jmeter学习之jforum注册
上一篇学习了jforum登入,接下来实现jfroum注册脚本。
流程:首页->注册确认页面->点击 I argee->填写注册信息页面->点击提交
首先用Fidder抓包分析报文(也可以用badboy录制脚本)
1、Fidder抓包查看流程如下。接下来一个个分析每个请求。
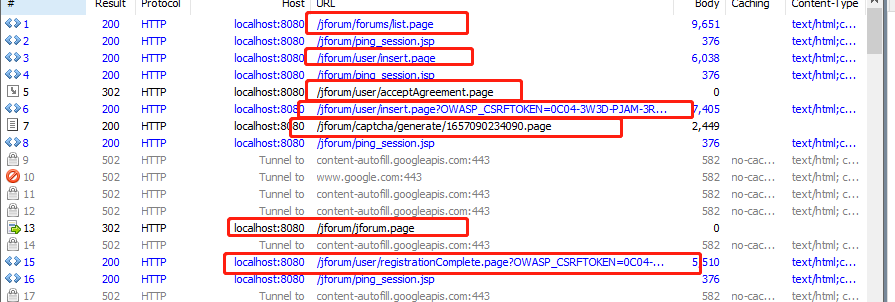
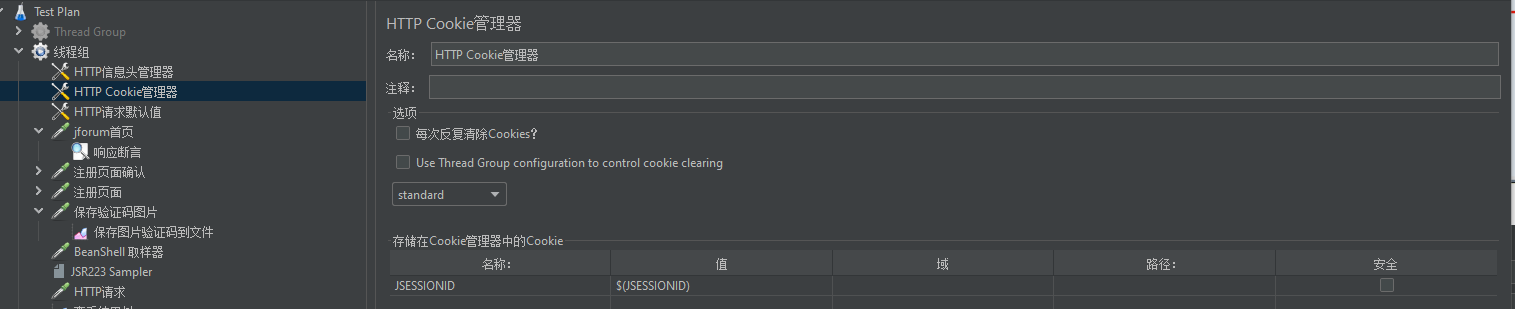
a、 第一个http请求GET /jforum/forums/list.page,很明显是首页的请求,获得了请求头,Cookies信息,根据这些信息在jmeter编写第一个请求
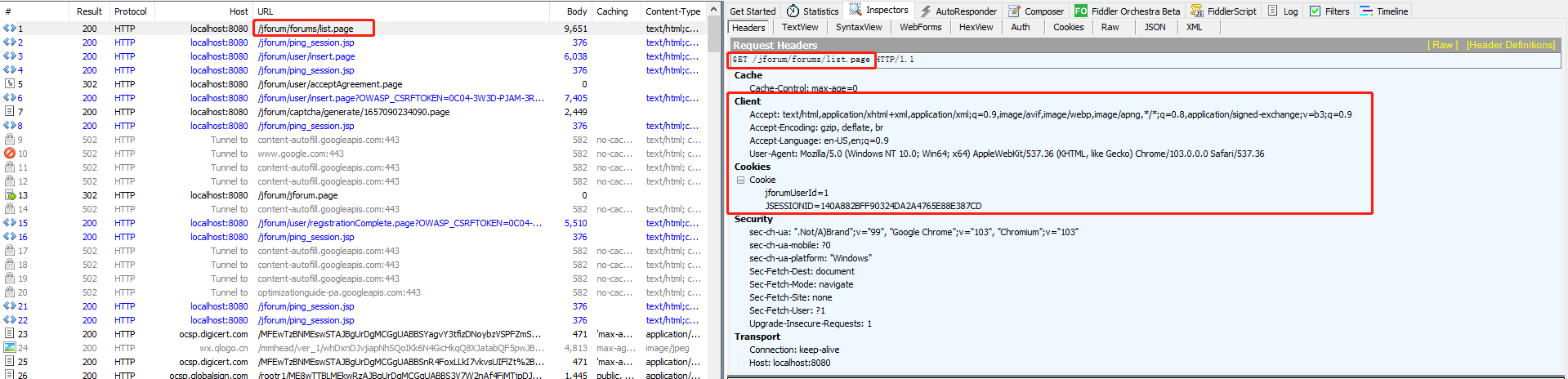
首先配置HTTP信息头管理器和HTTP Cookie管理器

