

Java基础补缺4:Java IO
Java 中是通过流处理IO 的,那么什么是流?
流(Stream),是一个抽象的概念,是指一连串的数据(字符或字节),是以先进先出的方式发送信息的通道。
当程序需要读取数据的时候,就会开启一个通向数据源的流,这个数据源可以是文件,内存,或是网络连接。类似的,当程序需要写入数据的时候,就会开启一个通向目的地的流。这时候你就可以想象数据好像在这其中“流”动一样。
一般来说关于流的特性有下面几点:
- 先进先出:最先写入输出流的数据最先被输入流读取到。
- 顺序存取:可以一个接一个地往流中写入一串字节,读出时也将按写入顺序读取一串字节,不能随机访问中间的数据。(RandomAccessFile除外)
- 只读或只写:每个流只能是输入流或输出流的一种,不能同时具备两个功能,输入流只能进行读操作,对输出流只能进行写操作。在一个数据传输通道中,如果既要写入数据,又要读取数据,则要分别提供两个流。
虽然 IO 类的方法也很多,但核心的也就 2 个:read 和 write。
InputStream 类
int read():读取数据int read(byte b[], int off, int len):从第 off 位置开始读,读取 len 长度的字节,然后放入数组 b 中long skip(long n):跳过指定个数的字节int available():返回可读的字节数void close():关闭流,释放资源
OutputStream 类
void write(int b): 写入一个字节,虽然参数是一个 int 类型,但只有低 8 位才会写入,高 24 位会舍弃(这块后面再讲)void write(byte b[], int off, int len): 将数组 b 中的从 off 位置开始,长度为 len 的字节写入void flush(): 强制刷新,将缓冲区的数据写入void close():关闭流
Reader 类
int read():读取单个字符int read(char cbuf[], int off, int len):从第 off 位置开始读,读取 len 长度的字符,然后放入数组 b 中long skip(long n):跳过指定个数的字符int ready():是否可以读了void close():关闭流,释放资源
Writer 类
void write(int c): 写入一个字符void write( char cbuf[], int off, int len): 将数组 cbuf 中的从 off 位置开始,长度为 len 的字符写入void flush(): 强制刷新,将缓冲区的数据写入void close():关闭流
理解了上面这些方法,基本上 IO 的灵魂也就全部掌握了。
我们再以文件的字符流和字节流来做一下对比,代码差别很小。
// 字节流
try (FileInputStream fis = new FileInputStream("input.txt");
FileOutputStream fos = new FileOutputStream("output.txt")) {
byte[] buffer = new byte[1024];
int len;
while ((len = fis.read(buffer)) != -1) {
fos.write(buffer, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
// 字符流
try (FileReader fr = new FileReader("input.txt");
FileWriter fw = new FileWriter("output.txt")) {
char[] buffer = new char[1024];
int len;
while ((len = fr.read(buffer)) != -1) {
fw.write(buffer, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}操作对象划分
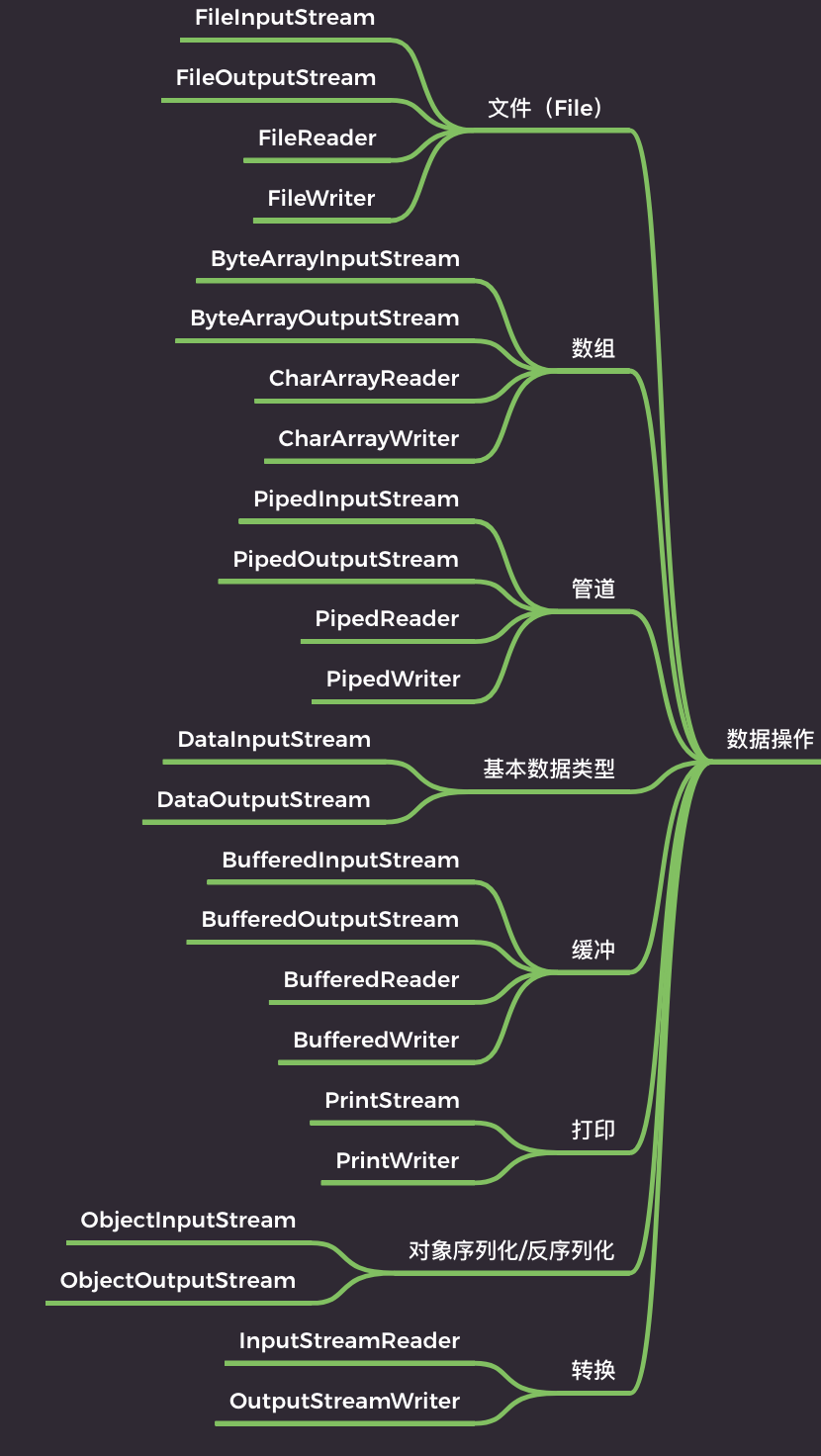
1.1)文件
文件流也就是直接操作文件的流,可以细分为字节流(FileInputStream 和 FileOuputStream)和字符流(FileReader 和 FileWriter)。
FileInputStream 的例子:
// 声明一个 int 类型的变量 b,用于存储读取到的字节
int b;
// 创建一个 FileInputStream 对象,用于读取文件 fis.txt 中的数据
FileInputStream fis1 = new FileInputStream("fis.txt");
// 循环读取文件中的数据
while ( ( b = fis1.read() ) != -1 ) {
// 将读取到的字节转换为对应的 ASCII 字符,并输出到控制台
System.out.println((char)b);
}
// 关闭 FileInputStream 对象,释放资源
fis1.close();FileOutputStream 的例子:
// 创建一个 FileOutputStream 对象,用于写入数据到文件 fos.txt 中
FileOutputStream fos = new FileOutputStream("fos.txt");
// 向文件中写入数据,这里写入的是字符串 "沉默王二" 对应的字节数组
fos.write("沉默王二".getBytes());
// 关闭 FileOutputStream 对象,释放资源
fos.close();FileReader 的例子:
// 声明一个 int 类型的变量 b,用于存储读取到的字符
int b = 0;
// 创建一个 FileReader 对象,用于读取文件 read.txt 中的数据
FileReader fileReader = new FileReader("read.txt");
// 循环读取文件中的数据
while ( ( b = fileReader.read() ) != -1 ) {
// 将读取到的字符强制转换为 char 类型,并输出到控制台
System.out.println((char)b);
}
// 关闭 FileReader 对象,释放资源
fileReader.close();FileWriter 的例子:
// 创建一个 FileWriter 对象,用于写入数据到文件 fw.txt 中
FileWriter fileWriter = new FileWriter("fw.txt");
// 将字符串 "沉默王二" 转换为字符数组
char[] chars = "沉默王二".toCharArray();
// 向文件中写入数据,这里写入的是 chars 数组中的所有字符
fileWriter.write(chars, 0, chars.length);
// 关闭 FileWriter 对象,释放资源
fileWriter.close();文件流还可以用于创建、删除、重命名文件等操作。FileOutputStream 和 FileWriter 构造函数的第二个参数可以指定是否追加数据到文件末尾。
1.3)管道
Java 中的管道和 Unix/Linux 中的管道不同,在 Unix/Linux 中,不同的进程之间可以通过管道来通信,但 Java 中,通信的双方必须在同一个进程中,也就是在同一个 JVM 中,管道为线程之间的通信提供了通信能力。
一个线程通过 PipedOutputStream 写入的数据可以被另外一个线程通过相关联的 PipedInputStream 读取出来。
// 创建一个 PipedOutputStream 对象和一个 PipedInputStream 对象
final PipedOutputStream pipedOutputStream = new PipedOutputStream();
final PipedInputStream pipedInputStream = new PipedInputStream(pipedOutputStream);
// 创建一个线程,向 PipedOutputStream 中写入数据
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
try {
// 将字符串 "沉默王二" 转换为字节数组,并写入到 PipedOutputStream 中
pipedOutputStream.write("沉默王二".getBytes(StandardCharsets.UTF_8));
// 关闭 PipedOutputStream,释放资源
pipedOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
});
// 创建一个线程,从 PipedInputStream 中读取数据并输出到控制台
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
try {
// 定义一个字节数组用于存储读取到的数据
byte[] flush = new byte[1024];
// 定义一个变量用于存储每次读取到的字节数
int len = 0;
// 循环读取字节数组中的数据,并输出到控制台
while (-1 != (len = pipedInputStream.read(flush))) {
// 将读取到的字节转换为对应的字符串,并输出到控制台
System.out.println(new String(flush, 0, len));
}
// 关闭 PipedInputStream,释放资源
pipedInputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
});
// 启动线程1和线程2
thread1.start();
thread2.start();使用管道流可以实现不同线程之间的数据传输,可以用于线程间的通信、数据的传递等。但是,管道流也有一些局限性,比如只能在同一个 JVM 中的线程之间使用,不能跨越不同的 JVM 进程。
1.5)缓冲
为了减少程序和硬盘的交互,提升程序的效率,就引入了缓冲流,也就是类名前缀带有 Buffer 的那些,比如说 BufferedInputStream、BufferedOutputStream、BufferedReader、BufferedWriter。
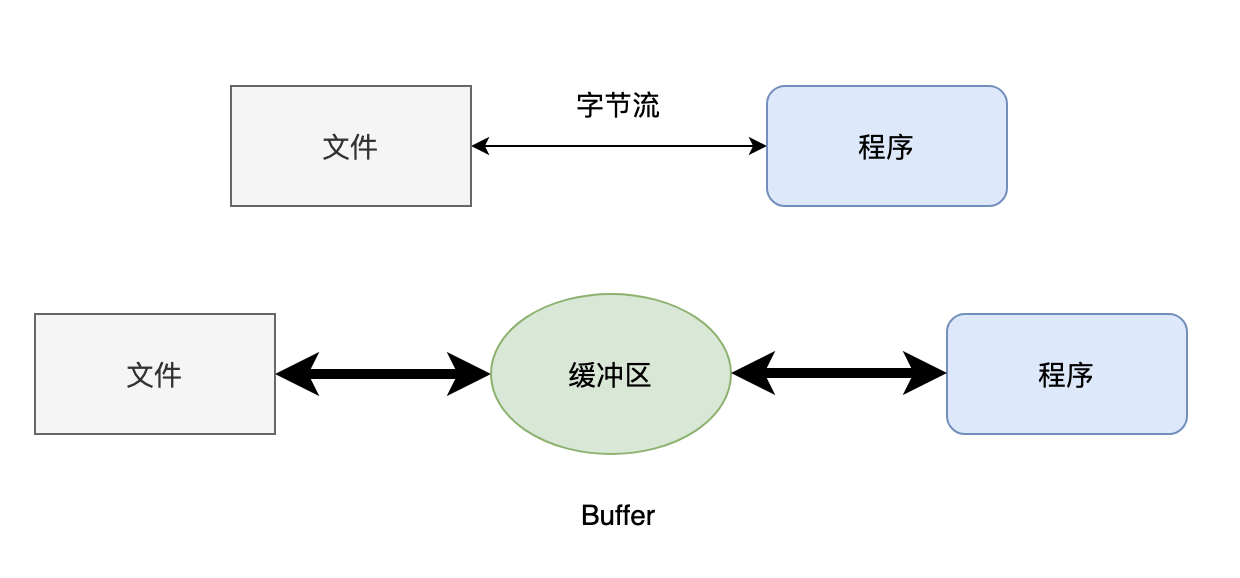
缓冲流在内存中设置了一个缓冲区,只有缓冲区存储了足够多的带操作的数据后,才会和内存或者硬盘进行交互。简单来说,就是一次多读/写点,少读/写几次,这样程序的性能就会提高。
