 动态代码里很严重。
命名混乱会传导进图谱。 如果代码库里有大量命名不一致的 util 函数(handleData、processData、dealWithData)做着同样的事,图谱只能忠实反映这种混乱,不会帮你整理。Understand-Anything 自己的文档也承认:「如果代码库命名一片混乱,生成的图谱也会是一片混乱。」
大型代码库的初始构建时间。 20 万行代码的 monorepo,哪怕并发处理 5 个文件,首次构建也要几分钟。增量更新之后这个问题基本消失,但首次接入的等待是真实的。
LLM 调用费用由你承担。 构建图谱时的语义摘要、架构分类这些步骤需要 LLM。图谱构建完之后的查询和浏览不再消耗 token,但初始构建是有成本的。
动手接入:从安装到第一次查询(5 分钟)
本文环境: macOS/Linux · Claude Code v1.x · 前置条件:项目目录里有代码,已配置 LLM API Key
第一步:安装插件
Claude Code 原生安装(推荐):
/plugin marketplace add Lum1104/Understand-Anything
/plugin install understand-anything
macOS / Linux 通用安装:
curl -fsSL https://raw.githubusercontent.com/Lum1104/Understand-Anything/main/install.sh | bash
Windows PowerShell:
iwr -useb https://raw.githubusercontent.com/Lum1104/Understand-Anything/main/install.ps1 | iex
Cursor 和 VS Code + Copilot 会在克隆含 .understand-anything/ 目录的仓库后自动发现,无需额外安装。
第二步:首次构建知识图谱
进入项目根目录,在 Claude Code 里执行:
/understand
这一条命令触发完整的 7 Agent 流水线:project-scanner 扫文件树 → file-analyzer 用 Tree-sitter 做 AST 解析 → architecture-analyzer 识别层次 → tour-builder 生成学习路径 → graph-reviewer 验证完整性 → domain-analyzer 提取业务语义。
耗时参考(根据代码库大小):
- 1 万行以内:~1 分钟
- 5 万行:~3–5 分钟
- 20 万行 monorepo:~10–15 分钟
图谱完成后,会在项目根目录生成 .understand-anything/knowledge-graph.json。首次看到这个文件时,可以快速验证节点数量是否合理:
# 验证图谱节点数
cat .understand-anything/knowledge-graph.json | python3 -c "
import json, sys
g = json.load(sys.stdin)
print(f'节点数:{len(g[\"nodes\"])},边数:{len(g[\"edges\"])}')
"
一个 2 万行的 TypeScript 项目,正常范围是节点 800–2,000、边 1,500–4,000。如果节点数接近 0,说明文件树扫描失败,检查是否在项目根目录执行了命令。
第三步:用图谱回答真实工程问题
图谱构建完之后,以下这些命令是我用得最多的:
打开可视化仪表盘:
/understand-dashboard
浏览器会打开一个交互式图谱,可以点击任意节点看它的调用关系、所在架构层、依赖文件。
直接问代码库问题:
/understand-chat
示例对话:
- 「UserSessionManager 类被哪些地方调用了?」→ 返回完整调用链,带文件路径和行号
- 「支付模块和订单模块之间的接口是什么?」→ 返回跨模块的接口定义,不依赖文件名猜测
评估改动影响范围(高频使用):
/understand-diff
在改完某个函数之后,执行这个命令,它会列出所有直接和间接受影响的调用链。改核心接口之前先跑一遍,能规避不少「改了 A 没想到 B 坏了」的情况。
深入特定文件或函数:
/understand-explain src/payment/processor.ts
配置选项
中文输出(适合国内团队):
/understand --language zh
自动增量更新(接入 CI/CD):
/understand --auto-update
开启后,会在 .git/hooks/post-commit 里写入一个钩子。每次 commit 后自动检测哪些文件的结构指纹变了,只重新分析改动文件,不重建整个图谱。对日常 feature 开发基本感知不到额外耗时。
排除敏感目录:
创建 .understandignore 文件(语法与 .gitignore 相同):
# 不分析测试夹具数据
fixtures/
# 不分析内部实现细节
src/internal/legacy/
把图谱提交到 Git 共享:
git add .understand-anything/knowledge-graph.json
git commit -m "chore: add code knowledge graph"
提交后,团队里所有人 git pull 就能直接用图谱,不需要每人重新构建一遍。新人第一天就能用 /understand-chat 问代码库的问题。
常见报错
问题:/understand 执行后节点数为 0
原因:通常是 LLM API Key 没有配置,或者 Tree-sitter 对某些语言版本不兼容。
解决:检查环境变量里的 ANTHROPIC_API_KEY 或 OPENAI_API_KEY;对不支持的语言文件,加入 .understandignore 先跳过。
问题:大型 monorepo 构建超时
原因:默认没有子目录限制,全量扫描。
解决:用路径参数限制范围:
/understand src/payment
先构建最关键的模块,再按需扩展。
问题:--auto-update 没有触发
原因:post-commit 钩子需要执行权限。
解决:
chmod +x .git/hooks/post-commit
常见问题
Q:已经在用 Cursor 或 Claude Code 的 @Codebase 功能了,还有必要接这个吗?