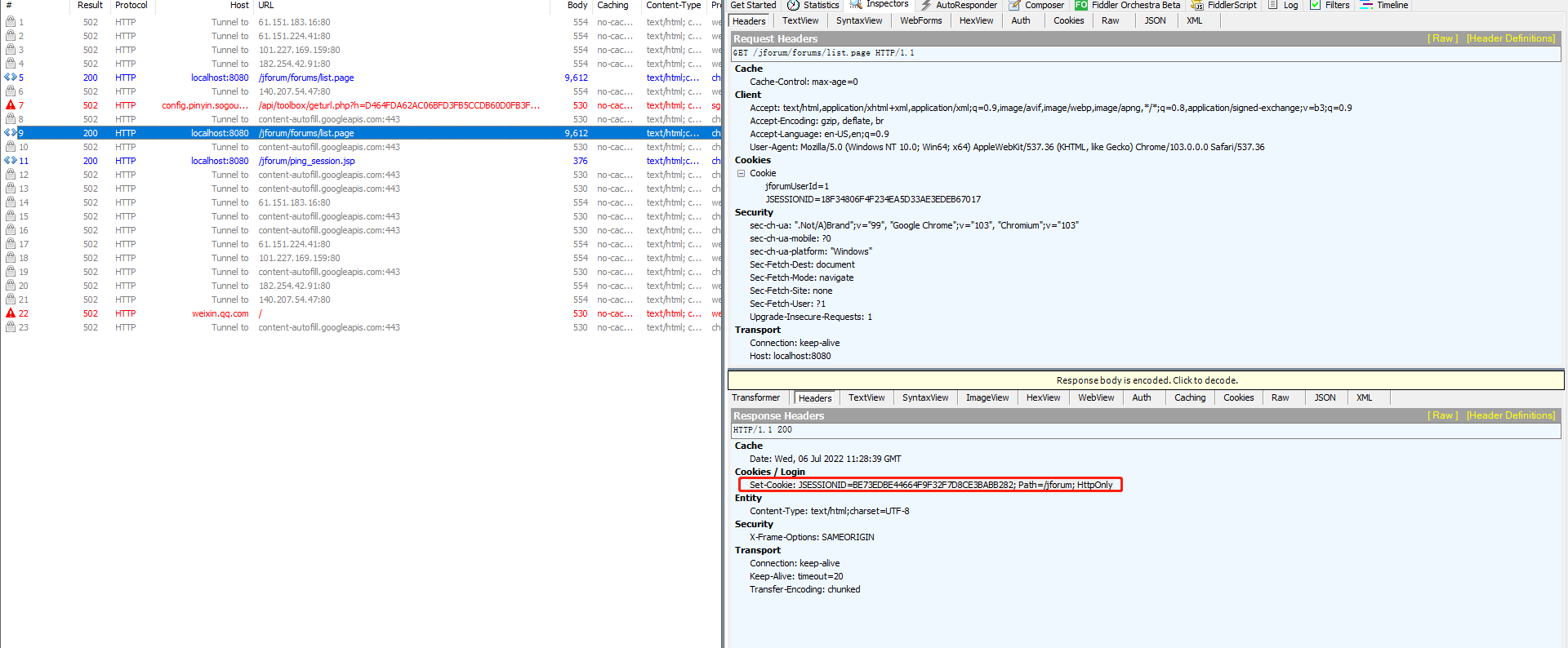
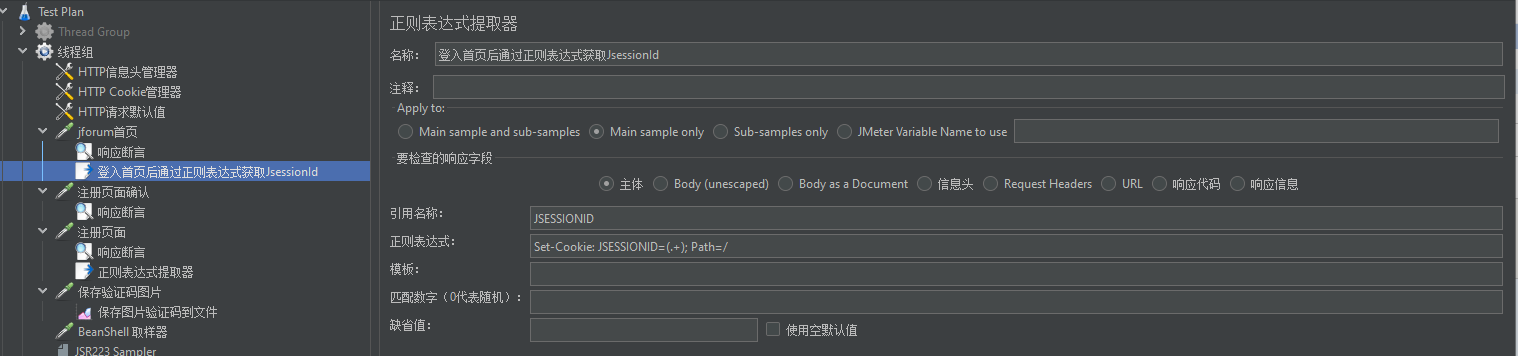
Cookie跟之前学习登入一样用后置处理器—正则表达式提取器获取保存到变量中,通过变量引用(在响应的头有set-cookine,说明之前的过期了,用的所有证照表达式为:Set-Cookie: JSESSIONID=(.+); Path=/)
http请求
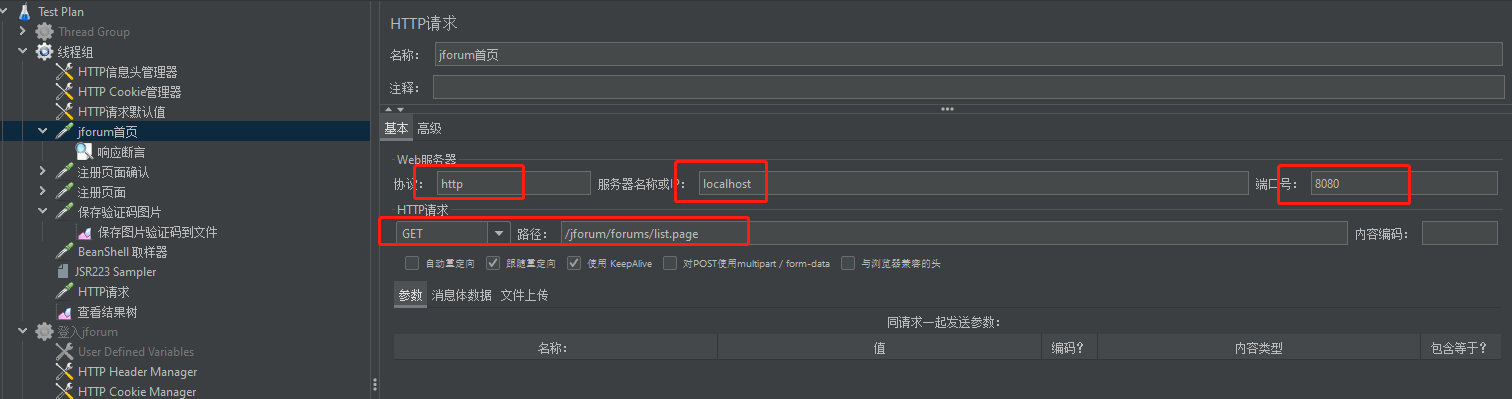
b、第二个http请求GET /jforum/user/insert.page。这个是我们进入首页后点击注册按钮的请求连接
http请求
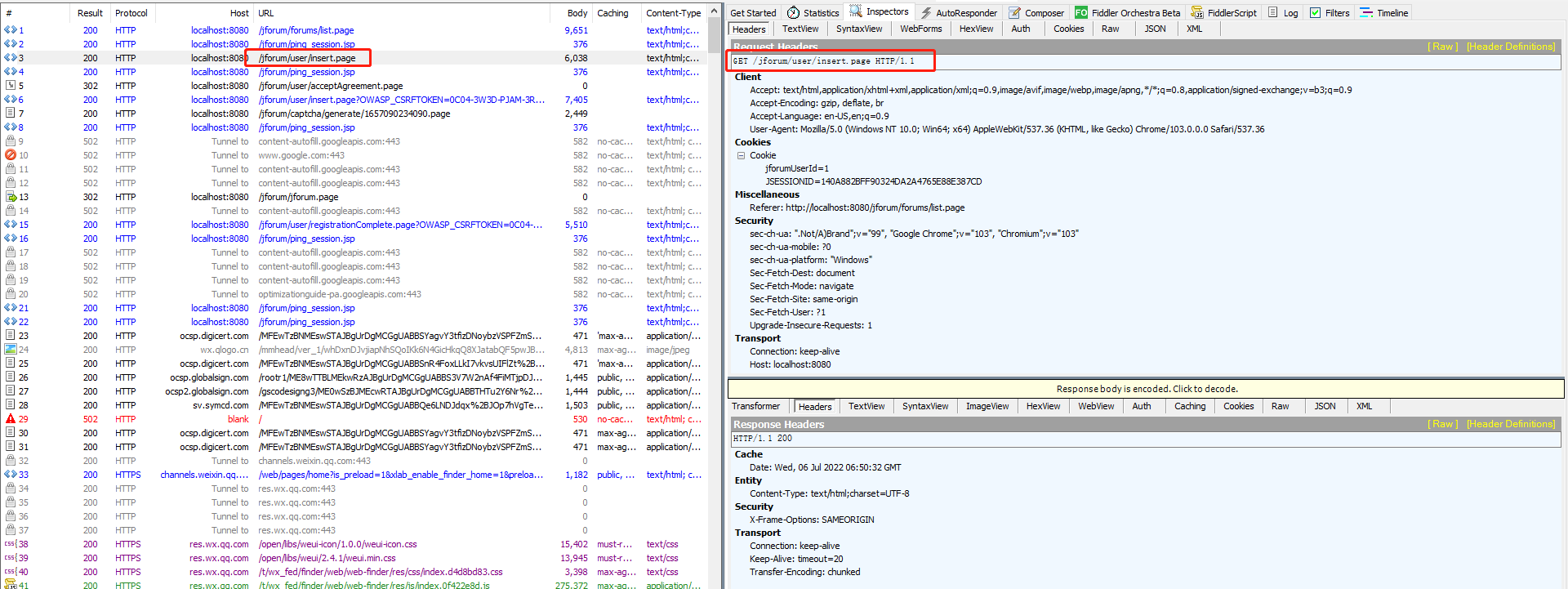
c、第三个http请求。在上一个请求(点击注册按钮)返回的页面是注册确认页面,这个请求是在注册页面点击“I agree to these terms”请求的链接,看返回头信息302,显然这个是一个重定向,重定向到Location的地址(就是报文流程中的下一个请求)
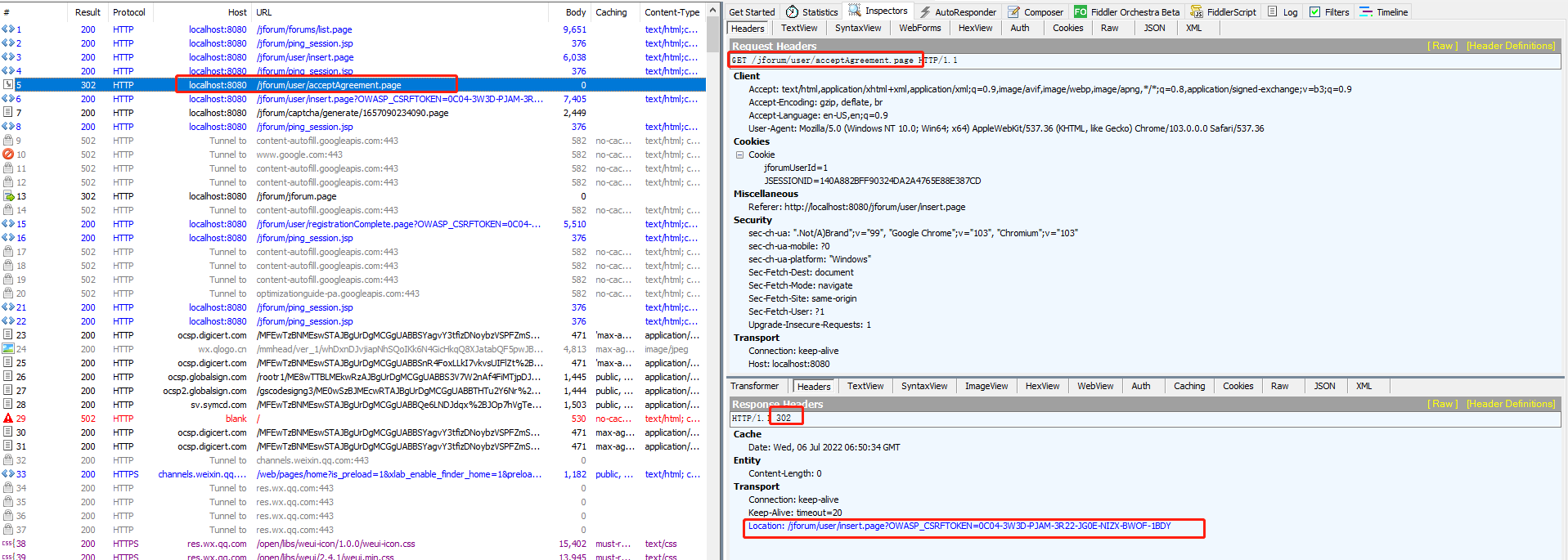
http请求,勾选跟随重定向
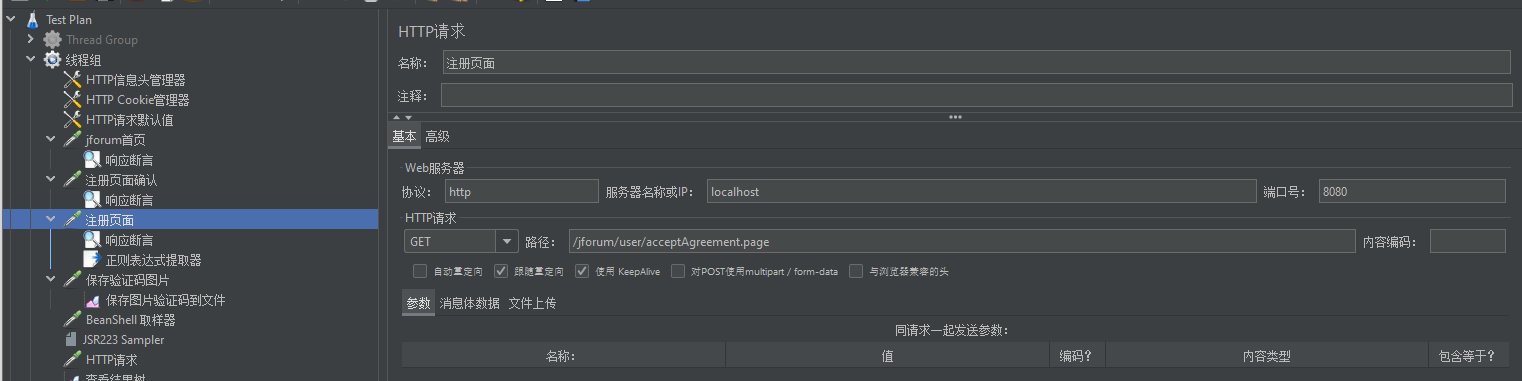