以下是一个使用 BufferedInputStream 读取文件的示例代码:
// 创建一个 BufferedInputStream 对象,用于从文件中读取数据
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("data.txt"));
// 创建一个字节数组,作为缓存区
byte[] buffer = new byte[1024];
// 读取文件中的数据,并将其存储到缓存区中
int bytesRead;
while ( ( bytesRead = bis.read(buffer) ) != -1 ) {
// 对缓存区中的数据进行处理
// 这里只是简单地将读取到的字节数组转换为字符串并打印出来
System.out.println( new String(buffer, 0, bytesRead) );
}
// 关闭 BufferedInputStream,释放资源
bis.close();上述代码中,首先创建了一个 BufferedInputStream 对象,用于从文件中读取数据。然后创建了一个字节数组作为缓存区,每次读取数据时将数据存储到缓存区中。读取数据的过程是通过 while 循环实现的,每次读取数据后对缓存区中的数据进行处理。最后关闭 BufferedInputStream,释放资源。
以下是一个使用 BufferedOutputStream 写入文件的示例代码:
// 创建一个 BufferedOutputStream 对象,用于将数据写入到文件中
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("data.txt"));
// 创建一个字节数组,作为缓存区
byte[] buffer = new byte[1024];
// 将数据写入到文件中
String data = "沉默王二是个大傻子!";
buffer = data.getBytes();
bos.write(buffer);
// 刷新缓存区,将缓存区中的数据写入到文件中
bos.flush();
// 关闭 BufferedOutputStream,释放资源
bos.close();上述代码中,首先创建了一个 BufferedOutputStream 对象,用于将数据写入到文件中。然后创建了一个字节数组作为缓存区,将数据写入到缓存区中。写入数据的过程是通过 write() 方法实现的,将字节数组作为参数传递给 write() 方法即可。
最后,通过 flush() 方法将缓存区中的数据写入到文件中。在写入数据时,由于使用了 BufferedOutputStream,数据会先被写入到缓存区中,只有在缓存区被填满或者调用了 flush() 方法时才会将缓存区中的数据写入到文件中。
以下是一个使用 BufferedReader 读取文件的示例代码:
// 创建一个 BufferedReader 对象,用于从文件中读取数据
BufferedReader br = new BufferedReader(new FileReader("data.txt"));
// 读取文件中的数据,并将其存储到字符串中
String line;
while ( ( line = br.readLine() ) != null ) {
// 对读取到的数据进行处理
// 这里只是简单地将读取到的每一行字符串打印出来
System.out.println(line);
}
// 关闭 BufferedReader,释放资源
br.close();上述代码中,首先创建了一个 BufferedReader 对象,用于从文件中读取数据。然后使用 readLine() 方法读取文件中的数据,每次读取一行数据并将其存储到一个字符串中。读取数据的过程是通过 while 循环实现的。
以下是一个使用 BufferedWriter 写入文件的示例代码:
// 创建一个 BufferedWriter 对象,用于将数据写入到文件中
BufferedWriter bw = new BufferedWriter(new FileWriter("data.txt"));
// 将数据写入到文件中
String data = "沉默王二,真帅气";
bw.write(data);
// 刷新缓存区,将缓存区中的数据写入到文件中
bw.flush();
// 关闭 BufferedWriter,释放资源
bw.close();上述代码中,首先创建了一个 BufferedWriter 对象,用于将数据写入到文件中。然后使用 write() 方法将数据写入到缓存区中,写入数据的过程和使用 FileWriter 类似。需要注意的是,使用 BufferedWriter 写入数据时,数据会先被写入到缓存区中,只有在缓存区被填满或者调用了 flush() 方法时才会将缓存区中的数据写入到文件中。
最后,通过 flush() 方法将缓存区中的数据写入到文件中,并通过 close() 方法关闭 BufferedWriter,释放资源。
使用缓冲流可以提高读写效率,减少了频繁的读写磁盘或网络的次数,从而提高了程序的性能。但是,在使用缓冲流时需要注意缓冲区的大小和清空缓冲区的时机,以避免数据丢失或不完整的问题。
1.6)打印
Java 的打印流是一组用于打印输出数据的类,包括 PrintStream 和 PrintWriter 两个类。
System.out 其实返回的就是一个 PrintStream 对象,可以用来打印各式各样的对象。
System.out.println("沉默王二是真的二!");PrintStream 最终输出的是字节数据,而 PrintWriter 则是扩展了 Writer 接口,所以它的 print()/println() 方法最终输出的是字符数据。使用上几乎和 PrintStream 一模一样。
StringWriter buffer = new StringWriter();
try (PrintWriter pw = new PrintWriter(buffer)) {
pw.println("沉默王二");
}
System.out.println(buffer.toString());
1.7)序列化
序列化本质上是将一个 Java 对象转成字节数组,然后可以将其保存到文件中,或者通过网络传输到远程。
2)文件流
或者叫目录)后者是文件(file),File 类就是用来操作它俩的。
2.1)File 构造方法
在 Java 中,一切皆是对象,File 类也不例外,不论是哪个对象都应该从该对象的构造说起,所以我们来分析分析File类的构造方法。
比较常用的构造方法有三个:
1、 File(String pathname) :通过给定的路径来创建新的 File 实例。
2、 File(String parent, String child) :从父路径(字符串)和子路径创建新的 File 实例。
3、 File(File parent, String child) :从父路径(File)和子路径名字符串创建新的 File 实例。
注意,macOS 路径使用正斜杠(/)作为路径分隔符,而 Windows 路径使用反斜杠(\)作为路径分隔符。所以在遇到路径分隔符的时候,不要直接去写/或者\。
Java 中提供了一个跨平台的方法来获取路径分隔符,即使用 File.separator,这个属性会根据操作系统自动返回正确的路径分隔符。
File 类的注意点:
- 一个 File 对象代表硬盘中实际存在的一个文件或者目录。
- File 类的构造方法不会检验这个文件或目录是否真实存在,因此无论该路径下是否存在文件或者目录,都不影响 File 对象的创建。
2.2)File 常用方法
File 的常用方法主要分为获取功能、获取绝对路径和相对路径、判断功能、创建删除功能的方法。
2.2.1)获取功能的方法
1、getAbsolutePath() :返回此 File 的绝对路径。
2、getPath() :结果和 getAbsolutePath 一致。
3、getName() :返回文件名或目录名。
4、length() :返回文件长度,以字节为单位。
2.2.3)判断功能的方法
1、 exists() :判断文件或目录是否存在。
2、 isDirectory() :判断是否为目录。
3、isFile() :判断是否为文件。
2.2.4)创建、删除功能的方法
createNewFile():文件不存在,创建一个新的空文件并返回true,文件存在,不创建文件并返回false。delete():删除文件或目录。如果是目录,只有目录为空才能删除。mkdir():只能创建一级目录,如果父目录不存在,则创建失败。返回 true 表示创建成功,返回 false 表示创建失败。mkdirs():可以创建多级目录,如果父目录不存在,则会一并创建。返回 true 表示创建成功,返回 false 表示创建失败或目录已经存在。
开发中一般用mkdirs();
方法测试,代码如下:
// 创建文件
File file = new File("/Users/username/example/test.txt");
if (file.createNewFile()) {
System.out.println("创建文件成功:" + file.getAbsolutePath());
} else {
System.out.println("创建文件失败:" + file.getAbsolutePath());
}
// 删除文件
if (file.delete()) {
System.out.println("删除文件成功:" + file.getAbsolutePath());
} else {
System.out.println("删除文件失败:" + file.getAbsolutePath());
}
// 创建多级目录
File directory = new File("/Users/username/example/subdir1/subdir2");
if (directory.mkdirs()) {
System.out.println("创建目录成功:" + directory.getAbsolutePath());
} else {
System.out.println("创建目录失败:" + directory.getAbsolutePath());
} 2.2.5)目录的遍历
String[] list():返回一个 String 数组,表示该 File 目录中的所有子文件或目录。File[] listFiles():返回一个 File 数组,表示该 File 目录中的所有的子文件或目录。