有区别。@Codebase 的底层是向量搜索,适合「这段代码在哪里」这类语义查询。知识图谱擅长「谁调用了这个函数」「改这里会影响什么」这类结构查询。两者互补,不冲突。实际上 CodeGraph 的实测数据显示,有图谱辅助时 Agent 的工具调用次数降低 70%——说明 Agent 自己也在频繁做这类结构查询,只是靠 grep 来做效率很低。
Q:Tree-sitter 支持我们用的语言吗?
TypeScript、JavaScript、Python、Go、Rust、Java、C#、PHP、Ruby、Kotlin、Swift、Dart 都支持,共 19+ 种语言。Vue 和 Svelte 也在支持列表里。
Q:代码库里有业务逻辑不想被 AI 看到,怎么处理?
Understand-Anything 支持 .understandignore 文件(类似 .gitignore 语法),指定不参与分析的目录和文件。整个构建流程可以完全本地运行,不向任何第三方上传代码——LLM 调用走你自己配置的 API Key,可以是本地模型。
Q:和 sourcegraph / Glean 这类企业级代码搜索工具比,有什么区别?
Sourcegraph 和 Glean 是企业级工具,解决的是「在几百个 repo 里找代码」的问题,需要部署索引服务器。Understand-Anything 是项目级工具,解决的是「深度理解一个代码库」的问题,开箱即用,零运维。两个不同量级的需求。
Q:知识图谱会随代码更新变陈旧吗?
v2.7.x 引入了 --auto-update,基于结构指纹检测文件变化,只重新分析改动的文件。接入 CI/CD 触发自动更新,图谱和代码库的同步基本可以做到自动化。
代码理解比代码生成难,因为结构不是文本
写到这里,我想说一个稍微大一点的判断。
过去两年我们讨论 AI 编程,几乎所有精力都放在「代码生成」上——Copilot、Claude Code、Cursor,本质都是在做续写。但当代码库超过 5 万行、超过 10 个人维护之后,瓶颈不是生成,而是理解。
向量 embedding 解决的是文本检索问题,代码库的核心问题是结构检索问题。函数调用图、依赖链、架构层次——这些不是文本相似度能描述的,需要图结构来表达。
Understand-Anything 目前单日 +2,299 Star 的热度,我觉得是市场在反应这个认知转变:工程师们开始意识到,给 AI 一个「代码库地图」,比给它一堆 embedding 向量更有用。
这工具本身还不完美——动态语言的支持仍是软肋,大型 monorepo 的首次构建时间有待优化,和主流 IDE 的深度集成也还差一些。但它的技术路线是对的。
把 CodeGraph 加进来那条链路我们内部跑了一个月,token 成本确实掉了不少,写 RAG 的同事有兴趣可以直接试。下一篇打算拆 Graph RAG 的实现细节,从 Neo4j + Tree-sitter 到 MCP 接口的完整链路——那个比今天的内容更硬核,感兴趣的关注一下,不然算法不一定会推给你。如果你身边有人正在给 AI 工具接代码库,这篇可以直接甩给他,省他走弯路。

参考资料
- Understand-Anything GitHub 仓库(MIT License,v2.7.3)
- CodeGraph GitHub 仓库(MIT License)
- Reliable Graph-RAG for Codebases: AST-Derived Graphs vs LLM-Extracted Knowledge Graphs(Chinthareddy, 2026)
- Why Cursor, Claude Code, and Devin Use grep, Not Vectors(MindStudio)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号