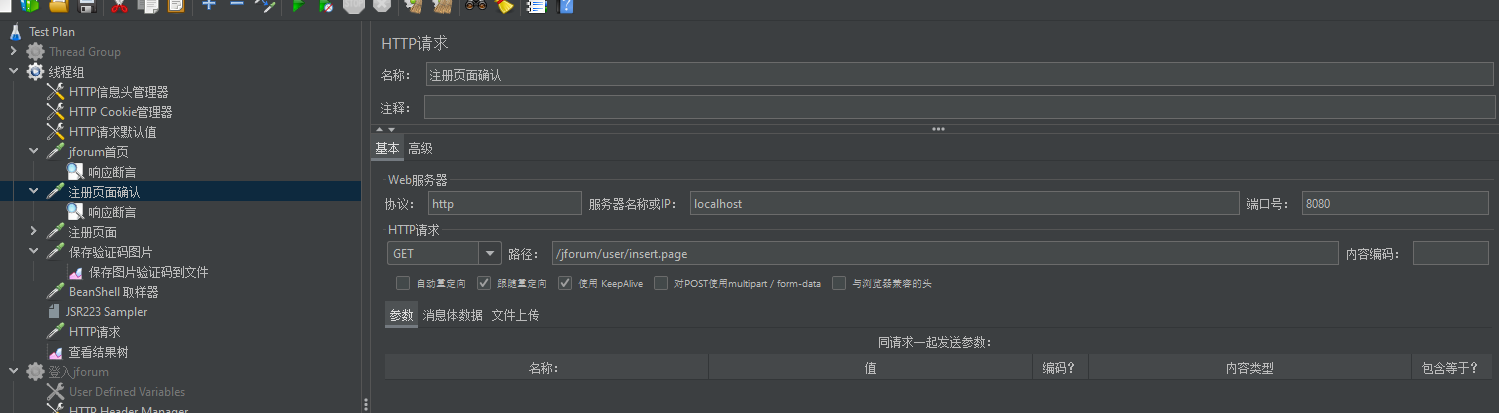
d、第四个http请求,这个是上一个请求的重定向请求,这个请求返回的页面就是注册页面,在此页面填写注册信息
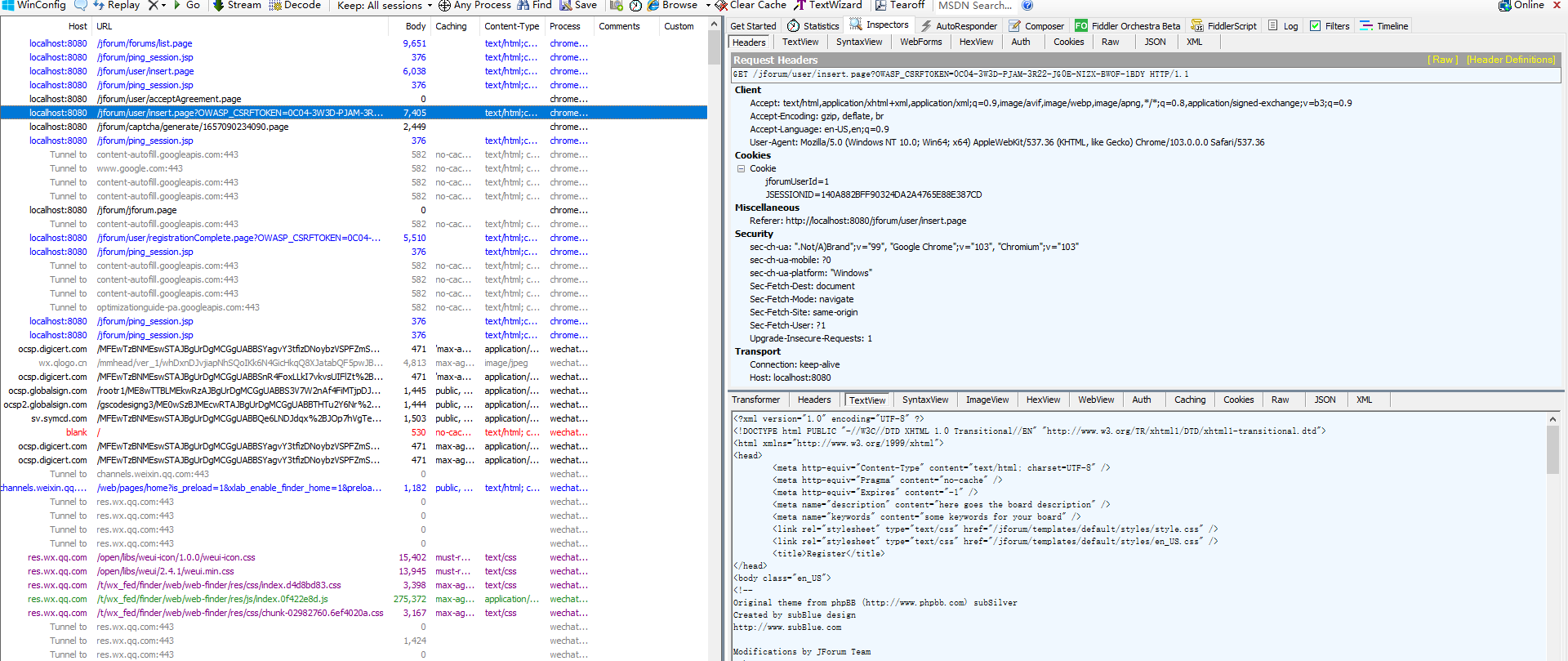
http请求:不需要写,因为是重定向,我们在上一个http请求中选择“跟随重定向”了
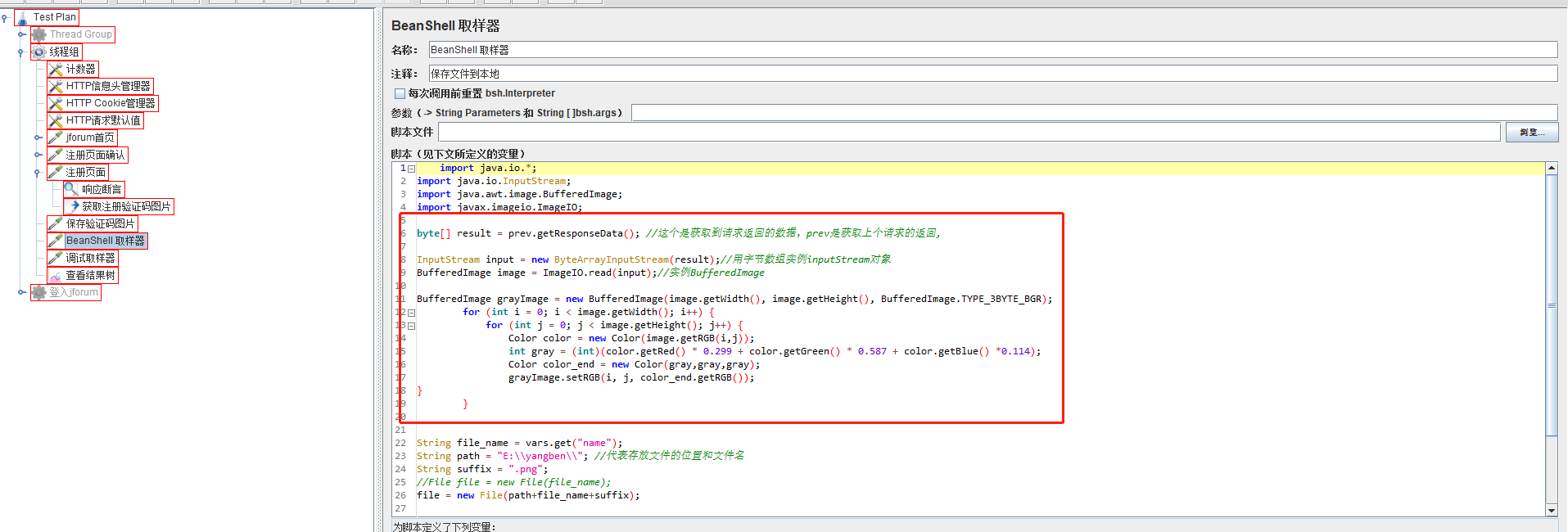
e、第五个请求,这个是注册验证码的图片,这个链接是在上一个请求返回的内容,我们可以通过在上一个请求后面添加后置处理器-正则表达式提取器获取,获取后把图片保存在本地(通过插件识别验证码)
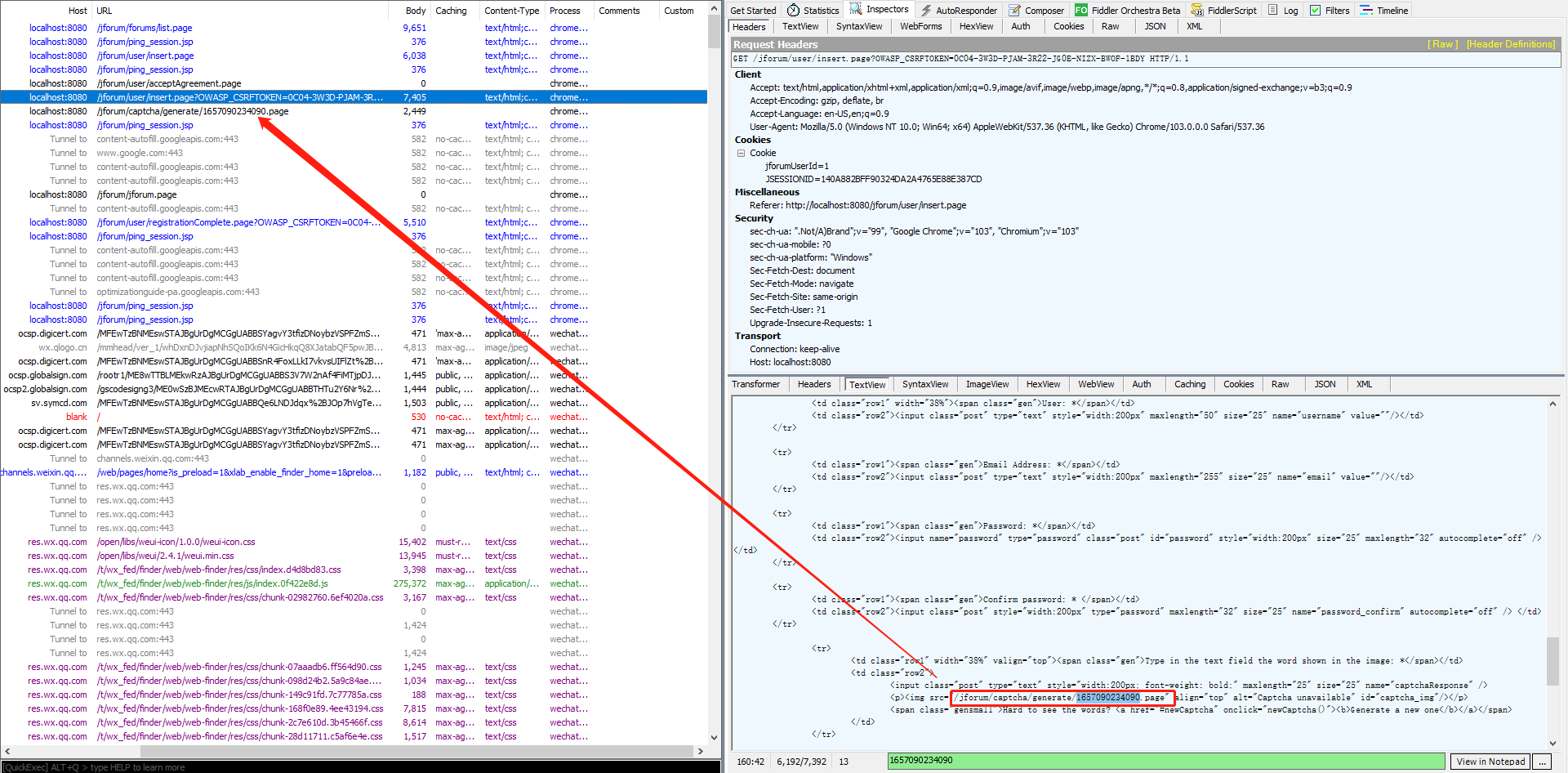
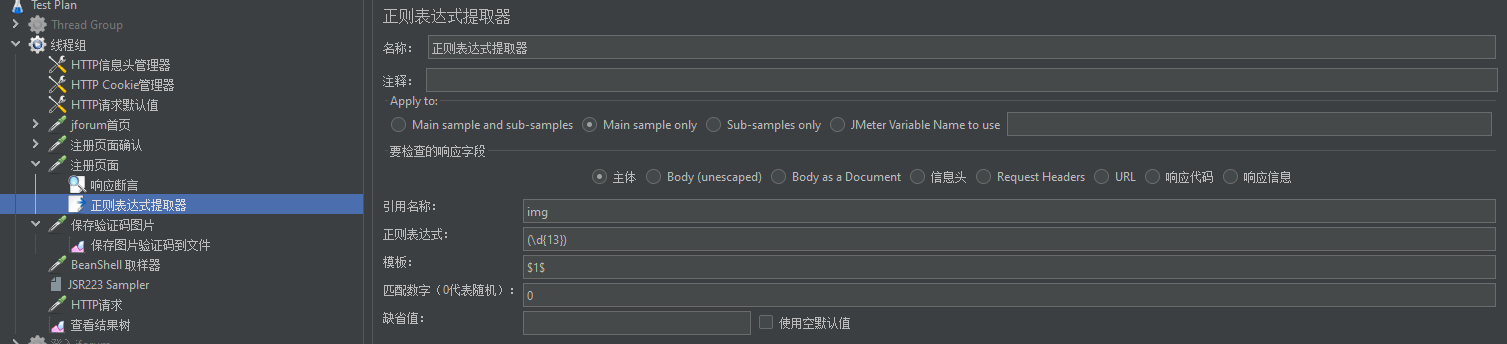
http请求
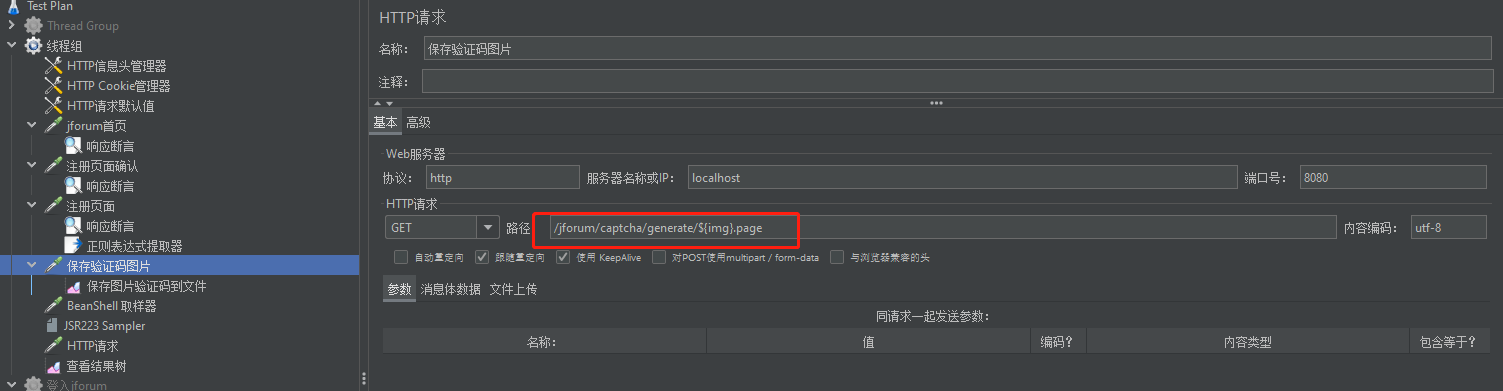
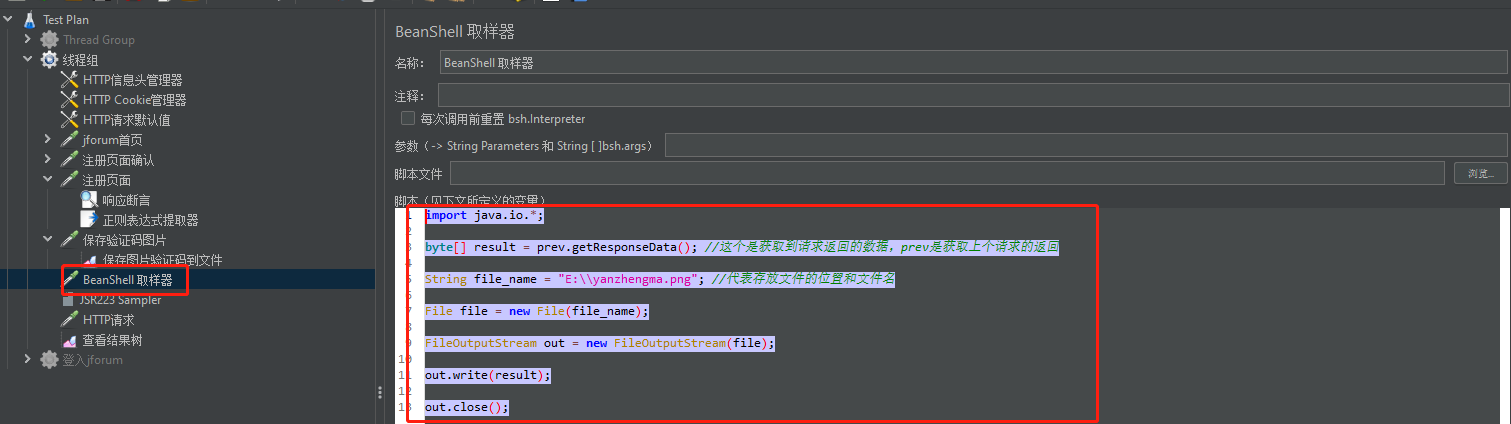
这个请求返回的就是验证码图片,可以选择监听器-保存响应到文件(但是我实际测试选择这个方法,保存的文件后缀为.unkonwn,需要改后缀为png才行),另一种方法通过-取样器-Beanshell 取样器,代码把响应的文件写入文件
报文的验证码图片