File directory = new File("/Users/itwanger/Documents/Github/paicoding");
// 列出目录下的文件名
String[] files = directory.list();
System.out.println("目录下的文件名:");
for (String file : files) {
System.out.println(file);
}
// 列出目录下的文件和子目录
File[] filesAndDirs = directory.listFiles();
System.out.println("目录下的文件和子目录:");
for (File fileOrDir : filesAndDirs) {
if (fileOrDir.isFile()) {
System.out.println("文件:" + fileOrDir.getName());
} else if (fileOrDir.isDirectory()) {
System.out.println("目录:" + fileOrDir.getName());
}
}listFiles在获取指定目录下的文件或者子目录时必须满足下面两个条件:
- 指定的目录必须存在
- 指定的必须是目录。否则容易引发 NullPointerException 异常
2.2.6)递归遍历
public static void main(String[] args) {
File directory = new File("/Users/itwanger/Documents/Github/paicoding");
// 递归遍历目录下的文件和子目录
traverseDirectory(directory);
}
public static void traverseDirectory(File directory) {
// 列出目录下的所有文件和子目录
File[] filesAndDirs = directory.listFiles();
// 遍历每个文件和子目录
for (File fileOrDir : filesAndDirs) {
if (fileOrDir.isFile()) {
// 如果是文件,输出文件名
System.out.println("文件:" + fileOrDir.getName());
} else if (fileOrDir.isDirectory()) {
// 如果是目录,递归遍历子目录
System.out.println("目录:" + fileOrDir.getName());
traverseDirectory(fileOrDir);
}
}
}2.2.7)RandomAccessFile类
RandomAccessFile类是一个功能独特且强大的文件操作工具,它支持对文件的随机读写,这在处理特定需求时非常高效。下面我将为你详细解析这个类。🔍 核心特性与工作模式
RandomAccessFile最大的特点是支持随机访问。它通过一个文件指针来记录当前位置,你可以使用 seek(long pos)方法自由地将指针移动到文件的任何位置进行读写,这与只能顺序读写的传统IO流截然不同。DataInput和DataOutput接口,这意味着它可以方便地读写各种基本数据类型(如int, double, boolean)和字符串。-
"r":只读模式。 -
"rw":读写模式。如果文件不存在,会尝试创建。 -
"rwd":读写模式,并且对文件内容的更新会同步写入底层存储设备(强制刷盘内容)。 -
"rws":读写模式,在"rwd"的基础上,对文件元数据(如最后修改时间)的更新也会同步(强制刷盘内容和元数据)。
📝 主要方法与基本用法
RandomAccessFile提供了丰富的方法,核心包括:-
指针控制:
long getFilePointer()获取当前指针位置;void seek(long pos)设置指针位置。 -
读取操作:提供了一系列
read方法,如read(),read(byte[] b),readInt(),readUTF()等。 -
写入操作:对应了一系列
write方法,如write(int b),write(byte[] b),writeDouble(),writeUTF(String str)等。 -
其他:
long length()获取文件长度;void setLength(long newLength)设置文件长度。
💡 典型应用场景与技巧
-
大文件的分块处理与断点续传这是
RandomAccessFile的经典应用场景。在多线程下载或处理大文件时,可以将文件分成若干块,每个线程负责读写不同的块(通过seek定位到指定偏移量),最后合并。这也天然支持了断点续传,因为可以记录每个块已传输的位置。 -
日志文件的追加使用
"rw"模式打开日志文件,通过seek(raf.length())将指针移动到文件末尾,即可轻松追加新日志内容。 -
在指定位置插入数据(而非覆盖)需要注意的是,如果在文件中间直接写入,会覆盖原有内容。如果希望实现“插入”效果,一个常见的技巧是使用临时文件或缓冲区:
-
将插入点之后的内容先读取出来并暂存。
-
在插入点写入新的数据。
-
将暂存的内容追加到新数据之后。
-
⚠️ 重要注意事项与面试视角
-
资源管理:
RandomAccessFile也是一种资源,使用后必须调用close()方法关闭,以防止资源泄漏。推荐使用 try-with-resources 语法来自动管理。 -
性能考量:对于大文件的频繁随机访问,Java NIO包中的
FileChannel配合MappedByteBuffer(内存映射文件)通常能提供更高的性能,因为它允许将文件直接映射到内存中进行操作。在面试中,如果你能主动对比这两者,会是一个加分项。 -
面试考察重点:
-
频率:
RandomAccessFile属于Java IO中频次中等但重要的考点,常出现在对文件操作有特定要求的场景讨论中。 -
考察角度:
-
与普通IO流的根本区别是什么?(随机访问 vs. 顺序访问)
-
"rwd"和"rws"模式的区别?(同步更新的粒度不同) -
如何实现向文件指定位置插入数据而不覆盖?(考察对文件操作原理的理解)
-
和NIO的
MappedByteBuffer相比有何优缺点?(RandomAccessFile更简单易用,MappedByteBuffer性能更高,但更复杂)
-
-
2.2.8)Apache FileUtils 类和Hutool FileUtil 类
FileUtils和 Hutool 的 FileUtil都是 Java 中用于简化文件操作的优秀工具类,它们能帮你避免编写冗长的底层 IO 代码。下面这个表格可以让你快速把握它们的核心特点与常见用法。|
特性对比
|
Apache Commons IO - FileUtils
|
Hutool - FileUtil
|
|---|---|---|
|
项目背景
|
Apache 软件基金会开源项目,历史悠久、稳定
|
国产工具库,中文文档友好,API 设计更符合国人习惯
|
|
核心定位
|
提供稳健、全面的文件与目录操作
|
提供简洁、高效且功能丰富的文件 IO 封装
|
|
设计哲学
|
功能细致,方法参数明确,逻辑严谨
|
追求极简,一行代码完成常见操作,自动处理异常和资源
|
|
特色功能
|
强大的文件过滤与遍历、内容比较、校验和计算
|
内置路径安全处理、文件监控、简易的压缩/解压
|
🔧 FileUtils 的常见用法
FileUtils功能非常全面,以下是几个核心场景的用法。-
读写文件内容:它提供了多种读写方式,可以轻松地将整个文件内容读入字符串或集合,也支持便捷的写入操作。
-
操作目录与文件:可以方便地复制、删除、清空目录,以及获取目录大小。
-
高级文件操作与过滤:支持复杂的文件遍历和内容比较。
🚀 FileUtil 的常见用法
FileUtil以其极简的 API 设计著称,许多操作只需一行代码。-
基础文件操作:文件创建、删除、复制、移动等操作非常简洁。
-
读写操作的简化与增强:Hutool 还提供了
FileReader和FileWriter类,让读写更专业。 -
路径安全与高级工具:内置了路径安全处理和文件监控等实用功能。
💡 如何选择?
-
选择 Apache Commons IO
FileUtils的情况:-
项目已经依赖了 Apache Commons 系列库,希望保持技术栈统一。
-
需要处理非常复杂的文件过滤、遍历场景。
-
项目对稳定性有极高要求,倾向于使用经过长期工业验证的库。
-
-
选择 Hutool
FileUtil的情况:-
追求极致的开发效率,希望用最少的代码完成工作。
-
团队对中文文档有偏好,或团队成员水平不一,Hutool 的低学习成本是巨大优势。
-
需要一些开箱即用的高级功能,如文件监控、简易压缩解压等。
-
💎 总结与面试视角
FileUtils像一位经验丰富、一丝不苟的老师傅,功能全面可靠;而 FileUtil则像一位贴心能干的助手,总能用最省力的方式帮你搞定问题。-
底层原理:比如这些工具方法是如何处理异常和资源关闭的,与原生
Files类的区别。 -
设计模式:能否看出其中运用的像策略模式(各种文件过滤器)、装饰器模式等。
-
场景选择:在什么业务场景下会优先选择哪一个,这能体现你的技术选型能力。
3)字节流
3.1)FileOutputStream类
使用示例
FileOutputStream fos = null;
try {
fos = new FileOutputStream("example.txt");
fos.write("沉默王二".getBytes());
} catch (IOException e) {
e.printStackTrace();
} finally {
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
写入指定长度字节数组:write(byte[] b, int off, int len),代码示例:
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt");
// 字符串转换为字节数组
byte[] b = "abcde".getBytes();
// 从索引2开始,2个字节。索引2是c,两个字节,也就是cd。
fos.write(b,2,2);
// 关闭资源
fos.close();
实现数据追加代码如下:
// 使用文件名称创建流对象
FileOutputStream fos = new FileOutputStream("fos.txt",true);
// 字符串转换为字节数组
byte[] b = "abcde".getBytes();
