
Mysql字符编码利用技巧(from p神)
0x00
<?php
$mysqli = new mysqli("localhost", "root", "333", "unknown");
/* check connection */
if ($mysqli->connect_errno) {
printf("Connect failed: %s\n", $mysqli->connect_error);
exit();
}
$mysqli->query("set names utf8");
$username = addslashes($_GET['username']);
echo "username: $username <br>";
/* Select queries return a resultset */
$sql = "SELECT * FROM `users` WHERE name='{$username}'";
if ($result = $mysqli->query( $sql )) {
printf("Select returned %d rows.\n", $result->num_rows);
while ($row = $result->fetch_array(MYSQLI_ASSOC))
{
var_dump($row);
}
/* free result set */
$result->close();
} else {
var_dump($mysqli->error);
}
$mysqli->close();
?>
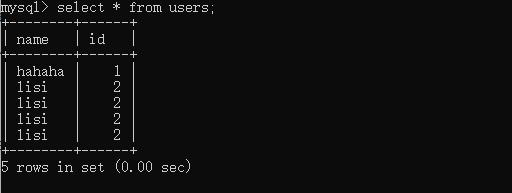
users表:
地址栏输入:?name=hahaha%c2,发现可以查到name=hahaha的数据:
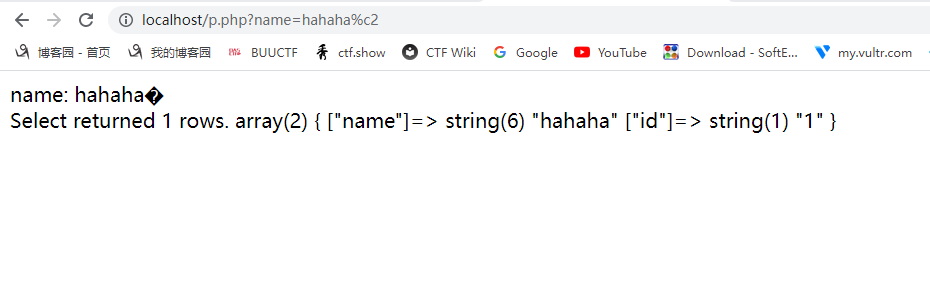
原理:Mysql的字符集默认是latin1,php mysqli客户端的字符集是utf-8,mysql接收php的数据涉及字符集转换。p神猜测:Mysql在转换字符集的时候,将不完整的字符给忽略了。
关于utf-8编码:
utf-8是变长编码,可能有1~4个字节表示,第一个字节所在的范围这个字符用多少个字节表示。
一字节时范围是[00-7F]