到此实现的脚本如下
后面的请求需要把验证码识别出来才能进行,因为注册需要验证码:
我再网上找了2中方法一个是ddddocr和tesseract,但是通过测试识别都不理想,如下:
ddddocr如下
import ddddocr
def picOcr():
ocr = ddddocr.DdddOcr()
with open(r"E:\\yanzhengma.png", "rb") as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
print(res) # 一定要有打印才能获取到
if __name__ == '__main__':
picOcr()
tesseract如下:
tesseract E:\yanzhengma.png E:\result -l eng
多次试验如下:分别是ddddocr、tesseract、原图



没有办法我只好选择训练tesseract:
准备训练工具jTessBoxEditorFX,下载即可
训练数据,验证码图片,通过jmeter脚本保存到本地,准备1000个样本
首先把让线程运行1000次
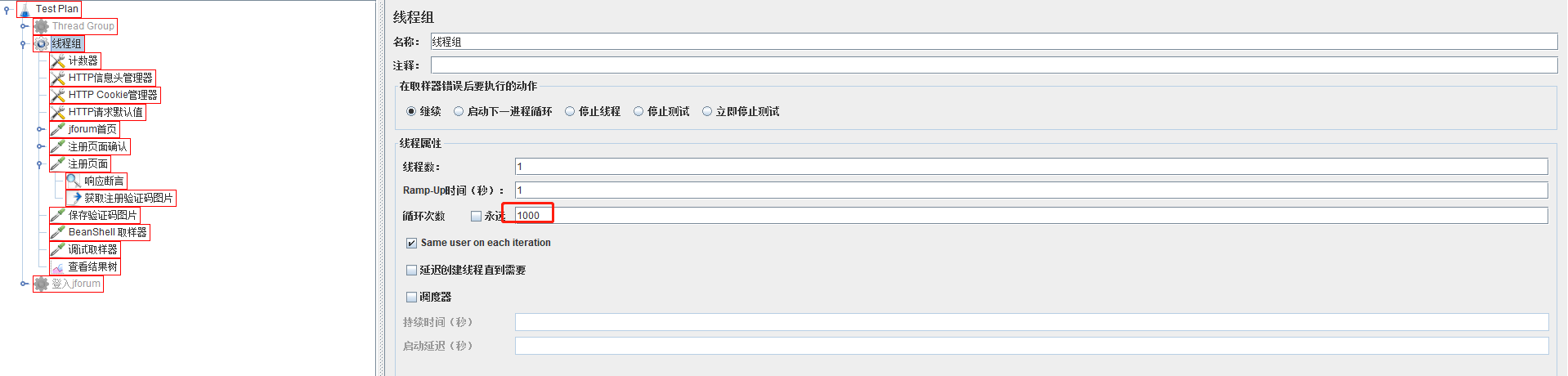
其次添加一个计数器,让数字从1递增当做文件的名称