// 写出从索引2开始,2个字节。索引2是c,两个字节,也就是cd。
fos.write(b);
// 关闭资源
fos.close();在 Windows 系统中,换行符号是\r\n,具体代码如下:
String filename = "example.txt";
FileOutputStream fos = new FileOutputStream(filename, true); // 追加模式
String content = "沉默王二\r\n"; // 使用回车符和换行符的组合
fos.write(content.getBytes());
fos.close();
3.2)FileInputStream类
FileInputStream类读取字节数据
①、读取字节:read()方法会读取一个字节并返回其整数表示。如果已经到达文件的末尾,则返回 -1。如果在读取时发生错误,则会抛出 IOException 异常。
代码示例如下:
// 创建一个 FileInputStream 对象
FileInputStream fis = new FileInputStream("test.txt");
// 读取文件内容
int data;
while ( ( data = fis.read() ) != -1 ) {
System.out.print( (char) data );
}
// 关闭输入流
fis.close();②、使用字节数组读取:read(byte[] b) 方法会从输入流中最多读取 b.length 个字节,并将它们存储到缓冲区数组 b 中。
代码示例如下:
// 创建一个 FileInputStream 对象
FileInputStream fis = new FileInputStream("test.txt");
// 读取文件内容到缓冲区
byte[] buffer = new byte[1024];
int count;
while ( ( count = fis.read(buffer) ) != -1 ) {
System.out.println(new String(buffer, 0, count));
}
// 关闭输入流
fis.close();
③把图片信息读入到字节输入流中,再通过字节输出流写入到文件中
// 创建一个 FileInputStream 对象以读取原始图片文件
FileInputStream fis = new FileInputStream("original.jpg");
// 创建一个 FileOutputStream 对象以写入复制后的图片文件
FileOutputStream fos = new FileOutputStream("copy.jpg");
// 创建一个缓冲区数组以存储读取的数据
byte[] buffer = new byte[1024];
int count;
// 读取原始图片文件并将数据写入复制后的图片文件
while ((count = fis.read(buffer)) != -1) {
fos.write(buffer, 0, count);
}
// 关闭输入流和输出流
fis.close();
fos.close();
3.3)字符流
当我们使用默认的字符编码(见上例)读取一个包含中文字符的文本文件时,就会出现乱码。因为默认的字符编码通常是 ASCII 编码,它只能表示英文字符,而不能正确地解析中文字符。
//FileInputStream为操作文件的字符输入流
FileInputStream inputStream = new FileInputStream("a.txt");//内容为“沉默王二是傻 X”
int len;
while ( ( len=inputStream.read() ) != -1 ){
System.out.print((char)len);//输出结果乱码
}
那使用字节流该如何正确地读出中文呢
try (FileInputStream fis = new FileInputStream("a.txt")) {
byte[] bytes = new byte[1024];
int len;
while ( ( len = fis.read(bytes) ) != -1 ) {
System.out.print( new String(bytes, 0, len) );
}
}
3.3.1)FileReader类
读取字符。read方法,每次可以读取一个字符,返回读取的字符(转为 int 类型),当读取到文件末尾时,返回-1。代码示例如下:
// 使用文件名称创建流对象
FileReader fr = new FileReader("abc.txt");
// 定义变量,保存数据
int b;
// 循环读取
while ( ( b = fr.read() ) != -1 ) {
System.out.println((char)b);
}
// 关闭资源
fr.close();
读取指定长度的字符。read(char[] cbuf, int off, int len),并将其存储到字符数组中。其中,cbuf 表示存储读取结果的字符数组,off 表示存储结果的起始位置,len 表示要读取的字符数。代码示例如下:
File textFile = new File("docs/约定.md");
// 给一个 FileReader 的示例
// try-with-resources FileReader
try(FileReader reader = new FileReader(textFile);) {
// read(char[] cbuf)
char[] buffer = new char[1024];
int len;
while ( ( len = reader.read(buffer, 0, buffer.length) ) != -1 ) {
System.out.print( new String(buffer, 0, len) );
}
}
3.3.2)FileWriter类
①写入字符:write(int b) 方法,每次可以写出一个字符,代码示例如下:
FileWriter fw = null;
try {
fw = new FileWriter("output.txt");
fw.write(72); // 写入字符'H'的ASCII码
fw.write(101); // 写入字符'e'的ASCII码
fw.write(108); // 写入字符'l'的ASCII码
fw.write(108); // 写入字符'l'的ASCII码
fw.write(111); // 写入字符'o'的ASCII码
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fw != null) {
fw.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
②写入字符数组:write(char[] cbuf) 方法,将指定字符数组写入输出流。代码示例如下:
FileWriter fw = null;
try {
fw = new FileWriter("output.txt");
char[] chars = {'H', 'e', 'l', 'l', 'o'};
fw.write(chars); // 将字符数组写入文件
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fw != null) {
fw.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
③写入指定字符数组:write(char[] cbuf, int off, int len) 方法,将指定字符数组的一部分写入输出流。代码示例如下
fw = new FileWriter("output.txt");
char[] chars = {'H', 'e', 'l', 'l', 'o', ',', ' ', 'W', 'o', 'r', 'l', 'd', '!'};
fw.write(chars, 0, 5); // 将字符数组的前 5 个字符写入文件
④写入字符串:write(String str) 方法,将指定字符串写入输出流。
fw = new FileWriter("output.txt");
String str = "沉默王二";
fw.write(str); // 将字符串写入文件
⑤写入指定字符串:write(String str, int off, int len) 方法,将指定字符串的一部分写入输出流。代码示例如下(try-with-resources形式):
String str = "沉默王二真的帅啊!";
try (FileWriter fw = new FileWriter("output.txt")) {
fw.write(str, 0, 5); // 将字符串的前 5 个字符写入文件
} catch (IOException e) {
e.printStackTrace();
}
文本文件复制
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class CopyFile {
public static void main(String[] args) throws IOException {
//创建输入流对象
FileReader fr=new FileReader("aa.txt");//文件不存在会抛出java.io.FileNotFoundException
//创建输出流对象
FileWriter fw=new FileWriter("copyaa.txt");
/*创建输出流做的工作:
* 1、调用系统资源创建了一个文件
* 2、创建输出流对象
* 3、把输出流对象指向文件
* */
//文本文件复制,一次读一个字符
copyMethod1(fr, fw);
//文本文件复制,一次读一个字符数组
copyMethod2(fr, fw);
fr.close();
fw.close();
}
public static void copyMethod1(FileReader fr, FileWriter fw) throws IOException {
int ch;
while( ( ch=fr.read() ) != -1 ) {//读数据
fw.write(ch);//写数据
}
fw.flush();
}
public static void copyMethod2(FileReader fr, FileWriter fw) throws IOException {
