pytest简易教程(16):parametrize参数化数据来自excle文件
pytest简易教程汇总,详见:https://www.cnblogs.com/uncleyong/p/17982846
测试数据
case.xlsx
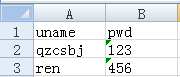
设置为文本格式:'123
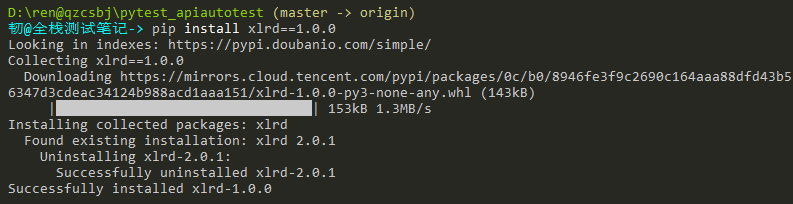
模块安装(读excel)
pip install xlrd==1.0.0
parametrize从excel获取数据
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : 韧
# @wx :ren168632201
# @Blog :https://www.cnblogs.com/uncleyong/
import xlrd
import pytest
import os
# 获取项目路径
BASE_PATH = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
def read_data_from_excel(file_path, sheet_name="Sheet1"):
# 打开文件
workbook = xlrd.open_workbook(file_path)
# 获取所有sheet
# sheets = workbook.sheet_names()
# print(sheets) # ['Sheet1', 'Sheet2', 'Sheet3']
# 根据sheet名称获取sheet内容(也可以格局索引,从0开始)
sheet = workbook.sheet_by_name(sheet_name)
# 获取第一行作为key
first_row = sheet.row_values(0)
# 获取行数
rows_length = sheet.nrows
all_rows = []
rows_dict = []
# 获取excel行数据
for i in range(rows_length):
if i<1:
continue
all_rows.append(sheet.row_values(i))
# 遍历行数据列表,生成字典
for row in all_rows:
# print('=========',type(row)) # row是list类型
# zip()函数用于将可迭代的对象作为参数,将对象中对应的元素(索引相同的元素)打包成一个个元组,然后返回由这些元组组成的列表
# 然后通过dict转换为字典
lis = dict(zip(first_row, row))
# 每行字典数据放到列表
rows_dict.append(lis)
return rows_dict
@pytest.mark.parametrize("param", read_data_from_excel(BASE_PATH + "/data/case.xlsx"))
def test_case(param):
print(param)
print(f"uname={param['uname']}, pwd={param['pwd']}")
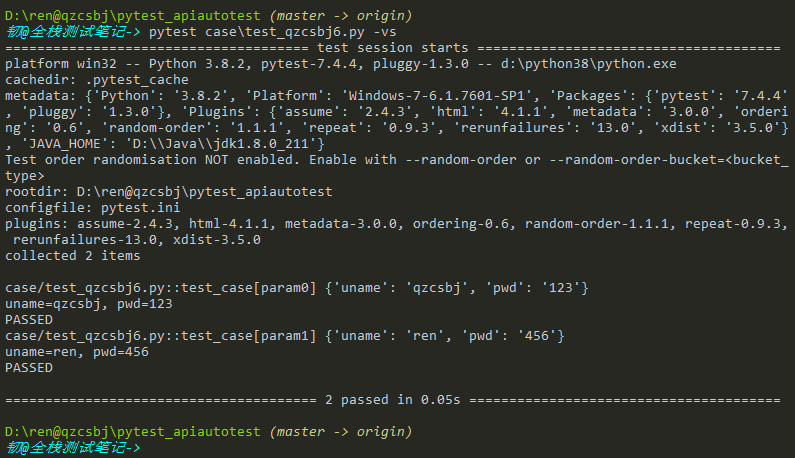
结果:
openpyxl模块
openpyxl是一个比较综合的工具,能够同时读取和修改excel文档。
pip install openpyxl
代码实现:
todo
__EOF__

本文作者:持之以恒(韧)
关于博主:擅长性能、全链路、自动化、企业级自动化持续集成(DevTestOps)、测开等
面试必备:项目实战(性能、自动化)、简历笔试,https://www.cnblogs.com/uncleyong/p/15777706.html
测试提升:从测试小白到高级测试修炼之路,https://www.cnblogs.com/uncleyong/p/10530261.html
欢迎分享:如果您觉得文章对您有帮助,欢迎转载、分享,也可以点击文章右下角【推荐】一下!
关于博主:擅长性能、全链路、自动化、企业级自动化持续集成(DevTestOps)、测开等
面试必备:项目实战(性能、自动化)、简历笔试,https://www.cnblogs.com/uncleyong/p/15777706.html
测试提升:从测试小白到高级测试修炼之路,https://www.cnblogs.com/uncleyong/p/10530261.html
欢迎分享:如果您觉得文章对您有帮助,欢迎转载、分享,也可以点击文章右下角【推荐】一下!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号