然后在修改Bean Shell 取样器代码

最后运行查看,本地已经有了1000个验证码图片样本

接下来就是训练tesseract:
第一步:打开训练工具,然后Tools→MergeTIFF,选中所有样本,然后保存为wml.font.exp0.tif
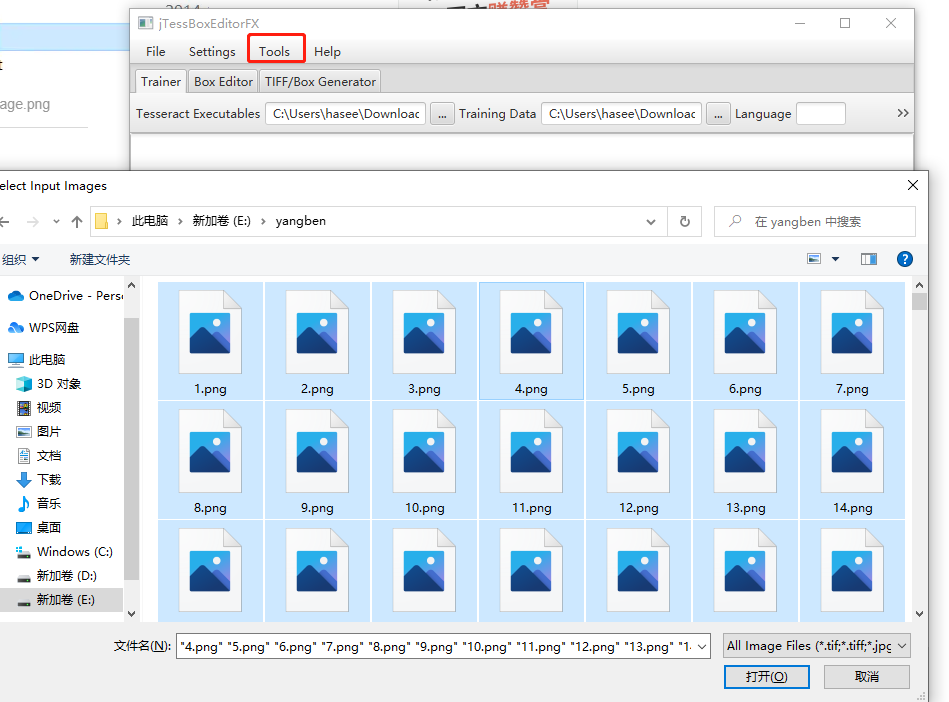
出现I/O Error reading PNG header,尚不知道原因;然后把样本后缀名从.png改成.tif或者.tiff重新Merge样本出现Couldn’t Seek 的错误
手动用画图工具制作tif文件样本,在Merge执行成功,大概率是样本有问题;最后把其中一个样本灰度处理后再Merge执行居然成功了,应该是我的样本没有经过灰度处理导致出现Couldn’t Seek(出现I/O Error reading PNG header和Couldn’t Seek都是没有进行灰度处理);
先灰度批量处理样本:
直接在保存验证码的Bean Shell 取样器代码中修改,灰度处理后再保存
 灰度处理代码参考原文链接:https://blog.csdn.net/weixin_54963748/article/details/122807140
灰度处理代码参考原文链接:https://blog.csdn.net/weixin_54963748/article/details/122807140
灰度处理的样本保存为.png格式(因为保存为tif格式又出现Couldn’t Seek 的错误|)(这样处理有个问题就是太慢,循环1000次都非常慢,如果后面做注册的压测会更慢,如果只是获取验证码样本训练tesseract还不要紧)
灰度处理后继续执行第一步:第一步:打开训练工具,然后Tools→MergeTIFF,选中所有样本,然后保存为wml.font.exp0.tif
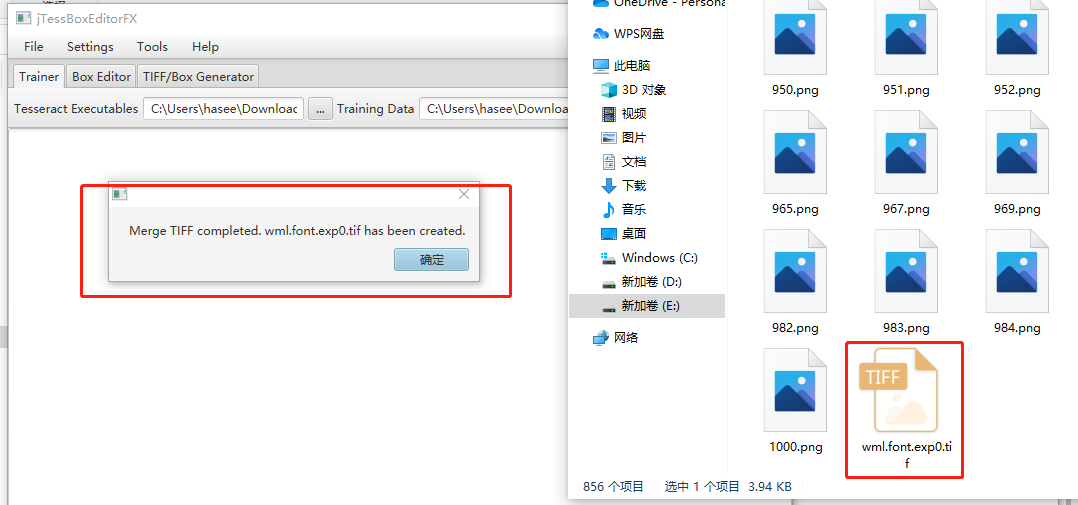
终于成功了
第二步:生产box文件,打开cmd,进入上面tiff所在的文件夹执行下面命令:
tesseract wml.font.exp0.tif wml.font.exp0 -l eng --psm 7 batch.nochop makebox
提示Error,尚不知原因,但是查看还是生产了box文件

灰度处理后继续第二步:
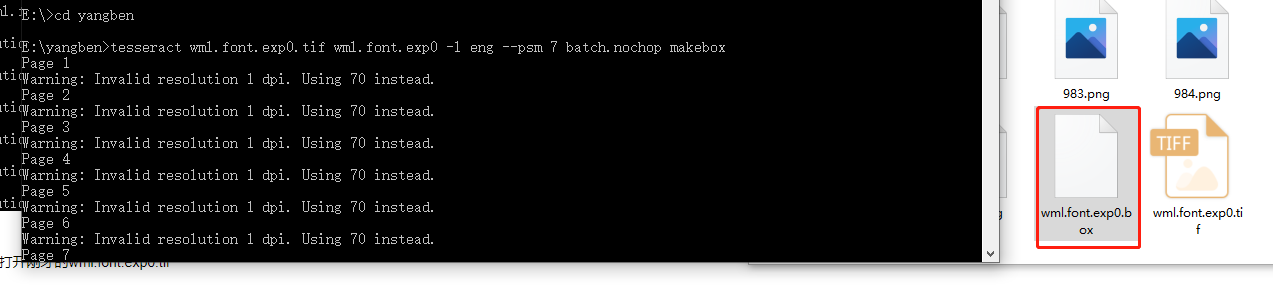
也成功了
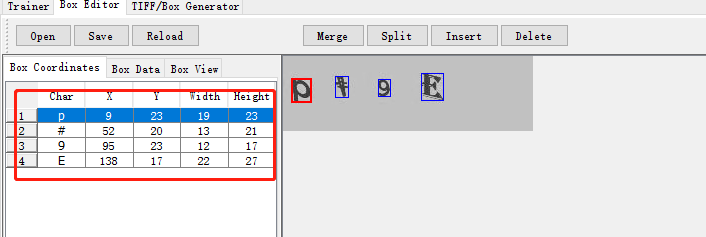
第三步:进入jTessBoxEditor,打开刚才的wml.font.exp0.tif,修正字符,把左边的字符修改成右边的,且红色的框包括整个字符
第四步:创建font_properties,其中font为wml.font.exp0.tif中的font,两个要一致

<fontname> <italic> <bold> <fixed> <serif> <fraktur>
fontname为字体名称,italic为斜体,bold为黑体字,fixed为默认字体,serif为衬线字体,fraktur德文黑字体,1和0代表有和无
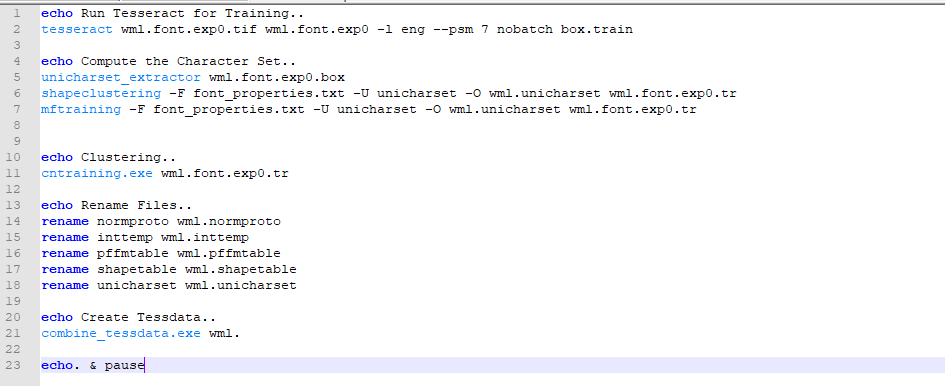
第五步,执行.bat命令,创建一个setup.bat输入下面的内容(也可以一条条执行)
注意:之前安装的tesseract,又下载了jTessBoxEditor,所以下面的命令都是有2个目录的:要执行的命令是jTessBoxEditor下的命令(我自己的电脑默认执行的是tesseract目录下的命令导致一直没有成功,在网上找了好久没有发现相同的问题,所以怀疑是自己的问题:首先更换了样本仍没有解决,也尝试过font_properties加后缀.txt也没有成功;后想起在linux配置过不同命令的路径遂查看发现有2个相同的命令,更换执行jTessBoxEditor下命令解决了)