char chs[] = new char[1024];
int len = 0;
while( ( len=fr.read(chs) ) != -1 ) {//读数据
fw.write(chs,0,len);//写数据
}
fw.flush();
}
}
3.4)缓冲流
传统的 Java IO 是阻塞模式的,它的工作状态就是“读/写,等待,读/写,等待。。。。。。”
字节缓冲流解决的就是这个问题:一次多读点多写点,减少读写的频率,用空间换时间。
- 减少系统调用次数:在使用字节缓冲流时,数据不是立即写入磁盘或输出流,而是先写入缓冲区,当缓冲区满时再一次性写入磁盘或输出流。这样可以减少系统调用的次数,从而提高 I/O 操作的效率。
- 减少磁盘读写次数:在使用字节缓冲流时,当需要读取数据时,缓冲流会先从缓冲区中读取数据,如果缓冲区中没有足够的数据,则会一次性从磁盘或输入流中读取一定量的数据。同样地,当需要写入数据时,缓冲流会先将数据写入缓冲区,如果缓冲区满了,则会一次性将缓冲区中的数据写入磁盘或输出流。这样可以减少磁盘读写的次数,从而提高 I/O 操作的效率。
- 提高数据传输效率:在使用字节缓冲流时,由于数据是以块的形式进行传输,因此可以减少数据传输的次数,从而提高数据传输的效率。
3.5)转换流InputStreamReader
当使用不同的编码方式读取或者写入文件时,就会出现乱码问题,来看示例。
String s = "沉默王二!";
try {
// 将字符串按GBK编码方式保存到文件中
OutputStreamWriter osw = new OutputStreamWriter(
new FileOutputStream("logs/test_utf8.txt"), "GBK");
osw.write(s);
osw.close();
FileReader fr = new FileReader("logs/test_utf8.txt");
int a;
while ((a = fr.read()) != -1) {
System.out.print((char)a);
}
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
首先定义了一个包含中文字符的字符串,然后将该字符串按 GBK 编码方式保存到文件中,接着将文件按默认编码方式(UTF-8)读取,并显示内容。此时就会出现乱码问题,显示为“��Ĭ������”。
这是因为文件中的 GBK 编码的字符在使用 UTF-8 编码方式解析时无法正确解析,从而导致出现乱码问题。
java.io.InputStreamReader 是 Reader 类的子类。它的作用是将字节流(InputStream)转换为字符流(Reader),同时支持指定的字符集编码方式,从而实现字符流与字节流之间的转换。
String s = "沉默王二!";
try {
// 将字符串按GBK编码方式保存到文件中
OutputStreamWriter outUtf8 = new OutputStreamWriter(
new FileOutputStream("logs/test_utf8.txt"), "GBK");
outUtf8.write(s);
outUtf8.close();
// 将字节流转换为字符流,使用GBK编码方式
InputStreamReader isr = new InputStreamReader(new FileInputStream("logs/test_utf8.txt"), "GBK");
// 读取字符流
int c;
while ( ( c = isr.read() ) != -1 ) {
System.out.print((char) c);
}
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
java.io.OutputStreamWriter 是 Writer 的子类,字面看容易误以为是转为字符流,其实是将字符流转换为字节流,是字符流到字节流的桥梁。
OutputStreamWriter(OutputStream in): 创建一个使用默认字符集的字符流。OutputStreamWriter(OutputStream in, String charsetName):创建一个指定字符集的字符流。
通常为了提高读写效率,我们会在转换流上再加一层缓冲流,来看代码示例:
try {
// 从文件读取字节流,使用UTF-8编码方式
FileInputStream fis = new FileInputStream("test.txt");
// 将字节流转换为字符流,使用UTF-8编码方式
InputStreamReader isr = new InputStreamReader(fis, "UTF-8");
// 使用缓冲流包装字符流,提高读取效率
BufferedReader br = new BufferedReader(isr);
// 创建输出流,使用UTF-8编码方式
FileOutputStream fos = new FileOutputStream("output.txt");
// 将输出流包装为转换流,使用UTF-8编码方式
OutputStreamWriter osw = new OutputStreamWriter(fos, "UTF-8");
// 使用缓冲流包装转换流,提高写入效率
BufferedWriter bw = new BufferedWriter(osw);
// 读取输入文件的每一行,写入到输出文件中
String line;
while ( ( line = br.readLine() ) != null ) {
bw.write(line);
bw.newLine(); // 每行结束后写入一个换行符
}
// 关闭流
br.close();
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
总结
InputStreamReader 和 OutputStreamWriter 是将字节流转换为字符流或者将字符流转换为字节流。通常用于解决字节流和字符流之间的转换问题,可以将字节流以指定的字符集编码方式转换为字符流,或者将字符流以指定的字符集编码方式转换为字节流。
InputStreamReader 类的常用方法包括:
read():从输入流中读取一个字符的数据。read(char[] cbuf, int off, int len):从输入流中读取 len 个字符的数据到指定的字符数组 cbuf 中,从 off 位置开始存放。ready():返回此流是否已准备好读取。close():关闭输入流。
OutputStreamWriter 类的常用方法包括:
write(int c):向输出流中写入一个字符的数据。write(char[] cbuf, int off, int len):向输出流中写入指定字符数组 cbuf 中的 len 个字符,从 off 位置开始。flush():将缓冲区的数据写入输出流中。close():关闭输出流。
在使用转换流时,需要指定正确的字符集编码方式,否则可能会导致数据读取或写入出现乱码。
3.6)序列流(序列化和反序列化)
java.io.Serializable。一个类只需实现此接口(不含任何方法),即表明其对象可被序列化。Java通过 ObjectOutputStream.writeObject()和 ObjectInputStream.readObject()方法完成序列化与反序列化。
3.6.1)OutputStream 类
java.io.ObjectOutputStream 继承自 OutputStream 类,因此可以将序列化后的字节序列写入到文件、网络等输出流中。
来看 ObjectOutputStream 的构造方法: ObjectOutputStream(OutputStream out)
该构造方法接收一个 OutputStream 对象作为参数,用于将序列化后的字节序列输出到指定的输出流中。例如:
FileOutputStream fos = new FileOutputStream("file.txt");
ObjectOutputStream oos = new ObjectOutputStream(fos);一个对象要想序列化,必须满足两个条件:
- 该类必须实现
java.io.Serializable接口,否则会抛出NotSerializableException。 - 该类的所有字段都必须是可序列化的。如果一个字段不需要序列化,则需要使用
transient关键字进行修饰。
使用示例如下:
public class Employee implements Serializable {
public String name;
public String address;
public transient int age; // transient瞬态修饰成员,不会被序列化
}
writeObject (Object obj) 方法,该方法是 ObjectOutputStream 类中用于将对象序列化成字节序列并输出到输出流中的方法,可以处理对象之间的引用关系、继承关系、静态字段和 transient 字段。
首先创建了一个 Person 对象,然后使用 FileOutputStream 和 ObjectOutputStream 将 Person 对象序列化并输出到 person.dat 文件中。在 Person 类中,实现了 Serializable 接口,表示该类可以进行对象序列化。
public class ObjectOutputStreamDemo {
public static void main(String[] args) {
Person person = new Person("沉默王二", 20);
try {
FileOutputStream fos = new FileOutputStream("logs/person.dat");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(person);
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
class Person implements Serializable {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {return name;}
public int getAge() {return age;}
}
3.6.2)ObjectInputStream