两字节时范围是[C0-DF][80-BF]
三字节时范围是[E0-EF][80-BF][80-BF]
四字节时范围是[F0-F7][80-BF][80-BF][80-BF]这些是大前提,但有一些字节值是不允许出现在UTF-8编码中的
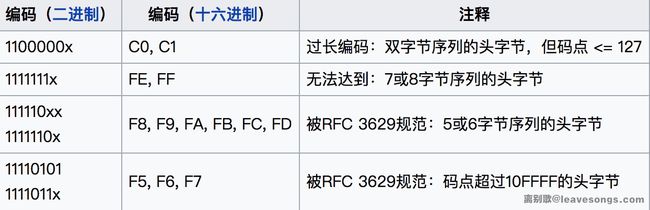
所以UTF-8第一字节最终取值范围是:00-7F、C2-F4。
举个例子:%c2%90%20%e2%b0%b1%f5%89%8a%8b
第一个是%c2,表示%c2%90表示一个字符,
下一个:%20,表示%20表示一个字符,
下一个:%e2,表示%e2%b0%b1是一个字符,
下一个:%f5,表示%f5%89%8a%8b是一个字符。
"不完整的字符"意思就是单独传一个%c2,后面还缺一个字节,所以是不完整。
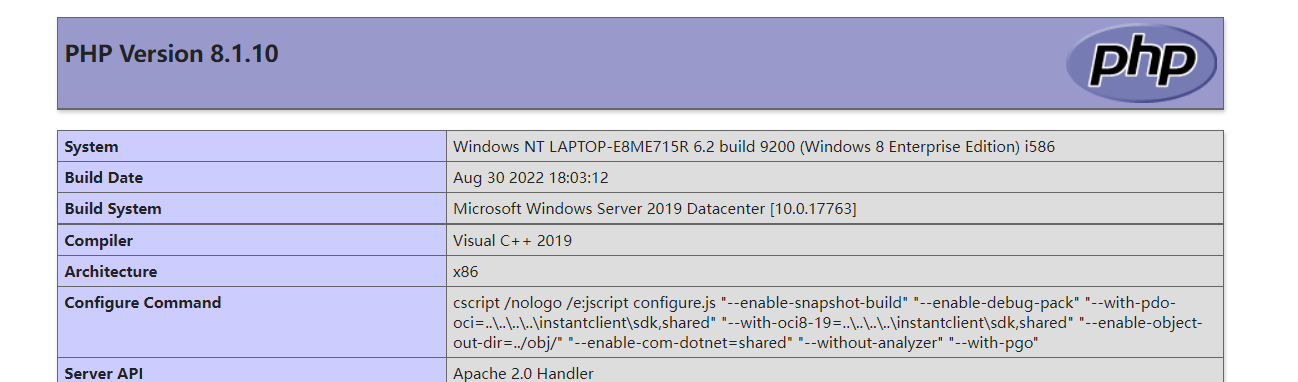
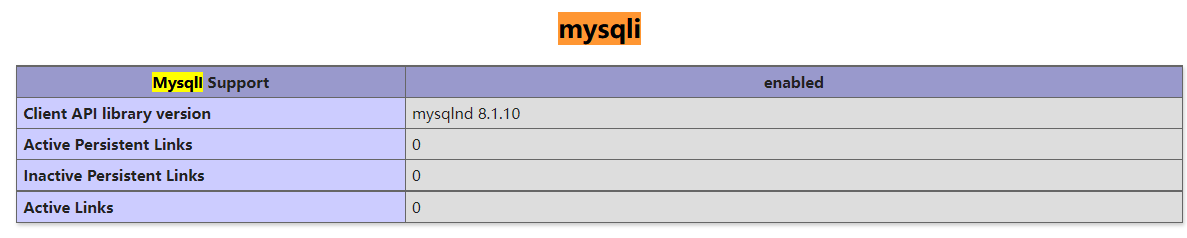
mysql:
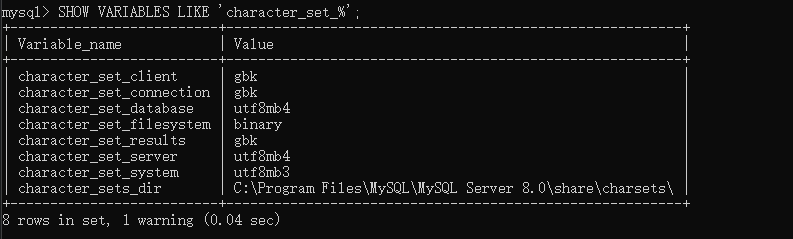
character_set_server的字符集也是utf8,客户端服务端字符集都是utf8,(客户端这里显示是gbk,但在php执行了$mysqli->query("set names utf8");,所以还是utf8) 这个trick竟然也复现成功了?!
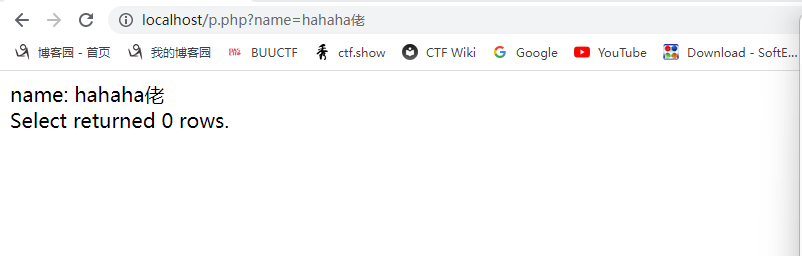
我把mysql配置改成和p神的一样,看看我的会不会传'佬'而报错:
(utf8mb3 和 utf8mb4 都是utf8,只是最大字节数不同。mb3 maximun of 3 bytes per multibyte character. 。https://blog.csdn.net/htuhxf/article/details/90676341)
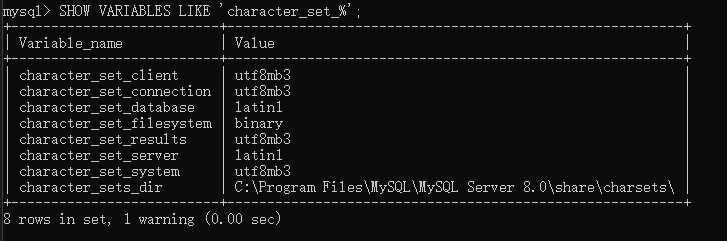
trick复现可以:
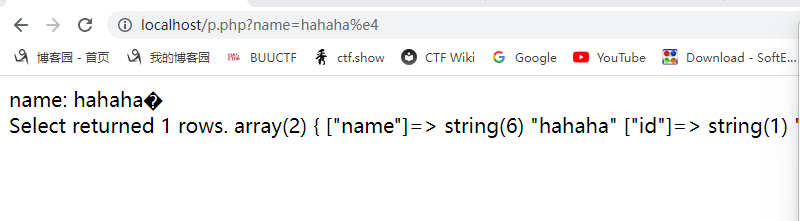
但是传'佬'不报错,这又和p神的有出入了:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号