第六步:把生成的wml.wml.traineddata放到Tesseract的tessdata目录下(C:\Program Files\Tesseract-OCR\tessdata)后执行tesseract 2.png result -l wml结果如下,完美识别

重新下载新的验证码验证效果(测试了10来个还是不理想,估计是样本过少和第三步修正样本没有修正完美)

由于验证码识别做得不理想,只能不上传验证码:修改SystemGlobals.properties如下2个属性为false
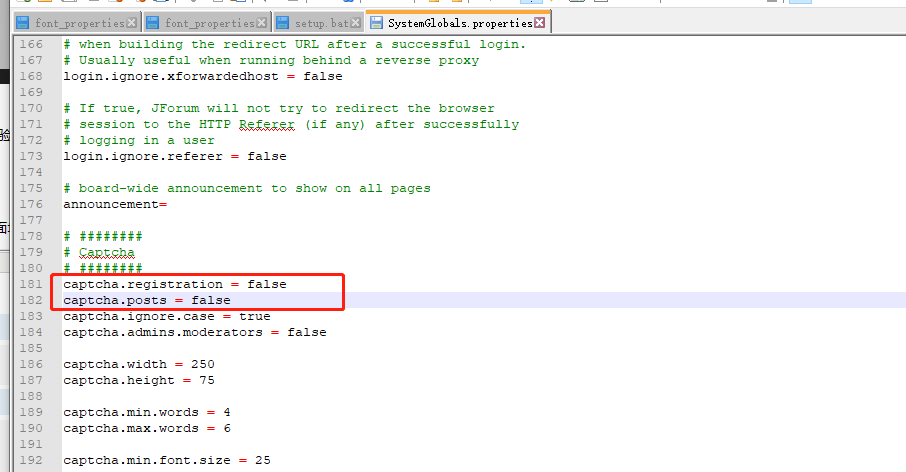
修改后查看,注册不需要验证码了

这样就得重新抓包查看注册流程和post上传的参数了,保存验证码图片的http取样器也要禁用
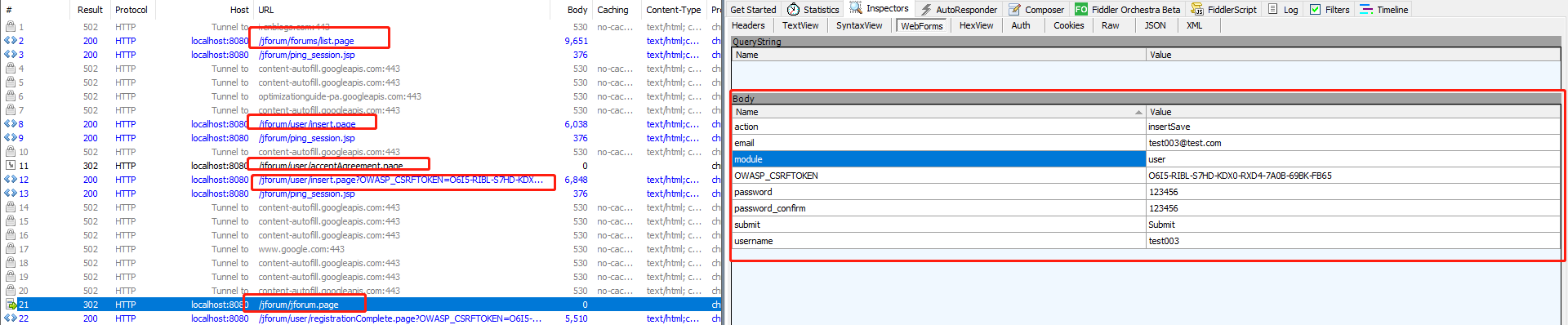
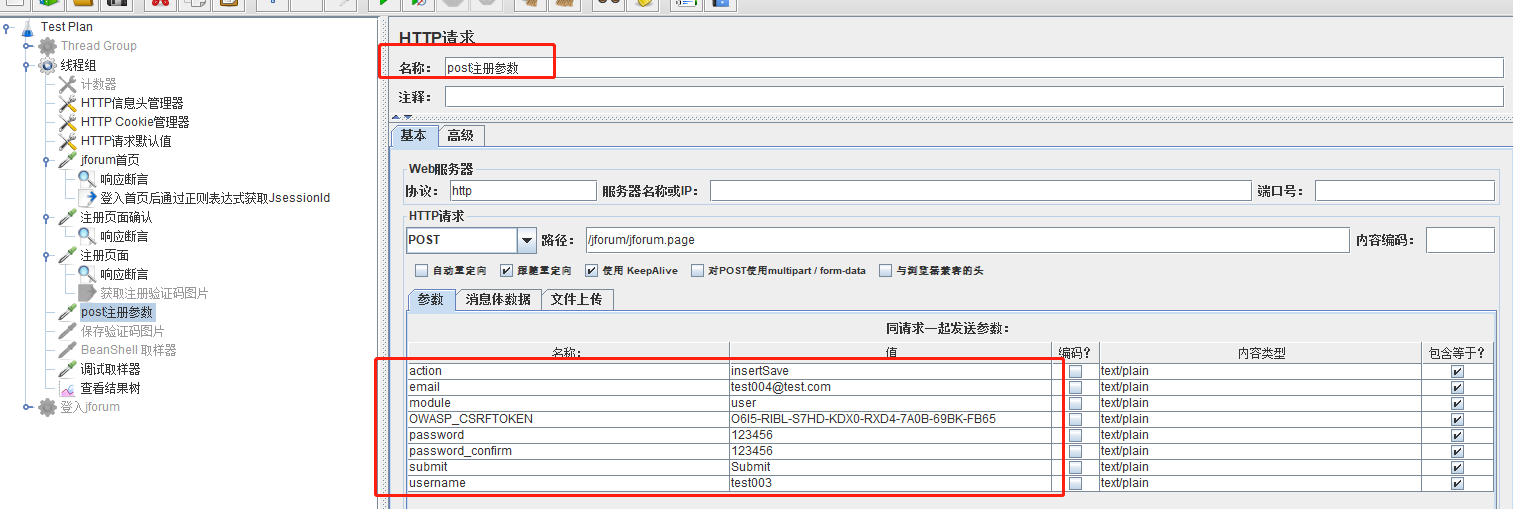
f、第六个http请求,这个请求是在注册页面填写注册信息后点击提交的请求,显然这个是post方法,需求上传的值也查看到如下
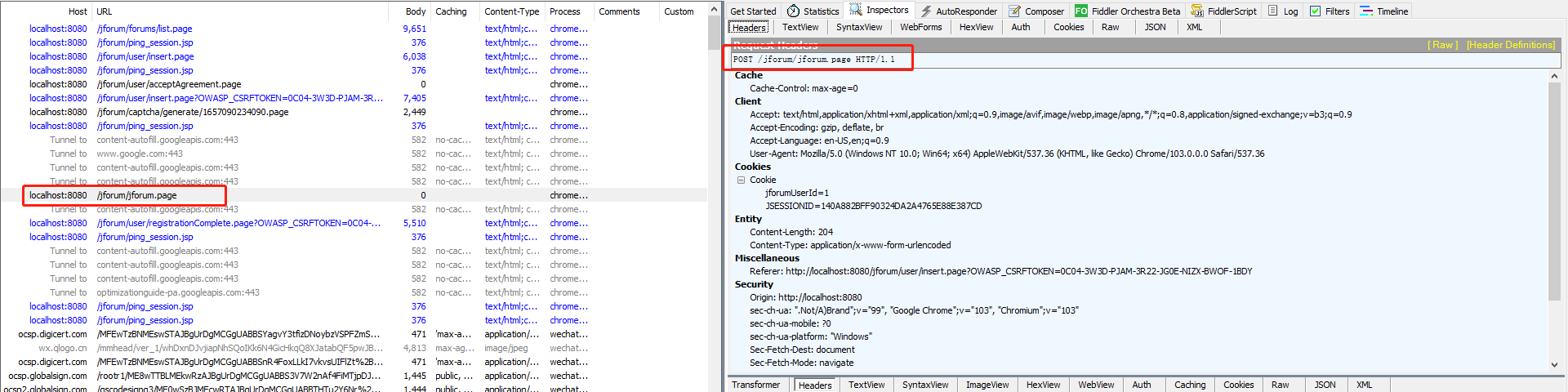
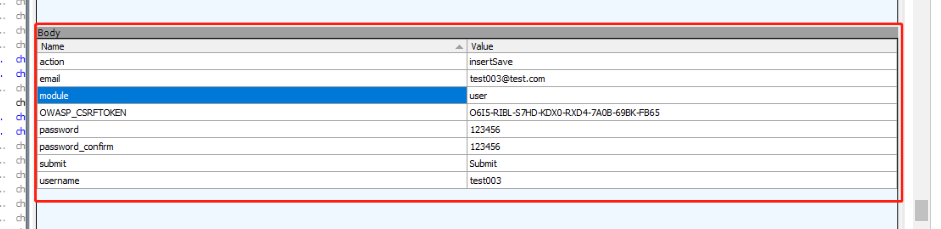
http请求:
g、最后一个请求,通过查看上一个请求知道,这个请求是重定向的,即注册成功后自动定向到这个页面
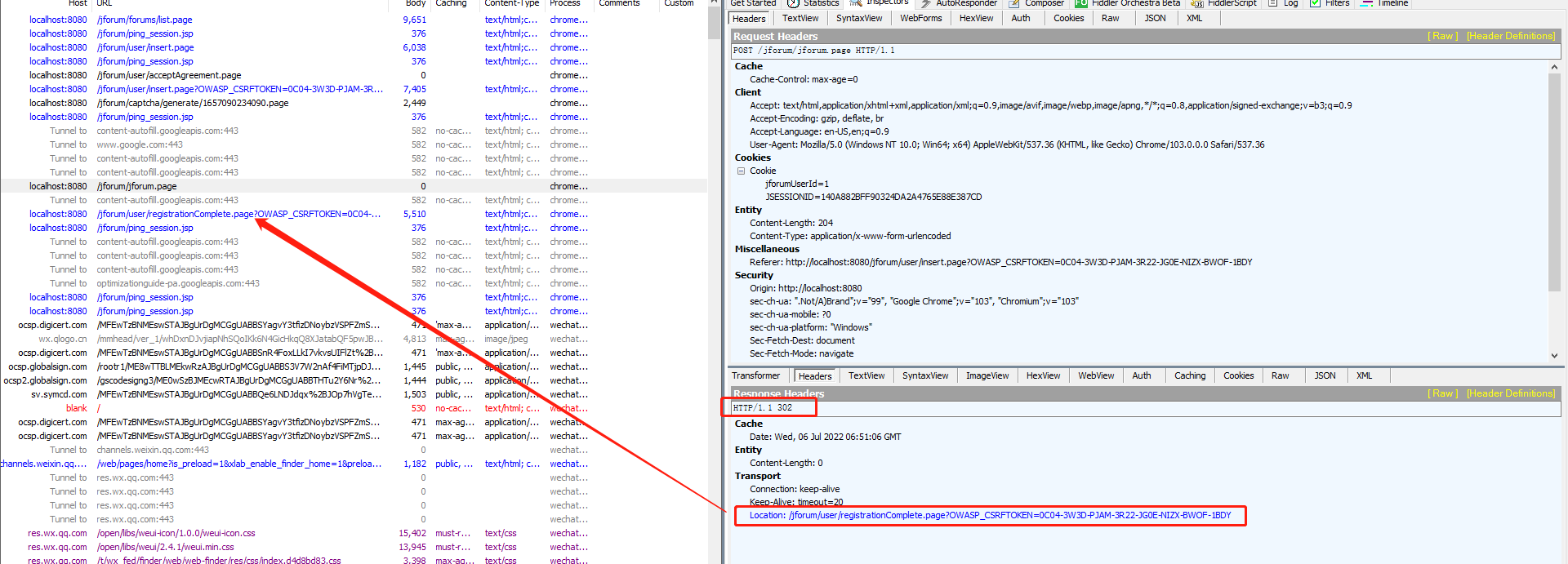
http请求:重定向不需要写,
最后完成的基本脚本如下:
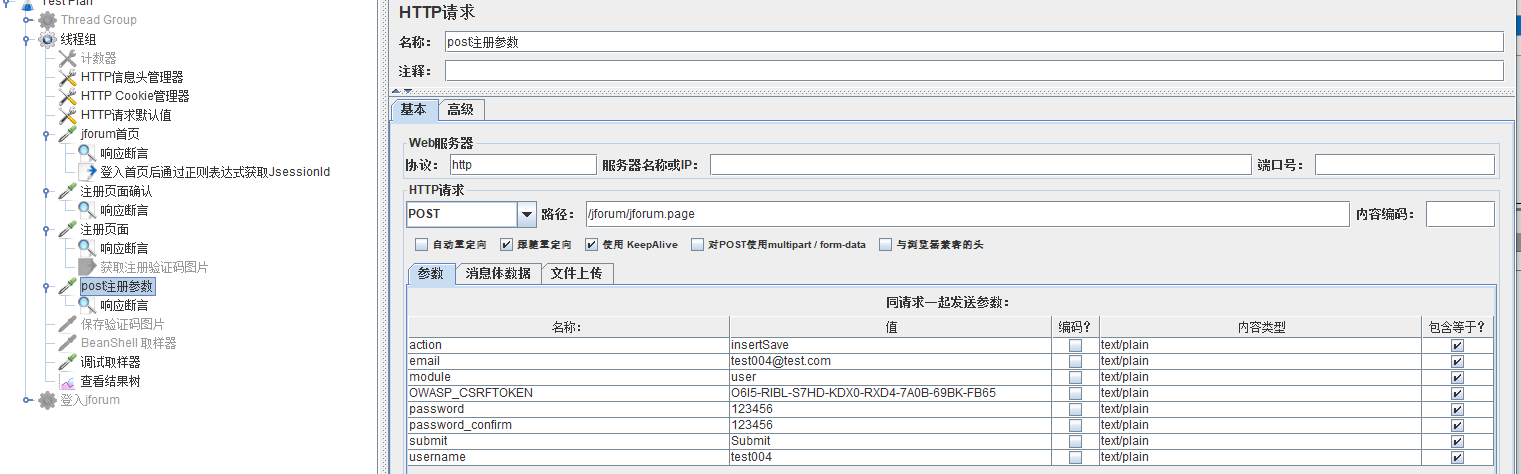
运行看下
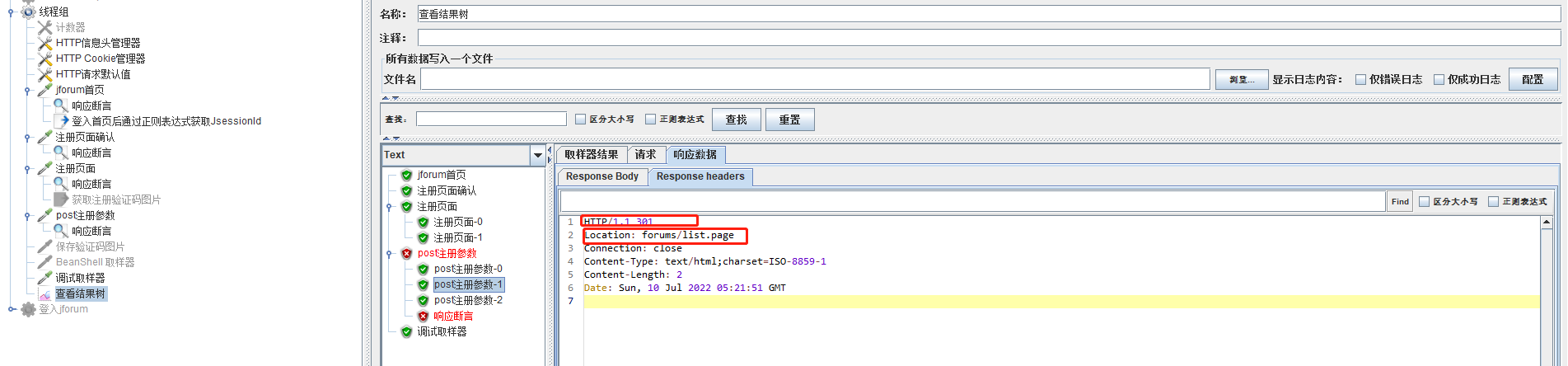
第一次运行失败,查看结果树是post注册参数http请求post没有成功,重定向到其他页面。
通过分析报文是,post的参数不对,OWASP_CSRFTOKEN是需要关联的,之前写http请求时是直接复制报文中的值,现在通过正则表达式获取。
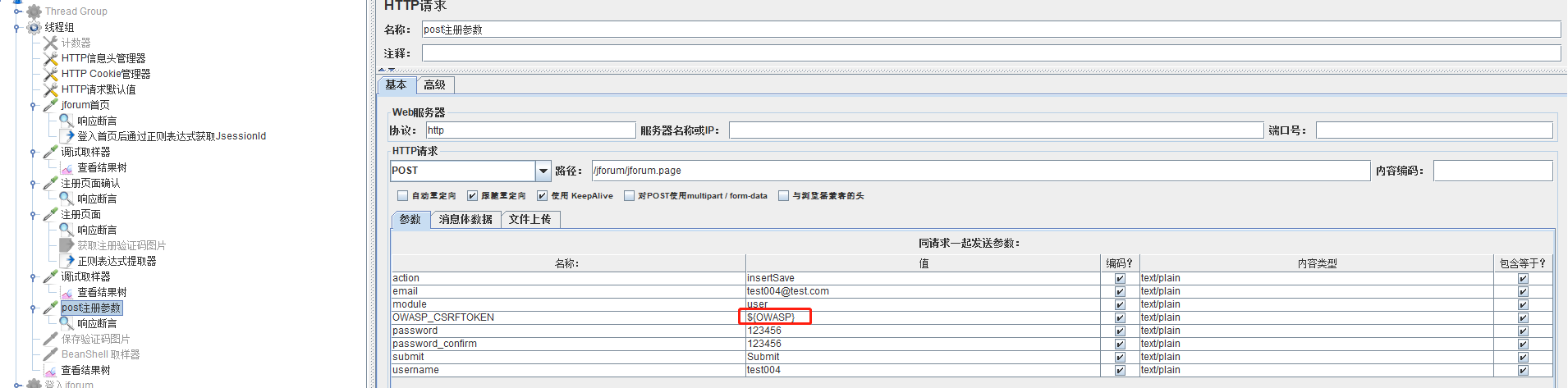