ObjectInputStream 可以读取 ObjectOutputStream 写入的字节流,并将其反序列化为相应的对象(包含对象的数据、对象的类型和对象中存储的属性等信息)。
说简单点就是,序列化之前是什么样子,反序列化后就是什么样子。
来看一下构造方法:ObjectInputStream(InputStream in) : 创建一个指定 InputStream 的 ObjectInputStream。
其中,ObjectInputStream 的 readObject 方法用来读取指定文件中的对象,示例如下:
首先指定了待反序列化的文件名(前面通过 ObjectOutputStream 序列化后的文件),然后创建了一个 FileInputStream 对象和一个 ObjectInputStream 对象。接着我们调用 ObjectInputStream 的 readObject 方法来读取指定文件中的对象,并将其强制转换为 Person 类型。最后我们打印了反序列化后的对象信息。
String filename = "logs/person.dat"; // 待反序列化的文件名
try ( FileInputStream fis = new FileInputStream(filename);
ObjectInputStream ois = new ObjectInputStream(fis) ) {
// 从指定的文件输入流中读取对象并反序列化
Object obj = ois.readObject();
// 将反序列化后的对象强制转换为指定类型
Person p = (Person) obj;
// 打印反序列化后的对象信息
System.out.println("Deserialized Object: " + p);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
3.6.3)Kryo
实际开发中,很少使用 JDK 自带的序列化和反序列化,这是因为:
- 可移植性差:Java 特有的,无法跨语言进行序列化和反序列化。
- 性能差:序列化后的字节体积大,增加了传输/保存成本。
- 安全问题:攻击者可以通过构造恶意数据来实现远程代码执行,从而对系统造成严重的安全威胁。相关阅读:Java 反序列化漏洞之殇 。
Kryo 是一个优秀的 Java 序列化和反序列化库,具有高性能、高效率和易于使用和扩展等特点,有效地解决了 JDK 自带的序列化机制的痛点。
Input和 Output类是 Kryo 框架中进行 IO 操作(即数据写入和读取)的核心工具。下面这个表格能帮你快速把握它们的分工:|
特性
|
Output 类
|
Input 类
|
|---|---|---|
|
角色
|
序列化输出通道
|
反序列化输入通道
|
|
功能
|
将对象序列化后的字节数据写出
|
从源中读取字节数据以进行反序列化
|
|
目标类型
|
OutputStream(如 FileOutputStream) 或 byte[] |
InputStream(如 FileInputStream) 或 byte[] |
|
缓冲机制
|
内部有缓冲区,满时自动刷新到目标流
|
内部有缓冲区,从源流预读数据以提高效率
|
|
线程安全
|
非线程安全
|
非线程安全
|
🔧 核心工作流程详解
-
序列化与 Output当你调用
kryo.writeObject(output, obj)时,Kryo 会执行以下步骤:-
序列化:Kryo 框架将
obj对象转换(序列化)成二进制字节数据。 -
缓冲写入:这些字节数据首先被写入到
Output对象内部的字节数组缓冲区中。 -
输出到目标:当缓冲区满了,或者你主动调用
output.close()或output.flush()时,缓冲区内的数据会被一次性写入到Output所关联的最终目标(比如代码中的FileOutputStream,即文件kryo.bin中)。使用缓冲区是为了减少直接操作磁盘或网络的次数,从而显著提升效率。
-
-
反序列化与 Input当你调用
kryo.readObject(input, KryoParam.class)时,过程正好相反:-
从源读取:
Input对象从其关联的源(如代码中的FileInputStream)读取二进制字节数据到自己的内部缓冲区。 -
缓冲与提供:Kryo 框架从
Input对象的缓冲区中获取这些字节数据。 -
反序列化:Kryo 根据字节数据和提供的类类型 (
KryoParam.class),将数据重新构建(反序列化)成一个新的 Java 对象。
-
💡 关键使用注意事项
-
资源管理:
Input和Output本质上是数据通道,并非数据源或目的地本身。它们需要与具体的InputStream/OutputStream或byte[]绑定才能工作。 -
及时关闭:就像代码中做的那样,使用完毕后务必调用
close()方法。这不仅能确保所有缓冲数据被正确写入和资源被释放,在某些情况下(如文件操作、网络传输)更是防止资源泄漏的关键步骤。 -
线程安全:
Kryo、Input和Output实例都是线程不安全的。如果在多线程环境中使用,需要为每个线程创建独立的实例,或通过ThreadLocal、对象池(Pool)等技术来管理。
使用示例:
第一步,在 pom.xml 中引入依赖。
<!-- 引入 Kryo 序列化工具 -->
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.4.0</version>
</dependency>第二步,创建一个 Kryo 对象,并使用 register() 方法将对象进行注册。然后,使用 writeObject() 方法将 Java 对象序列化为二进制流,再使用 readObject() 方法将二进制流反序列化为 Java 对象。最后,输出反序列化后的 Java 对象。
public class KryoDemo {
public static void main(String[] args) throws FileNotFoundException {
Kryo kryo = new Kryo();
kryo.register(KryoParam.class);
KryoParam obj = new KryoParam("沉默王二", 123);
Output output = new Output(new FileOutputStream("logs/kryo.bin"));
kryo.writeObject(output, obj);
output.close();
Input input = new Input(new FileInputStream("logs/kryo.bin"));
KryoParam obj2 = kryo.readObject(input, KryoParam.class);
System.out.println(obj2);
input.close();
}
}
class KryoParam {
private String name;
private int age;
public KryoParam() {}
public KryoParam(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {return name;}
public void setName(String name) {this.name = name;}
public int getAge() {return age;}
public void setAge(int age) {this.age = age;}
@Override
public String toString() {
return "KryoParam{" +
"name='" + name + '\'' +
", age=" + age + '}';
}
}
3.6.4)Serializbale 接口
Serializable 接口之所以定义为空,是因为它只起到了一个标识的作用,告诉程序实现了它的对象是可以被序列化的,但真正序列化和反序列化的操作并不需要它来完成。
static 和 transient 修饰的字段是不会被序列化的。
class Wanger implements Serializable {
private static final long serialVersionUID = -2095916884810199532L;
private String name;
private int age;
public static String pre = "沉默";
transient String meizi = "王三";
@Override
public String toString() {
return "Wanger{" + "name=" + name + ",age=" + age + ",pre=" + pre + ",meizi=" + meizi + "}";
}
}
在测试类中打印序列化前和反序列化后的对象,并在序列化后和反序列化前改变 static 字段的值。具体代码如下:
// 初始化
Wanger wanger = new Wanger();
wanger.setName("王二");
wanger.setAge(18);
System.out.println(wanger);
// 把对象写到文件中
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("chenmo"));){
oos.writeObject(wanger);
} catch (IOException e) {
e.printStackTrace();
}
// 改变 static 字段的值
Wanger.pre ="不沉默";
// 从文件中读出对象
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream(new File("chenmo")));){
Wanger wanger1 = (Wanger) ois.readObject();
System.out.println(wanger1);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
输出结果:
Wanger{name=王二,age=18,pre=沉默,meizi=王三}
Wanger{name=王二,age=18,pre=不沉默,meizi=null}从结果的对比当中,我们可以发现:
1)序列化前,pre 的值为“沉默”,序列化后,pre 的值修改为“不沉默”,反序列化后,pre 的值为“不沉默”,而不是序列化前的状态“沉默”。