通过调式取样器查看,获取成功且值正确
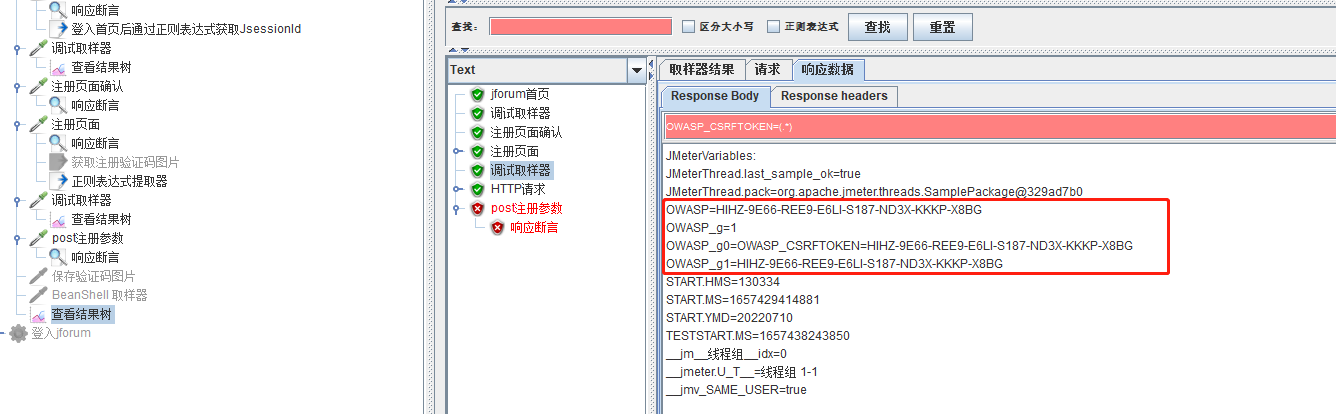
变量名:正则表达式提取的结果;
变量名_g:根据匹配规则所匹配的数量;
变量名_g0 :根据匹配规则所匹配的全部内容 ;
变量名_g1:根据匹配规则匹配出符合条件的内容
第二次运行:查看参数post正常,但是还是失败

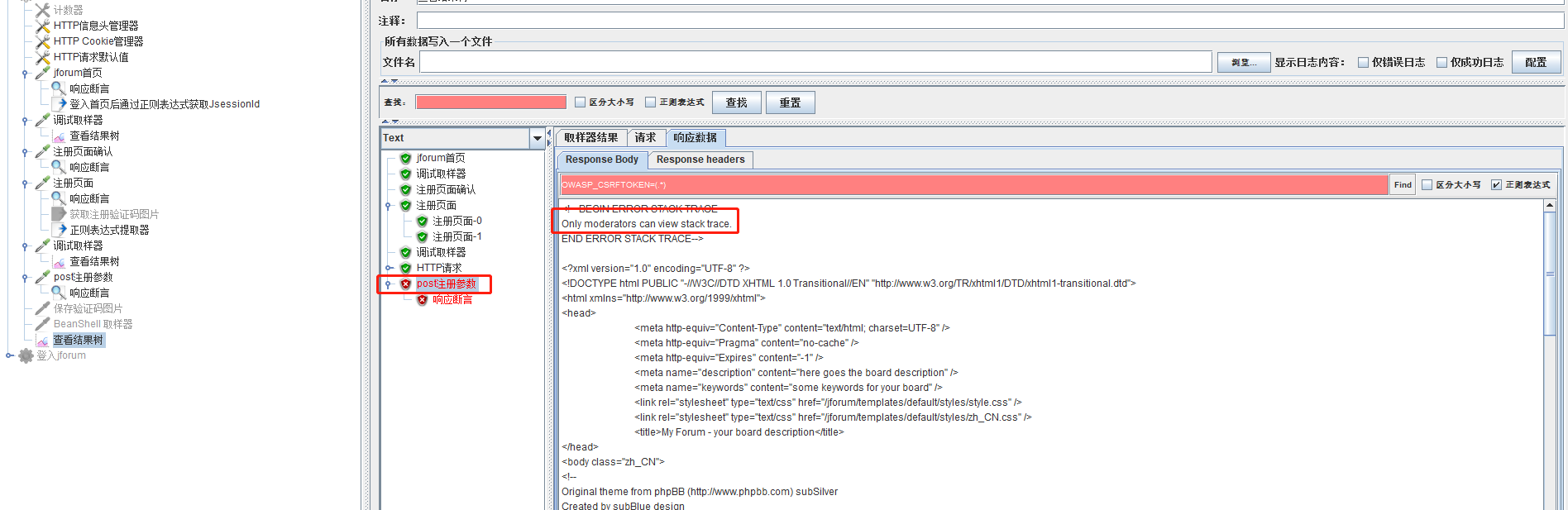
然后我什么都没有修改,再次运行居然成功了(不知道为什么):
重定向到恭喜页面
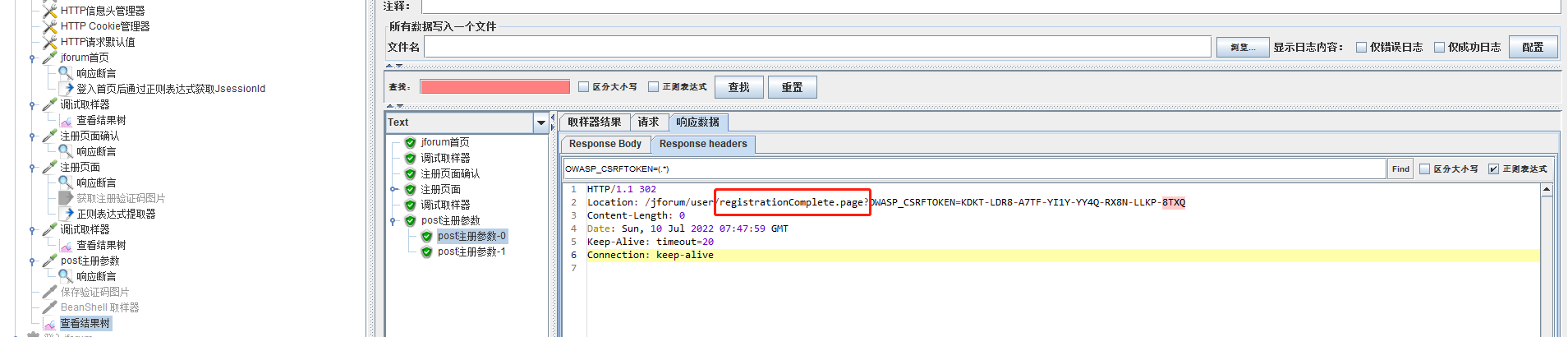
查看真的成功了。
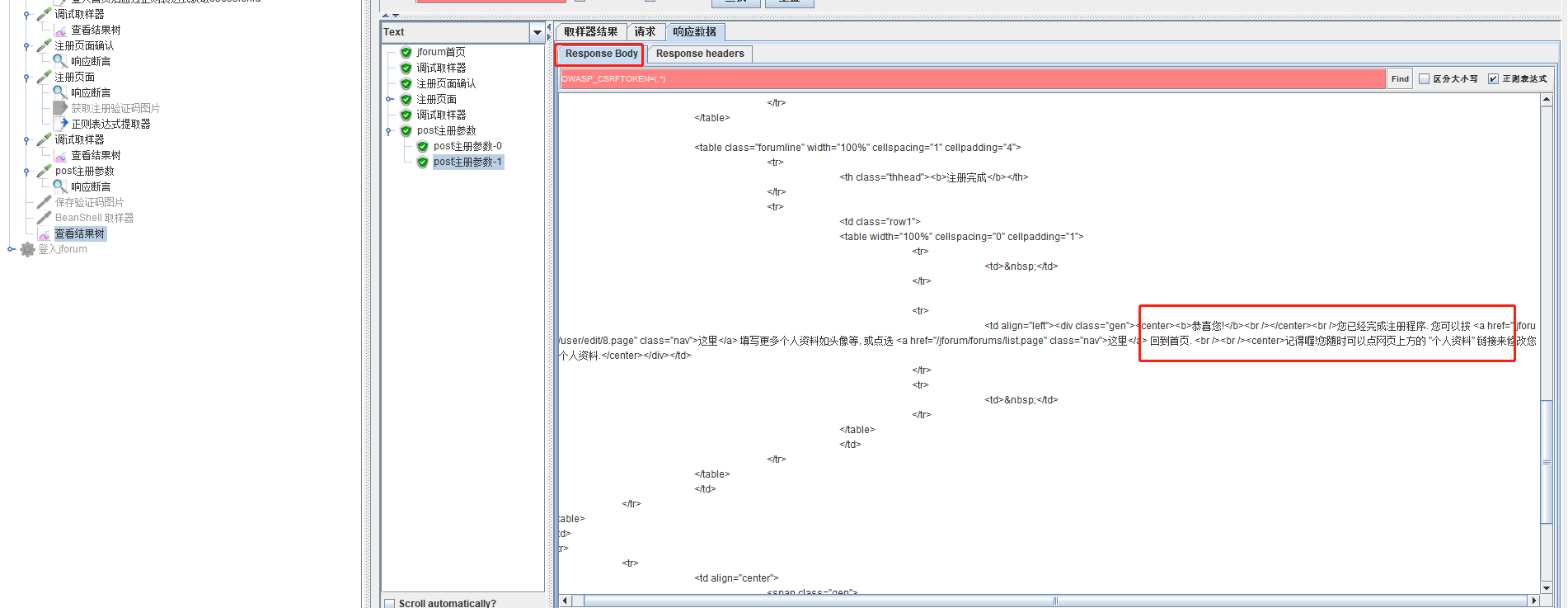
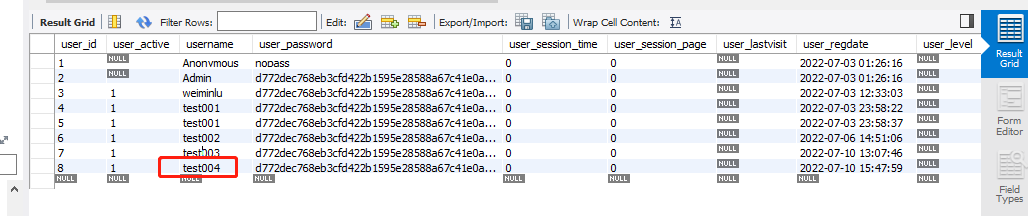
到数据库中查看,也看到了我们脚本中post的用户名
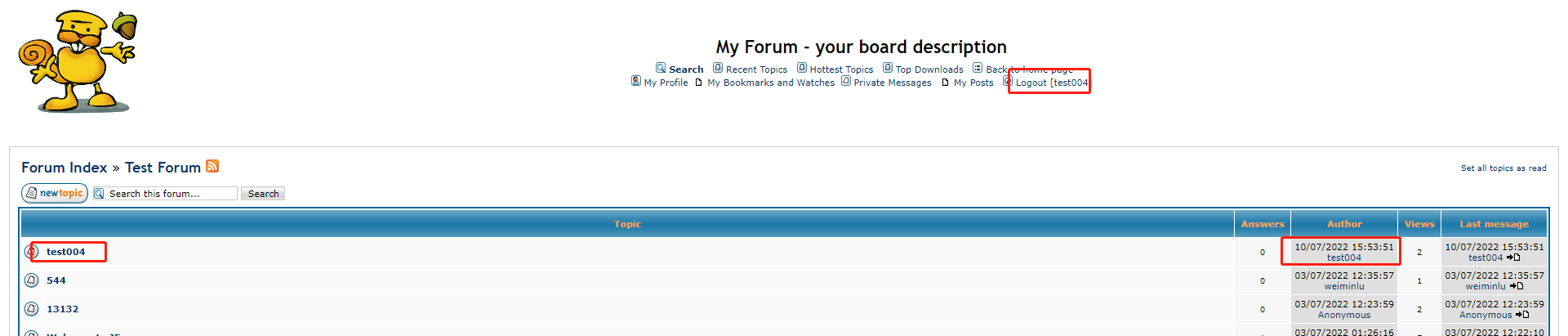
用这个用户登入成功,发帖也成功,
到此最基本的jforum无验证码注册脚本完成了,要在实际运用还是修改。 脚本链接:https://files.cnblogs.com/files/blogs/758732/jforumregist.7z?t=1657440470

 浙公网安备 33010602011771号
浙公网安备 33010602011771号