为什么呢?因为序列化保存的是对象的状态,而 static 修饰的字段属于类的状态,因此可以证明序列化并不保存 static 修饰的字段。
2)序列化前,meizi 的值为“王三”,反序列化后,meizi 的值为 null,而不是序列化前的状态“王三”。
为什么呢?transient 的中文字义为“临时的”,它可以阻止字段被序列化到文件中,在被反序列化后,transient 字段的值被设为初始值,比如 int 型的初始值为 0,对象型的初始值为 null。
3.6.5)Externalizable接口
Externalizable接口为你提供了对对象序列化过程的精细控制。下面这个表格能帮你快速把握它与常见的Serializable接口的核心区别。|
特性维度
|
Serializable |
Externalizable |
|---|---|---|
|
实现复杂度
|
简单(标记接口)
|
复杂(需实现两个方法)
|
|
控制粒度
|
自动序列化所有非
transient字段 |
完全手动控制,可自定义格式
|
|
序列化机制
|
通过反射自动完成
|
需实现
writeExternal()和readExternal()方法 |
|
反序列化机制
|
直接重建对象状态,不调用构造器
|
先调用公有无参构造器,再调用
readExternal() |
|
性能与空间
|
占用空间相对较大,含元数据
|
体积更小,速度更快,仅存储必要数据
|
|
版本兼容
|
依赖
serialVersionUID |
手动处理兼容性,更灵活
|
|
典型用例
|
通用持久化、简单网络传输
|
高性能RPC、敏感数据加密、自定义格式
|
🔧 核心工作机制
Externalizable接口赋予你完全掌控序列化过程的能力,其核心机制体现在以下两点:-
自定义序列化过程:你需要实现
writeExternal(ObjectOutput out)方法,手动决定将哪些对象状态写入流。ObjectOutput接口提供了写入基本数据类型(如writeInt,writeUTF)和对象(writeObject)的方法。写入的顺序至关重要,因为反序列化时必须按相同顺序读取。 -
特定的反序列化过程:与
Serializable不同,反序列化一个Externalizable对象时,JVM首先会调用类的公有无参构造器来创建一个新实例。如果该类没有公有无参构造器,反序列化会抛出InvalidClassException。之后,JVM调用readExternal(ObjectInput in)方法,让你根据之前写入的顺序,从流中读取数据并手动恢复对象状态。
📝 实现步骤与示例
Externalizable接口需要遵循以下步骤:-
实现接口:类必须实现
java.io.Externalizable接口。 -
提供无参构造器:这是反序列化的基础,必须为
public。 -
实现writeExternal方法:在此方法中明确指定要序列化的字段及其顺序。
-
实现readExternal方法:按照
writeExternal的写入顺序,精确读取字段值。
User类实现Externalizable接口,并在此基础上增加了简单的字段加密:import java.io.*;
public class User implements Externalizable {
private String username;
private String password; // 敏感信息
// 1. 必须的公有无参构造器
public User() {}
public User(String username, String password) {
this.username = username;
this.password = password;
}
// 2. 序列化:定义写入逻辑和简单加密
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeUTF(username); // 写入用户名
// 对密码进行简单的反转"加密"后写入
out.writeUTF(new StringBuilder(password).reverse().toString());
}
// 3. 反序列化:按顺序读取并解密
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
this.username = in.readUTF(); // 读取用户名
// 读取密码并反转回来以"解密"
String encryptedPwd = in.readUTF();
this.password = new StringBuilder(encryptedPwd).reverse().toString();
}
// ... getters and setters
}
💡 主要应用场景
Externalizable接口在以下特定场景中表现出巨大价值:-
性能优化:当你需要序列化大量对象或在高频PRC调用中传输时,
Externalizable可以生成更小的数据体积并减少反射开销,显著提升性能。 -
数据安全与加密:对于敏感数据,你可以在
writeExternal方法中先进行加密再写入,在readExternal方法中解密,确保数据在磁盘或网络传输中的安全。 -
处理复杂对象结构:当对象包含循环引用、需要序列化非
Serializable类的对象(可通过转换)或具有复杂的继承关系时,手动控制可以提供更大的灵活性。 -
实现版本兼容:类结构变更时,你可以通过自定义
readExternal方法逻辑来兼容旧版本的数据。例如,检查流中是否有新字段的数据,或为缺失的字段提供默认值。
⚠️ 使用注意事项
Externalizable功能强大,但也带来一些挑战:-
维护成本:任何字段的增删或顺序变更,都需要同步修改
writeExternal和readExternal方法,否则会引发错误。 -
错误风险:如果读写顺序不一致,会导致数据错乱且不易排查。
-
灵活性权衡:手动控制带来了灵活性,但也增加了代码量和维护负担。对于仅需排除少数字段的场景,使用
Serializable配合transient关键字可能更简单。
📊 面试考察点
Externalizable的考察重点通常包括:-
基础概念:与
Serializable的核心区别(控制方式、有无构造器、性能)。 -
实现机制:
writeExternal/readExternal方法的作用,为何需要公有无参构造器。 -
应用场景:何时选择
Externalizable(高性能、加密、自定义格式)。 -
陷阱与难点:读写顺序必须一致,缺乏无参构造器会导致的异常。
💎 简单总结
Externalizable接口是Java序列化机制中一把锋利的“手术刀”。它通过将序列化过程的控制权完全交给开发者,换来了极致的性能、更强的安全性和高度的灵活性。
3.6.6)序列化ID
serialVersionUID 被称为序列化 ID,它是决定 Java 对象能否反序列化成功的重要因子。在反序列化时,Java 虚拟机会把字节流中的 serialVersionUID 与被序列化类中的 serialVersionUID 进行比较,如果相同则可以进行反序列化,否则就会抛出序列化版本不一致的异常。
当一个类实现了 Serializable 接口后,IDE 就会提醒该类最好产生一个序列化 ID,就像下面这样:

1)添加一个默认版本的序列化 ID:
private static final long serialVersionUID = 1L。2)添加一个随机生成的不重复的序列化 ID。
private static final long serialVersionUID = -2095916884810199532L;3)添加 @SuppressWarnings 注解。
@SuppressWarnings("serial")首先,我们采用第二种办法,在被序列化类中添加一个随机生成的序列化 ID。
class Wanger implements Serializable {
private static final long serialVersionUID = -2095916884810199532L;
private String name;
private int age;
// 其他代码忽略
}然后,序列化一个 Wanger 对象到文件中。
// 初始化
Wanger wanger = new Wanger();
wanger.setName("王二");
wanger.setAge(18);
System.out.println(wanger);
// 把对象写到文件中
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("chenmo"));) {
oos.writeObject(wanger);
} catch (IOException e) {
e.printStackTrace();
}这时候,我们悄悄地把 Wanger 类的序列化 ID 偷梁换柱一下,嘿嘿。
// private static final long serialVersionUID = -2095916884810199532L;
private static final long serialVersionUID = -2095916884810199533L;好了,准备反序列化吧。
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream(new File("chenmo")));) {
Wanger wanger = (Wanger) ois.readObject();
System.out.println(wanger);
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}哎呀,出错了。
java.io.InvalidClassException: local class incompatible: stream classdesc
serialVersionUID = -2095916884810199532,
local class serialVersionUID = -2095916884810199533
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1521)
at com.cmower.java_demo.xuliehua1.Test.main(Test.java:27)异常堆栈信息里面告诉我们,从持久化文件里面读取到的序列化 ID 和本地的序列化 ID 不一致,无法反序列化。
那假如我们采用第三种方法,为 Wanger 类添加个 @SuppressWarnings("serial") 注解呢?
@SuppressWarnings("serial")
class Wanger implements Serializable {
// 省略其他代码
}好了,再来一次反序列化吧。可惜依然报错。
java.io.InvalidClassException: local class incompatible: stream classdesc
serialVersionUID = -2095916884810199532,
local class serialVersionUID = -3818877437117647968
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1521)
at com.cmower.java_demo.xuliehua1.Test.main(Test.java:27)异常堆栈信息里面告诉我们,本地的序列化 ID 为 -3818877437117647968,和持久化文件里面读取到的序列化 ID 仍然不一致,无法反序列化。这说明什么呢?使用 @SuppressWarnings("serial") 注解时,该注解会为被序列化类自动生成一个随机的序列化 ID。
由此可以证明,Java 虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,还有一个非常重要的因素就是序列化 ID 是否一致。
也就是说,如果没有特殊需求,采用默认的序列化 ID(1L)就可以,这样可以确保代码一致时反序列化成功。
class Wanger implements Serializable {
private static final long serialVersionUID = 1L;
// 省略其他代码
}总结
serialVersionUID)是 Java 序列化机制中用于版本控制的关键标识符。|
特性
|
显式声明 serialVersionUID
|
依赖 JVM 默认生成
|
|---|---|---|
|
控制力
|
完全手动控制,值由开发者指定
|
自动生成,值由 JVM 根据类结构决定
|
|
稳定性
|
稳定,除非主动修改,否则不变
|
敏感,类结构(字段、方法等)任何变更都可能引起变化
|
|
版本兼容性
|
灵活可控,可主动决定是否兼容旧版本
|
严格且脆弱,类结构稍有变动即可能导致反序列化失败
|
|
一致性保证
|
在不同 JVM、编译器环境下保持一致
|
可能因 JVM 实现、编译器版本不同而产生差异
|
|
推荐度
|
✅ 强烈推荐
|
❌ 不推荐,尤其在需要序列化的类中
|
🔧 核心工作机制
serialVersionUID是一个静态常量,用于标识一个可序列化类的版本。它的核心工作机制是验证反序列化时的版本一致性。-
序列化时:JVM 会将当前类的
serialVersionUID写入字节流。 -
反序列化时:JVM 会将字节流中的
serialVersionUID与本地当前类的serialVersionUID进行比较。-
如果两者相同,则认为版本兼容,反序列化继续进行。
-
如果两者不同,则会抛出
InvalidClassException,反序列化失败。
-
serialVersionUID时,JVM 会根据类的全限定名、属性、方法、接口等结构信息,通过一个复杂的算法(如 SHA-1)自动生成一个。这意味着,任何对类结构的修改(甚至是添加一个空格或注释)都可能导致自动生成的 ID 发生变化。💡 实际应用场景
-
保证版本兼容性这是
serialVersionUID最核心的应用。当你的类需要升级,但又希望反序列化旧版本数据时,显式声明serialVersionUID至关重要。-
场景:你的
User类 V1.0 只有name字段。升级到 V2.0 后,新增了email字段。如果你显式声明了相同的serialVersionUID,那么 V2.0 的程序仍然可以成功反序列化 V1.0 时期保存的数据,新字段email会被设置为默认值(如null)。 -
反之:如果没有显式声明,V2.0 类会自动生成一个新的 ID,与 V1.0 数据的 ID 不匹配,导致反序列化失败。
-
-
在分布式系统(RPC/RMI)中的应用在分布式系统中,对象经常需要在客户端和服务端之间传输。显式声明
serialVersionUID可以确保即使客户端和服务端的类文件不是同时编译的,只要serialVersionUID一致,反序列化就能成功,避免了因 JVM 或编译器差异导致的问题。 -
用于访问控制(不常见但值得了解)在一个特殊的设计模式(如 Façade 模式)中,服务器端可以通过更改
serialVersionUID并发布新的客户端 Jar 包,来强制客户端升级到最新版本。当旧客户端尝试反序列化服务器端的新对象时,会因 ID 不匹配而失败,从而实现访问控制。
⚠️ 使用要点与最佳实践
-
显式声明是首选阿里巴巴 Java 开发手册等规范都强制要求为可序列化类显式声明
serialVersionUID。这可以避免因无关紧要的改动(如添加注释)导致的意外反序列化失败,并提供稳定的版本控制基础。 -
谨慎处理类结构变更显式声明
serialVersionUID赋予了灵活性,但也意味着你需要对兼容性负责。-
向后兼容的修改:增加字段、删除字段(反序列化时新字段为默认值,旧字段丢失)、将字段改为
transient等,通常可以保持serialVersionUID不变。 -
不兼容的修改:更改字段类型、更改类名、删除方法等破坏性修改,必须更改
serialVersionUID的值,以明确表示不兼容,防止数据错乱。
-
-
理解不被序列化的数据无论
serialVersionUID如何,static静态变量和transient修饰的成员变量都不会被序列化。
📊 面试考察点
serialVersionUID的考察重点非常集中:|
考察角度
|
典型问题
|
回答要点
|
|---|---|---|
|
基础概念
|
什么是
serialVersionUID?它的作用是什么? |
强调其版本控制的核心作用,是序列化/反序列化过程的“密码”。
|
|
工作机制
|
不声明会怎样?声明了会怎样?
|
对比显式声明(稳定、可控)和默认生成(易变、脆弱)的区别。
|
|
应用场景
|
实际开发中为什么要显式声明?
|
结合版本升级和分布式系统场景,说明其对于保证兼容性和稳定性的重要性。
|
|
陷阱与难点
|
类结构变了但ID没变,会怎样?
|
说明可能导致的数据错乱(如字段类型不匹配),强调需要开发者自己判断兼容性。
|
💎 总结与建议
serialVersionUID是 Java 序列化机制中一把简单但关键的“钥匙”。在学习和实践中,请牢记以下几点:-
养成习惯:为每一个实现
Serializable接口的类显式声明一个serialVersionUID。 -
保持稳定:在类的生命周期内,不要随意修改已定义的
serialVersionUID,除非你明确要进行不兼容的升级。 -
明确职责:显式声明给了你控制权,也意味着你需要负责评估类结构变更对序列化兼容性的影响。
3.6.7)transient 关键字
在实际开发过程中,我们常常会遇到这样的问题,一个类的有些字段需要序列化,有些字段不需要,比如说用户的一些敏感信息(如密码、银行卡号等),为了安全起见,不希望在网络操作中传输或者持久化到磁盘文件中,那这些字段就可以加上 transient 关键字。
需要注意的是,被 transient 关键字修饰的成员变量在反序列化时会被自动初始化为默认值,例如基本数据类型为 0,引用类型为 null。
(1)一旦字段被 transient 修饰,成员变量将不再是对象持久化的一部分,该变量的值在序列化后无法访问。
(2)transient 关键字只能修饰字段,而不能修饰方法和类。
(3)被 transient 关键字修饰的字段不能被序列化,一个静态变量(static关键字修饰)不管是否被 transient 修饰,均不能被序列化
在 Java 中,对象的序列化可以通过实现两种接口来实现,如果实现的是 Serializable 接口,则所有的序列化将会自动进行,如果实现的是 Externalizable 接口,则需要在 writeExternal 方法中指定要序列化的字段,与 transient 关键字修饰无关。
public class ExternalizableTest implements Externalizable {
private transient String content = "是的,我将会被序列化,不管我是否被transient关键字修饰";
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(content);
}
@Override
public void readExternal(ObjectInput in) throws IOException,
ClassNotFoundException {
content = (String) in.readObject();
}
public static void main(String[] args) throws Exception {
ExternalizableTest et = new ExternalizableTest();
ObjectOutput out = new ObjectOutputStream(new FileOutputStream(
new File("test")));
out.writeObject(et);
ObjectInput in = new ObjectInputStream(new FileInputStream(new File(
"test")));
et = (ExternalizableTest) in.readObject();
System.out.println(et.content);
out.close();
in.close();
}
}
结果
是的,我将会被序列化,不管我是否被transient关键字修饰
transient 关键字用于修饰类的成员变量,在序列化对象时,被修饰的成员变量不会被序列化和保存到文件中。其作用是告诉 JVM 在序列化对象时不需要将该变量的值持久化,这样可以避免一些安全或者性能问题。但是,transient 修饰的成员变量在反序列化时会被初始化为其默认值(如 int 类型会被初始化为 0,引用类型会被初始化为 null),因此需要在程序中进行适当的处理。
transient 关键字和 static 关键字都可以用来修饰类的成员变量。其中,transient 关键字表示该成员变量不参与序列化和反序列化,而 static 关键字表示该成员变量是属于类的,不属于对象的,因此不需要序列化和反序列化。
在 Serializable 和 Externalizable 接口中,transient 关键字的表现也不同,在 Serializable 中表示该成员变量不参与序列化和反序列化,在 Externalizable 中不起作用,因为 Externalizable 接口需要实现 readExternal 和 writeExternal 方法,需要手动完成序列化和反序列化的过程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号